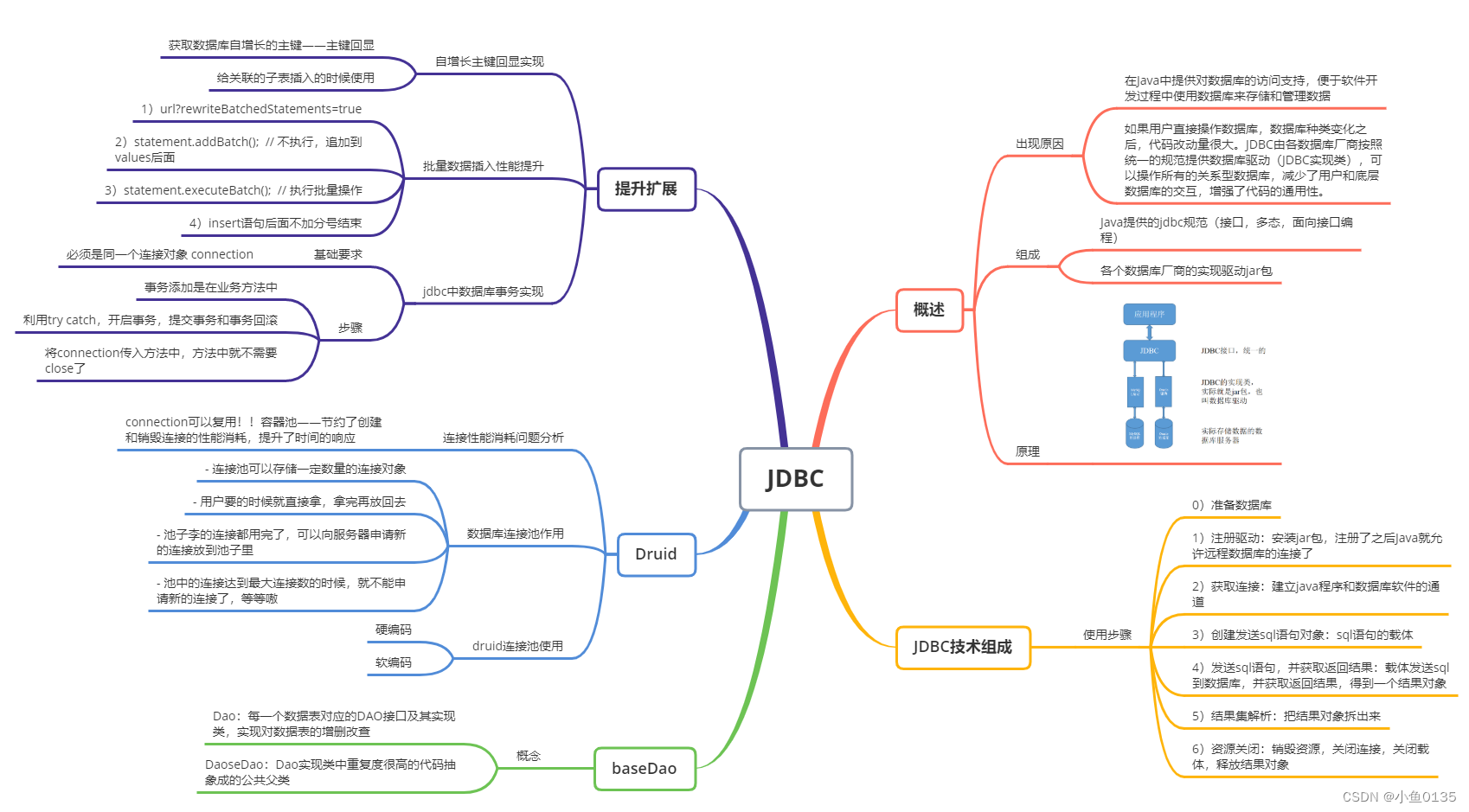
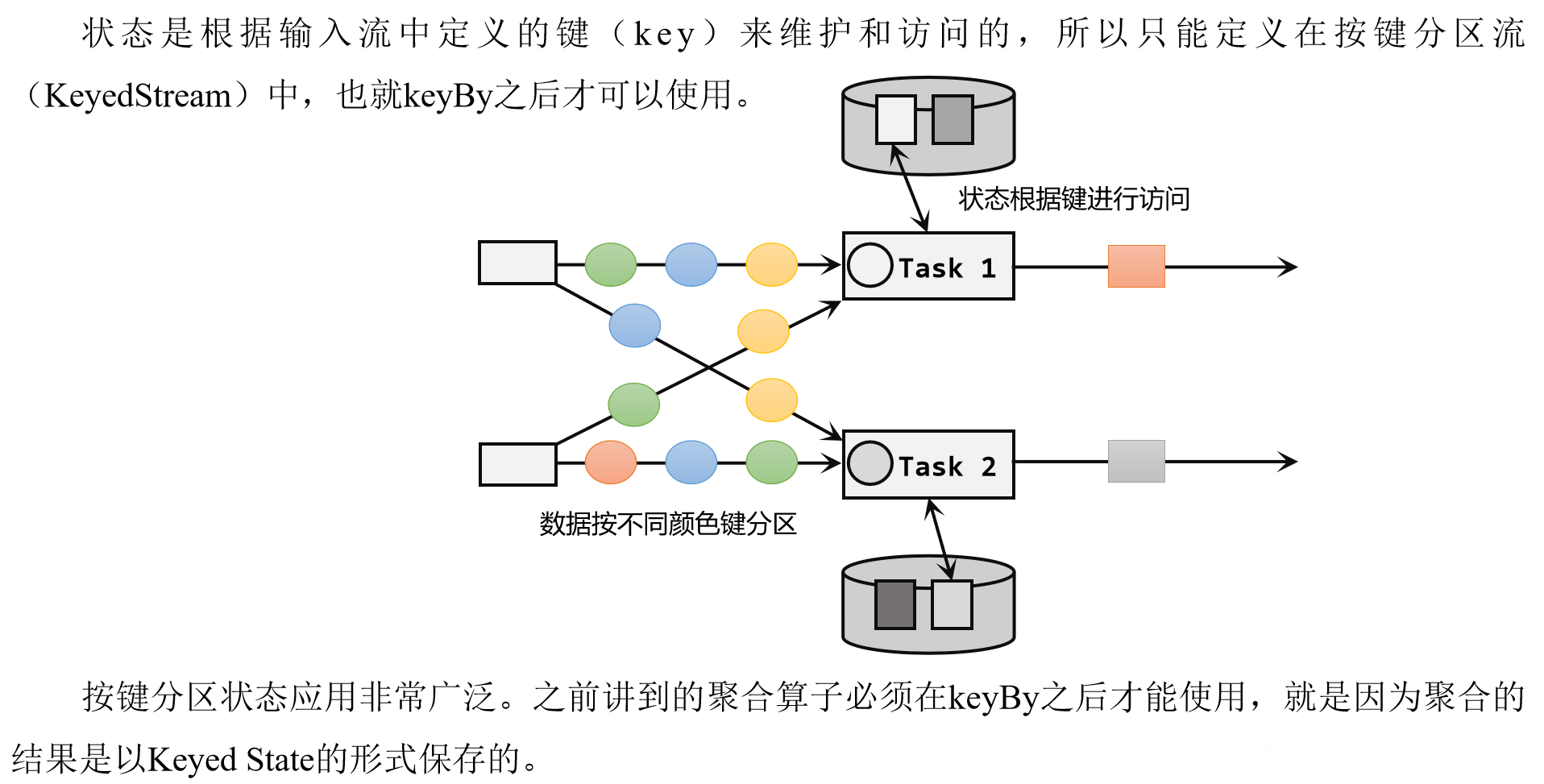
论文:Dosovitskiy A, Beyer L, Kolesnikov A, et al. An image is worth 16x16 words: Transformers for image recognition at scale[J]. arXiv preprint arXiv:2010.11929, 2020
源码的Pytorch版:https://github.com/lucidrains/vit-pytorch
0.前言
Transformer提出后在NLP领域中取得了极好的效果,其全Attention的结构,不仅增强了特征提取能力,还保持了并行计算的特点,可以又快又好的完成NLP领域内几乎所有任务,极大地推动自然语言处理的发展。
VIT这篇文章就是将Transformer模型应用在了CV领域,它将图像处理成Transformer模型可以应用的形式,沿用NLP领域中Transformer的方法,直接验证了其精度可以和ResNet不相上下,展示了在计算机视觉中使用纯Transformer结构的可能,为Transformer在CV领域的应用打开了大门。
直接读文章通常比较抽象,英文的原文更能劝退一大部分人,但对于程序员来说,代码是通行于世界的语言,理解起来就比较简单,结合源码理解论文中的结构,就比较事半功倍。
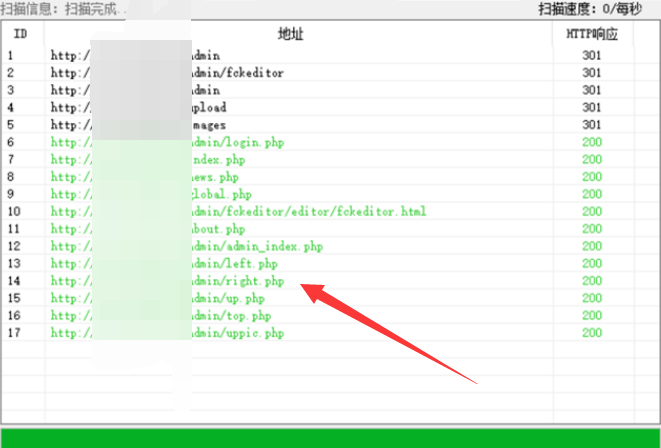
上图是VIT文章中的结构,我们看图提问题,从数据的流向来看:图像怎么切分重排的?Linear Projection of Flattened Patches对图像作了什么,怎么让图像变成Transformer能够输入的格式?
Position Embedding是怎么做图像位置编码的,为什么会多出来一个0的位置编码?Transformer Encoder中的各个结构分别代表什么,是怎么实现的?输出的类别是什么?
1.图像是如何适配Transformer输入的?
Transformer的输入是一个一维的向量,而我们的图像是二维的,需要把图像拉伸成一维的,最简单的方式就是沿着x轴展开,将所有的行拼接在一起,也就是Flatten的操作,但是这样处理会导致向量维度比较大,而且同一张图片也只能生成一个Embedding,不能适配Multi-head Embedding(这种解释有点牵强,有点拿结果去解释原因)。
1.1 图像切分重排
如结构图所示,VIT采取了图像切分重排的方式,将一个完整的图像按照行列的方向切分成小块,然后再进行后续处理。切分重排是怎么实现的,我们看代码:
self.to_patch_embedding = nn.Sequential(Rearrange('b c (h p1) (w p2) -> b (h w) (p1 p2 c)', p1 = patch_height, p2 = patch_width), #图片切分重排nn.Linear(patch_dim, dim), # Linear Projection of Flattened Patches)
这里的Rearrange使用到了einops的库,相关的介绍可以查看文档
这里主要是对b c (h p1) (w p2) -> b (h w) (p1 p2 c)表达式的理解,b是batchsize,c是chanel,h和w是图像的高度和宽度,表达式前边的(h p1)表示将输入的h重新拆分成一个h*p1的向量,同理(w p2)是将输入的w拆分成w*p2的向量,这里的p1和p2是模型定义的patch_height和patch_width,可以理解为切分后小图的高和宽;
表达式右边表示输出向量的维度,(p1 p2 c)表示这3个数相乘,表示的是切分后一个小图的一维向量大小,(h w)则表示总共有多少个切分后的小图所生成的向量。这里的h和w的值跟输入的h和w值不同,表示的是原有h和w除以patch_height或patch_width的值,也就是在高和宽上各能切分出几个小图。
通过这样的处理,就将输入的c个channel的h*w的二维向量,转换成小图展开后的一维向量。
1.2 构建patch0
图像在输入Transformer之前,还连接了一个patch0,这一步的操作可以认为是延续了nlp的操作,在VIT这边的操作,可以认为是将分类类别拼接上去。
cls_tokens = repeat(self.cls_token, '1 1 d -> b 1 d', b = b)
x = torch.cat((cls_tokens, x), dim=1)
1.3 Positional Embedding
为了在模型中引入位置信息,VIT引入了位置编码的形式,也就是图中的0、1、2、3…
x += self.pos_embedding[:, :(n + 1)]
然后将position_embedding与图像的Embedding相加。
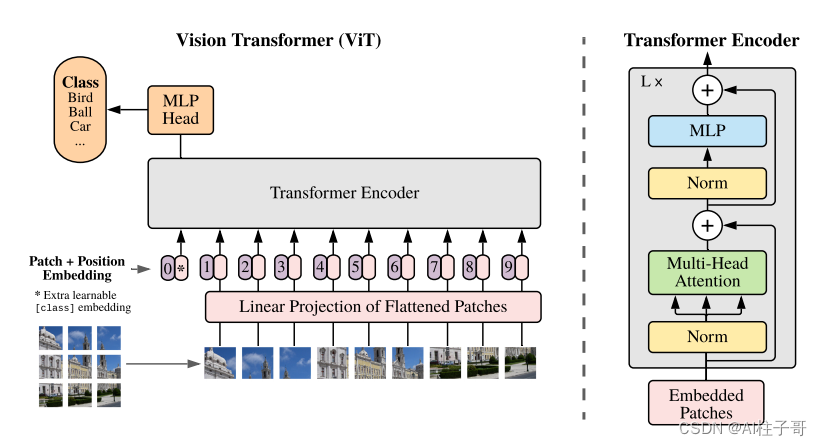
2.Transformer Encoder中的各个结构分别代表什么,是怎么实现的?
结构中的Norm可以认为是归一化处理,MLP是多个全连接层,理解起来都比较简单。其实最主要的结构就是Multi-head Attention。
2.1 Attention 定义
class Attention(nn.Module):def __init__(self, dim, heads = 8, dim_head = 64, dropout = 0.):super().__init__()inner_dim = dim_head * headsproject_out = not (heads == 1 and dim_head == dim)self.heads = headsself.scale = dim_head ** -0.5self.attend = nn.Softmax(dim = -1)self.to_qkv = nn.Linear(dim, inner_dim * 3, bias = False)self.to_out = nn.Sequential(nn.Linear(inner_dim, dim),nn.Dropout(dropout)) if project_out else nn.Identity()def forward(self, x):b, n, _, h = *x.shape, self.headsqkv = self.to_qkv(x).chunk(3, dim = -1)#得到qkvq, k, v = map(lambda t: rearrange(t, 'b n (h d) -> b h n d', h = h), qkv)dots = einsum('b h i d, b h j d -> b h i j', q, k) * self.scaleattn = self.attend(dots)out = einsum('b h i j, b h j d -> b h i d', attn, v)out = rearrange(out, 'b h n d -> b n (h d)')return self.to_out(out)
2.2 Attention 的理解
VIT不同于之前RNN的地方就是引入了Attention机制,其本质可以认为是相似度计算,是计算每一个输入值与其他输入值的相似度,然后带入到计算中,如图所示,q是输入的查询值,k是关键词,v是计算值,计算每一个q与其他k的相似度,然后再带入计算中去。
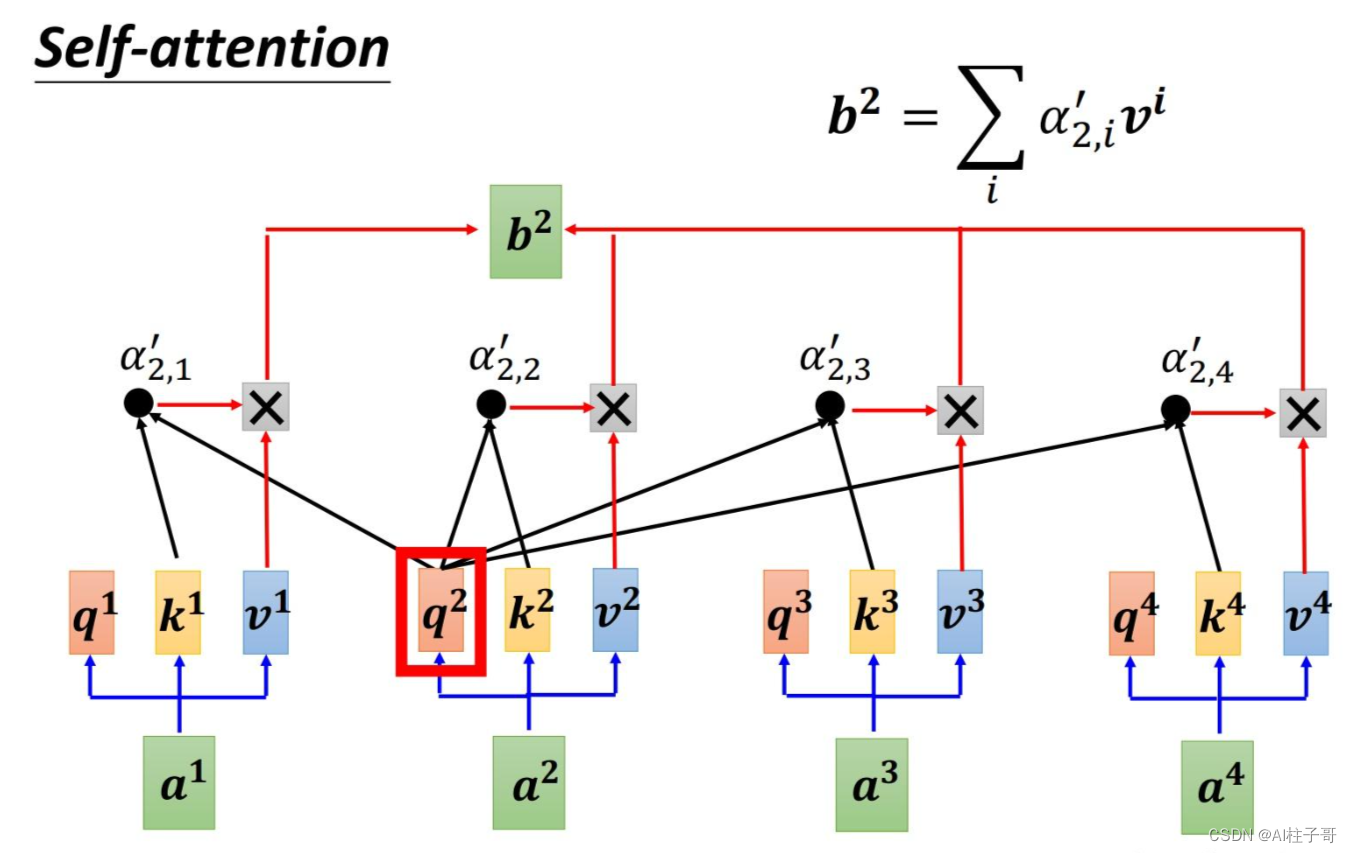
其对应的计算公式为:
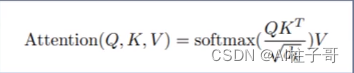
相似度计算是用的点积的形式,除以根号下dk是为了抑制极端值,保证softmax之后数值不至于丧失梯度。对应的代码如下:
qkv = self.to_qkv(x).chunk(3, dim = -1)
q, k, v = map(lambda t: rearrange(t, 'b n (h d) -> b h n d', h = self.heads), qkv)dots = torch.matmul(q, k.transpose(-1, -2)) * self.scale
然后过一个softmax
attn = self.attend(dots) # self.attend = nn.Softmax(dim = -1)
attn = self.dropout(attn)
然后跟value值相乘
out = torch.matmul(attn, v)
2.3 Multihead Attention
多头注意力机制可以认为是定义多个Attention(每个attention关注的重点不同)分别来对数据进行处理,这里从源码中的循环结构可以体现出来:
class Transformer(nn.Module):def __init__(self, dim, depth, heads, dim_head, mlp_dim, dropout = 0.):super().__init__()self.norm = nn.LayerNorm(dim)self.layers = nn.ModuleList([])for _ in range(depth):self.layers.append(nn.ModuleList([Attention(dim, heads = heads, dim_head = dim_head, dropout = dropout),FeedForward(dim, mlp_dim, dropout = dropout)]))def forward(self, x):for attn, ff in self.layers:x = attn(x) + xx = ff(x) + xreturn self.norm(x)
3.使用示例
这里可以参考官方的readme文档
$ pip install vit-pytorch
使用示例
import torch
from vit_pytorch import ViTv = ViT(image_size = 256,patch_size = 32,num_classes = 1000,dim = 1024,depth = 6,heads = 16,mlp_dim = 2048,dropout = 0.1,emb_dropout = 0.1
)img = torch.randn(1, 3, 256, 256)preds = v(img) # (1, 1000)
![[Redis实战]优惠券秒杀](https://img-blog.csdnimg.cn/direct/a948fd24a90a48ca8cdd57655b26988c.png)