关于微服务链路追踪的一些概念:【分布式链路追踪】
文章目录
- 1、整合Seluth
- 2、日志信息分析
- 3、Zipkin介绍
- 4、Zipkin服务端安装
- 5、搭配Sleuth整合客户端Zipkin
- 6、收集数据
- 7、存储trace数据
1、整合Seluth
Spring Cloud Sleuth是一个用于追踪的工具,它可以将微服务调用的追踪信息(trace ID、parent ID、span ID、timestamp等)进行收集和传输
- 微服务的pom.xml中引入Sleuth依赖
<!--sleuth链路追踪-->
<dependency><groupId>org.springframework.cloud</groupId><artifactId>spring-cloud-starter-sleuth</artifactId><version>2.2.0.RELEASE</version>
</dependency>- 在微服务的配置文件application.yml中添加日志级别
logging:level:org.springframework.cloud.sleuth: DEBUG
- 重启服务,调用相关接口,查看控制台输出
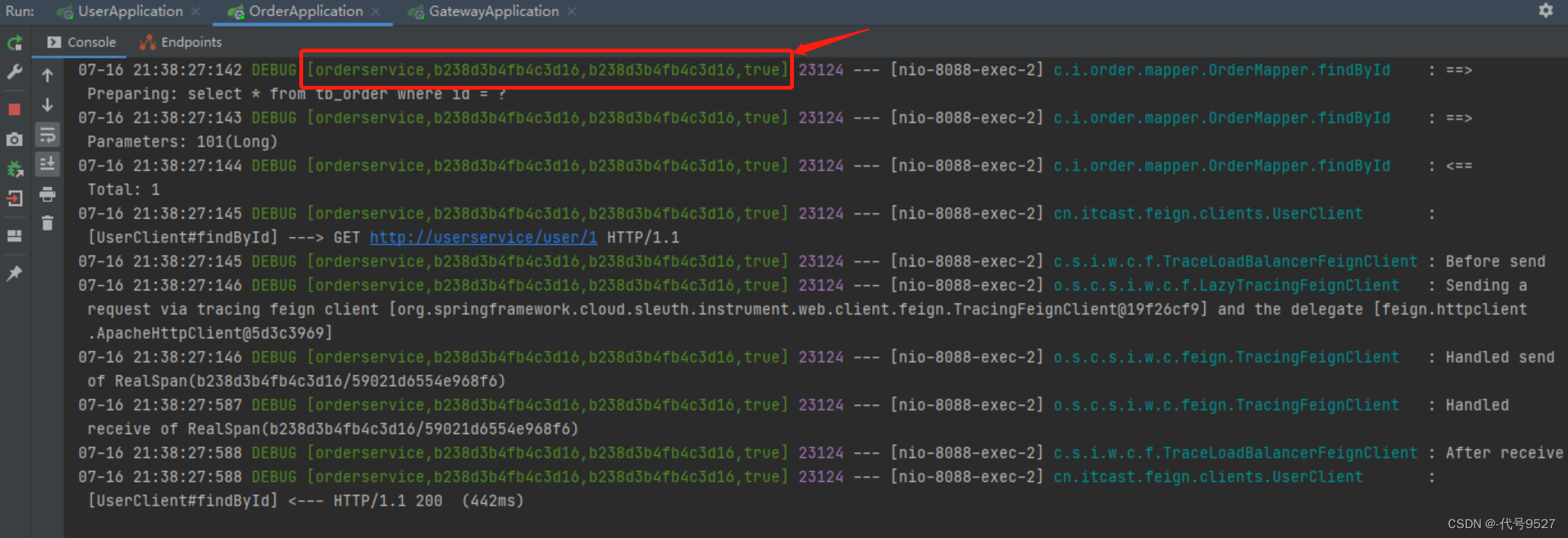
2、日志信息分析
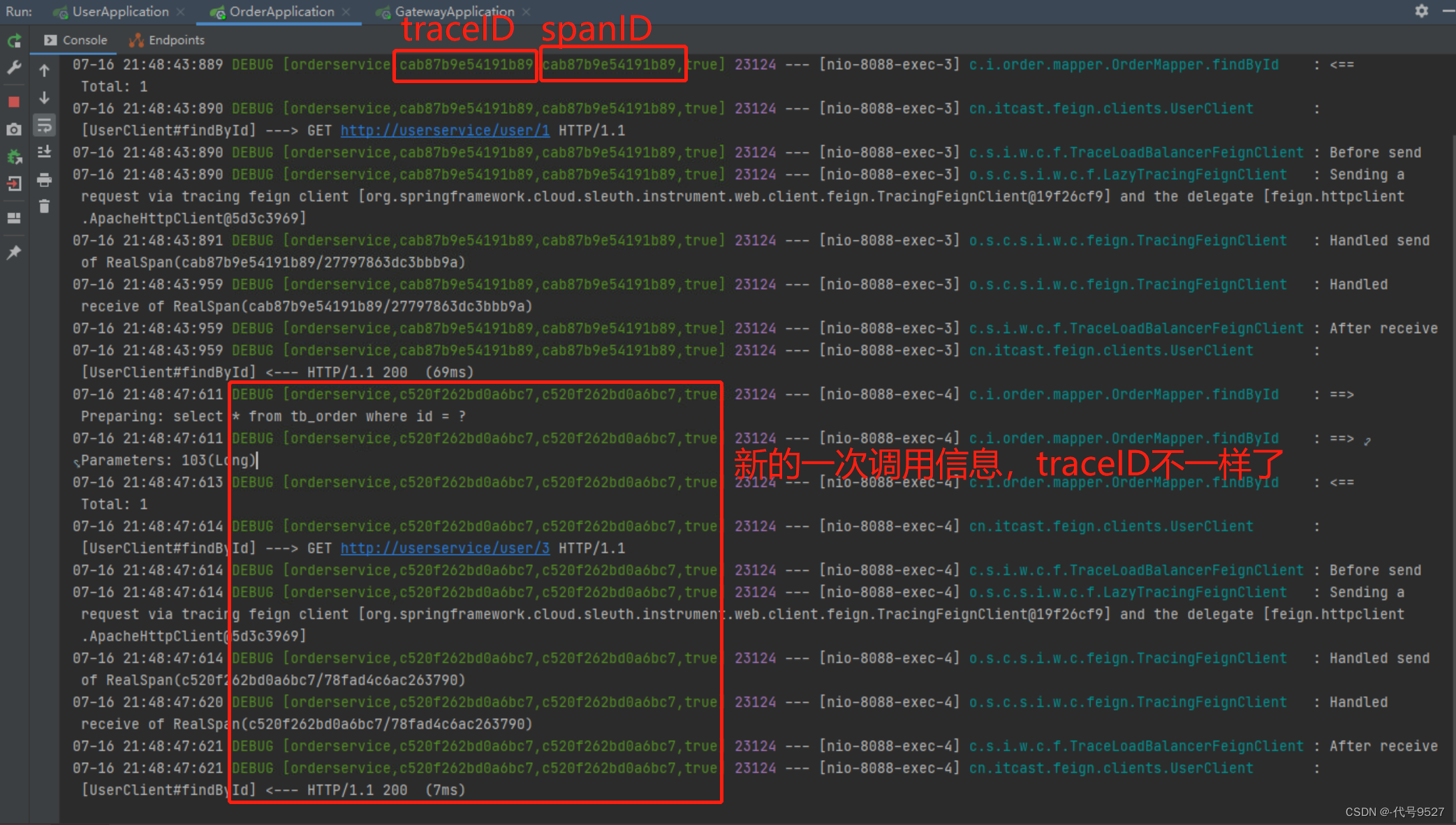
- 方括号[ ]中的两个数字,第一个是traceID,后面的是spanID
- 一次调用有一个全局的traceID
- 后面的true,和抽样比例有关,为false时,不会被后面的zipkin处理
使用traceID和spanID将整个链路串起来,就是请求的具体过程,但当调用关系复杂时,这样查看日志,效率太低了。因此,可使用Zipkin将日志信息进行聚合,然后进行一个可视化的展示和全文检索。
3、Zipkin介绍
Zipkin 是 Twitter 的一个开源项目,基于 Google Dapper 实现,致力于收集服务的定时数据,以解决微服务架构中的延迟问题,包括数据的收集、存储、查找和展现。
# 官方文档
https://zipkin.io/pages/quickstart
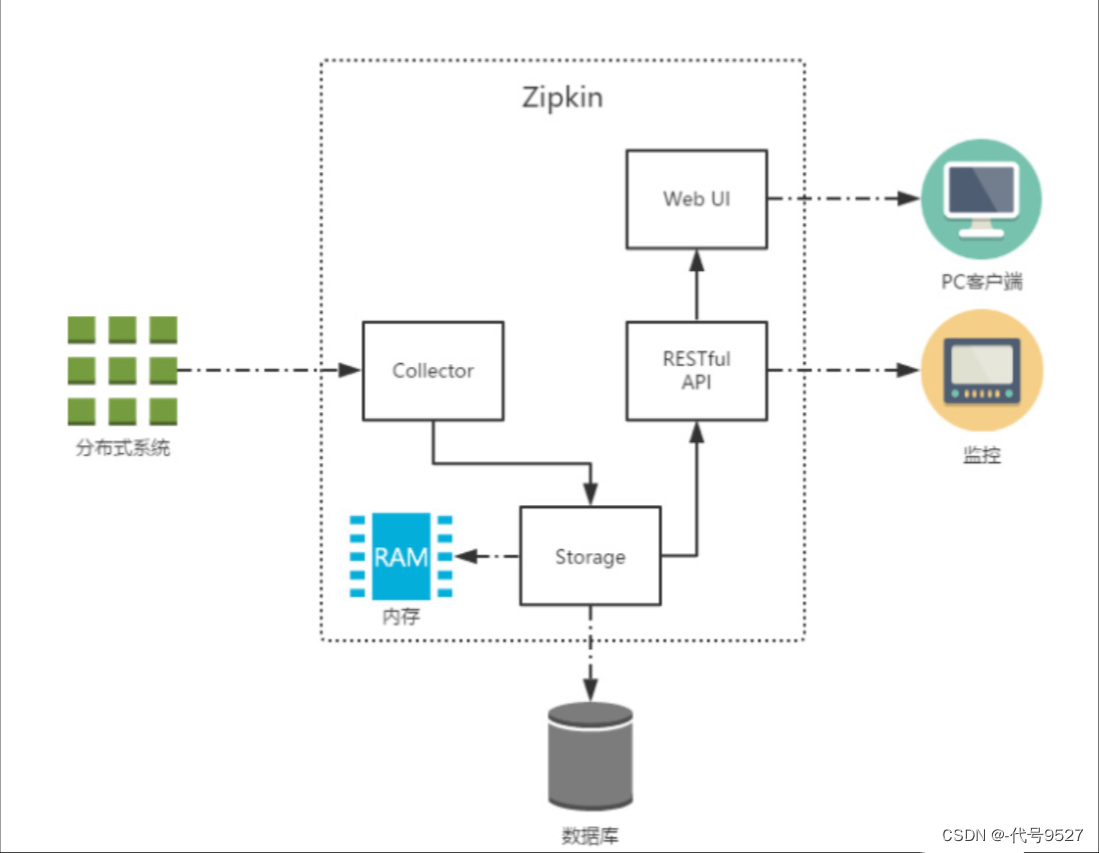
Zipkin的架构中,有四大块:
