目录
- nginx
- 介绍
- 代理
- 集群
- 安装
- 配置文件
- http
- 使用
- master和worker
- 升级问题
- 基于域名的虚拟主机
- 隐藏nginx的版本信息
- 供别人下载的网站
- 统计的信息的页面
- pv介绍
- ngixn续
- nginx认证
- nginx的allow和deny
- nginx限制并发数
- nginx限速
- 限速的算法
- nginx 限制请求数
- nginx 的 location
- nginx 的 location
- nginx压力测试
- 健康检测
- 参数
- HTTP
- 是什么
- 报文结构
- 请求头部
- 响应头部
- 工作原理
- 用户点击一个URL链接后,浏览器和web服务器会执行什么
- http的版本
- 持久连接和非持久连接
- 无状态与有状态
- Cookie和Session
- http方法:
- get和post的区别
- 状态码
- HTTPS
- 是什么
- ssl
- 如何搞到证书
- nginx中的部署
- 加密
- CA
- 数字证书
- hash算法
- 对称加密
- 非对称加密
- 数字签名
- webhook
- IO多路复用
- 基础
- 文件句柄
- /proc文件:
- 内核
- uri和url
- url
- 介绍
- 方法
- select
- poll
- epoll
- 总结
- DNS
- 是什么以及作用
- 下载DNS服务
- named.conf
- DNS查询
- DNS缓存机制
- 解析过程
- 递归查询和迭代查询
- DNS服务器的类型
- DNS域名
- DNS服务器的类型
- 搭建dns服务器
- 缓存域名服务器
- 主域名服务器
- 从域名服务器
- 排错
- 反向解析
- CDN
- 介绍
- DNS转发
- 介绍
- 配置
- DNS劫持
- nginx 负载均衡
- 负载均衡策略(方法、算法)
- nginx配置
- round-robin
- 加权轮询
- least-connected
- ip-hasp
- 使用Https
- realip
- 后端real server不使用realip模块
- 后端
- real server使用realip模块
- ab压力测试
- 不同负载
- 四层负载
- 7层负载
- 4层和7层
- nfs
- 安装、使用
- nfs机器上的操作
- server机器
- 权限问题
- 开机自动挂载
- 相关的命令和文件
- rpc
- rpc和nfs
- san
- nfs和san区别
- 高可用
- 介绍
- keepalived
- 安装、使用
- vip漂移
- 抓包
- 脑裂
- 脑裂有没有危害?如果有危害对业务有什么影响?
- keepalived架构
- 双vip架构
- Healthcheck
- 实现
- notify
- VRRP
- 选举
- 格式
- 系统性能监控
- 相关命令
- lscpu
- top
- free
- htop
- dstat
- glances
- iftop
- iptraf
- nethogs
- 监控软件
- Prometheus
- 安装、使用
- 将promethues做成服务
- 监控其他机器
- exporter
- grafana
- 配置、使用
- 密码忘记重置
nginx

介绍
nginx是一个http和高性能的开源Web服务器和反向代理服务器、邮件服务器软件、
方向代理服务器:作用就是负载均衡
协议 protocol:理解为一种语言,不同的程序之间沟通交流使用的,规定了数据在传输的过程中应该是什么样子的,由哪些组成,里面包含哪些内容等等。
协议在本质就是一个程序,用来封装我们的数据,把它想象成python里的字典等。(很多协议都是使用c语言编写)
超文本传输协议(Hypertext Transfer Protocol,简称HTTP):是一种用于在网络中传输超文本和其他资源的应用层协议。HTTP是Web应用程序的基础,用于客户端(如Web浏览器)与服务器之间的通信。
超文本(Hypertext)是一种文本的形式,可以包含引用其他文本的链接,使用户能够非线性地浏览和导航信息。与传统线性文本不同,超文本通过嵌入链接(超链接)将文本与其他相关内容或资源连接起来,使用户可以通过点击链接跳转到相关的文本、图像、音频、视频或其他多媒体元素。
超文本:html、css、js等语言编写的内容。
http协议使用场景:Web浏览器、Web应用程序开发、API交互、文件传输、数据推送、资源获取和缓存等
代理
正向代理(Forward Proxy)和反向代理(Reverse Proxy)是代理服务器的两种常见配置方式,它们在网络通信中扮演不同的角色和提供不同的功能。
-
正向代理(Forward Proxy):
正向代理是位于客户端和目标服务器之间的代理服务器。当客户端需要访问互联网上的资源时,它首先向正向代理发送请求,然后代理服务器将请求转发给目标服务器,并将目标服务器的响应返回给客户端。客户端对目标服务器的存在和身份信息一般是不可见的。使用场景:
- 突破网络限制:正向代理可以用于绕过网络限制,访问被屏蔽的网站或服务。
- 隐藏客户端身份:正向代理可以隐藏客户端的真实IP地址和身份,提高用户的隐私和安全性。
- 缓存和加速:正向代理可以缓存常用的响应结果,减少对目标服务器的请求,提高访问速度。
-
反向代理(Reverse Proxy):
反向代理是位于目标服务器和客户端之间的代理服务器。当客户端发送请求时,它并不直接与目标服务器通信,而是向反向代理发送请求。反向代理根据配置和负载均衡算法,将请求转发给一个或多个目标服务器,并将目标服务器的响应返回给客户端。客户端对目标服务器的存在和身份信息一般是不可见的。使用场景:
- 负载均衡:反向代理可以将客户端的请求分发给多个目标服务器,平衡服务器的负载,提高系统的性能和可扩展性。
- 安全性和保护:反向代理可以作为一个安全屏障,隐藏和保护后端目标服务器的真实IP地址和身份,提供额外的安全层。
- 缓存和加速:反向代理可以缓存目标服务器的响应结果,减少对目标服务器的请求,提高访问速度。
总结:
正向代理和反向代理是两种常见的代理服务器配置方式。正向代理位于客户端和目标服务器之间,隐藏客户端的身份和提供缓存等功能。反向代理位于目标服务器和客户端之间,平衡负载、提供安全性和缓存等功能。它们在网络通信中扮演不同的角色,并在突破网络限制、提高性能和保护后端服务器等方面发挥重要作用。
集群
集群(Cluster)是指将多个计算机或服务器组合在一起,作为一个整体来共同完成特定任务或提供某种服务的系统。集群的目的是通过将计算和资源分布在多台机器上,提高系统的性能、可扩展性、可靠性和容错性。
-
架构和工作原理:
- 水平扩展:集群使用水平扩展的方式增加系统的处理能力。通过在集群中添加更多的计算机或服务器,可以平均分担负载,提高系统的处理能力。
- 负载均衡:集群中的负载均衡器将客户端请求分发给集群中的各个节点,以均衡负载和提高系统性能。负载均衡器可以根据不同的算法将请求分发给最空闲或最适合的节点。
- 高可用性:集群中的节点可以相互冗余和备份,当某个节点发生故障或不可用时,其他节点可以接管服务,保证系统的高可用性。
- 数据同步和共享:集群中的节点之间需要进行数据同步和共享,以保证数据的一致性和可靠性。
-
使用场景:
- Web应用负载均衡:通过集群,可以将客户端的请求分发到多个服务器上,实现Web应用的负载均衡,提高网站的访问性能和响应速度。
- 大规模数据处理:集群可以用于大规模数据处理和分布式计算。通过将数据分片和并行处理,可以提高数据处理的速度和效率。
- 分布式存储系统:集群可以用于构建分布式存储系统,将数据分散存储在多个节点上,提高存储容量和可靠性。
- 高可用性和容错性:通过将多个节点组成集群,可以提供高可用性和容错性。当某个节点发生故障时,其他节点可以接管服务,保证系统的连续性和可靠性。
-
技术和工具:
- 负载均衡器:常见的负载均衡器包括Nginx、HAProxy、F5等,用于将请求分发到集群中的节点。
- 分布式文件系统:如Hadoop的HDFS、GlusterFS、Ceph等,用于在集群中分布存储和管理大规模数据。
- 分布式计算框架:如Apache Hadoop、Apache Spark等,用于在集群中进行大规模数据处理和分布式计算。
安装
安装脚本。
[root@localhost nginx]# cat onekey_install_mjh_nginx.sh
#!/bin/bash#新建一个文件夹用来存放下载的nginx源码包mkdir -p /opt/nginx
cd nginx#新建用户
useradd -s /sbin/nologin yandonghao#下载 nginx
curl -O http://nginx.org/download/nginx-1.25.0.tar.gz#解压nginx 源码包tar xf nginx-1.25.0.tar.gz#解决依赖关系
yum install gcc openssl openssl-devel pcre pcre-devel automake make -y#编译前的配置,创建Makefile文件。
./configure --prefix=/usr/local/ydhnginx --user=yandonghao --with-http_ssl_module --with-http_v2_module --with-threads --with-http_stub_status_module --with-stream#编译,开启2个进程同时编译,make其实就是安装Makefile的配置去编译程序成二进制文件,二进制文件就是执行可以运行的程序。
make -j 2#安装: 将编译好的二进制代码文件复制到指定的安装路径目录下
make install# 启动nginx
/usr/local/ydhnginx/sbin/nginx#修改PATH变量
#临时修改
PATH=$PAth:/usr/local/ydhnginx/sbin
#永久修改
echo "PATH=$PATH:/usr/local/ydhnginx/sbin" >>/root/.bashrc#设置nginx的开机启动
echo "/usr/local/ydhnginx/sbin" >>/etc/rc.local
chomd +x /etc/rc.d/rc.local#selinux和firewalld防火墙都关闭
service firewalld stop
systemctl disable firewalld#临时关闭selinux
setenforec 0
#永久关闭selinux
sed -i '/^SELINUX=/ s/enforcing/disabled' /etc/selinux/confug编译安装的参数:
-
–with-http_ssl_module :用于启用 HTTP SSL 模块
-
–with-http_v2_module :用于启用 HTTP/2 协议支持的模块
-
–with-threads :用于启用 Nginx 的线程支持
-
–with-http_stub_status_module :状态统计功能
-
–with-stream:4层负载均衡功能
配置文件
并发(Concurrency):
- 并发指的是多个任务在同一时间段内执行,通过任务之间的切换来实现同时进行的假象。
- 在并发模型中,任务可能以交替的方式执行,每个任务分配到的时间片很小,通过任务切换的方式来实现任务之间的共享处理器资源。
- 并发适用于处理任务的交替执行,重点在于任务的调度和管理,而不是真正的同时执行。
并行(Parallelism):
- 并行指的是多个任务同时进行,实际上是多个任务同时在不同的处理器上执行。
- 在并行模型中,每个任务都有自己的处理器资源,它们可以独立地执行而不需要等待其他任务。
- 并行适用于真正同时执行的任务,重点在于任务的分解和并发执行,可以通过多处理器、多核心或分布式系统来实现。
#user nobody; #指定使用nobody用户去启动nginx worker进程,也可以改成 user xiaoli,需要用户存在才可以。worker_processes 1; #启动一个worker进制,也可以改成其他数字。启动4个worker进程,看cpu核心的数量,一般是cpu核心数量一致 ,16核心启动16个进程。user xiaoli
worker_processer 2;
#error_log logs/error.log; #指定错误日志存放的路径
#error_log logs/error.log notice; #日志的等级
#error_log logs/error.log info;#pid logs/nginx.pid; #记录master进程的进程号
日志的等级
在Linux系统中,通常使用以下几个常见的日志级别(从高到低):
Emergency(紧急):表示系统无法使用,需要立即采取行动修复。例如,系统崩溃、关键服务不可用等。
Alert(警报):表示必须立即采取行动,但系统仍然可以使用。这个级别通常用于通知关键事件的发生,需要管理员的干预。
Critical(严重):表示关键错误或故障发生,但系统仍可以继续运行。需要注意并立即处理。
Error(错误):表示非常重要的错误事件,但系统仍然可以正常运行。需要检查和修复。
Warning(警告):表示可能会引起问题的情况。需要关注和调查,但不会影响系统的正常运行。
Notice(注意):表示正常但重要的事件,通常用于记录系统运行状态的变化或其他需要注意的情况。
Info(信息):表示一般信息,用于记录系统的一般操作和状态。
Debug(调试):用于调试目的的详细信息,通常只在调试过程中启用。
None:
不同的日志工具和应用程序可能会有不同的命名和细分级别,但上述日志级别是常见的标准级别,可供参考。根据实际需求,可以根据这些级别进行适当的配置和过滤。
events {worker_connections 1024;
}
#表示每个工作进程可以支持最多 1024 个并发连接。
在 Nginx 的配置文件(通常是 nginx.conf)中,events 部分用于配置与服务器事件处理相关的参数。其中,worker_connections 是一个重要的指令,用于设置每个工作进程(Worker Process)所能够支持的最大并发连接数。
以下是对 events 部分和 worker_connections 指令的详细解释:
events部分:events部分用于配置与服务器事件处理相关的参数,例如并发连接数、文件描述符限制等。- 该部分通常位于 Nginx 配置文件的顶层,与其他部分(如
http、server)并列。 - 在
events部分中,可以设置多个与事件处理相关的指令。
worker_connections指令:worker_connections指令用于设置每个工作进程(Worker Process)所能够支持的最大并发连接数。- 每个客户端连接到 Nginx 服务器都会占用一个连接数,因此该指令的值决定了服务器能够同时处理的最大连接数。
- 默认情况下,Nginx 设置的最大连接数是 512。
- 通常,您可以根据服务器的硬件资源和预期的并发负载来调整此值。较高的值可以支持更多的并发连接,但可能需要更多的系统资源。
请注意,worker_connections 的值应该根据服务器的实际情况进行调整。过小的值可能导致并发连接过载,从而影响服务器的性能和可靠性。过大的值可能会占用过多的系统资源,导致服务器负载过高。
用进程和线程解释
1个进程里可以包含很多线程,一个连接:1个线程
进程process:pcb(进程控制块process contorl block 、程序代码、程序产生的数据
其中pcb(进程控制块)理解为进程的身份证,包含pid,用于启动,内存里的地址,进程的状态等信息
线程thread:tcb(线程控制块)、程序代码块、程序产生的数据
线程比进程更加节约内存资源,因为所有的线程都共享同一份程序代码。
http
http {include mime.types;default_type application/octet-stream;#log_format main '$remote_addr - $remote_user [$time_local] "$request" '# '$status $body_bytes_sent "$http_referer" '# '"$http_user_agent" "$http_x_forwarded_for"';#access_log logs/access.log main;sendfile on;#tcp_nopush on;#keepalive_timeout 0;keepalive_timeout 65;#gzip on;server {listen 8088;server_name localhost;#charset koi8-r;#access_log logs/host.access.log main;location / {root html;index index.html index.htm;}#error_page 404 /404.html;# redirect server error pages to the static page /50x.html#error_page 500 502 503 504 /50x.html;location = /50x.html {root html;}# proxy the PHP scripts to Apache listening on 127.0.0.1:80##location ~ \.php$ {# proxy_pass http://127.0.0.1;#}# pass the PHP scripts to FastCGI server listening on 127.0.0.1:9000##location ~ \.php$ {# root html;# fastcgi_pass 127.0.0.1:9000;# fastcgi_index index.php;# fastcgi_param SCRIPT_FILENAME /scripts$fastcgi_script_name;# include fastcgi_params;#}# deny access to .htaccess files, if Apache's document root# concurs with nginx's one##location ~ /\.ht {# deny all;#}}# another virtual host using mix of IP-, name-, and port-based configuration##server {# listen 8000;# listen somename:8080;# server_name somename alias another.alias;# location / {# root html;# index index.html index.htm;# }#}# HTTPS server##server {# listen 443 ssl;# server_name localhost;# ssl_certificate cert.pem;# ssl_certificate_key cert.key;# ssl_session_cache shared:SSL:1m;# ssl_session_timeout 5m;# ssl_ciphers HIGH:!aNULL:!MD5;# ssl_prefer_server_ciphers on;# location / {# root html;# index index.html index.htm;# }#}}在 Nginx 的配置文件 nginx.conf 中,您看到的是关于日志格式的配置部分。具体来说,log_format 指令用于定义日志的格式,而 main 是该日志格式的名称。下面是对该配置段的详细解释:
log_format main '$remote_addr - $remote_user [$time_local] "$request" ''$status $body_bytes_sent "$http_referer" ''"$http_user_agent" "$http_x_forwarded_for"';
log_format:这是 Nginx 的指令,用于定义日志的格式。main:这是日志格式的名称,您可以根据需要自定义一个名称,这里使用了main。'...':这是定义日志格式的字符串,使用单引号包围。在字符串中,您可以使用变量和文本来构建日志的输出格式。
解析字符串中的变量和文本:
$remote_addr:客户端的 IP 地址。$remote_user:通过基本身份验证(Basic Authentication)认证的远程用户。[$time_local]:请求发生的本地时间。"$request":请求的内容,包括请求方法、URI和协议。$status:响应的状态码。$body_bytes_sent:发送给客户端的响应内容的大小(以字节为单位)。"$http_referer":引用页面的 URL,从那个网址引流过来的,从那个网址跳转过来的。"$http_user_agent":客户端使用的用户代理(浏览器、爬虫等)。"$http_x_forwarded_for":通过代理服务器传递的客户端真实 IP 地址。
通过定义日志格式,您可以在 Nginx 的访问日志中记录这些变量的值,以及其他自定义的文本,以满足您对日志的需求和分析要求。
#keepalive_timeout 0;keepalive_timeout 65;在 Nginx 的配置文件中,keepalive_timeout 指令用于设置与客户端的 keep-alive 连接的超时时间。在配置文件中,可能会有两个相关的 keepalive_timeout 指令的设置。
-
keepalive_timeout 0;:keepalive_timeout 0;的设置意味着关闭 keep-alive 连接,即客户端和服务器之间的连接每次请求结束后都会立即关闭。- 这通常用于在高负载环境中,为了释放服务器上的连接资源,或者由于某些特殊要求需要禁用 keep-alive 连接。
-
keepalive_timeout 65;:- 这是一个实际启用的
keepalive_timeout设置,超时时间为 65 秒。 keepalive_timeout设置的默认单位是秒(s),即客户端和服务器之间的 keep-alive 连接在经过指定的时间后如果没有新的请求,则会自动关闭。- 在设置较短的超时时间可以减少服务器上的连接数,但可能会增加客户端与服务器之间建立和断开连接的频率。
- 这是一个实际启用的
server {listen 8088;server_name localhost;#charset koi8-r;#access_log logs/host.access.log main;location / {root html;index index.html index.htm;}上述是一个简单的 Nginx 配置文件中的 server 块的示例。下面是对其中各项配置的详细解释:
-
listen 8088;:指定该服务器块监听的端口号为 8088。这意味着 Nginx 将监听来自该端口的请求。 -
server_name localhost;:设置该服务器块的域名或主机名为 “localhost”。这意味着只有使用 “localhost” 访问该 Nginx 服务器时,该服务器块中的配置将生效。 -
location / { ... }:定义了一个请求位置(location)“/”。这表示所有匹配到根路径"/"的请求将由此位置块处理。 -
root html;:指定了网站根目录为 “html”。这意味着服务器将在配置文件所在的目录下的 “html” 目录中查找文件来响应请求。 -
index index.html index.htm;:定义了索引文件的顺序。在该示例中,当访问一个目录时,服务器将依次查找 “index.html” 和 “index.htm” 文件,最左边的优先级最高,以作为默认的索引文件返回给客户端。 -
#charset koi8-r;:- 这个指令用于设置字符集编码,具体是
koi8-r字符集。该字符集通常用于俄罗斯和其他一些东欧语言。 - 注释掉该指令意味着使用默认的字符集编码。
- 这个指令用于设置字符集编码,具体是
-
#access_log logs/host.access.log main;:- 这个指令用于定义访问日志的配置。
access_log指令用于启用或禁用访问日志,并指定日志文件的路径和格式。 - 在示例中,日志文件路径是
logs/host.access.log,日志格式是main。logs是相对于 Nginx 配置文件的路径。 - 注释掉该指令意味着禁用访问日志,不会记录访问日志文件。
- 这个指令用于定义访问日志的配置。
虚拟主机的配置
- 基于端口
- 基于ip
- 基于域名:推荐
一个域名对应一个server(虚拟主机)
只安装一个nginx,开启三个server(虚拟主机),对应三个域名,一个域名就是一个网站。
使用
[root@localhost ydhnginx]# lslogs sbin conf html
- logs:存放日志文件
- sbin:存放nginx的启动文件
- conf:存放nginx的配置文件
- html:目录,存放网站的网页文件
[root@localhost logs]# ls
access.log error.log nginx.pid
- nginx.pid :放置master的进程号
- access.log: 正常的访问网站
- error.log: 访问错误的日志
日志的好处:
- 排错故障:根据日志的记录
- 进行数据分析
nginx -t
用于测试 Nginx 配置文件的语法和正确性。它会检查**配置文件(nginx.config)**的语法错误并输出相关的错误信息。
以下是运行成功的情况:
[root@localhost conf]# nginx -t
nginx: the configuration file /usr/local/ydhnginx/conf/nginx.conf syntax is ok
nginx: configuration file /usr/local/ydhnginx/conf/nginx.conf test is successful修改ngixn.config文件
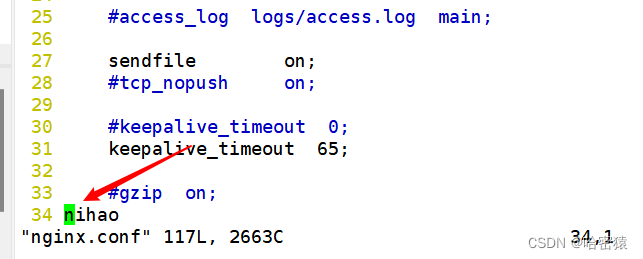
这个时候会报错:
[root@localhost conf]# nginx -t
nginx: [emerg] unknown directive "nihao" in /usr/local/ydhnginx/conf/nginx.conf:35
nginx: configuration file /usr/local/ydhnginx/conf/nginx.conf test failed
启动nginx
[root@localhost ydhnginx]# cd sbin/
[root@localhost sbin]# ls
nginx
[root@localhost sbin]# ./nginx
查看是否启动了
查看进程号:
[root@localhost sbin]# ps aux|grep nginx
root 30983 0.0 0.3 149820 5632 pts/5 S+ 19:42 0:00 vim onekey_install_mjh_nginx.sh
root 34527 0.0 0.0 46240 1164 ? Ss 21:33 0:00 nginx: master process ./nginx
yandong+ 34528 0.0 0.1 46700 2152 ? S 21:33 0:00 nginx: worker process
root 34582 0.0 0.0 112824 988 pts/1 S+ 21:45 0:00 grep --color=auto nginx
查看端口:
netstat -anplut|grep nginx #查看ngixn进程网络的状态
lsof -i:80
ss -anpluts
[root@localhost sbin]# netstat -anplut|grep nginx
tcp 0 0 0.0.0.0:80 0.0.0.0:* LISTEN 34527/nginx: master
查看是否在网页上能正常显示
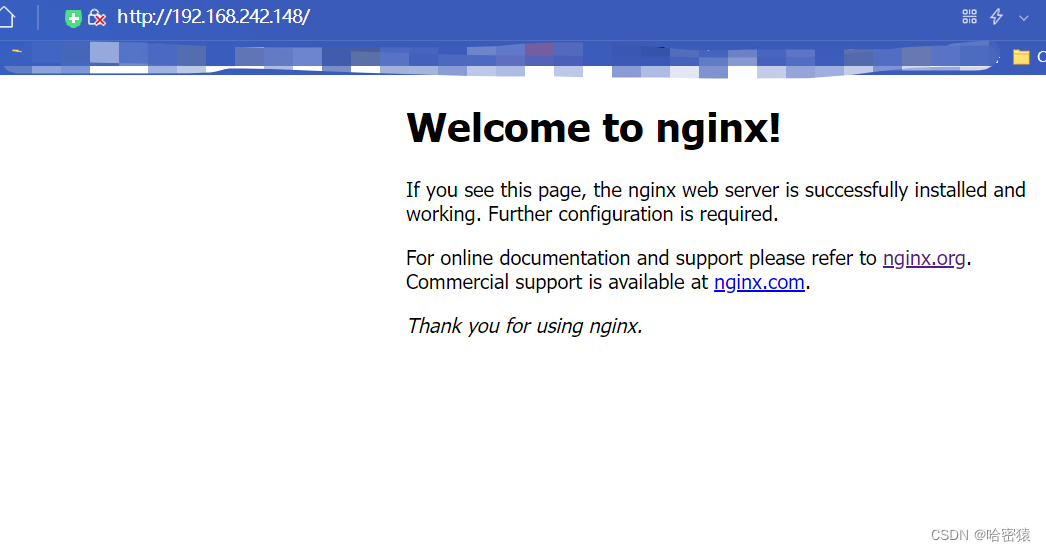
出现这样的画面就是表示nginx安装成功了。
如果前面都配置好了,画面显示不出来,考虑是不是防火墙没关的原因。
停止nginx服务
[root@localhost sbin]# /usr/local/ydhnginx/sbin/nginx -s stop
#使用绝对路径停止服务
[root@localhost sbin]# ./nginx -s stop
#使用相对路径停止服务
查看nginx服务是否已经停止了
[root@localhost sbin]# ps aux|grep nginx
root 30983 0.0 0.3 149820 5632 pts/5 S+ 19:42 0:00 vim onekey_install_mjh_nginx.sh
root 34603 0.0 0.0 112824 984 pts/1 S+ 21:50 0:00 grep --color=auto nginx
yun安装的nginx和编译安装的nginx是否冲突?
冲突的点:默认都想抢占80端口
如果不使用相同的端口,不冲突的
能否在机器里编译安装多个nginx?
可以,如果不使用相同的端口,不冲突的
[root@localhost nginx]# ps aux|grep nginx
root 40988 0.0 0.0 46240 1168 ? Ss 18:34 0:00 nginx: master process ./nginx
yandong+ 40989 0.0 0.1 46700 1916 ? S 18:34 0:00 nginx: worker process
root 41071 0.0 0.0 39308 972 ? Ss 18:34 0:00 nginx: master process /usr/sbin/nginx
nginx 41072 0.0 0.0 39728 1852 ? S 18:34 0:00 nginx: worker process
nginx 41073 0.0 0.0 39728 1852 ? S 18:34 0:00 nginx: worker process
root 41145 0.0 0.0 112824 988 pts/2 S+ 18:36 0:00 grep --color=auto nginxmaster和worker
在Linux中,Nginx是一个流行的高性能Web服务器和反向代理服务器。Nginx的架构涉及两个主要组件:Master进程和Worker进程。下面是对Nginx的Master进程和Worker进程的详细介绍和区别:
-
Master进程:
- Master进程是Nginx的控制进程,负责启动和管理整个Nginx服务器。
- Master进程通常以root权限运行,并负责处理系统信号、读取和解析配置文件以及启动Worker进程。
- Master进程还负责监听网络端口,接收客户端请求,并将请求分发给Worker进程进行处理。
- Master进程通常只有一个实例。
-
Worker进程:
- Worker进程是Nginx的工作进程,负责处理客户端请求和提供服务。
- Worker进程由Master进程创建和管理,通常以非特权用户的身份运行。
- 每个Worker进程都是独立的,具有独立的事件循环和线程池,可以并发地处理多个客户端请求。
- Worker进程负责接收来自Master进程的任务,处理请求,执行业务逻辑,并向客户端返回响应。
区别:
- Master进程和Worker进程的功能不同。Master进程负责管理和控制整个Nginx服务器的运行,包括配置解析、进程管理和任务分发;而Worker进程负责实际的请求处理和服务提供。
- Master进程通常只有一个实例,而Worker进程可以有多个实例,每个实例对应一个CPU核心或处理器,以实现并行处理和提高性能。
- Master进程以root权限运行,而Worker进程以非特权用户的身份运行,以提高服务器的安全性和稳定性。
Nginx的Master-Worker架构使其能够处理大量并发请求,并在高负载下保持高性能和可靠性。Master进程负责监控和管理Worker进程的运行状态,并在需要时重启或回收Worker进程,从而实现动态的负载均衡和故障恢复。
需要注意的是,Nginx的Master-Worker架构是一种常见的服务器架构,并不仅限于Nginx。许多其他Web服务器和应用服务器也采用类似的架构,以实现高性能、可扩展和稳定的服务。
[root@localhost local]# ps aux|grep nginx
root 40988 0.0 0.0 46240 1344 ? Ss 18:34 0:00 nginx: master process ./nginx
yandong+ 42598 0.0 0.1 46700 1916 ? S 19:03 0:00 nginx: worker process
root 42929 0.0 0.0 112824 988 pts/3 S+ 19:09 0:00 grep --color=auto nginx
杀死master进程
[root@localhost local]# ps aux|grep nginx
yandong+ 42598 0.0 0.1 46700 1916 ? S 19:03 0:00 nginx: worker process
root 45678 0.0 0.0 112824 988 pts/3 S+ 19:10 0:00 grep --color=auto nginx
可以看到master进程杀死后,不会再生成了,同时剩下的worker进制变成父进程了。
这个时候我们去重新加载nginx的配置文件,会出错:
[root@localhost local]# nginx -s reload
nginx: [alert] kill(40988, 1) failed (3: No such process)
这是因为是master进程去重新加载配置文件,随后再将信息转递给下面的worker进程。
nginx -s reload
只是杀死worker进程,而master进程不会。父进程的pid不会发生改变。
重新启动nginx服务:
[root@localhost local]# ps aux|grep nginx
root 45907 0.0 0.0 46240 1172 ? Ss 19:14 0:00 nginx: master process nginx
yandong+ 45908 0.0 0.1 46700 1920 ? S 19:14 0:00 nginx: worker process
root 45918 0.0 0.0 112824 988 pts/3 S+ 19:14 0:00 grep --color=auto nginx- 这次选择杀死worker进程。
[root@localhost local]# ps aux|grep nginx
root 45907 0.0 0.0 46240 1348 ? Ss 19:14 0:00 nginx: master process nginx
yandong+ 45969 0.0 0.1 46700 1920 ? S 19:15 0:00 nginx: worker process
root 45978 0.0 0.0 112824 988 pts/3 S+ 19:16 0:00 grep --color=auto nginx
可以看到 进程号为45908的worker进程已经被杀死,新的worker进程号为45969。
升级问题
-
重新编译安装一个新的
先去卸载以前版本的nginx,先删除安装指定的目录(–prefix指定的路径),随后,在PATH变量里删除nginx的安装路径,最后就可以编译安装了。
-
热升级
- 备份老的准备nginx二进制文件
- 准备新的nginx二进制文件,新的nginx二进制各配置路径保持一致
- 向老的nginx进程发送“SIGUSR2 (12)”信号,启动新的进程(新老进程并存)
- 向老的nginx进程发送“SIGQUIT (3)”信号停掉老的nginx进程
基于域名的虚拟主机
修改配置文件nginx.config。一个server对应一个服务。
将server的内容修改如下,同时增加两个server。
server {listen 80;server_name www.yan.com;access_log logs/yan.com.access.log main;location / {root html/yan;index shouye.html index.html index.htm;}error_page 404 /404.html;error_page 500 502 503 504 /50x.html;location = /50x.html {root html;}
}server {listen 80; server_name www.d.com;access_log logs/d.com.access.log main;location / { root html/d;index shouye.html index.html index.htm;} error_page 404 /404.html;error_page 500 502 503 504 /50x.html;location = /50x.html {root html;}
}server {listen 80; server_name www.hao.com;access_log logs/hao.com.access.log main;location / { root html/hao;index shouye.html index.html index.htm;} error_page 404 /404.html;error_page 500 502 503 504 /50x.html;location = /50x.html {root html;}
}listen:指定服务器监听的端口号,这里设置为 80,表示使用 HTTP 协议的默认端口。server_name:指定虚拟主机的域名,分别为 www.yan.com、www.d.com 和 www.hao.com。access_log:指定访问日志的路径和文件名,用于记录访问日志。这里的路径为logs/,文件名为域名.access.log。访问www.hao.com时会生成hao.com.access.log等文件location /:定义请求的 URL 路径匹配规则,这里的/表示匹配所有请求。root:指定静态文件的根目录,用于查找请求的资源文件。对于 www.yan.com,根目录为html/yan;对于 www.d.com,根目录为html/d;对于 www.hao.com,根目录为html/hao。我们需要去创建对应的文件,同时在对应的文件要创建shouye.html index.html index.htm其中的一个页面,或者会报错的。index:指定当请求的 URL 不包含具体文件名时,默认返回的文件。这里定义了三个默认文件名,按照优先级依次为shouye.html、index.html和index.htm。
error_page:定义错误页面的处理方式。404:指定当出现 404 错误时,返回的 URL 路径为/404.html。500 502 503 504:指定当出现 500、502、503 或 504 错误时,返回的 URL 路径为/50x.html。
location = /50x.html:定义对/50x.htmlURL 路径的处理方式。root:指定错误页面文件的根目录,这里为html。
总结起来,这段代码配置了三个虚拟主机,每个主机有自己的域名、访问日志路径和根目录。当请求到达时,会根据 URL 匹配规则查找相应的资源文件,并设置了错误页面的处理方式。
- 最后结果
修改好配置文件nginx.config以及创建好对应的html文件后,我们需要创建新的域名解析,在C:\Windows\System32\drivers\etc目录下的hosts文件中添加域名解析可以实现本地的域名解析功能:
192.168.242.149 www.yan.com
192.168.242.149 www.d.com
192.168.242.149 www.hao.com
当你在浏览器中输入www.yan.com、www.d.com或www.hao.com时,系统将会使用hosts文件中的域名解析规则进行解析,将这些域名映射到指定的IP地址192.168.242.149。
注意,修改hosts文件需要管理员权限。在编辑hosts文件之前,建议先备份原始文件,以防修改错误导致问题。我们可以将hosts文件先复制到桌面上去,然后对该文件进行修改,随后将修改好的文件替换C:\Windows\System32\drivers\etc中的hosts文件即可,同样的可以先将hosts文件进行备份才进行操作。
将上面的操作完成后:
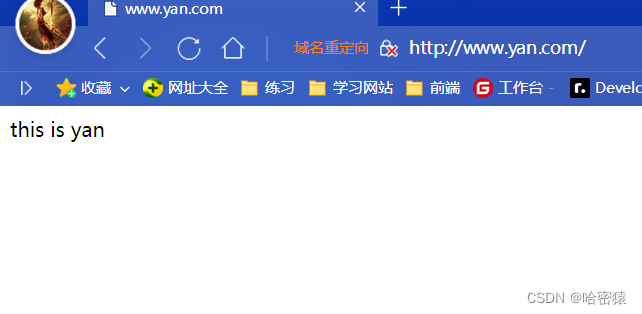
在html/yan下面创建404.html后:
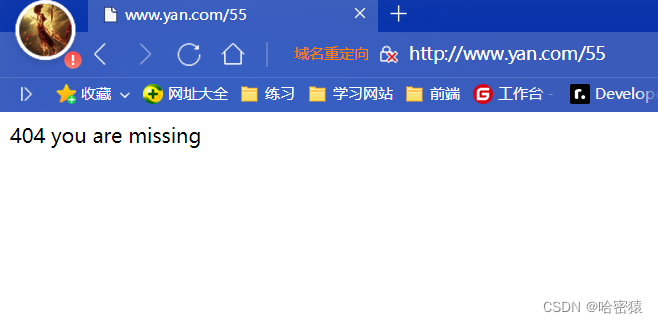
- 问题
同一个服务器,一个进程,相同的端口,用户访问的时候,ngixn是如何区分开不同的网站的?
http协议:
1.请求报文
当用户发送HTTP请求时,请求中通常包含了目标网站的域名信息(Host头字段)。Nginx可以通过检查请求中的域名信息来确定用户访问的是哪个网站。通过在配置文件中定义不同的虚拟主机,并将每个虚拟主机与对应的域名进行绑定,Nginx可以根据请求的域名来将请求分发到相应的虚拟主机,从而实现对不同网站的区分。
2.响应报文
隐藏nginx的版本信息
安装nginx的时候,server_tokens是默认开启的。
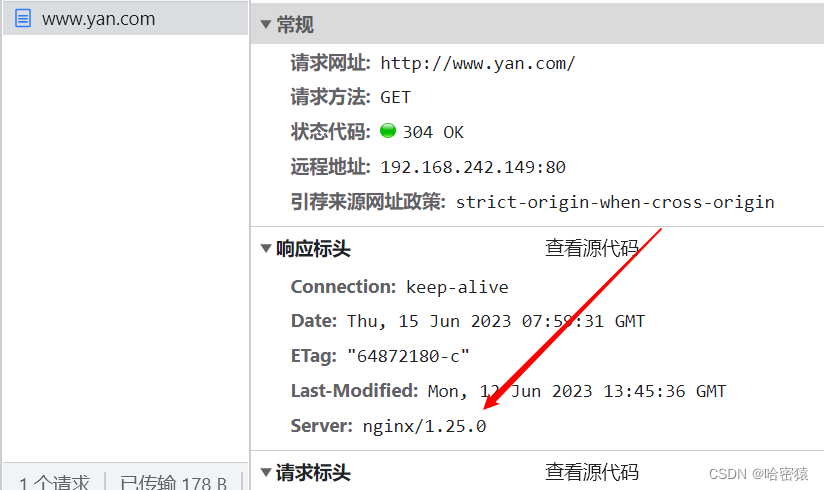
我们可以在nginx.config中的http里面添加server_tokens off;
配置完成后,重新加载nginx
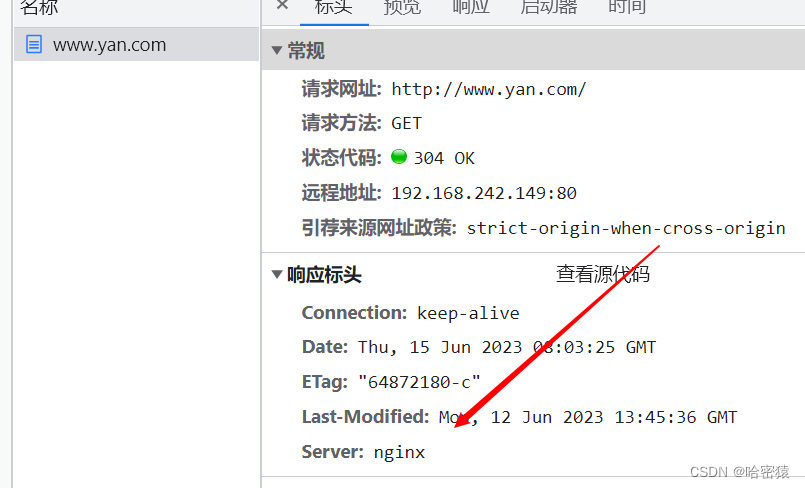
供别人下载的网站
-
可以放到指定server的location中,这样只会在该server生效
-
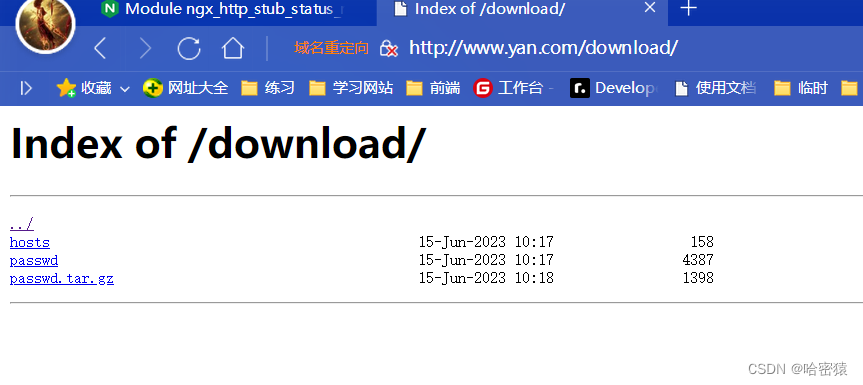
这个时候访问www.hao.com/download是禁止的。 -
同样的也可以放到http的里面,这样所有的主机都可以生效了。
autoindex on; 不放在指定的server里面了。server_tokens off;#gzip on;server {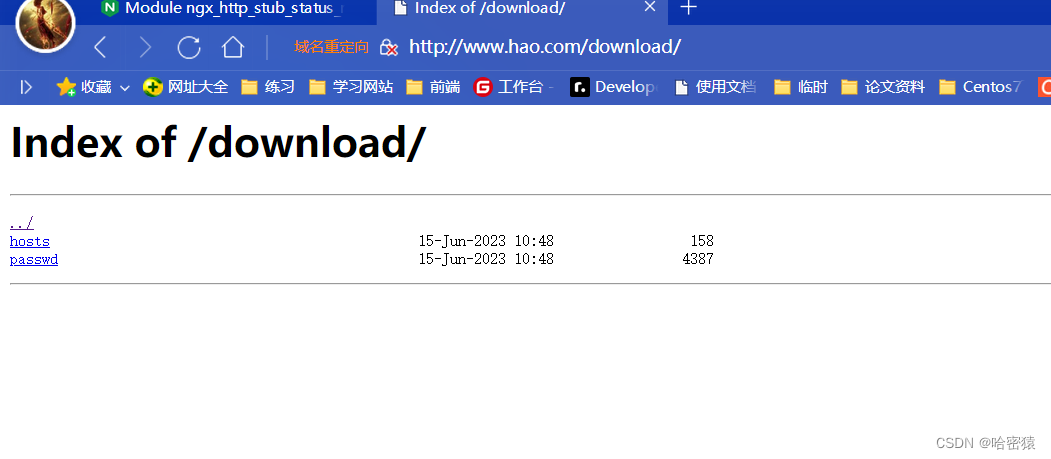
这样基本的具有下载功能的页面就完成了。
统计的信息的页面
可以在指定的server添加一个单独的路由
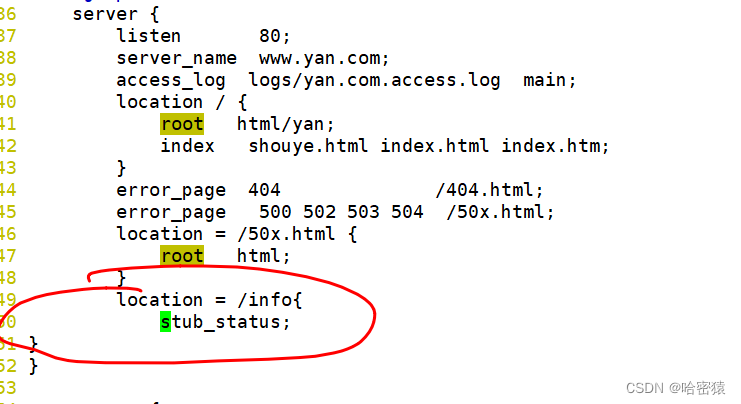
加上access_log off;再访问**/info**不会记录信息到access_log中去了。
访问页面如下:
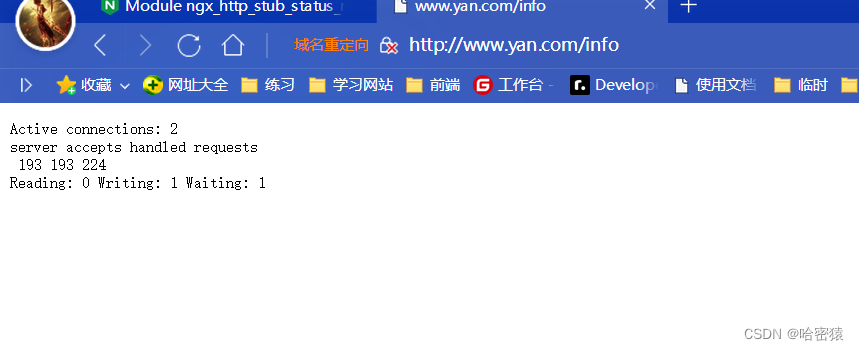
同样的,我们也可以不放指定的server里面,放在http上面的位置,以便所有的域名都可以访问统计信息。
- Active connections: 2(活动连接数:2):这表示服务器当前有两个活动连接。
- Server accepts handled requests(服务器接受处理的请求):这三个数字分别表示服务器接受、处理和响应的请求数量。根据您提供的数据,服务器已接受了202个请求,处理了202个请求,并成功响应了245个请求。
- Reading: 0(读取中的连接数:0):这表示当前没有正在读取数据的连接。
- Writing: 1(写入中的连接数:1):这表示当前有一个连接正在向服务器写入数据。
- Waiting: 1(等待中的连接数:1):这表示当前有一个连接处于等待状态,即等待服务器的响应(占着茅坑不拉屎0.0)。
这些信息通常用于监视服务器的性能和负载情况。
pv介绍
在Linux中,Nginx是一款常用的开源Web服务器软件,它可以处理静态资源、反向代理、负载均衡和HTTP缓存等功能。在Nginx中,“pv"代表"Page View”,即页面浏览量。
“pv”(或者有时也称为"ngx_http_stub_status_module")是Nginx提供的一个模块,用于收集和展示服务器的状态信息,包括请求的总数、活跃连接数、各个URI的访问量等。这些信息对于监控服务器性能、调优和故障排查非常有用。
要启用"pv"模块,需要在Nginx的配置文件中进行相应的设置。首先,确保你的Nginx已经编译安装了该模块,通常在编译安装Nginx时,可以通过添加 --with-http_stub_status_module 参数来启用它。然后,在Nginx的配置文件(通常是nginx.conf)中,添加以下配置块:
location /nginx_status {stub_status on;access_log off;allow 127.0.0.1; # 允许访问的IP地址deny all; # 拒绝其他IP地址的访问
}
上述配置中,location /nginx_status 定义了一个URI路径,用于获取服务器状态信息。stub_status on; 表示开启状态信息的收集,access_log off; 则是为了禁止将访问日志写入磁盘,避免不必要的IO开销。allow 和 deny 分别指定了允许访问的IP地址和禁止访问的IP地址。
配置完成后,通过访问指定的URI路径(例如:http://your_server_address/nginx_status)即可获取服务器的状态信息。返回的信息通常是一组文本,包含了请求数、连接数、各个URI的访问量等统计数据,可以通过解析这些数据进行分析和监控。
需要注意的是,为了安全起见,通常只允许本地或可信任的IP地址访问"pv"页面,以防止未经授权的访问。
ngixn续
nginx认证
ngx_http_auth_basic_module
49 location = /info{50 stub_status;51 access_log off;52 auth_basic "ydh website" #add53 auth_basic_user_file htpasswd; #add54 }
查看htpasswd的来源
[root@localhost conf]# yum provides htpasswdhttpd-tools-2.4.6-98.el7.centos.7.x86_64 : Tools for use with the: Apache HTTP Server
源 :updates
匹配来源:
文件名 :/usr/bin/htpasswd下载httpd-tools
[root@localhost conf]# yum install httpd-tools -y
nginx的allow和deny
ngx_http_access_module
在Linux中,Nginx的allow和deny是用于控制访问权限的指令。它们通常在Nginx的配置文件中与location指令一起使用。下面是对它们的详细解析和使用说明:
-
allow指令:
allow指令用于允许特定的IP地址或IP地址段访问Nginx服务器的特定区域。只有匹配allow指令中定义的IP地址的请求才会被允许通过。如果没有定义allow指令,则默认情况下所有IP地址都是被允许的。使用示例:
allow 192.168.1.100; allow 10.0.0.0/24;上述示例中,第一行允许IP地址为192.168.1.100的请求通过,而第二行允许10.0.0.0/24网段内的IP地址通过。
-
deny指令:
deny指令用于拒绝特定的IP地址或IP地址段访问Nginx服务器的特定区域。只有匹配deny指令中定义的IP地址的请求才会被拒绝。如果没有定义deny指令,则默认情况下所有IP地址都是被允许的。使用示例:
deny 192.168.1.200; deny 10.0.0.0/24;上述示例中,第一行拒绝IP地址为192.168.1.200的请求,而第二行拒绝10.0.0.0/24网段内的IP地址。
-
allow和deny的使用:
这两个指令可以单独使用,也可以结合使用。它们通常与location指令一起使用,以定义特定区域的访问权限。使用示例:
location /private {allow 192.168.1.0/24;deny all; }上述示例中,
location指令匹配路径为/private的请求。然后,allow指令允许192.168.1.0/24网段内的IP地址访问该路径,而deny all指令拒绝其他所有IP地址的请求。
使用allow和deny指令可以有效地控制Nginx服务器的访问权限,限制特定IP地址或IP地址段的访问或拒绝访问。这对于保护服务器安全和限制资源访问非常有用。
请注意,在配置文件中的顺序很重要。allow和deny的顺序会影响访问规则的优先级。一般情况下,最好将deny指令放在allow指令之前,以确保拒绝规则优先生效。
修改nginx.conf中的server中的数据如下
49 location = /info{50 stub_status;51 access_log off;52 auth_basic "ydh website";53 auth_basic_user_file htpasswd;54 allow 192.168.2.67; #add55 deny all; #add56 }nginx限制并发数
- ngx_http_limit_conn_module
用于设置连接限制的区域.
limit_conn_zone $binary_remote_addr zone=addr:10m;
zone=addr:10m表示将创建一个名为"addr"的共享内存区域,大小为10兆字节(MB)。
location /download/ {limit_conn addr 1;autoindex on;root html/yan;}
该配置块的作用是限制每个客户端IP地址在/download/位置上的并发连接数为1,并在请求该位置时自动列出并返回html/yan目录下的文件和子目录的目录索引页面。
在/usr/local/ydhnginx/html/yan/download生产大文件机进行测试。
[root@localhost download]# dd if=/dev/zero of=dd.test bs=1M count=200当我同时打开两个窗口进行下载大文件的时候,在一方没有下载完的时候,再打开另一个进行下载的时候,会出现下面的报错。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-1CN9yeD6-1687870647700)(C:\Users\asus\AppData\Roaming\Typora\typora-user-images\image-20230616101757493.png)]](https://img-blog.csdnimg.cn/2406e143bba745769ce94211dcc7a46b.png)
下面是日志里记录的信息,可以清晰的看到503的错误。

至此,基本的并发数的限制设置完成了.
下面的配置将同时限制每个客户端IP对服务器的连接数以及对虚拟服务器的总连接数。
limit_conn_zone $binary_remote_addr zone=perip:10m;
limit_conn_zone $server_name zone=perserver:10m;server {...limit_conn perip 10;limit_conn perserver 100;
}
limit_conn_zone $binary_remote_addr zone=perip:10m;: 这行指令定义了一个名为perip的连接限制区域,并将客户端的二进制远程地址(IP地址)作为键来识别连接。$binary_remote_addr表示客户端的二进制远程地址。zone=perip:10m表示将创建一个名为perip的共享内存区域,大小为10兆字节(MB)。limit_conn_zone $server_name zone=perserver:10m;: 这行指令定义了一个名为perserver的连接限制区域,并将服务器名称作为键来识别连接。$server_name表示服务器的名称。zone=perserver:10m表示将创建一个名为perserver的共享内存区域,大小为10兆字节(MB)。limit_conn perip 10;: 这行指令设置了名为perip的连接限制区域的连接数限制为10。这表示每个客户端IP地址最多可以同时建立10个连接。limit_conn perserver 100;: 这行指令设置了名为perserver的连接限制区域的连接数限制为100。这表示每个服务器名称(可以是多个域名或虚拟主机)最多可以同时建立100个连接。
nginx限速
ngx_http_core_module中的limit_rate、limit_rate_after
limit_rate 10k; #限制每秒10k的速度limit_rate_after 100k; #下载速度达到100k每秒的时候,进行限制
这段代码放在http里或者指定的server都都会生效,http针对全局,而server针对特定的。
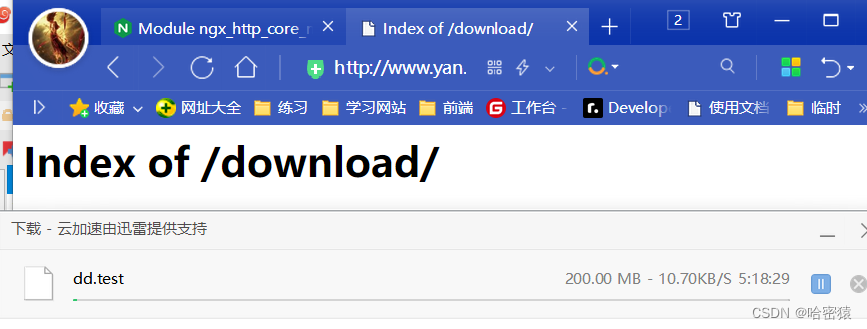
可以通过下载测试看到,下载的速度在10k左右了。
至此,基本的限速就完成了。
限速的算法
Nginx中的令牌桶和漏桶算法都是用于流量控制的算法,用于平滑限制和管理请求的处理速率。它们在处理请求流量时有不同的工作方式和效果。
- 令牌桶算法:
令牌桶算法是一种基于令牌的流量控制算法。在令牌桶算法中,系统以固定的速率生成令牌,并将这些令牌放入一个令牌桶中。每当一个请求到达时,它需要获取一个令牌才能被处理。如果令牌桶中有足够的令牌,则请求被允许处理,并从令牌桶中取走一个令牌。如果令牌桶为空,则请求被暂时阻塞或丢弃。这样可以控制请求的处理速率,使其不超过设定的速率限制。
令牌桶算法的优点是可以应对突发请求。如果请求速率超过了设定的速率限制,令牌桶算法可以使用令牌桶中的剩余令牌来处理这些请求,但处理速率会受限制。它可以提供较为平滑的请求处理速率。
- 漏桶算法:
漏桶算法是一种基于容量的流量控制算法。在漏桶算法中,系统以固定的速率处理请求,并将请求放入一个漏桶中。如果请求到达时漏桶还有剩余容量,则请求被接受并加入漏桶中。如果漏桶已满,则请求被丢弃或者以某种形式进行处理(例如返回错误)。
漏桶算法的特点是无论请求的到达速率如何,处理速率始终保持恒定。这意味着即使有突发请求,漏桶算法也能保持固定的处理速率。它可以用于平滑请求流量和保护后端服务器免受突发请求的影响。
区别:
- 工作方式:令牌桶算法基于令牌生成和消费,请求需要获取令牌才能被处理;漏桶算法基于容量限制和固定的处理速率,请求被放入漏桶并以固定速率处理。
- 效果:令牌桶算法可以应对突发请求,使用令牌桶中的剩余令牌来处理,但处理速率会受限制;漏桶算法保持固定的处理速率,能够平滑流量和保护后端服务器。
- 弹性:令牌桶算法具有一定的弹性,
nginx 限制请求数
ngx_http_limit_req_module
http {limit_req_zone $binary_remote_addr zone=one:10m rate=1r/s;...server {...location / {root html/yan;index shouye.html index.html index.htm;limit_req zone=one burst=5;} limit_req_zone $binary_remote_addr zone=one:10m rate=1r/s;解释
-
limit_req_zone指令用于定义一个请求限制区域(zone),该区域用于跟踪来自特定客户端地址的请求频率。它具有以下参数: -
$binary_remote_addr:这是一个Nginx变量,表示客户端的二进制远程地址。 -
zone=one:10m:这个参数定义了请求限制区域的名称为"one",并且指定了该区域的大小为10兆字节(可以根据需要进行调整)。 -
rate=1r/s:这个参数表示限制每秒钟来自客户端的请求速率为1个请求。
limit_req zone=one burst=5;解释
-
limit_req指令,将请求限制区域应用于该位置。它具有以下参数: -
zone=one:这个参数指定要使用的请求限制区域的名称,即上面定义的"one"。 -
burst=5:这个参数表示在超过请求速率限制之前,可以临时允许的最大突发请求数。在这种情况下,最多允许突发请求达到5个。
多次请求www.yan.com网页后,出现的情况如下
这是日志记录的信息:

至此,基本的nginx的请求数的限制已经设置完成了。
nginx 的 location
ngx_http_core_module中的location
Syntax: location [ = | ~ | ~* | ^~ ] uri { ... }
- = 开头表示精确匹配
- ^~ 开头表示uri以某个常规字符串开头,理解为匹配 url路径即可。nginx不对url做编码,因此请求为/image,可以被规则^~ /image/ /a.txt匹配到(注意是没有空格)。
- ~ 开头表示区分大小写的正则匹配
- ~* 开头表示不区分大小写的正则匹配
- !和!*分别为区分大小写不匹配及不区分大小写不匹配 的正则
- / 通用匹配,任何请求都会匹配到。
(location `=` ) > (location `完整路径` ) > (location `^~` 路径) > (location `~`,`~*` ) > (location 普通匹配) > (`/`)
至此,基本的nginx的请求数的限制已经设置完成了。
nginx 的 location
ngx_http_core_module中的location
Syntax: location [ = | ~ | ~* | ^~ ] uri { ... }
- = 开头表示精确匹配
- ^~ 开头表示uri以某个常规字符串开头,理解为匹配 url路径即可。nginx不对url做编码,因此请求为/image,可以被规则^~ /image/ /a.txt匹配到(注意是没有空格)。
- ~ 开头表示区分大小写的正则匹配
- ~* 开头表示不区分大小写的正则匹配
- !和!*分别为区分大小写不匹配及不区分大小写不匹配 的正则
- / 通用匹配,任何请求都会匹配到。
(location `=` ) > (location `完整路径` ) > (location `^~` 路径) > (location `~`,`~*` ) > (location 普通匹配) > (`/`)
先进行精准匹配,如果匹配成功,立即返回结果并结束匹配过程。
进行普通匹配,如果有多个location匹配成功,将“最长前缀”的location作为临时结果.
通常,匹配成功了普通字符串location后还会进行正则表达式location匹配。有两种方法改变这种行为,精准匹配成功后就终止;另外一种就是使用“^~”前缀,如果把这个前缀用于一个常规字符串那么告诉nginx 如果路径匹配那么不测试正则表达式。
修改server的代码如下:
location /download/ { root html/hao;} location ~/download/sc { root html/hao;} location ~* /download/ { root html/hao;} location ^~/image//a.txt{root html/hao;} location /user/ {proxy_pass http://www.jd.com;} location = /user {proxy_pass http://www.taobao.com;
}-
location /download/ { ... }:- 当请求的URL以
/download/开头时,NGINX会在html/hao目录中查找相应的文件或资源。 - 例如,
http://example.com/download/file.txt会尝试在html/hao目录中查找file.txt文件。
- 当请求的URL以
-
location ~/download/sc { ... }:- 此location块使用了正则表达式匹配,表示当URL以
/download/sc开头时,NGINX会在html/hao目录中查找相应的文件或资源。 - 注意,此处的
~表示区分大小写的正则匹配。
- 此location块使用了正则表达式匹配,表示当URL以
-
location ~* /DOWNLODA/ { ... }:- 类似于前一个location块,此处的
~*表示不区分大小写的正则匹配。 - 当请求的URL以
/DOWNLOAD/开头时,NGINX会在html/hao/download目录中查找相应的文件或资源。
- 类似于前一个location块,此处的
-
location ^~/image//a.txt { ... }:- 当请求的URL精确匹配
/image//a.txt时(注意双斜杠),NGINX会在html/hao目录中查找相应的文件或资源。 - 这是一个精确匹配的location块,其中的
^~表示匹配到此处后停止继续匹配其他location块。
- 当请求的URL精确匹配
-
location /user/ { proxy_pass http://www.jd.com; }:- 当请求的URL以
/user/开头时,NGINX会将请求代理到http://www.jd.com网站。 - 例如,
http://example.com/user/login会将请求代理到http://www.jd.com/login。
- 当请求的URL以
-
location = /user { proxy_pass http://www.taobao.com; }:- 当请求的URL精确匹配
/user时,NGINX会将请求代理到http://www.taobao.com网站。 - 这也是一个精确匹配的location块,其中的
=表示精确匹配。
- 当请求的URL精确匹配
有如下的图:
这是以image开头的:
这是进行跳转的
至此,可看到进行location配置已经基本完成了。
nginx压力测试
python代码
import requests
import time
from concurrent.futures import ThreadPoolExecutorURL = 'http://192.168.2.67' # 待测试的网页URL
NUM_REQUESTS = 4097 # 并发请求数量def make_request(url):start_time = time.time()response = requests.get(url)end_time = time.time()elapsed_time = end_time - start_timereturn elapsed_timedef test_website():print(f'Testing website: {URL}')print(f'Number of concurrent requests: {NUM_REQUESTS}\n')with ThreadPoolExecutor(max_workers=NUM_REQUESTS) as executor:# 提交并发请求futures = [executor.submit(make_request, URL) for _ in range(NUM_REQUESTS)]total_time = 0.0for future in futures:elapsed_time = future.result()total_time += elapsed_timeprint(f'Response time: {elapsed_time:.3f} seconds')avg_time = total_time / NUM_REQUESTSprint(f'\nAverage response time: {avg_time:.3f} seconds')if __name__ == '__main__':test_website()健康检测
Nginx提供了健康检测功能,它能够自动检测后端服务器的可用性,并根据检测结果来动态调整负载均衡。下面是关于Nginx健康检测的详细信息:
-
健康检测类型:
Nginx支持两种健康检测类型:主动健康检测(Active Health Checks)和被动健康检测(Passive Health Checks)。-
主动健康检测(Active Health Checks):Nginx通过定期发送检测请求到后端服务器来主动检测服务器的健康状况。可以配置检测请求的频率、超时时间和响应码等参数,以及定义成功和失败的检测条件。
-
被动健康检测(Passive Health Checks):Nginx根据来自后端服务器的请求和响应情况来判断服务器的健康状态。如果后端服务器未能及时响应请求或返回错误码,Nginx将标记该服务器为不可用。
-
-
健康检测配置:
在Nginx配置文件中,可以使用"health_check"指令来配置健康检测。通过指定检测请求的URL、间隔时间、超时时间、检测成功和失败的条件等参数,以及定义健康检测的类型(主动或被动),来设置健康检测的行为。 -
健康状态标记:
当Nginx发现后端服务器不可用时,它会将服务器标记为不可用状态,并暂时停止将请求分发给该服务器。当服务器恢复正常后,Nginx会重新将其标记为可用状态,继续将请求分发给该服务器。 -
健康检测事件:
Nginx提供了一些相关的事件,可以用于监控和记录健康检测的结果。例如,可以使用"proxy_next_upstream"指令来配置在健康检测失败时如何处理请求。
参数
- fail_timeout –设置必须多次尝试失败才能将服务器标记为不可用的时间,以及将服务器标记为不可用的时间(默认为10秒)。
- max_fails –设置在fail_timeout服务器标记为不可用的时间内必须发生的失败尝试次数(默认为1次尝试)。
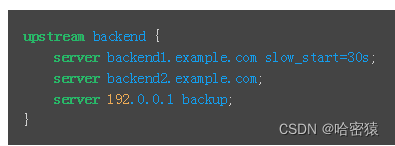
- backup 备份:当其他的服务器都不提供服务的时候,再启用这台服务器提供服务 --》备胎
- slow_start 慢启动
- down 将上游的服务器标识为不可用,不会再发送任何的请求给这台服务器

文章目录
- nginx
- 介绍
- 代理
- 集群
- 安装
- 配置文件
- http
- 使用
- master和worker
- 升级问题
- 基于域名的虚拟主机
- 隐藏nginx的版本信息
- 供别人下载的网站
- 统计的信息的页面
- pv介绍
- ngixn续
- nginx认证
- nginx的allow和deny
- nginx限制并发数
- nginx限速
- 限速的算法
- nginx 限制请求数
- nginx 的 location
- nginx 的 location
- nginx压力测试
- 健康检测
- 参数
- HTTP
- 是什么
- 报文结构
- 请求头部
- 响应头部
- 工作原理
- 用户点击一个URL链接后,浏览器和web服务器会执行什么
- http的版本
- 持久连接和非持久连接
- 无状态与有状态
- Cookie和Session
- http方法:
- get和post的区别
- 状态码
- HTTPS
- 是什么
- ssl
- 如何搞到证书
- nginx中的部署
- 加密
- CA
- 数字证书
- hash算法
- 对称加密
- 非对称加密
- 数字签名
- webhook
- IO多路复用
- 基础
- 文件句柄
- /proc文件:
- 内核
- uri和url
- url
- 介绍
- 方法
- select
- poll
- epoll
- 总结
- DNS
- 是什么以及作用
- 下载DNS服务
- named.conf
- DNS查询
- DNS缓存机制
- 解析过程
- 递归查询和迭代查询
- DNS服务器的类型
- DNS域名
- DNS服务器的类型
- 搭建dns服务器
- 缓存域名服务器
- 主域名服务器
- 从域名服务器
- 排错
- 反向解析
- CDN
- 介绍
- DNS转发
- 介绍
- 配置
- DNS劫持
- nginx 负载均衡
- 负载均衡策略(方法、算法)
- nginx配置
- round-robin
- 加权轮询
- least-connected
- ip-hasp
- 使用Https
- realip
- 后端real server不使用realip模块
- 后端
- real server使用realip模块
- ab压力测试
- 不同负载
- 四层负载
- 7层负载
- 4层和7层
- nfs
- 安装、使用
- nfs机器上的操作
- server机器
- 权限问题
- 开机自动挂载
- 相关的命令和文件
- rpc
- rpc和nfs
- san
- nfs和san区别
- 高可用
- 介绍
- keepalived
- 安装、使用
- vip漂移
- 抓包
- 脑裂
- 脑裂有没有危害?如果有危害对业务有什么影响?
