1.Prometheus配置文件
Prometheus可以通过命令行或者配置文件的方式对服务进行配置。
- 命令行方式一般用于不可变的系统参数配置,例如存储位置、要保留在磁盘和内存中的数据量等;配置文件用于定义与数据动态获取相关的配置选项和文件等内容。
- 命令行方式的配置属性可以通过 prometheus -h 的方式来获取,这些配置属性主要在服务启动时候设置;
- 配置文件方式,需要在prometheus.yml 文件中修改配置属性,该配置文件的内容是以YAML格式编写的。
1.1 配置文件的组成
]# egrep -v '^#| #|^$' prometheus.yml
global:
scrape_interval: 15s
evaluation_interval: 15s
alerting:
alertmanagers:- static_configs:- targets:
rule_files:
scrape_configs:- job_name: 'prometheus'static_configs:- targets: ['localhost:9090']
#核心配置:
global #全局配置内容
alerting #触发告警相关的配置,主要是与Alertmanager相关的设置。
rule_files #各种各样的外置规则文件配置,包含了各种告警表达式、数据查询表达式等
scrape_configs #监控项的配置列表,这是最核心的配置
#除了默认的四项配置之外,prometheus还有另外可选的其它配置如下
#扩展配置(8项)
tls_config、static_config、relabel_config、metric_relabel_configs、
alert_relabel_configs、alertmanager_config、remote_write、remote_read
#平台集成配置(12项)
azure_sd_config、consul_sd_config、dns_sd_config、ec2_sd_config、
openstack_sd_config、file_sd_config、gce_sd_config、kubernetes_sd_config、
marathon_sd_config、nerve_sd_config、serverset_sd_config、triton_sd_config
1.2 scrape_configs 管理
scrape_configs 是操作最多的一个配置段,它指定了一组监控目标及其细节配置参数,这些目标和参数描述了如何获取指定主机上的时序数据。配置样例如下
scrape_configs:- job_name: '<job_name>'static_configs:- targets: [ '<host_ip:host_port>', ... ]labels: { <labelname>: <labelvalue> ... }
#配置解析:
#在一般情况下,一个scrape_configs配置需要指定一个或者多个job,根据我们之前对基本概念的了解,
每一个job都是一系列的instance集合,借助job我们可以将目标主机进行分组管理。
