本篇是NLP论文系列的最后一篇,主要介绍如何计算情感分析结果,并将其融入到XX评价体系和物流关键词词库,之前我已经写了两篇关于情感分析的文章,分别是 SnowNLP 和 Cemotion 技术,最终我才用了 jiagu 来写我的论文,因为 jiagu 准确率还行,并且写这个技术的毕竟少。
目录
1 基于 Jiagu 的情感分析
1.1 Jiagu 介绍
1.2 情感分析计算
① 语料
② Jiagu 计算
③ xx 关键词匹配
2 XX评价体系结合情感分析
代码地址:nlp_yinyu
1 基于 Jiagu 的情感分析
Jiagu 和 SnowNLP + Cemotion 类似,均是情感分析技术之一,另外两种技术文章也在该专栏下,采用哪种看大家如何选择,本文主要介绍如何将情感分析技术融入到论文中。
1.1 Jiagu 介绍
Jiagu 情感分析是一种中文自然语言处理工具,用于识别和分析文本中的情感倾向,它可以根据文本的内容和语义,判断文本中的情感是积极的、消极的还是中性的。
它使用机器学习算法和自然语言处理技术来处理文本,并通过训练模型来识别情感。该工具可以应用于各种文本数据,如社交媒体评论、新闻文章、产品评论等。
Jiagu情感分析具有以下特点:高准确性、快速处理和多种应用场景。
1.2 情感分析计算
① 语料
语料依然是以之前爬取的京东网站上的 5000 条评论数据,可在文章顶部的代码仓库中下载!

② Jiagu 计算
主要分为以下三步:
- 引入语料 excel 数据
- 计算每条评论的情感值
- 生成【Jiagu情感分析原始结果_京东.xlsx】文件
代码如下:
import pandas as pd
import jiagu
from base_handle import BaseHandle # 引入工具类baseHandle = BaseHandle() # 实例化def jiagu_cal(url):'''计算每条评论的情感值'''df = pd.read_excel(url, sheet_name='Sheet1')# print(df)# 定义函数,批量处理所有的评论信息def get_sentiment_cn(text):return jiagu.sentiment(text)[1] # jiagu的后边带positive或negative# 根据df里的“comments”列,将读取文本后的情感分析结果添加到新的一列,命名为“sentiment”df["sentiment"] = df['评论'].apply(get_sentiment_cn)# print(df)# 储存为表格。df.to_excel('Jiagu情感分析原始结果_京东.xlsx')if __name__ == "__main__":jiagu_cal(baseHandle.get_file_abspath('语料库_京东_5000条评论.xlsx'))
最终输出【Jiagu情感分析原始结果_京东.xlsx】文件如下:
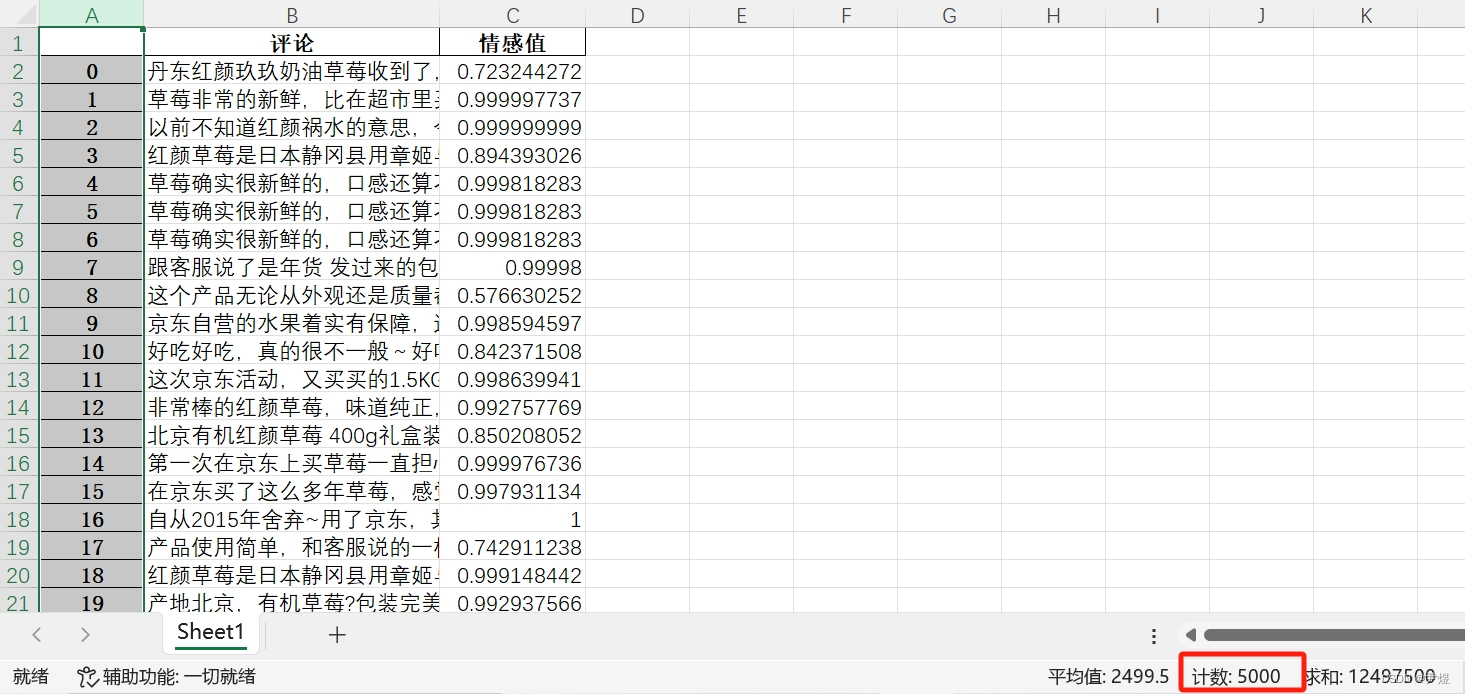
每条评论都给安排了一个情感值~
③ xx 关键词匹配
以物流关键词词库为例,将每个关键词的情感值计算出来,本文的计算逻辑:统计该关键词在多少条评论中存在,若存在,则这些评论的情感值加和。
步骤如下:
- 读取物流关键词词库
- 统计每个关键词的情感值大小
- 生成【jiagu情感分析匹配结果_京东.xlsx】文件
import pandas as pd
import jiagu
from base_handle import BaseHandle # 引入工具类baseHandle = BaseHandle() # 实例化def match_words_jiagu():'''匹配关键词和情感分析结果'''words = baseHandle.logistics_listitems = []for word in words:row = handle_senti_result(word, "评论", "情感值")row.insert(0, word)items.append(row)dt = pd.DataFrame(items, columns=['关键词', '评论数量', '好评率', '情感值方差', '情感均值', '情感中值'])dt.to_excel("jiagu情感分析匹配结果_京东.xlsx")def handle_senti_result(word, col1, col2):'''子方法—统计每个关键词的情感值大小'''df = pd.read_excel('Jiagu情感分析原始结果_京东.xlsx', sheet_name='Sheet1')b1 = []b2 = []for i in range(len(df)):comment = df.loc[i, col1]if word in comment: # 判断关键词是否存在于某个字符串(str)中a1 = df.loc[i, col1]a2 = df.loc[i, col2]if not a1 in b1: # col1:评论,col2:情感值,去掉重复的评论,也可不去掉b1.append(a1)b2.append(a2)else:continueelse:continuef1 = pd.DataFrame(columns=['评论', '情感值'])f1['评论'] = b1f1['情感值'] = b2# print('分值之和:',f1['情感值'].sum())seti = f1['情感值']# 一些列数据row = [seti.count(), f1[seti >= 0.6]['情感值'].count() / seti.count(),seti.var(), seti.mean(), seti.median()]return rowif __name__ == "__main__":match_words_jiagu()
最终输出【jiagu情感分析匹配结果_京东.xlsx】文件如下:
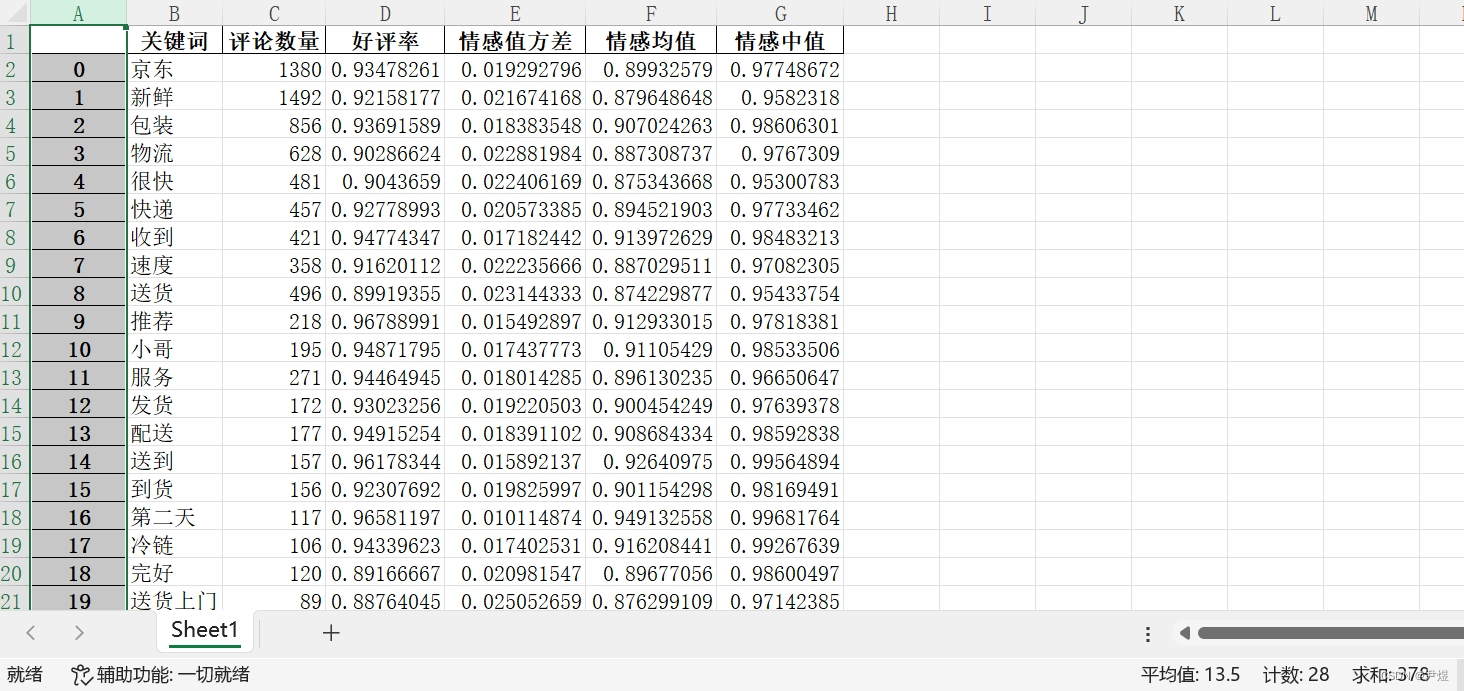
如图,得到了每个关键词的情感分析详细数据,那么就可以拿这些数据来做些其他事情了~
2 XX评价体系结合情感分析
以物流评价体系为例,结合 TF-IDF 和 Jiagu 情感分析结果(本文只采用了它的情感均值)
如图:
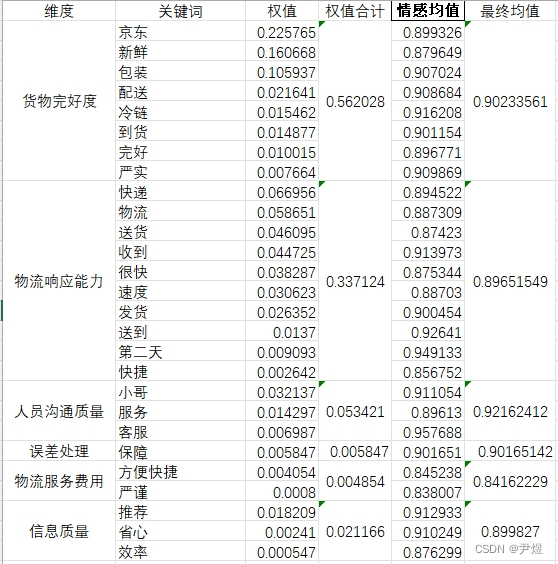
这是一个比较粗略的统计结果,可以展示各维度他的重要程度以及情感值(或者说评分大小),不要忘了语料来自于网上在线评论。
以上还可以做更多研究,希望给大家提供帮助。因为毕业论文用到了这些技术,所以想着总结一下,最近终于有空把它更完了,纪念一下学生时代~





![web:[BJDCTF2020]The mystery of ip(ssti模板注入、Smarty 模板引擎)](https://img-blog.csdnimg.cn/direct/f6884aa9d28b4722a2c0cca18ce80514.png)