- keepalived架构
- 双vip架构
- Healthcheck
- 实现
- notify
- VRRP
- 选举
- 格式
- 系统性能监控
- 相关命令
- lscpu
- top
- free
- htop
- dstat
- glances
- iftop
- iptraf
- nethogs
- 监控软件
- Prometheus
- 安装、使用
- 将promethues做成服务
- 监控其他机器
- exporter
- grafana
- 配置、使用
- 密码忘记重置
HTTP
是什么
HTTP(Hypertext Transfer Protocol)是一种用于传输超文本的协议。它是互联网上数据传输的基础,用于客户端和服务器之间的通信。HTTP使用TCP/IP协议来传输数据,通常在Web浏览器和Web服务器之间进行通信。
HTTP的主要目标是实现客户端和服务器之间的通信和数据传输。客户端发送HTTP请求到服务器,服务器则返回HTTP响应作为回应。HTTP请求通常由一个URL(Uniform Resource Locator)来标识要访问的资源,例如网页、图片或其他文件。HTTP响应包含了请求的结果,例如HTML文档、图片的二进制数据或其他数据。
HTTP使用了一些常见的方法来定义请求的类型,例如GET、POST、PUT和DELETE等。GET方法用于请求服务器发送指定资源,而POST方法用于向服务器提交数据。HTTP还使用状态码来表示请求的结果,例如200表示请求成功,404表示未找到请求的资源,等等。
HTTP协议是无状态的,这意味着服务器不会保存客户端的状态信息。为了保持状态,HTTP使用了一些机制,如Cookie和Session,以跟踪用户的会话。
总之,HTTP是一种用于在客户端和服务器之间传输超文本数据的协议,它在互联网上扮演着重要的角色,使得我们能够访问和交换网页、图片、文件和其他资源。
报文结构
HTTP报文是在HTTP协议中用于在客户端和服务器之间传输数据的格式。它由请求报文和响应报文两种类型组成,下面详细解释每种报文的结构:
-
请求报文结构:
请求报文由以下几个部分组成:- 请求行(Request Line):包含了请求方法、目标URL和HTTP协议版本。
- 请求头部(Header):包含了关于请求的各种附加信息,如请求的主机、内容类型、缓存控制等。
- 空行(Blank Line):空行用于分隔请求头部和请求体。
- 请求体(Request Body):可选的,用于传输请求的数据,例如在POST请求中的表单数据。
请求行的格式:请求方法 请求目标 HTTP协议版本
示例:GET /index.html HTTP/1.1
请求头部的格式:字段名: 值
示例:Host: www.example.com
Content-Type: application/json -
响应报文结构:
响应报文由以下几个部分组成:- 状态行(Status Line):包含了HTTP协议版本、状态码和状态消息。
- 响应头部(Header):包含了关于响应的各种附加信息,如内容类型、响应的日期、服务器信息等。
- 空行(Blank Line):空行用于分隔响应头部和响应体。
- 响应体(Response Body):可选的,用于传输响应的数据,例如HTML文档、图片或JSON数据。
状态行的格式:HTTP协议版本 状态码 状态消息
示例:HTTP/1.1 200 OK
响应头部的格式:字段名: 值
示例:Content-Type: text/html
Content-Length: 1024
在请求和响应报文中,请求行和状态行指定了HTTP协议版本、请求或响应的状态码和相关信息。请求头部和响应头部用于传递各种元数据,如主机、内容类型、缓存控制等。请求体和响应体则用于传输具体的数据内容。
总结:HTTP报文结构包括请求报文和响应报文。请求报文包含请求行、请求头部、空行和请求体,而响应报文包含状态行、响应头部、空行和响应体。这种结构化的格式使得客户端和服务器能够准确地交换数据,并理解请求和响应的含义和要求。
请求头部
请求头部(Headers)是HTTP请求报文中的一部分,它包含了关于请求的各种附加信息。下面是一些常见的请求头部字段及其详细信息:
-
Host:
- 描述:指定目标服务器的主机名和端口号。
- 示例:Host: www.example.com
-
User-Agent:
- 描述:标识客户端(浏览器或其他工具)的名称和版本信息。
- 示例:User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36
-
Accept:
- 描述:指定客户端可以接受的响应内容类型。
- 示例:Accept: text/html, application/xhtml+xml, application/xml;q=0.9, /;q=0.8
-
Accept-Language:
- 描述:指定客户端接受的自然语言。
- 示例:Accept-Language: en-US,en;q=0.9
-
Accept-Encoding:
- 描述:指定客户端可以接受的内容编码方式,如gzip、deflate等。
- 示例:Accept-Encoding: gzip, deflate
-
Referer:
- 描述:指定当前请求的源URL,用于告诉服务器请求的来源,从那个网站跳转过来的。
- 示例:Referer: https://www.example.com/page1.html
-
Cookie:
- 描述:包含客户端之前接收到的服务器发送的Cookie信息。
- 示例:Cookie: session_id=abc123; user_id=123456
-
Authorization:
- 描述:用于在需要身份验证的请求中发送用户凭证,如用户名和密码。
- 示例:Authorization: Basic YWxhZGRpbjpvcGVuc2VzYW1l
-
Content-Type:
- 描述:指定请求体中的内容类型。
- 示例:Content-Type: application/json
-
Content-Length:
- 描述:指定请求体的长度(以字节为单位)。
- 示例:Content-Length: 1024
这些是常见的请求头部字段,可以根据具体需求添加或修改头部字段来传递更多的请求信息。请求头部的信息帮助服务器理解客户端的需求,并进行相应的处理和响应。
响应头部
HTTP响应头部(Header)包含了关于响应的各种附加信息,以下是一些常见的响应头部字段及其详细信息:
- Content-Type:
该字段指示了响应体中所传输数据的媒体类型(MIME类型),例如"text/html"表示HTML文档,"application/json"表示JSON数据,"image/jpeg"表示JPEG图片等。 - Content-Length:
该字段指示了响应体的长度(以字节为单位),用于客户端确定响应体的大小。 - Content-Encoding:
该字段指示了响应体所采用的编码方式,例如"gzip"表示使用GZIP压缩,"deflate"表示使用Deflate压缩等。 - Cache-Control:
该字段指示了响应的缓存策略,包括缓存的最大有效时间、是否允许缓存副本以及是否允许缓存服务器等。 - Expires:
该字段指示了响应的过期时间,即响应将在何时过期,过期后客户端必须向服务器重新请求。 - Last-Modified:
该字段指示了响应体的最后修改时间,用于缓存验证,客户端可以在后续请求中发送"If-Modified-Since"字段以检查资源是否已经被修改。 - Server:
该字段指示了响应的服务器软件名称和版本号。 - Set-Cookie:
该字段用于在客户端设置一个或多个HTTP Cookie,以便在后续请求中进行会话跟踪或用户识别。 - Location:
该字段用于重定向响应,指示客户端应该跳转到的新的URL地址。 - Connection: 指示客户端与服务器之间的连接类型。"keep-alive"表示保持持久连接,允许多个请求和响应在同一个连接上进行。
- Date: 指示响应生成的日期和时间。
- ETag: 提供与响应关联的实体标签,用于缓存机制。它可以是一个唯一的标识符,用于标记特定版本的资源,可以判断网页是否发生了变化。
以上是一些常见的HTTP响应头部字段,通过这些字段,服务器可以向客户端提供更多有关响应的相关信息,以便客户端正确处理响应并进行适当的处理。
工作原理
HTTP的工作原理可以分为以下几个步骤:
-
客户端发起请求:客户端(通常是Web浏览器)向服务器发送HTTP请求。请求由以下组成:
- 请求行:包括请求方法(如GET、POST)、请求的URL和使用的HTTP协议版本。
- 请求头:包含附加的请求信息,如浏览器类型、接受的数据类型等。
- 请求体(可选):在某些请求中,如POST请求,可能会包含数据,例如表单字段或上传的文件。
-
服务器响应请求:服务器接收到请求后,会解析请求并准备响应。响应由以下组成:
- 状态行:包括HTTP协议版本、状态码(如200表示成功、404表示未找到资源)和相应的状态信息。
- 响应头:包含附加的响应信息,如数据类型、日期等。
- 响应体:包含服务器返回的实际数据,例如HTML文档、图片的二进制数据或其他数据。
-
数据传输:在响应的过程中,数据通过TCP/IP协议在客户端和服务器之间进行传输。TCP/IP协议提供了可靠的数据传输机制,确保数据的准确性和完整性。
-
完成请求:一旦服务器完成响应,它会关闭与客户端的连接,完成请求-响应过程。客户端收到响应后,根据响应的内容进行相应的处理,例如渲染网页或显示图像。
需要注意的是,HTTP是一种无状态协议,每个请求-响应周期都是相互独立的。为了跟踪用户的状态,HTTP使用了一些机制,如Cookie和Session。Cookie是服务器通过响应头在客户端存储的小型数据文件,它包含了与用户相关的信息。当客户端发送下一次请求时,Cookie会随着请求头一起发送到服务器,服务器可以根据Cookie中的信息来识别和跟踪用户。Session则是在服务器端保存用户状态的一种机制,服务器会为每个会话分配一个唯一的标识符,将用户的状态信息存储在会话中。
通过这样的工作原理,HTTP协议使得客户端和服务器能够进行可靠的数据交换,实现了互联网上的信息传输和资源访问。
用户点击一个URL链接后,浏览器和web服务器会执行什么
当用户点击一个URL链接后,浏览器和Web服务器会执行以下步骤:
-
解析URL:浏览器首先解析URL(Uniform Resource Locator),提取出其中的协议、主机名、端口号(如果有)、路径和查询参数等信息。
-
建立连接:浏览器根据解析得到的主机名和端口号,使用TCP/IP协议与Web服务器建立连接。默认情况下,HTTP使用端口号80进行通信,而HTTPS使用端口号443。
-
发起HTTP请求:一旦与Web服务器建立连接,浏览器会构建HTTP请求。该请求包括请求行、请求头和请求体等部分:
- 请求行:包括请求方法(例如GET、POST)、路径和使用的HTTP协议版本。
- 请求头:包含附加的请求信息,如浏览器类型、接受的数据类型等。
- 请求体(可选):对于某些请求,如POST请求,可能会包含数据,例如表单字段或上传的文件。
-
服务器处理请求:Web服务器接收到浏览器发送的HTTP请求后,会解析请求并根据请求的内容执行相应的处理。这可能涉及查询数据库、读取文件、处理业务逻辑等。
-
生成HTTP响应:服务器根据请求的处理结果生成HTTP响应。响应由以下组成:
- 状态行:包括HTTP协议版本、状态码(如200表示成功、404表示未找到资源)和相应的状态信息。
- 响应头:包含附加的响应信息,如数据类型、日期等。
- 响应体:包含服务器返回的实际数据,例如HTML文档、图片的二进制数据或其他数据。
-
数据传输:在响应的过程中,服务器通过已建立的TCP/IP连接将HTTP响应发送回浏览器。TCP/IP协议确保数据的可靠传输,以确保数据的准确性和完整性。
-
浏览器处理响应:浏览器接收到服务器发送的HTTP响应后,根据响应的内容进行相应的处理。这可能包括渲染网页、显示图像、执行JavaScript代码等。
-
关闭连接:一旦响应完成,服务器关闭与浏览器之间的连接。浏览器根据需要可以继续发送其他请求或保持连接以获取其他资源。
渲染网页:渲染网页指的是将从服务器获取的HTML、CSS和JavaScript等网页资源在浏览器中进行解析和显示的过程。简单来说,渲染网页就是将网页内容呈现给用户,以便用户能够看到和与网页进行交互。
通过这些步骤,用户点击一个URL链接后,浏览器和Web服务器之间完成了请求和响应的交互过程,从而实现了网页的加载和显示。
问题:一个网站打不开了,如何去判断问题所在
- 检查域名解析是否有问题,能否解析出一个ip地址
- ping 服务器ip地址。看服务是否开机启动
- 检查服务器的文本服务是否开启或者检查服务器的web服务的短端口是否打开
- 检查web服务器的日志,看看web服务是否有限制
- 检查web服务器的日志,看看web服务是否有限制
思路:由外到内,一层一层去检查。
[root@localhost ~]# iptables -A INPUT -p tcp --dport 80 -j DROP
[root@localhost ~]# iptables -F
这段代码是针对Linux系统上的iptables防火墙进行配置的命令。
-
iptables -A INPUT -p tcp --dport 80 -j DROP:这是iptables命令的一部分,用于添加一个规则到INPUT链。下面是对每个选项的解析:iptables:该命令用于配置iptables防火墙规则。-A INPUT:指定规则将添加到INPUT链中,该链用于处理进入系统的数据包。-p tcp:指定协议为TCP,表示该规则仅适用于TCP数据包。--dport 80:指定目标端口为80,表示该规则仅适用于目标端口为80的数据包(通常用于HTTP服务)。-j DROP:指定动作为DROP,表示匹配该规则的数据包将被丢弃(即阻止进入系统)。
因此,这行命令的作用是阻止通过TCP协议访问本机的80端口(通常是Web服务器的默认端口)的数据包。
-
iptables -F:这是另一个iptables命令,用于清除防火墙规则,即将所有规则恢复到默认设置。下面是对命令的解析:-F:指定清除(flush)规则,即删除所有的防火墙规则。
所以,这行命令的作用是清除所有已配置的防火墙规则,将iptables恢复到默认设置。
请注意,这段代码需要以root用户身份执行,因为iptables命令通常需要root权限来配置系统级防火墙规则。并且在对防火墙进行配置时,请确保你知道自己在做什么,以免意外地阻止了正常的网络流量或导致其他问题。
http的版本
HTTP(Hypertext Transfer Protocol)是一种用于在Web上传输数据的协议。HTTP的不同版本有不同的特点和优缺点。以下是几个常见的HTTP版本及其区别:
- HTTP/1.0:
- 非持久连接:每次请求/响应完成后,TCP连接会关闭,需要重新建立连接,造成性能上的开销。
- 无状态:服务器不会保存客户端请求的任何信息,每个请求都是独立的。
- 缺点:每个请求都需要建立和关闭连接,效率较低。
- HTTP/1.1:
- 持久连接:多个请求/响应可以共享同一个TCP连接,减少了连接建立和关闭的开销。
- 无状态:与HTTP/1.0相同,服务器不会保存客户端请求的任何信息。
- 新增功能:引入了请求头的Host字段、分块传输编码、缓存控制等。
- 优点:减少了连接建立和关闭的开销,提高了性能。
- HTTP/2:
- 二进制分帧:将请求和响应消息分割为二进制的帧,可以并行发送和解析,提高效率。
- 多路复用:通过单个TCP连接并行处理多个请求和响应,消除了HTTP/1.x中的队头阻塞问题。
- 服务器推送(Server Push):服务器可以主动将多个相关资源推送给客户端,减少了额外的请求。
- 头部压缩:使用专门的算法对头部信息进行压缩,减少了数据传输量。
- 优点:提高了性能和效率,减少了延迟。
- HTTP/3:
- 基于UDP:使用QUIC(Quick UDP Internet Connections)作为传输协议,减少了TCP的握手延迟。
- 多路复用:类似于HTTP/2,通过单个连接并行处理多个请求和响应。
- 错误恢复:在网络切换或连接中断后,能够更快地恢复连接。
- 优点:提高了性能和效率,特别是在高延迟和丢包环境下。
总结:
- HTTP/1.0和HTTP/1.1是基于TCP的协议,HTTP/2和HTTP/3则在传输层选择了更高效的协议(HTTP/2使用TCP,HTTP/3使用UDP)。
- 持久连接和多路复用是HTTP/1.1、HTTP/2和HTTP/3相较于HTTP/1.0的重要改进,减少了连接建立和关闭的开销,提高了性能。
- HTTP/2和HTTP/3的头部压缩、二进制分帧以及服务器推送等功能进一步优化了性能和效率。
可以从速度和安全性方面进行回答。
持久连接和非持久连接
HTTP的持久连接和不持久连接是关于建立和维持连接的不同方式。下面是它们的详细解释:
-
非持久连接(Non-Persistent Connection):
- 在非持久连接的情况下,每次请求都需要建立一个新的连接。
- 当客户端发送一个请求到服务器时,建立TCP连接,发送请求并接收响应后,连接就会被关闭。
- 每个请求/响应周期都需要重新建立连接,导致了较高的延迟。
-
持久连接(Persistent Connection):
- 在持久连接中,客户端和服务器之间的连接在多个请求和响应之间保持打开状态。
- 客户端可以发送多个请求,而无需为每个请求建立新的连接。
- 服务器在接收到请求后,可以在同一个连接上发送多个响应。
- 连接可以在一定的时间后关闭,或者根据头部字段"Connection: close"来指示关闭连接。
持久连接相对于不持久连接有以下优点:
- 减少了连接建立和断开的开销:不需要为每个请求建立新的连接,节省了时间和资源。
- 减少了网络延迟:由于连接保持打开状态,后续请求可以更快地发送和接收响应,减少了整体的延迟时间。
- 提高了性能和吞吐量:通过复用连接,可以同时处理多个请求和响应,提高了服务器的处理能力和系统的吞吐量。
然而,持久连接也存在一些注意事项和限制:
- 连接资源限制:由于每个持久连接需要占用服务器资源,服务器需要管理和控制同时打开的连接数,以防止资源耗尽。
- 阻塞问题:如果一个响应较慢,可能会阻塞其他请求的处理,影响性能。
- 超时和过期问题:由于连接保持打开的时间较长,可能会导致某些资源的过期或变化,需要进行适当的缓存策略和处理。
总而言之,持久连接是一种提高性能和效率的方法,可以减少连接建立和断开的开销,但需要注意资源管理和阻塞等问题。
无状态与有状态
有状态和无状态是两种不同的概念,涉及到系统或协议如何管理和处理信息的持久性。
-
有状态(Stateful):
- 概念:有状态是指系统或协议在处理请求时会记住之前的状态信息。服务器会保留客户端的状态,以便在后续请求中使用。服务器可以识别不同的客户端,跟踪会话,存储和共享状态数据。
- 优点:
- 上下文传递:服务器可以跟踪用户会话和上下文信息,可以根据之前的请求处理逻辑来响应后续请求,提供个性化的服务。
- 简化开发:服务器可以在会话期间存储和管理数据,减少了开发人员需要考虑的状态管理和数据存储的复杂性。
- 缺点:
- 扩展性:由于服务器需要维护客户端的状态信息,扩展服务器规模和处理并发请求可能更加困难。
- 可靠性:服务器的故障或重启可能导致客户端的状态丢失,需要进行额外的处理来确保数据的持久性和可靠性。
- 负载均衡:在多台服务器之间进行负载均衡时,需要确保客户端的状态在不同服务器之间的一致性,增加了管理的复杂性。
-
无状态(Stateless):
- 概念:无状态是指系统或协议在处理请求时不保留之前的状态信息。每个请求都是独立的,服务器不会识别客户端,不会跟踪会话,不会存储客户端的状态信息。
- 优点:
- 可伸缩性:由于服务器不需要维护客户端的状态,可以更容易地扩展服务器规模,处理更多的并发请求。
- 简化部署:无状态协议和应用程序可以更容易地部署和复制,减少了服务器之间状态同步的需求。
- 可缓存性:由于每个请求都是独立的,可以对响应进行缓存,提高性能和效率。
- 缺点:
- 会话管理:服务器无法直接跟踪用户会话,需要使用额外的机制(如会话标识符或Cookie)来管理会话状态。
- 身份验证:每个请求都需要进行身份验证,以确认用户的权限和身份,增加了处理的复杂性。
- 上下文传递:对于需要传递上下文信息的应用,可能需要使用额外的机制来传递上下文,如查询参数、URL重写、隐藏字段等。
选择有状态还是无状态取决于具体的需求和场
景。有状态适用于需要跟踪会话、上下文和个性化服务的应用,但可能面临扩展性和可靠性方面的挑战。无状态适用于高可伸缩性和可缓存性的场景,但需要额外的会话管理和上下文传递机制。
Cookie和Session
Cookie和Session是用于在Web应用程序中管理用户状态和跟踪会话的常见机制。
-
Cookie(Cookie):
- 介绍:Cookie是服务器在客户端(通常是浏览器)存储少量数据的一种方式。当用户访问网站时,服务器可以通过HTTP响应在用户的浏览器中设置一个Cookie。该Cookie会被保存在浏览器中,每次用户发送请求时,浏览器会自动将Cookie发送给服务器。
- 关键点:
- 存储位置:Cookie存储在用户的浏览器中。
- 数据大小:Cookie通常只能存储小量的文本数据。
- 客户端发送:每次请求时,浏览器会自动将相应的Cookie发送给服务器。
- 生命周期:可以设置Cookie的过期时间,也可以创建会话Cookie,仅在用户关闭浏览器时过期。
- 用途:Cookie常用于实现用户身份验证、跟踪用户偏好设置、记录购物车内容等。
-
会话(Session):
- 介绍:会话是一种在服务器端存储和管理用户状态信息的机制。当用户访问网站时,服务器会为每个用户创建一个唯一的会话,并分配一个会话标识符(Session ID)。会话ID通常通过Cookie或URL重写的方式发送给客户端,在后续的请求中,客户端会将会话ID发送回服务器。
- 关键点:
- 存储位置:会话数据存储在服务器端,通常保存在内存或持久化存储(如数据库)中。
- 数据大小:会话可以存储更大的数据量,不受浏览器限制。
- 客户端发送:会话ID通常通过Cookie发送给客户端,浏览器会自动将会话ID附加在每个请求中。
- 生命周期:会话的生命周期由服务器管理,可以根据需要设置过期时间。
- 用途:会话常用于实现用户登录状态管理、保持用户上下文信息、存储用户数据等。
关系:
- Cookie和Session经常结合使用。服务器可以使用Cookie在客户端存储一个唯一的会话ID,而将实际的会话数据存储在服务器端的Session对象中。当客户端发送请求时,会自动附带包含会话ID的Cookie,服务器可以根据会话ID找到对应的会话数据,实现状态的管理和跟踪。
- 典型的流程是:用户通过登录页面进行身份验证,服务器验证成功后创建一个会话,生成一个会话ID,并将会话ID存储在一个名为"session"的Cookie中发送给客户端。客户端在后续的请求中会自动附带该Cookie,服务器根据会话ID来获取对应的会话数据,
实现状态管理和个性化服务。
总结:Cookie是一种在客户端存储少量数据的机制,用于传递会话ID;而Session是一种在服务器端存储和管理用户状态信息的机制。Cookie用于在客户端存储会话ID,而Session用于在服务器端存储实际的会话数据。它们结合使用可以实现状态管理和会话跟踪。
http方法:
-
以下是HTTP中常用的四种方法(也称为HTTP动词)的详细介绍:
-
GET(获取):
GET方法用于从服务器获取指定资源的表示形式。通过发送GET请求,客户端可以请求服务器发送特定资源的数据。GET请求通常是幂等的,这意味着多个相同的GET请求不会对服务器产生副作用,也不会改变资源的状态。它主要用于获取数据,而不是修改或创建数据。 -
POST(提交):
POST方法用于向服务器提交数据,通常用于创建新资源或对现有资源进行修改。通过发送POST请求,客户端将数据作为请求的主体发送给服务器,并期望服务器根据请求执行相应的操作。与GET请求不同,POST请求不是幂等的,即多个相同的POST请求可能会导致不同的结果。POST请求常用于提交表单数据、上传文件等操作。 -
PUT(更新):
PUT方法用于向服务器发送数据,以便在指定位置创建或更新资源。通过发送PUT请求,客户端将数据作为请求的主体发送给服务器,并要求服务器将该数据存储在指定的URL位置。PUT请求通常是幂等的,即多次发送相同的PUT请求将具有相同的结果。PUT请求常用于更新整个资源或在指定位置创建新资源。 -
DELETE(删除):
DELETE方法用于请求服务器删除指定的资源。通过发送DELETE请求,客户端可以请求服务器删除指定URL位置的资源。DELETE请求是幂等的,即多次发送相同的DELETE请求将具有相同的结果。DELETE请求常用于删除资源,但要谨慎使用,因为删除后无法恢复数据。
这些HTTP方法允许客户端与服务器进行不同类型的交互,以便进行数据的获取、创建、更新和删除操作。根据具体的应用场景和需求,选择适当的HTTP方法非常重要。
-
get和post的区别
GET和POST是HTTP协议中最常用的两种方法,它们在以下几个方面有明显的区别:
- 数据传输位置:
- GET:通过URL的查询参数(Query Parameters)传输数据。数据附加在URL的末尾,以键值对的形式出现,例如:
https://example.com/resource?key1=value1&key2=value2。GET请求的数据可以被缓存、保存在浏览器的历史记录中,以及书签中。 - POST:通过请求的主体(Request Body)传输数据。数据不会显示在URL中,而是封装在请求的主体中进行传输。POST请求的数据不会被缓存或保存在浏览器的历史记录中。
- 数据长度限制:
- GET:由于数据通过URL传输,受到URL长度的限制。不同浏览器和服务器对URL长度的限制不尽相同,一般在几千个字符左右。
- POST:由于数据通过请求的主体传输,没有固定的长度限制。但是,服务器和应用程序可能会有对请求主体大小的限制。
- 安全性:
- GET:GET请求的数据会附加在URL中,因此在网络传输过程中容易被拦截和查看。因此,不应将敏感数据通过GET请求传输,例如密码或用户身份验证信息。
- POST:POST请求的数据位于请求主体中,不会明文显示在URL中,相对于GET请求具有更好的安全性。可以将敏感数据通过POST请求进行传输。
- 幂等性:
- GET:GET请求是幂等的,多次发送相同的GET请求不会对服务器产生副作用。即使多次请求,也不会改变资源的状态。
- POST:POST请求不是幂等的,多次发送相同的POST请求可能会导致不同的结果。每次请求都可能对服务器资源进行修改、创建新资源或执行其他非幂等操作。
总的来说,GET适合用于获取数据,对于幂等的操作和数据量较小的情况;而POST适合用于传输大量数据、进行非幂等操作、创建新资源或修改资源的情况。在设计和开发Web应用程序时,根据实际需求选择适当的HTTP方法非常重要。
状态码
以下是常用的HTTP状态码及其详细介绍:
-
200 OK:
表示请求成功。服务器成功处理了客户端的请求,并返回了请求的资源。 -
201 Created:
表示请求已成功,并且服务器创建了新的资源。通常在使用POST方法创建新资源时返回此状态码。 -
204 No Content:
表示服务器成功处理了请求,但没有返回任何内容。通常在使用DELETE方法删除资源或执行某些不需要返回内容的操作时返回此状态码。 -
400 Bad Request:
表示服务器无法理解客户端的请求。常见的原因包括语法错误、无效的请求消息、缺少必需的参数等。 -
401 Unauthorized:
表示请求需要进行身份验证。客户端未提供有效的身份验证凭据或未通过身份验证。 -
403 Forbidden:
表示服务器理解客户端的请求,但拒绝执行该请求。通常是因为客户端没有访问请求资源的权限。 -
404 Not Found:
表示服务器无法找到请求的资源。这可能是由于URL路径错误、资源被移除或不存在等原因造成的。 -
500 Internal Server Error:
表示服务器在执行请求时遇到了意外的错误。这通常是服务器端的问题,而不是客户端请求的问题。 -
503 Service Unavailable:
表示服务器暂时无法处理请求,通常是因为服务器过载或维护。客户端可以稍后重试该请求。
这些状态码是HTTP协议中常见的一部分,用于表示请求和响应之间的状态和结果。客户端根据状态码可以了解请求的处理情况,并根据需要采取适当的操作或显示相关的错误信息。
HTTPS
是什么
HTTPS代表超文本传输安全协议(Hypertext Transfer Protocol Secure)。它是一种通过加密和认证的方式来保护网络通信安全的HTTP协议扩展。
下面是HTTPS的详细说明:
-
安全性:
HTTPS通过使用安全套接层(SSL)或传输层安全性(TLS)协议来保护通信的安全性。这些协议使用加密算法对数据进行加密,以确保传输过程中的机密性和完整性。这样,敏感数据(如密码、个人信息等)在传输过程中不容易被窃听或篡改。 -
数据加密:
HTTPS使用公开密钥加密(Public Key Encryption)来保护数据的机密性。客户端和服务器之间的通信过程中,使用公钥对数据进行加密,只有服务器拥有相应的私钥才能解密数据。这样,即使有人在网络上截获了数据,也无法解密其内容。 -
证书验证:
HTTPS使用数字证书来验证服务器的身份。服务器拥有由可信的证书颁发机构(Certificate Authority,CA)签发的数字证书。客户端在与服务器建立连接时,会验证服务器提供的证书是否有效和可信。这样可以防止中间人攻击和伪装服务器的问题。 -
端口:
HTTP使用默认端口80进行通信,而HTTPS使用默认端口443进行通信。这样,服务器可以通过不同的端口区分HTTP和HTTPS请求,并正确处理相应的协议。 -
SEO影响:
HTTPS对网站的搜索引擎优化(SEO)有一定影响。搜索引擎(如Google)更倾向于显示和排名使用HTTPS的网站,因为HTTPS可以提供更好的安全性和数据保护。 -
速度影响:
由于HTTPS需要进行加密和解密操作,相对于HTTP而言,通信过程可能会稍微慢一些。但是,随着计算机硬件和网络技术的进步,这种差异已经趋于减小,一般用户很难察觉到明显的速度差异。
总的来说,HTTPS通过加密和认证机制提供了更高级别的网络通信安全,使得网站和应用程序能够保护用户的敏感数据,防止信息泄露和篡改。因此,对于需要保护隐私和数据安全的网站、电子商务平台和用户身份验证等应用,使用HTTPS是非常重要的。
ssl
Nginx是一个流行的开源Web服务器软件,它也可以用作反向代理服务器和负载均衡器。Nginx提供了支持SSL/TLS的功能,使得它可以安全地传输数据。下面是关于Nginx中SSL的详细介绍:
-
SSL和TLS:
SSL(Secure Sockets Layer)和TLS(Transport Layer Security)是一组用于加密和身份验证的协议,用于保护在网络上传输的数据。SSL是较早的协议版本,而TLS是SSL的继任者,目前广泛使用的是TLS的不同版本,如TLS 1.2和TLS 1.3。 -
Nginx中的SSL模块:
Nginx使用ngx_http_ssl_module模块来提供SSL/TLS功能。该模块需要在编译Nginx时启用,并且需要加载相应的SSL库。 -
证书和密钥:
SSL/TLS使用证书和私钥来进行加密和身份验证。证书用于验证服务器的身份,私钥用于解密数据。在Nginx中,您需要为您的域名获取有效的SSL证书,并将其与相应的私钥配对。 -
配置SSL:
在Nginx配置文件中,您需要进行以下配置来启用SSL:-
指定证书和私钥的文件路径:
ssl_certificate /path/to/ssl_certificate.crt; ssl_certificate_key /path/to/ssl_certificate.key; -
配置SSL协议和加密算法:
ssl_protocols TLSv1.2 TLSv1.3; ssl_ciphers EECDH+AESGCM:EDH+AESGCM:AES256+EECDH:AES256+EDH; ssl_prefer_server_ciphers on; -
配置SSL会话缓存:
ssl_session_cache shared:SSL:10m; ssl_session_timeout 10m; -
配置SSL会话票据:
ssl_session_tickets on; ssl_session_ticket_key /path/to/ssl_ticket.key; -
配置SSL证书验证:
ssl_trusted_certificate /path/to/trusted_certificate.crt; ssl_verify_client on;
-
-
HTTP重定向到HTTPS:
如果您想将所有HTTP请求重定向到HTTPS,可以添加以下配置:server {listen 80;server_name example.com;return 301 https://$server_name$request_uri; } -
HTTP/2支持:
Nginx还支持HTTP/2协议,它是一种更高效的传输协议。要启用HTTP/2,您需要在SSL配置中添加以下指令:listen 443 ssl http2;
这些是关于Nginx中SSL的一些详细介绍。使用SSL可以提供安全的数据传输和身份验证,帮助保护您的应用程序和用户的隐私。请注意,以上只是一个概述,Nginx的
SSL配置选项和功能更加丰富,您可以根据具体需求进行进一步的配置和优化。
如何搞到证书
在阿里云里先要购买域名,然后根据域名区申请免费的证书。
证书是捆绑到域名上的 --》对域名进行担保
nginx中的部署
1.上传下载的证书到ngixn服务器的conf目录下
10488089_*.online_nginx.zip
2.unzip 10488089_*.online_nginx.zip解压
*.online.key 私钥
*.online.pem 公钥
3.修改配置文件启用nginx
server {listen 443 ssl;server_name **.online;ssl_certificate **.pem;ssl_certificate_key **.key;ssl_session_cache shared:SSL:1m;ssl_session_timeout 5m;ssl_ciphers HIGH:!aNULL:!MD5;ssl_prefer_server_ciphers on;location / {root html;index index.html index.htm;}}4.我们还需要配置hosts文件,防止将网站解析到公网上了。
5.我们也需要Linux中的hosts文件。
[root@localhost ~]# curl https://www.*.online
我们会访问到公网上的网站。
需要在/etc/hosts加路径
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
192.168.2.24 www.*.online6.重启服务nginx -s reload
在输入网站的时候,出现小锁就代表成功了。
加密
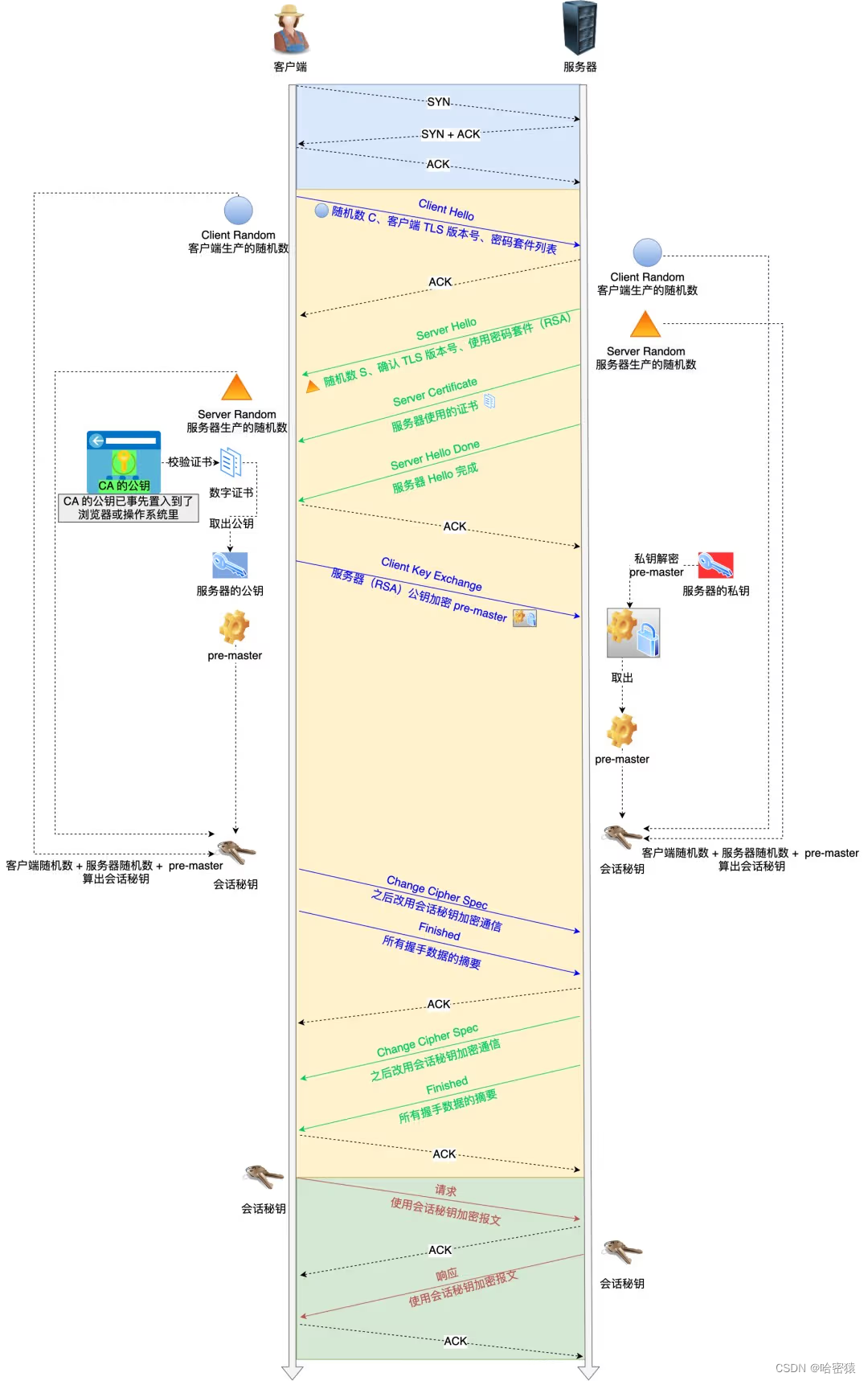
ssl的四次握手
CA
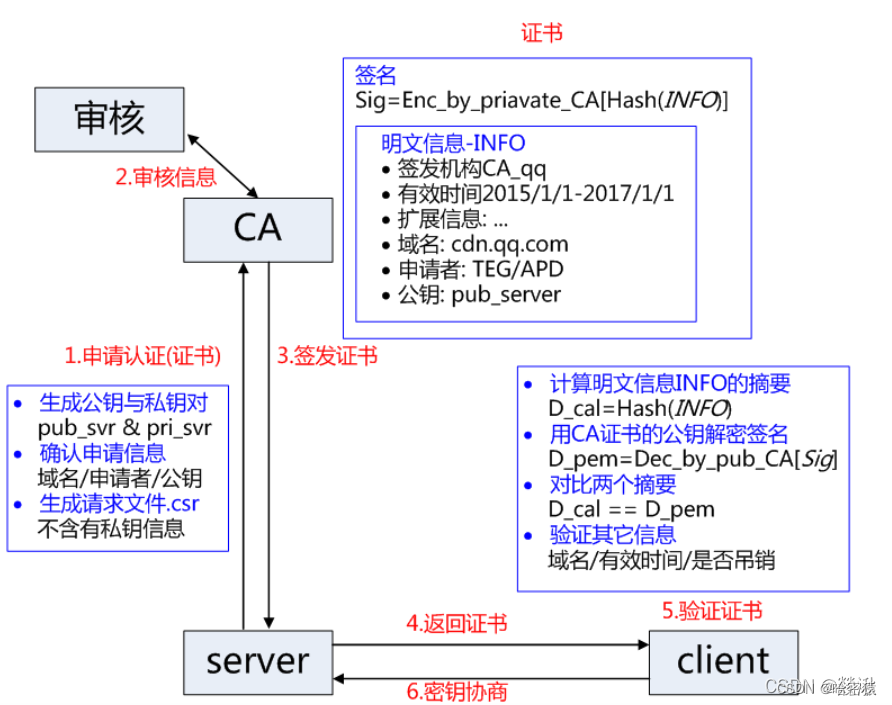
CA是数字证书认证机构(Certificate Authority)的缩写,是一种专门负责颁发和管理数字证书的第三方机构。以下是对CA的全面详细介绍:
-
定义:数字证书认证机构(CA)是一种受信任的第三方实体,负责验证和确认公钥与实体(例如个人、组织或网站)之间的关联关系,并使用数字签名来对这种关联进行认证。CA的主要任务是为各种实体颁发数字证书,并提供公钥基础设施(PKI)的相关服务。
-
功能:
- 验证身份:CA通过严格的身份验证程序,确认实体(如个人或组织)的身份和信息,以确保数字证书中的公钥与正确的实体相关联。
- 颁发数字证书:一旦身份验证成功,CA会生成一个数字证书,其中包含实体的公钥、身份信息和数字签名。证书是对实体身份和公钥的数字化确认。
- 数字签名:CA使用自己的私钥对生成的数字证书进行签名,这个数字签名是对证书的认证,用于验证证书的真实性和完整性。
- 证书撤销:CA负责管理和维护证书的有效性。如果证书的私钥被泄露、实体的信息发生变化或证书出现其他问题,CA可以将证书撤销,以保持数字证书的可信性。
- 证书存储和检索:CA通常维护一个证书数据库,用于存储颁发的数字证书,并提供检索和查询服务,以便用户可以验证证书的有效性和真实性。
-
信任体系:CA的权威性和可信度是基于信任体系建立的。操作系统、浏览器和其他应用程序内置了一组受信任的CA根证书,这些根证书的公钥用于验证由CA颁发的数字证书。这种信任体系确保了数字证书的可靠性和合法性。
-
应用领域:
- 安全通信:CA用于保证网络通信的安全性,例如在HTTPS中使用CA颁发的数字证书对网站进行身份验证和加密通信。
- 数字签名:CA用于验证数字签名的合法性,确保签名的身份和文件的完整性。
- 身份认证:CA用于验证用户身份,例如在电子商务和网上银行等应用中,通过颁发数字证书对用户进行身份认证。
-
CA的责任和安全性:作为数字证书的权威颁发机构,CA承担着重要的责任,包括保
护私钥的安全性、正确执行身份验证程序、及时撤销证书等。CA需要具备高度的安全性和可靠性,以确保数字证书系统的有效性和可信度。
总之,CA是数字证书认证的核心机构,负责验证和认证公钥与实体身份之间的关联,以建立安全的通信和身份认证机制。通过数字证书,用户可以验证实体的身份,确保通信的安全性和完整性。
数字证书
数字签名是一种用于确保数字信息完整性、认证身份和防止篡改的加密技术。它在信息安全领域中起着重要作用,特别是在数据传输和电子文档领域。下面是数字签名的详细介绍:
-
概述:
数字签名使用非对称加密算法,通过对信息进行加密和验证,确保信息的真实性和完整性。它结合了加密技术和公钥基础设施(PKI)来提供身份认证和数据完整性的保证。 -
工作原理:
(1)生成密钥对:首先,签名者生成一对密钥,包括私钥和公钥。私钥只有签名者自己知道,并且必须保密。公钥可以公开分享给其他人。
(2)签名过程:- 签名者使用私钥对要签名的数据进行加密(通常是通过对数据进行哈希运算生成摘要,然后对摘要进行加密)。
- 加密后的数据成为数字签名,附加在原始数据上。
(3)验证过程:- 接收者使用签名者的公钥解密数字签名,得到原始的哈希值。
- 接收者对接收到的原始数据进行相同的哈希运算,生成一个新的哈希值。
- 接收者将新的哈希值与解密得到的哈希值进行比较。如果两者一致,说明数据完整且未被篡改。
- 加密后的数据成为数字签名,附加在原始数据上。
- 签名者使用私钥对要签名的数据进行加密(通常是通过对数据进行哈希运算生成摘要,然后对摘要进行加密)。
-
作用和优势:
- 数据完整性:数字签名提供了一种验证数据是否被篡改的方法。如果数据在传输或存储过程中被修改,其签名验证将失败。
- 身份认证:数字签名使用私钥来生成签名,因此可以确保签名者的身份。接收者可以使用签名者的公钥来验证签名的真实性。
- 不可否认性:数字签名是由签名者生成的,他们不能否认对信息的签名行为,因为私钥只有签名者拥有。
- 保密性:数字签名不需要将私钥传输给其他人,只需要共享公钥。这样可以确保私钥的保密性,降低了密钥泄露的风险。
-
PKI(公钥基础设施):
PKI是数字签名的关键基础设施,用于管理和验证公钥的可信性。PKI由证书颁发机构(CA)负责,CA会颁发数字证书,包含公钥和相关身份信息,并对其进行签名。接收者可以使用CA的公钥验证证书的真实性,从
而信任其中的公钥。
- 应用领域:
- 电子商务:数字签名用于确保在线交易的安全性和完整性。
- 文件认证:数字签名可用于证明文件的来源和完整性,例如软件供应商的数字签名可以验证软件的真实性。
- 邮件安全:数字签名可以防止电子邮件被篡改,并提供发件人身份的认证。
- 身份验证:数字签名可以用于用户身份认证,例如通过数字签名登录系统。
总之,数字签名通过使用加密技术和非对称密钥对来提供数据完整性、身份认证和防止篡改的保证。它在许多领域中起着重要作用,确保信息安全和可靠性。
hash算法
在 Nginx 中,hash 模块是一种用于负载均衡的模块,它基于客户端 IP 地址或其他指定的变量进行哈希运算,并根据哈希值选择后端服务器进行请求转发。下面是对 Nginx hash 模块的详细介绍:
-
负载均衡原理:
负载均衡是将客户端的请求分发给多个后端服务器,以实现请求的平衡分配和增加系统的可靠性和性能。Nginx 提供了多种负载均衡算法,其中之一就是哈希算法。 -
Hash 算法:
Hash 算法是将输入数据通过哈希函数转换为固定长度的哈希值的过程。在 Nginx 中,hash 模块使用指定的变量(如客户端 IP 地址)作为输入,通过哈希运算生成一个哈希值。 -
哈希算法的作用:
哈希算法可以将不同的输入映射到固定范围的哈希值,从而实现请求的分发。对于相同的输入,哈希算法保证始终生成相同的哈希值,因此同一客户端的请求将始终被分发到相同的后端服务器上。 -
Nginx hash 模块的配置:
在 Nginx 的配置文件中,可以使用 hash 模块进行负载均衡的配置。例如:http {upstream backend {hash $remote_addr consistent;server backend1.example.com;server backend2.example.com;}server {listen 80;location / {proxy_pass http://backend;}} }上述配置中,使用
$remote_addr变量作为哈希的输入,consistent参数表示在添加或删除后端服务器时保持哈希的一致性。 -
哈希算法的优势和注意事项:
- 哈希算法能够将特定客户端的请求始终分发到相同的后端服务器,适用于需要维持会话的应用程序。
- 使用哈希算法进行负载均衡时,如果后端服务器的数量发生变化,部分请求可能会被分配到不同的后端服务器上,导致负载不均衡。
- 在使用哈希算法时,要注意选择适当的哈希变量,以确保均匀分配请求并避免哈希碰撞(多个输入映射到相同的哈希值)。
总之,Nginx 的 hash 模块提供了一种基于哈希算法的负载均衡机制,通过选择特定变量进行哈希运算,将客户端请求分发到后端服务器。这
种方式可以确保相同客户端的请求始终被转发到相同的后端服务器,适用于需要维持会话的应用场景。
对称加密
对称加密是一种加密算法,使用相同的密钥(也称为密钥或密码)进行加密和解密数据。它是加密领域中最常用的一种加密方法。下面是对称加密的详细介绍:
-
基本原理:
对称加密使用相同的密钥来加密和解密数据。发送方使用密钥将明文数据转换为加密数据,接收方使用相同的密钥将加密数据解密为原始明文数据。由于加密和解密使用相同的密钥,因此对称加密也被称为共享密钥加密。 -
密钥管理:
在对称加密中,密钥的管理非常重要。发送方和接收方必须在安全的方式下交换密钥,以确保只有授权的人可以访问加密数据。传统上,密钥可以通过安全的通道手动交换,但这种方法不够安全和可扩展。因此,通常使用密钥交换协议(如Diffie-Hellman密钥交换)来安全地生成和交换密钥。 -
加密算法:
对称加密使用不同的加密算法来执行加密和解密操作。一些常见的对称加密算法包括:- AES(Advanced Encryption Standard):目前最常用的对称加密算法之一,支持不同的密钥长度,包括128位、192位和256位。
- DES(Data Encryption Standard):是最早的对称加密算法之一,但因为密钥长度较短而不再推荐使用。
- 3DES(Triple DES):对DES进行了改进,使用多次DES算法执行加密,提高了安全性。
- Blowfish、RC4、RC5等:其他一些对称加密算法。
-
安全性和性能:
对称加密算法通常具有高加密和解密速度,并且在处理大量数据时表现出色。然而,对称加密的一个主要挑战是密钥管理和安全性。由于密钥需要在发送方和接收方之间共享,因此存在被中间人截取密钥的风险。此外,对称加密算法通常面临密钥分发和密钥轮换的挑战。 -
使用场景:
对称加密广泛应用于数据保护和信息安全领域,包括以下场景:- 保护敏感数据的存储和传输:对称加密可用于加密存储在本地计算机、服务器或数据库中的敏感数据,以及在网络上传输的数据。
- 安全通信:对称加密可用于保护网络通信中的数据传输,例如通过安全套接
层(SSL)或传输层安全(TLS)加密协议实现的加密通信。
- 文件和文件夹加密:对称加密可用于加密文件和文件夹,以保护其内容免受未经授权的访问。
总之,对称加密是一种使用相同密钥进行加密和解密的加密方法。它具有高性能和广泛应用的优点,但需要安全地管理密钥以确保数据的机密性和完整性。
非对称加密
非对称加密(Asymmetric Encryption)是一种加密算法,使用了一对密钥,包括公钥(Public Key)和私钥(Private Key)。与对称加密算法不同,非对称加密算法使用不同的密钥来进行加密和解密操作。
下面是非对称加密的详细介绍:
-
公钥和私钥:
非对称加密算法使用一对密钥,公钥和私钥。公钥是公开的,可以被任何人获取,用于加密数据。私钥是保密的,只有私钥的拥有者可以使用它进行解密操作。 -
加密过程:
在非对称加密中,发送者使用接收者的公钥来加密要发送的数据。发送者在使用公钥加密数据后,只有拥有相应私钥的接收者才能解密数据。这种方式确保了数据的机密性。 -
解密过程:
接收者使用其私钥来解密通过非对称加密算法加密的数据。私钥的保密性保证了只有接收者能够解密数据。 -
安全性:
非对称加密算法的安全性基于数学问题的难解性,如大素数的因式分解问题或离散对数问题。这些问题在当前计算能力下被认为是非常困难的。因此,即使公钥被泄露,私钥仍然能够保证数据的安全性。 -
数字签名:
非对称加密算法还可以用于生成和验证数字签名。发送者可以使用私钥对消息进行签名,接收者可以使用发送者的公钥来验证签名的有效性。这种方式可以确保数据的完整性和身份认证。 -
密钥交换:
非对称加密算法也可以用于密钥交换过程。在密钥交换中,双方可以使用对方的公钥来加密要传输的密钥,然后通过安全的通信渠道发送给对方。这样,双方可以通过使用自己的私钥解密对方的加密密钥,从而安全地交换密钥,用于后续的对称加密通信。 -
效率问题:
相比对称加密算法,非对称加密算法的计算复杂性较高,加密和解密操作耗时较长。因此,在实际应用中,通常使用非对称加密算法来解决密钥交换和数字签名等场景,而对实际数据的加密通常使用对称加密算法。
常见的非对称加密算法包括RSA(Rivest-Shamir-Adleman)、DSA(Digital Signature Algorithm)和ECC(Elliptic Curve Cryptography)等。
总结:
非对称加密算法通过使用一对密钥(公钥和私钥)来实现加密和解密操作,确保了数据的机密性、完整性和身份认证。它在密钥交换和数字签名等场景中发挥着重要作用,但由于计算复杂性较高,实际应用中通常与对称加密算法结合使用,以实现高效的加密通信。
数字签名
数字签名是一种用于确保数字信息完整性、认证身份和防止篡改的加密技术。它在信息安全领域中起着重要作用,特别是在数据传输和电子文档领域。下面是数字签名的详细介绍:
-
概述:
数字签名使用非对称加密算法,通过对信息进行加密和验证,确保信息的真实性和完整性。它结合了加密技术和公钥基础设施(PKI)来提供身份认证和数据完整性的保证。 -
工作原理:
(1)生成密钥对:首先,签名者生成一对密钥,包括私钥和公钥。私钥只有签名者自己知道,并且必须保密。公钥可以公开分享给其他人。
(2)签名过程:
- 签名者使用私钥对要签名的数据进行加密(通常是通过对数据进行哈希运算生成摘要,然后对摘要进行加密)。
- 加密后的数据成为数字签名,附加在原始数据上。
(3)验证过程:
- 接收者使用签名者的公钥解密数字签名,得到原始的哈希值。
- 接收者对接收到的原始数据进行相同的哈希运算,生成一个新的哈希值。
- 接收者将新的哈希值与解密得到的哈希值进行比较。如果两者一致,说明数据完整且未被篡改。 -
作用和优势:
- 数据完整性:数字签名提供了一种验证数据是否被篡改的方法。如果数据在传输或存储过程中被修改,其签名验证将失败。
- 身份认证:数字签名使用私钥来生成签名,因此可以确保签名者的身份。接收者可以使用签名者的公钥来验证签名的真实性。
- 不可否认性:数字签名是由签名者生成的,他们不能否认对信息的签名行为,因为私钥只有签名者拥有。
- 保密性:数字签名不需要将私钥传输给其他人,只需要共享公钥。这样可以确保私钥的保密性,降低了密钥泄露的风险。
-
PKI(公钥基础设施):
PKI是数字签名的关键基础设施,用于管理和验证公钥的可信性。PKI由证书颁发机构(CA)负责,CA会颁发数字证书,包含公钥和相关身份信息,并对其进行签名。接收者可以使用CA的公钥验证证书的真实性,从
而信任其中的公钥。
- 应用领域:
- 电子商务:数字签名用于确保在线交易的安全性和完整性。
- 文件认证:数字签名可用于证明文件的来源和完整性,例如软件供应商的数字签名可以验证软件的真实性。
- 邮件安全:数字签名可以防止电子邮件被篡改,并提供发件人身份的认证。
- 身份验证:数字签名可以用于用户身份认证,例如通过数字签名登录系统。
总之,数字签名通过使用加密技术和非对称密钥对来提供数据完整性、身份认证和防止篡改的保证。它在许多领域中起着重要作用,确保信息安全和可靠性。
webhook
Webhook是一种通过HTTP协议实现的回调机制,用于实现应用程序之间的实时数据传递和事件通知。通俗来讲,可以将Webhook看作是一个“电话号码”,当某个事件发生时,系统会拨打这个电话号码,将相关的信息传递给指定的接收方。
具体来说,Webhook的工作原理如下:
-
注册Webhook:首先,你需要在某个应用程序或服务中注册Webhook。这通常涉及提供一个URL,该URL由你提供,作为接收事件通知的终点。
-
事件发生:当注册的事件发生时,触发Webhook。例如,你可能在一个电子商务平台上注册了一个Webhook来接收订单创建事件。
-
发送HTTP请求:事件发生后,触发方会发送一个HTTP请求到你提供的URL,即Webhook的目标地址。这个HTTP请求中包含了事件相关的数据,如订单信息。
-
处理事件:一旦你的应用程序接收到Webhook的HTTP请求,你可以根据接收到的数据进行相应的处理。这可能包括处理订单、更新数据、发送通知等。
Webhook的优点是实时性和灵活性。相比轮询(通过定期发送请求来查询更新),Webhook是一种被动的方式,只有在事件发生时才会触发通知,节省了资源和网络带宽。同时,Webhook可以与各种应用程序和服务集成,使得数据传递和事件通知更加方便和可靠。
举个例子来说,假设你有一个博客网站,并希望在有新评论时收到通知。你可以通过设置一个评论事件的Webhook,将Webhook的目标地址设置为你自己的服务器或第三方服务。当有新评论时,博客平台会发送一个包含评论信息的HTTP请求到你提供的URL,你的服务器或第三方服务接收到请求后可以进行相应的处理,比如发送邮件通知你有新评论。这样你就能够实时了解到评论的情况,而无需手动去查询。
总的来说,Webhook提供了一种简单、高效的机制,用于实现实时数据传递和事件通知,使不同应用程序之间的集成更加方便和实用。
文章目录
- nginx
- 介绍
- 代理
- 集群
- 安装
- 配置文件
- http
- 使用
- master和worker
- 升级问题
- 基于域名的虚拟主机
- 隐藏nginx的版本信息
- 供别人下载的网站
- 统计的信息的页面
- pv介绍
- ngixn续
- nginx认证
- nginx的allow和deny
- nginx限制并发数
- nginx限速
- 限速的算法
- nginx 限制请求数
- nginx 的 location
- nginx 的 location
- nginx压力测试
- 健康检测
- 参数
- HTTP
- 是什么
- 报文结构
- 请求头部
- 响应头部
- 工作原理
- 用户点击一个URL链接后,浏览器和web服务器会执行什么
- http的版本
- 持久连接和非持久连接
- 无状态与有状态
- Cookie和Session
- http方法:
- get和post的区别
- 状态码
- HTTPS
- 是什么
- ssl
- 如何搞到证书
- nginx中的部署
- 加密
- CA
- 数字证书
- hash算法
- 对称加密
- 非对称加密
- 数字签名
- webhook
- IO多路复用
- 基础
- 文件句柄
- /proc文件:
- 内核
- uri和url
- url
- 介绍
- 方法
- select
- poll
- epoll
- 总结
- DNS
- 是什么以及作用
- 下载DNS服务
- named.conf
- DNS查询
- DNS缓存机制
- 解析过程
- 递归查询和迭代查询
- DNS服务器的类型
- DNS域名
- DNS服务器的类型
- 搭建dns服务器
- 缓存域名服务器
- 主域名服务器
- 从域名服务器
- 排错
- 反向解析
- CDN
- 介绍
- DNS转发
- 介绍
- 配置
- DNS劫持
- nginx 负载均衡
- 负载均衡策略(方法、算法)
- nginx配置
- round-robin
- 加权轮询
- least-connected
- ip-hasp
- 使用Https
- realip
- 后端real server不使用realip模块
- 后端
- real server使用realip模块
- ab压力测试
- 不同负载
- 四层负载
- 7层负载
- 4层和7层
- nfs
- 安装、使用
- nfs机器上的操作
- server机器
- 权限问题
- 开机自动挂载
- 相关的命令和文件
- rpc
- rpc和nfs
- san
- nfs和san区别
- 高可用
- 介绍
- keepalived
- 安装、使用
- vip漂移
- 抓包
- 脑裂
- 脑裂有没有危害?如果有危害对业务有什么影响?
- keepalived架构
- 双vip架构
- Healthcheck
- 实现
- notify
- VRRP
- 选举
- 格式
- 系统性能监控
- 相关命令
- lscpu
- top
- free
- htop
- dstat
- glances
- iftop
- iptraf
- nethogs
- 监控软件
- Prometheus
- 安装、使用
- 将promethues做成服务
- 监控其他机器
- exporter
- grafana
- 配置、使用
- 密码忘记重置
IO多路复用
基础
文件句柄
文件句柄(File Handle)是在操作系统中用于标识和管理文件或I/O设备的抽象概念。它是一个由操作系统分配的整数或指针,用于表示打开的文件或设备的引用。文件句柄充当了应用程序与实际文件或设备之间的桥梁,通过它应用程序可以对文件进行读取、写入和其他操作。
以下是文件句柄的一些详细介绍:
-
打开文件:当应用程序打开一个文件时,操作系统为该文件分配一个文件句柄。文件句柄可以通过系统调用(如open())返回给应用程序。打开文件时,操作系统会分配一些内部数据结构来管理该文件的状态和属性,并将文件句柄与这些数据结构相关联。
-
文件标识符:文件句柄通常以文件标识符(File Descriptor)的形式存在。在Unix-like系统中,文件句柄常用整数表示,称为文件描述符。文件描述符是一个非负整数,用于唯一标识打开的文件。标准输入(stdin)、标准输出(stdout)和标准错误(stderr)通常使用预定义的文件描述符(0、1和2)。
-
资源管理:文件句柄是操作系统进行文件资源管理的重要手段。通过文件句柄,操作系统可以跟踪和管理打开的文件的状态,包括文件的位置、权限、打开模式等。操作系统还使用文件句柄来实现文件的共享和保护机制,以及对文件进行并发访问的控制。
-
文件操作:应用程序使用文件句柄进行对文件的各种操作,如读取文件内容、写入数据、移动文件指针、修改文件属性等。通过提供文件句柄接口,操作系统屏蔽了底层文件系统的细节,使应用程序可以方便地进行文件操作,而无需直接处理底层文件系统。
-
设备访问:除了文件,文件句柄也可用于访问I/O设备,如串口、网络套接字等。应用程序可以使用文件句柄进行与设备的交互,发送和接收数据等操作。
-
关闭文件:当应用程序不再需要使用文件时,应该关闭文件句柄。关闭文件时,操作系统会释放与文件相关的资源,并将文件句柄回收。文件句柄的回收可以使操作系统能够更好地管理系统资源,避免资源泄漏。
总结:
文件句柄是操作系统中用于标识和管理文件或设备的抽象概念。它充当了应用程序与实际文件或设备之间的桥梁,通过它应用程序可以进行文件操作和设备访
/proc文件:
在Linux系统中,/proc文件系统是一种特殊的文件系统,它提供了对系统内核运行时状态的访问接口。
这个文件夹消耗的是内存的空间,重启系统,这个文件夹的内容会消耗。
因为proc文件系统消耗的是内存的空间,内存停电会丢失数据。
内核
内核(Kernel)是计算机操作系统中最核心的部分,它是操作系统的主要组成部分之一。内核负责管理计算机硬件和软件资源,提供基本的系统服务,以及执行和协调各种系统任务。以下是内核的一些主要功能和用途:
-
硬件管理:内核负责管理计算机硬件资源,包括处理器(CPU)、内存、设备驱动程序、输入输出设备(如硬盘、键盘、鼠标等)等。它为硬件提供抽象接口,使得应用程序可以通过内核访问和操作硬件资源。
-
进程管理:内核管理和调度系统中运行的进程(程序的执行实例)。它负责创建、销毁、调度和切换进程,分配和管理进程所需的资源,以及处理进程间的通信和同步。
-
内存管理:内核管理计算机的内存资源,包括分配、释放和保护内存空间,实现虚拟内存机制,将物理内存映射到进程的虚拟地址空间,以及处理内存的页面置换和回收。
-
文件系统管理:内核提供文件系统的支持和管理,包括文件的创建、读写、删除,目录的管理,文件的权限和访问控制,以及文件缓存等。
-
设备驱动程序管理:内核提供设备驱动程序的接口和管理,用于与硬件设备进行通信。它负责加载和卸载设备驱动程序,处理设备的输入和输出,以及提供统一的接口供应用程序访问设备。
-
系统调用:内核提供系统调用接口,使得应用程序可以请求内核执行特权操作或访问系统资源。系统调用是用户空间程序与内核之间的桥梁,应用程序通过系统调用接口向内核发出请求,内核根据请求执行相应的操作并返回结果。
-
网络和通信:内核管理计算机的网络和通信功能,包括网络协议栈的实现,网络连接的建立和管理,数据包的传输和路由,以及处理网络中的各种通信协议。
总之,内核是操作系统的核心,负责管理和控制计算机的硬件和软件资源,提供基本的系统服务和功能。它通过抽象和统一的接口,为应用程序提供了访问和操作系统功能的途径,保证系统的稳定性、安全性和性能。
uri和url
URI和URL是用于定位资源的两个相关概念,但它们有一些区别。下面是对它们的详细介绍:
URI(统一资源标识符)是一个用于标识唯一资源的字符串。它可以是一个文件、一个网页、一个数据库记录或任何其他可以通过网络访问的东西。URI的主要目的是为了唯一标识资源,并提供一种机制来定位这些资源。(nignx内部的资源的区别标识)
URL(统一资源定位器)是URI的一种常见形式。它是一种具体的URI,用于描述网络上的资源的位置。URL包含了访问资源所需的详细信息,包括协议类型(如HTTP、FTP等)、服务器地址(域名或IP地址)、端口号(可选)、路径和查询参数等。通过解析URL,可以确定如何访问和获取特定资源。(全球范围)
简而言之,URL是URI的子集。每个URL都是一个有效的URI,但并非每个URI都是URL。URL提供了更具体的位置信息,可以直接用于访问网络资源,而URI可能仅仅是标识资源的唯一名称。
以下是一个示例,说明URI和URL之间的区别:
URI: download.passwd.tar.gz
URL: https://www.yan.com/download.passwd.tar.gz
总结:
- URI是用于唯一标识资源的字符串。
- URL是一种特定形式的URI,提供了访问资源所需的详细信息。
- 每个URL都是有效的URI,但并非每个URI都是URL。
url
URL(统一资源定位符)是用于标识和定位互联网上资源的字符串。它是在Web浏览器中输入的网址的基础,告诉浏览器要访问的资源在哪里以及如何获取它。一个标准的URL由以下几个组成部分构成:
-
协议(Protocol):URL以协议开头,指示浏览器使用哪种协议来获取资源。常见的协议包括HTTP、HTTPS、FTP等。例如,http://、https://和ftp://。
-
域名(Domain Name):域名是资源所在的主机的名称。它可以是一个网站的名称,例如google.com,或者是一个IP地址,例如192.168.0.1。域名是用于定位服务器的重要部分。
-
端口(Port):端口号是服务器上正在监听的特定网络端口。它指定了服务器上的特定服务。例如,HTTP通常使用端口号80,HTTPS使用端口号443。如果未指定端口号,则使用协议的默认端口号。
-
路径(Path):路径指定了服务器上资源的具体位置。它可以是一个文件路径,也可以是一个目录路径。路径以斜杠(/)开头,可以包含多个级别的目录和文件名。
-
查询字符串(Query String):查询字符串包含在URL中的额外参数,用于向服务器发送附加的数据或参数。它以问号(?)开头,参数之间使用&符号分隔。查询字符串通常用于GET请求,以提供特定的搜索、过滤或排序条件。
-
锚点(Fragment):锚点标识了在页面内部的特定位置。它以井号(#)开头,后面跟着一个锚点标识符。浏览器在加载页面后,会滚动到该锚点所指示的位置。
下面是一个示例URL的结构:
http://www.example.com:8080/path/to/resource?param1=value1¶m2=value2#section1
在这个示例中:
- 协议是HTTP。
- 域名是www.example.com。
- 端口是8080。
- 路径是/path/to/resource。
- 查询字符串是param1=value1¶m2=value2。
- 锚点是section1。
URL的结构和组成部分可以根据具体的应用和需求而有所变化,但以上列出的组成部分是最常见和基本的部分。
介绍
IO 多路复用是一种同步 IO 模型,实现一个线程可以监视多个文件句柄。一旦某个文件句柄就绪,就能够通知应用程序进行相应的读写操作;没有文件句柄就绪时会阻塞应用程序,交出 cpu。IO 是指网络 IO,多路指多个TCP连接(即 socket 或者 channel),复用指复用一个或几个线程。
意思说一个或一组线程处理多个 TCP 连接。最大优势是减少系统开销小,不必创建过多的进程/线程,也不必维护这些进程/线程。IO 多路复用的三种实现方式:select、poll、epoll。
IO多路复用:解决了大并发连接的问题。
方法
select
在早期的版本中,Nginx使用了基于select函数的IO多路复用来处理并发连接。下面是对select实现方式的详细介绍以及其优缺点:
-
select函数简介:
select是一个系统调用,用于同时监听多个文件描述符(sockets)的状态变化,例如可读、可写或异常等事件。它是一种阻塞调用,即在没有任何事件发生时,它会一直等待,直到至少一个事件发生或超时。 -
select的工作原理:
- 程序创建一个
fd_set结构体,用于保存要监听的文件描述符集合。 - 使用
FD_ZERO宏将fd_set清零。 - 使用
FD_SET宏将需要监听的文件描述符添加到fd_set中。 - 调用
select函数,传入需要监听的最大文件描述符值加1,以及要监听的fd_set。 select函数会阻塞,直到文件描述符状态发生变化或超时。- 当文件描述符状态发生变化时,
select函数返回,可以通过FD_ISSET宏检查具体哪些文件描述符有事件发生。
- 程序创建一个
-
nginx中select的应用:
在Nginx的早期版本中,它使用了单个进程来处理并发连接。当有新的连接到来时,Nginx会将其添加到一个全局的文件描述符集合中,并使用select函数阻塞等待,直到有文件描述符上的事件发生,例如读取数据、写入数据或连接关闭等。然后,Nginx会遍历所有的文件描述符,检查哪些文件描述符有事件发生,并调用相应的处理函数来处理事件。 -
select的优点:
- 简单易用:select是一个标准的系统调用,使用起来相对简单。
- 跨平台:select在大多数操作系统中都得到支持,因此具有良好的跨平台性。
- 适用于连接数不太多的场景:当并发连接数较少时,select的性能表现还可以接受。
-
select的缺点:
- 遍历文件描述符集合:每次调用select函数后,Nginx需要遍历所有的文件描述符,以检查哪些文件描述符有事件发生,这会带来较大的性能开销。随着并发连接数的增加,遍历的时间会逐渐增加,影响Nginx的性能。
- 文件描述符数限制:select函数使用fd_set结构体来存储文件描述符集合,该结构体的大小是有限制的,通常在1024左右,这意味着在高并发的场景下,select的能力有限。
- 慢速系统调用问题:当使用select函数
由于select的性能限制和缺点,随着时间的推移,Nginx逐渐采用了更高效的IO多路复用模型,如基于epoll或kqueue的方式,以提高并发连接的处理能力和性能。
poll
在 Nginx 中,IO 多路复用是实现高性能和高并发的关键技术之一。Nginx 使用了多种 IO 多路复用机制,其中包括 poll。
poll 是一种基于事件驱动的 IO 多路复用模型。它通过一个系统调用来等待多个文件描述符(sockets)上的事件,并将就绪的事件通知给应用程序处理。下面是 poll 的实现方式的详细介绍以及其优缺点。
-
实现方式:
- 创建一个大小为
nfds的pollfd结构体数组,其中nfds是监视的文件描述符的数量。 - 通过循环遍历所有的文件描述符,为每个文件描述符设置感兴趣的事件类型(例如读、写、错误)。
- 使用
poll系统调用等待事件的发生。 - 当有事件就绪时,
poll返回,并将就绪的文件描述符和事件类型填充到pollfd结构体数组中。 - 应用程序可以根据事件类型执行相应的操作。
- 创建一个大小为
-
优点:
- 简单易用:
poll是相对简单的 IO 多路复用模型,对于开发者来说使用起来比较方便。 - 可移植性:
poll在大多数主流操作系统上都有良好的支持,因此具有较高的可移植性。 - 支持大量并发连接:
poll可以同时监视多个文件描述符,使得单个进程可以处理大量的并发连接。 - 没有最大连接数限制:相比于传统的同步阻塞模型,
poll没有固定的最大连接数限制,能够更好地应对高并发场景。
- 简单易用:
-
缺点:
- 性能下降:在大规模连接的情况下,
poll的性能可能会下降,因为每次调用poll都需要遍历整个pollfd结构体数组,无论就绪的文件描述符的数量是多少。 - 文件描述符复制:
poll需要将所有感兴趣的文件描述符复制到内核空间,这对于大量的文件描述符可能会导致性能损失。 - 不支持信号处理:
poll无法处理信号,因此在处理信号时需要使用其他的机制。
- 性能下降:在大规模连接的情况下,
需要注意的是,虽然 poll 在过去是一种常见的 IO 多路复用模型,但随着时间的推移,更高效的模型如 epoll 在现代操作系统中得到了广泛应用。在实际使用中,往往建议使用更高性能的模型来代替 poll,例如 Nginx 在 Linux 上使用的就
epoll
在 Nginx 中,IO 多路复用是通过使用 Linux 的 epoll 模块来实现的。Epoll 是一种事件通知机制,它使得服务器能够同时监视多个文件描述符(包括套接字)的状态,以确定是否有可读、可写或出错事件发生。
下面是 epoll 的工作方式:
-
创建 epoll 实例:使用
epoll_create函数创建一个 epoll 实例,它会返回一个文件描述符,用于后续的操作。 -
注册文件描述符:使用
epoll_ctl函数将需要监视的文件描述符注册到 epoll 实例中,指定感兴趣的事件类型,如可读事件、可写事件等。 -
等待事件:使用
epoll_wait函数等待事件的发生。该函数会阻塞直到有事件发生或超时。 -
处理事件:当
epoll_wait函数返回时,表示有事件发生。通过遍历返回的事件列表,可以获取到哪些文件描述符发生了感兴趣的事件。 -
处理事件的回调:根据事件的类型,执行相应的处理逻辑,如读取数据、写入数据等。
优点:
- 高效的事件通知机制:epoll 使用事件驱动的方式,只在发生事件时才通知服务器,相比于传统的轮询方式,减少了不必要的资源消耗。
- 支持大规模并发:通过使用 epoll,Nginx 能够处理大量的并发连接,提高系统的吞吐能力。
- 惊群效应的避免:epoll 采用了边缘触发模式(Edge Triggered),只在状态发生变化时通知,避免了传统水平触发模式(Level Triggered)中的惊群效应。
缺点:
- 对于连接数较少的情况,epoll 的性能优势不明显,甚至可能略逊于传统的轮询方式。
- 使用 epoll 需要依赖于特定的操作系统(如 Linux),因此不具有跨平台的特性。
总体而言,epoll 在高并发场景下表现出色,能够提供高效的事件驱动机制,适用于构建高性能的服务器应用。
总结
在 Nginx 中,IO 多路复用是一种关键的技术,用于实现高效的网络通信。它通过同时监视多个网络连接的状态,从而实现在单个线程中处理多个连接的能力。下面是三种常见的 IO 多路复用的实现方式以及它们的优缺点:
-
select:
- 优点:
- 跨平台支持,可在大多数操作系统上使用。
- 简单易用,对于小规模连接数和低并发的场景,使用 select 是一种合适的选择。
- 缺点:
- 时间复杂度为 O(n),随着连接数的增加,性能下降明显。
- 需要将全部的描述符集合从用户态拷贝到内核态,造成性能损耗。
- 优点:
-
poll:
- 优点:
- 跨平台支持,可在大多数操作系统上使用。
- 不需要像 select 一样限制描述符集合的大小。
- 缺点:
- 时间复杂度为 O(n),性能随着连接数的增加而下降。
- 需要将全部的描述符集合从用户态拷贝到内核态,造成性能损耗。
- 优点:
-
epoll:
- 优点:
- 仅在活跃的连接上进行操作,不受连接数的限制,具有更好的性能表现。
- 使用回调机制,减少了数据的拷贝次数,提高了性能。
- 支持边缘触发和水平触发两种模式,可以更灵活地适应不同的应用场景。
- 缺点:
- 仅在 Linux 系统上可用,不具备跨平台能力。
- 优点:
需要注意的是,Nginx 使用的是 epoll 实现方式,因为它在性能上具有明显的优势。但对于特定的应用场景和平台需求,select 和 poll 也可能是可行的选择。
文章目录
- nginx
- 介绍
- 代理
- 集群
- 安装
- 配置文件
- http
- 使用
- master和worker
- 升级问题
- 基于域名的虚拟主机
- 隐藏nginx的版本信息
- 供别人下载的网站
- 统计的信息的页面
- pv介绍
- ngixn续
- nginx认证
- nginx的allow和deny
- nginx限制并发数
- nginx限速
- 限速的算法
- nginx 限制请求数
- nginx 的 location
- nginx 的 location
- nginx压力测试
- 健康检测
- 参数
- HTTP
- 是什么
- 报文结构
- 请求头部
- 响应头部
- 工作原理
- 用户点击一个URL链接后,浏览器和web服务器会执行什么
- http的版本
- 持久连接和非持久连接
- 无状态与有状态
- Cookie和Session
- http方法:
- get和post的区别
- 状态码
- HTTPS
- 是什么
- ssl
- 如何搞到证书
- nginx中的部署
- 加密
- CA
- 数字证书
- hash算法
- 对称加密
- 非对称加密
- 数字签名
- webhook
- IO多路复用
- 基础
- 文件句柄
- /proc文件:
- 内核
- uri和url
- url
- 介绍
- 方法
- select
- poll
- epoll
- 总结
- DNS
- 是什么以及作用
- 下载DNS服务
- named.conf
- DNS查询
- DNS缓存机制
- 解析过程
- 递归查询和迭代查询
- DNS服务器的类型
- DNS域名
- DNS服务器的类型
- 搭建dns服务器
- 缓存域名服务器
- 主域名服务器
- 从域名服务器
- 排错
- 反向解析
- CDN
- 介绍
- DNS转发
- 介绍
- 配置
- DNS劫持
- nginx 负载均衡
- 负载均衡策略(方法、算法)
- nginx配置
- round-robin
- 加权轮询
- least-connected
- ip-hasp
- 使用Https
- realip
- 后端real server不使用realip模块
- 后端
- real server使用realip模块
- ab压力测试
- 不同负载
- 四层负载
- 7层负载
- 4层和7层
- nfs
- 安装、使用
- nfs机器上的操作
- server机器
- 权限问题
- 开机自动挂载
- 相关的命令和文件
- rpc
- rpc和nfs
- san
- nfs和san区别
- 高可用
- 介绍
- keepalived
- 安装、使用
- vip漂移
- 抓包
- 脑裂
- 脑裂有没有危害?如果有危害对业务有什么影响?