#对于job内部的每一个instance的配置,都需要借助于static_configs参数获取目标列表,只要在该列表
位置的目标,都可以被Prometheus动态服务自动发现。
#static_configs可以借助于 targets 以ip+port 方式发现目标,也可以使用labels以标签方式发现
目标
1.3 语法检查
对配置的prometheus进行语法检查
/etc/prometheus $ promtool check config prometheus.yml
Checking prometheus.ymlSUCCESS: prometheus.yml is valid prometheus config file syntax2. 标签简介
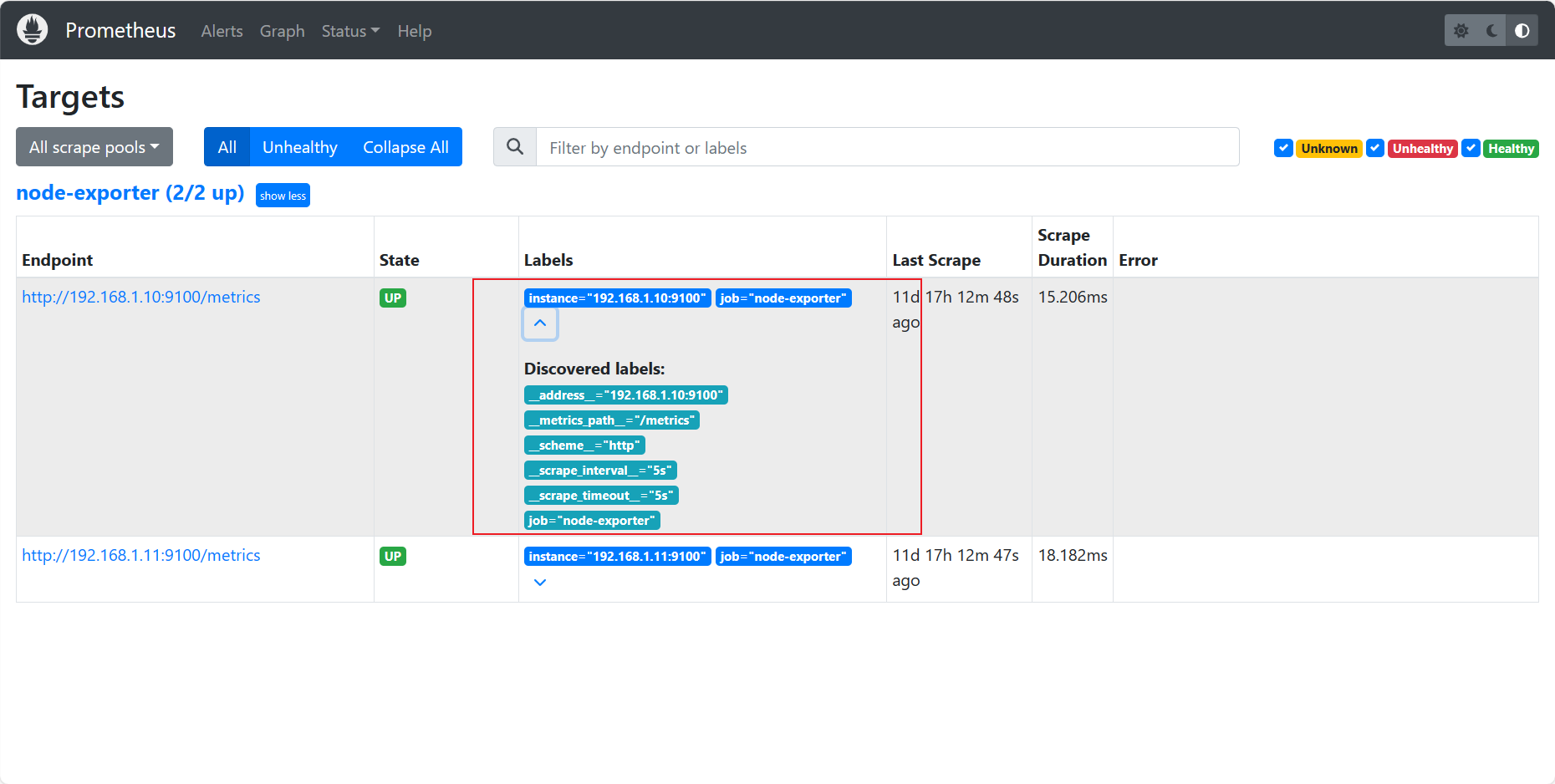
标签功能: 用于对数据分组和分类,利用标签可以将数据进行过滤筛选
标签的常见场景:
- 删除不必要的指标
- 从指标中删除敏感或不需要的标签
- 添加、编辑或修改指标的标签值或标签格式
标签分类:
- 默认标签: Prometheus 自身内置
形式: keyname
- 应用标签: 应用本身内置
形式: keyname
- 自定义标签: 用户定义
形式: keyname
2.1 添加主机标签
global:scrape_interval: 15s external_labels:monitor: 'codelab-monitor'
scrape_configs:- job_name: 'node-exporter' scrape_interval: 5smetrics_path: /metrics static_configs:- targets: ['192.168.1.10:9100','192.168.1.11:9100'] - job_name: 'test-1'static_configs:- targets: ['192.168.1.12:9100']labels: {app: 'k8s-node2', type: 'dev'}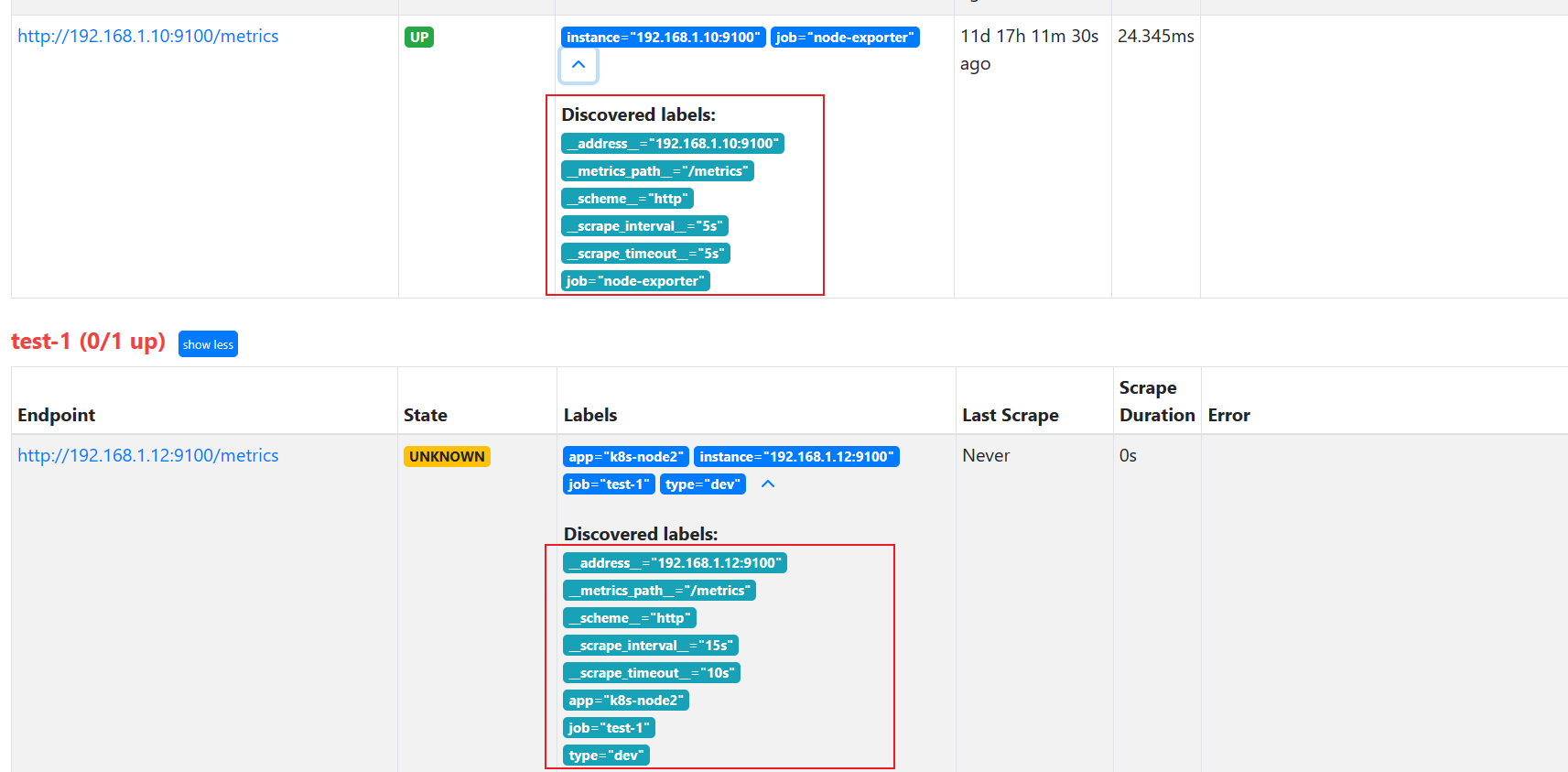
我们发现增加了app这个便签
2.2 标签管理
Prometheus对数据的处理流程是:
先从各目标节点上获取数据,然后对数据进行本地化处理,然后进行各种数据分析。这个流程中最核心的就是监控数据的本地化处理
在prometheus的配置选项中,有两个与监控指标密切相关的配置,relabel_config,metric_relabel_configs,他们的作用就是监控目标上面的监控项进行标签管理和设置,便于在
prometheus上设置更灵活的时序数据。
2.2.1 标签主要有两种表现形式:
私有标签
私有标签以"__*"样式存在,用于获取监控目标的默认元数据属性,比如__address__用于获取目标的
地址,__scheme__用户获取目标的请求协议方法,__metrics_path__获取请求的url地址等
普通标签
对个监控主机节点上的监控指标进行各种灵活的管理操作,常见的操作有,删除不必要|敏感指标,添
加、编辑或者修改指标的标签值或者标签格式
2.2.2 全局标签
global:
...# 与外部系统通信时添加到任何时间序列或警报的标签
external_labels:[ <labelname>: <labelvalue> ... ]
relabel_config、metric_relabel_configs 的使用格式基本上一致,虽然他们有很多配置,但是我们使用的最多的也就那么三四个。
#配置示例如下:
scrape_configs:- job_name: 'prometheus'metric_relabel_configs:- source_labels: [<labelname> [, ...]]regex: '<regex> | default = (.*)'replacement: '<string> | default = $1'target_label: '<labelname>'action: '<relabel_action> | default = replace'
#属性解析:
source_labels #指定正则表达式匹配成功的Label进行标签管理
regex #source_labels对应Label的匹配正则表达式的指定值
target_label #在进行标签替换的时候,可以将原来的source_labels替换为指定修改后的
label
replacement #替换标签时,指定label对应的值进行修改后的值
action #对标签进行管理,常见的动作有replace|keep|drop|labelmap|labeldrop
等
#动作解析:
labeldrop #删除regex匹配的标签label
labelkeep #删除regex不匹配的标签label
labelmap #将regex对所有的标签名进行匹配,而后将匹配到的标签的值赋给replacement字段指定的
标签名的值;通常用于取出匹配的标签名的一部分生成新标签,旧的标签仍会存在
replace #此为默认值,通过regex匹配source_label的值,使用replacement来进行替换
keep #从获取的监控数据中删除与regex不匹配的目标 source_labels
drop #从获取的监控数据中删除与regex匹配的目标 source_labels
2.3 默认标签修改为定制新标签
修改前的:
global:scrape_interval: 15s external_labels:monitor: 'codelab-monitor'
scrape_configs:- job_name: 'node-exporter'
# scrape_interval: 5s
# metrics_path: /metrics static_configs:- targets: ['192.168.1.10:9100','192.168.1.11:9100'] relabel_configs:- source_labels:- __scheme__- __address__- __metrics_path__regex: "(http|https)(.*)"separator: ""target_label: "endpoint"replacement: "${1}://${2}"action: replace- job_name: 'test-1'static_configs:- targets: ['192.168.1.12:9100']labels: {app: 'k8s-node2', type: 'dev'}2.4 基于已存在的标签进行删除
2.4.1 匹配内容重写标签名称
