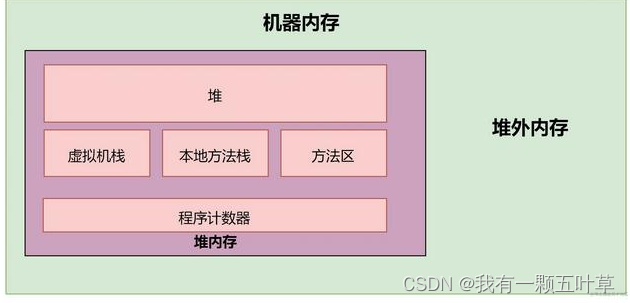
redolog(可以恢复数据,保证数据不丢失) 、undolog(事务回滚) 和binlog(主从同步数据)
脏页
在mysql中,当内存数据页和磁盘数据页上的内容不一致时,则称这个内存页为脏页
脏页什么时候会刷入磁盘?
● redo log 日志空间满的时候,会主动触发脏页刷新到磁盘中
● Buffer Pool 空间满的时候,需要根据淘汰算法,淘汰一些数据页,如果淘汰的页是脏页的话,需要先将脏页刷新到磁盘中。
● MySQL认为空闲的时候,后台线程会定期将脏页刷新回磁盘中。
● 关闭MySQL的时候,会将所有的脏页刷新回磁盘中。
Mysql日志主要包括
1、慢查询日志:记录执行时间超过long_query_time的所有查询,方便我们对查询优化
2、通用查询:日志:记录所有连接的起始时间和终止时间,以及连接发送给数据库服务器的所有指令,对我们复原操作的实际场景、发现问题,甚至是对数据库操作的审计都有很大的帮助。
3、查询日志:错误日志:记录MySQL服务的启动、运行或停止MySQL服务时出现的问题,方便我们了解服务器的状态,从而对服务器进行维护。
4、二进制日志(bin log):记录所有更改数据的语句,可以用于主从服务器之间的数据同步,以吸服务器遇到故障时数据的无损失恢复。
5、中继日志:用于主从服务器架构中,从服务器用来存放主服务器二进制日志内容的一个中间文件。从服务器通过读取中继日志的内容,来同步主服务器上的操作。
6、数据定义语句日志:记录数据定义语句执行的元数据操作。
redo log
首先明确,redo是InnoDB引擎特有的。记录着事务里对数据的修改。
在mysql中,如果修改了数据,那么事务提交前,首先会被记录成redo日志写入磁盘,等到事务提交时,再把新数据写入磁盘。
这也就是经常说的WAL(Write-Ahead Logging)。
redo log 称为重做日志 ,是储存引擎层(innodb)生成的日志。提供再写入的操作,回复提交事务修改页的操作,用来保证事务持久性,假如说发生宕机,可以进行恢复数据,保证持久性,。他记录的是“物理级别”上的页修改操作,比如页号x,偏移量y,写入了“”ds‘’数据。为了保证数据的可靠性;
undo log
undo log 称为回滚日志,也是是储存引擎层(innodb)生成的日志。回滚记录到某个特定的版本,用来保证事务原子性,一致性。主要用于事物的回滚 和 一致性非锁定读(undo log 会滚到记录某种特定的版本—mvcc,也就是多版本并发控制)。其实现原理借鉴以下图片
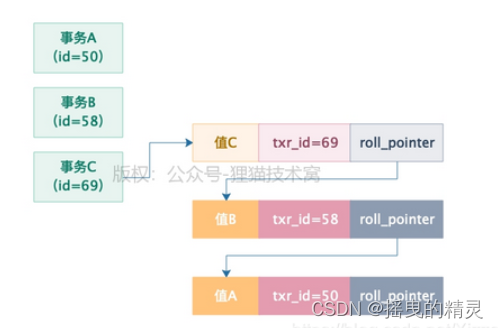
他是不断指向上一个日志链条,以此实现回滚。
好处:
redo日志降低了刷盘频率
占用空间非常小(只是储存空间ID、页号、偏移量和需要更新的值)
特点
顺序写入磁盘(每执行一条语句就可能产生redo日志,这些日志是按顺序写入磁盘的)事务执行过程中,redo不断记录,假设一个事务我们插入10万数据,在这个过程,redo 会不断地记录。但是bin log(数据库层产生) 不会记录,直到事务提交完成才一次性写入
组成
redo log buffer 和 redo log file
redo log buffer
保存在内存之中,容易丢失
每次启动时后就会申请一大片称之为redo,log buffer的连续空间,然后这款空间再被划分成若干连续的redo log block 。一个 block占512字节
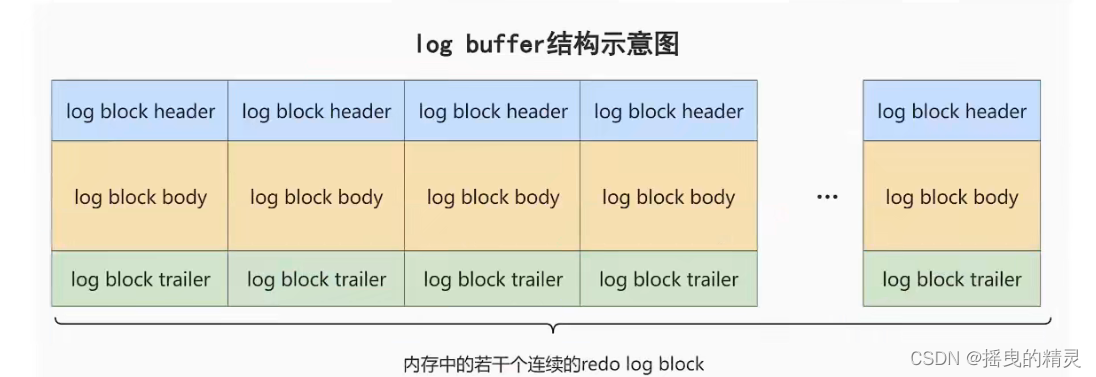
参数设置:innodb_log_buffer_size
默认16MB ,最大值4096M ,最小值1M
redo log file
保存在磁盘中,是最持久的
默认存储当前文件夹下

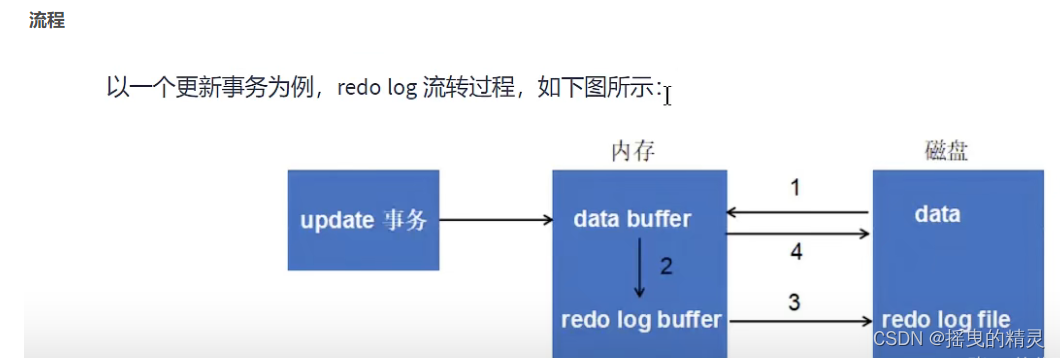
第1步:先将原始数据从磁盘中读入内存中来,修改数据的内存拷贝
第2步:生成一条重做日志并写入redo log buffer, 记录的是数据被修改后的值
第3步:当事务commit时,将redo log buffer中的内容刷新到redo log file, 对redo log file采用追加写的方式
第4步:定期将内存中修改的数据刷新到磁盘中
redo log 的刷盘策略
其实就是redo log buffer 到 redo log file 的过程
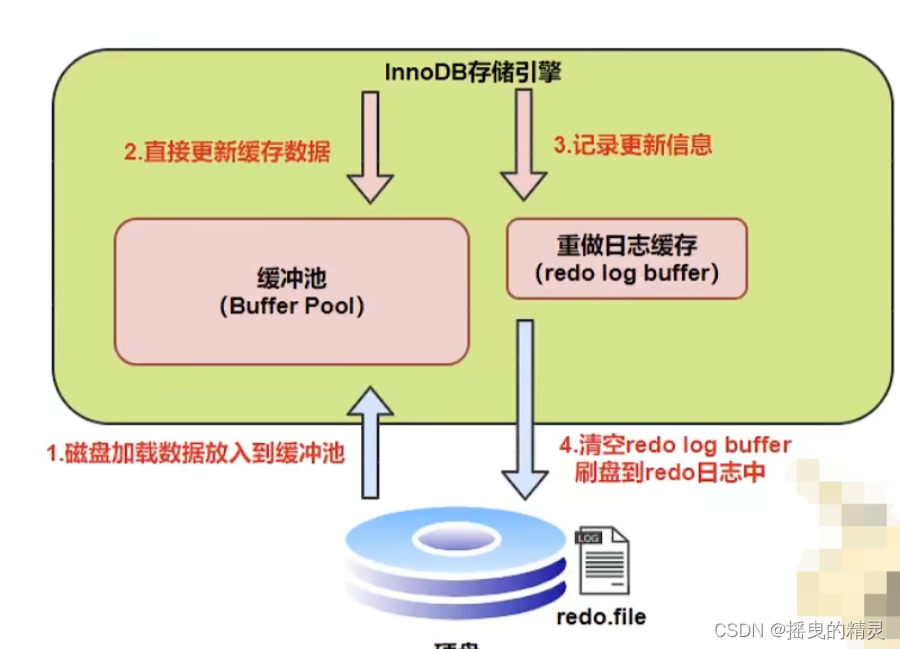
InnoDB给出 innodb_ flush_ .log- at_ trx .commit 参数,该参数控制commit提交事务时,如何将redo log buffer中的日志刷新到redo log file中。它支持三种策略:
●设置为0 :表示每次事务提交时不进行刷盘操作。 (系统默认master thread每隔1s进行一次重做日志的同步) 有可能丢失数据
●设置为1 :表示每次事务提交时都将进行同步,刷盘操作(默认值) 安全性好 效率差
●设置为2 :表示每次事务提交时都只把redo log buffer内容写入page cache,不进行同步。由os自己决定什么时候同步到磁盘文件。
Undo log
简介
undo log 称为回滚日志,也是是储存引擎层(innodb)生成的日志。回滚记录到某个特定的版本,用来保证事务原子性,一致性。主要用于事物的回滚 和 一致性非锁定读(undo log 会滚到记录某种特定的版本—mvcc,也就是多版本并发控制)。其实现原理借鉴以下图片
作用1:回滚数据
undo是逻辑日志,只是将数据库逻辑地回复到原来的样子。所有的修改被逻辑的取消了,但是数据结构和页本身和之前大不相同,
作用2:MVCC
mvcc是通过undo来完成的,当用户读取一条行记录时,若该记录已经被其他事务占用,当前事务可以通过undo读取之前的行版本信息,以此实现非锁定读取
读已提交如何基于ReadView机制实现的
RC级别的核心是每次发起查询都重新生成一个ReadView。第一次查询的时候,发现数据的trx_id在自己的min和max之间和m_ids之中,所以它是一个活跃的事务修改的,并且此时尚未提交,所以它会顺着undo log版本链查找以及提交的事务。第二次查询的时候,重新开启一个新的READ VIEW,发现数据的trx_id不在m_ids中,说明该事务已经提交,所以直接读取数据行的数据。这就是RC级别的实现原理。
可重复读如何基于ReadView实现的
可重复读的核心是只在事务开始时生成一个ReadView,后续再次读的时候,即使事务B提交了,但是事务A它的ReadView还是刚开始事务时的,所以认为B还是活跃的,所以继续沿着undo log版本链查询,读取到始终一样。MySQL的可重复读还解决了幻读,因为新插入的数据记录的trx_id要么大于事务A的max_trx_id,要么在m_ids之中 (而且非本身)所以认为插入的数据记录时不能被读取的。
储存结构
1、回滚段与undo页
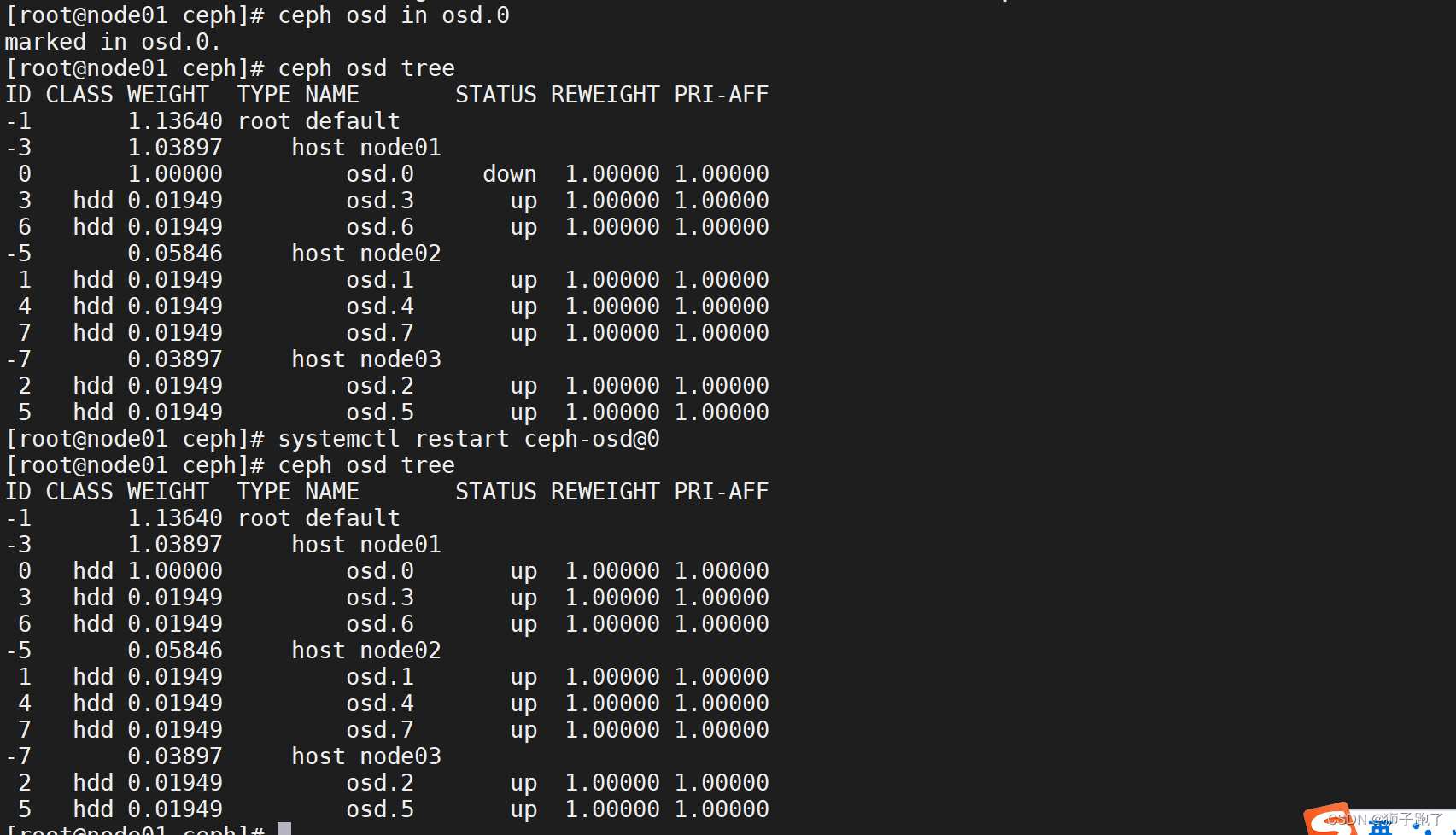
InnoDB对undo log的管理采用段的方式,也就是回滚段(rollback segment) 。每个回滚段记录了1024个undo log segment ,而在每个undo log segment段中进行undo页的申请。
●在InnoDB1.1版本之前 (不包括1.1版本) ,只有一个rollback segment, 因此支持同时在线的事务限制为1024。虽然对绝大多数的应用来说都已经够用。
●从1.1版本开始InnoDB支持最大128个rollback segment ,故其支持同时在线的事务限制提高到了
128*1024。
undo页的重用
当我们开启一个事务需要写undo log的时候,就得先去undo log segment中去找到一个空闲的位置,当有空位的时候,就去申请undo页,在这个申请到的undo页中进行undo log的写入。我们知道mysql默认- -页的大小是16k。为每一个事务分配一个页, 是非常浪费的(除非你的事务非常长),假设你的应用的TPS (每秒处理的事务数目)为1000, 那么1s就需要1000个页,大概需要16M的存储,1分钟大概需要1G的存储。如果照这样下去除非MySQL清理的非常勤快,否则随着时间的推移,磁盘空间会增长的非常快,而且很多空间都是浪费的。于是undo页就被设计的可以重用了,当事务提交时,并不会立刻删除undo页。 因为重用,所以这个undo页可能混杂着其他事务的undo log。undo log在commit后,会被放到一一个链表中,然后判断undo页的使用空间是否小于3/4,如果小于3/4的话,则表示当前的undo页可以被重用,那么它就不会被回收,其他事务的undo log可以记录在当前undo页的后面。由于undo log是离散的,所以清理对应的磁盘空间时,效率不高。
流程图
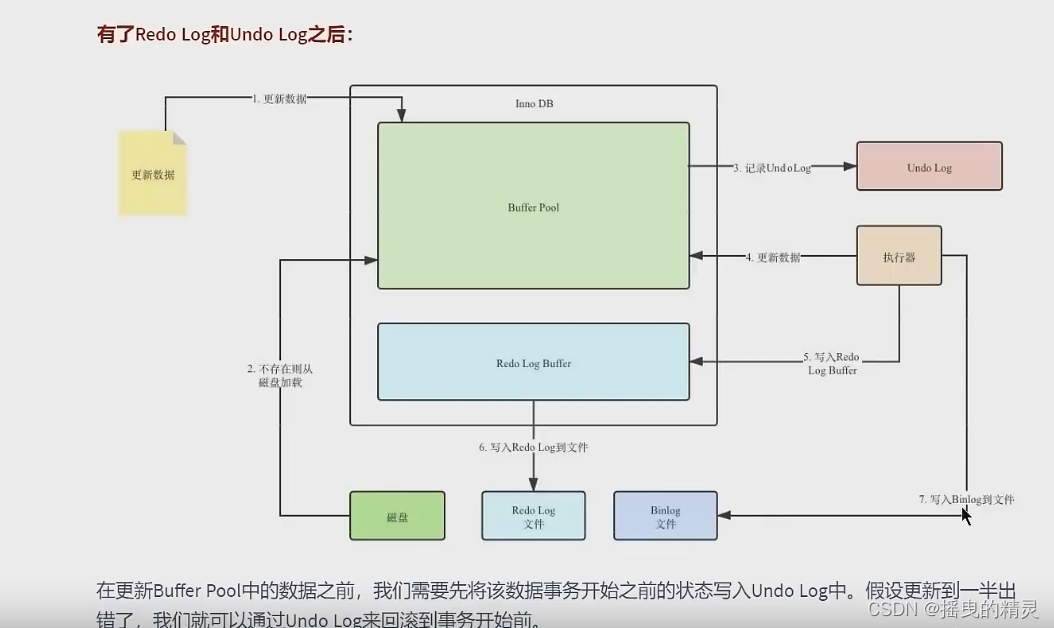
undo的版本回滚是基于ReadView机制
bin log
简介
binlog即binary log,二进制日志文件,也叫作变更日志(update log)。它记录了数据库所有执行的DDL和DML等数据库更新事件的语句,但是不包含没有修改任何数据的语句(如数据查询语句select、show等) 。它以事件形式记录并保存在二进制文件中。通过这些信息,我们可以再现数据更新操作的全过程。