- keepalived架构
- 双vip架构
- Healthcheck
- 实现
- notify
- VRRP
- 选举
- 格式
- 系统性能监控
- 相关命令
- lscpu
- top
- free
- htop
- dstat
- glances
- iftop
- iptraf
- nethogs
- 监控软件
- Prometheus
- 安装、使用
- 将promethues做成服务
- 监控其他机器
- exporter
- grafana
- 配置、使用
- 密码忘记重置
DNS
是什么以及作用
DNS(Domain Name System)是一个用于将域名转换为 IP 地址的系统,它在互联网中起着重要的作用。通常,人们在浏览器中键入域名(例如www.baidu.com)来访问网站,而不是输入网站的 IP 地址。DNS 就是负责将这些域名解析为相应的 IP 地址的系统。
监听端口号:53,UDP协议
DNS 的主要功能包括:
-
域名解析(正向解析):最常见的用途是将人们易于记忆的域名(如www.baidu.com)解析为计算机网络上的 IP 地址(如14.215.177.39)。这种转换是必需的,因为互联网通信实际上是通过 IP 地址进行的,而不是域名。
-
负载均衡:DNS 还可以根据特定的策略将流量分发到多个服务器上。通过将一个域名映射到多个 IP 地址,DNS 可以将用户的请求分发到可用的服务器上,从而实现负载均衡,提高网站的性能和可靠性。
-
电子邮件路由:DNS 在电子邮件交换中起着关键作用。它负责查找目标电子邮件服务器的 IP 地址,以便将电子邮件正确地路由到目标服务器。
-
反向解析:除了将域名解析为 IP 地址外,DNS 还可以执行反向解析,即将 IP 地址转换为域名。这在网络安全和故障排除方面非常有用。
DNS 是分层的,由多个服务器组成。当您输入一个域名时,您的计算机首先向本地 DNS 服务器(通常由您的互联网服务提供商提供)发出查询请求。如果本地 DNS 服务器没有所需的信息,它会向其他更高层次的 DNS 服务器发出请求,直到找到能够提供所需信息的服务器为止。
总结来说,DNS 是互联网上用于将域名解析为 IP 地址的系统。它允许我们使用易于记忆的域名来访问网站,而无需记住复杂的 IP 地址。此外,DNS 还支持负载均衡、电子邮件路由和反向解析等功能,为互联网的正常运行提供了重要的基础设施。
hosts文件:只是给本机提供域名解析的服务,不能给其他人提供。
dns:可以给全球的人提供域名查询服务。
下载DNS服务
在Linux系统中,可以使用包管理器来下载和安装DNS服务。以下是几个常见的DNS服务软件和它们在不同的Linux发行版上的安装方法:
-
BIND (Berkeley Internet Name Domain):
-
在Ubuntu和其他基于Debian的系统上,可以使用以下命令安装BIND:
sudo apt-get update sudo apt-get install bind9 -
在CentOS和其他基于Red Hat的系统上,可以使用以下命令安装BIND:
sudo yum install bind*::
-
-
dnsmasq:
-
在Ubuntu和其他基于Debian的系统上,可以使用以下命令安装dnsmasq:
sudo apt-get update sudo apt-get install dnsmasq -
在CentOS和其他基于Red Hat的系统上,可以使用以下命令安装dnsmasq:
sudo yum install dnsmasq
-
-
Unbound:
-
在Ubuntu和其他基于Debian的系统上,可以使用以下命令安装Unbound:
sudo apt-get update sudo apt-get install unbound -
在CentOS和其他基于Red Hat的系统上,可以使用以下命令安装Unbound:
sudo yum install unbound
-
这些命令将会自动从软件仓库下载相应的DNS服务软件,并安装到系统中。安装完成后,你可以根据具体的需求对DNS服务进行配置,并启动相应的服务。
named.conf
[root@ydh conf]# cat /etc/named.conf
//
// named.conf
//
// Provided by Red Hat bind package to configure the ISC BIND named(8) DNS
// server as a caching only nameserver (as a localhost DNS resolver only).
//
// See /usr/share/doc/bind*/sample/ for example named configuration files.
//
// See the BIND Administrator's Reference Manual (ARM) for details about the
// configuration located in /usr/share/doc/bind-{version}/Bv9ARM.htmloptions {listen-on port 53 { any; };listen-on-v6 port 53 { any; };directory "/var/named";dump-file "/var/named/data/cache_dump.db";statistics-file "/var/named/data/named_stats.txt";memstatistics-file "/var/named/data/named_mem_stats.txt";recursing-file "/var/named/data/named.recursing";secroots-file "/var/named/data/named.secroots";allow-query { any; };recursion yes;dnssec-enable yes;dnssec-validation yes;/* Path to ISC DLV key */bindkeys-file "/etc/named.root.key";managed-keys-directory "/var/named/dynamic";pid-file "/run/named/named.pid";session-keyfile "/run/named/session.key";
};logging {channel default_debug {file "data/named.run";severity dynamic;};
};zone "." IN {type hint;file "named.ca";
};include "/etc/named.rfc1912.zones";
include "/etc/named.root.key";在Linux系统中,/etc/named.conf是BIND(Berkeley Internet Name Domain)服务的主要配置文件。BIND是一种常用的DNS(Domain Name System)软件,用于将域名转换为IP地址和执行其他DNS相关功能。
/etc/named.conf文件用于配置BIND服务器的行为和属性,其中包含了全局选项、区域定义、区域传送、日志记录等各个方面的配置信息。下面是一些/etc/named.conf文件中常见的配置项和其作用:
- options:
options部分包含了全局选项的配置,如BIND服务器的名称、监听的IP地址和端口、查询缓存设置、递归查询设置等。这些选项决定了BIND服务器的全局行为。 - zone:
zone部分用于定义DNS区域,即域名和IP地址之间的映射关系。每个zone定义包括了区域的名称、类型(如正向区域或反向区域)、文件路径、传输设置等。这些配置项指定了BIND服务器应该如何处理特定的域名区域。 - logging:
logging部分用于配置BIND服务器的日志记录设置。可以定义不同级别的日志信息,如信息、警告、错误等,并指定日志文件的位置和格式。 - include:
include指令用于包含其他配置文件,可以将配置分为多个文件进行管理,提高配置文件的可读性和维护性。
/etc/named.conf是BIND服务的主要配置文件,通过修改该文件可以自定义BIND服务器的行为和属性。管理员可以根据实际需求,对其中的配置项进行调整和定制,以满足特定的DNS服务需求。
DNS查询
本地DNS服务器在递归查询过程中可能会从根域名服务器开始,也可能直接向权威域名服务器发送查询请求。
DNS缓存机制
DNS缓存机制在浏览器、操作系统、路由器、ISP(Internet Service Provider)和递归DNS服务器中都起着重要的作用。下面是对每个部分的详细说明:
-
浏览器缓存:
浏览器会在本地缓存中存储最近访问的域名解析结果。当用户再次访问相同的域名时,浏览器首先检查本地缓存,如果存在相应的解析结果且未过期,则直接使用缓存结果,避免再次发送DNS查询请求。 -
操作系统缓存:
操作系统也会维护一个DNS缓存,存储最近的域名解析结果。这个缓存属于系统级别的缓存,被多个应用程序共享。当应用程序发起域名查询请求时,操作系统首先检查自己的缓存,如果有匹配的解析结果,会直接返回给应用程序,而无需进行网络查询。 -
路由器缓存:
一些路由器也会具有DNS缓存功能,以减少内部网络中的DNS查询次数。当设备连接到路由器并发起DNS查询请求时,路由器会检查自己的缓存,如果存在匹配的解析结果,则直接返回给设备,避免向上游DNS服务器发送查询请求。 -
ISP缓存:
ISP(Internet Service Provider,互联网服务提供商)通常会维护自己的DNS缓存。当用户通过ISP的网络连接访问域名时,ISP的DNS服务器会首先检查自己的缓存,如果有相应的解析结果,则直接返回给用户。这样可以减少对上层DNS服务器的查询,提高查询速度。 -
递归DNS服务器缓存:
递归DNS服务器是负责处理DNS解析请求的服务器。它们在处理请求过程中也会进行缓存。当递归DNS服务器接收到查询请求时,它会先检查自己的缓存,如果有匹配的解析结果,则直接返回给请求的客户端。如果缓存中没有,则递归DNS服务器会按照DNS解析过程中的步骤,向上层DNS服务器发送查询请求,并将获取的解析结果保存在缓存中,以备将来使用。
解析过程
追踪整个域名解析的过程。
[root@localhost named]# dig +trace www.baidu.com
DNS(Domain Name System)的解析过程涉及多个步骤和参与者,包括递归查询、缓存查询、迭代查询和权威服务器等。下面是一个详细的、全面的DNS解析过程的说明:
-
发起域名查询请求:
用户在浏览器或其他应用程序中输入一个域名(例如www.baidu.com),然后向本地DNS服务器发送查询请求。 -
本地DNS服务器缓存查询:
本地DNS服务器首先会检查自己的缓存,看是否存在该域名的解析结果。如果在缓存中找到了对应的解析结果,且该结果未过期(根据TTL时间确定),则本地DNS服务器将直接返回解析结果给客户端。 -
递归查询:
如果本地DNS服务器的缓存中没有对应的解析结果,它将执行递归查询。递归查询是指本地DNS服务器负责从根域名服务器开始,一直追踪查询过程,直到获得最终的解析结果。 -
根域名服务器查询:
本地DNS服务器向根域名服务器发送查询请求,询问根域名服务器关于顶级域名(例如.com)的权威域名服务器的IP地址。 -
顶级域名服务器查询:
根域名服务器返回给本地DNS服务器关于顶级域名的权威域名服务器的IP地址。本地DNS服务器接着向该权威域名服务器发送查询请求,询问次级域名(例如baidu.com)的权威域名服务器的IP地址。 -
权威域名服务器查询:
本地DNS服务器继续向次级域名的权威域名服务器发送查询请求,请求获取具体的域名解析结果。 -
解析结果返回:
权威域名服务器返回解析结果给本地DNS服务器。本地DNS服务器将结果保存在缓存中,并将解析结果返回给发起查询请求的客户端。 -
解析结果传递:
本地DNS服务器将解析结果传递给客户端,使客户端能够建立与所查询域名对应的IP地址的连接。 -
缓存更新:
本地DNS服务器将新获得的解析结果保存在缓存中,以便在下次有相同查询请求时可以直接返回结果,提高查询效率。
需要注意的是,DNS解析过程中存在着缓存机制,即在每个DNS服务器上都有一个缓存,用于存储最近的解析结果。缓存可以减轻DNS服务器的负载,加快域名解析速度,并提高整体的网络性能。
优化和变化,例如使用负载均衡的DNS服务器、DNS缓存的更新策略、DNS安全扩展(例如DNSSEC)等。但总体而言,以上步骤描述了DNS解析过程的主要流程和参与者。
递归查询和迭代查询
在DNS中,递归查询和迭代查询是两种不同的查询方式,用于解析域名并获取相应的IP地址。
- 递归查询(Recursive Query):
递归查询是指客户端向本地DNS服务器发送查询请求,并要求本地DNS服务器负责进行完整的解析过程。当本地DNS服务器接收到递归查询请求后,它会负责从根域名服务器开始一直追踪查询过程,直到获得最终的解析结果,并将结果返回给客户端。递归查询的过程中,本地DNS服务器会代表客户端与其他DNS服务器进行通信,获取所需的信息。
使用递归查询的优点是它能够提供完整的解析结果,客户端只需要发送一次查询请求,而无需自己去跟踪查询过程。递归查询适用于普通用户或客户端,因为它简化了查询的过程,让用户能够快速获取所需的IP地址。
- 迭代查询(Iterative Query):
迭代查询是指DNS服务器之间进行的一种查询方式,其中一个DNS服务器向另一个DNS服务器发送查询请求,并且期望得到一个具体的响应,而不是完整的解析结果。当接收到迭代查询请求的DNS服务器接收到请求后,它会返回自己所知道的信息,或者告诉请求的DNS服务器去询问其他DNS服务器。这个过程会一直重复,直到得到最终的解析结果。
使用迭代查询的优点是它更加灵活,DNS服务器之间可以相互交互并进行信息交换,以获得最终的解析结果。迭代查询适用于DNS服务器之间的通信和协作,例如当本地DNS服务器需要向其他DNS服务器查询域名解析结果时,就可以使用迭代查询。
总结:
- 递归查询用于客户端向本地DNS服务器查询,本地DNS服务器负责从根域名服务器开始追踪查询过程,直到获取最终的解析结果。
- 迭代查询用于DNS服务器之间的查询,一个DNS服务器向另一个DNS服务器发送查询请求,并且期望得到具体的响应,过程中可能需要多次交互。
在实际使用中,通常客户端使用递归查询方式向本地DNS服务器发送查询请求,而DNS服务器之间则使用迭代查询方式进行通信和协作,以完成域名解析的过程。
DNS服务器的类型
DNS服务器可以根据其角色和功能进一步分为缓存域名服务器、主域名服务器和从域名服务器。
-
缓存域名服务器:
缓存域名服务器是最常见的DNS服务器类型。它们负责缓存最近的域名解析结果,以提高查询性能和减轻上层DNS服务器的负载。当接收到查询请求时,缓存域名服务器首先检查自己的缓存,如果存在匹配的解析结果,则直接返回给请求者。如果缓存中没有相应的结果,它会向上层DNS服务器发送查询请求,并将获取的结果保存在缓存中供将来使用。 -
主域名服务器:
主域名服务器是负责管理特定域名的权威域名服务器之一。它存储了该域名的全部解析记录,包括IP地址、MX记录、CNAME记录等。主域名服务器是授权提供特定域名解析结果的服务器,在域名解析过程中,其他DNS服务器会向主域名服务器查询相关域名的解析信息。 -
从域名服务器:
从域名服务器也是权威域名服务器,它与主域名服务器同步,并存储了主域名服务器的副本。从域名服务器的主要作用是提供冗余和容错性,以确保即使主域名服务器不可用,仍能继续提供域名解析服务。从域名服务器定期与主域名服务器进行数据同步,以保持数据的一致性。
主域名服务器和从域名服务器一起构成了域名的权威域名服务器组。主域名服务器存储并管理域名解析信息的主要副本,而从域名服务器则保存主域名服务器的备份副本,以提供冗余和可靠性。
DNS域名
nslookup是一个查询域名的命令
ping、host、dig
windows里有一个域名查询的命令
ping和nslookup
[root@localhost ~]# nslookup
> set type=ns
> qq.com
Server: 192.168.2.1
Address: 192.168.2.1#53Non-authoritative answer:
qq.com nameserver = ns1.qq.com.
qq.com nameserver = ns2.qq.com.
qq.com nameserver = ns4.qq.com.
qq.com nameserver = ns3.qq.com.DNS服务器的类型
DNS系统中有不同类型的服务器,包括缓存域名服务器、主域名服务器和从域名服务器。下面对它们进行详细解释:
-
缓存域名服务器(也称为本地域名服务器或递归域名服务器):
缓存域名服务器是位于网络中的计算机或设备,它们负责接收来自客户端的DNS查询请求,并尝试解析域名。缓存服务器的主要目标是提供高效的域名解析,并尽可能减少对上层服务器的查询。它们通过在本地缓存中存储最近解析的域名和对应的IP地址,以便快速响应重复的查询请求。如果缓存服务器无法解析请求,它将向上层的主域名服务器发出查询请求。 -
主域名服务器(也称为权威域名服务器或域名服务器):
主域名服务器是负责管理特定域名的服务器。它们存储着特定域名下的DNS记录,例如A记录、CNAME记录、MX记录等。当缓存域名服务器向主域名服务器查询某个域名时,主域名服务器会提供该域名的DNS记录。主域名服务器通常由域名的所有者或管理员进行管理和配置,并确保域名的解析信息是最新的。 -
从域名服务器(也称为辅助域名服务器或镜像域名服务器):
从域名服务器是对主域名服务器进行备份和复制的服务器。它们存储着主域名服务器上的域名解析信息的副本。从域名服务器的主要作用是提高系统的冗余和可靠性。当主域名服务器不可用或负载过高时,从域名服务器可以接收和处理DNS查询请求,确保域名解析的可用性。从域名服务器会定期与主域名服务器同步更新,以确保数据的一致性。
综上所述,缓存域名服务器用于接收和缓存DNS查询请求,以提供快速的域名解析。主域名服务器存储特定域名的DNS记录,并提供域名解析的权威信息。从域名服务器是主域名服务器的备份,并提供冗余和可靠性。这些服务器协同工作,确保DNS系统的正常运行和高效性能。
搭建dns服务器
数据文件: 存放域名解析相关的数据的
[root@localhost named]# pwd
/var/named将SELinux和firewalld服务关闭。
[root@localhost ~]# getenforce
Disabled
[root@localhost ~]# service firewalld stop
1.下载
[root@localhost ~]# yum install bind*
bind-utils 提供了很多的dns域名查询的命令
[root@localhost ~]# rpm -qf /bin/nslookup
bind-utils-9.11.4-26.P2.el7_9.13.x86_64
[root@localhost ~]# rpm -qf /bin/dig
bind-utils-9.11.4-26.P2.el7_9.13.x86_642.设置named服务开机启动,并且立马启动DNS服务
[root@localhost ~]# service named start
Redirecting to /bin/systemctl start named.service[root@localhost ~]# systemctl start named.service[root@localhost ~]# systemctl enable named
Created symlink from /etc/systemd/system/multi-user.target.wants/named.service to /usr/lib/systemd/system/named.service.service named start:
这是一种旧的启动服务的方式,它将根据系统的/etc/init.d/目录中的脚本来启动名为named的服务。在这种情况下,它将执行/etc/init.d/named start命令来启动BIND服务。systemctl start named.service:
这个命令使用systemctl命令来启动名为named.service的服务。named.service是BIND服务的系统单位(unit),systemctl命令用于管理系统单位。启动服务后,BIND将开始运行并监听DNS请求。systemctl enable named:
这个命令使用systemctl命令将名为named的服务设置为在系统引导时自动启动。它创建了一个符号链接(symlink),将/usr/lib/systemd/system/named.service链接到/etc/systemd/system/multi-user.target.wants/named.service,从而确保在系统启动时启用BIND服务。
3.看进程和端口看服务是否已经启动了。
[root@localhost ~]# ps aux|grep named
named 42128 0.0 3.0 242032 57628 ? Ssl 16:42 0:00 /usr/sbin/named -u named -c /etc/named.conf
root 42390 0.0 0.0 112824 988 pts/1 S+ 16:46 0:00 grep --color=auto named
[root@localhost ~]# netstat -anplut|grep named
tcp 0 0 127.0.0.1:53 0.0.0.0:* LISTEN 42128/named
tcp 0 0 127.0.0.1:953 0.0.0.0:* LISTEN 42128/named
tcp6 0 0 ::1:53 :::* LISTEN 42128/named
tcp6 0 0 ::1:953 :::* LISTEN 42128/named
udp 0 0 127.0.0.1:53 0.0.0.0:* 42128/named
udp6 0 0 ::1:53 :::* 42128/named
修改本机的dns解析文件,增加我们自己的dns服务器地址
[root@localhost ~]# cat /etc/resolv.conf
# Generated by NetworkManager
#nameserver 192.168.2.1
#nameserver 2409:8950:40:a756:81cd:1b25:9622:fc3a
nameserver 127.0.0.1
/etc/resolv.conf 文件中的配置,系统当前使用的 DNS 解析服务器是本地回环地址 127.0.0.1。这意味着系统使用本机上运行的 DNS 解析服务进行域名解析。
测试查询
[root@localhost ~]# nslookup
> www.qq.com
Server: 127.0.0.1
Address: 127.0.0.1#53Non-authoritative answer:
www.qq.com canonical name = ins-r23tsuuf.ias.tencent-cloud.net.
Name: ins-r23tsuuf.ias.tencent-cloud.net
Address: 121.14.77.221
Name: ins-r23tsuuf.ias.tencent-cloud.net
Address: 121.14.77.201
Name: ins-r23tsuuf.ias.tencent-cloud.net
Address: 2402:4e00:1020:1404:0:9227:71ab:2b74
Name: ins-r23tsuuf.ias.tencent-cloud.net
Address: 2402:4e00:1020:1404:0:9227:71a3:83d2缓存域名服务器
两台机器实验():
修改/etc/named.conf文件
这样外来网也可以用该ip了。
options {listen-on port 53 { any; }; 修改 listen-on-v6 port 53 { any; }; 修改directory "/var/named";dump-file "/var/named/data/cache_dump.db";statistics-file "/var/named/data/named_stats.txt";memstatistics-file "/var/named/data/named_mem_stats.txt"; recursing-file "/var/named/data/named.recursing";secroots-file "/var/named/data/named.secroots";allow-query { any; }; 修改另外一台机器的设置如下:
进入/etc/sysconfig/network-scripts修改ifcfg-ens33 如下:
OTPROTO="none"
NAME="ens33"
DEVICE="ens33"
ONBOOT="yes"
IPADDR=192.168.2.25
PREFIX=24
GATEWAY=192.168.2.1
DNS1=192.168.2.24 #关键DNS服务器用于将域名转换为与之关联的IP地址。当你在浏览器中输入一个网址时,例如www.example.com,你的设备会向DNS服务器发送请求,以获取该域名对应的IP地址。在这种情况下,DNS1被设置为192.168.2.24,这是一个本地的DNS服务器地址。
[root@ydh-mysql network-scripts]# nslookup
> qq.com
Server: 192.168.2.24
Address: 192.168.2.24#53这样就表示设置成功了。
主域名服务器
主配置文件:/etc/named.conf
次要配置文件:/etc/named.rfc1912.zones
主进程名字:named
监听的端口:53 /tcp/udp
记录类型:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-X0K1MKPO-1689352566873)(C:\Users\asus\AppData\Roaming\Typora\typora-user-images\image-20230624193052653.png)]
1.在次要配置文件进行修改
在文件中添加
zone "ydh.com" IN {type master;file "ydh.com.zone";allow-update { none; };
};2.在/var/named目录下创建ydh.com.zone文件,可以直接复制named.localhost 同时重命名为ydh.com.zone。
[root@localhost named]# cp -a named.localhost ydh.com.zone
cp:是否覆盖"ydh.com.zone"? y
[root@localhost named]# ll
总用量 20
drwxr-x--- 7 root named 61 6月 24 16:39 chroot
drwxr-x--- 7 root named 61 6月 24 16:39 chroot_sdb
drwxrwx--- 2 named named 23 6月 24 16:42 data
drwxrwx--- 2 named named 60 6月 24 17:41 dynamic
drwxrwx--- 2 root named 6 4月 1 2020 dyndb-ldap
-rw-r----- 1 root named 2253 4月 5 2018 named.ca
-rw-r----- 1 root named 152 12月 15 2009 named.empty
-rw-r----- 1 root named 152 6月 21 2007 named.localhost
-rw-r----- 1 root named 168 12月 15 2009 named.loopback
drwxrwx--- 2 named named 6 1月 26 00:48 slaves
-rw-r----- 1 root named 152 6月 21 2007 ydh.com.zone-a:这是cp命令的一个选项,表示以递归方式复制文件,并保留源文件的属性(包括权限、所有者、组和时间戳等)。这是一步很重要,这保存了named有权限访问ydh.com.zone文件。
3.在ydh.com.zone文件进行修改
[root@localhost named]# cat ydh.com.zone
$TTL 1D
@ IN SOA @ rname.invalid. (0 ; serial 序列号 1D ; refresh 刷新1H ; retry 从服务器多长时间重新尝试去连接主服务器1W ; expire 从服务器的数据什么时候过去3H ) ; minimumNS @A 127.0.0.1AAAA ::1以上是原记录。
修改如下:
[root@localhost named]# cat ydh.com.zone
$TTL 1D
@ IN SOA @ rname.invalid. (0 ; serial1D ; refresh1H ; retry1W ; expire3H ) ; minimumNS @IN MX 10 mail.ydh.comA 192.168.1.24
www IN A 192.168.1.24 集群,轮询解析
www IN A 192.168.1.25
www IN A 192.168.1.26
www IN A 192.168.1.27main IN A 192.168.1.24
vue IN A 192.168.1.25
ftp IN A 192.168.1.120
xiaoming IN A 192.168.1.28
ming IN CNAME xiaoming 这是别名解析
* IN A 192.168.1.24 通配符解析(泛域名解析)在另外一台机器上进行测试:
[root@ydh-mysql ~]# nslookup www.ydh.com
Server: 192.168.2.24
Address: 192.168.2.24#53Name: www.ydh.com
Address: 192.168.2.26
Name: www.ydh.com
Address: 192.168.2.27
Name: www.ydh.com
Address: 192.168.2.24
Name: www.ydh.com[root@ydh-mysql ~]# nslookup xiaoming.ydh.com
Server: 192.168.2.24
Address: 192.168.2.24#53 #这里显示的ip地址是主域名服务器就可以了。Name: xiaoming.ydh.com
Address: 192.168.2.23表示这已经成功了。
从域名服务器
主域名服务器的配置
192.168.2.25 -->slave的ip
192.168.2.24 -->master的ip
vim /etc/named.rfc1912.zones
主域名服务器的配置
zone "test.com" IN {type master;file "test.com.zone";allow-transfer { 192.168.2.25; };
};从域名服务器的配置
zone "test.com" IN {type slave;file "slaves/test.com.zone";masters { 192.168.2.24; };
};在/etc/named/slaves下创建对应文件就可以了。
[root@web1 slaves]# ls
test.com.zone排错
1.权限问题
2.看日志:/var/log/messages
3.使用检查工具:检查配置文件和数据文件
检查数据文件是否有错误
[root@localhost named]# named-checkconf /etc/named.rfc1912.zones 检查配置文件
[root@localhost named]# named-checkzone ydh.com /var/named/ydh.com.zone
zone ydh.com/IN: loaded serial 0
OK查看日志:
[root@localhost named]# less /var/log/messages
反向解析
修改/etc/named.rfc1912.zones
zone "0.168.192.in-addr.arpa" IN {type master;file "192.168.0.zone";allow-update { none; };
};
创建数据文件:
[root@ydh namecp named.loopback 192.168.0.zone -a修改数据文件:
[root@ydh named]# cat 192.168.0.zone
$TTL 1D
@ IN SOA @ rname.invalid. (0 ; serial1D ; refresh1H ; retry1W ; expire3H ) ; minimumNS @A 192.168.0.24AAAA ::1PTR localhost.
24 IN PTR www.yan.com测试
[root@ydh named]# nslookup
> 192.168.0.24
24.0.168.192.in-addr.arpa name = www.yan.com.0.168.192.in-addr.arpa.ip能正确解析到域名就方面反向解析配置成功了。
CDN
介绍
CDN(内容分发网络)是一种通过分布在全球不同地点的服务器来提供高效内容交付的网络架构。它的目标是将内容(如网页、图片、视频等)快速传送给用户,提供更好的用户体验。
CDN的工作原理如下:
-
原始服务器:网站的内容首先存储在原始服务器上,这是内容的源头。
-
边缘服务器:CDN网络由多个位于全球各地的边缘服务器组成。这些服务器分布在离用户较近的位置,通常位于不同的城市或国家。
-
负载均衡和缓存:当用户发起请求访问网站时,CDN会通过负载均衡算法将请求路由到最接近用户的边缘服务器。边缘服务器上有缓存,它们会缓存原始服务器上的内容,包括静态文件、图片、视频等。如果用户请求的内容已经缓存在边缘服务器上,边缘服务器会立即将内容返回给用户,减少了请求的响应时间。
-
动态内容和就近访问:对于动态内容(如个性化页面或需要实时生成的数据),CDN会将请求转发到原始服务器,原始服务器根据请求生成相应的动态内容,并将其返回给边缘服务器进行缓存。下次同样的请求就可以直接从边缘服务器返回,减少了请求到原始服务器的次数。
通过使用CDN,网站可以获得以下好处:
-
加速内容交付:由于边缘服务器分布在全球各地,用户可以从离他们最近的服务器获取内容,减少了延迟和带宽使用,加快了内容的传输速度。
-
节省带宽成本:CDN网络可以分担原始服务器的流量负载,减少了对原始服务器的直接请求,从而降低了带宽成本。
-
提供高可用性:当原始服务器出现故障或不可用时,CDN可以自动将请求路由到其他可用的边缘服务器,保证了网站的可用性。
-
改善用户体验:由于内容更快地交付给用户,加载速度更快,网页响应更迅速,从而提供了更好的用户体验。
总之,CDN是一种通过分布在全球的边缘服务器提供内容的网络架构,它可以加速内容交付,降低带宽成本,并提供高可用性和良好的用户体验。
DNS转发
介绍
DNS转发是指将DNS查询请求从一个DNS服务器转发到另一个DNS服务器以获取查询结果的过程。通常情况下,DNS服务器会根据其配置和功能进行查询的处理,但在某些情况下,DNS服务器可能无法直接提供查询结果,或者需要从其他DNS服务器获取更准确的结果。这时,DNS转发就起到了关键的作用。
以下是DNS转发的详细介绍:
-
转发原理:
当DNS服务器接收到一个查询请求时,如果配置为启用转发功能,它会将查询请求发送给预定义的转发器(也称为上游服务器)。转发器是一个可信赖的、更高级别的DNS服务器,它负责处理查询请求并返回响应结果。 -
转发流程:
- 客户端向本地DNS服务器发送查询请求。
- 本地DNS服务器检查自身的缓存,如果找到匹配的结果,直接返回响应给客户端。
- 如果本地DNS服务器的缓存中没有查询结果,它会将查询请求发送给预配置的转发器。
- 转发器接收到查询请求后,会根据自身的配置和功能处理查询请求,可能会进行递归查询或向其他DNS服务器发送查询请求。
- 转发器获取查询结果后,将结果返回给本地DNS服务器。
- 本地DNS服务器将结果缓存,并将响应返回给客户端。
-
转发的优点:
- 提高查询性能:通过转发查询请求给更高级别的DNS服务器,可以利用其更大的资源和更广泛的缓存来提高查询性能和响应速度。
- 解决递归查询问题:某些网络环境中,DNS服务器可能无法进行递归查询,或者需要使用特定的DNS服务器来进行递归查询。通过转发查询请求,可以将递归查询任务交给配置好的转发器来完成。
- 过滤恶意请求:通过设置合适的转发器,可以对查询请求进行过滤和安全筛选,防止恶意请求或垃圾查询进入本地DNS服务器。
-
转发的配置:
在DNS服务器的配置中,通常需要指定转发器的IP地址或主机名。可以配置多个转发器,以实现冗余和负载均衡。同时,还可以设置转发超时时间和转发器的优先级,以进一步优化转发过程。
总结而言,DNS转发是一种将查询请求从一个DNS服务器转发到另一个DNS服务器的机制。它能提高查询性能、解决递归查询问题,并允许进行过滤和安全筛选。通过合理配置转发器,可以有效地管理和优化DNS查询过程。
配置
修改/etc/named.conf文件
options {listen-on port 53 { any; };listen-on-v6 port 53 { ::1; };directory "/var/named";dump-file "/var/named/data/cache_dump.db";statistics-file "/var/named/data/named_stats.txt";memstatistics-file "/var/named/data/named_mem_stats.txt";recursing-file "/var/named/data/named.recursing";secroots-file "/var/named/data/named.secroots";allow-query { any; };forward only;forwarders { 192.168.2.130; 114.114.114.114; };BIND的forward转发机制的这样的:
当设置了forwarders转发器后,所有非本域的和在缓存中无法找到的域名查询都将转发到设置的DNS转发器上,由这台DNS来完成解析工作并做缓存,因此这台转发器的缓存中记录了丰富的域名信息。因而对非本域的查询,很可能转发器就可以在缓存中找到答案,避免了再次向外部发送查询,减少了流量。
问题:
转发器没有给我们做解析
在本地dns服务器的配置文件里注释一条配置
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-HtvRpgGz-1689352566874)(C:\Users\asus\AppData\Roaming\Typora\typora-user-images\image-20230630200900358.png)]](https://img-blog.csdnimg.cn/e9b31bca2f8440938a93af603eca6f45.png)
在DNS配置中,使用 forward only 指令时,并不需要包含 include "/etc/named.root.key"; 这一行。这两者之间没有直接的关联。
include "/etc/named.root.key"; 是用于引入根域名服务器的密钥文件,用于验证从根域名服务器返回的数据的完整性和真实性。这与 DNS 转发的工作方式没有直接的依赖关系。
forward only 指令指示 DNS 服务器只使用配置的转发器(forwarders)进行域名解析,不会尝试其他解析方式。它独立于密钥文件的设置。
因此,如果你想要使用 forward only 指令进行 DNS 转发,你可以将 include "/etc/named.root.key"; 这一行注释掉,或者保持不包含在配置文件中,不会影响转发的功能。
DNS劫持
当你在浏览器中输入一个网址,比如"www.baidu.com",你的计算机会向域名系统(DNS)服务器发送请求,以获取该网址对应的IP地址。DNS劫持是一种恶意行为,它会干扰这个过程,将用户的DNS请求重定向到一个恶意的IP地址上,而不是正确的IP地址。
DNS劫持可以分为两种类型:本地DNS劫持和远程DNS劫持。
-
本地DNS劫持:
在本地DNS劫持中,恶意软件或黑客修改了用户计算机或本地网络上的DNS设置,以将用户的DNS请求重定向到错误的IP地址。这可以导致用户访问的网站被劫持或重定向到恶意网站,而用户可能不知情。 -
远程DNS劫持:
远程DNS劫持是通过攻击公共的DNS服务器或网络基础设施来实施的。黑客可以通过篡改或破坏DNS服务器的响应,将用户的DNS请求重定向到恶意IP地址上。这种类型的DNS劫持可以广泛地影响多个用户,甚至可能影响整个网络。
文章目录
- nginx
- 介绍
- 代理
- 集群
- 安装
- 配置文件
- http
- 使用
- master和worker
- 升级问题
- 基于域名的虚拟主机
- 隐藏nginx的版本信息
- 供别人下载的网站
- 统计的信息的页面
- pv介绍
- ngixn续
- nginx认证
- nginx的allow和deny
- nginx限制并发数
- nginx限速
- 限速的算法
- nginx 限制请求数
- nginx 的 location
- nginx 的 location
- nginx压力测试
- 健康检测
- 参数
- HTTP
- 是什么
- 报文结构
- 请求头部
- 响应头部
- 工作原理
- 用户点击一个URL链接后,浏览器和web服务器会执行什么
- http的版本
- 持久连接和非持久连接
- 无状态与有状态
- Cookie和Session
- http方法:
- get和post的区别
- 状态码
- HTTPS
- 是什么
- ssl
- 如何搞到证书
- nginx中的部署
- 加密
- CA
- 数字证书
- hash算法
- 对称加密
- 非对称加密
- 数字签名
- webhook
- IO多路复用
- 基础
- 文件句柄
- /proc文件:
- 内核
- uri和url
- url
- 介绍
- 方法
- select
- poll
- epoll
- 总结
- DNS
- 是什么以及作用
- 下载DNS服务
- named.conf
- DNS查询
- DNS缓存机制
- 解析过程
- 递归查询和迭代查询
- DNS服务器的类型
- DNS域名
- DNS服务器的类型
- 搭建dns服务器
- 缓存域名服务器
- 主域名服务器
- 从域名服务器
- 排错
- 反向解析
- CDN
- 介绍
- DNS转发
- 介绍
- 配置
- DNS劫持
- nginx 负载均衡
- 负载均衡策略(方法、算法)
- nginx配置
- round-robin
- 加权轮询
- least-connected
- ip-hasp
- 使用Https
- realip
- 后端real server不使用realip模块
- 后端
- real server使用realip模块
- ab压力测试
- 不同负载
- 四层负载
- 7层负载
- 4层和7层
- nfs
- 安装、使用
- nfs机器上的操作
- server机器
- 权限问题
- 开机自动挂载
- 相关的命令和文件
- rpc
- rpc和nfs
- san
- nfs和san区别
- 高可用
- 介绍
- keepalived
- 安装、使用
- vip漂移
- 抓包
- 脑裂
- 脑裂有没有危害?如果有危害对业务有什么影响?
- keepalived架构
- 双vip架构
- Healthcheck
- 实现
- notify
- VRRP
- 选举
- 格式
- 系统性能监控
- 相关命令
- lscpu
- top
- free
- htop
- dstat
- glances
- iftop
- iptraf
- nethogs
- 监控软件
- Prometheus
- 安装、使用
- 将promethues做成服务
- 监控其他机器
- exporter
- grafana
- 配置、使用
- 密码忘记重置
nginx 负载均衡

负载均衡(Load Balancing)是一种将工作负载(如网络请求、数据流量等)分配到多个服务器或计算资源上的技术。它的主要目的是确保资源的合理利用,提高系统的性能、可靠性和可扩展性。
在负载均衡中,有一个负载均衡器(Load Balancer)作为中间层,它接收来自客户端的请求,并将这些请求分发给后端的多个服务器,使每个服务器都能够处理一部分工作负载。负载均衡器通常基于一些算法和策略来决定如何分配请求,以实现负载均衡。
以下是负载均衡的一些关键特点和优势:
-
分布负载:负载均衡器可以将工作负载平均地分发到多个服务器上,以避免某个服务器过载而导致性能下降或服务不可用。
-
提高性能:通过将工作负载分散到多个服务器上,负载均衡器可以提高整体系统的处理能力和响应速度,提供更好的用户体验。
-
高可用性:当某个服务器发生故障或不可用时,负载均衡器可以自动将请求转发到其他正常的服务器上,保证服务的连续性和可靠性。
-
扩展性:通过添加更多的服务器来增加系统的处理能力,负载均衡器可以实现系统的水平扩展,适应不断增长的工作负载和用户需求。
-
健康检查:负载均衡器可以定期检查后端服务器的健康状态,如响应时间、负载情况等,以便动态地调整负载分配策略,避免将请求发送到不可用或故障的服务器上。
-
透明性:对于客户端来说,负载均衡器是一个单一的入口点,它隐藏了后端服务器的细节,使客户端无需知道实际处理请求的服务器是哪台。
负载均衡在许多场景中都有广泛应用,特别是在高流量的网络服务、Web应用程序、数据库集群、虚拟化环境等领域。通过合理配置和使用负载均衡技术,可以提高系统的可靠性、性能和可扩展性,实现更好的资源利用和服务质量。
负载均衡策略(方法、算法)
Nginx的负载均衡模块提供了多种策略来分发请求到后端服务器。以下是一些常见的负载均衡策略:
-
轮询(Round Robin):
这是最常用的负载均衡策略。Nginx按照事先定义的顺序依次将请求分发给后端服务器。每个请求依次轮询到不同的服务器,实现负载均衡。 -
IP Hash:
根据客户端的IP地址,将同一个客户端的请求始终分发给同一个后端服务器。这种方式可以保持会话的一致性,因为同一个客户端的请求总是被发送到同一个服务器上。 -
最少连接(Least Connections):
Nginx将请求发送到当前连接数最少的后端服务器上。这样可以确保将负载均衡到连接数较少的服务器上,从而实现动态负载均衡。 -
加权轮询(Weighted Round Robin):
对每个后端服务器分配一个权重,根据权重的比例将请求分发给后端服务器。具有较高权重的服务器将处理更多的请求。 -
加权最少连接(Weighted Least Connections):
类似于最少连接策略,但每个后端服务器的连接数还会乘以一个权重值。连接数较少且权重较高的服务器将优先处理请求。 -
URI哈希(URI Hash):
根据请求的URI对后端服务器进行哈希,将同一个URI的请求始终发送到同一个服务器上。这种方式可以保持特定URI的请求在同一个服务器上处理,适用于一些需要保持一致性的应用场景。
以上是一些常见的负载均衡策略,Nginx提供了灵活的配置选项,使得管理员可以根据具体需求选择合适的策略。可以通过Nginx的配置文件进行相应的调整和定制。
nginx配置
实验前提:
需要准备多台虚拟机:
其中一台作为负载均衡器。
其他的作为service服务器。
需要在/usr/loacl/ydhnginx/conf的http中添加。
round-robin
#定义一个负载均衡器upstream myweb{server 192.168.2.25;server 192.168.2.26;} server {listen 80;#charset koi8-r;#access_log logs/host.access.log main;location / {proxy_pass http://myweb;}加权轮询
#定义一个负载均衡器upstream myweb{server 192.168.2.25 weight=3;server 192.168.2.26;} server {listen 80;#charset koi8-r;#access_log logs/host.access.log main;location / {proxy_pass http://myweb;}least-connected
#定义上游服务器集群,定义一个负载均衡器upstream myweb1 {least_conn;server 192.168.2.25;server 192.168.2.26;server 192.168.2.27;}server {listen 80;location / {proxy_pass http://myweb;}}ip-hasp
#定义上游服务器集群,定义一个负载均衡器upstream myweb1 {ip_hash;server 192.168.2.25;server 192.168.2.26;server 192.168.2.27;}server {listen 80;location / {proxy_pass http://myweb;}}使用Https
在/usr/local/ydhnginx/conf/ngixn.conf的http中加上下面代码,同时nginx需要开通https的服务。
server {listen 443 ssl;server_name localhost;ssl_certificate **.pem;ssl_certificate_key **.key;ssl_session_cache shared:SSL:1m;ssl_session_timeout 5m;ssl_ciphers HIGH:!aNULL:!MD5;ssl_prefer_server_ciphers on;location / {proxy_pass http://myweb;# root html;# index index.html index.htm;}}realip
问题:
后端的real server不知道前端真正访问的ip地址,只是知道负载均衡的ip地址,如何让后端的real server知道前端真正的用户的ip地址?
后端real server不使用realip模块
- 在负载均衡器上修改http请求报文头部字段,添加一个X-Real-IP字段
在cong/nginx.conf的http里面加
server {listen 80;server_name www.sc.com;location / {proxy_pass http://myweb1;proxy_set_header X-Real-IP $remote_addr;}}将nginx内部的remote_addr这个变量的值,赋值给X-Real-IP这个变量,X-Real-IP这个变量会在http协议的请求报文里添加一个X-Real-IP的字段,后端的real server 服务器上的nginx就可以读取这个字段的值
X-Real-IP 这个变量名可以自己定义,随便取名,后面引用的时候,不区分大小写
- 在后端real server上使用这个x_real_ip这个字段
在主配置文件nginx.conf里的日志部分调用这个变量,获取x_real_ip的值
http {include mime.types;default_type application/octet-stream;log_format main '$remote_addr - $http_x_real_i - $remote_user [$time_local] "$request" ''$status $body_bytes_sent "$http_referer" ''"$http_user_agent" "$http_x_forwarded_for"';后端

可以看到通过访问负载均衡器访问的,也可以通过查看日志知晓源ip地址了。
注意:
需要server机器的配置干净,无其他代理,否则可能会失败。
real server使用realip模块
提前条件需要在后端的backend服务器上在编译安装nginx的时候,需要接 --with-http_realip_module 开启这个功能
- 在负载均衡器上修改http请求报文头部字段,添加一个X_REAL_IP字段
server {listen 80;server_name www.yan.com;location / {proxy_pass http://myweb;proxy_set_header X-Real-IP $remote_addr;}}将nginx内部的remote_addr这个变量的值,赋值给X-Real-IP这个变量,X-Real-IP这个变量会在http协议的请求报文里添加一个X-Real-IP的字段,后端的real server 服务器上的nginx就可以读取这个字段的值
X-Real-IP 这个变量名可以自己定义,随便取名,后面引用的时候,不区分大小写
- 在后端real server上使用set_real_ip_from 192.168.2.24
server{listen 80;set_real_ip_from 192.168.2.24;set_real_ip_from 192.168.2.24 告诉本机的nginx 192.168.2.24 是负载均衡器,不是真正的client
ab压力测试
需要先准备一台机器,用来测试的。不能用负载均衡器或者server服务器
负载均衡器的作用是在多台服务器之间平衡负载,将请求分配给可用的服务器。它可以帮助提高系统的可靠性和性能。如果你不能使用负载均衡器,可能意味着你需要测试的系统没有多台服务器,或者你不希望在测试期间使用负载均衡功能。
服务器通常用于托管和处理应用程序或服务。它们提供计算资源和网络连接,使应用程序能够在网络上访问。如果你不能使用服务器,可能是因为你无法获得或设置一台服务器,或者你的测试并不依赖于服务器特定的功能。
ab(ApacheBench)是一个常用的性能测试工具,用于对网站或 Web 服务器进行压力测试。在CentOS 7上安装ab工具非常简单。以下是在CentOS 7上安装和使用ab工具的详细步骤:
-
安装Apache的HTTP服务器软件包:
sudo yum install httpd -
安装ab工具:
sudo yum install httpd-tools这将安装包含ab工具的httpd-tools软件包。
-
验证ab工具是否成功安装:
ab -V运行该命令后,你应该能够看到ab工具的版本信息。
-
使用ab工具进行压力测试:
ab -n <请求数量> -c <并发数> <URL>-n:指定要发送的请求数量。-c:指定并发请求数量。<URL>:要测试的网址或服务器的URL。
例如,要发送100个请求并发测试一个网址,可以使用以下命令:
ab -n 100 -c 10 http://example.com/运行测试后,ab工具将输出关于测试结果的统计信息,包括请求数、失败数、传输速度、请求延迟等。
请注意,压力测试可能会对服务器和网络造成负载,因此在进行测试时应谨慎操作,并确保不会对生产环境造成过大的影响。
ab工具的结果分析主要关注以下几个关键指标:
请求数(Requests):总共发送的请求数量。
失败数(Failed requests):请求失败的数量,包括请求超时、连接重置等错误。
平均请求响应时间(Time per request):每个请求的平均响应时间,以毫秒为单位。
平均并发请求响应时间(Time per request: across all concurrent requests):所有并发请求的平均响应时间。
请求吞吐量(Requests per second):每秒处理的请求数量。较高的吞吐量表示服务器处理能力较强。
传输速度(Transfer rate):服务器响应的数据传输速率,通常以每秒传输的字节数来衡量。
请求延迟百分比(Percentage of the requests served within a certain time):表示在指定时间内处理的请求占总请求数的百分比。常见的百分比包括50%,90%,95%,99%等。
这些指标可以帮助你评估服务器的性能和稳定性。通常情况下,你希望请求数越高、失败数越低、平均响应时间和并发请求响应时间越短、吞吐量和传输速度越高,以及高百分比的请求在较短的时间内得到处理。
不同负载
四层负载
https://docs.nginx.com/nginx/admin-guide/load-balancer/tcp-udp-load-balancer/官方配置
前提:编译安装的时候需要接--with-stream是在nginx的ngx_stream_core_module模块中。
#user nobody;
worker_processes 1;#error_log logs/error.log;
#error_log logs/error.log notice;
#error_log logs/error.log info;#pid logs/nginx.pid;events {worker_connections 1024;
}
#4层的负载均衡
stream {#负载均衡器的定义webupstream scweb {server 192.168.2.25:80;server 192.168.2.26:80;}#负载均衡器的定义dnsupstream dns_servers {hash $remote_addr consistent;server 192.168.2.130:80;server 192.168.2.131:80;}
server {listen 80;proxy_pass scweb;}
}
注意:
网页在nginx不停止重启的时候,画面不会发生变化,我们可以通过查看server服务器的日志知道确实放生了访问。
7层负载
nginx默认使用7层负载
这是7层的nginx.conf配置文件。
[root@ydh conf]# cat nginx_bak.conf
user **;
worker_processes 2;#error_log logs/error.log;
error_log logs/error.log notice;
#error_log logs/error.log info;pid logs/nginx.pid;events {worker_connections 2048;
}
http {include mime.types;default_type application/octet-stream;log_format main '$remote_addr - $remote_user [$time_local] "$request" ''$status $body_bytes_sent "$http_referer" ''"$http_user_agent" "$http_x_forwarded_for"';access_log logs/access.log main;sendfile on;#tcp_nopush on;#keepalive_timeout 0;keepalive_timeout 65;autoindex on;server_tokens off;#gzip on;limit_conn_zone $binary_remote_addr zone=addr:10m;limit_req_zone $binary_remote_addr zone=one:10m rate=1r/s;server {listen 80;server_name www.yan.com;access_log logs/yan.com.access.log main;limit_rate 10k; #限制每秒10k的速度limit_rate_after 100k; #下载速度达到100k每秒的时候,进行限制location / {root html/yan;index shouye.html index.html index.htm;limit_req zone=one burst=5;}location /download/ {limit_conn addr 1;autoindex on;root html/yan;}error_page 404 /404.html;error_page 500 502 503 504 /50x.html;location = /50x.html {root html;}location = /info{stub_status; #返回nginx的状态的统计信息access_log off;auth_basic "ydh website";auth_basic_user_file htpasswd;allow 192.168.1.126;deny all;
}
}server {listen 80; server_name www.d.com;access_log logs/d.com.access.log main;location / { root html/d;index shouye.html index.html index.htm;} error_page 404 /404.html;error_page 500 502 503 504 /50x.html;location = /50x.html {root html;}
}server {listen 80; server_name www.hao.com;access_log logs/hao.com.access.log main;location / { root html/hao;index shouye.html index.html index.htm;} error_page 404 /404.html;error_page 500 502 503 504 /50x.html;location = /50x.html {root html;} location /download/ { root html/hao;} location ~/download/sc { root html/hao;} location ~* /DOWNLOAD/ { root html/hao;} location ^~/image//a.txt{root html/hao;}location /user/ {proxy_pass http://www.jd.com;}location = /user {proxy_pass http://www.taobao.com;
}
}# HTTPS serverserver {listen 443 ssl;server_name www.**.online;ssl_certificate **e.pem;ssl_certificate_key **.key;ssl_session_cache shared:SSL:1m;ssl_session_timeout 5m;ssl_ciphers HIGH:!aNULL:!MD5;ssl_prefer_server_ciphers on;location / {root html;index index.html index.htm;}}}
4层和7层
在NGINX中,4层负载均衡和7层负载均衡是两种不同的负载均衡方式,它们在处理网络流量和请求分发方面有一些关键的区别。
- 4层负载均衡(Transport Layer Load Balancing):
4层负载均衡是在传输层(Transport Layer)操作,主要基于IP地址和端口号来进行负载均衡。它在收到请求后,将请求转发到后端服务器,但并不理解或修改传输的数据。这种方式适用于处理传输层协议,如TCP和UDP。4层负载均衡不关心请求的内容,只关注网络连接的基本信息。
支持的服务:4层负载均衡适用于基于网络连接的服务,如数据库服务器、SMTP服务器、DNS服务器等。它可以根据IP地址和端口号将请求转发到后端服务器。
- 7层负载均衡(Application Layer Load Balancing):
7层负载均衡是在应用层(Application Layer)操作,对请求进行深入解析和处理。它不仅考虑了IP地址和端口号,还能理解请求的内容,例如HTTP请求头和报文体。通过分析请求的内容,7层负载均衡可以根据更多的信息来进行负载均衡决策,例如根据URL、请求头、会话信息等。
支持的服务:7层负载均衡适用于基于应用层协议的服务,如Web服务器(HTTP/HTTPS)、应用服务器(如Java应用服务器)、消息队列(如MQTT、AMQP)等。它可以根据请求的内容来智能地将请求分发给后端服务器。
总结:
4层负载均衡主要关注网络连接的基本信息,而7层负载均衡则对请求的内容进行深入解析和处理。4层负载均衡适用于基于网络连接的服务,而7层负载均衡适用于基于应用层协议的服务。选择使用哪种负载均衡方式取决于具体的应用场景和需求。
nfs
NFS,全称为Network File System,是一种网络文件系统协议,用于在计算机网络中实现文件共享。它允许在不同的操作系统之间共享文件和目录,使得在网络中的计算机可以像访问本地文件一样访问远程计算机上的文件。
NFS最初由Sun Microsystems开发,并在1984年首次发布。它是基于客户端-服务器模型的,其中一个计算机作为NFS服务器提供文件和目录的共享,而其他计算机则作为NFS客户端请求和访问这些共享资源。NFS支持在不同的操作系统之间进行文件共享,包括UNIX、Linux和Windows等。
NFS使用RPC(Remote Procedure Call)机制进行通信。客户端通过发送RPC请求来访问服务器上的文件,服务器则相应地提供文件访问和操作。NFS可以实现文件的读取、写入、修改、删除等基本操作,并支持文件和目录的访问控制。
NFS的工作原理如下:
- 客户端向服务器发送挂载请求,指定要访问的共享资源的位置。
- 服务器确认挂载请求,并将共享资源挂载到客户端的文件系统中,使其在客户端上可见。
- 客户端可以像访问本地文件一样访问挂载的共享资源,可以读取、写入、修改和删除文件。
- 客户端可以向服务器发送文件操作请求,服务器响应并执行相应的操作。
- 客户端可以卸载共享资源,从文件系统中移除它。
NFS具有以下特点和优势:
- 透明性:NFS使得远程文件访问对用户来说是透明的,就像访问本地文件一样,无需了解底层的网络细节。
- 共享性:NFS允许多个客户端同时访问共享资源,实现文件共享和协作工作。
- 可靠性:NFS提供了一些机制来确保文件访问的可靠性和完整性,如文件锁定和写入确认等。
- 性能:NFS在文件访问速度上具有较高的性能,可以通过一些优化技术进一步提高性能,如缓存和预读取等。
需要注意的是,NFS是一种基于网络的文件系统协议,它依赖于网络连接的稳定性和性能。在设计和配置NFS时,需要考虑网络带宽、延迟和安全等因素,以确保文件访问的效率和安全性。
安装、使用
nfs机器上的操作
安装
[root@abweb ~]# yum install nfs-utils -y
启动
[root@abweb ~]# service nfs restart
restart、stop、start
查看是否启动
[root@abweb web]# ps aux|grep nfs
nfs自己并没有去对外监听某个端口号,而是外包给了rpc服务,rpc帮助nfs去监听端口,然后告诉客户机和本机的那个进程对应的端口连续
查看rpc服务相关的端口
netstat -anplut|grep rpc
编辑共享文件的配置文件
[root@abweb ~]# vim /etc/exports
[root@abweb web]# cat /etc/exports
/web 192.168.2.0/24(ro,all_squash,sync)/web 是我们共享的文件夹的路径–》使用绝对路径
192.168.2.0/24 允许过来访问的客户机的ip地址网段
(rw,all_squash,sync) 表示权限的限制
rw 表示可读可写 read and write
ro 表示只能读 read-only
all_squash :任何客户机上的用户过来访问的时候,都把它认为是普通的用户
root_squash 当NFS客户端以root管理员访问时,映射为NFS服务器匿名用户
no_root_squash 当NFS客户端以root管理员访问时,映射为NFS服务器的root管理员
sync 同时将数据写入到内存与硬盘中,保证不丢失数据
async 优先将数据保存到内存,然后再写入硬盘,效率更高,但可能丢失数据
刷新输出文件的列表
exportfs -rv
建议关闭防火墙和selinux
service firewalld stop
systemctl disable firewalld
server机器
安装
[root@abweb ~]# yum install nfs-utils -y
启动
[root@abweb ~]# service nfs restart
挂载nfs服务器上的目录到本机上
[root@web1 html]# mount 192.168.2.27:/web /usr/local/ydhnginx/html/
[root@web1 html]# df192.168.2.27:/web 17811456 3744256 14067200 22% /usr/local/ydhnginx/html
挂载成功
重新进入/usr/local/ydhnginx/html就可以看到共享文件了
[root@web1 html]# ls
index.html y
权限问题
在NFS中,权限问题是指控制客户端对共享文件系统的访问权限的设置和管理。以下是有关NFS权限的详细解释:
-
导出选项(Export Options):在NFS服务器上,通过在
/etc/exports文件或其他类似配置文件中设置导出选项来定义共享目录的权限。常见的导出选项包括:rw:读写权限,允许客户端对共享目录进行读写操作。ro:只读权限,只允许客户端对共享目录进行读取操作。root_squash:启用root映射,将客户端以root权限的请求映射为匿名用户。这样可以限制root用户在共享目录中的权限,提高安全性。no_root_squash:禁用root映射,允许客户端以root权限访问共享目录。- 其他选项根据需要进行配置。
-
客户端访问权限(Client Access Permissions):NFS服务器上的导出选项可以指定允许访问共享目录的客户端地址或地址范围。通过配置正确的允许访问的客户端,可以限制哪些客户端可以访问共享目录,提高安全性。
-
客户端身份映射(Client Identity Mapping):在NFS服务器上,可以配置客户端身份映射,将客户端的身份映射为服务器上的对应用户或组。这对于确保在共享文件系统中正确应用文件和目录的权限非常重要。
-
客户端和服务器的用户和组标识(User and Group Identifiers):在NFS共享中,客户端和服务器之间需要保持用户和组标识的一致性。如果客户端和服务器上的用户和组标识不匹配,可能会导致权限问题。
-
权限同步(Permission Synchronization):当在NFS共享目录中进行更改时,需要确保权限的同步。这涉及到在客户端和服务器之间同步文件和目录的权限,以确保客户端对文件和目录的访问权限保持正确。
客户机上能否有写的权限要看2种权限:
1.共享权限 --》/etc/exports文件里的权限,例如ro,rw
2.文件系统里的权限 --》/web 在linux里的权限
会取权限较小的,例如有nfs机器有rw权限,server机器有ro权限,那么server机器只会有权限。
开机自动挂载
-
第一种方式
vim/etc/re.localmount 192.168.2.24:/web /usr/local/sczhengbo/html使用
rc.local需要给可执行权限chmod +x /etc/rc.d/rc.local -
第二种方式:修改
/etc/fstab,文件。/etc/fstab是linux系统开机会自动根据这个文件里的内容挂载磁盘分区192.168.2.24:/web /usr/local/sczhengbo99/html nfs defaults 0 0
192.168.2.24:/web 挂载的分区–》nfs的文件系统
/usr/local/sczhengbo/html 在本地的挂载点nfs 文件系统的类型
defaults 挂载的选项,使用默认
0 是否支持dump命令进行备份
0 是否开机的时候进行分区的文件系统的检查,分区的文件系统是否有问题
相关的命令和文件
- mount:是一个用于挂载文件系统的命令
- showmount:是一个用于显示NFS服务器上已经导出(共享)的目录列表的命令
- exportfs -rv:一个用于重新导出(刷新)NFS共享的命令
- /etc/exports:是一个位于Linux系统中的配置文件,用于定义NFS共享的配置信息。
- umount:是一个用于卸载(取消挂载)文件系统的命令
rpc
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-u4SiUSBh-1689353071975)(C:\Users\asus\AppData\Roaming\Typora\typora-user-images\image-20230704192247879.png)]](https://img-blog.csdnimg.cn/ab930594055d498ca1afe977d31f05e3.png)
RPC(Remote Procedure Call)是一种用于实现分布式系统中进程间通信的机制。它允许一个应用程序在一台计算机上调用另一台计算机上的远程过程(也称为远程函数、远程方法)并获取执行结果,就像调用本地过程一样。
以下是RPC的详细介绍:
-
基本原理:RPC基于客户端-服务器模型。客户端应用程序通过RPC机制发起远程过程调用,请求服务器上的特定过程执行。请求通常包括过程名称和参数。服务器接收到RPC请求后,执行相应的过程,并将结果返回给客户端。
-
抽象透明性:RPC提供了一种抽象透明的编程模型,使得客户端调用远程过程时无需关心底层网络细节和通信协议。客户端和服务器之间的通信对于应用程序来说是透明的,就像调用本地过程一样,使得分布式系统的开发更加方便。
-
过程映射:RPC需要将远程过程映射到具体的网络地址和端口,以便客户端可以正确地发起请求。这个映射通常是通过在客户端和服务器之间定义一个接口描述语言(IDL)来实现的。IDL定义了可供调用的过程、参数和数据类型,并提供了接口规范。通过IDL,客户端和服务器可以在语义上一致地定义和理解远程过程。
-
通信协议:RPC使用不同的通信协议来实现远程过程调用。常见的RPC协议包括:
- ONC RPC(Open Network Computing Remote Procedure Call):也称为Sun RPC,是早期RPC协议的一种实现,广泛用于UNIX和Linux系统。
- gRPC:由Google开发的高性能RPC框架,基于HTTP/2协议,支持多种编程语言和平台。
- JSON-RPC:基于JSON(JavaScript Object Notation)格式的RPC协议,通过HTTP或其他传输协议进行通信。
- XML-RPC:基于XML(Extensible Markup Language)格式的RPC协议,通过HTTP或其他传输协议进行通信。
-
序列化和反序列化:RPC需要将传输的数据在客户端和服务器之间进行序列化和反序列化,以便在网络上传输。序列化将数据对象转换为字节流,以便传输;反序列化将字节流还原为数据对象。序列化和反序列化的过程在RPC中是透明的,由RPC框架自动处理。
-
错误处理:RPC框架通常提供错误处理机制,用于处理在远程过程调用过程中可能出现的
错误。这包括网络故障、超时、服务不可用等情况。RPC可以定义错误码、异常处理和重试机制,以便客户端能够适当地处理错误情况。
RPC在分布式系统中广泛应用,例如在微服务架构中用于服务间的通信,远程API调用等场景。它简化了分布式系统的开发和集成,提供了一种方便、高效的方式来实现进程间的通信和协作。
rpc和nfs
NFS(Network File System)和RPC(Remote Procedure Call)之间存在紧密的关系。RPC是NFS协议所依赖的通信机制,用于在客户端和服务器之间进行远程过程调用。
以下是NFS和RPC之间的详细关系:
-
NFS协议基于RPC:NFS协议使用RPC作为通信机制。RPC是一种用于实现分布式系统中进程间通信的机制,它允许客户端应用程序调用位于远程服务器上的服务,并获取服务的响应。NFS客户端和服务器之间的交互通过RPC进行。
-
RPC实现远程过程调用:RPC允许NFS客户端在本地发起远程过程调用,请求服务器执行相应的操作。客户端应用程序可以像调用本地过程一样调用远程服务器上的过程。通过RPC,客户端可以向NFS服务器发送文件操作请求,如读取、写入、创建和删除文件等。
-
RPC通信过程:当NFS客户端发起远程过程调用时,它会向服务器发送一个RPC请求。该请求包括要调用的过程名称和相应的参数。服务器接收到RPC请求后,执行相应的操作,并将结果发送回客户端作为RPC响应。客户端接收到响应后,可以继续执行后续操作。
-
RPC协议栈:RPC通信涉及到多个协议层次的交互。在NFS中,RPC协议栈通常基于TCP/IP协议栈进行通信。RPC在应用层上提供了一个透明的接口,使得客户端和服务器之间的通信对于应用程序来说是透明的,无需关心底层网络细节。
总结来说,NFS和RPC密切相关,RPC提供了NFS客户端和服务器之间的远程过程调用和通信机制。NFS客户端通过RPC发送请求到NFS服务器,并获取服务器的响应,实现了在网络中共享和访问文件的功能。RPC允许NFS客户端和服务器之间的透明通信,使得对于应用程序来说,远程过程调用的细节被抽象和隐藏,简化了分布式文件系统的使用。
san
存储区域网络(Storage Area Network,简称SAN)采用网状通道(Fibre Channel ,简称FC,区别与Fiber Channel光纤通道)技术,通过FC交换机连接存储阵列和服务器主机,建立专用于数据存储的区域网络。
设备:
- 专业的存储服务器(有很大块磁盘,从容量非常大)
- 专业的光纤交换机
- 专业服务器:例如web服务器或者数据库服务器等,业务服务器通过HBA卡设备与光纤交换机
需要大量的资金投入:效果好,传输速度块。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-7AC5xj7n-1689353071976)(C:\Users\asus\AppData\Roaming\Typora\typora-user-images\image-20230704181104578.png)]](https://img-blog.csdnimg.cn/0813cfbe05534db6b14719b118b7f264.png)
nfs和san区别
NFS(Network File System)和SAN(Storage Area Network)是两种不同的技术用于实现存储和数据共享的方式。它们之间存在以下区别:
-
架构和定位:
- NFS是一种基于网络的文件系统协议,用于在计算机网络中实现文件共享。它允许不同操作系统之间通过网络访问和共享文件。
- SAN是一种独立的存储网络架构,用于连接存储设备和计算机系统。它提供高性能的块级存储访问,允许计算机直接访问存储设备。
-
访问方式:
- NFS提供文件级别的访问,通过共享文件和目录实现远程访问。客户端通过NFS协议访问远程服务器上的文件,像访问本地文件一样进行读取和写入。
- SAN提供块级别的访问,将存储设备的磁盘块作为逻辑单元进行访问。计算机系统通过SAN连接到存储设备,并可以直接访问和管理存储设备的磁盘块。
-
数据传输:
- NFS使用TCP/IP协议进行数据传输,通过网络传输文件内容。它在网络上传输文件数据,并依赖于网络的带宽和延迟。
- SAN使用专用的高速网络(如光纤通道或以太网)进行数据传输。它提供低延迟、高带宽的数据传输通道,适用于需要高性能存储访问的场景。
-
存储管理:
- NFS服务器通常是文件服务器,负责管理共享的文件和目录。它提供访问控制、文件锁定和权限管理等功能。
- SAN提供集中式存储管理,可以将多个存储设备汇集到一个逻辑池中,实现统一管理和配置。它提供高可用性、冗余和数据保护等功能。
-
应用场景:
- NFS适用于需要在不同操作系统之间共享文件的场景,如文件共享、协作和远程访问等。它在大多数UNIX、Linux和Windows系统上都有广泛的支持。
- SAN适用于需要高性能、低延迟的块级存储访问场景,如数据库、虚拟化和大规模数据存储等。它通常用于企业级应用和数据中心环境。
综上所述,NFS和SAN是两种不同的存储和数据共享技术。NFS主要用于文件级别的共享和访问,适用于跨平台的文件共享场景;SAN主要提供块级别的
存储访问,适用于需要高性能存储访问的应用。选择适合的技术应根据具体需求和应用场景进行评估和决策。
注意:
老的数据一致性解决方案:
- nfs
- san
新的解决方案:
使用云存储
- 金山与
- 亚马逊
- 谷歌云
- 阿里云
- 七牛云
- 腾讯云
文章目录
- nginx
- 介绍
- 代理
- 集群
- 安装
- 配置文件
- http
- 使用
- master和worker
- 升级问题
- 基于域名的虚拟主机
- 隐藏nginx的版本信息
- 供别人下载的网站
- 统计的信息的页面
- pv介绍
- ngixn续
- nginx认证
- nginx的allow和deny
- nginx限制并发数
- nginx限速
- 限速的算法
- nginx 限制请求数
- nginx 的 location
- nginx 的 location
- nginx压力测试
- 健康检测
- 参数
- HTTP
- 是什么
- 报文结构
- 请求头部
- 响应头部
- 工作原理
- 用户点击一个URL链接后,浏览器和web服务器会执行什么
- http的版本
- 持久连接和非持久连接
- 无状态与有状态
- Cookie和Session
- http方法:
- get和post的区别
- 状态码
- HTTPS
- 是什么
- ssl
- 如何搞到证书
- nginx中的部署
- 加密
- CA
- 数字证书
- hash算法
- 对称加密
- 非对称加密
- 数字签名
- webhook
- IO多路复用
- 基础
- 文件句柄
- /proc文件:
- 内核
- uri和url
- url
- 介绍
- 方法
- select
- poll
- epoll
- 总结
- DNS
- 是什么以及作用
- 下载DNS服务
- named.conf
- DNS查询
- DNS缓存机制
- 解析过程
- 递归查询和迭代查询
- DNS服务器的类型
- DNS域名
- DNS服务器的类型
- 搭建dns服务器
- 缓存域名服务器
- 主域名服务器
- 从域名服务器
- 排错
- 反向解析
- CDN
- 介绍
- DNS转发
- 介绍
- 配置
- DNS劫持
- nginx 负载均衡
- 负载均衡策略(方法、算法)
- nginx配置
- round-robin
- 加权轮询
- least-connected
- ip-hasp
- 使用Https
- realip
- 后端real server不使用realip模块
- 后端
- real server使用realip模块
- ab压力测试
- 不同负载
- 四层负载
- 7层负载
- 4层和7层
- nfs
- 安装、使用
- nfs机器上的操作
- server机器
- 权限问题
- 开机自动挂载
- 相关的命令和文件
- rpc
- rpc和nfs
- san
- nfs和san区别
- 高可用
- 介绍
- keepalived
- 安装、使用
- vip漂移
- 抓包
- 脑裂
- 脑裂有没有危害?如果有危害对业务有什么影响?
- keepalived架构
- 双vip架构
- Healthcheck
- 实现
- notify
- VRRP
- 选举
- 格式
- 系统性能监控
- 相关命令
- lscpu
- top
- free
- htop
- dstat
- glances
- iftop
- iptraf
- nethogs
- 监控软件
- Prometheus
- 安装、使用
- 将promethues做成服务
- 监控其他机器
- exporter
- grafana
- 配置、使用
- 密码忘记重置
高可用
介绍
高可用性(High Availability)是指系统或服务能够在大部分时间内保持可用状态的能力。高可用性的设计目标是确保系统在面对硬件故障、软件错误、网络问题或其他意外情况时,能够持续提供服务而不中断或降低性能。
实现高可用性通常需要以下几个关键方面的考虑:
-
冗余:冗余是指在系统的各个层面引入备份组件或资源,以确保在某个组件或资源发生故障时,能够无缝切换到备份组件或资源上。例如,使用冗余服务器、存储设备、网络连接等。
-
负载均衡:负载均衡是指将系统的负载分散到多个节点或服务器上,以确保每个节点的负载相对均衡。这有助于避免单点故障,并提高整个系统的容量和性能。
-
故障检测与恢复:系统需要能够及时检测到故障并采取相应的恢复措施。这可能包括自动监测组件的健康状态、故障检测算法、自动故障转移或恢复机制等。
-
容错设计:容错设计是指在系统设计和实施中考虑到可能的故障情况,并采取相应的措施来减少或避免故障对系统可用性的影响。例如,使用错误检测和纠正机制、数据备份和恢复策略等。
-
持续监控:高可用系统需要进行实时监控和性能度量,以便及时发现问题并采取措施解决。这包括监测系统组件的状态、负载情况、响应时间等指标,并及时发出警报或自动触发恢复机制。
-
容量规划:合理的容量规划是确保系统能够应对不断增长的负载和需求的关键因素。通过预测和评估系统的负载情况,以及合理的扩展策略和资源配置,可以保证系统在高负载时仍然保持高可用性。
高可用性的实现需要在系统设计和实施的各个方面进行考虑,并综合利用冗余、负载均衡、故障检测与恢复、容错设计、持续监控和容量规划等策略和技术来保证系统的稳定性和可用性。
三个经典的HA软件:
- heartbeat
- keepalive
- HAproxy
keepalived
Keepalived是一个用于负载均衡和高可用性的开源软件,旨在为Linux系统和基于Linux的基础架构提供简单而强大的解决方案。它通过实现负载均衡和VRRP协议来提供高可用性。
下面是Keepalived的一些重要特性和功能的详细介绍:
-
负载均衡:Keepalived使用Linux Virtual Server (IPVS)内核模块提供第四层负载均衡。它可以将传入的请求分发到一组服务器(称为服务器池),以平衡负载和提高性能。Keepalived实现了一组健康检查器,以监测服务器的可用性,并根据服务器的健康状况调整请求的分发。
-
高可用性:Keepalived使用虚拟路由冗余协议(Virtual Router Redundancy Protocol,VRRP)来实现高可用性。VRRP允许多个路由器(或防火墙)组成一个虚拟路由器,共享一个虚拟IP地址。当主要路由器发生故障时,其他备份路由器可以接管虚拟IP地址,以确保网络的连通性和可用性。
-
VRRP有限状态机:Keepalived实现了一组钩子函数,用于VRRP有限状态机。这些钩子函数提供了低级别和高速的与VRRP协议交互的能力。通过钩子函数,Keepalived可以在不同的状态转换时执行自定义操作,以适应特定的网络环境和需求。
-
快速故障检测:为了提供快速的网络故障检测和切换,Keepalived实现了双向转发检测(Bidirectional Forwarding Detection,BFD)协议。BFD协议可以在网络路径上进行快速的故障检测,并提供提示给VRRP状态转换,以实现快速的主备切换。
-
灵活的配置:Keepalived提供了一个灵活的配置文件,允许管理员定义负载均衡、高可用性和监控的策略和行为。管理员可以配置负载均衡算法、健康检查的类型和参数、故障转移的设置等。
通过使用Keepalived,管理员可以轻松地配置和管理负载均衡和高可用性解决方案,提高系统的可用性和性能。Keepalived可以应用于各种场景,包括网站负载均衡、数据库集群、应用服务的高可用性等。
安装、使用
安装
[root@ydh ~]# yum install keepalived -y
修改配置文件/etc/keepalived/keepalived.conf
[root@ydh keepalived]# cat keepalived.conf
! Configuration File for keepalivedglobal_defs {notification_email {acassen@firewall.locfailover@firewall.locsysadmin@firewall.loc}notification_email_from Alexandre.Cassen@firewall.locsmtp_server 192.168.200.1smtp_connect_timeout 30router_id LVS_DEVELvrrp_skip_check_adv_addrvrrp_strictvrrp_garp_interval 0vrrp_gna_interval 0
}vrrp_instance VI_1 {state MASTERinterface ens33virtual_router_id 58priority 100advert_int 1authentication {auth_type PASSauth_pass 1111}virtual_ipaddress {192.168.2.188}
}
这是一个VRRP实例的配置示例,称为"VI_1"。下面对每个配置项进行详细解释:
state MASTER:指定当前路由器在VRRP组中的状态为"MASTER",即主路由器。这意味着该路由器将成为虚拟IP地址的所有者,并负责处理来自其他设备的数据包。
interface ens33:指定VRRP组使用的网络接口为"ens33"。这是与VRRP相关的物理接口或虚拟接口。
virtual_router_id 58:指定VRRP组的虚拟路由器ID为"58"。这个ID用于标识属于同一个VRRP组的路由器。
priority 100:设置当前路由器的优先级为"100"。优先级值越高,成为主路由器的机会就越大。
advert_int 1:设置VRRP Advertisement(通告)消息的发送间隔为"1"秒。这是路由器发送VRRP消息的频率,用于通知其他设备该路由器的存在和状态。
authentication:设置VRRP的认证信息,用于确保只有经过认证的路由器才能参与VRRP组。
auth_type PASS:指定认证类型为"PASS",表示使用密码进行认证。
auth_pass 1111:设置密码为"1111",用于进行认证。
- virtual_ipaddress:指定VRRP组的虚拟IP地址。在这个例子中,虚拟IP地址为"192.168.2.188"。这个IP地址将被路由器拥有,用于接收和处理来自其他设备的数据包。
通过以上配置,该VRRP实例将在"ens33"接口上创建一个VRRP组,使用虚拟路由器ID为"58",并将路由器配置为主路由器(MASTER)并拥有虚拟IP地址"192.168.2.188"。优先级为"100",发送VRRP通告消息的间隔为"1"秒,并使用密码"1111"进行认证。
启动
[root@ydh keepalived]# systemctl start keepalived查看是否启动
[root@ydh keepalived]# ps aux|grep keepalived
root 5164 0.0 0.0 123012 1404 ? Ss 21:18 0:00 /usr/sbin/keepalived -D
root 5165 0.0 0.1 133984 3404 ? S 21:18 0:00 /usr/sbin/keepalived -D
root 5166 0.0 0.1 138152 2964 ? S 21:18 0:00 /usr/sbin/keepalived -D
root 5183 0.0 0.0 112824 992 pts/0 S+ 21:18 0:00 grep --color=auto keepalived在Keepalived启动后,通常会有三个关键的进程在运行,它们的作用如下:
Keepalived进程(keepalived):这是Keepalived的主要进程,负责管理整个Keepalived的运行。它读取配置文件,启动和停止其他子进程,并处理来自其他进程的通信和控制信息。
VRRP子进程(vrrp):VRRP子进程是Keepalived的关键组件之一。它负责实现VRRP协议,与其他设备进行通信,并执行VRRP的状态转换和路由器间的选举过程。该进程监控主机的状态,包括主机的可用性和健康状况,并根据配置的规则决定主备路由器的切换。
路由检测子进程(checkers):路由检测子进程是Keepalived的另一个重要组件。它负责进行网络健康检查,以确定各个后端服务器的可用性。检测器可以使用各种协议,如ICMP、TCP、HTTP等,来监测后端服务器的状态。如果检测到服务器故障或不可用,它将通知VRRP子进程进行状态转换。
这三个进程之间相互协作,形成了Keepalived的完整功能。Keepalived进程负责协调和管理这些子进程的工作,确保VRRP协议的正确运行和故障切换的顺利进行。VRRP子进程负责实现VRRP协议,维护虚拟IP地址的所有权和主备状态的切换。路由检测子进程负责监测后端服务器的可用性,提供健康检查和故障检测的功能。
配置是否成功
[root@ydh keepalived]# ip add
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00inet 127.0.0.1/8 scope host lovalid_lft forever preferred_lft foreverinet6 ::1/128 scope host valid_lft forever preferred_lft forever
2: ens33: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP group default qlen 1000link/ether 00:0c:29:10:22:3d brd ff:ff:ff:ff:ff:ffinet 192.168.2.24/24 brd 192.168.2.255 scope global noprefixroute ens33valid_lft forever preferred_lft foreverinet 192.168.2.188/32 scope global ens33valid_lft forever preferred_lft foreverinet6 fe80::20c:29ff:fe10:223d/64 scope link valid_lft forever preferred_lft foreverinet 192.168.2.188/32 scope global ens33出现这个就显示成功了
vip漂移
VIP(Virtual IP)漂移是指在高可用性环境中,将虚拟IP地址(VIP)从一个节点(主节点)快速切换到另一个节点(备份节点)的过程。这种切换通常发生在主节点发生故障或无法提供服务时,为了确保服务的连续性和可用性。
VIP漂移的详细过程如下:
-
主节点失效检测:系统会监测主节点的状态,例如网络连通性、服务器运行状态等。一旦检测到主节点发生故障或无法提供服务,触发VIP漂移的条件将被满足。
-
触发漂移事件:一旦触发条件满足,系统会通知备份节点执行VIP漂移。这可以通过一种心跳检测机制、集群管理软件或网络设备的协作实现。
-
VIP切换:备份节点接收到漂移事件后,会接管虚拟IP地址。它会在自己的网络接口上添加VIP,并通过更新路由表或通知相关网络设备来确保数据包正确地传输到备份节点。
-
通告其他节点:一旦备份节点成功接管VIP,它会向其他节点发送通告,以便更新它们的路由表或配置,确保数据包正确地路由到新的VIP所在的节点。
-
服务恢复:一旦VIP成功漂移到备份节点,备份节点将开始处理来自客户端的请求,并提供服务。这样,故障期间的服务中断将被最小化,用户将继续获得可用的服务。
VIP漂移通常是在高可用性环境中使用的一种机制,例如负载均衡集群、高可用数据库集群等。它可以确保服务在主节点故障时能够快速地恢复到备份节点,从而保证了系统的连续性和可用性。
问题:
master挂了吗,vip漂移到backup服务器上,如果master好了,vip会漂移回master上吗?
在 Keepalived 中,默认情况下,一旦 VIP 漂移到备份服务器上,即使主服务器恢复正常,VIP 不会自动漂移回主服务器。这是为了避免频繁的 VIP 切换和可能的服务中断。
如果你希望在主服务器恢复后,VIP 能够自动漂移回主服务器上,你可以使用
track_script配置项。track_script允许你指定一个脚本,用于监测主服务器的可用性。当主服务器恢复时,脚本返回成功状态,Keepalived 将会触发 VIP 漂移回主服务器。以下是一个示例的 Keepalived 配置,演示了如何使用
track_script配置项来实现 VIP 漂移回主服务器:vrrp_instance VI_1 { state BACKUP interface eth0 virtual_router_id 58 priority 100 advert_int 1 authentication {auth_type PASSauth_pass 1111 } virtual_ipaddress {192.168.2.188 } track_script {script "/path/to/monitor_script.sh"fall 2rise 2weight -1 } }在上面的配置中,
/path/to/monitor_script.sh是一个自定义的脚本,用于监测主服务器的可用性。你需要编写一个脚本来检测主服务器是否已经恢复正常。脚本返回成功状态时,Keepalived 将会触发 VIP 漂移回主服务器。在脚本中,你可以使用各种方法和命令来检测主服务器的可用性,例如 ping 命令、HTTP 请求等。根据你的具体需求和环境,自定义脚本来实现主服务器的可用性监测。
需要注意的是,使用
track_script配置项需要在 Keepalived 配置中启用vrrp_strict选项。可以将vrrp_strict设置为 “on” 来启用严格模式。配置完成后,当主服务器恢复正常并
track_script返回成功状态时,Keepalived 将自动触发 VIP 漂移回主服务器。这样,主服务器将重新成为服务的主要提供者。
抓包
下载抓包工具
[root@ydh ~]# yum install tcpdump -y查看信息
[root@ydh ~]# tcpdump -i ens33 vrrp -vv
tcpdump: listening on ens33, link-type EN10MB (Ethernet), capture size 262144 bytes
10:50:02.296290 IP (tos 0xc0, ttl 255, id 7901, offset 0, flags [none], proto VRRP (112), length 40)192.168.2.24 > vrrp.mcast.net: vrrp 192.168.2.24 > vrrp.mcast.net: VRRPv2, Advertisement, vrid 58, prio 120, authtype simple, intvl 1s, length 20, addrs: 192.168.2.188 auth "1111^@^@^@^@"
10:50:03.303095 IP (tos 0xc0, ttl 255, id 7902, offset 0, flags [none], proto VRRP (112), length 40)192.168.2.24 > vrrp.mcast.net: vrrp 192.168.2.24 > vrrp.mcast.net: VRRPv2, Advertisement, vrid 58, prio 120, authtype simple, intvl 1s, length 20, addrs: 192.168.2.188 auth "1111^@^@^@^@"
10:50:04.306855 IP (tos 0xc0, ttl 255, id 7903, offset 0, flags [none], proto VRRP (112), length 40)192.168.2.24 > vrrp.mcast.net:
该命令是使用tcpdump工具进行网络数据包分析的命令。下面是对命令的解析:
tcpdump: 这是一个网络数据包分析工具,用于捕获和分析经过特定网络接口的数据包。-i ens33: 这是tcpdump命令的选项之一,指定要捕获数据包的网络接口。在这个例子中,它指定了接口ens33,也可以是其他网络接口的名称。vrrp: 这是tcpdump的过滤器之一,用于只捕获VRRP(Virtual Router Redundancy Protocol)数据包。VRRP是一种网络协议,用于提供冗余的默认网关功能。-vv: 这是tcpdump命令的选项之一,用于增加详细的输出。通过使用两个-v选项,可以显示更多关于捕获的数据包的信息。
脑裂
在分布式系统中,Keepalive(保活)机制用于检测节点或服务器的可用性,并确保节点之间的正常通信。通常,节点之间通过发送周期性的Keepalive消息来维持连接的活动状态。然而,Keepalive的脑裂(Keepalive Brain Split)是指在一些特定情况下,Keepalive机制无法有效地检测到节点或服务器的故障,导致节点之间的通信被中断,即使节点实际上已经失去了正常的连接。
脑裂可能在以下情况下发生:
-
vrid(虚拟路由id)不一样
-
网络通信有问题,中间有防火墙阻止了网络之间的选举的过程,vrrp报文的通信
-
认证密码不一样也会出现脑裂
脑裂可能导致数据一致性问题、服务中断以及系统的不稳定性。为了解决脑裂问题,通常采用以下策略:
-
心跳超时机制:合理设置心跳超时时间,确保故障节点能够及时被检测到,并进行相应的处理。
-
多重故障检测机制:使用多种独立的故障检测机制,例如基于网络层和应用层的检测,以提高故障检测的可靠性和准确性。
-
多数派决策机制:在集群中采用多数派决策机制来解决节点状态的冲突。通过确保大多数节点的一致性,可以避免脑裂问题。
综上所述,Keepalive的脑裂是指在Keepalive机制下,由于网络分区、故障检测问题或超时设置不当等原因,节点无法正确地检测到故障,导致节点之间的通信中断,从而产生的一种问题。
如何出现脑裂现象:
- 对防火墙进行设置:
[root@ydh ~]# iptables -I INPUT -p tcp --dport 22 -j ACCEPT
iptables: 这是一个用于管理Linux内核网络数据包过滤的工具,它可以用来配置和控制防火墙规则。
-I INPUT: 这是iptables命令的选项之一,表示在"INPUT"链(即入站数据包)中插入规则。
-p tcp: 这是iptables命令的选项之一,用于指定匹配的传输层协议。在这个例子中,它指定要匹配TCP协议的数据包。
--dport 22: 这是iptables命令的选项之一,用于指定目标端口。在这个例子中,它指定要匹配目标端口号为22的数据包。端口22通常用于SSH(Secure Shell)服务,用于远程登录和管理Linux系统。
-j ACCEPT: 这是iptables命令的选项之一,用于指定匹配规则后的动作。在这个例子中,它指定如果数据包与规则匹配,则接受该数据包。该命令的作用是在防火墙的"INPUT"链中插入一条规则,允许进入的TCP数据包,目标端口为22(即SSH服务)。这样配置后,防火墙将接受并允许通过22端口的SSH连接请求。
[root@ydh ~]# iptables -L
-L: 这是iptables命令的选项之一,用于列出当前的防火墙规则。它会显示"filter"表中的规则,这是iptables默认使用的表,用于过滤数据包。
[root@ydh ~]# iptables -P INPUT DROP
-P INPUT DROP: 这是iptables命令的选项之一,用于设置"INPUT"链(即入站数据包)的默认策略为"DROP"。"DROP"策略表示拒绝所有未明确允许的入站数据包,即默认情况下将丢弃这些数据包。
192.168.2.23
oup default qlen 1000link/ether 00:0c:29:03:b2:81 brd ff:ff:ff:ff:ff:ffinet 192.168.2.23/24 brd 192.168.2.255 scope global noprefixroute ens33valid_lft forever preferred_lft foreverinet 192.168.2.188/32 scope global ens33192.168.2.24
inet 192.168.2.24/24 brd 192.168.2.255 scope global noprefixroute ens33valid_lft forever preferred_lft foreverinet 192.168.2.188/32 scope global ens33firewalld恢复正常。
[root@ydh ~]# iptables -P INPUT ACCEPT
-P INPUT ACCEPT: 这是iptables命令的选项之一,用于设置"INPUT"链(即入站数据包)的默认策略为"ACCEPT"。"ACCEPT"策略表示接受所有未明确拒绝的入站数据包,即默认情况下允许这些数据包通过。
- 不同的虚拟路由id
192.168.2.23
这是keepalive.conf的设置
vrrp_instance VI_1 {state MASTERinterface ens33virtual_router_id 59oup default qlen 1000link/ether 00:0c:29:03:b2:81 brd ff:ff:ff:ff:ff:ffinet 192.168.2.23/24 brd 192.168.2.255 scope global noprefixroute ens33valid_lft forever preferred_lft foreverinet 192.168.2.188/32 scope global ens33192.168.2.24
这是keepalive.conf的设置
vrrp_instance VI_1 {state MASTERinterface ens33virtual_router_id 58 inet 192.168.2.24/24 brd 192.168.2.255 scope global noprefixroute ens33valid_lft forever preferred_lft foreverinet 192.168.2.188/32 scope global ens33- 认证密码不一样
192.168.2.24
keepalive.conf的设置
authentication {auth_type PASSauth_pass 111122} inet 192.168.2.24/24 brd 192.168.2.255 scope global noprefixroute ens33valid_lft forever preferred_lft forever
inet 192.168.2.188/32 scope global ens33
192.168.2.23
keepalive.conf的设置
authentication {auth_type PASSauth_pass 11112
}
oup default qlen 1000link/ether 00:0c:29:03:b2:81 brd ff:ff:ff:ff:ff:ffinet 192.168.2.23/24 brd 192.168.2.255 scope global noprefixroute ens33valid_lft forever preferred_lft foreverinet 192.168.2.188/32 scope global ens33
脑裂有没有危害?如果有危害对业务有什么影响?
没有危害,能正常访问,反而还有负载均衡的作用
脑裂恢复的时候,还是有影响的,会短暂的中断,影响业务的。
keepalived架构
Keepalived可以使用单VIP(Virtual IP)或双VIP架构来实现高可用性。
-
单VIP架构:
- 在单VIP架构中,只有一个虚拟IP地址(VIP)被配置,用于将客户端的请求导向到主节点。
- 主备节点通过Keepalived进行状态同步和心跳检测。主节点持有VIP,而备节点监视主节点的状态。
- 如果主节点发生故障或不可用,备节点将接管VIP,并开始提供服务,以确保服务的高可用性。
- 当主节点恢复时,它会重新获得VIP,并继续提供服务。
-
双VIP架构:
- 在双VIP架构中,有两个虚拟IP地址(VIP1和VIP2),分别用于主节点和备节点。
- 主VIP(VIP1)用于将客户端的请求导向到主节点,而备VIP(VIP2)用于将客户端的请求导向到备节点。
- 主备节点之间进行状态同步和心跳检测。主节点持有主VIP,备节点持有备VIP。
- 如果主节点发生故障或不可用,备节点将接管主VIP,并开始提供服务。备节点的备VIP保持不变。
- 当主节点恢复时,它会重新获得主VIP,并继续提供服务。备节点仍然持有备VIP,但不提供服务。
双VIP架构相对于单VIP架构提供了更高的冗余性和故障切换的灵活性。它允许同时在主备节点上提供服务,并且客户端可以选择性地连接到主节点或备节点,从而在故障发生时可以更快地切换到备节点。然而,双VIP架构也需要更多的IP地址和网络资源。
选择单VIP架构还是双VIP架构取决于具体的需求和应用场景。对于大多数常见的情况,单VIP架构已经足够实现高可用性和故障切换。双VIP架构通常用于更复杂的环境,需要更高级的灵活性和可扩展性。
双vip架构
192.168.2.24的配置文件代码
vrrp_instance VI_1 {state MASTERinterface ens33virtual_router_id 58priority 120advert_int 1authentication {auth_type PASSauth_pass 1111}virtual_ipaddress {192.168.2.188}
}vrrp_instance VI_2 {state BACKUPinterface ens33virtual_router_id 59priority 100 advert_int 1authentication {auth_type PASSauth_pass 1111} virtual_ipaddress {192.168.2.199}
}查看ip
[root@ydh ~]# ip addinet 192.168.2.24/24 brd 192.168.2.255 scope global noprefixroute ens33valid_lft forever preferred_lft foreverinet 192.168.2.188/32 scope global ens33valid_lft forever preferred_lft foreverinet6 fe80::20c:29ff:fe10:223d/64 scope link valid_lft forever preferred_lft forever
192.168.2.23的配置文件设置
vrrp_instance VI_1 {state BACKUPinterface ens33virtual_router_id 58priority 100advert_int 1authentication {auth_type PASSauth_pass 1111}virtual_ipaddress {192.168.2.188}
}
vrrp_instance VI_2 {state MASTERinterface ens33virtual_router_id 59priority 120 advert_int 1authentication {auth_type PASSauth_pass 1111} virtual_ipaddress {192.168.2.199}
}
查看ip
[root@ydh ~]# ip addinet 192.168.2.23/24 brd 192.168.2.255 scope global noprefixroute ens33valid_lft forever preferred_lft foreverinet 192.168.2.199/32 scope global ens33valid_lft forever preferred_lft foreverinet6 fe80::20c:29ff:fe03:b281/64 scope link valid_lft forever preferred_lft forever
Healthcheck
如果负载均衡器上的nginx出现了问题,keepalived还有没有价值?
keepalived的价值是建立在nginx能正常工作的情况下,如果nginx异常,这台机器就不是负载均衡器了,需要停止它的master身份了,将优先级降低,让为给其他的机器,背后有健康检测功能。
Keepalived的Healthcheck(健康检查)是一种用于监测服务器或服务状态的功能。在Keepalived中,Healthcheck用于定期检查服务器的可用性,以确保主备节点的状态以及它们提供的服务的正常运行。
健康检查的目的是在故障或服务不可用时及时检测并采取相应的措施,比如切换到备用节点,以保持服务的高可用性。Healthcheck的工作方式是定期发送请求或监测服务器状态,然后根据响应结果来判断服务器是否处于健康状态。通常,主备节点会相互监测对方的健康状态,以便在发现故障时自动进行故障转移。
在Keepalived中,可以配置多种类型的Healthcheck,其中两个常见的类型是:
-
TCP连接检查:这种类型的Healthcheck会定期尝试建立到服务器端口的TCP连接。如果连接成功建立,表示服务器健康。如果连接失败,表示服务器不可用,需要进行故障转移。
-
HTTP健康检查:这种类型的Healthcheck会发送HTTP请求到服务器,并根据服务器的响应状态码来判断服务器是否健康。例如,如果服务器返回200 OK状态码,表示服务器正常运行;如果返回其他状态码,可能表示服务器出现故障或服务不可用。
Healthcheck的频率和超时时间可以根据需要进行配置。通常,健康检查的频率较高,以便及时发现服务器故障,并且超时时间要足够短,以避免等待过长时间才判定为故障。如果连续多次健康检查失败,则会触发故障转移操作,将服务从故障节点切换到备用节点。
Keepalived中的Healthcheck是用于监测服务器或服务状态的功能,以确保主备节点的状态和服务的正常运行,并在发现故障时自动触发故障转移操作,从而实现服务的高可用性。
实现
实例:监控本机的nginx进程是否运行,如果nginx进程不运行就立马将优先级降低30
-
编写监控nginx的脚本
-
如何判断nginx是否运行,方法很多?
-
pidof nginx killall -0 nginx #如果返回的是0代表是正常运行,否则nginx没有正常运行。
-
-
[root@ydh nginx]# cat check_nginx.sh #!/bin/bashif /usr/sbin/pidof nginx &>/dev/null;thenexit 0 elseexit 1 fi
-
-
在keepalived里定义监控脚本
-
#定义监控脚本chk_nginx vrrp_script chk_nginx { script "/nginx/check_nginx.sh" intervel 1 weight -30 } -
vrrp_script chk_nginx:这是定义监控脚本的起始行,chk_nginx是脚本的名称。script "/nginx/check_nginx.sh":这是脚本文件的路径和名称。根据路径,脚本文件位于/nginx/check_nginx.sh。脚本文件可能包含一些逻辑和命令,用于检测Nginx服务的健康状态。interval 1:这是监控脚本的执行间隔,表示每隔1秒运行一次脚本。根据需求,您可以根据自己的要求进行调整。weight -30:这是脚本的权重,用于决定主备节点之间进行故障转移时的优先级。较低的权重值表示脚本优先级较高,当监控脚本执行失败时,会影响节点的优先级,从而可能导致故障转移。
-
-
在keepalived里调用监控脚本
-
keepalived 会通过看脚本执行的返回看脚本是否成功执行
- 返回0代表成功,否则失败
-
vrrp_instance VI_1 {state MASTERinterface ens33virtual_router_id 58priority 120advert_int 1authentication {auth_type PASSauth_pass 1111}virtual_ipaddress {192.168.2.188} #调用监控脚本 track_script { chk_nginx} }
-
注意:
- 监控nginx的脚本主要设置在master里面,实现master不灵的时候,实现vip漂移到backup上
weight -30需要实现master和backup的优先级大小调换才有效果,否则不会是实现vip漂移
notify
当本节点服务器成为某个角色的时候,我们去执行某个脚本
notify_master:当当前节点成为master时,通知脚本执行任务(一般用于启动某服务)
notify_backup:当当前节点成为backup时,通知脚本执行任务(一般用于关闭某服务
notify_fault:当当前节点出现故障,执行的任务;
如果检测到nginx进程关闭了,里面关闭keepalived的软件
定义脚本
[root@ydh nginx]# cat halt_keepalived.sh
#!/bin/bashservice keepalived stop
配置文件中使用
notify_backup "nginx/halt_keepalived.sh"
关闭nginx后,按照之前的配置,master会变为backup。随后可以看keepalived进程是否关闭了,关闭了就代表配置成功了.
VRRP
虚拟路由器冗余协议(Virtual Router Redundancy Protocol,VRRP)是一种网络协议,用于提供路由器的冗余和故障切换功能。它允许多个路由器(或防火墙)组成一个虚拟路由器,共享一个虚拟IP地址,以提供高可用性和故障恢复。
工作在网络层。
下面是VRRP的一些重要特性和功能的详细介绍:
-
虚拟路由器:VRRP允许多个路由器组成一个虚拟路由器组,这个组由一个虚拟IP地址标识。虚拟路由器组中的路由器互为备份,其中一个被选为主路由器(Master),负责接收和处理传入的数据包,而其他路由器则处于备份状态(Backup)。
-
主备切换:在VRRP组中,只有主路由器才会接收和处理传入的数据包,其他备份路由器会监听主路由器的状态。如果主路由器失效(例如发生故障或不可访问),备份路由器中的一个会自动接管虚拟IP地址,并成为新的主路由器。这样可以实现无缝的主备切换,确保网络的连通性和可用性。
-
优先级和选举:每个路由器在VRRP组中都有一个优先级值,用于确定主路由器的选举。具有较高优先级的路由器通常会被选为主路由器,而其他路由器则成为备份路由器。在主备切换时,备份路由器中的一个会根据优先级来接管虚拟IP地址。
-
路由器通信:VRRP组中的路由器通过周期性地发送VRRP通告消息来保持彼此之间的通信。这些消息包含了路由器的状态和优先级信息。备份路由器会定期检查主路由器的状态,以便在主路由器失效时接管虚拟IP地址。
-
虚拟IP地址:VRRP组中的虚拟IP地址是由主路由器使用的,用于接收和处理传入的数据包。当主路由器失效时,新的主路由器会接管虚拟IP地址,确保网络流量继续正常传输到虚拟路由器组。
通过使用VRRP,网络管理员可以实现路由器的冗余和故障切换,提供高可用性和可靠性的网络服务。VRRP广泛应用于企业网络、数据中心和云环境中,确保网络设备的故障不会影响网络的连通性和性能。
只要安装keepalive软件就可以运行vrrp协议,只要通过vrrp协议就可以选举出master和backup。
选举
VRRP(Virtual Router Redundancy Protocol)选举过程如下:
-
VRRP组创建:在一个网络中,多个路由器或防火墙被配置为参与同一个VRRP组。每个路由器都会配置一个虚拟路由器标识(VRID),用于识别属于同一个VRRP组的路由器。
-
优先级设置:每个路由器在VRRP组中都被配置一个优先级值。优先级值决定了路由器在选举中的地位,数值越高表示优先级越高。
-
Master选举:当VRRP组中的路由器启动或者检测到当前Master路由器失效时,会开始进行Master选举过程。选举过程中,路由器将发送VRRP Advertisement(通告)消息,包含自己的优先级和其他相关信息。
-
优先级比较:在Master选举过程中,各个路由器比较彼此的优先级。优先级较高的路由器将有更大的机会成为Master路由器。如果路由器的优先级相同,则根据路由器的IP地址进行比较,IP地址较大的路由器将成为Master。
-
Master路由器确定:经过优先级比较后,最高优先级的路由器将成为Master路由器。它将负责处理接收和处理来自网络中其他设备的数据包,并维护VRRP组的虚拟IP地址。
-
备份路由器:除了Master路由器外,其他路由器将成为备份(Backup)路由器。它们继续发送VRRP Advertisement消息,但不处理传入的数据包。备份路由器会监听Master路由器的状态,以便在Master失效时接管虚拟IP地址。
-
状态迁移:如果Master路由器失效,备份路由器中的一个将根据优先级和其他配置信息接管虚拟IP地址,并成为新的Master路由器。此过程通常很快,以确保网络的连通性和故障切换的快速完成。
需要注意的是,VRRP选举过程是根据优先级进行的,但也受到其他配置参数的影响,例如预先设定的权重值、IP地址等。此外,VRRP还支持预先设定的倾向值(preemption),用于指定在Master路由器恢复正常后是否重新成为Master。
格式
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-VBX41bK5-1689353286902)(C:\Users\asus\AppData\Roaming\Typora\typora-user-images\image-20230704213959810.png)]](https://img-blog.csdnimg.cn/354f1f3f832848a49f3cfdbc8ad9631b.png)
文章目录
- nginx
- 介绍
- 代理
- 集群
- 安装
- 配置文件
- http
- 使用
- master和worker
- 升级问题
- 基于域名的虚拟主机
- 隐藏nginx的版本信息
- 供别人下载的网站
- 统计的信息的页面
- pv介绍
- ngixn续
- nginx认证
- nginx的allow和deny
- nginx限制并发数
- nginx限速
- 限速的算法
- nginx 限制请求数
- nginx 的 location
- nginx 的 location
- nginx压力测试
- 健康检测
- 参数
- HTTP
- 是什么
- 报文结构
- 请求头部
- 响应头部
- 工作原理
- 用户点击一个URL链接后,浏览器和web服务器会执行什么
- http的版本
- 持久连接和非持久连接
- 无状态与有状态
- Cookie和Session
- http方法:
- get和post的区别
- 状态码
- HTTPS
- 是什么
- ssl
- 如何搞到证书
- nginx中的部署
- 加密
- CA
- 数字证书
- hash算法
- 对称加密
- 非对称加密
- 数字签名
- webhook
- IO多路复用
- 基础
- 文件句柄
- /proc文件:
- 内核
- uri和url
- url
- 介绍
- 方法
- select
- poll
- epoll
- 总结
- DNS
- 是什么以及作用
- 下载DNS服务
- named.conf
- DNS查询
- DNS缓存机制
- 解析过程
- 递归查询和迭代查询
- DNS服务器的类型
- DNS域名
- DNS服务器的类型
- 搭建dns服务器
- 缓存域名服务器
- 主域名服务器
- 从域名服务器
- 排错
- 反向解析
- CDN
- 介绍
- DNS转发
- 介绍
- 配置
- DNS劫持
- nginx 负载均衡
- 负载均衡策略(方法、算法)
- nginx配置
- round-robin
- 加权轮询
- least-connected
- ip-hasp
- 使用Https
- realip
- 后端real server不使用realip模块
- 后端
- real server使用realip模块
- ab压力测试
- 不同负载
- 四层负载
- 7层负载
- 4层和7层
- nfs
- 安装、使用
- nfs机器上的操作
- server机器
- 权限问题
- 开机自动挂载
- 相关的命令和文件
- rpc
- rpc和nfs
- san
- nfs和san区别
- 高可用
- 介绍
- keepalived
- 安装、使用
- vip漂移
- 抓包
- 脑裂
- 脑裂有没有危害?如果有危害对业务有什么影响?
- keepalived架构
- 双vip架构
- Healthcheck
- 实现
- notify
- VRRP
- 选举
- 格式
- 系统性能监控
- 相关命令
- lscpu
- top
- free
- htop
- dstat
- glances
- iftop
- iptraf
- nethogs
- 监控软件
- Prometheus
- 安装、使用
- 将promethues做成服务
- 监控其他机器
- exporter
- grafana
- 配置、使用
- 密码忘记重置
系统性能监控
相关命令
lscpu
lscpu 是一个 Linux 命令,用于显示关于 CPU(中央处理器)架构和信息的详细信息。它提供了关于 CPU 型号、核心数量、线程数量、缓存大小和其他与 CPU 相关的特性的信息。以下是 lscpu 命令输出的一些常见信息及其解释:
-
Architecture(架构):显示操作系统所运行的 CPU 架构,如 x86、x86_64、ARM 等。
-
CPU(s)(CPU 数量):显示系统中的物理 CPU 数量。
-
Thread(s) per core(每核线程数):显示每个 CPU 核心支持的线程数。如果 CPU 支持超线程技术,该值将大于 1,表示每个物理核心可以同时运行多个线程。
-
Core(s) per socket(每个插槽核心数):显示每个物理 CPU 插槽中的核心数。
-
Socket(s)(插槽数量):显示系统中的物理 CPU 插槽数量。
-
Model name(型号名称):显示 CPU 的型号和描述信息。
-
CPU MHz(CPU 主频):显示 CPU 的主频(运行频率)。
-
CPU max MHz(CPU 最大主频):显示 CPU 的最大主频。
-
CPU min MHz(CPU 最小主频):显示 CPU 的最小主频。
-
L1d cache(一级数据缓存):显示 CPU 的一级数据缓存大小。
-
L1i cache(一级指令缓存):显示 CPU 的一级指令缓存大小。
-
L2 cache(二级缓存):显示 CPU 的二级缓存大小。
-
L3 cache(三级缓存):显示 CPU 的三级缓存大小。
-
Virtualization(虚拟化支持):显示 CPU 是否支持虚拟化技术。
-
Flags(特性标志):显示 CPU 支持的特性标志,如 SSE(流式 SIMD 扩展)、AVX(高级矢量扩展)、AES(高级加密标准)等。
以上是 lscpu 命令输出中常见的一些信息,它们提供了有关系统中 CPU 架构和特性的详细信息。可以使用 lscpu 命令来查看您的系统上 CPU 的相关信息,以了解 CPU 的配置和功能。
top
top 是一个常用的终端命令,用于实时监视和显示系统中运行的进程和系统性能指标。它可以让您查看正在运行的进程的资源使用情况,例如 CPU 占用率、内存占用率、交换空间使用情况等。以下是 top 命令输出的一些常见信息及其解释:
-
第一行:整体系统性能指标
top:显示当前时间和运行时间。up:系统的运行时间。users:当前登录用户数量。load average:过去 1 分钟、5 分钟和 15 分钟的平均负载。
-
第二行:进程统计信息
Tasks:当前运行的进程数量。total:总进程数。running:正在运行的进程数。sleeping:休眠(等待)的进程数。stopped:停止的进程数。zombie:僵尸进程数。
-
第三行:CPU 占用率信息
%Cpu(s):CPU 使用率统计。us:用户空间程序占用 CPU 的百分比。sy:系统空间程序占用 CPU 的百分比。ni:以较低优先级运行的用户空间程序占用 CPU 的百分比。id:空闲 CPU 的百分比。wa:等待 I/O 的 CPU 时间百分比。hi:硬件中断(Hardware IRQ)占用 CPU 的百分比。si:软件中断(Software IRQ)占用 CPU 的百分比。
-
进程列表:显示当前运行的进程列表
PID:进程 ID。USER:进程的所属用户。PR:进程的优先级。NI:进程的优先级修改值。VIRT:进程使用的虚拟内存大小。RES:进程使用的物理内存大小(常驻内存)。SHR:进程使用的共享内存大小。S:进程的状态(R: 运行, S: 睡眠, Z: 僵尸进程等)。%CPU:进程占用 CPU 的百分比。%MEM:进程占用内存的百分比。TIME+:进程累计的 CPU 使用时间。COMMAND:进程的命令行。
top 命令会实时更新并显示系统的运行情况,您可以使用键盘上的不同快捷键来执行特定操作,例如杀死进程、改变排序方式、切换显示模式等。要退出 top命令,可以按下 q 键。通过使用 top 命令,您可以及时监测系统的性能指标和进程活动,以便快速了解系统的状态和资源使用情况。
`load average(系统平均负载)
系统平均负载是指过去的1分钟、5分钟、15分组,处于可运行(可运行或就绪的状态)或不可中断状态(阻塞的状态)的进程的平均数量。这是进程的平均数量,用来判断系统是否繁忙的指标,假如我们的系统是1个cpu核心,这个值超过1就说明系统比较繁忙了,但是不超过5说明还没有达到最忙的时候,0~5以内,说明系统还可以接受,只要超过1就比较忙了。
假如有8个核心,这个值就是8,超过8就比较忙,但是可以承受的总值是5*8=40.
系
交互性命令:
在 top 命令的交互界面中,可以使用多个键盘快捷键执行不同的操作。以下是一些常见的 top 命令的交互性命令:
-
切换排序方式:
M:按内存占用排序。P:按 CPU 占用排序。T:按时间/累计 CPU 排序。
-
进程操作:
k:杀死选中的进程。r:修改选中进程的优先级。
-
显示模式切换:
1:显示全局汇总信息。2:显示每个 CPU 核心的详细信息。3:显示每个任务(进程)的详细信息。
-
刷新频率控制:
s:改变刷新间隔时间。d或D:改变刷新间隔时间为动态调整模式。
-
过滤器和搜索:
o:添加或修改显示字段。/:进入进程搜索模式,可输入关键字搜索进程。=:清除进程搜索过滤器。
-
系统操作:
H:在线程和进程之间切换显示。i:显示内核和 I/O 统计信息。b:显示中断统计信息。
-
退出
top:q:退出top命令。
这只是一些常见的 top 命令的交互性命令示例,实际上 top 命令提供了更多的功能和选项。可以在 top 命令的交互界面中按下 h 键获取更详细的帮助信息,其中包含了所有可用的快捷键和操作说明。
实例
[root@ydh nginx]# top -d 3 -n 1
-d 3:表示刷新间隔为 3 秒。这将使top命令每隔 3 秒更新一次显示内容。-n 1:表示只执行一次top命令后退出。这将使top命令只显示一次系统状态和进程信息,然后立即退出。
top -d 3 -n 1 命令将执行一次 top 命令并在终端显示系统的实时状态和进程信息,刷新间隔为 3 秒,然后在显示一次后立即退出。这样可以获取系统状态的一个快照而不会持续监视和更新。
free
free 是一个常用的 Linux 命令,用于显示系统中的内存使用情况。它提供了物理内存(RAM)和交换空间(Swap)的相关统计信息。以下是 free 命令输出的详细解释:
-
第一行:系统整体内存使用情况
-
total:物理内存总量。 -
used:应用程序已使用的物理内存量。 -
free:可用的物理内存量。 -
shared:被共享使用的物理内存量(多个进程共享的内存)。 -
buffers:被缓存的文件数据的物理内存量(内存–》buffer–》磁盘)(减少IO的次数)。 -
cached:被缓存的文件系统的物理内存量(磁盘–》cached–》内存)(可以将数据先写道cached,提升速度)。 -
total = used + free + shared +buff/cahce
-
available=free + buff/cached里的为使用完的空间:下一次进程可以使用的内存空间
-
-
第二行:内存详细信息
Mem:物理内存统计信息。total:物理内存总量。used:已使用的物理内存量。free:可用的物理内存量。shared:被共享使用的物理内存量。buffers/cache:被缓存的文件数据和文件系统的物理内存量。available:可用的物理内存量,考虑了系统保留的内存和缓存的影响。
-
第三行:交换空间(Swap)信息
Swap:交换空间(Swap)统计信息。total:交换空间总量。used:已使用的交换空间量。free:可用的交换空间量。
free 命令的输出以字节(Bytes)为单位,但通常也以更友好的格式显示,如千字节(Kilobytes)、兆字节(Megabytes)或千兆字节(Gigabytes)。
参数:
-b:以字节(Bytes)为单位显示内存大小。-k:以千字节(Kilobytes)为单位显示内存大小(默认选项)。-m:以兆字节(Megabytes)为单位显示内存大小。-g:以千兆字节(Gigabytes)为单位显示内存大小。-h:以人类可读的格式显示内存大小(自动选择合适的单位)。-s <delay>:指定刷新间隔的时间间隔(以秒为单位)。-c <count>:指定输出的次数后退出。-t:在输出中显示总计行。
可以通过在终端中运行 man free 命令来查看完整的 free 命令的参数列表和详细说明。
注意:
交换分区是从磁盘里划分出来的一块空间临时做内存使用的,当物理内存不足的时候,将不活跃的进程交换到swap分区里(尽量不要使用交换分区,因为速度慢)
实例:
[root@ydh nginx]# cat /proc/sys/vm/swappiness
30
当物理内存只剩下30%的时候空闲的时候,开始使用交换分区
[root@ydh nginx]# echo 0 >/proc/sys/vm/swappiness
[root@ydh nginx]# cat /proc/sys/vm/swappiness
0htop
htop 是一个交互式的系统监视工具,功能类似于经典的 top 命令,但提供了更丰富的功能和更友好的用户界面。以下是对 htop 命令的详细解析:
-
主要显示区域:
- CPU 利用率:显示每个 CPU 核心的使用率和总体 CPU 使用率。
- 内存使用情况:显示物理内存和交换空间的使用情况。
- 任务列表:显示系统上运行的进程和线程的列表,按 CPU 或内存使用排序。
-
导航和交互操作:
- 使用方向键或鼠标滚轮可以滚动浏览任务列表。
- 使用 F1 到 F10 键可以访问不同的功能键菜单,提供了各种系统监视和操作选项。
- 使用键盘上的数字键可以快速切换不同的排序方式(如按 CPU 使用率、内存使用率等)。
- 使用键盘上的快捷键(如 F9)可以对选定的进程执行操作,如终止进程、优先级调整等。
-
颜色编码和标识:
- 不同颜色的文本和背景用于标识不同类型的进程和任务状态,如运行中、睡眠中、僵尸进程等。
- 显示了进程的 CPU 使用率、内存使用量、虚拟内存、线程数量等关键信息。
-
其他功能:
- 支持在任务列表中搜索进程。
- 提供了实时的系统负载图表,显示 CPU 和内存的实时使用情况。
- 可以显示进程树,显示进程之间的父子关系。
- 支持在任务列表中设置进程筛选器,以过滤显示特定的进程。
htop 提供了一个直观且交互式的界面,使您能够更方便地监视系统状态、查看进程信息和执行操作。它对于系统管理员和开发人员来说是一个非常有用的工具,可以帮助他们更好地了解和管理系统。
dstat
dstat 是一个全能的系统资源监视工具,它提供了丰富的统计数据和信息,并以可配置的格式输出。以下是对 dstat 的数据展示解析:
-
CPU 相关数据:
- 用户空间 CPU 使用率(usr):表示用户进程所使用的 CPU 时间的百分比。
- 系统 CPU 使用率(sys):表示内核进程所使用的 CPU 时间的百分比。
- 等待 I/O 的 CPU 使用率(iowait):表示 CPU 等待 I/O 完成的时间的百分比。
- 硬中断的 CPU 使用率(irq):表示处理硬件中断的 CPU 时间的百分比。
- 软中断的 CPU 使用率(soft):表示处理软件中断的 CPU 时间的百分比。
- CPU 空闲率(idle):表示 CPU 空闲时间的百分比。
-
内存相关数据:
- 已使用内存量(used):表示系统当前已使用的内存量。
- 空闲内存量(free):表示系统当前空闲的内存量。
- 缓存使用量(buff):表示系统当前用于文件缓存的内存量。
- 缓冲区使用量(cache):表示系统当前用于缓冲 I/O 操作的内存量。
- 可用内存量(available):表示系统当前可用的内存量。
-
磁盘相关数据:
- 磁盘读取速率(read):表示磁盘读取数据的速率。
- 磁盘写入速率(writ):表示磁盘写入数据的速率。
- 磁盘读取操作数(read_ops):表示磁盘读取操作的数量。
- 磁盘写入操作数(writ_ops):表示磁盘写入操作的数量。
-
网络相关数据:
- 网络传入数据速率(recv):表示网络接收数据的速率。
- 网络传出数据速率(send):表示网络发送数据的速率。
- 网络传入数据包数(recv_pkg):表示网络接收的数据包数量。
- 网络传出数据包数(send_pkg):表示网络发送的数据包数量。
-
进程相关数据:
- 运行进程数(procs):表示系统当前运行的进程数。
- 阻塞进程数(blocked):表示当前阻塞状态的进程数。
- 睡眠进程数(sleeping):表示当前睡眠状态的进程数。
- 线程数(thread):表示当前系统中的线程数。
dstat 的输出可以根据用户需求进行自定义配置,并且支持通过命令行参数选择要显示的数据类型、采样间隔和显示持续时间等。通过监视和分析 dstat 的输出数据,可以获得对系统资源使用情况的全面了解,以便进行性能优化、故障排查和资源规划等操作。
参数:
dstat 是一个功能强大的系统资源监视工具,提供了许多参数和选项,以满足用户对系统性能数据的不同需求。以下是 dstat 常用参数的详细介绍:
-
-c, --cpu:显示 CPU 相关的统计数据。usr:用户空间 CPU 使用率。sys:系统 CPU 使用率。idl:CPU 空闲率。wai:等待 I/O 的 CPU 使用率。hiq:硬中断的 CPU 使用率。siq:软中断的 CPU 使用率。
-
-d, --disk:显示磁盘相关的统计数据。read:磁盘读取速率。writ:磁盘写入速率。read_ops:磁盘读取操作数。writ_ops:磁盘写入操作数。
-
-n, --net:显示网络相关的统计数据。recv:网络传入数据速率。send:网络传出数据速率。recv_pkg:网络传入数据包数。send_pkg:网络传出数据包数。
-
-m, --mem:显示内存相关的统计数据。used:已使用内存量。free:空闲内存量。buff:缓存使用量。cach:缓冲区使用量。free:可用内存量。
-
-p, --proc:显示进程相关的统计数据。run:运行进程数。blk:阻塞进程数。slp:睡眠进程数。thd:线程数。
-
-s, --swap:显示交换空间相关的统计数据。used:已使用交换空间量。free:空闲交换空间量。
-
-g, --page:显示页面交换相关的统计数据。in:页面交换入速率。out:页面交换出速率。
-
-y, --sys:显示系统相关的统计数据。intr:每秒中断数。ctxt:每秒上下文切换数。
-
-l, --load:显示系统负载平均值。 -
-r, --io:显示系统 I/O 相关的统计数据。read:每秒读取字节数。writ:每秒写入字节数。
-
-N, --fs:显示文件系统相关的统计数据。read:文件系统读取速率。writ:文件系统写入速率。used:已使用的文件系统空间。free:可用的文件系统空间。
-
`-S,
–sockets:显示套接字相关的统计数据。 - total:总套接字数。 - udp:UDP 套接字数。 - tcp:TCP 套接字数。 - raw`:RAW 套接字数。
还有其他一些参数和选项可以与上述参数组合使用,以进一步定制 dstat 的输出,例如:
-a:显示所有可用的统计数据。-f:显示文件系统统计数据。-T:显示时间戳。
通过在命令行中使用这些参数和选项,可以根据需要监视和分析系统资源的各个方面。可以通过 man dstat 命令查看完整的参数和选项列表以及其详细说明。
glances
Glances是一个跨平台的系统监视工具,提供了实时的系统状态和性能指标的全面视图。下面是Glances的一些主要特点和功能:
-
实时监视:Glances提供实时的系统监视,可以即时查看CPU、内存、磁盘、网络、传感器等方面的数据。
-
用户友好的界面:Glances采用交互式终端界面,通过命令行展示信息,并以颜色和图表的形式直观地呈现数据。
-
多平台支持:Glances可以在Linux、Windows、MacOS等多个操作系统上运行,并提供相应的可执行文件和软件包。
-
详细的系统信息:Glances显示了关于系统的详细信息,包括操作系统类型、内核版本、主机名等。
-
多项性能指标:Glances提供了广泛的性能指标,包括CPU使用率、内存使用情况、磁盘读写速度、网络流量、进程数量等。
-
进程管理:Glances允许查看和管理运行中的进程,包括CPU和内存占用最高的进程。
-
警报和通知:Glances可以配置警报和通知,以便在达到特定阈值时通知用户。
-
扩展性:Glances支持插件系统,可以通过安装额外的插件来扩展其功能,例如监视数据库、Web服务器等。
总体而言,Glances是一个功能强大且易于使用的系统监视工具,可以为用户提供全面的系统状态和性能数据,并帮助用户监控系统健康、排查问题和优化性能。
[root@ydh ~]# yum install glances -y
进入
[root@ydh ~]# iptraf-ng
按q退出
iftop
iftop是一款开源的命令行工具,用于实时监视网络流量。它提供了一个直观的界面,显示正在进行的网络连接以及每个连接的流量信息。以下是iftop的一些主要特点和功能:
-
实时流量监视:iftop以实时的方式监视网络流量,显示当前网络连接的流量情况,包括传入流量和传出流量。
-
可视化界面:iftop以交互式的方式展示网络连接和流量信息,使用类似于top命令的界面,易于理解和操作。
-
按连接排序:iftop根据流量大小对连接进行排序,使用户可以快速找到产生最多流量的连接。
-
IP和端口信息:iftop显示与每个连接相关的IP地址和端口号,帮助用户识别网络流量的来源和目标。
-
过滤功能:iftop支持根据IP地址、端口号和网络接口等条件进行流量过滤,以便用户关注特定的网络流量。
-
网络带宽图表:iftop提供带宽使用情况的实时图表,使用户可以直观地了解网络的使用情况和趋势。
-
统计信息:iftop提供有关总体流量、平均流量和流量峰值的统计信息,帮助用户评估网络性能和负载。
iftop是一个强大的工具,特别适用于需要实时监视网络流量的情况,如网络故障排除、带宽优化和网络安全监控等。通过iftop,用户可以迅速获取关于网络流量的详细信息,并对网络连接进行分析和管理。
[root@ydh ~]# yum install iftop -y
iptraf
iptraf是一个实时网络流量监视工具,用于在Linux系统上监视网络接口的活动。它提供了一个交互式的界面,显示网络接口的统计信息、连接状态、端口信息等。以下是iptraf的一些主要特点和功能:
-
实时流量监视:iptraf以实时的方式监视网络接口的流量情况,包括传入流量和传出流量。
-
多种统计信息:iptraf提供了各种统计信息,如总流量、每秒流量、传输速率、错误包数量等,以便用户了解网络接口的使用情况。
-
连接状态监视:iptraf可以显示当前活动的连接状态,包括TCP连接和UDP连接,以及连接的源IP地址和目标IP地址。
-
端口监视:iptraf可以监视特定端口的活动情况,包括连接数量、数据传输量等。
-
按协议过滤:iptraf支持按照不同的网络协议进行过滤,如TCP、UDP、ICMP等,以便用户查看特定协议的流量情况。
-
日志功能:iptraf可以将监视的数据记录到日志文件中,方便后续分析和审查。
-
交互式界面:iptraf提供一个交互式的终端界面,允许用户通过按键或菜单选择来查看不同的统计信息和设置选项。
iptraf是一个功能丰富且易于使用的网络流量监视工具,适用于网络管理人员、系统管理员和安全分析师等对网络流量进行实时监视和分析的用户。它可以帮助用户监控网络接口的使用情况、识别潜在的网络问题,并进行网络性能优化和故障排除。
[root@ydh ~]# yum install iptraf -y
nethogs
Nethogs是一款开源的命令行工具,用于实时监视网络接口的流量和进程。它可以显示当前正在使用网络带宽的进程及其相应的流量使用情况。以下是Nethogs的一些主要特点和功能:
-
实时流量监视:Nethogs以实时的方式监视网络接口的流量使用情况,显示当前正在使用带宽的进程及其相应的上传和下载流量。
-
进程识别:Nethogs能够识别每个网络连接对应的进程,并显示相关进程的PID、用户和执行路径。
-
流量分组:Nethogs按照进程进行流量分组,使用户可以快速了解每个进程消耗的带宽情况。
-
用户友好的界面:Nethogs提供一个交互式的终端界面,以表格形式展示进程、带宽和流量信息,易于理解和操作。
-
排序和过滤:Nethogs支持按照进程名称、PID、上传或下载流量进行排序和过滤,以便用户查找特定进程或关注特定类型的流量。
-
统计信息:Nethogs提供有关总体流量、平均流量和流量峰值的统计信息,帮助用户评估网络带宽的使用情况。
Nethogs是一个实用的工具,适用于需要实时监视网络带宽和了解流量消耗情况的场景。通过Nethogs,用户可以迅速发现网络中消耗带宽的进程,并根据需要进行优化和管理。
监控软件
- cacti
- nagios
- zabbix:集合cacti+nagios
- openfalcon
- Prometheus
Prometheus
是什么
Prometheus是一个开源的系统监控和告警工具,它最初由SoundCloud开发并于2012年开源。Prometheus的目标是收集和存储系统和服务的时间序列数据,并提供强大的查询语言和灵活的告警机制,以帮助用户监控其应用程序和基础设施的健康状况。
以下是Prometheus的一些重要特点和概念:
-
多维度数据模型:Prometheus采用多维度数据模型来描述时间序列数据。每个数据样本都由一个指标名称和一组键值对标签组成,用于区分不同的时间序列。这种模型非常适合动态标记的数据,例如系统资源使用情况、应用程序指标等。
-
灵活的查询语言:Prometheus提供了PromQL(Prometheus Query Language)用于查询和聚合时间序列数据。PromQL支持强大的表达式和函数,使用户能够执行复杂的查询和计算。
-
数据采集和存储:Prometheus通过使用自己的数据采集器(exporter)或与其他系统集成,从目标应用程序和基础设施中收集时间序列数据。数据存储在本地时间序列数据库中,并通过基于磁盘的块存储格式进行持久化。
-
动态发现和服务发现:Prometheus支持动态发现目标实例,可以自动发现和监控新的实例。它还与服务发现机制(如Kubernetes的服务发现)集成,以便自动发现和监控动态变化的服务。
-
告警和警报管理:Prometheus具有灵活的告警规则定义和警报通知机制。用户可以定义自定义告警规则,并通过电子邮件、Slack等方式接收警报通知。
-
可视化和仪表板:Prometheus提供了一个内置的基本图形化界面,用于数据可视化和监控仪表板。此外,Prometheus还支持与其他监控工具(如Grafana)进行集成,以创建更复杂和丰富的仪表板。
-
社区支持和生态系统:Prometheus拥有庞大的活跃社区,并且具有丰富的第三方工具和库的生态系统。用户可以通过使用这些工具和库来扩展和增强Prometheus的功能。
Prometheus是一个功能强大的系统监控和告警工具,具有灵活的数据模型、查询语言和告警机制。它被广泛应用于云原生环境、容器化应用程序和微服务架构中,帮助用户实时监控和调优他们的系统和服务的性能。
组成
安装、使用
解压
tar -xf prometheus-2.45.0.linux-amd64.tar.gz
改名
mv prometheus-2.45.0.linux-amd64 prometheus临时修改
PATH=/prom/prometheus:$PATH永久修改
vim /root/.bashrc 启动
nohup prometheus --config.file=/prom/prometheus/prometheus.yml &
查看是否运行
[root@prometheus prom]# ps aux|grep prometheus
root 2015 0.8 4.3 797792 42996 pts/0 Sl 11:53 0:00 prometheus --con
root 2025 0.0 0.0 112824 980 pts/0 S+ 11:54 0:00 grep --color=aut查看Prometheus监听的端口号
[root@prometheus prom]# netstat -anplut|grep prometheus
tcp6 0 0 :::9090 :::* LISTEN 2015/prometheus
tcp6 0 0 ::1:9090 ::1:34724 ESTABLISHED 2015/prometheus
tcp6 0 0 ::1:34724 ::1:9090 ESTABLISHED 2015/prometheus
关闭防火墙
[root@prometheus prom]# service firewalld stop
Redirecting to /bin/systemctl stop firewalld.service
[root@prometheus prom]# systemctl disable firewalld
Removed symlink /etc/systemd/system/multi-user.target.wants/firewalld.service.
Removed symlink /etc/systemd/system/dbus-org.fedoraproject.FirewallD1.service.
看本机的http
http://192.168.2.22:9090/
将promethues做成服务
/usr/lib/systemd/system/创建prometheus.service文件
vim /usr/lib/systemd/system/prometheus.service
promethes.service文件里的代码
[Unit]
Description=prometheus
[Service]
ExecStart=/prom/prometheus/prometheus --config.file=/prom/prometheus/prometheus.yml
ExecReload=/bin/kill -HUP $MAINPID
KillMode=process
Restart=on-failure
[Install]
WantedBy=multi-user.target
~
重新加载 systemd 的配置文件
[root@prometheus system]# systemctl daemon-reload
systemctl启动
[root@prometheus system]# systemctl start prometheus
查看进程是否启动,启动就代表prometheus.service配置成功了
注意:
第一次如果是用nohup启动的,不能用systemctl停止,需要用kill命令
nohup prometheus --config.file=/prom/prometheus/prometheus.yml &
监控其他机器
前提:被监控的机器需要将数据导出,安装好了exporter,同时知道机器的ip和端口号
/prom/prometheus/prometheus.yml文件,修改代码如下,增加被监控机器的信息。
- job_name: "prometheus"static_configs:- targets: ["localhost:9090"]- job_name: "origin"static_configs:- targets: ["192.168.2.24:8090"]- job_name: "LB1"static_configs:- targets: ["192.168.2.23:8090"]![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-LHmxOASH-1689353423437)(C:\Users\asus\AppData\Roaming\Typora\typora-user-images\image-20230706155937291.png)]](https://img-blog.csdnimg.cn/8290698c89cf4a5ba38711309cfd63bf.png)
可以看到已经收集到指定机器的数据了
exporter
https://grafana.com/grafana/download下载地址
[root@prometheus grafana]# yum install -y https://dl.grafana.com/enterprise/release/grafana-enterprise-10.0.1-1.x86_64.rpm解压
[root@ydh ~]# tar xf node_exporter-1.6.0.linux-amd64.tar.gz
移位加改名
[root@ydh ~]# mv node_exporter-1.6.0.linux-amd64 /node_exporter
修改环境变量
[root@ydh node_exporter]# PATH=/node_exporter/:$PATH[root@ydh node_exporter]# vim /root/.bashrc #放到该文件下永久修改
运行
[root@ydh node_exporter]# nohup node_exporter --web.listen-address 0.0.0.0:8090 &
查看node是否运行
[root@ydh node_exporter]# ps aux|grep node
root 4955 0.1 0.5 724024 11032 pts/1 Sl 15:43 0:00 node_exporter --web.listen-address 0.0.0.0:8090
root 4985 0.0 0.0 112824 988 pts/1 S+ 15:43 0:00 grep --color=auto nodegrafana
Grafana是一个开源的监控、度量分析和可视化工具,通常与时序数据库(如Prometheus、InfluxDB等)搭配使用。Grafana的主要功能和优点包括:
-
强大的图表和面板可视化。Grafana提供多样化的图表类型,如折线图、柱状图、饼图、热力图等,可以灵活制作出各种监控面板。
-
支持多种数据源。Grafana支持接入Prometheus、Elasticsearch、InfluxDB、MySQL等多种时序数据库作为数据源。
-
自定义监控仪表板。用户可以通过简单的配置就能快速构建自定义的监控仪表盘,方便查看应用或系统的运行状态。
-
丰富的插件系统。Grafana有700多个插件,可以实现警报、访问控制、自动化任务等扩展功能。
-
多用户多权限管理。Grafana可以创建不同的组织和用户,以实现灵活的访问控制。
-
模板变量和钻取功能。模板变量可以实现交互式的监控面板;钻取功能可以快速探查和关联问题。
-
企业级特性。Grafana Enterprise版提供了高级特性,如高可用性、增强的安全控制、数据源权限控制等。
-
开源与免费。Grafana是一个成熟的开源软件,社区活跃,使用免费。也提供企业版的高级功能。
总体来说,Grafana是一个功能强大且易于使用的开源监控 visualize 工具,可以快速搭建出美观实用的监控系统,因此被广泛应用于各类监控场景。
配置、使用
下载
[root@prometheus ~]# yum install -y https://dl.grafana.com/enterprise/release/grafana-enterprise-10.0.1-1.x86_64.rpm
启动
[root@prometheus ~]# service grafana-server start
Starting grafana-server (via systemctl): [ 确定 ]
开机自启
[root@prometheus ~]# systemctl enable grafana-server
查看进程是否启动
[root@prometheus ~]# ps aux|grep grafana
查看端口号
[root@prometheus ~]# netstat -anplut|grep grafana
tcp 0 0 192.168.2.22:35768 34.120.177.193:443 ESTABLISHED 1529/grafana
tcp6 0 0 :::3000 :::* LISTEN 1529/grafana
监听端口号是3000
在浏览器上登录
http://192.168.2.22:3000/
默认的用户名和密码都是:admin
grafana配置数据源
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-COVr41rx-1689353423438)(D:\Snipaste\03【电脑截图软件】snipaste截图软件\Typora\运维\Prometheus\配置源.png)]](https://img-blog.csdnimg.cn/8eee6914aff6445eaad5599cc4bd1439.png)
grafana导入模版
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-fKgWXiIQ-1689353423439)(D:\Snipaste\03【电脑截图软件】snipaste截图软件\Typora\运维\Prometheus\配置源.png)]](https://img-blog.csdnimg.cn/393c4dde41924341b96f8eef9e5b0800.png)
nginx的1860画面
nginx的8919画面
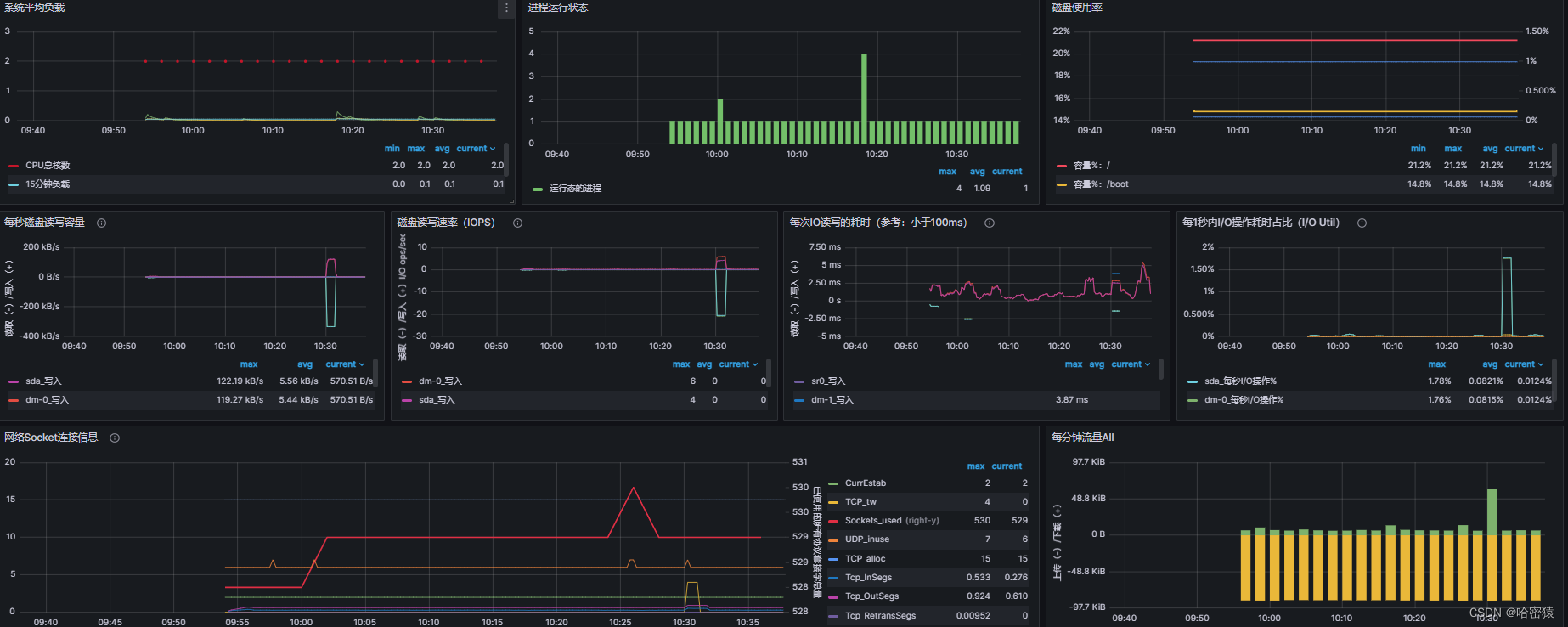
密码忘记重置
grafana-cli admin reset-admin-password '新密码'
systemctl restart grafana-server
grafana-cli admin reset-admin-password 123456


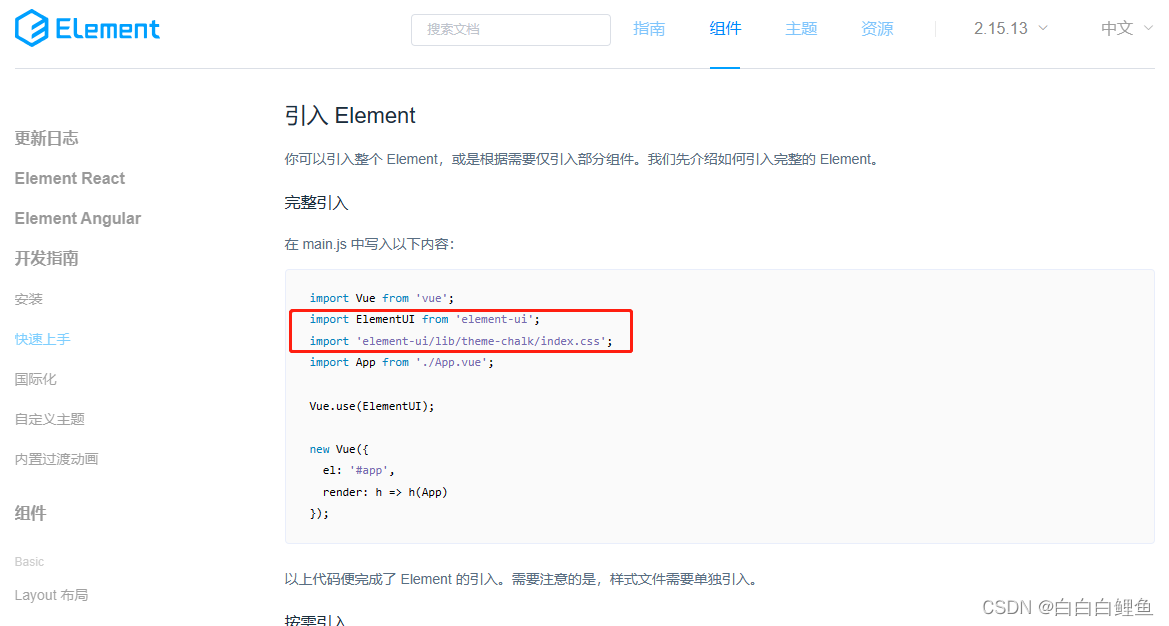
![[极客大挑战 2019]PHP(反序列化)](https://img-blog.csdnimg.cn/ed7befb0d79847128e142421ffda6f4b.png)