- Controller:收集器,处理从外部系统发送过来的跟踪信息,将这些跟踪信息处理成Zipkin需要的Span格式,以便后面的存储、分析、展示
- Storage:存储,处理收集器接收到的跟踪信息,默认存于内存,可改为MySQL、ES等
- RESTful API:API,用来提供外部访问接口,如给客户端展示跟踪信息,或外接系统访问以实现监控
- Web UI:可视化界面,方便直观地查询和分析跟踪信息
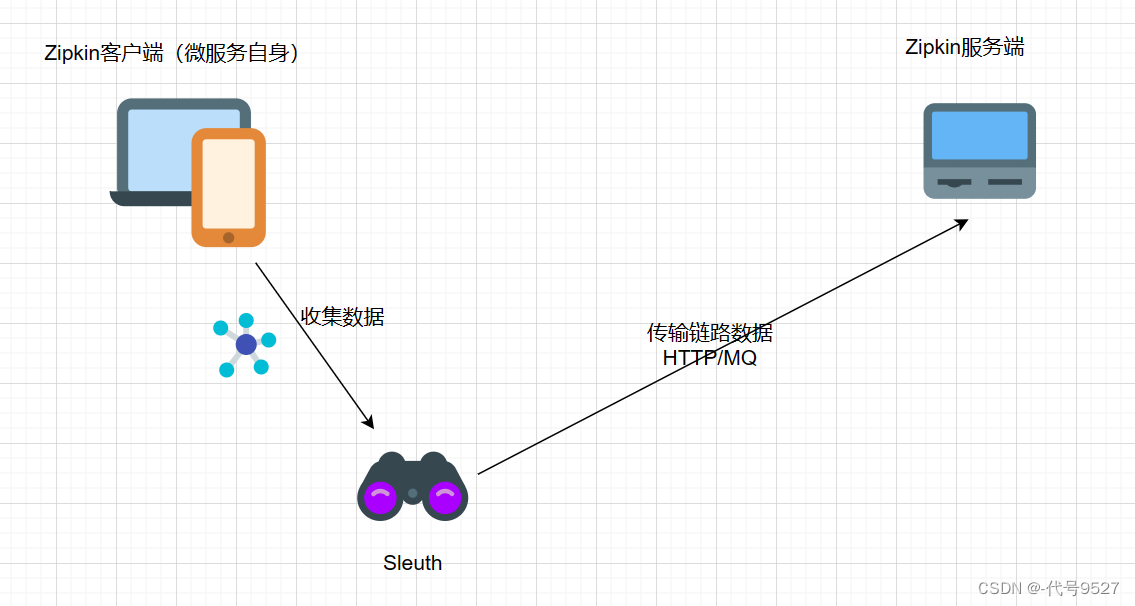
Zipkin 分为两端,一个是 Zipkin 服务端,一个是 Zipkin 客户端。客户端也就是微服务自身,客户端会配置服务端的 URL 地址,一旦发生服务间的调用的时候,会被配置在微服务里面的 Sleuth 的监听器监听,并生成相应的 Trace 和 Span 数据发送给Zipkin服务端。发送的方式主要有两种,一种是 HTTP 报文的方式,还有一种是消息总线的方式如 RabbitMQ。
4、Zipkin服务端安装
这里可以jar包启动,也可以在容器里启动,具体看官方文档,我采用jar包:
- 下载编译好的Zipkin-server的jar包
# zipkin-server-2.12.9-exec.jar版本下载
https://search.maven.org/remote_content?g=io.zipkin.java&a=zipkin-server&v=LATEST&c=exec
- cmd窗口运行jar包
# -Dserver.xxx=xxx参数按需自加
java -jar zipkin-server-2.12.9-exec.jar
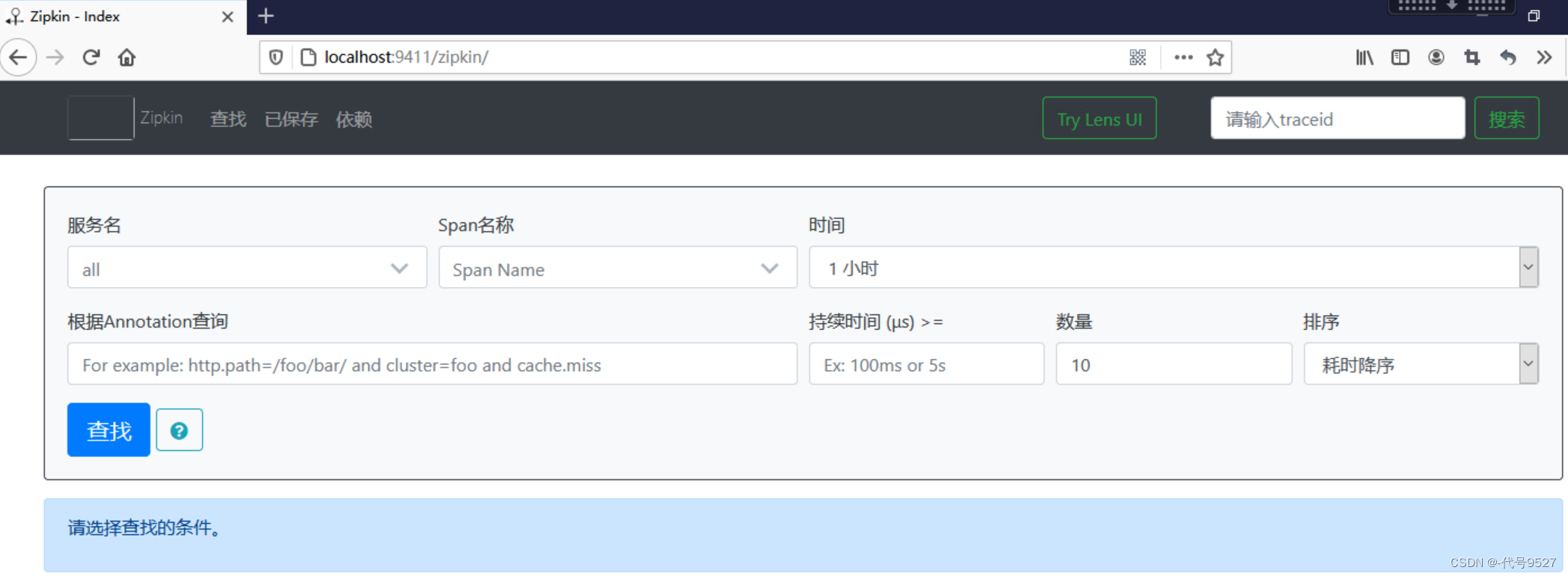
- 访问localhost:9411查看Zipkin服务端的管理控制台
5、搭配Sleuth整合客户端Zipkin
前面提到了,仅靠Sleuth收集到的链路日志信息来分析,相当低效,这里继续整合Zipkin来进行链路信息的存储、查找和可视化分析。
- 需要追踪的微服务中添加Zipkin客户端依赖
<!--zipkin依赖-->
<dependency><groupId>org.springframework.cloud</groupId><artifactId>spring-cloud-starter-zipkin</artifactId><version>2.2.0.RELEASE</version>
