事务
- 一.MVCC机制(读-写)
- 1.预备知识
- 1.三个记录隐藏字段
- 2.undo日志
- 2.模拟MVCC
- 3.Read View
- 4.整体流程
- 二.RC与RR的本质区别
- 1.当前读和快照读在RR级别下的区别
- 1.测试一
- 2.测试二
- 2.RR 与 RC的本质区别
数据库并发的场景有三种:
读-读 :不存在任何问题,也不需要并发控制(不讨论)
读-写 :有线程安全问题,可能会造成事务隔离性问题,可能遇到脏读,幻读,不可重复读(主要内容)
写-写 :有线程安全问题,可能会存在更新丢失问题,比如第一类更新丢失,第二类更新丢失(问题较少本篇不讨论)
一.MVCC机制(读-写)
多版本并发控制( MVCC )是一种用来解决 读-写冲突的无锁并发控制。
1.预备知识
1.每个事务都要有自己的事务ID,可以根据事务ID的大小,来决定事务到来的先后顺序。
2.mysqla可能会面临处理多个事务的情况,事务也有自己的生命周期,mysqd要对多个事务进行管理,先描述,再组织。事务在我看来,mysqla中一定是对应的一个或者一套结构体对象(类对象,事务也要有自己的结构体。
1.三个记录隐藏字段
DB_TRX_ID :6 byte,最近修改( 修改/插入 )事务ID,记录创建这条记录/最后一次修改该记录的事
务ID。
DB_ROLL_PTR : 7 byte,回滚指针,指向这条记录的上一个版本(简单理解成,指向历史版本就行,这些数据一般在 undo log 中)。
DB_ROW_ID : 6 byte,隐含的自增ID(隐藏主键),如果数据表没有主键, InnoDB 会自动以
DB_ROW_ID 产生一个聚簇索引。
补充:实际还有一个删除flag隐藏字段, 既记录被更新或删除并不代表真的删除,而是删除flag变了
例如创建一张表
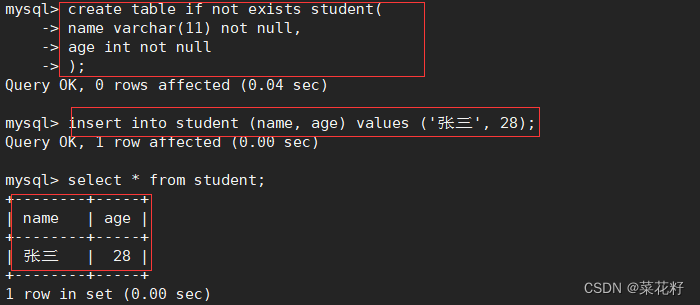
上面的意思是:

2.undo日志
MySQL 将来是以服务进程的方式,在内存中运行。我们之前所讲的所有机制:索引,事务,隔离性,日志等,都是在内存中完成的,即在 MySQL 内部的相关缓冲区中,保存相关数据,完成各种判断操作。然后在合适的时候,将相关数据刷新到磁盘当中的。
所以,我们这里理解undo log,简单理解成,就是 MySQL 中的一段内存缓冲区,用来保存日志数据的就行。
2.模拟MVCC
现在有一个事务10,对student表中记录进行修改(update):将name(张三)改成name(李四)。
修改前,现该行记录拷贝到undo log中,所以undo log中就有了一行副本数据。(原理就是写时拷贝)所以现在 MySQL 中有两行同样的记录。现在修改原始记录中的name,改成 ‘李四’。并且修改原始记录的隐藏字段 DB_TRX_ID 为当前 事务10 的ID,我们默认从 10 开始,之后递增。而原始记录的回滚指针 DB_ROLL_PTR 列,里面写入undolog中副本数据的地址,从而指向副本记录,即表示我的上一个版本就是它。

