本文已收录至Github,推荐阅读 👉 Java随想录
微信公众号:Java随想录
文章目录
- 写入过程
- 写操作
- 写流程
- 写一致性策略
- 写入原理
- Refresh
- Merge
- Flush
- Translog
- 图解写入流程
ES作为一款开源的分布式搜索和分析引擎,以其卓越的性能和灵活的扩展性而备受青睐。
在实际应用中,如何最大限度地发挥ES的写入能力并保证数据的一致性和可靠性仍然是一个值得关注的话题。
接下来,我们将深入了解ES的写入过程和原理。
写入过程
写操作
ES支持四种对文档的数据写操作:
- create:如果在PUT数据的时候当前数据已经存在,则数据会被覆盖。如果在PUT的时候加上操作类型create,此时如果数据已存在,则会返回失败,因为已经强制指定了操作类型为create,ES就不会再去执行update操作。
- delete:删除文档,ES对文档的删除是懒删除机制,即标记删除,会被记录在
.del文件中。在后续的合并(merge)过程中,Elasticsearch会根据一定的条件和策略,将包含已删除文档的分段进行合并。在合并期间,.del文件中的已删除文档将被完全删除,从而释放磁盘空间。 - index:在ES中,写入操作被称为Index,这里Index为动词,即索引数据,为数据创建在ES中的索引。
- update:执行partial update(全量更新,部分更新)。PUT是全量更新,POST是部分更新。
写流程
ES中的数据写入均发生在 Primary Shard,当数据在 Primary Shard 写入完成之后会同步到相应的 Replica Shard
下图演示了单条数据写入ES的流程:

以下为数据写入的步骤:
- 客户端发起写入请求至node-4。
- node-4通过文档 id 在路由表中的映射信息确定当前数据的位置在分片0,分片0的主分片位于node-5,并将数据转发至node-5。
- 数据在node-5写入,写入成功之后将数据的同步请求转发至其副本所在的node-4和node-6上面,等待所有副本数据写入成功之后,node-5将结果报告node-4,并由node-4将结果返回给客户端,报告数据写入成功。
在这个过程中,接收用户请求的节点是不固定的,上述例子中,node-4 发挥了协调节点和客户端节点的作用,将数据转发至对应节点和接收以及返回用户请求。
数据在由 node-4 转发至 node-5的时候,是通过以下公式来计算指定的文档具体在哪个分片的:
shard_num = hash(_routing) % num_primary_shards
其中,_routing 的默认值就是文档的 id。
写一致性策略
ES 5.x 之后,一致性策略由 wait_for_active_shards 参数控制。
wait_for_active_shards 即确定客户端返回数据之前必须处于 active 的分片数(包括主分片和副本),默认值为1,即只需要主分片写入成功。
最大值为 number_of_replicas + 1 ,可以设置为 all或任何正整数。如果当前 active 状态的分片没有达到设定阈值,写操作必须等待并且重试,默认等待时间30秒,直到 active 状态的副本数量超过设定的阈值或者超时返回失败为止。
假设我们有一个由A、B、C三个节点组成的集群。并且我们创建了一个index副本数设置为3的索引(此时共4个分片数据,比节点数多一个)。
如果我们尝试索引操作,默认情况下,该操作只会确保每个主分片的主副本在继续之前可用。这意味着即使B和c出现故障被A托管主分片,索引操作仍将仅使用数据的一个副本进行。
如果wait_for_active_shards设置为3(并且所有3个节点都已启动),那么索引操作将需要3个活动分片才能继续进行,因为集群中有3个活动节点,每个节点都持有一个活跃,所以满足这一要求。
但是,如果我们设置wait_for_active_shards为all(或设置为4),数据写入将直接失败,因为集群此时根本不可能有四个活跃的分片。
除非在集群中启动一个新节点来托管分片的第四个分片,否则该操作将超时。
写入原理
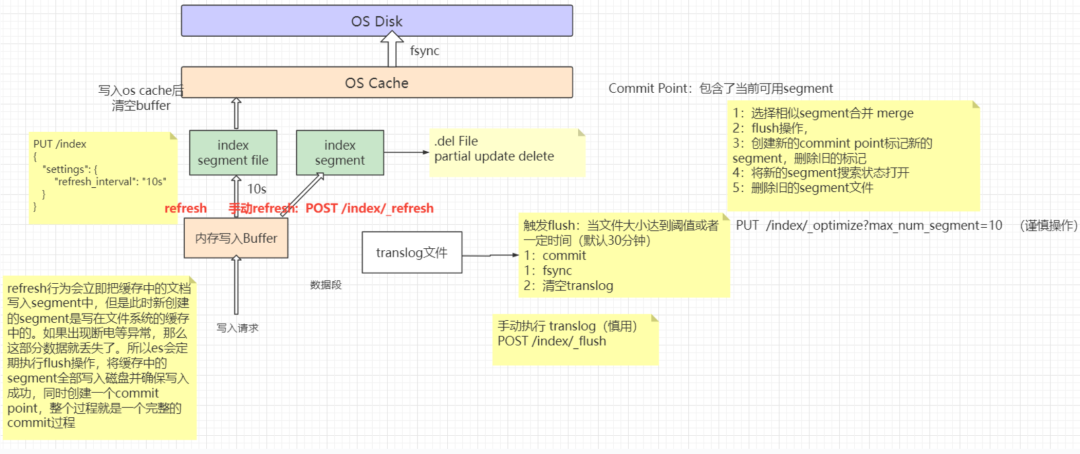
Refresh
ES中数据并不是直接写到文件系统缓存里的,在内部ES开辟了名为:Memory Buffer的缓存区。
Memory Buffer的性能非常高,客户端发出写入请求的时候是直接写在Memory Buffer里的。
Memory Buffer的空间阈值默认大小为堆内存的10%,时间阈值为1s。空间阈值和时间阈值只要达成任意一个,就会触发 Refresh操作
也可以调用 Refresh API 来人工触发 Refresh 操作:
POST <target>/_refreshGET <target>/_refreshPOST /_refreshGET /_refresh
Refresh 操作会将缓存中的数据生成一个个 segment 文件。
原理见下图:

内存索引缓冲区中的文档被写入新段,新段首先写入文件系统缓存(这个过程性能消耗很低),然后才刷新到磁盘(这个过程代价很高)。但是,在文件进入缓存后,它就可以像任何其他文件一样被打开和读取。

Lucene 允许写入和打开新的段,使它们包含的文档对搜索可见,而无需执行完整的提交。这是一个比提交到磁盘更轻松的过程,并且可以经常执行而不会降低性能。

这个写入和打开新段的过程即被称为 Refresh 。刷新使自上次刷新以来对索引执行的所有操作都可用于搜索。
index.refresh_interval参数可以设置多久执行一次刷新操作,默认为 1s,可以设置 -1 禁用刷新。
并不是所有的情况都需要每秒刷新。比如 Elasticsearch 索引大量的日志文件,此时并不需要太高的写入实时性, 可以增大刷新间隔来降低每个索引的刷新频率,从而降低因为实时性而带来的性能开销,进而提升检索效率。
POST <index_name>
{"settings": {"refresh_interval": "30s"}
}
需要注意的是,虽然此时数据能被查询到,但还没落到磁盘中,数据仍然是不安全的
Merge
由于自动刷新流程每秒会创建一个新的段 ,这样会导致短时间内的段数量暴增。而段数量太多会带来较大的麻烦,每一个段都会消耗文件句柄、内存和cpu运行周期。更重要的是,每个搜索请求都必须轮流检查每个段,所以段越多,搜索也就越慢。
Elasticsearch通过在后台进行段合并来解决这个问题。小的段被合并到大的段,然后这些大的段再被合并到更大的段。

Elasticsearch 中的一个 shard 是一个 Lucene 索引,一个 Lucene 索引被分解成段。段是存储索引数据的索引中的内部存储元素,并且是不可变的。较小的段会定期合并到较大的段中,并删除较小的段。

Merge是非常消耗资源的,Refesh的频率越高,生成Segment的频率就越高,Merge就执行的越频繁
合并大的段需要消耗大量的I/O和CPU资源,如果任其发展会影响搜索性能。Elasticsearch在默认情况下会对合并流程进行资源限制,所以搜索仍然有足够的资源很好地执行。
Flush
Flush 是确保当前存储在 Translog 中的数据也永久存储在 Lucene 索引中的过程。
重新启动时,Elasticsearch 会将所有未刷新的操作从 Translog 重播到 Lucene 索引,以使其恢复到重新启动前的状态。Elasticsearch 会根据需要自动触发Flush,使用启发式算法来权衡未刷新事务日志的大小与执行每次刷新的成本。
一旦操作被刷新,它就会永久存储在 Lucene 索引中。这可能意味着不需要在事务日志中维护它的额外副本。事务日志由多个文件组成,称为 generation ,一旦不再需要,Elasticsearch 将删除相应的文件,从而释放磁盘空间。
也可以使用 Flush API 触发一个或多个索引的刷新,尽管用户很少需要直接调用此 API。如果您在索引某些文档后调用刷新 API,并成功响应,表明 Elasticsearch 已刷新在调用刷新 API 之前索引的所有文档。
POST /my_index/_flush
请注意,手动调用刷新操作可能会对系统性能产生一定的影响,因为它涉及到磁盘写入和索引更新。建议在必要时使用手动刷新操作,而不是频繁地调用。
Translog
对索引的修改操作会在 Lucene 执行 commit 之后真正持久化到磁盘,这个过程是非常消耗资源的,因此不可能在每次索引操作或删除操作后执行。Lucene 提交的成本太高,无法对每个单独的更改执行,因此每个分片副本先将操作写入其事务日志,也就是 Translog。
所有索引和删除操作在被内部 Lucene 索引处理之后,但在它们被确认之前写入到 translog。如果发生崩溃,当分片恢复时,已确认但尚未包含在最后一次 Lucene 提交中的最近操作将从 translog 中恢复。
ES的 Flush 是 Lucene 执行 commit 并开始写入 translog 的过程,Flush 是在后台自动执行的,translog 中的数据仅在 translog 被执行 fsync 和 commit 时才会持久化到磁盘。如果发生硬件故障或操作系统崩溃或 JVM 崩溃或分片故障,自上次 translog 提交以来写入的任何数据都将丢失。
以下参数可控制 translog 的行为:
-
index.translog.sync_interval:无论写入操作如何,translog 默认每隔 5s 被 fsync 写入磁盘并 commit 一次,不允许设置小于 100ms 的提交间隔。设置得较小,例如设置为 1s,会增加磁盘 I/O 的频率,但能提供更高的数据持久性。与之相反,若设置得较大,例如设置为 -1,表示关闭自动触发的 Translog 刷新机制,将完全依赖于系统或文件系统层面的刷新策略。这样可以提高写入性能,但可能会增加数据丢失风险。 -
index.translog.durability:此参数定义了刷新到磁盘的方式,该参数有以下可选值:request:表示 Elasticsearch 在响应客户端请求之前必须将数据刷新到磁盘。这是最安全的选项,但可能会影响写入性能。async:表示 Elasticsearch 在异步模式下将数据刷新到磁盘。它允许更高的写入性能,但可能会增加一定的数据丢失风险。fsync:表示 Elasticsearch 在将数据刷新到磁盘后,通过执行 fsync 操作来确保数据已经写入到物理介质。这是最慢的选项,但提供了最高的数据持久性。
默认情况下,
index.translog.durability的值为request,即 Elasticsearch 必须在响应客户端请求之前将数据刷新到磁盘,以确保数据的持久性。 -
index.translog.flush_threshold_size:此参数定义了触发 Translog 刷新的阈值大小,默认值为 512MB。这意味着当 Translog 中累积的数据大小达到或超过 512MB 时,Elasticsearch 将自动触发刷新操作,将数据刷新到磁盘。可以根据实际需求调整该参数的值。如果值设置得较小,例如设置为 128MB,会增加 Translog 刷新的频率,但可能会对系统的写入性能产生一定影响。而将其设置得较大,则会减少 Translog 刷新的频率,提高写入性能,但也会增加数据丢失风险。
图解写入流程
一图以蔽之: