用`qteasy`+`tushare`实现金融数据本地化存储及访问
- 目的
- 什么是`qteasy`
- 什么是`tushare`
- 为什么要本地化
- 使用qteasy创建本地数据仓库
- qteasy支持的几种本地化仓库类型
- 配置本地数据仓库
- 配置`tushare` 的API token
- 配置本地数据源 —— 用MySQL数据库作为本地数据源
- 下载金融历史数据
- 数据的定期下载
- 更多用法请参见文档
目的
做量化投资或者对量化交易感兴趣的朋友应该都需要用到大量的金融数据,例如股票价格,基金净值、上市公司技术指标和财务指标等等。但是,如何有效、可靠地获取金融数据,并且有效地使用,却是一个令人头疼的问题。在这篇文章中,我想跟大家交流我的使用心得,分享我的最佳实践——建立一个本地数据仓库、定期拉取数据;按照这个最佳实践,可以实现以下功能:
- 数据本地化存储,实现数据高速查询,没有数量限制
- 定期下载数据,实现去重和清洗,保持本地数据最新
以上的功能通过qteasy+tushare来实现,可以比较容易地整合到量化投资系统里去。
什么是qteasy
qteasy是本人正在开发的一个快速量化交易工具包,完全免费使用。利用这个工具包,可以快速灵活地生成各种量化交易策略,生成历史数据并回测策略的表现,有针对性地优化策略的性能;还能模拟实盘自动化交易;不仅如此,qteasy还内嵌了tushare,可以快速建立一个本地数据仓库,实现大量金融数据的快速下载、清洗、存储和快速调用。qteasy目前最新版本为v1.0.14,并且正在不断迭代中,最新版本可以通过pip安装。
python -m pip install qteasy
qteasy的Github项目地址在这里
请访问qteasy文档获取更多信息
什么是tushare
tushare是一个立足于国内的金融数据包。通过它可以相当容易地获取包括股票、基金、期货在内的大量金融数据,使用非常简便而且基础功能免费。
tushare的早期版本是完全免费的,不过功能也相对单一,后来升级到了tushare pro之后,支持的数据种类大大扩展,同时也开启了积分的功能,部分高级数据获取功能是需要一定积分的,积分通常需要付费而且每年都需要支付。不过,平心而论,相比早期版本,升级到pro版本后,数据的丰富程度、数据提取速度和稳定性、可靠性都大大提升,相比获得的提升,支付一点点费用完全可以说是物超所值的。
这里是tushare的 文档链接。使用pip安装qteasy时,会自动安装tushare。
为什么要本地化
现在有一些金融数据包提供了在线实时读取金融数据的功能,但是,如果每次都使用在线下载的方式获取金融数据,会有不少问题:
- 网络连接不够可靠:不管网络速度有多快,从服务器上获取数据的速度总归是一个大问题,尤其是需要获取大量数据的时候,还容易出现连接失败的问题。
- 单次下载信息量受限:
tushare有一些特殊的下载限制要求,比如某些数据单次下载最多不能超过5000行数据,或者某些数据单次下载限定了股票的数量等等,为了获取完整的数据,比如所有指数的指标,就必须分批下载,进一步降低速度。 - 增加服务器负载:当然,这是从
tushare的角度来考虑的,如果所有人都依赖于从服务器上下载数据,tushare的服务器很快就会超负荷
因此,最佳实践是使用qteasy建立一个本地数据仓库,并创建一个定期拉取程序,需要数据的时候从本地数据仓库中获取,同时定期运行数据拉取程序,将最新的数据下载并合并到本地数据仓库中,确保数据仓库中的数据时时最新。
使用qteasy创建本地数据仓库
安装好qteasy后,只需要简单的配置,就可以快速建立数据仓库了。qteasy数据仓库内置了相当完整的数据类型清单,涵盖股票、指数、基金、期货、期权等投资品种,数据类型除量价、K线数据以外,还内置了几乎所有常见的股票技术指标、宏观经济数据、上市公司基本信息,以及完整的财务报表数据等等信息。
部分支持的数据如下表:
所有上面提到的这些信息,qteasy都给它们赋予了一个唯一的数据类型标识,通过这个数据类型标识,用户可以用一行代码就从网上下载相应的历史数据,并将它们存储到本地。在下载的过程中,qteasy会自动完成数据清洗、归类、去重,并将数据分门别类存储到多张不同的数据表中。
在需要数据的时候,同样只要通过数据类型标识,也仅仅通过一行代码,即可从数据仓库中读取相应的数据,同时还具备自动的数据频率调整、插值功能,也具备较完善的数据可视化功能,以方便用户使用。
qteasy支持的几种本地化仓库类型
金融数据的量是非常大的,尤其是高频数据。比如,仅沪深股市所有上市股票的分钟级K线数据量就超过200GB,其余期货、期权、基金、指数等数据量也在几十到数百GB的量级。不过如果是日频数据,例如过去20年所有A股股票的日K线数据,全部加起来也不过只有10G不到。
因此,建议大家根据自己的数据使用频率来规划相应的磁盘空间,如果需要使用高频数据,建议使用NAS系统,或者至少需要有一个足够大的硬盘。首先规划好至少1TB的磁盘空间准备用来存储所需的数据是必要的。如果只需要短期内的低频数据,本地文件存储也就足够了。
使用qteasy,可以选择采用不同的文件形式来存储本地数据仓库:
- 本地文件存储 (默认文件格式为csv,除此以外还可以选择hdf5和feather文件类型)
- mysql数据库存储
两种方法各自有优缺点。默认的csv文件优点在于上手简单,不需要特殊配置,而且文件内容可以直接使用Excel等软件查看,支持超大的文件(但是文件太大用Excel就不容易打开了),但是读取速度慢,安全性和稳定性差,mysql正好相反,上手稍微复杂一些,需要配置数据库,需要有一些数据库基础,但是速度快、稳定性好。
还是那句话,各人需要根据自己的实际需要选择合适的存储方式,如果需要用到大量高频数据,首选mysql作为数据仓库存储介质,如果数据量不是特别大的话,csv文件系统也可以胜任工作。
