在现代的Java应用中,使用一个高效可靠的数据源是至关重要的。Druid连接池作为一款强大的数据库连接池,提供了丰富的监控和管理功能,成为很多Java项目的首选。本文将详细介绍如何在Spring Boot 3项目中配置数据源,集成Druid连接池,以实现更高效的数据库连接管理。

Spring Boot 3 配置数据源
Spring Boot 提供了自动配置(auto-configuration)功能,其中包括了对数据源的自动配置,我们只需要在项目中导入spring-boot-starter-jdbc依赖及对应数据源的驱动依赖即可,我们使用的mysql数据库,pom依赖如下:
<!-- SPRINGBOOT JDBC -->
<dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-jdbc</artifactId>
</dependency>
<!-- Mysql驱动包 -->
<dependency><groupId>mysql</groupId><artifactId>mysql-connector-java</artifactId><version>8.0.33</version>
</dependency>
配置文件如下:
spring:datasource:driver-class-name: com.mysql.cj.jdbc.Driverurl: jdbc:mysql://192.168.10.106:3306/xj_doc?characterEncoding=utf8&serverTimezone=Asia/Shanghaiusername: rootpassword: 123456
Spring Boot默认使用 HikariCP 作为连接池,这是因为 HikariCP 提供了卓越的性能、低延迟和高效的资源利用。Spring Boot默认情况下会自动检测 classpath 下是否存在 HikariCP。如果存在,Spring Boot 会将 HikariCP 作为默认的数据库连接池。如果 classpath 下没有 HikariCP,Spring Boot 会尝试检测其他连接池的存在,选择顺序如下:

如果不想通过自动检测的方式,我们可以在配置文件application.yml 中设置 spring.datasource.type 属性,指定要使用的连接池类型的完整类名,示例如下:
spring:datasource:type: com.alibaba.druid.pool.DruidDataSource
Spring Boot 3 集成 Druid
Druid网址
Druid是Java语言中最好的数据库连接池。Druid能够提供强大的监控和扩展功能。在国内是是数据库连接池的首选。
Druid的github网址:https://github.com/alibaba/druid
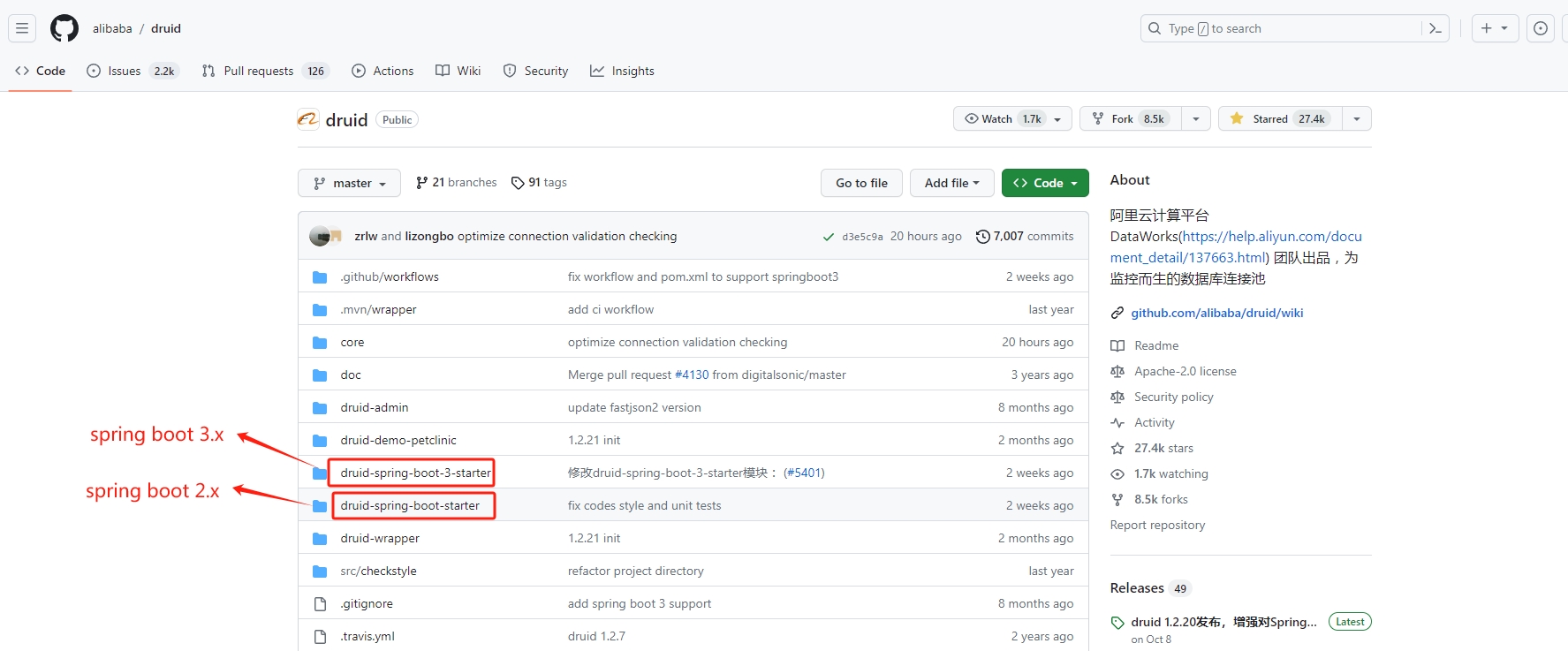
引入依赖
在Spring Boot 3.x版本中引入依赖如下:
<dependency><groupId>com.alibaba</groupId><artifactId>druid-spring-boot-3-starter</artifactId><version>1.2.20</version>
</dependency>
添加配置### 添加配置
配置文件如下:
spring:datasource:type: com.alibaba.druid.pool.DruidDataSourcedriver-class-name: com.mysql.cj.jdbc.Driverurl: jdbc:mysql://192.168.10.106:3306/xj_doc?characterEncoding=utf8&serverTimezone=Asia/Shanghaiusername: rootpassword: 123456# druid 连接池管理druid:# 初始化时建立物理连接的个数initial-size: 5# 连接池的最小空闲数量min-idle: 5# 连接池最大连接数量max-active: 20# 获取连接时最大等待时间,单位毫秒max-wait: 60000# 申请连接的时候检测,如果空闲时间大于timeBetweenEvictionRunsMillis,执行validationQuery检测连接是否有效。