现在又有一个事务11,对student表中记录进行修改(update):将age(28)改成age(38)。
修改前,现将改行记录拷贝到undo log中,所以,undo log中就又有了一行副本数据。此时,新的 副本,我们采用头插方式,插入undo log。现在修改原始记录中的age,改成 38。并且修改原始记录的隐藏字段 DB_TRX_ID 为当前 事务11的ID。而原始记录的回滚指针 DB_ROLL_PTR 列,里面写入undolog中副本数据的地址,从而指向副本记录,既表示我的上一个版本就是它。
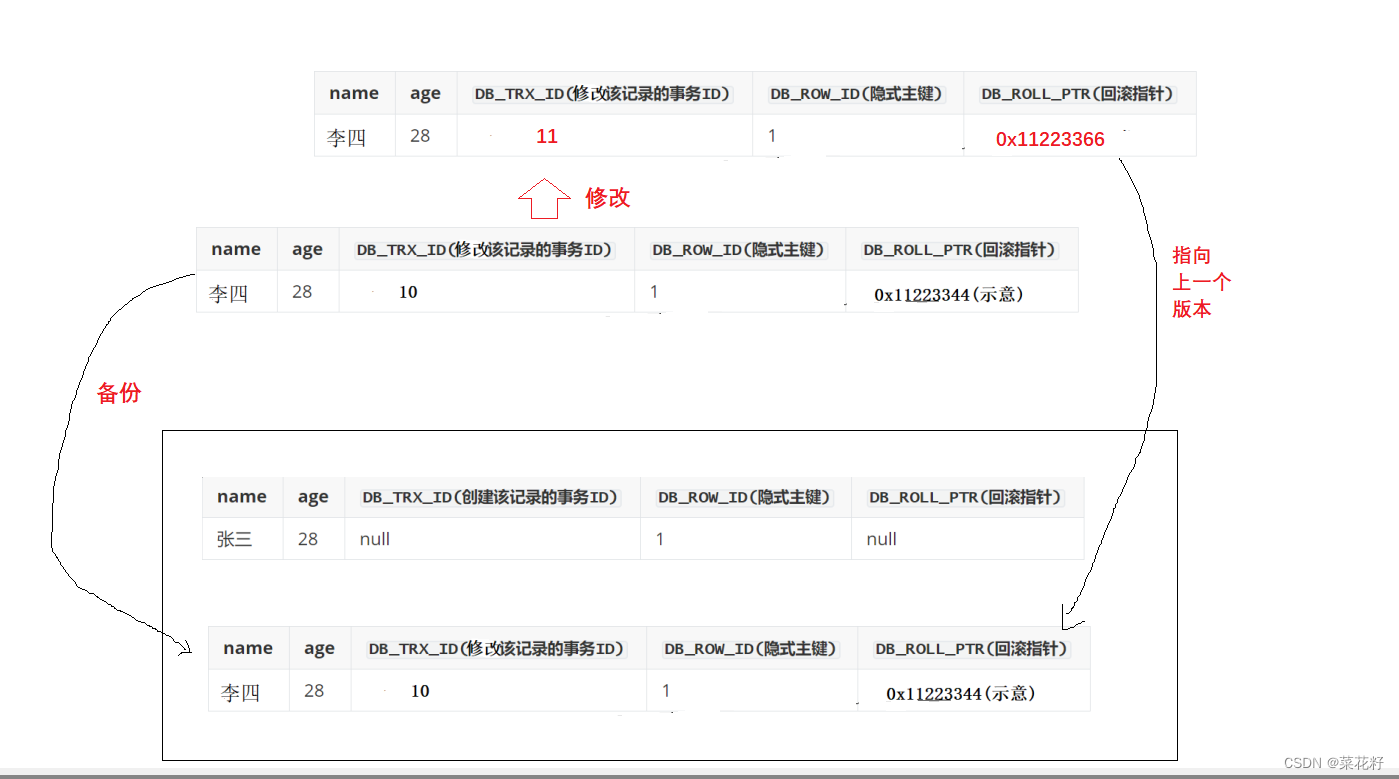
这样,我们就有了一个基于链表记录的历史版本链。所谓的回滚,无非就是用历史数据,覆盖当前数
据。
上面的一个一个版本,我们可以称之为一个一个的快照。快照读:读取历史版本(一般而言),就叫做快照读。
一些思考
上面是以更新(
upadte)主讲的,如果是delete呢?一样的,别忘了,删数据不是清空,而是设置flag为删除即可。也可以形成版本。
如果是
insert呢?因为insert是插入,也就是之前没有数据,那么insert也就没有历史版本。但是一般为了回滚操作,insert的数据也是要被放入undo
log中,如果当前事务commit了,那么这个undolog的历史insert记录就可以被清空了。
总结一下,也就是我们可以理解成,
update和delete可以形成版本链,insert暂时不考虑。
所以为什么我们选择不同的隔离级别用select看到的数据是不一样的呢?就是因为我们看到的是不同版本。换言之我们select看到哪个版本,由隔离级别决定。
3.Read View
Read View就是事务进行 快照读 操作的时候生产的 读视图 (Read View),在该事务执行的快照读的那一刻,会生成数据库系统当前的一个快照,记录并维护系统当前活跃事务的ID(当每个事务开启时,都会被分配一个ID, 这个ID是递增的,所以最新的事务,ID值越大)
Read View 在 MySQL 源码中,就是一个类,本质是用来进行可见性判断的。 即当我们某个事务执行快照读的时候,对该记录创建一个 Read View 读视图,把它比作条件,用来判断当前事务能够看到哪个版本的数据,既可能是当前最新的数据,也有可能是该行记录的 undo log 里面的某个版本的数据。
该类里有很多数据,最重要的是以下四个:

我们在实际读取数据版本链的时候,是能读取到每一个版本对应的事务ID的,即:当前记录的
DB_TRX_ID 。
那么,我们现在手里面有的东西就有,当前快照读的 ReadView 和 版本链中的某一个记录的
DB_TRX_ID 。
所以现在的问题就是,当前快照读,应不应该读到当前版本记录。
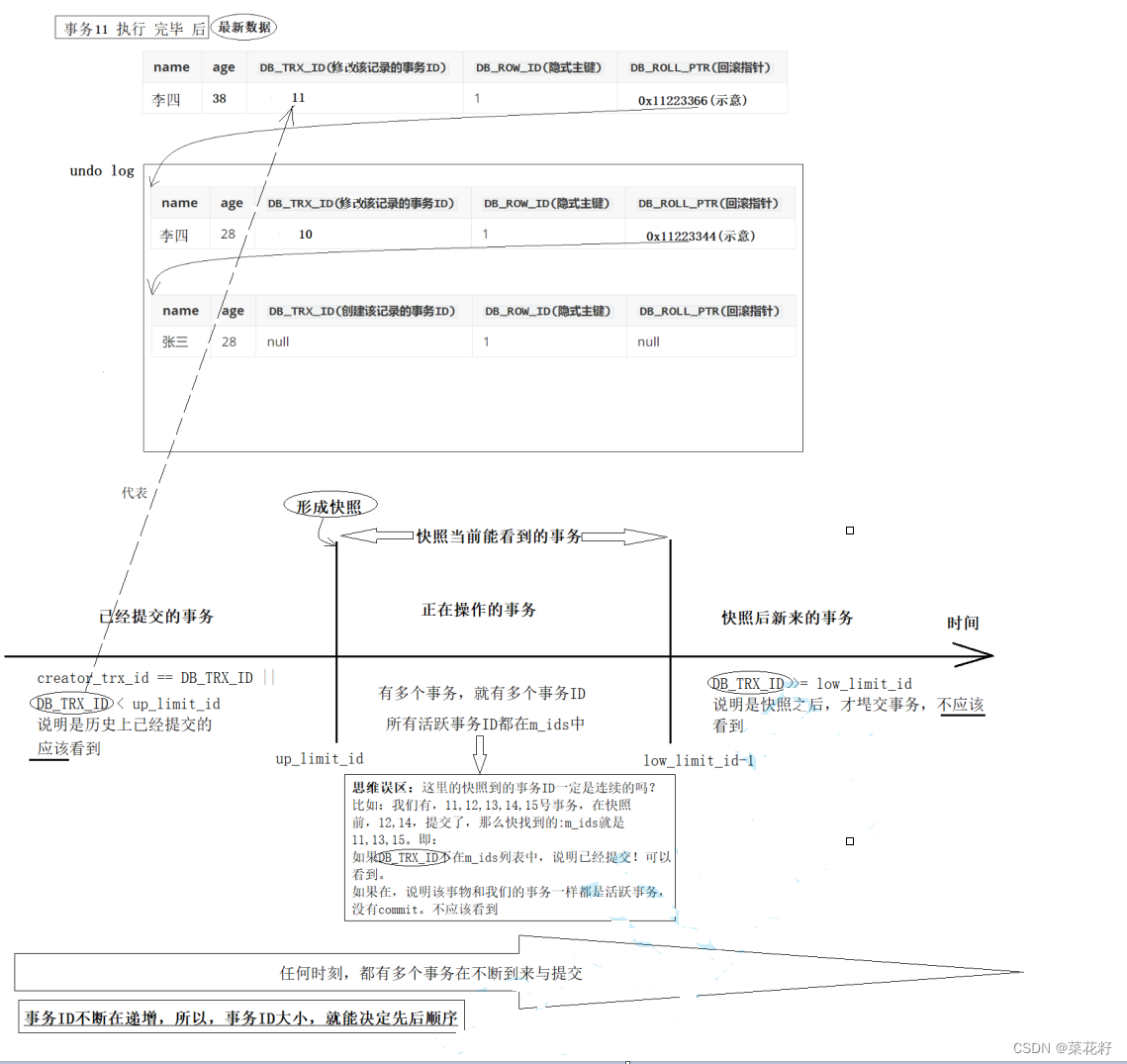
read view是事务的一个可见类,不是事务创建出来的,而是当事务首先进行快照读时而创建的。
4.整体流程
假设当前有条记录:

事务操作:
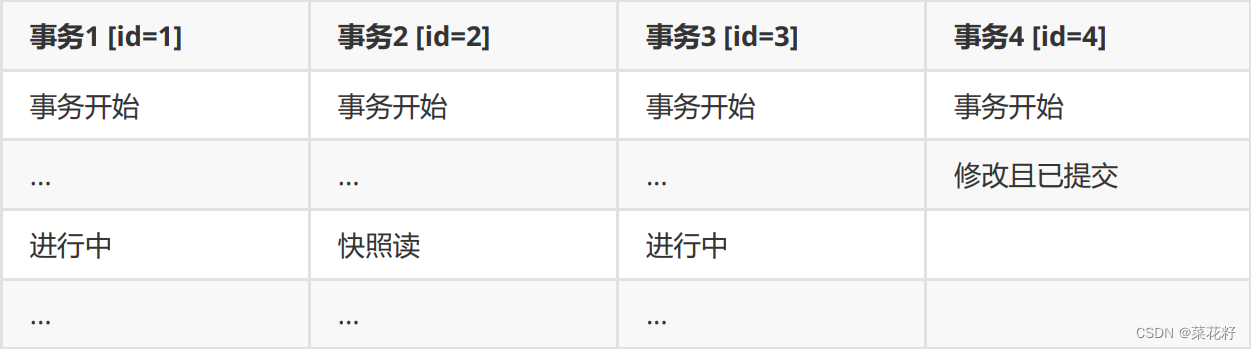
事务4:修改name(张三) 变成name(李四)。
当 事务2 对某行数据执行了 快照读 ,数据库为该行数据生成一个 Read View 读视图。

此时版本链是:

我们的事务2在快照读该行记录的时候,就会拿该行记录的 DB_TRX_ID 去跟up_limit_id,low_limit_id和活跃事务ID列表(trx_list) 进行比较,判断当前事务2能看到该记录的版本。

二.RC与RR的本质区别
1.当前读和快照读在RR级别下的区别
创建一张表:
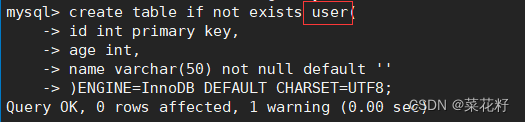
插入一条数据:

设置表为RR隔离级别,再开启手动提交:

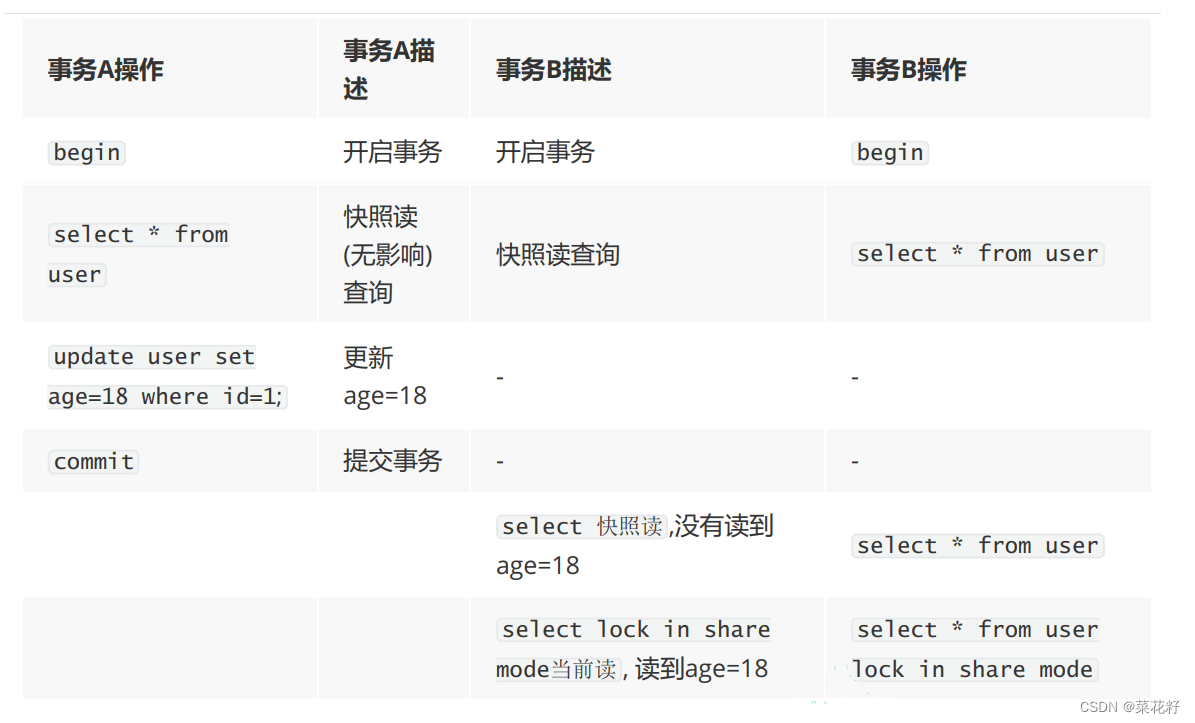
1.测试一
首先对两个终端都进行select查找。

接着使用左边终端对age进行修改,然后提交事务。
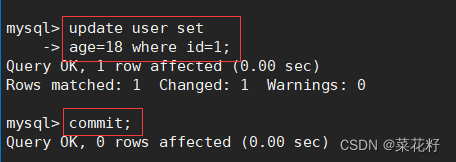
再使用右边终端进行快照读。
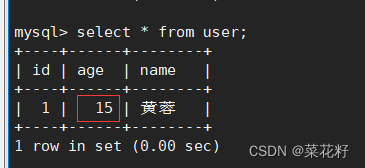
可以看到其实查到的表并未发生改变。因为事务B在事务A修改之前使用了select*(也就是快照的),生成了read view,那么它读到的版本就应该是A进行修改前的版本。
2.测试二
把两个事务进行rollback。接着与上面的操作保持一致,仅仅将事务A进行commit前,事务B的select*动作去掉。

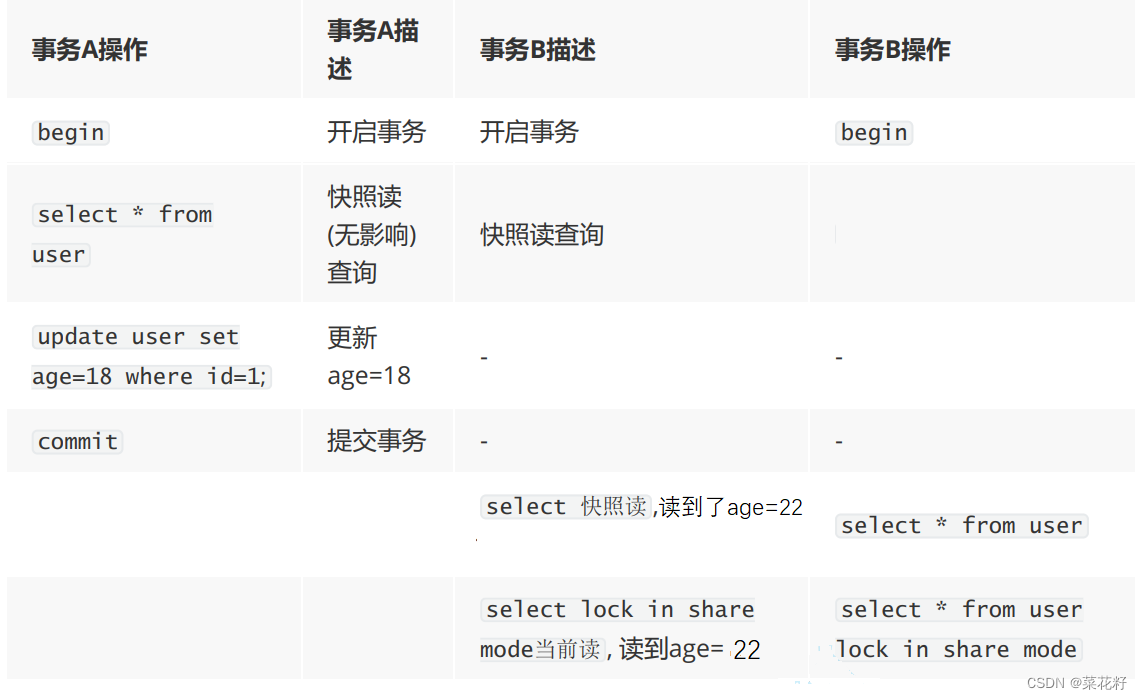
结论:
-
事务中快照读的结果是非常依赖该事务首次出现快照读的地方,即某个事务中首次出现快照读,决定该事务后续快照读结果的能力。
-
delete同样如此。
2.RR 与 RC的本质区别
1.正是Read View生成时机的不同,从而造成RC,RR级别下快照读的结果的不同。
2.在RR级别下的某个事务的对某条记录的第一次快照读会创建一个快照及Read View, 将当前系统活跃的其他事务记录起来此后在调用快照读的时候,还是使用的是同一个Read View,所以只要当前事务在其他事务提交更新之前使用过快照读,那么之后的快照读使用的都是同一个Read View,所以对之后的修改不可见;
3.即RR级别下,快照读生成Read View时,Read View会记录此时所有其他活动事务的快照,这些事 务的修改对于当前事务都是不可见的。而早于Read View创建的事务所做的修改均是可见。
4.而在RC级别下的,事务中,每次快照读都会新生成一个快照和Read View, 这就是我们在RC级别下 的事务中可以看到别的事务提交的更新的原因。
5.总之在RC隔离级别下,是每个快照读都会生成并获取最新的Read View;而在RR隔离级别下,则是同一个事务中的第一个快照读才会创建Read View, 之后的快照读获取的都是同一个Read View。
6.正是RC每次快照读,都会形成Read View,所以,RC才会有不可重复读问题。