</dependency>- 修改application.yaml配置文件
spring:zipkin:base-url: http://127.0.0.1:9411/ #zipkin server端的请求地址sender:type: web #请求方式,默认以http的方式向zipkin server发送追踪数据sleuth:sampler:probability: 1.0 #采样的百分比,默认0.1,即10%,我这里写1,不想调那么多次,就看个效果- 重启微服务,调用一次接口,查看Zipkin控制台,点击链路,查看细节
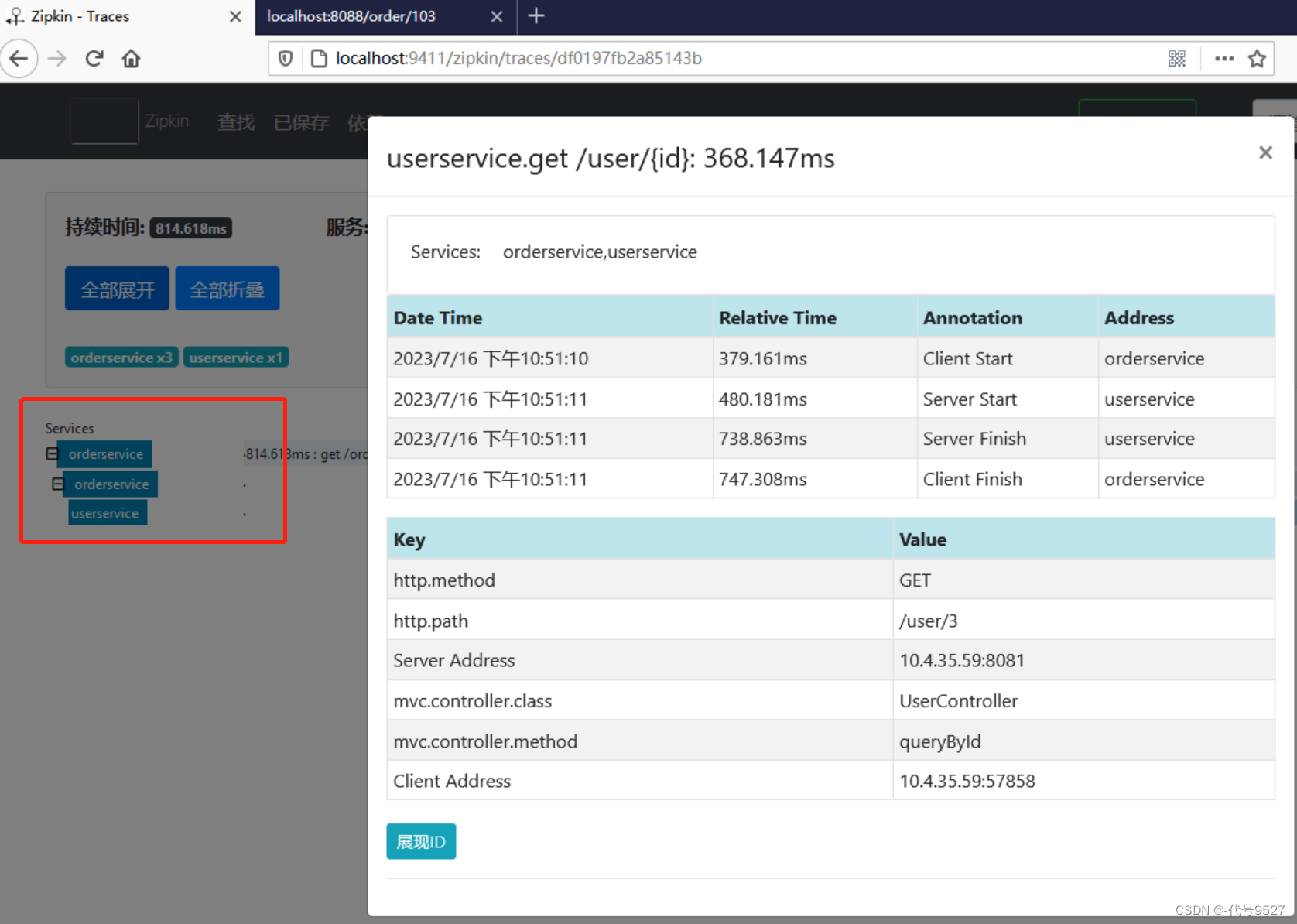
6、收集数据
在默认情况下,Zipkin客户端和服务端之间是使用HTTP请求的方式进行通信(即同步的请求方式),在网络波动,Server端异常等情况下可能存在信息收集不及时的问题。Zipkin支持与rabbitMQ整合完成异步消息传输。
- 起个RabbitMQ的容器,并把端口映射到宿主机上:
docker run -d -p 5672:5672 -p 15672:15672 rabbitmq:3-management
# 访问host:15672,用户和密码为默认的guest- 重新启动Zipkin的Server端,这次加参数,指定RabbitMQ的信息
java -jar zipkin-server-2.12.9-exec.jar --RABBIT_ADDRESSES=127.0.0.1:5672# RABBIT_ADDRESSES : 指定RabbitMQ地址
# RABBIT_USER: 用户名(默认guest)
# RABBIT_PASSWORD : 密码(默认guest)
# 起RabbitMQ容器时我就用默认账户,这里启动Zipkin不再加USER参数
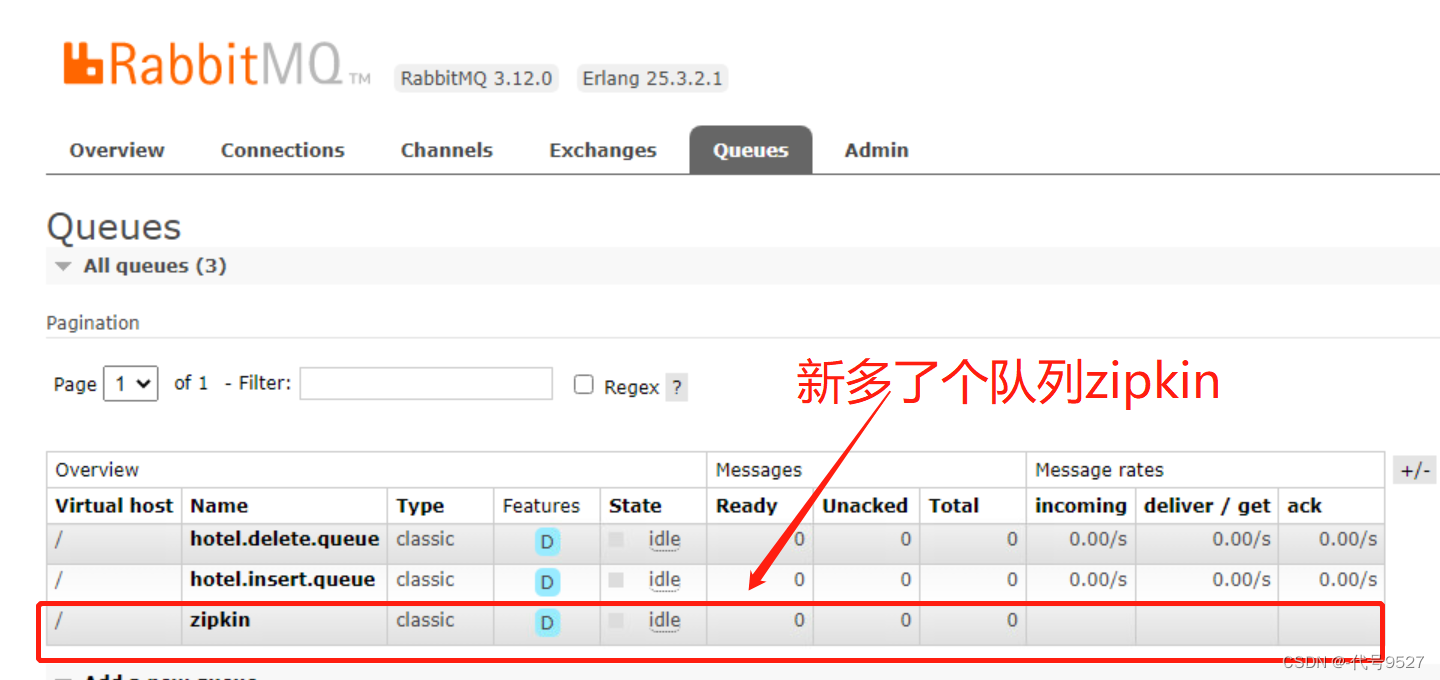
- 此时登录15672端口查看RabbitMQ,可以看到新多了个队列叫zipkin
- 在微服务中整合SpringAMQP,引入依赖:
<!--AMQP依赖,包含RabbitMQ-->
<dependency><groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-amqp</artifactId>
</dependency>- 在application.yaml配置文件中配置RabbitMQ的相关信息:
spring:rabbitmq:host: 192.168.150.101 # MQ服务器主机名port: 5672 # 端口virtual-host: / # 虚拟主机 username: guest # 用户名password: guest # 密码
- 别忘了把zipkin的sender.type改为rabbit,而不是web
spring:zipkin:# base-url: http://127.0.0.1:9411/ #zipkin server端的请求地址,此时可有可无,# 因为client向MQ写,server从MQ拿,启动zipkin时注意关联MQ的信息就行sender:type: rabbit
- 接下来做测试,先关闭Zipkin服务端,防止队列中的消息被立马消费,再调用一次微服务的某个接口
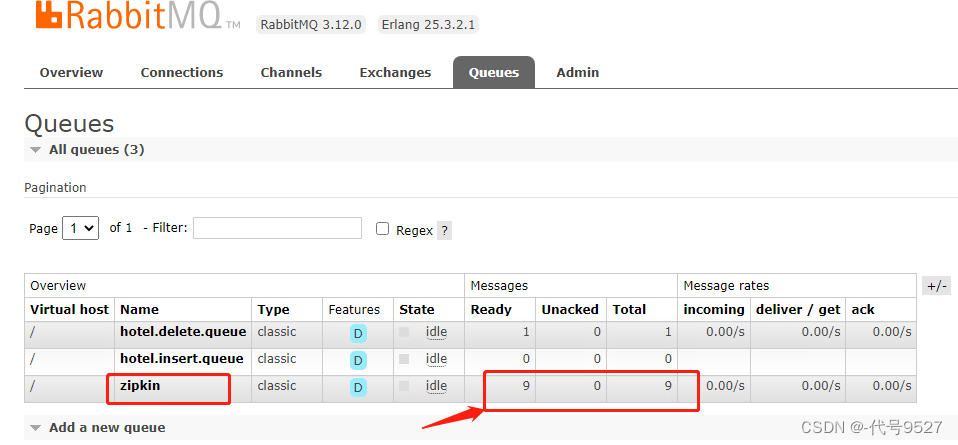
- 再启动Zipkin的服务端,可以看到MQ中的消息被成功消费:
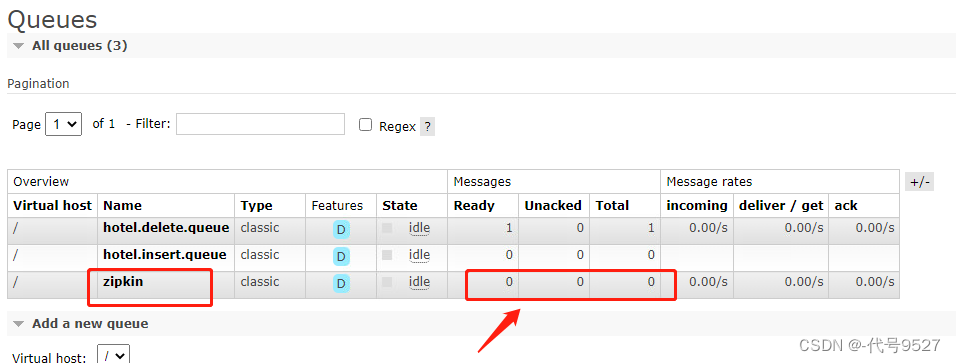
如此,即使Zipkin Server端不可用,或者网络不通,也不会丢失追踪信息。且Client端只要把信息丢MQ就算自己任务完成,耗时缩短。
最后,这里有些坑,比如zipkin队列有了,但是client端不往里面写数据,具体参考这篇:【spring cloud sleuth和zipkin常遇问题及解决方案】
7、存储trace数据
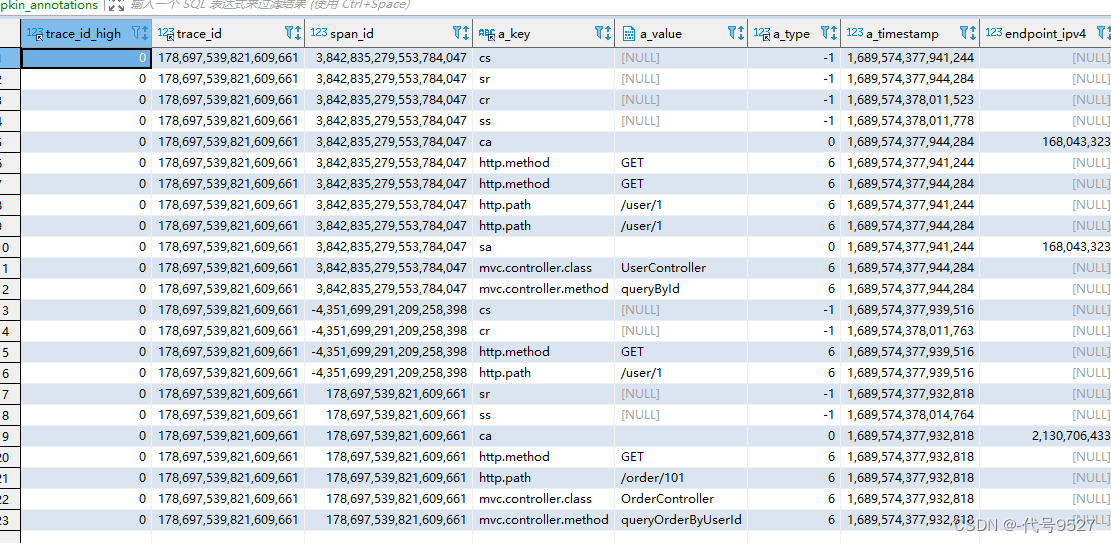
追踪的相关数据,Zipkin服务端默认存于内存中,Service重启或者异常会导致历史追踪数据消息,生产环境中应该将追踪数据持久化到MySQL或者ES中。
- 这里展示下存储到MySQL,在Zipkin官网复制MySQL建表语句并执行:
/*
SQLyog Ultimate v11.33 (64 bit)
MySQL - 5.5.58 : Database - zipkin
*********************************************************************
*//*!40101 SET NAMES utf8 */;/*!40101 SET SQL_MODE=''*/;/*!40014 SET @OLD_UNIQUE_CHECKS=@@UNIQUE_CHECKS, UNIQUE_CHECKS=0 */;
