语雀原文链接
文章目录
- 1、概述
- 2、代码段中使用数据
- 示例1:不指定程序入口
- 示例2:指定程序入口
- 原理梳理
- 3、在代码段中使用栈
- 例子1
- 例子2
- 4、数据、代码、栈放入不同的段
- 例子1:end start指定程序入口
- 第一步:设置栈顶
- 第二步:设置DS
- 第三步:push入栈
- 第四步:pop出站
- 第五步:程序退出
- 误解
- 例子2:段占据空间是16的倍数
- 例子3:db的使用
1、概述
- 在操作系统的环境中,合法地通过操作系统取得的空间都是安全的,因为操作系统不会让一个程序所用的空间和其他程序以及系统自己的空间相冲突。在操作系统允许的情况下,程序可以取得任意容量的空间。
- 程序取得所需空间的方法有两种,一是在加载程序的时候为程序分配,再就是程序在执行的过程中向系统申请。这里我们主要研究下第一种方式:加载程序的时候为程序分配空间。
- 我们若要一个程序在被加载的时候取得所需的空间,则必须要在源程序中做出说明。我们通过在源程序中定义段来进行内存空间的获取。
2、代码段中使用数据
- 目前有这样一个需求,计算8个数据之和,结果存储在AX寄存器中。可以先将这8个数放在一个连续的内存单元中。但是这里有个问题,这个内存单元具体在哪里?
- 从规范的角度来讲,我们是不能自己随便决定哪段空间可以以使用的,应该让系统来为我们分配。我们可以在程序中,定义我们希望处理的数据,这些数据就会被编译、连接程序作为程序的一部分写到可执行文件中。当可执行文件中的的程序被加载入内存时,这些数据也同时被加载入内存中。与此同时,我们要处理的数据也就自然而然地获得了存储空间。
示例1:不指定程序入口
- dw 的含义是定义字型数据,dw 即 define word,字型数据可以直接放入寄存器中去,因为数据寄存器的大小也是一个字的大小
- db 的含义是定义字节型数据,db 即 define byte,字节型数据应该使用数据寄存器的高 8 位或是低 8 位进行存放。
assume cs:code
code segmentdw 0123h,0456h,0789h,0abch,0defh,0fedh,0cbah,0987hmov bx,0mov ax,0mov cx,8s:add ax,cs:[bx]add bx,2loop smov ax,4c00hint 21hcode endsend
- 编译链接debug调试如下

- 程序是从CS:IP=076A:0000开始存放,但是-u命令是看不懂的程序,和我们的程序不太一样。仔细一看是我们076A:0000 000F保存的是我们的8个数据,每个占用2个字节,总共16个字节;从076A:0010开始才是我们的程序
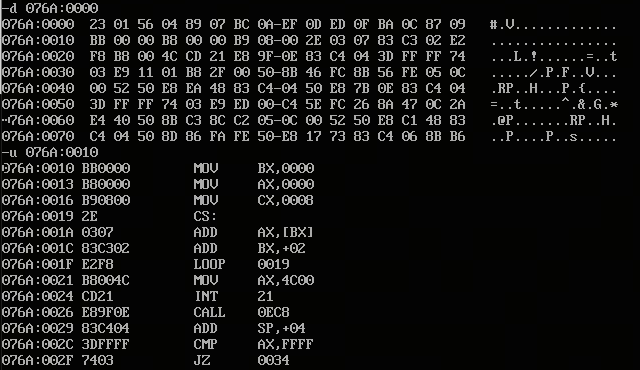
- 上述程序我们无法直接执行,只有将IP=0010h后才能指向程序的第一条指令,才能执行。
示例2:指定程序入口
- end除了通知编译器程序结束外,还可以通知编译器程序的入口在什么地方。
- 下述代码表示程序的入口在标号start处,也就是mov bx,0
assume cs:code
code segmentdw 0123h,0456h,0789h,0abch,0defh,0fedh,0cbah,0987hstart: mov bx,0mov ax,0mov cx,8s: add ax,cs:[bx]add bx,2loop smov ax,4c00hint 21hcode endsend start
- 编译链接debug运行后,发现CS:IP=076A:0010,也能正常执行了

原理梳理
- 接下来我们在梳理下大致原理,在单任务系统中,可执行文件中的程序执行过程如下
- 由其他的程序(Debug、command或其他程序)将可执行文件牛中的程序加载入内存;
- 设置CS:IP指向程序的第一条要执行的指令(即程序的入口),从而使程序得以运行;
- 程序运行结束后,返回到加载者。
- 现在的问题是,根据什么设置CPU的CS:IP指向程序的第一条要执行的指令?这一点,是由可执行文件中的描述信息指明的。我们知道可执行文件由描述信息和程序组成,程序来自于源程序中的汇编指令和定义的数据:描述信息则主要是编译、连接程序对源程序中相关伪指令进行处理所得到的信息。用伪指令end描述了程序的结束和程序的入口。在编译、连接后,由"end start"指明的程序入口,被转化为一个入口地址,存储在可执行文件的描述信息中。
- 标号不局限于start,也可以使用其他符号
assume cs:code
code segmentdw 0123h,0456h,0789h,0abch,0defh,0fedh,0cbah,0987hstart123: mov bx,0mov ax,0mov cx,8s: add ax,cs:[bx]add bx,2loop smov ax,4c00hint 21hcode endsend start123
- 因此,程序的框架大致如下

3、在代码段中使用栈
- 将程序中定义的数据逆序存放,利用栈来实现
assume cs:code
code segmentdw 0123h,0456h,0789h,0abch,0defh,0fedh,0cbah,0987hdw 0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0start: mov ax,csmov ss,axmov sp,30hmov bx,0mov cx,8s: push cs:[bx]add bx,2loop smov bx,0mov cx,8s0: pop cs:[bx]add bx,2loop s0mov ax,4c00hint 21hcode endsend start
- cs:0~cs:f 存储8个字,16个字节,保存数据
- cs:10~cs:2f 存储16个字,32个字节,作为栈来用
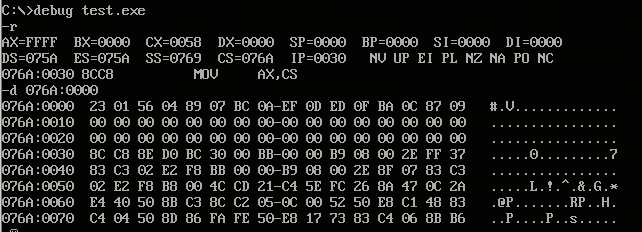
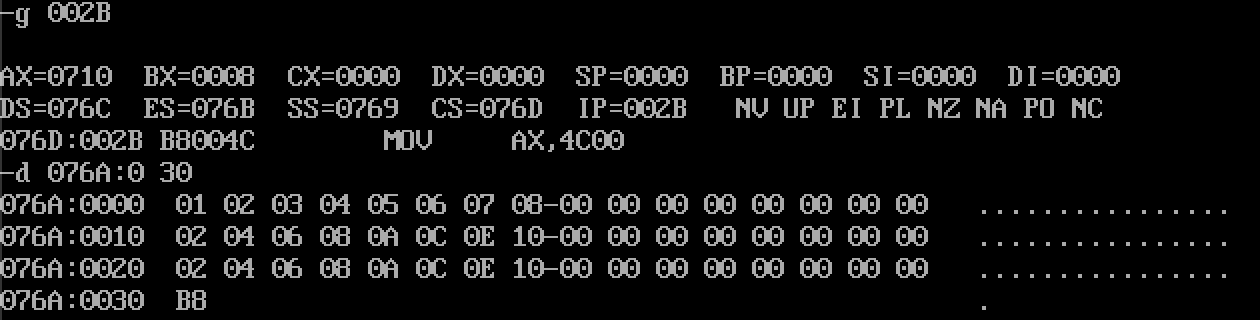
- 程序从CS:IP=076A:0030

- 执行

- 将数据push入栈(这里有个疑问:076A:0010 这行最后的数据为什么变了)
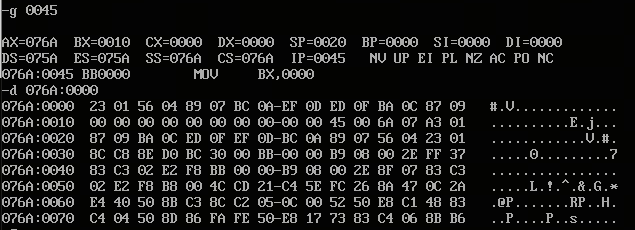
- 出栈刚好实现逆序存放(这里有个疑问:076A:0020这行出栈后数据也发生了改变,076A:0010这行也发生了改变)


例子1
- 下面的代码实现把内存0:0~0:F单元中的内容改写程序中的数据(也就是改写CS:0中的程序)
assume cs:codesgcodesg segmentdw 0123h,0456h,0789h,0abch,0defh,0fedh,0cbah,0987hstart: mov ax,0mov ds,axmov bx,0mov cx,8s: mov ax,[bx]mov cs:[bx],axadd bx,2loop smov ax,4c00hint 21hcodesg endsend start
- 运行结果
- DS=075A:0000 倒076A:0000 存储的事PSP区域
- 076A:0 000F存储的是dw的8个字 16个字节长度
- 076A:0010 开始存储程序 mov ax,0


例子2
- 下面的代码实现把内存0:0~0:F单元中的内容改写程序中的数据(也就是改写CS:0中的程序),用栈来实现
assume cs:codesgcodesg segmentdw 0123h,0456h,0789h,0abch,0defh,0fedh,0cbah,0987hdw 0,0,0,0,0,0,0,0,0,0start: mov ax,csmov ss,axmov sp,24hmov ax,0mov ds,axmov bx,0mov cx,8s: push [bx]pop cs:[bx]add bx,2loop smov ax,4c00hint 21h
codesg endsend start
- 初始状态

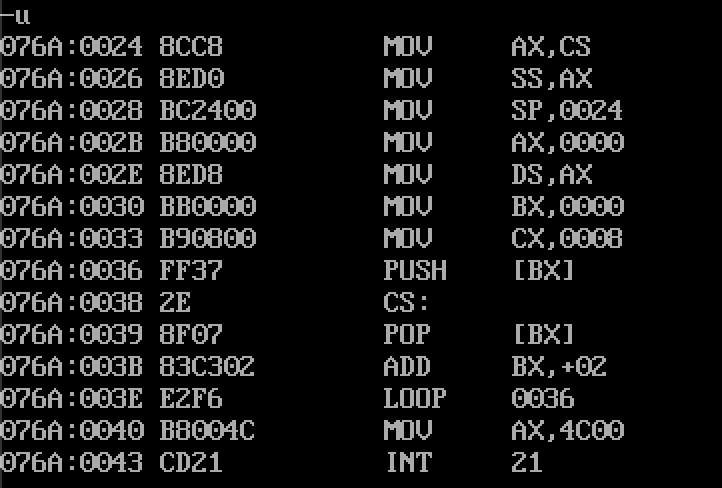
- 运行结果

4、数据、代码、栈放入不同的段
- 前面的例子中,我们将数据、栈和代码都放到一个段里面,编程的时候我们要注意何处是数据,何处是栈,何处是代码,这样有两个问题
- 1 全部防在一个段中程序显得混乱
- 2 如果数据、栈、代码需要的空间超过64KB,就不能防在一个段中
例子1:end start指定程序入口
- 接下来我们用一个例子,将数据、栈、代码放在不同的段中。下例实现将8个字数据倒叙排列
- ds:data:将段data的地址赋值给ds寄存器
- ss:stack:将段stack的地址赋值给ss寄存器
- cs:code:将段code的地址赋值给cs寄存器
assume cs:code,ds:data,ss:stackdata segmentdw 0123h,0456h,0789h,0abch,0defh,0fedh,0cbah,0987h
data endsstack segmentdw 0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0
stack endscode segmentstart: mov ax,stackmov ss,axmov sp,20hmov ax,datamov ds,axmov bx,0mov cx,8s: push [bx]add bx,2loop smov bx,0mov cx,8s0: pop [bx]add bx,2loop s0mov ax,4c00hint 21hcode endsend start- debug加载程序后,初始状态如下

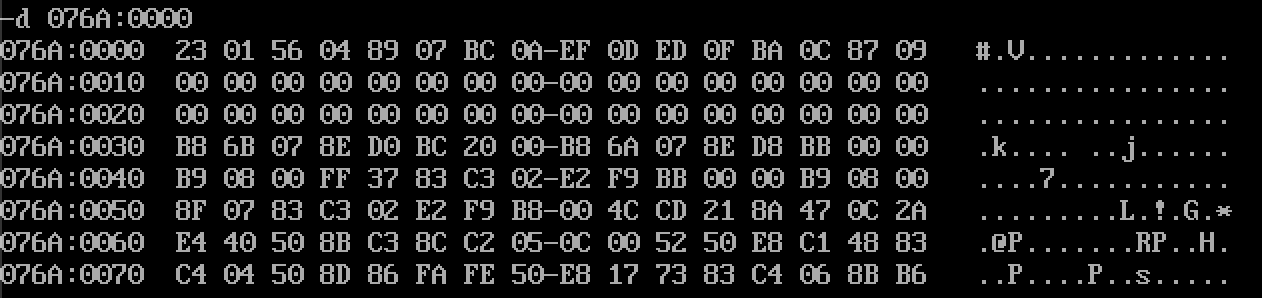
- 程序是从DS=075A开始,默认有256个字节的PSP区域,也就是从075A:0000开始的256字节是不可用的,程序和数据真真是从076A:0000开始
- 076A:0000 ~ 076A:000F 存储的是要逆序的8个字(16个字节)
- 076A:0010 ~ 076A:002F 存储的是定义的栈内存,占据16个字(32个字节)
- 程序是从076A:0030开始的,也就是CS:IP中保存076D:0000
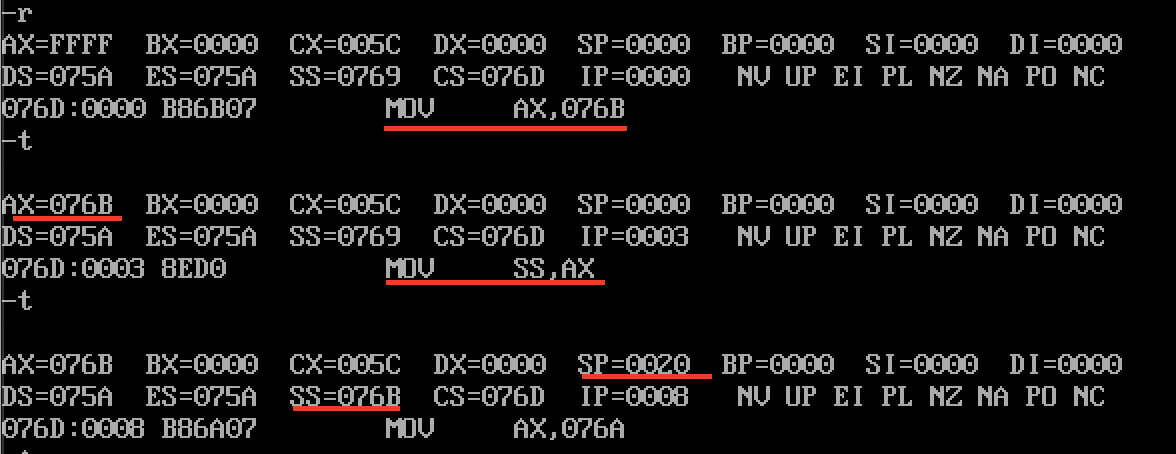
第一步:设置栈顶
- 代码如下,其中的stack是段名,编译期会将他转换成段地址。也就是前面定义的16个字(32个字节)的栈内存,并且让栈顶指向
start: mov ax,stackmov ss,axmov sp,20h
- 此时栈顶SS:SP=076B:0020,此时栈空,栈顶刚好在076D:0000
- 运行结果如下
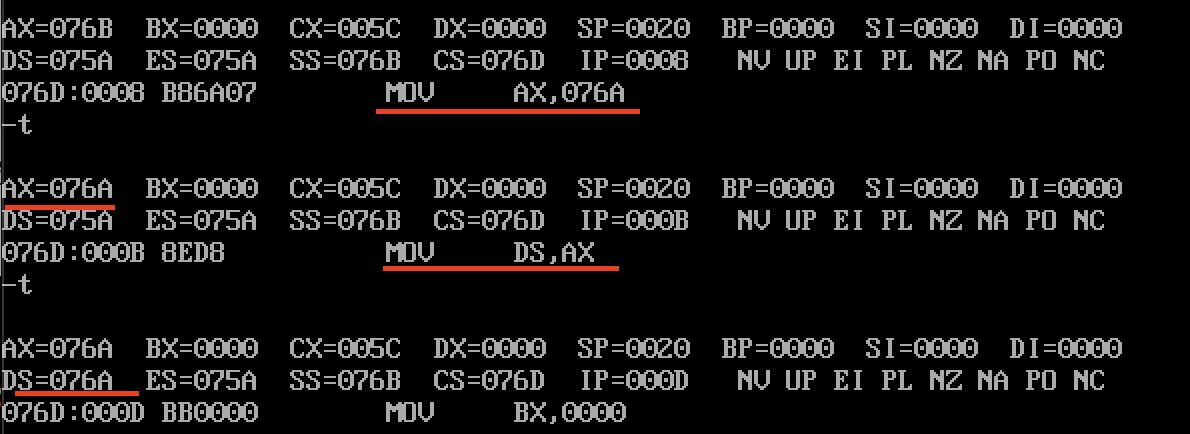
第二步:设置DS
- data段之前定义了8个字,mov ax,data中data会被转换成段地址,就是这8个字保存的段地址,偏移地址就是0000~0007
mov ax,datamov ds,ax
- debug运行,最终DS=076A
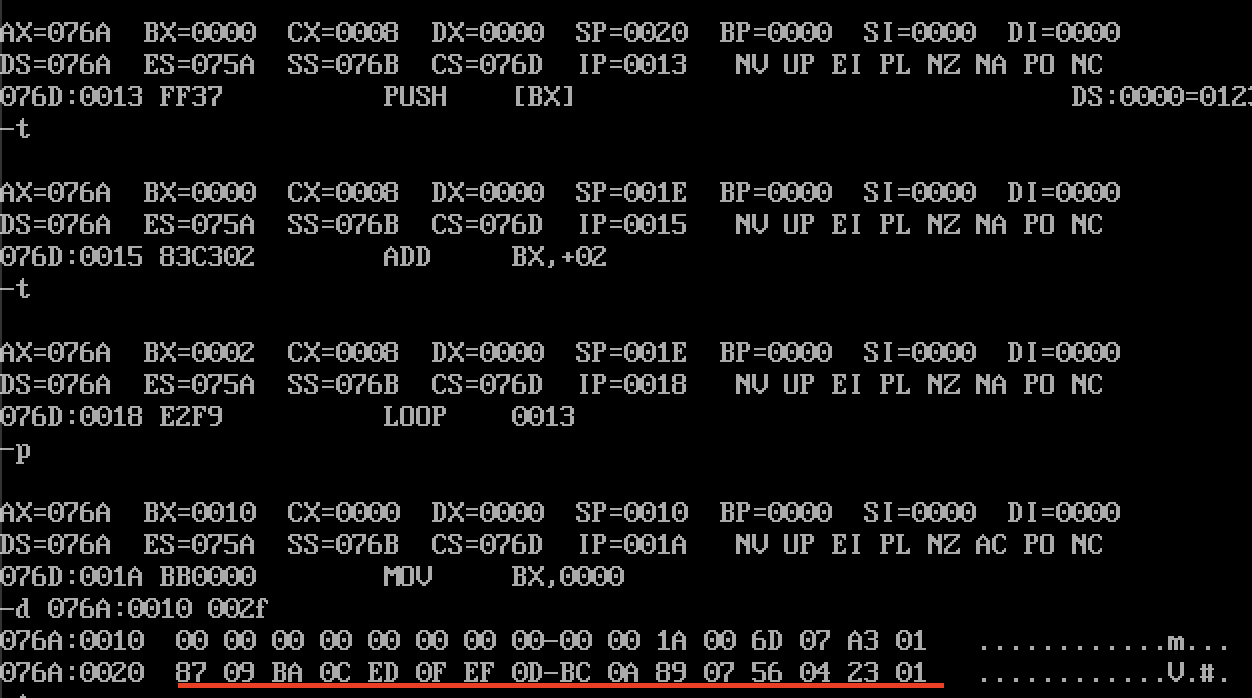
第三步:push入栈
mov bx,0mov cx,8s: push [bx]add bx,2loop s
- 实现了将076A:0000 ~ 076A:000F的8个字逆序存储倒076A:0020 ~ 076A:002F中
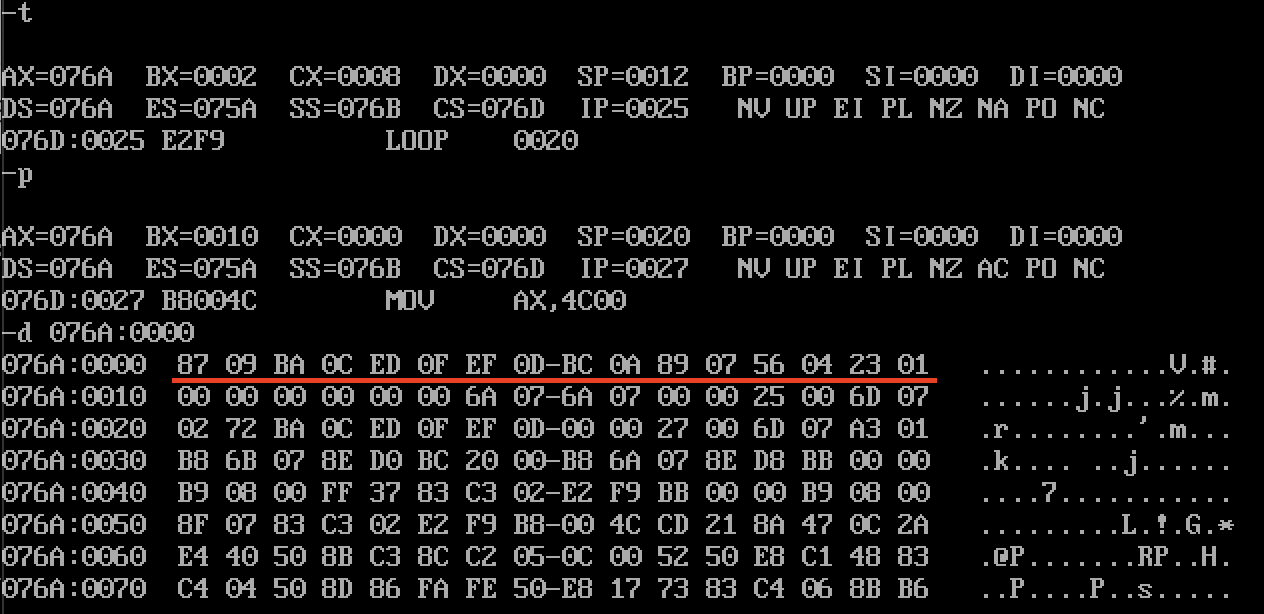
第四步:pop出站
mov bx,0mov cx,8s0: pop [bx]add bx,2loop s0
- 最终实现了076A:0000 ~ 076A:000F的8个字的逆序存储
第五步:程序退出

误解
- 并不是程序中写assume cs:code,ds:data,ss:stack,程序就会自动将cs指向code,ds指向data,ss指向stack,这个完全靠程序中后续具体指令来决定的
- 段的标号也可以随便定义
assume cs:b,ds:a,ss:ca segmentdw 0123h,0456h,0789h,0abch,0defh,0fedh,0cbah,0987h
a endsc segmentdw 0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0
c endsb segmentd: mov ax,stackmov ss,axmov sp,20hmov ax,datamov ds,axmov bx,0mov cx,8s: push [bx]add bx,2loop smov bx,0mov cx,8
s0: pop [bx]add bx,2loop s0mov ax,4c00hint 21hb endsend d例子2:段占据空间是16的倍数
- 代码
assume cs:code,ds:data,ss:stackdata segmentdw 0123h,0456h
data endsstack segmentdw 1h,2h
stack endscode segmentstart: mov ax,stackmov ss,axmov sp,10hmov ax,datamov ds,axpush ds:[0]push ds:[2]pop ds:[2]pop ds:[0]mov ax,4c00hint 21h
code endsend start- 结论:数据段和栈段在程序加载后实际占据的空间以16个字节为单位,其余补零

例子3:db的使用
- 将a段和b端中的数据依次相加,结果存储倒c中去
assume cs:codea segmentdb 1, 2, 3, 4, 5, 6, 7, 8
a endsb segmentdb 1, 2, 3, 4, 5, 6, 7, 8
b endsc segmentdb 0, 0, 0, 0, 0, 0, 0, 0
c endscode segmentstart:mov ax, amov ds, axmov ax, bmov es, axmov bx, 0mov cx, 8s:mov al, ds:[bx]add es:[bx], alinc bxloop smov ax, cmov ds, axmov bx, 0mov cx, 8s0:mov al, es:[bx]add ds:[bx], alinc bxloop s0mov ax,4c00hint 21hcode endsend start
- 初始化状态
- 076A:0 f 存储a段的数据
- 076A:10 1F 存储b段数据
- 076A:20 2F 存储c段数据
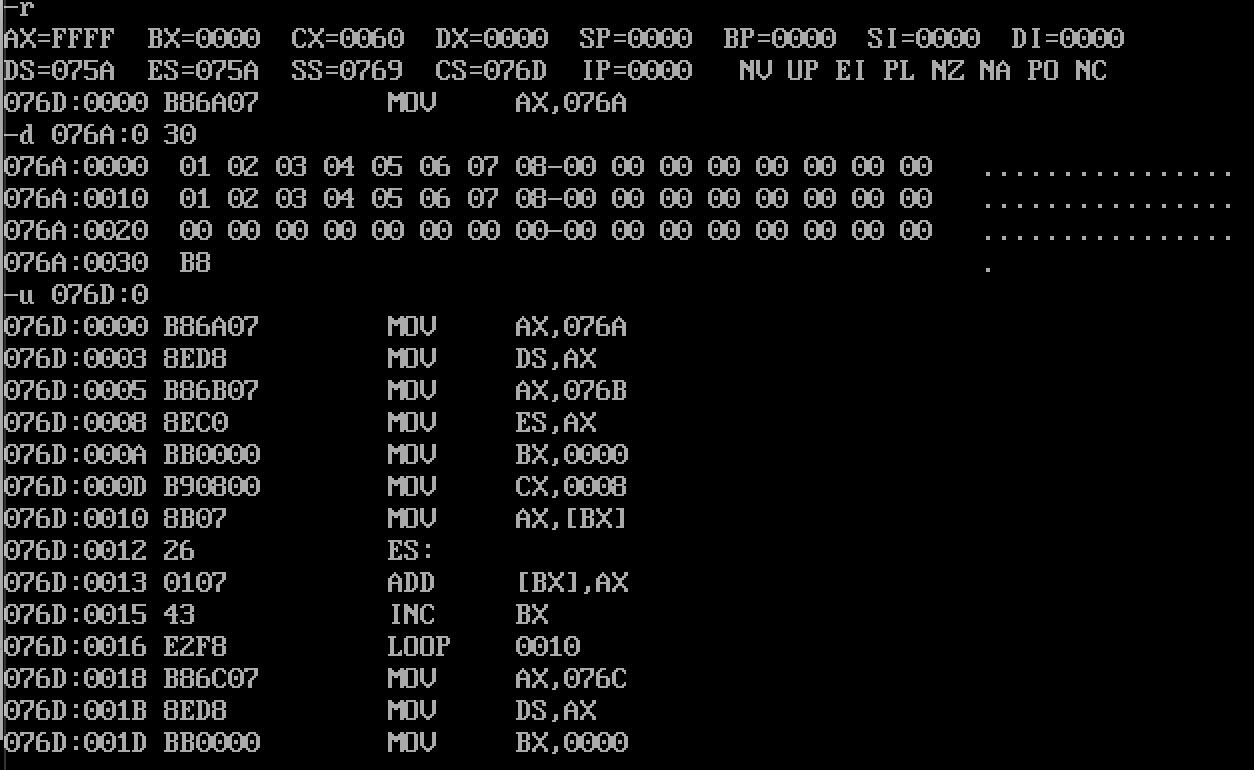
- 运行结果