五大原则
想要让ChatGPT产出有效的回答,需要遵循以下五个原则:
提问清晰:
请尽可能清晰地描述您的问题
简明扼要:
请尽量使用简单的语言和简洁的句子来表达您的问题
确认问题:
请确认您的问题是清晰、明确和完整
单一提问:
请一个一个地问,而不是把所有问题放在一个问题中
不要提供敏感信息:
请不要在您的问题中提供任何个人敏感信息
三要素
提示的特定格式,一般包含 了个主要元素:
角色(role):
在生成文本时,模型应该扮演什么。
任务(task):
一份清晰简洁的陈述,提示要求模型生成的内容。确保输出的相关性、高质量。
动词:编号、总结、分类、翻译、排序、查找、分析、评估、改进、开发、优化等
名词(输出载体):句子、段落(或摘要)、文章、邮件、表格、代码/程序、求职信、论文、案例研究、合同、指南、剧本、歌词/诗歌、商业/运营/财务/营销计划等
指示 (instructions):
在生成文本时,模型应该遵循什么。越直接,信息越有效。
形容词:300字的xx,20个xx的,正式或非正式的、通俗易懂的、严肃的、幽默的、有说服力的、鼓舞人心的、讽刺的、强烈的、深思熟虑的、充满激情的、浪漫的、冷静的、富有想象力的、欢乐的、暖心的、令人兴奋的等。
前导信息/上下文:提供来自x的数据或研究报告、客户数据、目前已有的代码、我已完成的工作内容等
总结:你是谁,我需要你干什么。其中,你需要遵守或知晓什么。
Prompt十大技巧
1.角色设定
在编写Prompt时,需要设定角色,以便Al模型更好地理解我们的问题。
提示:假定你是xxx方面的专家,…(对应英文为:You're an expert in ...)
改进的提示:
你现在是一个数据仓库工程师,你不用直接操作数据库,我会给你数据库的DDL,指标体系。我希望你能帮我完成业务的建模。当建模时有什么东西需要提供,你要及时向我反馈。我们的数仓分为ODS层,dwd层,dws层和ads层。数仓工具使用hive, 当你要创建表时,应当指明这张表属于数据的哪一层
角色设定参考: https://github.com/f/awesome-chatgpt-prompts

2.清除记忆
提示:回复此条对话前,请忽略前面所有的对话。(英文:Ignore all previous instructions before this one.)
因为ChatGFT是基于聊天进行的模型,它会记住或跟踪您之前写的所有聊天记录。如果之前你的角色设定是体育老师,下面又问数学问题,那就会出现“你的数学是体育老师教的”问题。
所以这句话的使用可以使得接下来的结果生成与前面聊天内容无关。
3.提供需求细节
在编写Prompt时,需要提供尽可能多的细节,以便A模型更好地理解我们的需求。
我想在使用flume将linux本地目录里的数据同步到hdfs上
请帮我写一个agent的配置来完成这项功能
1, 使用taildir source司生/opt/module/gpt/data下的数据
2.使用file channel
3. 写到hdfs的/data/gpt目录下
输出的文件请使用gzip格式压缩
4.step by step
提示:你必须一步一步地解释所有的事情。(英文:step by step)
"step by step’在现代工程界称为 零思维链。它会让人工智能一步一步地思考,井以逻辑精确和详细的方式得到结果,而不仅仅是一般信息。尤其对于数理逻铜问题特别有用。
5. 关注目标受众
提示:假设你是一个从事xx多年的xx,而我是一个没有基础的x岁的小孩子(或没有相关行业背景的小白用户)
这样可以让ChatGPT用通俗易懂的语言来解释,没有太多专业术语,适于用户汇报。
6.要提“todo” 不提“not todo“
避免描述不应该做什么,而是描述应该做什么。这样可以提高提示的具体性,同时使得模型更容易理解并产生良好的响应
举例1:
普通的提示:请对上述产品进行描述,几句话就行,不要太多
更好的提示:使用3到5句话,对上述产品进行描述
当然并不是 Not Todo 就不能用。如果你已经告知模型很明确的点,然后你想縮小范围,那增加一些 Not Todo 会
提高不少效率。
7.使用"""指令
可以用"““将指令和文本分开。根据我的测试,如果你的文本有多段,增加””"会提升 Al反馈的准确性(这个技巧来自于 OpenAl 的API 最佳实践文档)
普通的提示:
请总结以下句子,使它们更容易理解。
OpenAl 是一家美国人工智能(A) 研究实验室,由非营利性 OpenAl Incorporated (0penAl Iinc) 及其营利性子公司 OpenAl Limited Partnership (OpenAl LP) 组成。OpenAl 进行 Al 研究的目的是促进和开发友好的Al。 OpenAl
系统运行在世界上第五强大的超级计算机上。 该组织于 2015 年由 Sam Altman、 Reid Hoffman、 JessicaLivingston、Elon Musk、 Ilya Sutskever、Peter Thiel 等人在1日金山创立,他们共同认捐了 10 亿美元。马斯克千2018 年辞去董事会职务,但仍是捐助者。微软在 2019 年向OpenAILP提供了10 亿美元的投资,并于
2023 年1月向其提供了第二笔多年期投资,据报道为 100 亿美元。
更好的提示:
请总结以下句子,使它们更容易理解。
文本:""
OpenAl 是一家美国人工智能(A)研究实验室,由非营利性 OpenAl Incorporated (OpenAl Inc.) 及其营利性子公司 OpenAl Limited Partnership (OpenAl LP) 组成。 OpenAl 进行 Al 研究的目的是促进和开发友好的Al。 OpenAl
系统运行在世界第五强大的超级计算机上。该组织于 2015 年由 Sam Altman、 Reid Hoffman、 JessicaLivingston、 Elon Musk、 llya Sutskever、Peter Thiel 等人在1旧金山创立,他们共同认捐了 10 亿美元。马斯克于2018 年辞去董事会职务,但仍是捐助者。微软在2019 年向 OpenAl LP 提供了10 亿美元的投资,并于
2023 年1月向其提供了第二笔多年期投资,据报道为 100 亿美元。"""
8.让GPT提问
提示:在你要产生回复之前 你有任何问题可以问我。(英文:If you have any questions about this, ask before you try to generate content.Ok?)
9.“让我们想一下”
“让我们想一下“这个提示,生成的文本具备反思能力、深度思考,对写散文,写诗歌、创意写作的群体来说很有帮助。
提示1:让我们想一下气候变化对农业的影响
提示2:让我们讨论下人工智能的现状
提示3:让我们谈一下远程工作的好处和坏处
还可以添加一个开放式问题、陈述,或者添加一段希望模型继续的文本,一段建立在其基础之上的文本。
这种独特的提示,有助于 ChatGPT 以不同视角、不同角度给出答案,让产出更具活力、更具信息量。
10.use English
中文的回答不好时,翻译成英文试试,因为训练集中文占比不到1%。
GPT不擅长的任务
1.精确查询类任务
在使用ChatGFT的时候,一定要记住, ChatGFT的内容是“生成”的而不是“搜索”的,也有称GFT的交互方式为“概率鹦鹉”。
因此,它并不适合用来做一些需要精准查询的任务。比如,识别ChatGPT写的学术论文的一种非常有效的方式就是检查这篇文章的参考文献是否真实存在
2.长上下文任务
GPT模型有一个最大tokens限制,即输入内容和输出内容的总单词数量 (例如4096tokens)在单词问答中。因此,ChatGFT的上下文理解能力是有限的。随着会话时间的延长,模型处理过去信息的能力会受到限制,从而导致遗忘之前的内容。
ChatGPT主要 依赖于短期记忆 来处理当前输入。它没有一个有效的长期记忆机制来保存之前的信息。在GFT刚出现时,曾经有一个将PDF文档灌入GPT来写综述的软件。但是,由于一个PDF对于 GPT模型来说过于元长,导致计算质量迅速下降,因此用户体验很差。
3.实时信息任务
ChatGFT的训练数据截至日期是2021年9月,所以ChatGPT无法提供之后发生的事件、新闻或趋势的信息。
推荐插件一:
WebChatGFT:可访问互联网的 ChatGPT
推荐插件二:
ChatGPT for Google 在搜索引擎结果中同时显示ChatGPT的回答
4.模糊问题
在向GPT询问问题时应当尽可能确保问题本身是精确的, 没有歧义的。如果问题本身的含义需要GPT进行推断和预测,那么回答的质量就会大大降低。因此,应将问题整理清楚后 再问ChatGPT。
5.高度专业的问题(小众问题)
越是专业度高的问题,它对应解决方案的模型训练数据就越少。既然我们说ChatGPT是“概率鹦鹉”,那么我们在用它的时候,就应该尽可能少地用它处理小众问题。对技术专家来说,专业问题是逻辑推理,对GPT来说,却是小概率事件。
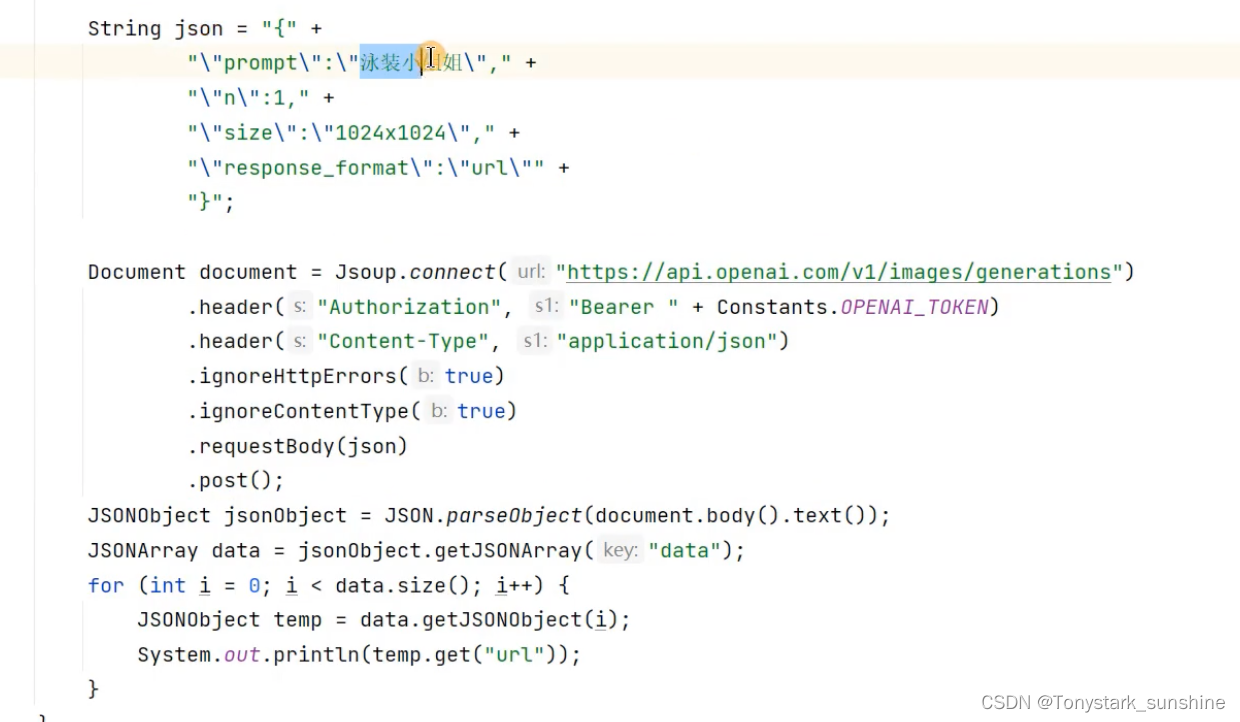
Java调用openAI的API进行程序开发
示例一:返回文本
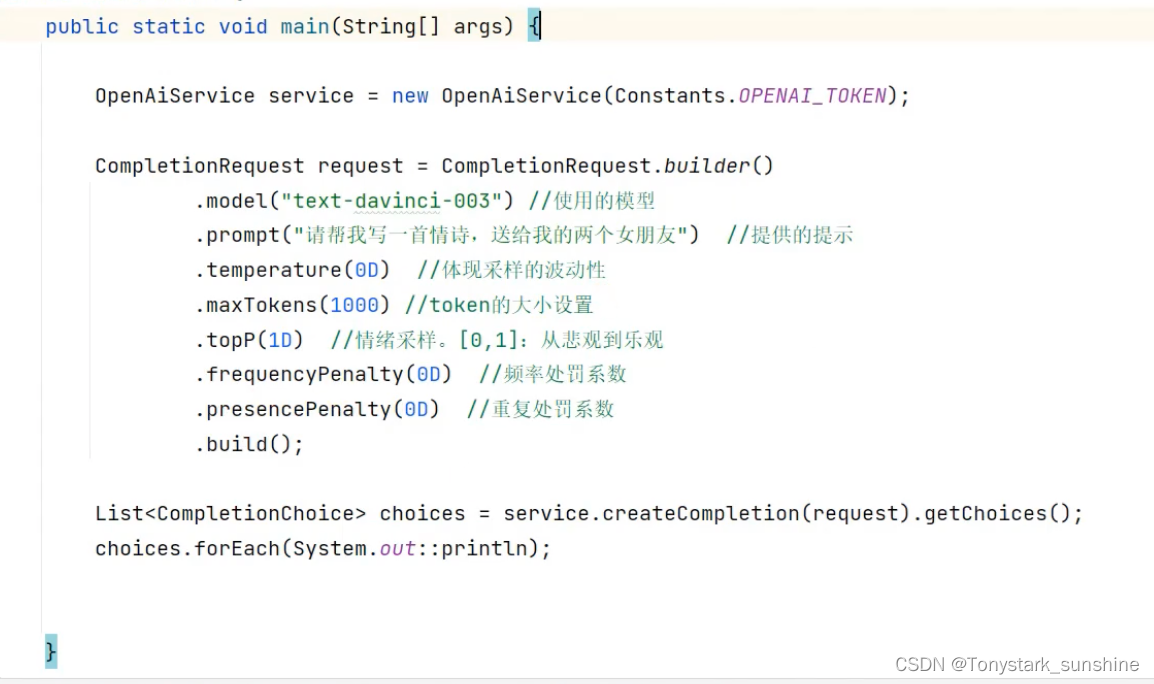
示例二:返回图片