static_configs:- targets: ['192.168.1.10:9100','192.168.1.11:9100'] relabel_configs:- source_labels:- __scheme__- __address__- __metrics_path__regex: "(http|https)(.*)"separator: ""target_label: "endpoint"replacement: "${1}://${2}"action: replace- regex: "(job|app)" #所有名为job或app的标签修改标签名称,但旧的标签还会存在replacement: ${1}_nameaction: labelmap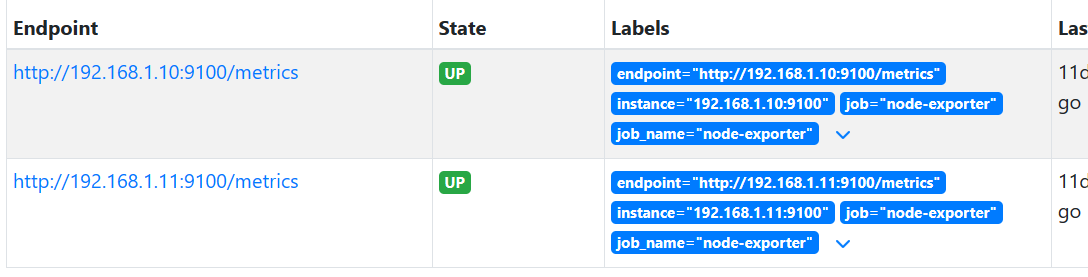
2.4.2 删除旧标签的名称
scrape_configs:- job_name: 'node-exporter'
# scrape_interval: 5s
# metrics_path: /metrics static_configs:- targets: ['192.168.1.10:9100','192.168.1.11:9100'] relabel_configs:- source_labels:- __scheme__- __address__- __metrics_path__regex: "(http|https)(.*)"separator: ""target_label: "endpoint"replacement: "${1}://${2}"action: replace- regex: "(job|app)" #所有名为job或app的标签修改标签名称,但旧的标签还会存在replacement: ${1}_nameaction: labelmap- regex: "(job|app)" #加下面两行,则删除旧的标签,注意上面修改和此删除的前后顺序action: labeldrop
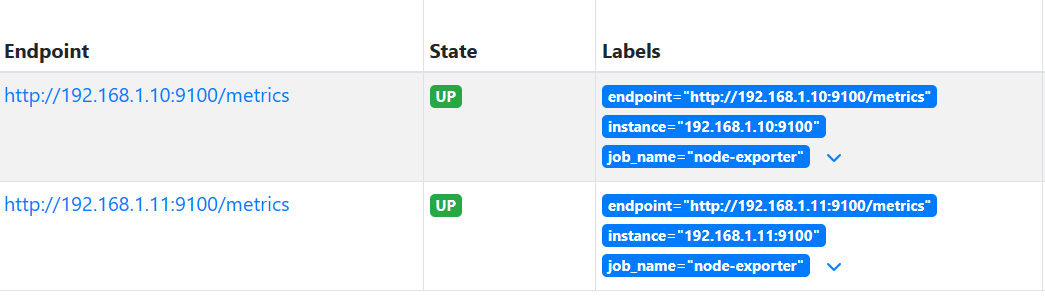
3.Promsql
3.1 数据选择器
所谓的数据选择器,其实指的是获取实时数据或者历史数据的一种方法
metrics_name{筛选label=值,...}[<时间范围>] offset <偏移>
3.1.1 实时选择器
获取及时的一组时间序列和单个样本值,根据数据的精确度,可以有以下几种使用方法
3.1.1.1 根据监控项名称获取最新值
node_filefd_allocated
prometheus_http_requests_total
3.1.1.2 通过{key=value,}样式获取符合条件的数据值
prometheus_http_requests_total{instance="localhost:9090", job="prometheus"}
prometheus_http_requests_total{handler=~".*meta.*"}
#属性解析:
多个条件间可以使用逗号","隔开,每个条件内部可以通过多种符号,表示不同含义
=(精确匹配)、!=(不匹配)、=~(正则匹配)、!~(正则不匹配)
如果条件中存在多值,可以使用"|"表示或的意思,env=~"staging|testing|development"
条件中必须包含一个与空标签值不匹配的选择器,不能写成{job=~".*"}
node_memory_MemFree_bytes{instance=~"10.0.0.(101|102):9100"}
#注意:指标 prometheus_http_requests_total 默认情况下,针对的是 localhost:9090 的
target,其他无效
3.1.1.3 通过 name 匹配多个监控项的名称
{__name__="prometheus_http_requests_total"}
{__name__=~"^prometheus.*"}
3.1.2 范围选择器
工作方式与瞬时向量选择器一样,区别在于时间范围长一些,主要是在瞬时选择器多了一个[]格式的时间范围后缀,在[]内部可以采用多个单位表示不同的时间范围,比如s(秒)、m(分)、h(时)、d(日)、w(周)、y(年)
prometheus_http_requests_total{job="prometheus"}[5m]
#属性解析:这表示过去5分钟内的监控数据值,这些数据一般以表格方式展示,而不是列表方式展示
3.1.2.1 偏移修饰符
范围选择器可以获取最近时间段的数据,而对于某个历史时间段中的数据,就需要通过offset时间偏移的方式来进行获取了。
prometheus_http_requests_total offset 5m
prometheus_http_requests_total{code="200"} offset 5m
prometheus_http_requests_total{handler="/metrics"}[5m] offset 3m
#注意:offset与数据选择器是一个整体,不能分割,offset 偏移的是时间点
如果既有偏移又有范围,先偏移后再取范围,如[5m] offset 3m 表示取当前时间的3分钟前的5m范围的值
3.2 查询语法格式
3.2.1 二元运算符
对于二元运算符来说,它主要包含三类:算术、比较、逻辑,作用效果与我们平常使用的效果一致
#算术运算符:+、-、*、/、%、^
#比较运算符:==、!=、=~、!~>、<、>=、<=
#逻辑运算符:and、or、unless 目前该运算符仅允许在两个即时向量之间进行操作,不支持标量(标量只有
一个数字,没有时序)参与运算
#运算符优先级:
1 ^
2 *, /, %
3 +, -
4 ==, !=, <=, <, >=, >
5 and, unless
6 or#注意:二元运算符是prometheus进行数据可视化或者数据分析操作的时候,应用非常多的一种功能。