配置本地数据仓库
qteasy通过tushare金融数据包来获取大量的金融数据,用户需要自行申请tushare的API Token,获取相应的权限和积分。详情请参考这里。
因此,在使用qteasy之前需要对本地数据源和tushare进行必要的配置。在QT_ROOT_PATH/qteasy/路径下打开配置文件qteasy.cfg,可以看到下面内容:
# qteasy configuration file
# following configurations will be loaded when initialize qteasy# example:
# local_data_source = database
配置tushare 的API token
将你获得的tushare API token添加到配置文件中,如下所示:
tushare_token = <你的tushare API Token>
配置本地数据源 —— 用MySQL数据库作为本地数据源
默认情况下qteasy使用存储在data/路径下的.csv文件作为数据源,不需要特殊设置。
如果设置使用mysql数据库作为本地数据源,在配置文件中添加以下配置:
local_data_source = database local_db_host = <host name>
local_db_port = <port number>
local_db_user = <user name>
local_db_password = <password>
local_db_name = <database name>
关闭并保存好配置文件后,重新导入qteasy,就完成了数据源的配置,可以开始下载数据到本地了。
下载金融历史数据
要下载金融价格数据,使用qt.refill_data_source()函数。下面的代码下载2021及2022两年内所有股票、所有指数的日K线数据,同时下载所有的股票和基金的基本信息数据。
(根据网络速度,下载数据可能需要十分钟左右的时间,如果存储为csv文件,将占用大约200MB的磁盘空间):
import qteasy as qt
qt.refill_data_source(tables=['stock_daily', # 股票的日线价格'index_daily', # 指数的日线价格'basics'], # 股票和基金的基本信息start_date='20210101', # 下载数据的开始时间end_date='20221231', # 下载数据的截止时间
)
数据下载到本地后,可以使用qt.get_history_data()来获取数据,如果同时获取多个股票的历史数据,每个股票的历史数据会被分别保存到一个dict中。
import qteasy as qt