/*!40014 SET @OLD_FOREIGN_KEY_CHECKS=@@FOREIGN_KEY_CHECKS, FOREIGN_KEY_CHECKS=0 */;
/*!40101 SET @OLD_SQL_MODE=@@SQL_MODE, SQL_MODE='NO_AUTO_VALUE_ON_ZERO' */;
/*!40111 SET @OLD_SQL_NOTES=@@SQL_NOTES, SQL_NOTES=0 */;
CREATE DATABASE /*!32312 IF NOT EXISTS*/`zipkin` /*!40100 DEFAULT CHARACTER SET utf8 */;USE `zipkin`;/*Table structure for table `zipkin_annotations` */DROP TABLE IF EXISTS `zipkin_annotations`;CREATE TABLE `zipkin_annotations` (`trace_id_high` bigint(20) NOT NULL DEFAULT '0' COMMENT 'If non zero, this means the trace uses 128 bit traceIds instead of 64 bit',`trace_id` bigint(20) NOT NULL COMMENT 'coincides with zipkin_spans.trace_id',`span_id` bigint(20) NOT NULL COMMENT 'coincides with zipkin_spans.id',`a_key` varchar(255) NOT NULL COMMENT 'BinaryAnnotation.key or Annotation.value if type == -1',`a_value` blob COMMENT 'BinaryAnnotation.value(), which must be smaller than 64KB',`a_type` int(11) NOT NULL COMMENT 'BinaryAnnotation.type() or -1 if Annotation',`a_timestamp` bigint(20) DEFAULT NULL COMMENT 'Used to implement TTL; Annotation.timestamp or zipkin_spans.timestamp',`endpoint_ipv4` int(11) DEFAULT NULL COMMENT 'Null when Binary/Annotation.endpoint is null',`endpoint_ipv6` binary(16) DEFAULT NULL COMMENT 'Null when Binary/Annotation.endpoint is null, or no IPv6 address',`endpoint_port` smallint(6) DEFAULT NULL COMMENT 'Null when Binary/Annotation.endpoint is null',`endpoint_service_name` varchar(255) DEFAULT NULL COMMENT 'Null when Binary/Annotation.endpoint is null',UNIQUE KEY `trace_id_high` (`trace_id_high`,`trace_id`,`span_id`,`a_key`,`a_timestamp`) COMMENT 'Ignore insert on duplicate',KEY `trace_id_high_2` (`trace_id_high`,`trace_id`,`span_id`) COMMENT 'for joining with zipkin_spans',KEY `trace_id_high_3` (`trace_id_high`,`trace_id`) COMMENT 'for getTraces/ByIds',KEY `endpoint_service_name` (`endpoint_service_name`) COMMENT 'for getTraces and getServiceNames',KEY `a_type` (`a_type`) COMMENT 'for getTraces',KEY `a_key` (`a_key`) COMMENT 'for getTraces',KEY `trace_id` (`trace_id`,`span_id`,`a_key`) COMMENT 'for dependencies job'
) ENGINE=InnoDB DEFAULT CHARSET=utf8 ROW_FORMAT=COMPRESSED;/*Data for the table `zipkin_annotations` *//*Table structure for table `zipkin_dependencies` */DROP TABLE IF EXISTS `zipkin_dependencies`;CREATE TABLE `zipkin_dependencies` (`day` date NOT NULL,`parent` varchar(255) NOT NULL,`child` varchar(255) NOT NULL,`call_count` bigint(20) DEFAULT NULL,UNIQUE KEY `day` (`day`,`parent`,`child`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8 ROW_FORMAT=COMPRESSED;/*Data for the table `zipkin_dependencies` *//*Table structure for table `zipkin_spans` */DROP TABLE IF EXISTS `zipkin_spans`;CREATE TABLE `zipkin_spans` (`trace_id_high` bigint(20) NOT NULL DEFAULT '0' COMMENT 'If non zero, this means the trace uses 128 bit traceIds instead of 64 bit',`trace_id` bigint(20) NOT NULL,`id` bigint(20) NOT NULL,`name` varchar(255) NOT NULL,`parent_id` bigint(20) DEFAULT NULL,`debug` bit(1) DEFAULT NULL,`start_ts` bigint(20) DEFAULT NULL COMMENT 'Span.timestamp(): epoch micros used for endTs query and to implement TTL',`duration` bigint(20) DEFAULT NULL COMMENT 'Span.duration(): micros used for minDuration and maxDuration query',UNIQUE KEY `trace_id_high` (`trace_id_high`,`trace_id`,`id`) COMMENT 'ignore insert on duplicate',KEY `trace_id_high_2` (`trace_id_high`,`trace_id`,`id`) COMMENT 'for joining with zipkin_annotations',KEY `trace_id_high_3` (`trace_id_high`,`trace_id`) COMMENT 'for getTracesByIds',KEY `name` (`name`) COMMENT 'for getTraces and getSpanNames',KEY `start_ts` (`start_ts`) COMMENT 'for getTraces ordering and range'
) ENGINE=InnoDB DEFAULT CHARSET=utf8 ROW_FORMAT=COMPRESSED;/*Data for the table `zipkin_spans` *//*!40101 SET SQL_MODE=@OLD_SQL_MODE */;
/*!40014 SET FOREIGN_KEY_CHECKS=@OLD_FOREIGN_KEY_CHECKS */;
/*!40014 SET UNIQUE_CHECKS=@OLD_UNIQUE_CHECKS */;
/*!40111 SET SQL_NOTES=@OLD_SQL_NOTES */;- 重启Zipkin的服务端:
java -jar zipkin-server-2.12.9-exec.jar --STORAGE_TYPE=mysql --MYSQL_HOST=127.0.0.1 --MYSQL_TCP_PORT=3306 --MYSQL_DB=zipkin --MYSQL_USER=root --MYSQL_PASS=root123# STORAGE_TYPE : 存储类型
- 此时调用微服务某个接口,可以看到trace数据已被持久化到MqSQL表中: