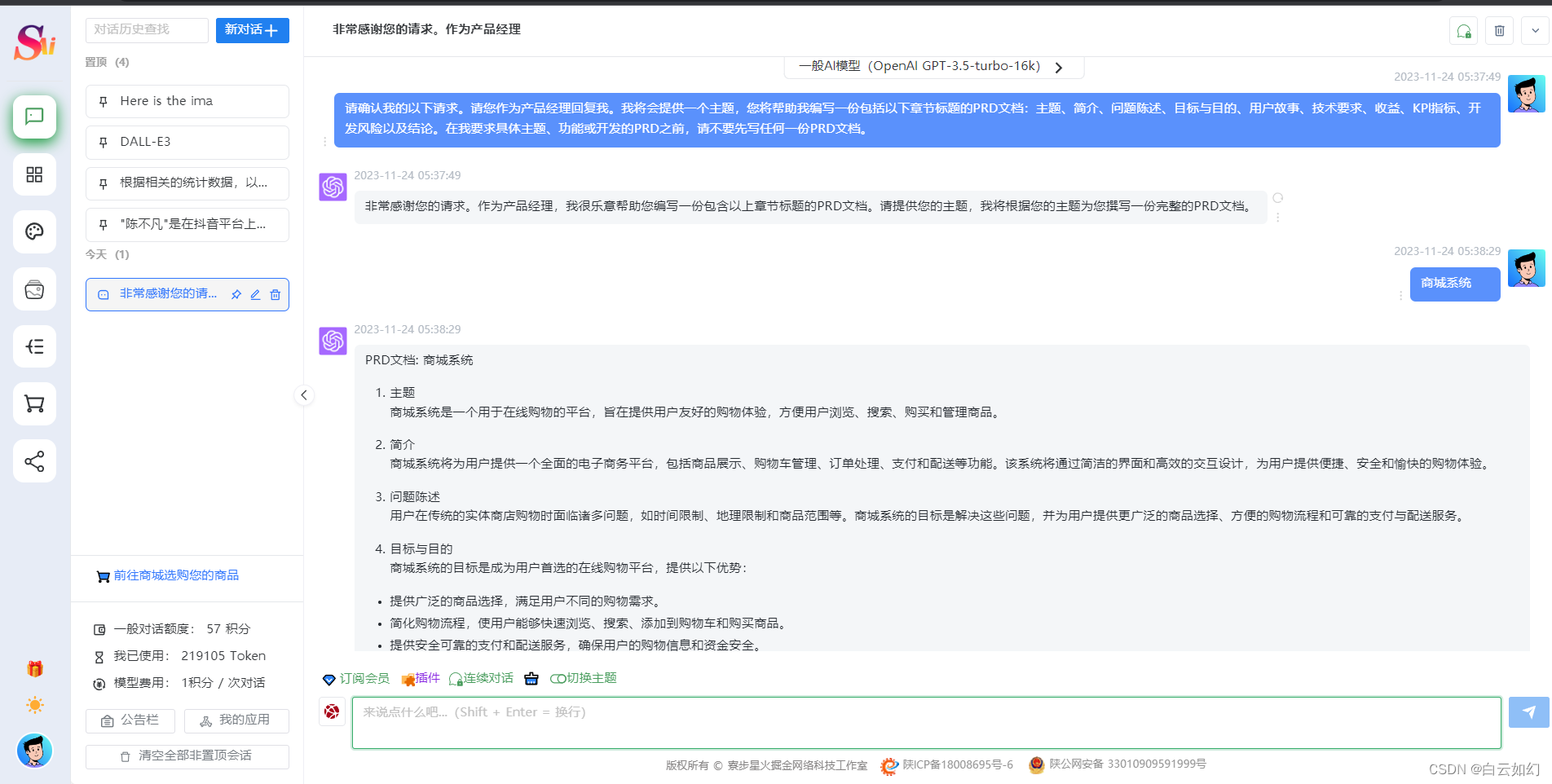
jsonpath只能解析本地文件
jsonpath的使用:
obj = json.load(open('.json文件','r',encoding='utf-8'))place_name = jsonpath.jsonpath(obj, 'json语法')
目录
1.安装jsonpath
2.Xpath和jsonpath的语法对比
练习:使用jsonpath解析JSON文件
3.使用jsonpath抓取淘票票中的城市名称
参考
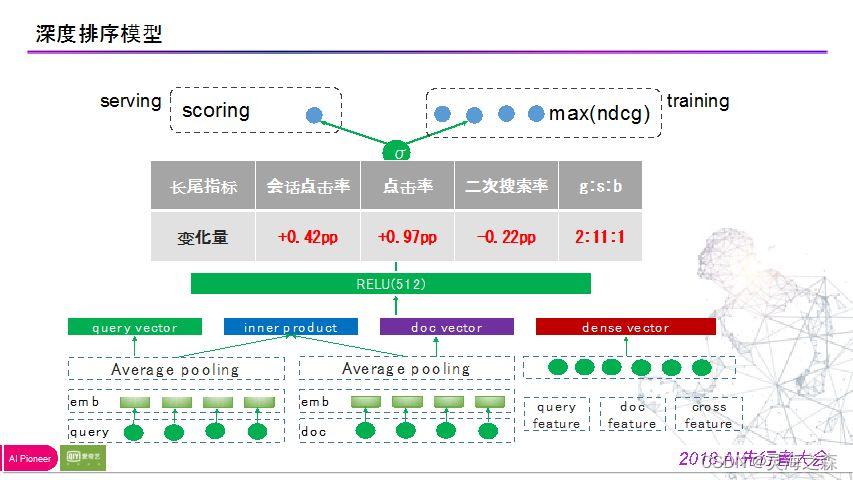
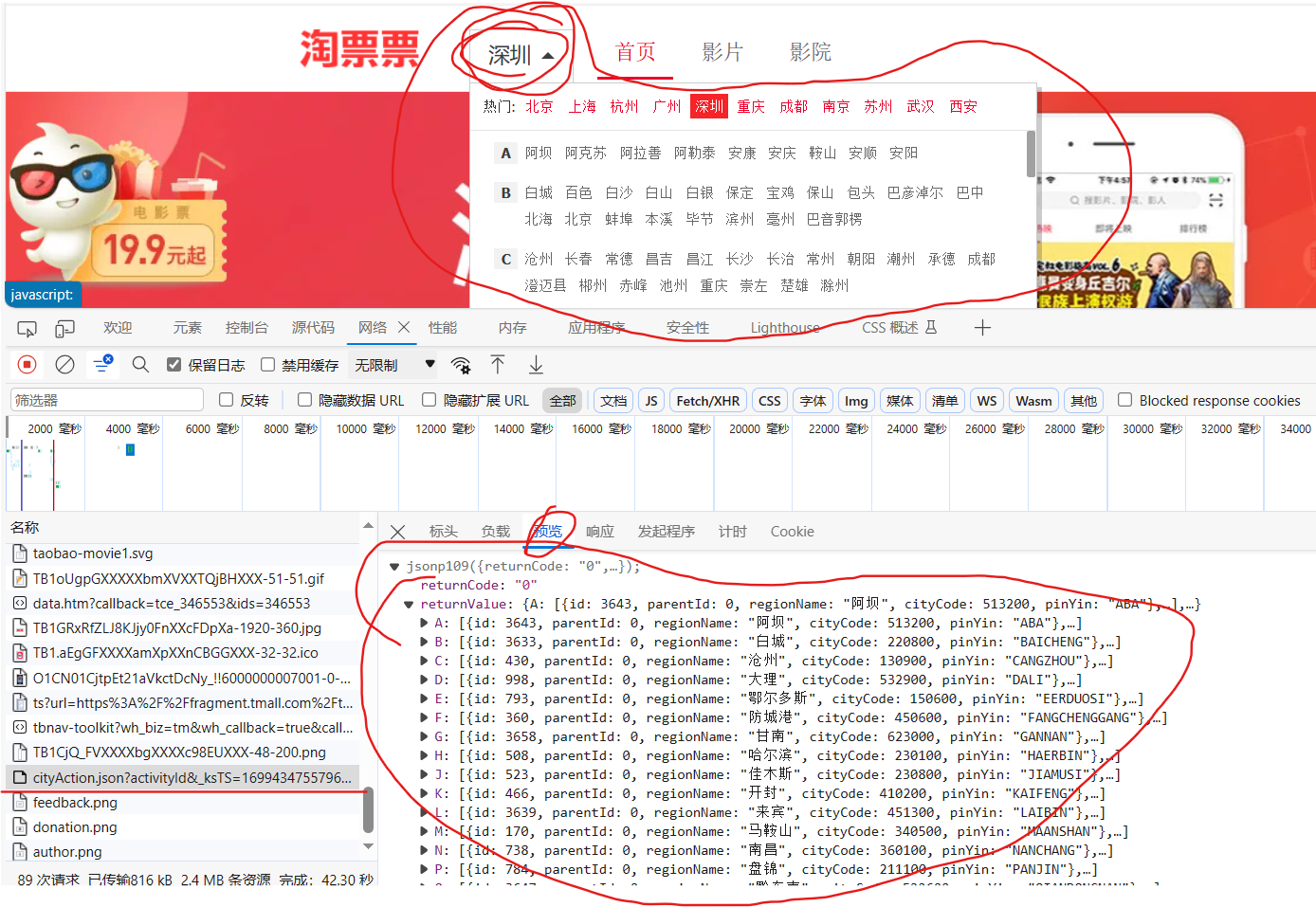
应用场景
打开检查中的网络,当鼠标悬浮在“深圳”这个位置上时,就会出现一个下拉列表,我门点击左侧新出现的名称后,从预览中可以看到与上面对应的所有的城市名称,我们就可以用jsonpath把这些城市都爬下来。
1.安装jsonpath
pip install jsonpath
2.Xpath和jsonpath的语法对比

练习:使用jsonpath解析JSON文件
JSON文件
{ "store": {"book": [{ "category": "reference","author": "Nigel Rees","title": "Sayings of the Century","price": 8.95},{ "category": "fiction","author": "Evelyn Waugh","title": "Sword of Honour","price": 12.99},{ "category": "fiction","author": "Herman Melville","title": "Moby Dick","isbn": "0-553-21311-3","price": 8.99},{ "category": "fiction","author": "J. R. R. Tolkien","title": "The Lord of the Rings","isbn": "0-395-19395-8","price": 22.99}],"bicycle": {"author": "me","color": "red","price": 19.95}}
}练习代码:
import json
import jsonpathobj = json.load(open('_073.json', 'r', encoding='utf-8'))
# 所有的作者
book_author = jsonpath.jsonpath(obj, '$.store.book.*.author')
print(book_author)# 所有的作者
# author = jsonpath.jsonpath(obj,'$.store..author')
author = jsonpath.jsonpath(obj,'$..author')
print(author)# store下的所有元素
element= jsonpath.jsonpath(obj,'$.store.*')
print(element)# store里面所有的钱
price = jsonpath.jsonpath(obj, '$.store..price')
# price = jsonpath.jsonpath(obj, '$..price')
print(price)# 第三个书
book = jsonpath.jsonpath(obj, '$.store.book[2].title')
print(book)# 最后一本书
last_book = jsonpath.jsonpath(obj, '$.store.book[(@.length-1)].title')
print(last_book)# 前两本书
first_book = jsonpath.jsonpath(obj, '$.store.book[:2].title')
print(first_book)# 过滤出所有包含编号的书
# 条件过滤需要在()的前面添加一个“?”
id_book = jsonpath.jsonpath(obj, '$..book[?(@.isbn)]')
print(id_book)# 哪本书超过了十块钱
top_price = jsonpath.jsonpath(obj, '$..book[?(@.price>10)]')
print(top_price)3.使用jsonpath抓取淘票票中的城市名称
获取我们所需要的JSON数据,并保存为JSON格式。
这里需要注意的就是header的问题,选择合适的请求头极为重要。
# 获取网页的源码
url = 'https://dianying.taobao.com/cityAction.json?activityId&_ksTS=1699438000391_108&jsoncallback=jsonp109&action=cityAction&n_s=new&event_submit_doGetAllRegion=true'
headers = {# 带 ":" 的请求头不好使"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/119.0.0.0 Safari/537.36 Edg/119.0.0.0","Cokkie":"cna=78fBGrbzhCMCAXjATRb+saw5; t=e7c798fa12372a57ee31f10dfd51cd4e; cookie2=1d03be736b566af7ea39001ed7fa3c8f; v=0; _tb_token_=e3b433bbbe03e; xlly_s=1; tfstk=dmCXbdYCzmmjr9JtgSaPVwh_85d_8iNUlVTO-NhqWIdv55sN4q7V7sWWWGSuSrAVWhs143b2Ql4mWTscJKS1SrY9XGI6btyzTZbDsCEFfWPFovp26kRTr2yhoCATY4lTLW_cYs2DvGBZP7NTiaZSwbGUKa3xooujl_T8jHQjTfTPNEgMAZK7jlXwdX-QYtDsPpc6PHz7PADGFn8r6; l=fBLfzOEPPRd-YECUBO5Bnurza77T5IRb41PzaNbMiIEGa6KCtFaihNCTsYuBSdtjgTCcBetrWDM-1dLHR3xg5c0c0KDtBa2K3xvtaQtJe; isg=BKamDko1_3qxi6vekFBO7lel9xwoh-pB-d4dQ5BPeUmkE0Yt-BaVUc7taw-fvOJZ","Referer":"https://dianying.taobao.com/index.htm?n_s=new"
}
# 请求对象定制
request = urllib.request.Request(url, headers=headers)
# 模拟客户端向服务器发送请求
response = urllib.request.urlopen(request)
# 获取网页源码
content = response.read().decode('utf-8')
with open('_074.json','w',encoding='utf-8') as file:file.write(content)然后我们就开始解析JSON文件
保存之后我们可以看到,前面有个json109()的头,我们把这一部分删除就可以了。
或者对保存JSON文件前对content进行操作
content = content.split('(')[1].split(')')[0]
开始解析JSON文件。
import json
import jsonpath
obj = json.load(open('_074.json','r',encoding='utf-8'))
place_name = jsonpath.jsonpath(obj, '$..regionName')
print(place_name)
用好了JSON解析数据真的太方便了。
对比一下使用字典的方式提取name,需要嵌套两层循环。
import json
obj = json.load(open('_074.json','r',encoding='utf-8'))
name = []
for key, value in obj['returnValue'].items():temp = obj['returnValue'][key]for i in temp:name.append(i["regionName"])
print(name)参考
尚硅谷Python爬虫教程小白零基础速通(含python基础+爬虫案例)