qt.get_history_data(htypes='open, high, low, close', # 获取的数据类型shares='000001.SZ, 000300.SH', # 股票代码start='20210101', # 开始日期end='20210115') # 结束日期
运行上述代码会得到一个Dict对象,包含两个股票"000001.SZ"以及"000005.SZ"的K线数据(数据存储为DataFrame):
{'000001.SZ':open high low close2021-01-04 19.10 19.10 18.44 18.602021-01-05 18.40 18.48 17.80 18.172021-01-06 18.08 19.56 18.00 19.56... 2021-01-13 21.00 21.01 20.40 20.702021-01-14 20.68 20.89 19.95 20.172021-01-15 21.00 21.95 20.82 21.00,'000300.SH':open high low close2021-01-04 5212.9313 5284.4343 5190.9372 5267.71812021-01-05 5245.8355 5368.5049 5234.3775 5368.50492021-01-06 5386.5144 5433.4694 5341.4304 5417.6677...2021-01-13 5609.2637 5644.7195 5535.1435 5577.97112021-01-14 5556.2125 5568.0179 5458.6818 5470.45632021-01-15 5471.3910 5500.6348 5390.2737 5458.0812}
除了价格数据以外,qteasy还可以下载并管理包括财务报表、技术指标、基本面数据等在内的大量金融数据,详情请参见qteasy文档
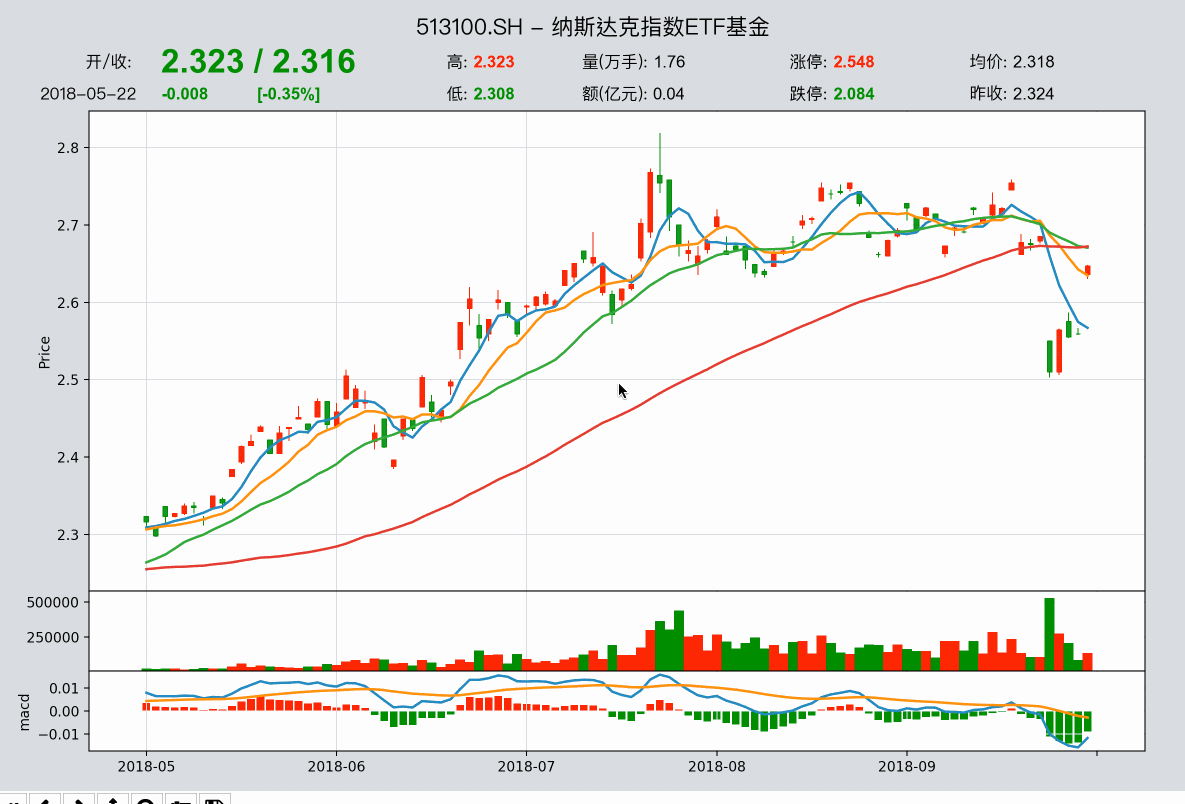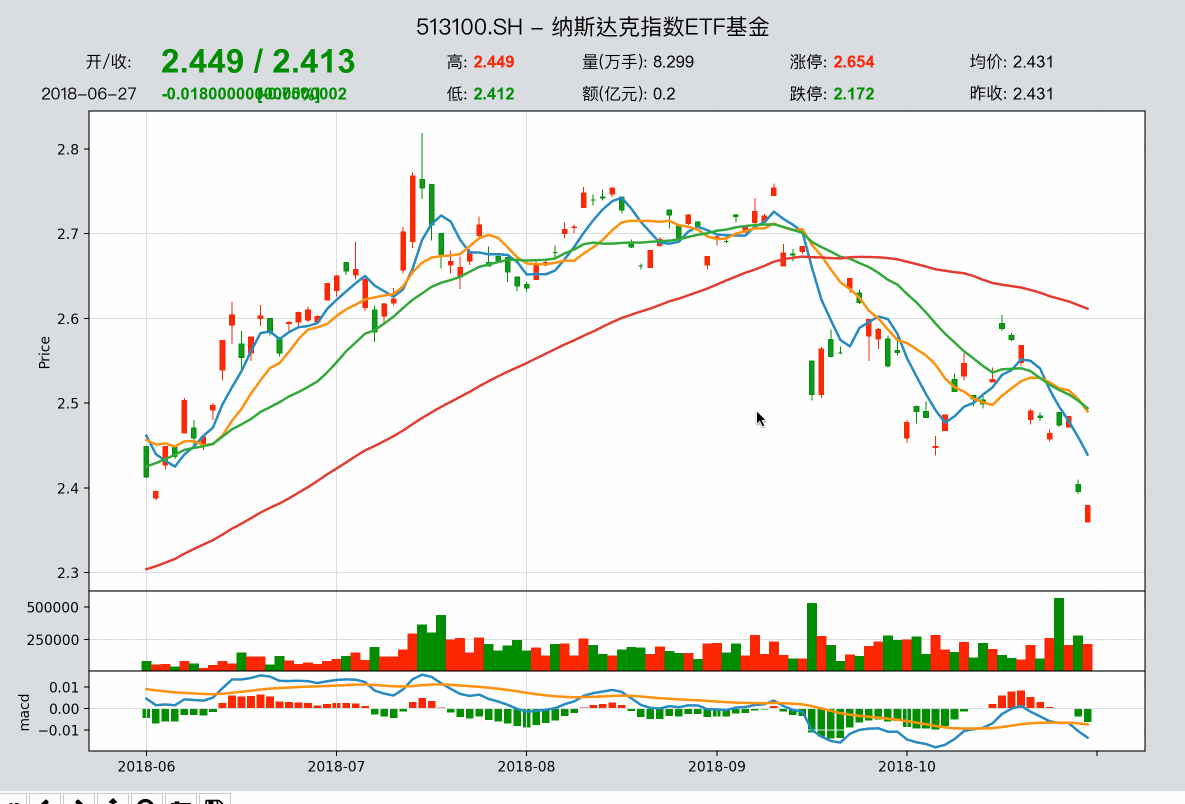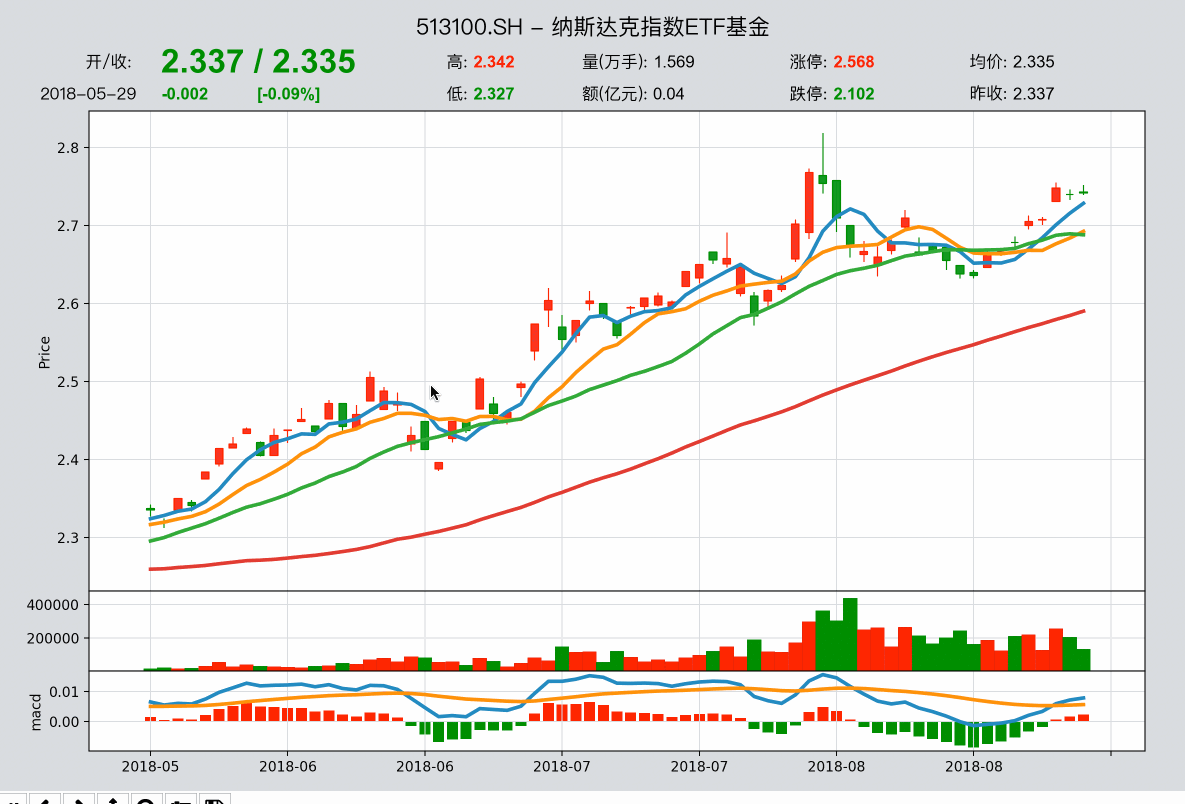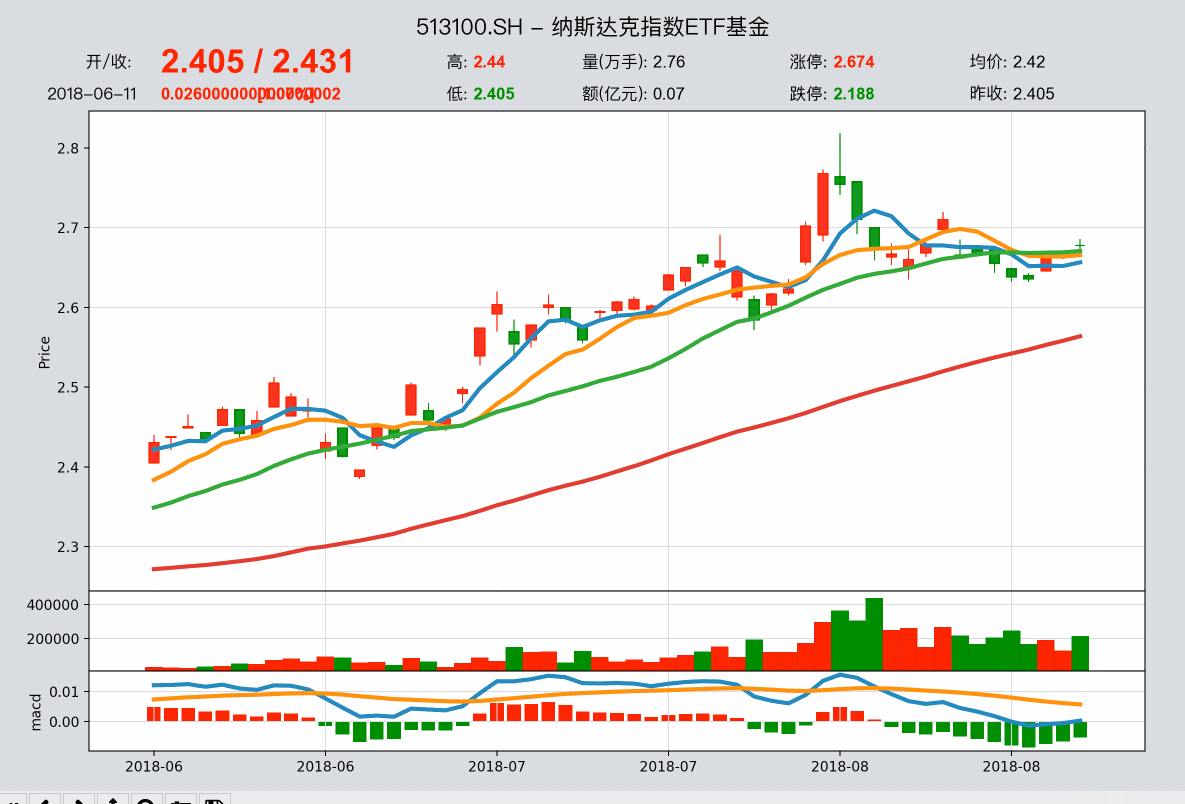
股票的数据下载后,使用qt.candle()可以显示股票数据K线图。
data = qt.candle('000300.SH', start='2021-06-01', end='2021-8-01', asset_type='IDX')

qteasy的K线图函数candle支持通过六位数股票/指数代码查询准确的证券代码,也支持通过股票、指数名称显示K线图
qt.candle()支持功能如下:
- 显示股票、基金、期货的K线
- 显示复权价格
- 显示分钟、 周或月K线
- 显示不同移动均线以及MACD/KDJ等指标
详细的用法请参考qteasy文档,示例如下(请先使用qt.refill_data_source()下载相应的历史数据):
# 场内基金的小时K线图
qt.candle('159601', start = '20220121', freq='h')
# 沪深300指数的日K线图
qt.candle('000300', start = '20200121')
# 股票的30分钟K线,复权价格
qt.candle('中国电信', start = '20211021', freq='30min', adj='b')
# 期货K线,三条移动均线分别为9天、12天、26天
qt.candle('沪铜主力', start = '20211021', mav=[9, 12, 26])
# 场外基金净值曲线图,复权净值,不显示移动均线
qt.candle('000001.OF', start='20200101', asset_type='FD', adj='b', mav=[])





生成的K线图可以是一个交互式动态K线图(请注意,K线图基于matplotlib绘制,在使用不同的终端时,显示功能有所区别,某些终端并不支持
动态图表,详情请参阅 matplotlib文档
在使用动态K线图时,用户可以用鼠标和键盘控制K线图的显示范围:
- 鼠标在图表上左右拖动:可以移动K线图显示更早或更晚的K线
- 鼠标滚轮在图表上滚动,可以缩小或放大K线图的显示范围
- 通过键盘左右方向键,可以移动K线图的显示范围显示更早或更晚的K线
- 通过键盘上下键,可以缩小或放大K线图的显示范围
- 在K线图上双击鼠标,可以切换不同的均线类型
- 在K线图的指标区域双击,可以切换不同的指标类型:MACD,RSI,DEMA
数据的定期下载
复制下面的源码,定期运行,即可定期下载相应数据到数据仓库中,供量化交易研究或实盘运行使用,源码如下:
import qteasy as qt
import pandas as pd# 下载低频data和event数据,下载周期较长以cover所有的季度月度周度数据 (每月下载)
tables = 'stock_weekly, stock_monthly, index_weekly, index_monthly, '
tables += 'income, balance, cashflow, financial, forecast, express, comp, report, events'
today = pd.to_datetime('today') # 结束日期为今天
begin = pd.to_datetime(today - pd.Time_delta(30, unit='d') # 开始日期为30天以前
qt.refill_data_source(tables=tables, start_date=begin.strftime('%Y%m%d'), end_date=today.strftime('%Y%m%d'), parallel=True, merge_type='update',reversed_par_seq=True)# 分批下载中频数据,下载周期较短以减少下载负载 (每周下载)
tables = 'adj, stock_daily, fund_daily, fund_nav, future_daily, options_daily, stock_indicator, stock_indicator2, index_indicator, shibor, libor, hibor, index_daily'
today = pd.to_datetime('today') # 结束日期为今天
begin = pd.to_datetime(today - pd.Time_delta(7, unit='d') # 开始日期为7天以前
qt.refill_data_source(tables=tables, start_date=begin.strftime('%Y%m%d'), end_date=today.strftime('%Y%m%d'), parallel= True, merge_type='update',reversed_par_seq=True)# 分批下载高频数据,下载周期最短以减少下载负载 (每天下载)
tables = 'adj, stock_1min, stock_5min, stock_15min, stock_30min, stock_hourly'
# tables = 'adj, index_1min, index_5min, index_15min, index_30min, index_hourly'
# tables = 'fund_1min, fund_5min, fund_15min, fund_30min, fund_hourly'
# tables = 'adj, future_daily, options_daily'
today = pd.to_datetime('today') # 结束日期为今天
begin = pd.to_datetime(today - pd.Time_delta(1, unit='d') # 开始日期为1天以前
qt.refill_data_source(tables=tables, start_date=begin.strftime('%Y%m%d'), end_date=today.strftime('%Y%m%d'), parallel= True, merge_type='update',reversed_par_seq=True)
更多用法请参见文档
关于DataSource对象的更多详细介绍,请参见qteasy文档