test-while-idle: true# 既作为检测的间隔时间又作为testWhileIdel执行的依据time-between-eviction-runs-millis: 60000# 销毁线程时检测当前连接的最后活动时间和当前时间差大于该值时,关闭当前连接(配置连接在池中的最小生存时间)min-evictable-idle-time-millis: 30000# 用来检测数据库连接是否有效的sql 必须是一个查询语句(oracle中为 select 1 from dual)validation-query: select 'x'# 申请连接时会执行validationQuery检测连接是否有效,开启会降低性能,默认为truetest-on-borrow: false# 归还连接时会执行validationQuery检测连接是否有效,开启会降低性能,默认为truetest-on-return: false# 是否缓存preparedStatement, 也就是PSCache,PSCache对支持游标的数据库性能提升巨大,比如说oracle,在mysql下建议关闭。pool-prepared-statements: false# 置监控统计拦截的filters,去掉后监控界面sql无法统计,stat: 监控统计、Slf4j:日志记录、waLL: 防御sqL注入filters: stat,wall,slf4j# 要启用PSCache,必须配置大于0,当大于0时,poolPreparedStatements自动触发修改为true。在Druid中,不会存在Oracle下PSCache占用内存过多的问题,可以把这个数值配置大一些,比如说100max-pool-prepared-statement-per-connection-size: -1# 合并多个DruidDataSource的监控数据use-global-data-source-stat: true# 通过connectProperties属性来打开mergeSql功能;慢SQL记录connect-properties: druid.stat.mergeSql=true;druid.stat.slowSqlMillis=5000web-stat-filter:# 是否启用StatFilter默认值trueenabled: true# 添加过滤规则url-pattern: /*# 忽略过滤的格式exclusions: /druid/*,*.js,*.gif,*.jpg,*.png,*.css,*.icostat-view-servlet:# 是否启用StatViewServlet默认值trueenabled: true# 访问路径为/druid时,跳转到StatViewServleturl-pattern: /druid/*# 是否能够重置数据reset-enable: false# 需要账号密码才能访问控制台,默认为rootlogin-username: druidlogin-password: druid# IP白名单allow: 127.0.0.1# IP黑名单(共同存在时,deny优先于allow)deny:启动项目
启动项目,出现如下日志,则标识数据库连接池已经使用了Druid。
2023-12-09T21:20:31.561+08:00 INFO 26176 --- [ main] c.a.d.s.b.a.DruidDataSourceAutoConfigure : Init DruidDataSource
2023-12-09T21:20:32.328+08:00 INFO 26176 --- [ main] com.alibaba.druid.pool.DruidDataSource : {dataSource-1} inited
访问页面
项目启动后,我们可以通过访问 Druid 控制台来监控和管理数据库连接池的状态。控制台的访问地址通常是:http://localhost:8080/druid/login.html。
在访问控制台时,系统将要求输入用户名和密码进行身份验证。这些用户名和密码是在项目的配置文件中进行了配置的,
# 需要账号密码才能访问控制台,默认为root
login-username: druid
login-password: druid
至此,你已成功配置了数据源并集成了 Druid 连接池。通过合理配置 Druid 连接池的参数,你可以优化数据库连接的性能和资源利用。同时,通过监控功能,你可以实时了解连接池的使用情况,及时发现潜在的问题。
总结
通过本文的介绍,你学会了如何在Spring Boot 3项目中配置数据源,集成Druid连接池,从而提高数据库连接管理的效率。Druid连接池的监控和管理功能可以为你的应用提供更好的性能和可维护性。
![【UnityUI程序框架】The PureMVC Framework[一]](https://img-blog.csdnimg.cn/430fd5b6362d48c281827ddc6a56789d.gif)