应用场景
1、数据恢复:如果MySQL数据库,意外停止,可以通过二进制的文件夹来查看用户执行了哪些操作,对数据库服务器文件做了哪些修改,然后根据二进制文件中的记录来恢复数据库服务器。
2、数据复制: 有数据库的延续性和时效性,master把他的二进制日志传递给slaves来达到master-save数据一致的目的
mysql数据库的数据备份 数据备份、主备、主主 ,主从都离不开binlog
写入机制
binlog写入时,事务执行过程中,先把日志写到binlog cache ,事务提交的时候,再把binlog cache写到binlog文件中。因为一个事务的binlog不能被拆开, 所以无论这个事务多大,也要确保一次性写入, 所以系统会给每个线程分配一个块内存作为binlog cache。我们可以通过binlog_ cache_ size 参数控制单个线程binlog cache大小,如果存储内容超过了这个参数,就要暂存到磁盘(Swap) 。主要流程如下

write和fsync的时机,可以由参数sync_ binlog 控制,默认是0。
为0的时候,表示每次提交事务都只write,由系统自行判断什么时候执行fsync。虽然性能得到提升,但是机器宕机,page cache里面的binglog会丢失
为1的时候,表示每次提交事务都会执行fsync,就跟redo log的刷盘流程一样
sync_ binlog可以设置成一个较大的数N,表示每次提交事务都会write但是只有当提交事务的数量到达N的时候才会刷盘。
binlog和redolog对比
●redo log它是物理日志,记录内容是“在某个数据页上做了什么修改”,属于InnoDB存储引擎层产生的。
●而binlog是逻辑日志,记录内容是语句的原始逻辑,类似于“给ID=2这- -行的c字段加1”, 属于MySQL Server层。
●虽然它们都属于持久化的保证,但是则重点不同。
redo log让InnoDB存储弓|擎拥有了崩溃恢复能力。
bin log 保证了My$QL集群架构的数据一致性。
redo的好处
那么为什么需要redo呢?
1.保证数据的持久性。众所周知,数据是记录在磁盘上的,如果事务提交后mysql突然挂了(比如断电之类的),那么内存里的数据,是不是就丢失了?我们数据恢复时候,通过redo 就可以恢复回来。
解释:因为我们在事务提交前都已经把相关日志写入了磁盘,所以碰到意外当然可以恢复。如果写redo的时候断电了呢?大致上可以认为事务回滚了。不过没这么简单,到底是回滚还是提交,还牵扯到bin log。我们下文会讲到。
2.redo只是记录了对数据的修改,数据会比一页数据小得多。大大减少了IO频率。
当然,写redo并不是一条条写的。因为一条redo日志并不是写入的最小单位,一般来说至少都是几条一起写。这是因为一条修改语句对B+树的修改,绝大多数情况下都不会是只产生一个修改点,比如你要插入一条数据,叶子节点容不下了,那么就可能页分裂,同时还会更新许多内节点的信息。所以这一系列对底层B+树的操作,都会以一组的形式去写入磁盘。
具体的写入过程下文会讲。现在只需要知道,一个事务会包含许多SQL,而一条SQL修改语句,会产生很多组redo就行了,而这一组(学名:Mini-Transaction)才是写入的最小单元。
3.redo日志的写入是顺序IO。而修改磁盘的B+树是随机IO。
解释:redo就是往一块硬盘的某个相邻的区域写就完事了。如果要直接去修改B+树,很可能这些页并不相邻,寻址会很慢的。当然,固态硬盘的随机IO会好很多。
redo log的空间重用
checkpoint是一个过程。当负责刷脏页的后台线程刷不动了(此时磁盘上的redo日志文件被写满了),就需要用户线程帮忙标记下,看看哪些redo日志可以被覆盖。
具体来说,redo文件里有一个偏移量(学名叫checkpoint_lsn),偏移量小于此值的redo日志可以被覆盖。当后台线程刷不动的时候,就意味着文件已经写到了上次checkpoint_lsn标记的地方。此时用户线程需要去写入日志文件里checkpoint_lsn的值。改完后后台线程就可以继续刷刷刷了。
总结:因为redo写满了,需要用户线程去写入chechpoint_lsn值的过程就是checkpoint
redo什么时候写入磁盘
1.后台线程刷刷刷。
2.后台线程刷不动了(其实就是磁盘日志写满了),用户线程就会去写入checkpoint的值。使得部分redo文件可以被重写。
3.事务提交时。脏页可以不写,但是redo log在提交前必须写!
4.log bugger空间不足。
5.正常关闭服务器。
因为mysql提交时,是采取了两段提交协议的:
1.redo log 处于prepare阶段,日志写入到磁盘。
2.写入binlog。
3.提交事务。