全文共18000余字,预计阅读时间约36~60分钟 | 满满干货,建议收藏!

一、介绍
树模型是目前机器学习领域最为重要的模型之一,同时它也是集成学习中最常用的基础分类器。
与线性回归、逻辑回归等算法不同,树模型并不只是一种特定的算法,而是一种涵盖了多种算法的模型族。
树模型原理简明易懂,计算效率高,判别能力强。更重要的是,它拥有优秀的可解释性,能提供清晰直观的决策路径。此外,它还能输出重要的附加信息,如特征重要性和连续变量的最佳分箱方式,进一步增强了其实用价值。
决策树是树模型的一种。
二 、使用逻辑回归复现决策树
先来做一个实验:使用逻辑回归对围绕鸢尾花数据集建模,代码如下:
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import GridSearchCV# 加载数据
iris_features, iris_target = load_iris(return_X_y=True)# 划分训练集和测试集
features_train, features_test, target_train, target_test = train_test_split(iris_features, iris_target, random_state=24)# 创建逻辑回归模型实例,添加参数“class_weight”和“random_state”
logreg_model = LogisticRegression(max_iter=int(1e6), solver='saga')# 定义逻辑回归模型的参数空间,添加参数"fit_intercept"和"tol"
logreg_param_grid = {'penalty': ['l1', 'l2'],'C': [1, 0.5, 0.1, 0.05, 0.01],}# 创建网格搜索评估器
grid_search_estimator = GridSearchCV(estimator=logreg_model,param_grid=logreg_param_grid)# 使用训练数据拟合模型
grid_search_estimator.fit(features_train, target_train)# 输出最优参数
best_params = grid_search_estimator.best_params_
print("Best parameters: \n", best_params)# 输出最优模型的系数和截距
best_estimator = grid_search_estimator.best_estimator_
best_estimator_coefficients = best_estimator.coef_
best_estimator_intercept = best_estimator.intercept_
print("Best estimator coefficients: \n", best_estimator_coefficients)
print("Best estimator intercept: \n", best_estimator_intercept)
重点来了!来分析一下输出结果:
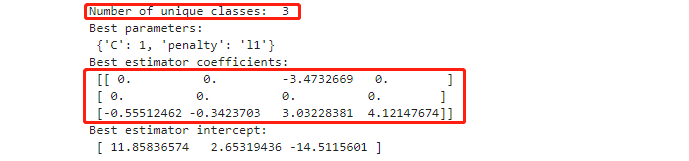
逻辑回归在处理多分类问题时,会为每个类别都生成一个方程,这个方程用于区分该类别和其他类别。
在鸢尾花数据集中有3个类别,所以有3个方程,对应的系数是一个3x4的矩阵。
对于第一个类别(也就是第一行的系数对应的类别),只有第三个特征的系数不为0(-3.47343992),其他特征的系数都为0。这意味着模型在区分第一个类别和其他类别时,主要依赖第三个特征。换句话说,根据这个模型,可以通过观察一个样本的第三个特征来判断它是否属于第一类。
按这个思路,看一下是否有效,直接上代码:
# 加载数据
iris = load_iris(as_frame=True)# 获取特征和目标变量
features = np.array(iris.data)
target = np.array(iris.target)# 将2、3类划归为一类
target[50:] = 1# 创建2x2的子图
fig, ax = plt.subplots(1, 3, figsize=(15, 5))# 分别对比第三个特征与第1,2,4个特征
for i, idx in enumerate([0, 1, 3]):ax[i].scatter(features[:, 2], features[:, idx], c=target)ax[i].set_title(f'3rd feature vs {idx+1}st feature')ax[i].set_xlabel('3rd feature')ax[i].set_ylabel(f'{idx+1}st feature')ax[i].plot([2.5]*50, np.linspace(min(features[:, idx]), max(features[:, idx]), 50), 'r--')plt.tight_layout()
plt.show()
解释一下上述代码的一个关键操作:为什么要将2、3类划归为一类?
这样做是为了检查第三个特征是否能够有效地将第一类(“setosa”)鸢尾花与其余两类(“versicolor” 和 “virginica”)鸢尾花区分开来。所以要将第二类和第三类鸢尾花合并为一类,从而把多分类变为二分类。
看下效果:
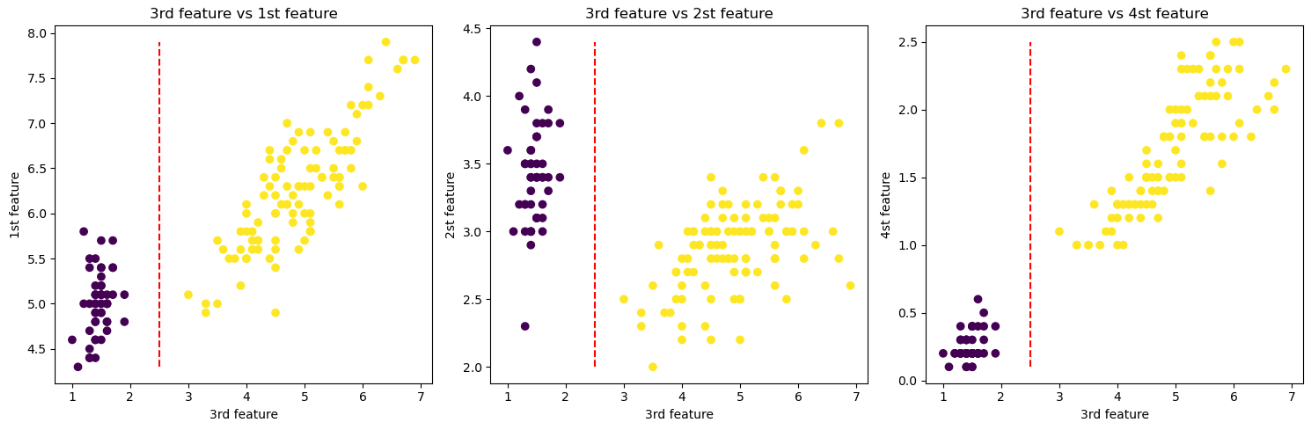
结论是确实可以通过第三个特征(横坐标)很好的区分第一类(紫色)和其他两类(黄色点),也就是说,从分类结果来看,能够简单通过一个分类规则来区分第一类鸢尾花和其他两类。
可以以petal length (cm) <= 2.5作为分类条件,当分类条件满足时,鸢尾花属于第一类,否则就属于第二、三类。基本分类情况如下:
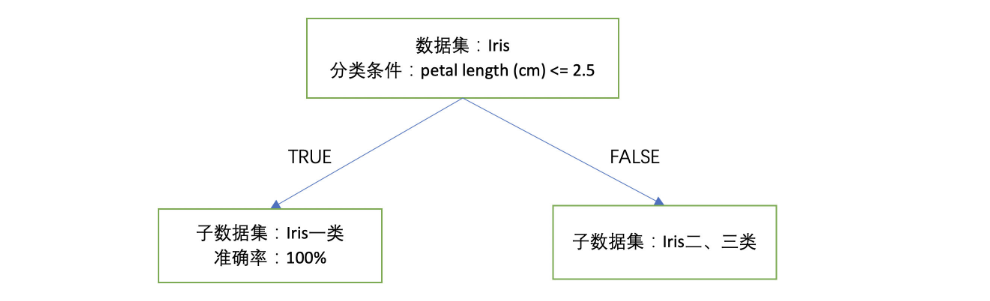
接下来,对于未分类的二、三类鸢尾花数据,再进一步找到类似刚才的分类规则对其进行有效分类。
思路如下:可以用特征选择方法,通过L1正则化(也被称为Lasso)来选择重要的特征。调整正则化参数C,可以控制模型复杂性。更小的C值会导致更强的正则化效果,使得模型的一部分系数变为零。这样,就能挑选出对二、三类分类最有分类效力的特征(也就是最重要的特征),然后根据只有一个特征系数不为0的带l1正则化的逻辑回归建模结果,找到决策边界,而该决策边界就是依据该单独特征划分Iris二、三类子数据的最佳方法。
直接上代码:
def select_feature_and_train_model():# 加载数据iris = load_iris(as_frame=True)X = np.array(iris.data)y = np.array(iris.target)# 提取待分类的子数据集X_sub = X[y > 0]y_sub = y[y > 0]# 尝试各种C值,观察系数变化C_values = np.linspace(1, 0.1, 100)coef_list = []for C in C_values:model = LogisticRegression(penalty='l1', C=C, max_iter=int(1e6), solver='saga')model.fit(X_sub, y_sub)coef_list.append(model.coef_.flatten())# 使用GridSearchCV来找到最优的C值param_grid = {'C': np.linspace(0.1, 1, 100)}grid_search = GridSearchCV(LogisticRegression(penalty='l1', max_iter=int(1e6), solver='saga'), param_grid, cv=5)grid_search.fit(X_sub[:, 2].reshape(-1, 1), y_sub)selected_C = grid_search.best_params_['C']# 使用选定的C值,只用第三个特征训练模型selected_model = LogisticRegression(penalty='l1', C=selected_C, max_iter=int(1e6), solver='saga')selected_model.fit(X_sub[:, 2].reshape(-1, 1), y_sub)# 打印模型参数和评分print("Best C: ", selected_C)print("Model Coefficients: ", selected_model.coef_)print("Model Intercept: ", selected_model.intercept_)print("Model Score: ", selected_model.score(X_sub[:, 2].reshape(-1, 1), y_sub))# 计算决策边界并绘图decision_boundary = -selected_model.intercept_[0] / selected_model.coef_[0][0]plt.plot(X_sub[:, 2][y_sub==1], X_sub[:, 3][y_sub==1], 'ro')plt.plot(X_sub[:, 2][y_sub==2], X_sub[:, 3][y_sub==2], 'bo')plt.plot([decision_boundary]*20, np.arange(0.5, 2.5, 0.1), 'r--')plt.show()return selected_model, coef_list# 使用函数
model, coef_list = select_feature_and_train_model()
来看下结果:
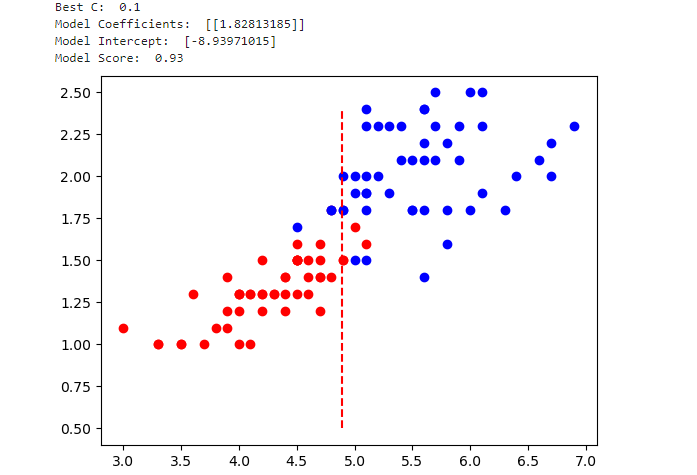
尽管准确率不足100%,但也是一个非常好的分类规则,即分类条件为petal length (cm) <= 4.879,当分类条件满足时,鸢尾花属于第二类、不满足时鸢尾花属于第三类,根据此分类条件进行的分类准确率为93%,所以可以得到下图:
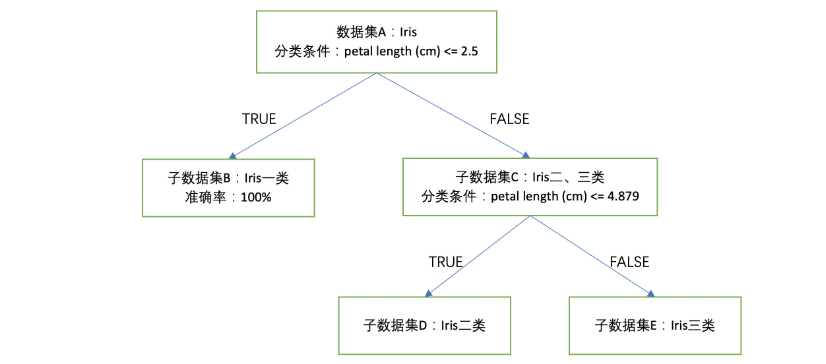
这个过程,其实也就是构建决策树的基本过程,通过带正则化项的逻辑回归模型挖掘出的两个分类规则,并且这两个分类规则呈现递进的关系,也就是一个分类规则是在另一个分类规则的分类结果下继续进行分类,最终这两个分类规则和对应划分出来的数据集呈现出树状,而带有不同层次分类规则的模型
总的来说,决策树的核心思想就是:挖掘有效分类规则并以树状形式呈现。
三、 决策树的基本概念
3.1 决策树的本质
决策树实质上就是一系列分类规则的叠加,其构建的本质就是挖掘有效的分类规则,最终以树的形式来进行呈现。
3.2 决策树的基本结构
决策树的基本结构是一个树形结构,从整体上来看就是一个有向无环图。
从图结构来理解的话,可以借助边的方向来定义不同类型点,如果一条边从A点引向B点,则这条边对于A点来说是出边、对于B点来说是入边,A节点是B节点的父节点,据此可以将决策树中所有的点进行如下类别划分:
- 根节点(Root Node):树的最顶部节点,没有进入的分支,但有两个或多个出去的分支。它对应的特征用于最初的分割数据。
- 内部节点(Internal Node):每个内部节点都有一个进入的分支和两个或多个出去的分支。每个内部节点对应一个特征,该特征用于根据某种规则(如特征值是否大于某个阈值)来进一步分割数据。
- 叶节点(Leaf Node):叶节点也称为终端节点,是树的最底部节点,没有出去的分支,但有一个进入的分支。每个叶节点对应一个预测结果,即在分类问题中的一个类别或在回归问题中的一个值。
每一条从根节点到叶节点的路径都对应一条决策规则。对于给定的输入,按照从根节点开始的决策规则,沿着某一条路径,最终到达某个叶节点,该叶节点的预测结果就是模型对该输入的预测。
在不断的划分数据集的过程中,原始的完整数据集对应着决策树的根节点,而根结点划分出的子数据集就构成了决策树中的内部节点,同时迭代停止的时候所对应的数据集,其实就是决策树中的叶节点。
每个数据集都是由一系列分类规则最终划分出来的,也可以理解成每个节点其实都对应着一系列分类规则,例如第二节中的案例中:E节点实际上就是petal length (cm) <= 2.5和petal length (cm) <= 4.879同时为False时划分出来的数据集。
3.3 决策树的生长过程
在树模型的构建过程中,实际上是分层来对数据集进行划分的,每当定下一个分类规则后,就可以根据是否满足分类规则来对数据集进行划分,而后续的分类规则的挖掘则进一步根据上一层划分出来的子数据集的情况来定,逐层划分数据集、逐数据集寻找分类规则再划分数据集,这就是树模型的生长过程,
通俗的理解是:决策树分类的过程就像是在回答一系列"是或否"的问题,直到找到最合适的类别。
对于一个新的数据样本,从决策树的根节点开始,每一步都按照该节点的决策规则(对某个特征的一个阈值判断)来检查这个样本。将样本送到左子节点(如果满足该决策规则)或右子节点(如果不满足),然后在这个新节点上重复上述过程,直到到达一个叶子节点。这个叶子节点的类别标签就是预测结果。
在第二节案例中,如果一朵鸢尾花的petal length (cm) <= 2.5,那么就预测它是第一类。否则,再查看petal length (cm)是否 <= 4.879,如果是,就预测它是第二类,如果不是,就预测它是第三类。这就是决策树分类的过程。
这个过程是一个迭代计算过程(上一层的数据集决定有效规律的挖掘、而有效规律的挖掘)。
四、分类规则的评估指标
4.1 什么是划分规则评估指标
在逻辑回归复现决策树的核心思想这个实验中,构建了这样一个决策树:
决策树的建模过程实际上就是挖掘有效分类规律的过程,而分类规律是否有效,是需要有一个评估标准的。
在逻辑回归的模型结论的基础上寻找分类规律,可以看成是根据分类结果的准确率来寻找分类规则,此时准确率就是评估分类条件好坏的评估指标。
例如在决策树开始生长的第一层,选取petal length (cm) <= 2.5作为分类条件将原始数据集一分为二,分出来的两个数据集其中一个100%是一类数据,另一个则全是二、三类数据,此时如果根据准确率来判断该分类规则是否能够很好的区分一类和二、三类数据的话,那此时的准确率就是100%,分类误差就是0。
这种定义分类评估指标的方法并不通用并且在多分类问题时容易引发混乱,例如如果是四分类问题,1条件能够100%区分A类和BCD类,2条件能够100%区分AB类和CD类,此时如果还按照准确率来进行判别分类条件好坏的判别指标,则选择哪个条件就成了问题。
因此一般来说树模型挑选分类规则的评估指标并不是看每个类别划分后的准确率,而是父节点划分子节点后子节点数据集标签的纯度。
4.2 纯度和不纯度
在决策树模型中,"纯度"和"不纯度"是用来衡量数据集中类别混杂程度的度量。
-
纯度(Purity):如果一个数据集的所有实例都属于同一类别,这个数据集就是"纯"的。换句话说,纯度高意味着一个节点包含的样本大部分都属于同一类别。
-
不纯度(Impurity):与纯度相对,如果一个数据集的实例属于多个类别,这个数据集就是"不纯"的。不纯度是一个衡量在同一个数据集中有多少种类别混合在一起的度量。
决策树生长的方向也就是令每个划分出来的子集纯度越来越高的方向。
在决策树中,最终的目标是通过选择合适的特征和切分点,将数据集划分为尽可能"纯"的子集。也就是说,希望每个子集中的实例尽可能都属于同一类别。
决策树使用的不纯度衡量指标有很多,其中最常用的有三种:分类误差(Classification Error),信息熵(Entropy)和基尼系数(Gini)。
对于决策树的每个节点,计算所有可能的切分方式对应的不纯度,选择不纯度下降最多的切分方式对数据集进行划分。
4.3 不纯度的衡量指标
4.3.1 分类误差
分类误差(classification error)是一个常见的衡量分类器性能的指标。在二分类问题中,分类误差可以简单地定义为被错误分类的样本数占总样本数的比例。对于多分类问题,分类误差同样可以扩展为被错误分类的样本数占总样本数的比例。
如果将其应用在决策树上,可以在每个节点上定义分类误差。对于一个给定的节点,分类误差就是这个节点上的样本中,非主要类别的样本数占总样本数的比例。也就是说如果按照这个节点上的主要类别来对所有样本进行预测,那么预测错误的比例就是分类误差。其数学表达式如下:
C l a s s i f i c a t i o n e r r o r ( t ) = 1 − max 1 ≤ i ≤ c [ p ( i ∣ t ) ] (1) Classification\ error(t) = 1-\max_{1\leq i\leq c}[p(i|t)] \tag{1} Classification error(t)=1−1≤i≤cmax[p(i∣t)](1)
- i i i表示第 i i i类
- c c c表示当前数据集共有 c c c类
- p ( i ∣ t ) p(i|t) p(i∣t)表示第 i i i类数据占当前数据集中总数据的比例。
如果用分类误差衡量的话,就是用1减去多数类的占比。
如一个10条数据的数据集,有6条0类数据、4条1类数据,此时该数据集分类误差就是1-6/10 = 0.4。分类误差在[0, 0.5]范围内取值,分类误差越小,说明数据集标签纯度越高。
贪心算法使用的决策树划分规则评估指标就是分类误差
但是在实践中,它对于节点的纯度不是一个好的度量。因为分类误差对于节点中样本的分布不敏感,它的值往往只由数量最多的类别决定。因此在决策树的构建中,常常使用更为敏感的度量,如基尼不纯度或信息熵。
4.3.2 信息熵(Entropy)
信息熵(Entropy)之前的文章也提到过,此处就不重复说了。它用来度量信息的不确定性或者说混乱程度。信息熵定义为:
E n t r o p y ( t ) = − ∑ i = 1 c p ( i ∣ t ) l o g 2 p ( i ∣ t ) (2) Entropy(t) = -\sum_{i=1}^c p(i|t)log_2p(i|t) \tag{2} Entropy(t)=−i=1∑cp(i∣t)log2p(i∣t)(2)
- E n t r o p y ( t ) Entropy(t) Entropy(t): 是指在目标变量 t t t(比如一个决策树的节点)上的信息熵,是要计算的量。
- p ( i ∣ t ) p(i|t) p(i∣t): 是在目标变量 t t t 的条件下,数据属于第 i i i 类的概率。具体来说,就是目标变量 t t t 下第 i i i 类数据的数量占总数据数量的比例。
- ∑ i = 1 c \sum_{i=1}^c ∑i=1c: 这个求和符号表示要对所有的类别进行求和,其中 c c c 是总的类别数量。
- l o g 2 log_2 log2: 这是对数函数的底数,使用2作为底数是因为在信息论中,信息量的计量单位通常是比特(bit)。
所以,信息熵应用于决策树时,整个公式的含义就是计算在给定目标变量 t t t(一个决策树节点)的条件下,根据各类别概率分布计算出的信息熵。它度量的是目标变量 t t t 上数据的不确定性或者说混乱程度。
还是使用这个10条数据的数据集,有6条0类数据、4条1类数据,计算其信息熵过程如下:
首先需要计算每个类别的概率分布 p ( i ∣ t ) p(i|t) p(i∣t):
- 对于0类
p ( 0 ∣ t ) = 6 10 = 0.6 (3) p(0|t)=\frac{6}{10}=0.6 \tag{3} p(0∣t)=106=0.6(3)
- 对于1类
p ( 1 ∣ t ) = 4 10 = 0.4 (4) p(1|t)=\frac{4}{10}=0.4 \tag{4} p(1∣t)=104=0.4(4)
接下来将这些概率分布带入信息熵的公式:
E n t r o p y ( t ) = − ∑ i = 1 c p ( i ∣ t ) log 2 p ( i ∣ t ) (5) Entropy(t) = -\sum_{i=1}^c p(i|t)\log_2p(i|t) \tag{5} Entropy(t)=−i=1∑cp(i∣t)log2p(i∣t)(5)
将具体的值带入公式:
E n t r o p y ( t ) = − [ 0.6 ∗ log 2 ( 0.6 ) + 0.4 ∗ log 2 ( 0.4 ) ] (6) Entropy(t) = -[0.6 * \log_2(0.6) + 0.4 * \log_2(0.4)] \tag{6} Entropy(t)=−[0.6∗log2(0.6)+0.4∗log2(0.4)](6)
经过计算,得到:
E n t r o p y ( t ) ≈ 0.97 (7) Entropy(t) \approx 0.97 \tag{7} Entropy(t)≈0.97(7)
这个值就是数据集的信息熵。信息熵越小则说明数据集纯度越高。
信息熵的直观含义是:如果一个事件的可能结果越多,结果发生的概率分布越均匀,那么这个事件的信息熵就越大,反之信息熵就越小。比如,对于一个公平的硬币,其正反面出现的概率是均等的,所以它的信息熵是最大的,为1比特。而对于一个两面都是正面的硬币,其信息熵为0,因为它的结果是确定的。
4.3 基尼系数(Gini)
基尼系数(Gini Index)也是一种衡量不纯度的方法,基尼系数的值越大,数据集的不纯度越高。定义如下:
G i n i ( t ) = 1 − ∑ i = 1 c p ( i ∣ t ) 2 (8) Gini(t) = 1-\sum_{i=1}^c p(i|t)^2 \tag{8} Gini(t)=1−i=1∑cp(i∣t)2(8)
- c c c 表示数据集中类别的总数
- p ( i ∣ t ) p(i|t) p(i∣t) 表示第 i i i 类数据占数据集的比例
基尼系数的计算涉及到将每个类别的概率的平方和从1中减去。在所有类别的分布概率都相等的情况下,基尼系数达到最大值,这时数据集的不纯度最高。在只有一类数据时,所有其他类别的概率为0,这时基尼系数等于0,表示数据集完全纯净。
基尼系数的计算更加直观,也更加高效,因为它不需要进行对数运算。另外,与信息熵相比,基尼系数对于不平衡的类别分布更敏感。
还是使用这个10条数据的数据集,有6条0类数据、4条1类数据,计算其基尼系数过程如下:
首先,计算两个类别在数据集中的比例:
- 对于0类
p ( 0 ∣ t ) = 6 10 = 0.6 (9) p(0|t)=\frac{6}{10}=0.6 \tag{9} p(0∣t)=106=0.6(9)
- 对于1类
p ( 1 ∣ t ) = 4 10 = 0.4 (10) p(1|t)=\frac{4}{10}=0.4 \tag{10} p(1∣t)=104=0.4(10)
将比例代入基尼系数的公式:
G i n i ( t ) = 1 − ∑ i = 1 c [ p ( i ∣ t ) ] 2 (11) Gini(t) = 1 - \sum_{i=1}^c [p(i|t)]^2 \tag{11} Gini(t)=1−i=1∑c[p(i∣t)]2(11)
带入具体的值计算:
G i n i ( t ) = 1 − [ p ( 0 ∣ t ) 2 + p ( 1 ∣ t ) 2 ] = 1 − [ ( 0.6 ) 2 + ( 0.4 ) 2 ] = 1 − [ 0.36 + 0.16 ] = 1 − 0.52 = 0.48 (12) Gini(t) = 1 - [p(0|t)^2 + p(1|t)^2] = 1 - [(0.6)^2 + (0.4)^2] = 1 - [0.36 + 0.16] = 1 - 0.52 = 0.48 \tag{12} Gini(t)=1−[p(0∣t)2+p(1∣t)2]=1−[(0.6)2+(0.4)2]=1−[0.36+0.16]=1−0.52=0.48(12)
而和信息熵不同的是,基尼系数在[0, 0.5]范围内取值,并且基尼系数越小表示数据集标签纯度越高
4.4. 多数据集的评估指标
上面的过程都是在单数集下的计算方式。但大部分情况下不仅需要衡量单独数据集标签的纯度,还需要衡量多个数据集作为一个整体时的标签的纯度,如一个父节点在划分成两个子节点时两个子节点整体的评估指标。
举个例子,看如下数据集:
-
数据集A共有两个特征、一个标签,并且标签只有0-1两个类别,数据集特征分别是收入(income)和信用评级(credit_rating)
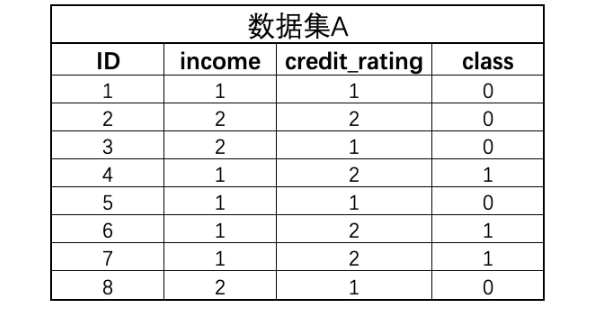
针对整体的数据集,计算过程是这样的:(Gini系数)
含8条数据的数据集A,其中有5条属于0类,3条属于1类,首先计算整体的Gini系数:
- 0类的比例 p ( 0 ∣ t ) = 5 8 = 0.625 p(0|t) = \frac{5}{8} = 0.625 p(0∣t)=85=0.625
- 1类的比例 p ( 1 ∣ t ) = 3 8 = 0.375 p(1|t) = \frac{3}{8} = 0.375 p(1∣t)=83=0.375:
G i n i ( A ) = 1 − [ p ( 0 ∣ A ) 2 + p ( 1 ∣ A ) 2 ] = 1 − [ ( 0.625 ) 2 + ( 0.375 ) 2 ] = 1 − [ 0.390625 + 0.140625 ] = 1 − 0.53125 = 0.46875 (13) Gini(A) = 1 - [p(0|A)^2 + p(1|A)^2] = 1 - [(0.625)^2 + (0.375)^2] = 1 - [0.390625 + 0.140625] = 1 - 0.53125 = 0.46875 \tag{13} Gini(A)=1−[p(0∣A)2+p(1∣A)2]=1−[(0.625)2+(0.375)2]=1−[0.390625+0.140625]=1−0.53125=0.46875(13)
假设随意设置一个分类条件:income <= 1.5,则可以将上述数据集进一步划分成两个子数据集B1、B2:
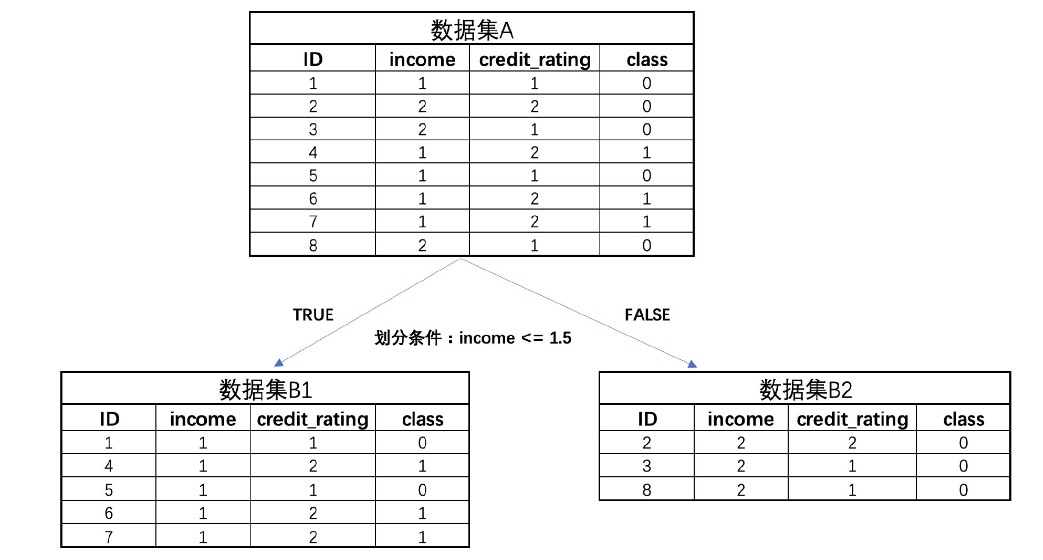
对于一个包含5条数据的子数据集B1,其中包含2个0类和3个1类,根据基尼系数公式计算B1的基尼系数。
- 0类的比例 p ( 0 ∣ B 1 ) = 2 5 = 0.4 p(0|B1) = \frac{2}{5} = 0.4 p(0∣B1)=52=0.4
- 1类的比例 p ( 1 ∣ B 1 ) = 3 5 = 0.6 p(1|B1) = \frac{3}{5} = 0.6 p(1∣B1)=53=0.6
G i n i ( B 1 ) = 1 − [ p ( 0 ∣ B 1 ) 2 + p ( 1 ∣ B 1 ) 2 ] = 1 − [ ( 0.4 ) 2 + ( 0.6 ) 2 ] = 1 − [ 0.16 + 0.36 ] = 1 − 0.52 = 0.48 (14) Gini(B1) = 1 - [p(0|B1)^2 + p(1|B1)^2] = 1 - [(0.4)^2 + (0.6)^2] = 1 - [0.16 + 0.36] = 1 - 0.52 = 0.48 \tag{14} Gini(B1)=1−[p(0∣B1)2+p(1∣B1)2]=1−[(0.4)2+(0.6)2]=1−[0.16+0.36]=1−0.52=0.48(14)
而B2数据集只包含一个标签,因此B2的基尼系数为0,即
G i n i ( B 2 ) = 0 (15) Gini(B2) = 0 \tag{15} Gini(B2)=0(15)
此时如果要计算B1、B2整体的基尼系数,则需要在gini_B1、gini_B2的基础上进行各自数据集样本数量占整体数据集比例的加权求和,即根据如下方式进行计算:
G i n i ( B ) = ∣ B 1 ∣ ∣ A ∣ G i n i ( B 1 ) + ∣ B 2 ∣ ∣ A ∣ G i n i ( B 2 ) (16) Gini(B) = \frac{|B_1|}{|A|}Gini(B_1)+\frac{|B_2|}{|A|}Gini(B_2) \tag{16} Gini(B)=∣A∣∣B1∣Gini(B1)+∣A∣∣B2∣Gini(B2)(16)
其中 ∣ B i ∣ ∣ A ∣ \frac{|B_i|}{|A|} ∣A∣∣Bi∣为子数据集 B i B_i Bi数据个数占父类数据集A中数据个数的比例。因此上述 B 1 B_1 B1、 B 2 B_2 B2整体基尼系数为:
G i n i ( B ) = 5 8 G i n i ( B 1 ) + 3 8 G i n i ( B 2 ) = 0.3 (17) Gini(B) = \frac {5}{8}Gini(B1) + \frac {3}{8}Gini(B2) = 0.3 \tag{17} Gini(B)=85Gini(B1)+83Gini(B2)=0.3(17)
至此,就构建了一个用于描述数据集划分完后两个子集的整体纯度的方法.
五、决策树算法
树模型的核心思想源于贪心算法的局部最优求解思想
目前为止,树模型已经有数十种之多,必须要了解的是ID3 、C4.5、C5.0决策树,必须要掌握的是CART决策树,它们都是构造决策树的具体算法,对应着不同的决策树构造策略,可以看作是不同的流派。每种算法都有自己的优点和缺点,适用于解决不同类型的问题。
5.1 ID3的算法基本建模流程
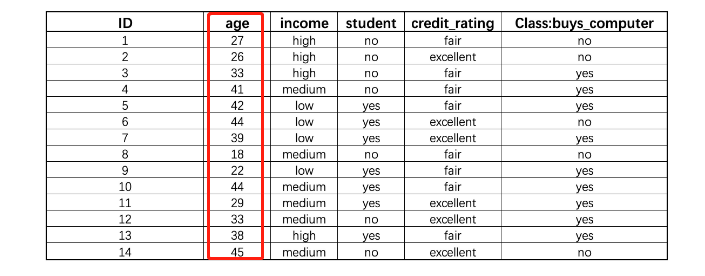
ID3(Iterative Dichotomiser 3):它是最早的、最经典的决策树算法,同时也是真正将树模型发扬光大的一派算法。由Ross Quinlan在1975年(博士毕业论文中)提出,它只能对离散型变量进行分类问题建模,也就是说:ID3无法处理连续型特征,也无法处理回归问题。如果训练数据中存在连续型变量,则首先需要对其进行离散化处理(如连续变量分箱)。
看一下例子:
这是一份个人消费数据,每个特征都是离散型变量(其中age和income两列就是连续型变量分箱之后的结果,例如age列就是以30、40为界进行连续变量分箱)
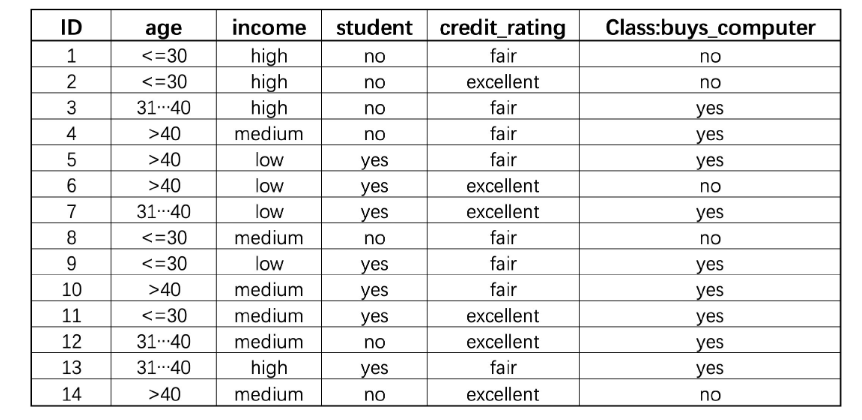
针对这样的数据,如果使用ID3算法来进行建模,其遵循的思路是:确定分类规则判别指标,寻找能够最快速降低信息熵的方式进行数据集划分(分类规则提取),不断迭代直至收敛
ID3的数据集划分过程(规律提取过程)是按照列来展开,即根据某列的不同取值来对数据集进行划分。例如根据上述数据集中的age列的不同取值来对原始数据集进行划分,则划分结果如下:
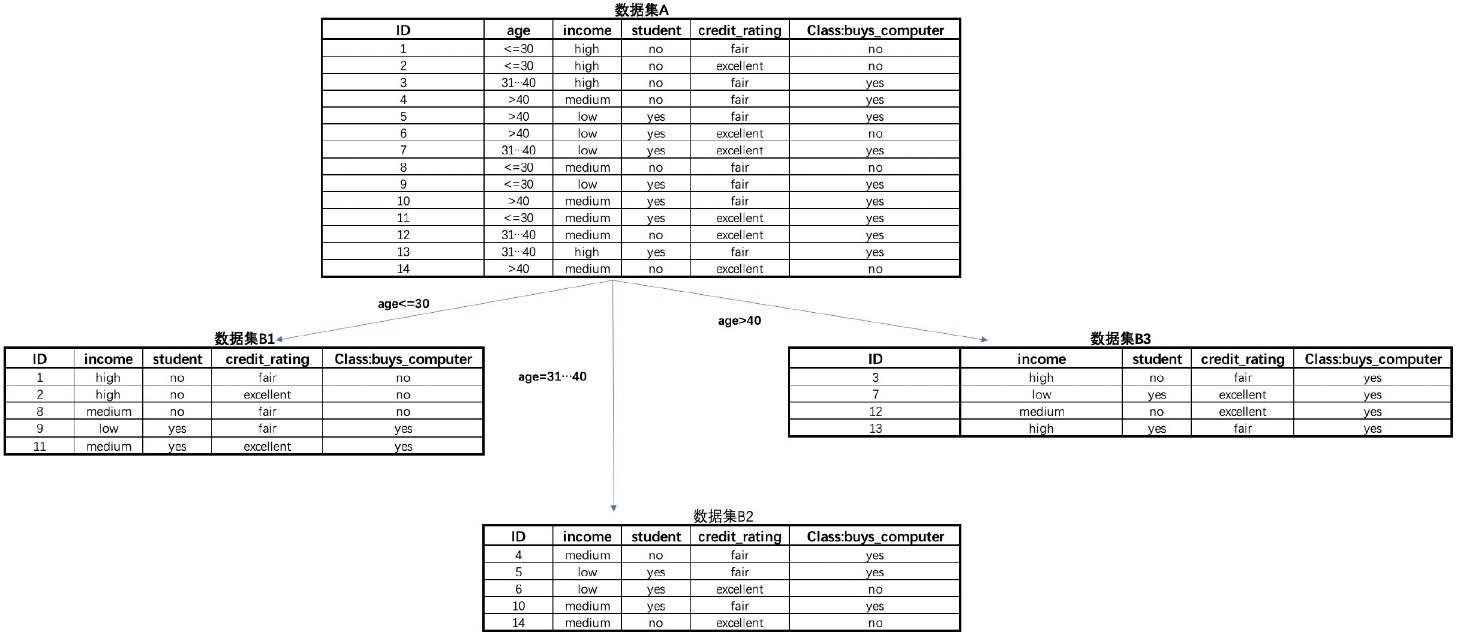
然后,就可以计算在以age的不同取值为划分规则、对数据集进行划分后数据集整体不纯度下降结果。
在ID3中采用信息熵作为评估指标,具体计算过程如下:
import numpy as npdef entropy(p):"""计算信息熵"""if p != 0 and p != 1:ent = -p * np.log2(p) - (1-p) * np.log2(1-p)else:ent = 0return entdef calculate_entropy(A, B1, B2, B3, weights):"""计算父节点和子节点的信息熵,并计算信息增益"""ent_A = entropy(A)ent_B1 = entropy(B1)ent_B2 = entropy(B2)ent_B3 = entropy(B3)ent_B = weights[0]*ent_B1 + weights[1]*ent_B2 + weights[2]*ent_B3gain = ent_A - ent_Bprint(f"Information entropy of parent node A: {ent_A:.3f}")print(f"Information entropy of child node B1: {ent_B1:.3f}")print(f"Information entropy of child node B2: {ent_B2:.3f}")print(f"Information entropy of child node B3: {ent_B3:.3f}")print(f"Information entropy of child nodes B: {ent_B:.3f}")print(f"Information gain from A to B: {gain:.3f}")return gain# 使用函数
A = 5/14
B1 = 2/5
B2 = 2/5
B3 = 0
weights = [5/14, 5/14, 4/14]calculate_entropy(A, B1, B2, B3, weights)
这段代码就是4.4节的复现,看下结果:
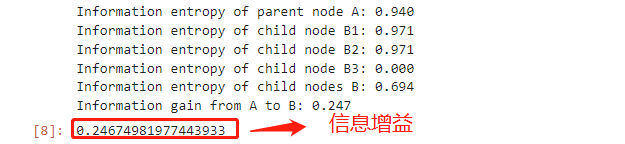
信息增益是在划分数据集前后计算信息熵的变化值,即原始数据集的信息熵减去划分后的数据集的信息熵。
上述过程就计算了按照age列的不同取值来进行数据集划分后数据集不纯度下降结果,而按照age列进行展开只能算是树的第一步生长中的一个备选划分规则,还需要测试按照income、student或者credit_rating列展开后数据集不纯度下降情况,具体计算过程和age列展开后的计算过程类似。结果如下:

按照age列展开能够更有效的降低数据集的不纯度,因此树的第一层生长就是按照age列的不同取值对数据集进行划分。
接下来就是不断进行迭代计算的过程,该模型最终树的生长形态如下:
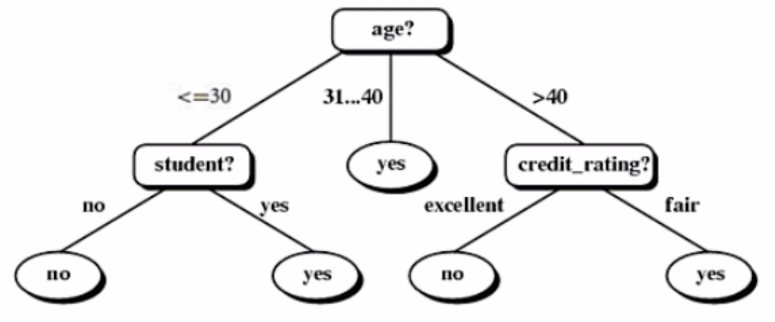
至此,就完成了ID3决策树的建模全流程。
需要明确的几个点:
1. ID3是按照列来提取规则,每一步生长会有几个分支,其实完全由当前列有几个分类水平决定
2. ID3每次展开一列,因此建模过程中对“列的消耗”非常快,数据集中特征个数就决定了树的最大深度
3. 正因为ID3是按照列来进行展开,因此只能处理特征都是离散变量的数据集。
4. ID3树在实际生长过程中会更倾向于挑选取值较多的分类变量展开,但如此一来便更加容易造成模型过拟合
5.2 C4.5算法的基本建模流程
C4.5是ID3的一个改进版本,也是由Ross Quinlan提出,在ID3的基础上进行了三个方面的优化:
1. 引入信息增益率(Gain Ratio)作为特征选择的准则,以克服ID3算法倾向于选择取值多的特征的问题
2. 可以处理连续特征和缺失值,通过寻找相邻取值的中间值作为切分点的方法实现
3. 加入了对决策树进行剪枝的策略,以防止过拟合。
- 信息值
C4.5中信息值(以下简称IV值)是一个用于衡量数据集在划分时分支个数的指标,如果划分时分支越多,IV值就越高。具体IV值的计算公式如下:
I n f o r m a t i o n V a l u e = − ∑ i = 1 K P ( v i ) l o g 2 P ( v i ) (18) Information\ Value = -\sum^K_{i=1}P(v_i)log_2P(v_i) \tag{18} Information Value=−i=1∑KP(vi)log2P(vi)(18)
其中 K K K表示某次划分是总共分支个数, v i v_i vi表示划分后的某样本, P ( v i ) P(v_i) P(vi)表示该样本数量占父节点数据量的比例
IV值计算公式和信息熵的计算公式基本一致,只是具体计算的比例不再是各类样本所占比例,而是各划分后子节点的数据所占比例,或者说信息熵是计算标签不同取值的混乱程度,而IV值就是计算特征不同取值的混乱程度
在实际建模过程中,ID3是通过信息增益的计算结果挑选划分规则,而C4.5采用IV值对信息增益计算结果进行修正,构建新的数据集划分评估指标:增益比例(Gain Ratio,被称为获利比例或增益率),来指导具体的划分规则的挑选。GR的计算公式如下:
G a i n R a t i o = I n f o r m a t i o n G a i n I n f o r m a t i o n V a l u e (19) Gain\ Ratio = \frac{Information\ Gain}{Information\ Value} \tag{19} Gain Ratio=Information ValueInformation Gain(19)
例如以age列展开后Information Gain结果为:
I G = e n t A − e n t B = 0.94 − 0.69 = 0.25 IG = ent_A - ent_B = 0.94 - 0.69 = 0.25 IG=entA−entB=0.94−0.69=0.25
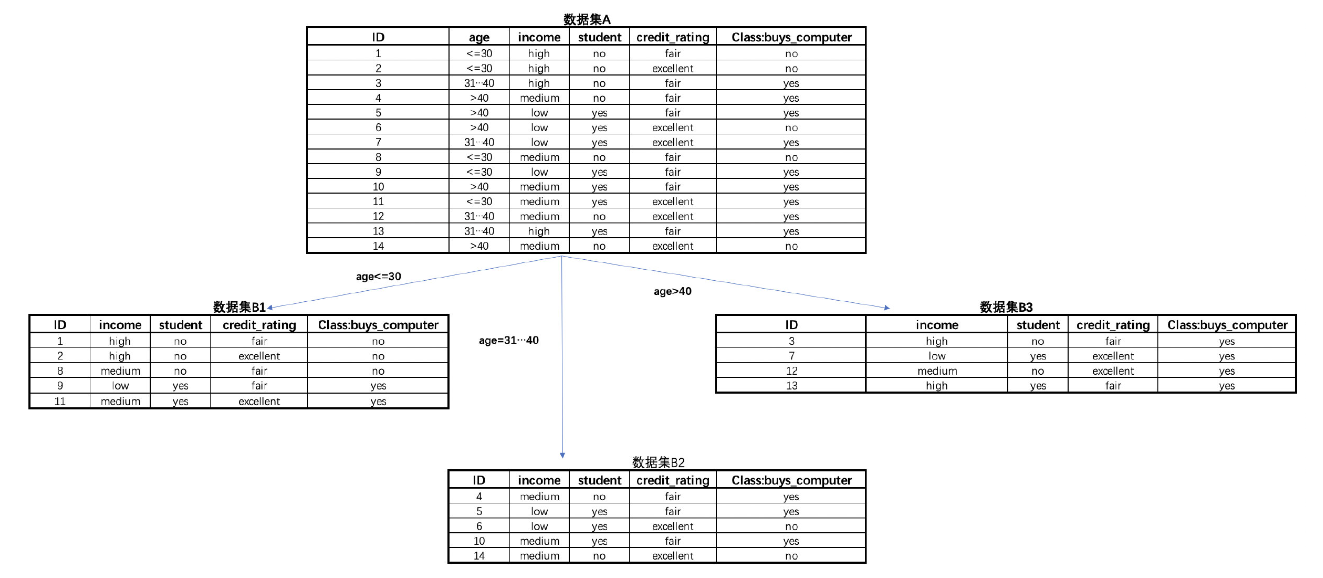
根据三个子集(B1、B2、B3)计算特征的分裂信息值(Split Information,IV)。
每个子集的权重(占总样本的比例)分别是5/14、5/14、4/14,计算公式如下:
I V = − ( 5 / 14 ∗ log 2 ( 5 / 14 ) + 5 / 14 ∗ log 2 ( 5 / 14 ) + 4 / 14 ∗ log 2 ( 4 / 14 ) ) = 1.577 (20) IV = - (5/14 * \log_2(5/14) + 5/14 * \log_2(5/14)+ 4/14 * \log_2(4/14)) = 1.577 \tag{20} IV=−(5/14∗log2(5/14)+5/14∗log2(5/14)+4/14∗log2(4/14))=1.577(20)
因此,最终得到的GR值:
G a i n R a t i o = I n f o r m a t i o n G a i n I n f o r m a t i o n V a l u e = 0.15 (21) Gain\ Ratio = \frac{Information\ Gain}{Information\ Value} = 0.15 \tag{21} Gain Ratio=Information ValueInformation Gain=0.15(21)
C4.5的连续变量处理方法就是在连续变量中寻找相邻的取值的中间点作为备选切分点,通过计算切分后的GR值来挑选最终数据集划分方式。
例如:如果将上述数据集的age列换成连续变量,则需要计算的GR情况就变成了GR(income)、GR(student)、GR(credit_rating)、GR(age<=26.5)、GR(age<=27.5)…
5.3 CART算法的基本建模流程(非常重要)
CART(Classification and Regression Trees)是决策树的一种,既可以用于分类任务也可以用于回归任务。它仅使用二叉树进行决策,即每个内部节点只会产生两个子节点,相比于ID3和C4.5,CART算法处理连续型和离散型数据更加方便。
CART分类树使用基尼系数来选择最优划分特征和划分点;CART回归树使用样本的方差或者绝对偏差作为划分准则。
还是使用这个数据来说明,它在创建备选规则时是这样做的:
首先逐列对其进行数值排序,单独提取income和credit_rating两列来进行降序排序,排序结果如下:

然后,寻找这些特征不同取值之间的中间点作为切点,来构造备选规则。
例如income有两个取值1、2,因此只有一个切点就是1.5,就能创造一个income <= 1.5的规则来对数据集进行划分,从而就能把income取值为1的数据划归一个子集、income取值为2的数据集划归另一个子集。如果特征是三个取值的特征,则可以找到两个切点、找到两种划分数据集的方式,依此类推。
如果该数据中某特征是连续变量,每条不同的数据取值都不同,例如:

可以将其看成是有8个分类水平的分类变量,通过寻找相邻取值水平的中间值作为切点来构造划分规则,比如可以构造7个备选的划分数据集的方法(age <= 36、age <= 34.5 …)。
总的来说,无论是连续型变量还是分类变量,只要有N个取值,就可以创造N-1个划分条件将原数据集划分成两份。
在理解了如何创建备选规则后,就需要挑选最佳分类规则进行建树。
对于上述A数据集,总共有两个特征,每个特征有一个备选划分规则,因此在对根结点划分时,其实是有两种数据集的划分方法,如果采用income <= 1.5进行分类的结果:
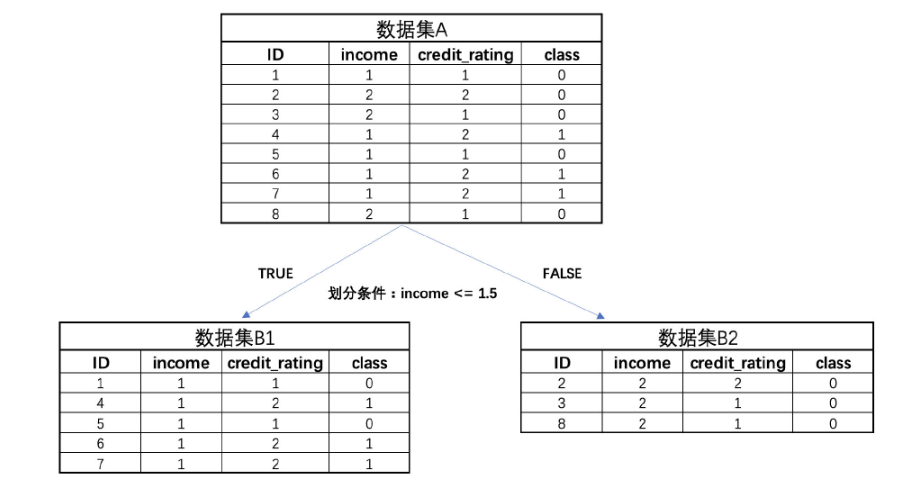
而如果采用credit_rating <= 1.5来对数据集进行划分,则将出现下述结果:
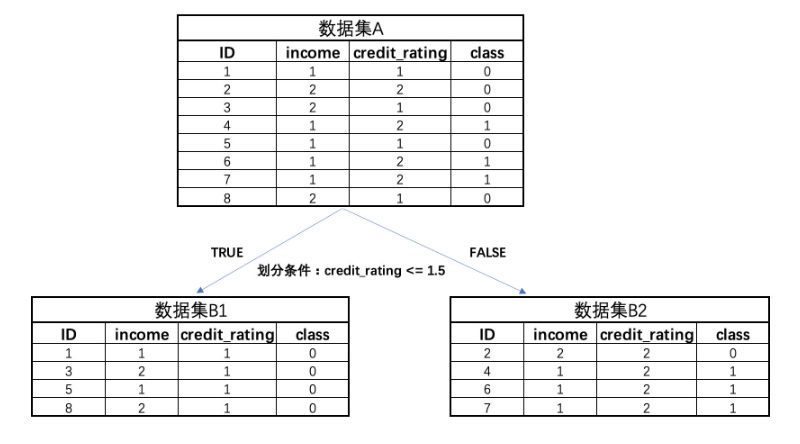
从结果上来看,这两个划分条件都能切分出一个只包含一类标签的数据集,结果区分不是很大,那么到底应该选用哪个分类规则对数据集进行第一次切分、让决策树完成第一步的生长呢?
这个时候就要用到分类规则的评估指标,一般来说对于多个规则,首先会计算父节点的基尼系数(Gini(A)),然后计算划分出的两个子节点整体基尼系数(Gini(B)),通过对比哪种划分方式能够让二者差值更大,即能够让子节点的基尼系数下降更快,就选用哪个规则,代码如下:
import numpy as npdef gini(p):"""根据类别概率计算基尼系数"""return 1 - np.sum(np.power(p, 2))# 计算数据集A的基尼系数
A = np.array([5/8, 3/8])
gini_A = gini(A)
print(f"Gini index of dataset A: {gini_A:.3f}")# 计算数据集B1的基尼系数
B1 = np.array([2/5, 3/5])
gini_B1 = gini(B1)
print(f"Gini index of dataset B1: {gini_B1:.3f}")# 计算数据集B2的基尼系数
B2 = np.array([3/3, 0/3])
gini_B2 = gini(B2)
print(f"Gini index of dataset B2: {gini_B2:.3f}")# 计算分类后的整体基尼系数
gini_total = 5/8 * gini_B1 + 3/8 * gini_B2
print(f"Overall Gini index after splitting: {gini_total:.3f}")# 计算基尼系数的下降值
gini_decrease = gini_A - gini_total
print(f"Gini decrease: {gini_decrease:.3f}")
结果如下:

如果采用第二个划分规则来进行数据集切分,则此时基尼系数下降结果为:
# 计算数据集B1的基尼系数
B1 = np.array([4/4, 0/4])
gini_B1 = gini(B1)
print(f"Gini index of dataset B1: {gini_B1:.3f}")# 计算数据集B2的基尼系数
B2 = np.array([1/4, 3/4])
gini_B2 = gini(B2)
print(f"Gini index of dataset B2: {gini_B2:.3f}")# 计算分类后的整体基尼系数
gini_total = 4/8 * gini_B1 + 4/8 * gini_B2
print(f"Overall Gini index after splitting: {gini_total:.3f}")# 计算基尼系数的下降值
gini_decrease = gini_A - gini_total
print(f"Gini decrease: {gini_decrease:.3f}")
结果如下:

第二个规则能够让父节点的基尼系数下降更快,即credit_rating <= 1.5,所以在第一次数据集划分时应该采用该规则。
当完成一次规则筛选与树生长后,接下来需要考虑的问题是,面对当前划分出的数据集B1、B2,是否还需要进一步寻找分类规则对其进行划分。
首先,对于数据集B1来说,其基尼系数已经为0,无需再进行计算;
B2数据集基尼系数为0.375,还可以进一步提取有效分类规则对其进行分类,以降低其基尼系数。此时就要完全重复数据集A的划分过程,首先围绕数据集B2进行备选规则的提取,对于B2来说备选规则只有income <= 1.5一条,因此就以该规则划分数据集:

最终划分出来的C1和C2基尼系数都是0,到此为止决策树也停止生长。
总的来说:决策树的生长过程本质上也是在进行迭代运算,根据上一轮的到的结论(数据集划分情况)作为基础条件,来寻找子数据集的最佳分类规则,然后来进行数据集划分,以此往复。
六、剪枝策略
决策树是一种贪心算法,它在每个节点处都会选择最好的分裂属性(即信息增益最大或基尼系数最小的属性),以尽可能准确地对训练数据进行分类。然而,这种方法有可能导致过拟合,即决策树模型过于复杂,对训练数据的拟合过好,以至于失去了对未知数据(测试数据)的泛化能力。
决策树其本身就是一个更容易过拟合的模型。生长的层数越多就表示树模型越复杂,此时模型结构风险就越高、模型越容易过拟合。因此,很多时候如果不对树的生长进行任何约束,即如果设置的收敛条件较为严格(例如要求最终基尼系数全为0),并且最大迭代次数不进行限制,则很有可能容易过拟合。因此在决策树的建模流程当中,有非常重要的一个环节,就是需要限制决策树模型过拟合倾向的。
不同决策树算法的剪枝策略也各有不同,总的来说树模型的剪枝分为两种,
- 在模型生长前就限制模型生长,这种方法也被称为预剪枝或者盆栽法,其思想是在构建决策树的过程中,对每一个节点在划分前先进行估计,若当前节点的划分不能带来决策树泛化性能的提升,则停止划分并将当前节点标记为叶节点;
- 先让树模型尽可能的生长,然后再进行剪枝,这种方法也被称为后剪枝或者修建法,其思想是先构造完整的决策树,然后自底向上对非叶节点进行考察,若剪枝后能带来决策树泛化性能的提升,则进行剪枝。
C4.5和CART树都采用的是后剪枝的方法,无论是预剪枝还是后剪枝,其目标都是为了简化模型,提高模型的泛化能力,避免过拟合现象的出现。
七、总结
在这篇文章中,详细介绍了决策树的基本概念、构建及生长过程。对分类规则评估指标,包括分类误差、信息熵和基尼系数的计算及其作用做了介绍。最后,深入分析了三种主要的决策树算法:ID3、C4.5和CART,以及它们的建模流程。希望能帮助到大家对决策树有一个清晰的理解。
最后,感谢您阅读这篇文章!如果您觉得有所收获,别忘了点赞、收藏并关注我,这是我持续创作的动力。您有任何问题或建议,都可以在评论区留言,我会尽力回答并接受您的反馈。如果您希望了解某个特定主题,也欢迎告诉我,我会乐于创作与之相关的文章。谢谢您的支持,期待与您共同成长!
期待与您在未来的学习中共同成长。