- 🍨 本文为🔗365天深度学习训练营 中的学习记录博客
- 🍖 原作者:K同学啊 | 接辅导、项目定制
- 🚀 文章来源:K同学的学习圈子
文章目录
- 前言
- 1 我的环境
- 2 pytorch实现DenseNet算法
- 2.1 前期准备
- 2.1.1 引入库
- 2.1.2 设置GPU(如果设备上支持GPU就使用GPU,否则使用CPU)
- 2.1.3 导入数据
- 2.1.4 可视化数据
- 2.1.4 图像数据变换
- 2.1.4 划分数据集
- 2.1.4 加载数据
- 2.1.4 查看数据
- 2.2 搭建densenet121模型
- 2.3 训练模型
- 2.3.1 设置超参数
- 2.3.2 编写训练函数
- 2.3.3 编写测试函数
- 2.3.4 正式训练
- 2.4 结果可视化
- 2.4 指定图片进行预测
- 2.6 模型评估
- 3 tensorflow实现DenseNet算法
- 3.1.引入库
- 3.2.设置GPU(如果使用的是CPU可以忽略这步)
- 3.3.导入数据
- 3.4.查看数据
- 3.5.加载数据
- 3.6.再次检查数据
- 3.7.配置数据集
- 3.8.可视化数据
- 3.9.构建DenseNet网络
- 3.10.编译模型
- 3.11.训练模型
- 3.12.模型评估
- 3.13.图像预测
- 4 知识点详解
- 4.1 DenseNet算法详解
- 4.1.1 前言
- 4.1.2 设计理念
- 4.1.2.1 标准神经网络
- 4.1.2.2 ResNet
- 4.1.2.3 DenseNet
- 4.1.3 网络结构
- 4.1.4 效果对比
- 4.1.5 使用Pytroch实现DenseNet121
- 总结
前言
关键字: pytorch实现DenseNet算法,tensorflow实现DenseNet算法,DenseNet算法详解
1 我的环境
- 电脑系统:Windows 11
- 语言环境:python 3.8.6
- 编译器:pycharm2020.2.3
- 深度学习环境:
torch == 1.9.1+cu111
torchvision == 0.10.1+cu111
TensorFlow 2.10.1 - 显卡:NVIDIA GeForce RTX 4070
2 pytorch实现DenseNet算法
2.1 前期准备
2.1.1 引入库
import torch
import torch.nn as nn
import time
import copy
from torchvision import transforms, datasets
from pathlib import Path
from PIL import Image
import torchsummary as summary
import torch.nn.functional as F
from collections import OrderedDict
import re
import torch.utils.model_zoo as model_zoo
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号
plt.rcParams['figure.dpi'] = 100 # 分辨率
import warningswarnings.filterwarnings('ignore') # 忽略一些warning内容,无需打印2.1.2 设置GPU(如果设备上支持GPU就使用GPU,否则使用CPU)
"""前期准备-设置GPU"""
# 如果设备上支持GPU就使用GPU,否则使用CPUdevice = torch.device("cuda" if torch.cuda.is_available() else "cpu")print("Using {} device".format(device))
输出
Using cuda device
2.1.3 导入数据
'''前期工作-导入数据'''
data_dir = r"D:\DeepLearning\data\bird\bird_photos"
data_dir = Path(data_dir)data_paths = list(data_dir.glob('*'))
classeNames = [str(path).split("\\")[-1] for path in data_paths]
print(classeNames)
输出
['Bananaquit', 'Black Skimmer', 'Black Throated Bushtiti', 'Cockatoo']2.1.4 可视化数据
'''前期工作-可视化数据'''
subfolder = Path(data_dir) / "Cockatoo"
image_files = list(p.resolve() for p in subfolder.glob('*') if p.suffix in [".jpg", ".png", ".jpeg"])
plt.figure(figsize=(10, 6))
for i in range(len(image_files[:12])):image_file = image_files[i]ax = plt.subplot(3, 4, i + 1)img = Image.open(str(image_file))plt.imshow(img)plt.axis("off")
# 显示图片
plt.tight_layout()
plt.show()

2.1.4 图像数据变换
'''前期工作-图像数据变换'''
total_datadir = data_dir# 关于transforms.Compose的更多介绍可以参考:https://blog.csdn.net/qq_38251616/article/details/124878863
train_transforms = transforms.Compose([transforms.Resize([224, 224]), # 将输入图片resize成统一尺寸transforms.ToTensor(), # 将PIL Image或numpy.ndarray转换为tensor,并归一化到[0,1]之间transforms.Normalize( # 标准化处理-->转换为标准正太分布(高斯分布),使模型更容易收敛mean=[0.485, 0.456, 0.406],std=[0.229, 0.224, 0.225]) # 其中 mean=[0.485,0.456,0.406]与std=[0.229,0.224,0.225] 从数据集中随机抽样计算得到的。
])
total_data = datasets.ImageFolder(total_datadir, transform=train_transforms)
print(total_data)
print(total_data.class_to_idx)
输出
Dataset ImageFolderNumber of datapoints: 565Root location: D:\DeepLearning\data\bird\bird_photosStandardTransform
Transform: Compose(Resize(size=[224, 224], interpolation=bilinear, max_size=None, antialias=None)ToTensor()Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]))
{'Bananaquit': 0, 'Black Skimmer': 1, 'Black Throated Bushtiti': 2, 'Cockatoo': 3}2.1.4 划分数据集
'''前期工作-划分数据集'''
train_size = int(0.8 * len(total_data)) # train_size表示训练集大小,通过将总体数据长度的80%转换为整数得到;
test_size = len(total_data) - train_size # test_size表示测试集大小,是总体数据长度减去训练集大小。
# 使用torch.utils.data.random_split()方法进行数据集划分。该方法将总体数据total_data按照指定的大小比例([train_size, test_size])随机划分为训练集和测试集,
# 并将划分结果分别赋值给train_dataset和test_dataset两个变量。
train_dataset, test_dataset = torch.utils.data.random_split(total_data, [train_size, test_size])
print("train_dataset={}\ntest_dataset={}".format(train_dataset, test_dataset))
print("train_size={}\ntest_size={}".format(train_size, test_size))
输出
train_dataset=<torch.utils.data.dataset.Subset object at 0x000001309DFA26D0>
test_dataset=<torch.utils.data.dataset.Subset object at 0x000001309DFA2760>
train_size=452
test_size=113
2.1.4 加载数据
'''前期工作-加载数据'''
batch_size = 32train_dl = torch.utils.data.DataLoader(train_dataset,batch_size=batch_size,shuffle=True,num_workers=1)
test_dl = torch.utils.data.DataLoader(test_dataset,batch_size=batch_size,shuffle=True,num_workers=1)
2.1.4 查看数据
'''前期工作-查看数据'''
for X, y in test_dl:print("Shape of X [N, C, H, W]: ", X.shape)print("Shape of y: ", y.shape, y.dtype)break
输出
Shape of X [N, C, H, W]: torch.Size([32, 3, 224, 224])
Shape of y: torch.Size([32]) torch.int64
2.2 搭建densenet121模型
"""构建DenseNet网络"""
# 这里我们采用了Pytorch的框架来实现DenseNet,
# 首先实现DenseBlock中的内部结构,这里是BN+ReLU+1×1Conv+BN+ReLU+3×3Conv结构,最后也加入dropout层用于训练过程。
class _DenseLayer(nn.Sequential):"""Basic unit of DenseBlock (using bottleneck layer) """def __init__(self, num_input_features, growth_rate, bn_size, drop_rate):super(_DenseLayer, self).__init__()self.add_module('norm1', nn.BatchNorm2d(num_input_features)),self.add_module('relu1', nn.ReLU(inplace=True)),self.add_module('conv1', nn.Conv2d(num_input_features, bn_size * growth_rate,kernel_size=1, stride=1, bias=False)),self.add_module('norm2', nn.BatchNorm2d(bn_size * growth_rate)),self.add_module('relu2', nn.ReLU(inplace=True)),self.add_module('conv2', nn.Conv2d(bn_size * growth_rate, growth_rate,kernel_size=3, stride=1, padding=1, bias=False)),self.drop_rate = drop_ratedef forward(self, x):new_features = super(_DenseLayer, self).forward(x)if self.drop_rate > 0:new_features = F.dropout(new_features, p=self.drop_rate, training=self.training)return torch.cat([x, new_features], 1)# 实现DenseBlock模块,内部是密集连接方式(输入特征数线性增长):
class _DenseBlock(nn.Sequential):"""DenseBlock """def __init__(self, num_layers, num_input_features, bn_size, growth_rate, drop_rate):super(_DenseBlock, self).__init__()for i in range(num_layers):layer = _DenseLayer(num_input_features + i * growth_rate, growth_rate, bn_size, drop_rate)self.add_module('denselayer%d' % (i + 1), layer)# 实现Transition层,它主要是一个卷积层和一个池化层:
class _Transition(nn.Sequential):def __init__(self, num_input_features, num_output_features):super(_Transition, self).__init__()self.add_module('norm', nn.BatchNorm2d(num_input_features))self.add_module('relu', nn.ReLU(inplace=True))self.add_module('conv', nn.Conv2d(num_input_features, num_output_features,kernel_size=1, stride=1, bias=False))self.add_module('pool', nn.AvgPool2d(kernel_size=2, stride=2))# 最后我们实现DenseNet网络:
class DenseNet(nn.Module):r"""Densenet-BC model class, based on`"Densely Connected Convolutional Networks" <https://arxiv.org/pdf/1608.06993.pdf>`Args:growth_rate (int) - how many filters to add each layer (`k` in paper)block_config (list of 3 or 4 ints) - how many layers in each pooling blocknum_init_features (int) - the number of filters to learn in the first convolution layerbn_size (int) - multiplicative factor for number of bottle neck layers(i.e. bn_size * k features in the bottleneck layer)drop_rate (float) - dropout rate after each dense layernum_classes (int) - number of classification classes"""def __init__(self, growth_rate=32, block_config=(6, 12, 24, 16),num_init_features=24, bn_size=4, compression=0.5, drop_rate=0,num_classes=1000):super(DenseNet, self).__init__()# First Conv2dself.features = nn.Sequential(OrderedDict([('conv0', nn.Conv2d(3, num_init_features, kernel_size=7, stride=2, padding=3, bias=False)),('norm0', nn.BatchNorm2d(num_init_features)),('relu0', nn.ReLU(inplace=True)),('pool0', nn.MaxPool2d(kernel_size=3, stride=2, padding=1))]))# Each denseblocknum_features = num_init_featuresfor i, num_layers in enumerate(block_config):block = _DenseBlock(num_layers, num_features, bn_size, growth_rate, drop_rate)self.features.add_module('denseblock%d' % (i + 1), block)num_features += num_layers * growth_rateif i != len(block_config) - 1:transition = _Transition(num_input_features=num_features,num_output_features=int(num_features * compression))self.features.add_module('transition%d' % (i + 1), transition)num_features = int(num_features * compression)# Final bn+reluself.features.add_module('norm5', nn.BatchNorm2d(num_features))self.features.add_module('relu5', nn.ReLU(inplace=True))# classification layerself.classifier = nn.Linear(num_features, num_classes)# params initializationfor m in self.modules():if isinstance(m, nn.Conv2d):nn.init.kaiming_normal_(m.weight)elif isinstance(m, nn.BatchNorm2d):nn.init.constant_(m.bias, 0)nn.init.constant_(m.weight, 1)elif isinstance(m, nn.Linear):nn.init.constant_(m.bias, 0)def forward(self, x):features = self.features(x)out = F.avg_pool2d(features, 7, stride=1).view(features.size(0), -1)out = self.classifier(out)return outmodel_urls = {'densenet121': 'https://download.pytorch.org/models/densenet121-a639ec97.pth','densenet169': 'https://download.pytorch.org/models/densenet169-b2777c0a.pth','densenet201': 'https://download.pytorch.org/models/densenet201-c1103571.pth','densenet161': 'https://download.pytorch.org/models/densenet161-8d451a50.pth'}def densenet121(pretrained=False, **kwargs):"""DenseNet121"""model = DenseNet(num_init_features=64, growth_rate=32, block_config=(6, 12, 24, 16), **kwargs)if pretrained:# '.'s are no longer allowed in module names, but pervious _DenseLayer# has keys 'norm.1', 'relu.1', 'conv.1', 'norm.2', 'relu.2', 'conv.2'.# They are also in the checkpoints in model_urls. This pattern is used# to find such keys.pattern = re.compile(r'^(.*denselayer\d+\.(?:norm|relu|conv))\.((?:[12])\.(?:weight|bias|running_mean|running_var))$')state_dict = model_zoo.load_url(model_urls['densenet121'])for key in list(state_dict.keys()):res = pattern.match(key)if res:new_key = res.group(1) + res.group(2)state_dict[new_key] = state_dict[key]del state_dict[key]model.load_state_dict(state_dict)return model"""搭建densenet121模型"""
# model = densenet121().to(device)
model = densenet121(True).to(device) # 使用预训练模型
print(model)
print(summary.summary(model, (3, 224, 224))) # 查看模型的参数量以及相关指标输出
DenseNet((features): Sequential((conv0): Conv2d(3, 64, kernel_size=(7, 7), stride=(2, 2), padding=(3, 3), bias=False)(norm0): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(relu0): ReLU(inplace=True)(pool0): MaxPool2d(kernel_size=3, stride=2, padding=1, dilation=1, ceil_mode=False)(denseblock1): _DenseBlock((denselayer1): _DenseLayer((norm1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(relu1): ReLU(inplace=True)(conv1): Conv2d(64, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)(norm2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(relu2): ReLU(inplace=True)(conv2): Conv2d(128, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False))(denselayer2): _DenseLayer((norm1): BatchNorm2d(96, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(relu1): ReLU(inplace=True)(conv1): Conv2d(96, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)(norm2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(relu2): ReLU(inplace=True)(conv2): Conv2d(128, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False))(denselayer3): _DenseLayer((norm1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(relu1): ReLU(inplace=True)(conv1): Conv2d(128, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)(norm2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(relu2): ReLU(inplace=True)(conv2): Conv2d(128, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False))(denselayer4): _DenseLayer((norm1): BatchNorm2d(160, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(relu1): ReLU(inplace=True)(conv1): Conv2d(160, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)(norm2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(relu2): ReLU(inplace=True)(conv2): Conv2d(128, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False))(denselayer5): _DenseLayer((norm1): BatchNorm2d(192, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(relu1): ReLU(inplace=True)(conv1): Conv2d(192, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)(norm2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(relu2): ReLU(inplace=True)(conv2): Conv2d(128, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False))(denselayer6): _DenseLayer((norm1): BatchNorm2d(224, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(relu1): ReLU(inplace=True)(conv1): Conv2d(224, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)(norm2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(relu2): ReLU(inplace=True)(conv2): Conv2d(128, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)))(transition1): _Transition((norm): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(relu): ReLU(inplace=True)(conv): Conv2d(256, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)(pool): AvgPool2d(kernel_size=2, stride=2, padding=0))(denseblock2): _DenseBlock((denselayer1): _DenseLayer((norm1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(relu1): ReLU(inplace=True)(conv1): Conv2d(128, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)(norm2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(relu2): ReLU(inplace=True)(conv2): Conv2d(128, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False))(denselayer2): _DenseLayer((norm1): BatchNorm2d(160, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(relu1): ReLU(inplace=True)(conv1): Conv2d(160, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)(norm2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(relu2): ReLU(inplace=True)(conv2): Conv2d(128, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False))(denselayer3): _DenseLayer((norm1): BatchNorm2d(192, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(relu1): ReLU(inplace=True)(conv1): Conv2d(192, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)(norm2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(relu2): ReLU(inplace=True)(conv2): Conv2d(128, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False))(denselayer4): _DenseLayer((norm1): BatchNorm2d(224, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(relu1): ReLU(inplace=True)(conv1): Conv2d(224, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)(norm2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(relu2): ReLU(inplace=True)(conv2): Conv2d(128, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False))(denselayer5): _DenseLayer((norm1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(relu1): ReLU(inplace=True)(conv1): Conv2d(256, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)(norm2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(relu2): ReLU(inplace=True)(conv2): Conv2d(128, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False))(denselayer6): _DenseLayer((norm1): BatchNorm2d(288, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(relu1): ReLU(inplace=True)(conv1): Conv2d(288, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)(norm2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(relu2): ReLU(inplace=True)(conv2): Conv2d(128, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False))(denselayer7): _DenseLayer((norm1): BatchNorm2d(320, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(relu1): ReLU(inplace=True)(conv1): Conv2d(320, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)(norm2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(relu2): ReLU(inplace=True)(conv2): Conv2d(128, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False))(denselayer8): _DenseLayer((norm1): BatchNorm2d(352, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(relu1): ReLU(inplace=True)(conv1): Conv2d(352, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)(norm2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(relu2): ReLU(inplace=True)(conv2): Conv2d(128, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False))(denselayer9): _DenseLayer((norm1): BatchNorm2d(384, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(relu1): ReLU(inplace=True)(conv1): Conv2d(384, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)(norm2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(relu2): ReLU(inplace=True)(conv2): Conv2d(128, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False))(denselayer10): _DenseLayer((norm1): BatchNorm2d(416, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(relu1): ReLU(inplace=True)(conv1): Conv2d(416, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)(norm2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(relu2): ReLU(inplace=True)(conv2): Conv2d(128, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False))(denselayer11): _DenseLayer((norm1): BatchNorm2d(448, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(relu1): ReLU(inplace=True)(conv1): Conv2d(448, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)(norm2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(relu2): ReLU(inplace=True)(conv2): Conv2d(128, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False))(denselayer12): _DenseLayer((norm1): BatchNorm2d(480, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(relu1): ReLU(inplace=True)(conv1): Conv2d(480, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)(norm2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(relu2): ReLU(inplace=True)(conv2): Conv2d(128, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)))(transition2): _Transition((norm): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(relu): ReLU(inplace=True)(conv): Conv2d(512, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)(pool): AvgPool2d(kernel_size=2, stride=2, padding=0))(denseblock3): _DenseBlock((denselayer1): _DenseLayer((norm1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(relu1): ReLU(inplace=True)(conv1): Conv2d(256, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)(norm2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(relu2): ReLU(inplace=True)(conv2): Conv2d(128, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False))(denselayer2): _DenseLayer((norm1): BatchNorm2d(288, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(relu1): ReLU(inplace=True)(conv1): Conv2d(288, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)(norm2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(relu2): ReLU(inplace=True)(conv2): Conv2d(128, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False))(denselayer3): _DenseLayer((norm1): BatchNorm2d(320, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(relu1): ReLU(inplace=True)(conv1): Conv2d(320, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)(norm2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(relu2): ReLU(inplace=True)(conv2): Conv2d(128, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False))(denselayer4): _DenseLayer((norm1): BatchNorm2d(352, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(relu1): ReLU(inplace=True)(conv1): Conv2d(352, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)(norm2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(relu2): ReLU(inplace=True)(conv2): Conv2d(128, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False))(denselayer5): _DenseLayer((norm1): BatchNorm2d(384, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(relu1): ReLU(inplace=True)(conv1): Conv2d(384, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)(norm2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(relu2): ReLU(inplace=True)(conv2): Conv2d(128, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False))(denselayer6): _DenseLayer((norm1): BatchNorm2d(416, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(relu1): ReLU(inplace=True)(conv1): Conv2d(416, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)(norm2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(relu2): ReLU(inplace=True)(conv2): Conv2d(128, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False))(denselayer7): _DenseLayer((norm1): BatchNorm2d(448, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(relu1): ReLU(inplace=True)(conv1): Conv2d(448, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)(norm2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(relu2): ReLU(inplace=True)(conv2): Conv2d(128, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False))(denselayer8): _DenseLayer((norm1): BatchNorm2d(480, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(relu1): ReLU(inplace=True)(conv1): Conv2d(480, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)(norm2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(relu2): ReLU(inplace=True)(conv2): Conv2d(128, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False))(denselayer9): _DenseLayer((norm1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(relu1): ReLU(inplace=True)(conv1): Conv2d(512, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)(norm2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(relu2): ReLU(inplace=True)(conv2): Conv2d(128, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False))(denselayer10): _DenseLayer((norm1): BatchNorm2d(544, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(relu1): ReLU(inplace=True)(conv1): Conv2d(544, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)(norm2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(relu2): ReLU(inplace=True)(conv2): Conv2d(128, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False))(denselayer11): _DenseLayer((norm1): BatchNorm2d(576, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(relu1): ReLU(inplace=True)(conv1): Conv2d(576, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)(norm2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(relu2): ReLU(inplace=True)(conv2): Conv2d(128, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False))(denselayer12): _DenseLayer((norm1): BatchNorm2d(608, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(relu1): ReLU(inplace=True)(conv1): Conv2d(608, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)(norm2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(relu2): ReLU(inplace=True)(conv2): Conv2d(128, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False))(denselayer13): _DenseLayer((norm1): BatchNorm2d(640, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(relu1): ReLU(inplace=True)(conv1): Conv2d(640, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)(norm2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(relu2): ReLU(inplace=True)(conv2): Conv2d(128, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False))(denselayer14): _DenseLayer((norm1): BatchNorm2d(672, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(relu1): ReLU(inplace=True)(conv1): Conv2d(672, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)(norm2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(relu2): ReLU(inplace=True)(conv2): Conv2d(128, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False))(denselayer15): _DenseLayer((norm1): BatchNorm2d(704, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(relu1): ReLU(inplace=True)(conv1): Conv2d(704, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)(norm2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(relu2): ReLU(inplace=True)(conv2): Conv2d(128, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False))(denselayer16): _DenseLayer((norm1): BatchNorm2d(736, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(relu1): ReLU(inplace=True)(conv1): Conv2d(736, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)(norm2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(relu2): ReLU(inplace=True)(conv2): Conv2d(128, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False))(denselayer17): _DenseLayer((norm1): BatchNorm2d(768, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(relu1): ReLU(inplace=True)(conv1): Conv2d(768, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)(norm2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(relu2): ReLU(inplace=True)(conv2): Conv2d(128, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False))(denselayer18): _DenseLayer((norm1): BatchNorm2d(800, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(relu1): ReLU(inplace=True)(conv1): Conv2d(800, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)(norm2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(relu2): ReLU(inplace=True)(conv2): Conv2d(128, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False))(denselayer19): _DenseLayer((norm1): BatchNorm2d(832, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(relu1): ReLU(inplace=True)(conv1): Conv2d(832, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)(norm2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(relu2): ReLU(inplace=True)(conv2): Conv2d(128, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False))(denselayer20): _DenseLayer((norm1): BatchNorm2d(864, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(relu1): ReLU(inplace=True)(conv1): Conv2d(864, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)(norm2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(relu2): ReLU(inplace=True)(conv2): Conv2d(128, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False))(denselayer21): _DenseLayer((norm1): BatchNorm2d(896, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(relu1): ReLU(inplace=True)(conv1): Conv2d(896, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)(norm2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(relu2): ReLU(inplace=True)(conv2): Conv2d(128, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False))(denselayer22): _DenseLayer((norm1): BatchNorm2d(928, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(relu1): ReLU(inplace=True)(conv1): Conv2d(928, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)(norm2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(relu2): ReLU(inplace=True)(conv2): Conv2d(128, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False))(denselayer23): _DenseLayer((norm1): BatchNorm2d(960, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(relu1): ReLU(inplace=True)(conv1): Conv2d(960, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)(norm2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(relu2): ReLU(inplace=True)(conv2): Conv2d(128, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False))(denselayer24): _DenseLayer((norm1): BatchNorm2d(992, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(relu1): ReLU(inplace=True)(conv1): Conv2d(992, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)(norm2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(relu2): ReLU(inplace=True)(conv2): Conv2d(128, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)))(transition3): _Transition((norm): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(relu): ReLU(inplace=True)(conv): Conv2d(1024, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)(pool): AvgPool2d(kernel_size=2, stride=2, padding=0))(denseblock4): _DenseBlock((denselayer1): _DenseLayer((norm1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(relu1): ReLU(inplace=True)(conv1): Conv2d(512, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)(norm2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(relu2): ReLU(inplace=True)(conv2): Conv2d(128, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False))(denselayer2): _DenseLayer((norm1): BatchNorm2d(544, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(relu1): ReLU(inplace=True)(conv1): Conv2d(544, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)(norm2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(relu2): ReLU(inplace=True)(conv2): Conv2d(128, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False))(denselayer3): _DenseLayer((norm1): BatchNorm2d(576, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(relu1): ReLU(inplace=True)(conv1): Conv2d(576, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)(norm2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(relu2): ReLU(inplace=True)(conv2): Conv2d(128, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False))(denselayer4): _DenseLayer((norm1): BatchNorm2d(608, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(relu1): ReLU(inplace=True)(conv1): Conv2d(608, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)(norm2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(relu2): ReLU(inplace=True)(conv2): Conv2d(128, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False))(denselayer5): _DenseLayer((norm1): BatchNorm2d(640, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(relu1): ReLU(inplace=True)(conv1): Conv2d(640, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)(norm2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(relu2): ReLU(inplace=True)(conv2): Conv2d(128, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False))(denselayer6): _DenseLayer((norm1): BatchNorm2d(672, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(relu1): ReLU(inplace=True)(conv1): Conv2d(672, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)(norm2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(relu2): ReLU(inplace=True)(conv2): Conv2d(128, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False))(denselayer7): _DenseLayer((norm1): BatchNorm2d(704, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(relu1): ReLU(inplace=True)(conv1): Conv2d(704, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)(norm2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(relu2): ReLU(inplace=True)(conv2): Conv2d(128, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False))(denselayer8): _DenseLayer((norm1): BatchNorm2d(736, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(relu1): ReLU(inplace=True)(conv1): Conv2d(736, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)(norm2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(relu2): ReLU(inplace=True)(conv2): Conv2d(128, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False))(denselayer9): _DenseLayer((norm1): BatchNorm2d(768, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(relu1): ReLU(inplace=True)(conv1): Conv2d(768, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)(norm2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(relu2): ReLU(inplace=True)(conv2): Conv2d(128, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False))(denselayer10): _DenseLayer((norm1): BatchNorm2d(800, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(relu1): ReLU(inplace=True)(conv1): Conv2d(800, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)(norm2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(relu2): ReLU(inplace=True)(conv2): Conv2d(128, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False))(denselayer11): _DenseLayer((norm1): BatchNorm2d(832, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(relu1): ReLU(inplace=True)(conv1): Conv2d(832, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)(norm2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(relu2): ReLU(inplace=True)(conv2): Conv2d(128, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False))(denselayer12): _DenseLayer((norm1): BatchNorm2d(864, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(relu1): ReLU(inplace=True)(conv1): Conv2d(864, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)(norm2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(relu2): ReLU(inplace=True)(conv2): Conv2d(128, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False))(denselayer13): _DenseLayer((norm1): BatchNorm2d(896, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(relu1): ReLU(inplace=True)(conv1): Conv2d(896, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)(norm2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(relu2): ReLU(inplace=True)(conv2): Conv2d(128, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False))(denselayer14): _DenseLayer((norm1): BatchNorm2d(928, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(relu1): ReLU(inplace=True)(conv1): Conv2d(928, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)(norm2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(relu2): ReLU(inplace=True)(conv2): Conv2d(128, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False))(denselayer15): _DenseLayer((norm1): BatchNorm2d(960, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(relu1): ReLU(inplace=True)(conv1): Conv2d(960, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)(norm2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(relu2): ReLU(inplace=True)(conv2): Conv2d(128, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False))(denselayer16): _DenseLayer((norm1): BatchNorm2d(992, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(relu1): ReLU(inplace=True)(conv1): Conv2d(992, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)(norm2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(relu2): ReLU(inplace=True)(conv2): Conv2d(128, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)))(norm5): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(relu5): ReLU(inplace=True))(classifier): Linear(in_features=1024, out_features=1000, bias=True)
)
----------------------------------------------------------------Layer (type) Output Shape Param #
================================================================Conv2d-1 [-1, 64, 112, 112] 9,408BatchNorm2d-2 [-1, 64, 112, 112] 128ReLU-3 [-1, 64, 112, 112] 0MaxPool2d-4 [-1, 64, 56, 56] 0BatchNorm2d-5 [-1, 64, 56, 56] 128ReLU-6 [-1, 64, 56, 56] 0Conv2d-7 [-1, 128, 56, 56] 8,192BatchNorm2d-8 [-1, 128, 56, 56] 256ReLU-9 [-1, 128, 56, 56] 0Conv2d-10 [-1, 32, 56, 56] 36,864BatchNorm2d-11 [-1, 96, 56, 56] 192ReLU-12 [-1, 96, 56, 56] 0Conv2d-13 [-1, 128, 56, 56] 12,288BatchNorm2d-14 [-1, 128, 56, 56] 256ReLU-15 [-1, 128, 56, 56] 0Conv2d-16 [-1, 32, 56, 56] 36,864BatchNorm2d-17 [-1, 128, 56, 56] 256ReLU-18 [-1, 128, 56, 56] 0Conv2d-19 [-1, 128, 56, 56] 16,384BatchNorm2d-20 [-1, 128, 56, 56] 256ReLU-21 [-1, 128, 56, 56] 0Conv2d-22 [-1, 32, 56, 56] 36,864BatchNorm2d-23 [-1, 160, 56, 56] 320ReLU-24 [-1, 160, 56, 56] 0Conv2d-25 [-1, 128, 56, 56] 20,480BatchNorm2d-26 [-1, 128, 56, 56] 256ReLU-27 [-1, 128, 56, 56] 0Conv2d-28 [-1, 32, 56, 56] 36,864BatchNorm2d-29 [-1, 192, 56, 56] 384ReLU-30 [-1, 192, 56, 56] 0Conv2d-31 [-1, 128, 56, 56] 24,576BatchNorm2d-32 [-1, 128, 56, 56] 256ReLU-33 [-1, 128, 56, 56] 0Conv2d-34 [-1, 32, 56, 56] 36,864BatchNorm2d-35 [-1, 224, 56, 56] 448ReLU-36 [-1, 224, 56, 56] 0Conv2d-37 [-1, 128, 56, 56] 28,672BatchNorm2d-38 [-1, 128, 56, 56] 256ReLU-39 [-1, 128, 56, 56] 0Conv2d-40 [-1, 32, 56, 56] 36,864BatchNorm2d-41 [-1, 256, 56, 56] 512ReLU-42 [-1, 256, 56, 56] 0Conv2d-43 [-1, 128, 56, 56] 32,768AvgPool2d-44 [-1, 128, 28, 28] 0BatchNorm2d-45 [-1, 128, 28, 28] 256ReLU-46 [-1, 128, 28, 28] 0Conv2d-47 [-1, 128, 28, 28] 16,384BatchNorm2d-48 [-1, 128, 28, 28] 256ReLU-49 [-1, 128, 28, 28] 0Conv2d-50 [-1, 32, 28, 28] 36,864BatchNorm2d-51 [-1, 160, 28, 28] 320ReLU-52 [-1, 160, 28, 28] 0Conv2d-53 [-1, 128, 28, 28] 20,480BatchNorm2d-54 [-1, 128, 28, 28] 256ReLU-55 [-1, 128, 28, 28] 0Conv2d-56 [-1, 32, 28, 28] 36,864BatchNorm2d-57 [-1, 192, 28, 28] 384ReLU-58 [-1, 192, 28, 28] 0Conv2d-59 [-1, 128, 28, 28] 24,576BatchNorm2d-60 [-1, 128, 28, 28] 256ReLU-61 [-1, 128, 28, 28] 0Conv2d-62 [-1, 32, 28, 28] 36,864BatchNorm2d-63 [-1, 224, 28, 28] 448ReLU-64 [-1, 224, 28, 28] 0Conv2d-65 [-1, 128, 28, 28] 28,672BatchNorm2d-66 [-1, 128, 28, 28] 256ReLU-67 [-1, 128, 28, 28] 0Conv2d-68 [-1, 32, 28, 28] 36,864BatchNorm2d-69 [-1, 256, 28, 28] 512ReLU-70 [-1, 256, 28, 28] 0Conv2d-71 [-1, 128, 28, 28] 32,768BatchNorm2d-72 [-1, 128, 28, 28] 256ReLU-73 [-1, 128, 28, 28] 0Conv2d-74 [-1, 32, 28, 28] 36,864BatchNorm2d-75 [-1, 288, 28, 28] 576ReLU-76 [-1, 288, 28, 28] 0Conv2d-77 [-1, 128, 28, 28] 36,864BatchNorm2d-78 [-1, 128, 28, 28] 256ReLU-79 [-1, 128, 28, 28] 0Conv2d-80 [-1, 32, 28, 28] 36,864BatchNorm2d-81 [-1, 320, 28, 28] 640ReLU-82 [-1, 320, 28, 28] 0Conv2d-83 [-1, 128, 28, 28] 40,960BatchNorm2d-84 [-1, 128, 28, 28] 256ReLU-85 [-1, 128, 28, 28] 0Conv2d-86 [-1, 32, 28, 28] 36,864BatchNorm2d-87 [-1, 352, 28, 28] 704ReLU-88 [-1, 352, 28, 28] 0Conv2d-89 [-1, 128, 28, 28] 45,056BatchNorm2d-90 [-1, 128, 28, 28] 256ReLU-91 [-1, 128, 28, 28] 0Conv2d-92 [-1, 32, 28, 28] 36,864BatchNorm2d-93 [-1, 384, 28, 28] 768ReLU-94 [-1, 384, 28, 28] 0Conv2d-95 [-1, 128, 28, 28] 49,152BatchNorm2d-96 [-1, 128, 28, 28] 256ReLU-97 [-1, 128, 28, 28] 0Conv2d-98 [-1, 32, 28, 28] 36,864BatchNorm2d-99 [-1, 416, 28, 28] 832ReLU-100 [-1, 416, 28, 28] 0Conv2d-101 [-1, 128, 28, 28] 53,248BatchNorm2d-102 [-1, 128, 28, 28] 256ReLU-103 [-1, 128, 28, 28] 0Conv2d-104 [-1, 32, 28, 28] 36,864BatchNorm2d-105 [-1, 448, 28, 28] 896ReLU-106 [-1, 448, 28, 28] 0Conv2d-107 [-1, 128, 28, 28] 57,344BatchNorm2d-108 [-1, 128, 28, 28] 256ReLU-109 [-1, 128, 28, 28] 0Conv2d-110 [-1, 32, 28, 28] 36,864BatchNorm2d-111 [-1, 480, 28, 28] 960ReLU-112 [-1, 480, 28, 28] 0Conv2d-113 [-1, 128, 28, 28] 61,440BatchNorm2d-114 [-1, 128, 28, 28] 256ReLU-115 [-1, 128, 28, 28] 0Conv2d-116 [-1, 32, 28, 28] 36,864BatchNorm2d-117 [-1, 512, 28, 28] 1,024ReLU-118 [-1, 512, 28, 28] 0Conv2d-119 [-1, 256, 28, 28] 131,072AvgPool2d-120 [-1, 256, 14, 14] 0BatchNorm2d-121 [-1, 256, 14, 14] 512ReLU-122 [-1, 256, 14, 14] 0Conv2d-123 [-1, 128, 14, 14] 32,768BatchNorm2d-124 [-1, 128, 14, 14] 256ReLU-125 [-1, 128, 14, 14] 0Conv2d-126 [-1, 32, 14, 14] 36,864BatchNorm2d-127 [-1, 288, 14, 14] 576ReLU-128 [-1, 288, 14, 14] 0Conv2d-129 [-1, 128, 14, 14] 36,864BatchNorm2d-130 [-1, 128, 14, 14] 256ReLU-131 [-1, 128, 14, 14] 0Conv2d-132 [-1, 32, 14, 14] 36,864BatchNorm2d-133 [-1, 320, 14, 14] 640ReLU-134 [-1, 320, 14, 14] 0Conv2d-135 [-1, 128, 14, 14] 40,960BatchNorm2d-136 [-1, 128, 14, 14] 256ReLU-137 [-1, 128, 14, 14] 0Conv2d-138 [-1, 32, 14, 14] 36,864BatchNorm2d-139 [-1, 352, 14, 14] 704ReLU-140 [-1, 352, 14, 14] 0Conv2d-141 [-1, 128, 14, 14] 45,056BatchNorm2d-142 [-1, 128, 14, 14] 256ReLU-143 [-1, 128, 14, 14] 0Conv2d-144 [-1, 32, 14, 14] 36,864BatchNorm2d-145 [-1, 384, 14, 14] 768ReLU-146 [-1, 384, 14, 14] 0Conv2d-147 [-1, 128, 14, 14] 49,152BatchNorm2d-148 [-1, 128, 14, 14] 256ReLU-149 [-1, 128, 14, 14] 0Conv2d-150 [-1, 32, 14, 14] 36,864BatchNorm2d-151 [-1, 416, 14, 14] 832ReLU-152 [-1, 416, 14, 14] 0Conv2d-153 [-1, 128, 14, 14] 53,248BatchNorm2d-154 [-1, 128, 14, 14] 256ReLU-155 [-1, 128, 14, 14] 0Conv2d-156 [-1, 32, 14, 14] 36,864BatchNorm2d-157 [-1, 448, 14, 14] 896ReLU-158 [-1, 448, 14, 14] 0Conv2d-159 [-1, 128, 14, 14] 57,344BatchNorm2d-160 [-1, 128, 14, 14] 256ReLU-161 [-1, 128, 14, 14] 0Conv2d-162 [-1, 32, 14, 14] 36,864BatchNorm2d-163 [-1, 480, 14, 14] 960ReLU-164 [-1, 480, 14, 14] 0Conv2d-165 [-1, 128, 14, 14] 61,440BatchNorm2d-166 [-1, 128, 14, 14] 256ReLU-167 [-1, 128, 14, 14] 0Conv2d-168 [-1, 32, 14, 14] 36,864BatchNorm2d-169 [-1, 512, 14, 14] 1,024ReLU-170 [-1, 512, 14, 14] 0Conv2d-171 [-1, 128, 14, 14] 65,536BatchNorm2d-172 [-1, 128, 14, 14] 256ReLU-173 [-1, 128, 14, 14] 0Conv2d-174 [-1, 32, 14, 14] 36,864BatchNorm2d-175 [-1, 544, 14, 14] 1,088ReLU-176 [-1, 544, 14, 14] 0Conv2d-177 [-1, 128, 14, 14] 69,632BatchNorm2d-178 [-1, 128, 14, 14] 256ReLU-179 [-1, 128, 14, 14] 0Conv2d-180 [-1, 32, 14, 14] 36,864BatchNorm2d-181 [-1, 576, 14, 14] 1,152ReLU-182 [-1, 576, 14, 14] 0Conv2d-183 [-1, 128, 14, 14] 73,728BatchNorm2d-184 [-1, 128, 14, 14] 256ReLU-185 [-1, 128, 14, 14] 0Conv2d-186 [-1, 32, 14, 14] 36,864BatchNorm2d-187 [-1, 608, 14, 14] 1,216ReLU-188 [-1, 608, 14, 14] 0Conv2d-189 [-1, 128, 14, 14] 77,824BatchNorm2d-190 [-1, 128, 14, 14] 256ReLU-191 [-1, 128, 14, 14] 0Conv2d-192 [-1, 32, 14, 14] 36,864BatchNorm2d-193 [-1, 640, 14, 14] 1,280ReLU-194 [-1, 640, 14, 14] 0Conv2d-195 [-1, 128, 14, 14] 81,920BatchNorm2d-196 [-1, 128, 14, 14] 256ReLU-197 [-1, 128, 14, 14] 0Conv2d-198 [-1, 32, 14, 14] 36,864BatchNorm2d-199 [-1, 672, 14, 14] 1,344ReLU-200 [-1, 672, 14, 14] 0Conv2d-201 [-1, 128, 14, 14] 86,016BatchNorm2d-202 [-1, 128, 14, 14] 256ReLU-203 [-1, 128, 14, 14] 0Conv2d-204 [-1, 32, 14, 14] 36,864BatchNorm2d-205 [-1, 704, 14, 14] 1,408ReLU-206 [-1, 704, 14, 14] 0Conv2d-207 [-1, 128, 14, 14] 90,112BatchNorm2d-208 [-1, 128, 14, 14] 256ReLU-209 [-1, 128, 14, 14] 0Conv2d-210 [-1, 32, 14, 14] 36,864BatchNorm2d-211 [-1, 736, 14, 14] 1,472ReLU-212 [-1, 736, 14, 14] 0Conv2d-213 [-1, 128, 14, 14] 94,208BatchNorm2d-214 [-1, 128, 14, 14] 256ReLU-215 [-1, 128, 14, 14] 0Conv2d-216 [-1, 32, 14, 14] 36,864BatchNorm2d-217 [-1, 768, 14, 14] 1,536ReLU-218 [-1, 768, 14, 14] 0Conv2d-219 [-1, 128, 14, 14] 98,304BatchNorm2d-220 [-1, 128, 14, 14] 256ReLU-221 [-1, 128, 14, 14] 0Conv2d-222 [-1, 32, 14, 14] 36,864BatchNorm2d-223 [-1, 800, 14, 14] 1,600ReLU-224 [-1, 800, 14, 14] 0Conv2d-225 [-1, 128, 14, 14] 102,400BatchNorm2d-226 [-1, 128, 14, 14] 256ReLU-227 [-1, 128, 14, 14] 0Conv2d-228 [-1, 32, 14, 14] 36,864BatchNorm2d-229 [-1, 832, 14, 14] 1,664ReLU-230 [-1, 832, 14, 14] 0Conv2d-231 [-1, 128, 14, 14] 106,496BatchNorm2d-232 [-1, 128, 14, 14] 256ReLU-233 [-1, 128, 14, 14] 0Conv2d-234 [-1, 32, 14, 14] 36,864BatchNorm2d-235 [-1, 864, 14, 14] 1,728ReLU-236 [-1, 864, 14, 14] 0Conv2d-237 [-1, 128, 14, 14] 110,592BatchNorm2d-238 [-1, 128, 14, 14] 256ReLU-239 [-1, 128, 14, 14] 0Conv2d-240 [-1, 32, 14, 14] 36,864BatchNorm2d-241 [-1, 896, 14, 14] 1,792ReLU-242 [-1, 896, 14, 14] 0Conv2d-243 [-1, 128, 14, 14] 114,688BatchNorm2d-244 [-1, 128, 14, 14] 256ReLU-245 [-1, 128, 14, 14] 0Conv2d-246 [-1, 32, 14, 14] 36,864BatchNorm2d-247 [-1, 928, 14, 14] 1,856ReLU-248 [-1, 928, 14, 14] 0Conv2d-249 [-1, 128, 14, 14] 118,784BatchNorm2d-250 [-1, 128, 14, 14] 256ReLU-251 [-1, 128, 14, 14] 0Conv2d-252 [-1, 32, 14, 14] 36,864BatchNorm2d-253 [-1, 960, 14, 14] 1,920ReLU-254 [-1, 960, 14, 14] 0Conv2d-255 [-1, 128, 14, 14] 122,880BatchNorm2d-256 [-1, 128, 14, 14] 256ReLU-257 [-1, 128, 14, 14] 0Conv2d-258 [-1, 32, 14, 14] 36,864BatchNorm2d-259 [-1, 992, 14, 14] 1,984ReLU-260 [-1, 992, 14, 14] 0Conv2d-261 [-1, 128, 14, 14] 126,976BatchNorm2d-262 [-1, 128, 14, 14] 256ReLU-263 [-1, 128, 14, 14] 0Conv2d-264 [-1, 32, 14, 14] 36,864BatchNorm2d-265 [-1, 1024, 14, 14] 2,048ReLU-266 [-1, 1024, 14, 14] 0Conv2d-267 [-1, 512, 14, 14] 524,288AvgPool2d-268 [-1, 512, 7, 7] 0BatchNorm2d-269 [-1, 512, 7, 7] 1,024ReLU-270 [-1, 512, 7, 7] 0Conv2d-271 [-1, 128, 7, 7] 65,536BatchNorm2d-272 [-1, 128, 7, 7] 256ReLU-273 [-1, 128, 7, 7] 0Conv2d-274 [-1, 32, 7, 7] 36,864BatchNorm2d-275 [-1, 544, 7, 7] 1,088ReLU-276 [-1, 544, 7, 7] 0Conv2d-277 [-1, 128, 7, 7] 69,632BatchNorm2d-278 [-1, 128, 7, 7] 256ReLU-279 [-1, 128, 7, 7] 0Conv2d-280 [-1, 32, 7, 7] 36,864BatchNorm2d-281 [-1, 576, 7, 7] 1,152ReLU-282 [-1, 576, 7, 7] 0Conv2d-283 [-1, 128, 7, 7] 73,728BatchNorm2d-284 [-1, 128, 7, 7] 256ReLU-285 [-1, 128, 7, 7] 0Conv2d-286 [-1, 32, 7, 7] 36,864BatchNorm2d-287 [-1, 608, 7, 7] 1,216ReLU-288 [-1, 608, 7, 7] 0Conv2d-289 [-1, 128, 7, 7] 77,824BatchNorm2d-290 [-1, 128, 7, 7] 256ReLU-291 [-1, 128, 7, 7] 0Conv2d-292 [-1, 32, 7, 7] 36,864BatchNorm2d-293 [-1, 640, 7, 7] 1,280ReLU-294 [-1, 640, 7, 7] 0Conv2d-295 [-1, 128, 7, 7] 81,920BatchNorm2d-296 [-1, 128, 7, 7] 256ReLU-297 [-1, 128, 7, 7] 0Conv2d-298 [-1, 32, 7, 7] 36,864BatchNorm2d-299 [-1, 672, 7, 7] 1,344ReLU-300 [-1, 672, 7, 7] 0Conv2d-301 [-1, 128, 7, 7] 86,016BatchNorm2d-302 [-1, 128, 7, 7] 256ReLU-303 [-1, 128, 7, 7] 0Conv2d-304 [-1, 32, 7, 7] 36,864BatchNorm2d-305 [-1, 704, 7, 7] 1,408ReLU-306 [-1, 704, 7, 7] 0Conv2d-307 [-1, 128, 7, 7] 90,112BatchNorm2d-308 [-1, 128, 7, 7] 256ReLU-309 [-1, 128, 7, 7] 0Conv2d-310 [-1, 32, 7, 7] 36,864BatchNorm2d-311 [-1, 736, 7, 7] 1,472ReLU-312 [-1, 736, 7, 7] 0Conv2d-313 [-1, 128, 7, 7] 94,208BatchNorm2d-314 [-1, 128, 7, 7] 256ReLU-315 [-1, 128, 7, 7] 0Conv2d-316 [-1, 32, 7, 7] 36,864BatchNorm2d-317 [-1, 768, 7, 7] 1,536ReLU-318 [-1, 768, 7, 7] 0Conv2d-319 [-1, 128, 7, 7] 98,304BatchNorm2d-320 [-1, 128, 7, 7] 256ReLU-321 [-1, 128, 7, 7] 0Conv2d-322 [-1, 32, 7, 7] 36,864BatchNorm2d-323 [-1, 800, 7, 7] 1,600ReLU-324 [-1, 800, 7, 7] 0Conv2d-325 [-1, 128, 7, 7] 102,400BatchNorm2d-326 [-1, 128, 7, 7] 256ReLU-327 [-1, 128, 7, 7] 0Conv2d-328 [-1, 32, 7, 7] 36,864BatchNorm2d-329 [-1, 832, 7, 7] 1,664ReLU-330 [-1, 832, 7, 7] 0Conv2d-331 [-1, 128, 7, 7] 106,496BatchNorm2d-332 [-1, 128, 7, 7] 256ReLU-333 [-1, 128, 7, 7] 0Conv2d-334 [-1, 32, 7, 7] 36,864BatchNorm2d-335 [-1, 864, 7, 7] 1,728ReLU-336 [-1, 864, 7, 7] 0Conv2d-337 [-1, 128, 7, 7] 110,592BatchNorm2d-338 [-1, 128, 7, 7] 256ReLU-339 [-1, 128, 7, 7] 0Conv2d-340 [-1, 32, 7, 7] 36,864BatchNorm2d-341 [-1, 896, 7, 7] 1,792ReLU-342 [-1, 896, 7, 7] 0Conv2d-343 [-1, 128, 7, 7] 114,688BatchNorm2d-344 [-1, 128, 7, 7] 256ReLU-345 [-1, 128, 7, 7] 0Conv2d-346 [-1, 32, 7, 7] 36,864BatchNorm2d-347 [-1, 928, 7, 7] 1,856ReLU-348 [-1, 928, 7, 7] 0Conv2d-349 [-1, 128, 7, 7] 118,784BatchNorm2d-350 [-1, 128, 7, 7] 256ReLU-351 [-1, 128, 7, 7] 0Conv2d-352 [-1, 32, 7, 7] 36,864BatchNorm2d-353 [-1, 960, 7, 7] 1,920ReLU-354 [-1, 960, 7, 7] 0Conv2d-355 [-1, 128, 7, 7] 122,880BatchNorm2d-356 [-1, 128, 7, 7] 256ReLU-357 [-1, 128, 7, 7] 0Conv2d-358 [-1, 32, 7, 7] 36,864BatchNorm2d-359 [-1, 992, 7, 7] 1,984ReLU-360 [-1, 992, 7, 7] 0Conv2d-361 [-1, 128, 7, 7] 126,976BatchNorm2d-362 [-1, 128, 7, 7] 256ReLU-363 [-1, 128, 7, 7] 0Conv2d-364 [-1, 32, 7, 7] 36,864BatchNorm2d-365 [-1, 1024, 7, 7] 2,048ReLU-366 [-1, 1024, 7, 7] 0Linear-367 [-1, 1000] 1,025,000
================================================================
Total params: 7,978,856
Trainable params: 7,978,856
Non-trainable params: 0
----------------------------------------------------------------
Input size (MB): 0.57
Forward/backward pass size (MB): 294.58
Params size (MB): 30.44
Estimated Total Size (MB): 325.59
----------------------------------------------------------------2.3 训练模型
2.3.1 设置超参数
"""训练模型--设置超参数"""
loss_fn = nn.CrossEntropyLoss() # 创建损失函数,计算实际输出和真实相差多少,交叉熵损失函数,事实上,它就是做图片分类任务时常用的损失函数
learn_rate = 1e-4 # 学习率
optimizer1 = torch.optim.SGD(model.parameters(), lr=learn_rate)# 作用是定义优化器,用来训练时候优化模型参数;其中,SGD表示随机梯度下降,用于控制实际输出y与真实y之间的相差有多大
optimizer2 = torch.optim.Adam(model.parameters(), lr=learn_rate)
lr_opt = optimizer2
model_opt = optimizer2
# 调用官方动态学习率接口时使用2
lambda1 = lambda epoch : 0.92 ** (epoch // 4)
# optimizer = torch.optim.SGD(model.parameters(), lr=learn_rate)
scheduler = torch.optim.lr_scheduler.LambdaLR(lr_opt, lr_lambda=lambda1) #选定调整方法2.3.2 编写训练函数
"""训练模型--编写训练函数"""
# 训练循环
def train(dataloader, model, loss_fn, optimizer):size = len(dataloader.dataset) # 训练集的大小,一共60000张图片num_batches = len(dataloader) # 批次数目,1875(60000/32)train_loss, train_acc = 0, 0 # 初始化训练损失和正确率for X, y in dataloader: # 加载数据加载器,得到里面的 X(图片数据)和 y(真实标签)X, y = X.to(device), y.to(device) # 用于将数据存到显卡# 计算预测误差pred = model(X) # 网络输出loss = loss_fn(pred, y) # 计算网络输出和真实值之间的差距,targets为真实值,计算二者差值即为损失# 反向传播optimizer.zero_grad() # 清空过往梯度loss.backward() # 反向传播,计算当前梯度optimizer.step() # 根据梯度更新网络参数# 记录acc与losstrain_acc += (pred.argmax(1) == y).type(torch.float).sum().item()train_loss += loss.item()train_acc /= sizetrain_loss /= num_batchesreturn train_acc, train_loss
2.3.3 编写测试函数
"""训练模型--编写测试函数"""
# 测试函数和训练函数大致相同,但是由于不进行梯度下降对网络权重进行更新,所以不需要传入优化器
def test(dataloader, model, loss_fn):size = len(dataloader.dataset) # 测试集的大小,一共10000张图片num_batches = len(dataloader) # 批次数目,313(10000/32=312.5,向上取整)test_loss, test_acc = 0, 0# 当不进行训练时,停止梯度更新,节省计算内存消耗with torch.no_grad(): # 测试时模型参数不用更新,所以 no_grad,整个模型参数正向推就ok,不反向更新参数for imgs, target in dataloader:imgs, target = imgs.to(device), target.to(device)# 计算losstarget_pred = model(imgs)loss = loss_fn(target_pred, target)test_loss += loss.item()test_acc += (target_pred.argmax(1) == target).type(torch.float).sum().item()#统计预测正确的个数test_acc /= sizetest_loss /= num_batchesreturn test_acc, test_loss2.3.4 正式训练
"""训练模型--正式训练"""
epochs = 10
train_loss = []
train_acc = []
test_loss = []
test_acc = []
best_test_acc=0for epoch in range(epochs):milliseconds_t1 = int(time.time() * 1000)# 更新学习率(使用自定义学习率时使用)# adjust_learning_rate(lr_opt, epoch, learn_rate)model.train()epoch_train_acc, epoch_train_loss = train(train_dl, model, loss_fn, model_opt)scheduler.step() # 更新学习率(调用官方动态学习率接口时使用)model.eval()epoch_test_acc, epoch_test_loss = test(test_dl, model, loss_fn)train_acc.append(epoch_train_acc)train_loss.append(epoch_train_loss)test_acc.append(epoch_test_acc)test_loss.append(epoch_test_loss)# 获取当前的学习率lr = lr_opt.state_dict()['param_groups'][0]['lr']milliseconds_t2 = int(time.time() * 1000)template = ('Epoch:{:2d}, duration:{}ms, Train_acc:{:.1f}%, Train_loss:{:.3f}, Test_acc:{:.1f}%,Test_loss:{:.3f}, Lr:{:.2E}')if best_test_acc < epoch_test_acc:best_test_acc = epoch_test_acc#备份最好的模型best_model = copy.deepcopy(model)template = ('Epoch:{:2d}, duration:{}ms, Train_acc:{:.1f}%, Train_loss:{:.3f}, Test_acc:{:.1f}%,Test_loss:{:.3f}, Lr:{:.2E},Update the best model')print(template.format(epoch + 1, milliseconds_t2-milliseconds_t1, epoch_train_acc * 100, epoch_train_loss, epoch_test_acc * 100, epoch_test_loss, lr))
# 保存最佳模型到文件中
PATH = './best_model.pth' # 保存的参数文件名
torch.save(model.state_dict(), PATH)
print('Done')
输出最高精度为Test_acc:100%
Epoch: 1, duration:5339ms, Train_acc:32.5%, Train_loss:4.717, Test_acc:94.7%,Test_loss:0.666, Lr:1.00E-04,Update the best model
Epoch: 2, duration:4585ms, Train_acc:98.5%, Train_loss:0.255, Test_acc:98.2%,Test_loss:0.120, Lr:1.00E-04,Update the best model
Epoch: 3, duration:4651ms, Train_acc:100.0%, Train_loss:0.037, Test_acc:99.1%,Test_loss:0.057, Lr:1.00E-04,Update the best model
Epoch: 4, duration:4610ms, Train_acc:99.8%, Train_loss:0.039, Test_acc:100.0%,Test_loss:0.040, Lr:1.00E-04,Update the best model
Epoch: 5, duration:4520ms, Train_acc:99.8%, Train_loss:0.032, Test_acc:100.0%,Test_loss:0.047, Lr:1.00E-04
Epoch: 6, duration:4528ms, Train_acc:100.0%, Train_loss:0.055, Test_acc:100.0%,Test_loss:0.038, Lr:1.00E-04
Epoch: 7, duration:4541ms, Train_acc:100.0%, Train_loss:0.021, Test_acc:100.0%,Test_loss:0.022, Lr:1.00E-04
Epoch: 8, duration:4568ms, Train_acc:100.0%, Train_loss:0.066, Test_acc:100.0%,Test_loss:0.018, Lr:1.00E-04
Epoch: 9, duration:4515ms, Train_acc:99.8%, Train_loss:0.084, Test_acc:100.0%,Test_loss:0.022, Lr:1.00E-04
Epoch:10, duration:4602ms, Train_acc:99.6%, Train_loss:0.136, Test_acc:100.0%,Test_loss:0.028, Lr:1.00E-04
这里使用了预训练模型,效果特别好
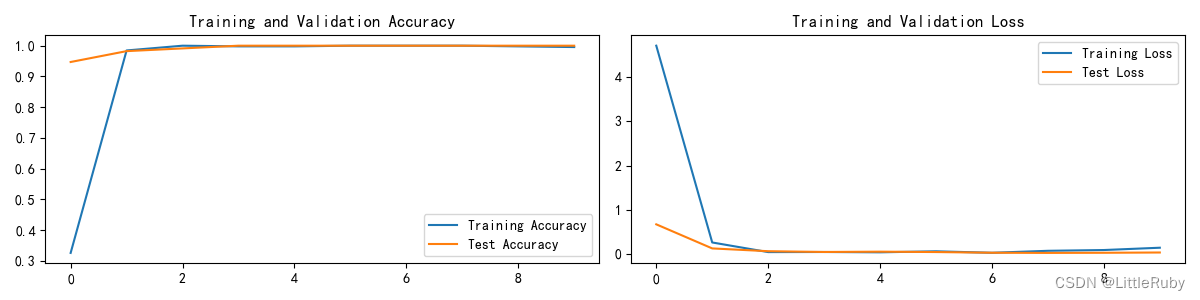
2.4 结果可视化
"""训练模型--结果可视化"""
epochs_range = range(epochs)plt.figure(figsize=(12, 3))
plt.subplot(1, 2, 1)plt.plot(epochs_range, train_acc, label='Training Accuracy')
plt.plot(epochs_range, test_acc, label='Test Accuracy')
plt.legend(loc='lower right')
plt.title('Training and Validation Accuracy')plt.subplot(1, 2, 2)
plt.plot(epochs_range, train_loss, label='Training Loss')
plt.plot(epochs_range, test_loss, label='Test Loss')
plt.legend(loc='upper right')
plt.title('Training and Validation Loss')
plt.show()
2.4 指定图片进行预测
def predict_one_image(image_path, model, transform, classes):test_img = Image.open(image_path).convert('RGB')plt.imshow(test_img) # 展示预测的图片plt.show()test_img = transform(test_img)img = test_img.to(device).unsqueeze(0)model.eval()output = model(img)_, pred = torch.max(output, 1)pred_class = classes[pred]print(f'预测结果是:{pred_class}')# 将参数加载到model当中
model.load_state_dict(torch.load(PATH, map_location=device))"""指定图片进行预测"""
classes = list(total_data.class_to_idx)
# 预测训练集中的某张照片
predict_one_image(image_path=str(Path(data_dir) / "Cockatoo/001.jpg"),model=model,transform=train_transforms,classes=classes)

输出
预测结果是:Cockatoo
2.6 模型评估
"""模型评估"""
best_model.eval()
epoch_test_acc, epoch_test_loss = test(test_dl, best_model, loss_fn)
# 查看是否与我们记录的最高准确率一致
print(epoch_test_acc, epoch_test_loss)输出
1.0 0.051054626121185723 tensorflow实现DenseNet算法
3.1.引入库
from PIL import Image
import numpy as np
from pathlib import Path
import matplotlib.pyplot as plt# 支持中文
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号
import tensorflow as tf
from keras import layers, models, Input
from keras.layers import Input, Activation, BatchNormalization, Flatten
from keras.layers import Dense, Conv2D, MaxPooling2D, ZeroPadding2D, GlobalMaxPooling2D, AveragePooling2D, Flatten, \Dropout, BatchNormalization, GlobalAveragePooling2D
from keras.models import Model
from keras import regularizers
from tensorflow import keras
from keras.callbacks import ModelCheckpoint
import matplotlib.pyplot as plt
import warningswarnings.filterwarnings('ignore') # 忽略一些warning内容,无需打印
3.2.设置GPU(如果使用的是CPU可以忽略这步)
'''前期工作-设置GPU(如果使用的是CPU可以忽略这步)'''
# 检查GPU是否可用
print(tf.test.is_built_with_cuda())
gpus = tf.config.list_physical_devices("GPU")
print(gpus)
if gpus:gpu0 = gpus[0] # 如果有多个GPU,仅使用第0个GPUtf.config.experimental.set_memory_growth(gpu0, True) # 设置GPU显存用量按需使用tf.config.set_visible_devices([gpu0], "GPU")
执行结果
True
[PhysicalDevice(name='/physical_device:GPU:0', device_type='GPU')]
3.3.导入数据
'''前期工作-导入数据'''
data_dir = r"D:\DeepLearning\data\bird\bird_photos"
data_dir = Path(data_dir)
3.4.查看数据
'''前期工作-查看数据'''
image_count = len(list(data_dir.glob('*/*.jpg')))
print("图片总数为:", image_count)
image_list = list(data_dir.glob('Bananaquit/*.jpg'))
image = Image.open(str(image_list[1]))
# 查看图像实例的属性
print(image.format, image.size, image.mode)
plt.imshow(image)
plt.axis("off")
plt.show()
执行结果:
图片总数为: 565
JPEG (224, 224) RGB

3.5.加载数据
'''数据预处理-加载数据'''
batch_size = 32
img_height = 224
img_width = 224
"""
关于image_dataset_from_directory()的详细介绍可以参考文章:https://mtyjkh.blog.csdn.net/article/details/117018789
"""
train_ds = tf.keras.preprocessing.image_dataset_from_directory(data_dir,validation_split=0.2,subset="training",seed=123,image_size=(img_height, img_width),batch_size=batch_size)
val_ds = tf.keras.preprocessing.image_dataset_from_directory(data_dir,validation_split=0.2,subset="validation",seed=123,image_size=(img_height, img_width),batch_size=batch_size)
class_names = train_ds.class_names
print(class_names)
运行结果:
Found 565 files belonging to 4 classes.
Using 452 files for training.
Found 565 files belonging to 4 classes.
Using 113 files for validation.
['Bananaquit', 'Black Skimmer', 'Black Throated Bushtiti', 'Cockatoo']3.6.再次检查数据
'''数据预处理-再次检查数据'''
# Image_batch是形状的张量(16, 336, 336, 3)。这是一批形状336x336x3的16张图片(最后一维指的是彩色通道RGB)。
# Label_batch是形状(16,)的张量,这些标签对应16张图片
for image_batch, labels_batch in train_ds:print(image_batch.shape)print(labels_batch.shape)break
运行结果
(32, 224, 224, 3)
(32,)
3.7.配置数据集
'''数据预处理-配置数据集'''
AUTOTUNE = tf.data.AUTOTUNE
train_ds = train_ds.cache().shuffle(1000).prefetch(buffer_size=AUTOTUNE)
val_ds = val_ds.cache().prefetch(buffer_size=AUTOTUNE)3.8.可视化数据
'''数据预处理-可视化数据'''
plt.figure(figsize=(10, 5))
for images, labels in train_ds.take(1):for i in range(8):ax = plt.subplot(2, 4, i + 1)plt.imshow(images[i].numpy().astype("uint8"))plt.title(class_names[labels[i]], fontsize=10)plt.axis("off")
# 显示图片
plt.show()
3.9.构建DenseNet网络
"""构建DenseNet网络"""
def conv_fn(x, growth_rate):x1 = keras.layers.BatchNormalization()(x)x1 = keras.layers.Activation('relu')(x)x1 = keras.layers.Activation('relu')(x1)x1 = keras.layers.Conv2D(4 * growth_rate, 1, 1, padding="same", use_bias=False)(x1)x1 = keras.layers.BatchNormalization()(x1)x1 = keras.layers.Activation("relu")(x1)x1 = keras.layers.Conv2D(growth_rate, 3, 1, padding="same", use_bias=False)(x1)return keras.layers.Concatenate(axis=3)([x, x1])def dense_block(x, block, growth_rate=32):for i in range(block):x = conv_fn(x, growth_rate)return xk = keras.backend
def trans_block(x, theta):x1 = keras.layers.BatchNormalization()(x)x1 = keras.layers.Activation("relu")(x1)x1 = keras.layers.Conv2D(int(k.int_shape(x)[3] * theta), 1, 1, use_bias=False)(x1)x1 = keras.layers.AveragePooling2D(pool_size=(2, 2), strides=2, padding="valid")(x1)return x1def densenet(input_shape, block, n_classes=1000):# 56*56*64x_input = keras.layers.Input(shape=input_shape)x = keras.layers.Conv2D(64, kernel_size=(7, 7), strides=2, padding="same", use_bias=False)(x_input)x = keras.layers.BatchNormalization()(x)x = keras.layers.MaxPooling2D(pool_size=3, strides=2, padding="same")(x)x = dense_block(x, block[0])x = trans_block(x, 0.5) # 28*28x = dense_block(x, block[1])x = trans_block(x, 0.5) # 14*14x = dense_block(x, block[2])x = trans_block(x, 0.5) # 7*7x = dense_block(x, block[3])x = keras.layers.BatchNormalization()(x)x = keras.layers.Activation("relu")(x)x = keras.layers.GlobalAveragePooling2D()(x)outputs = keras.layers.Dense(n_classes, activation="softmax")(x)model = keras.models.Model(inputs=[x_input], outputs=[outputs])return modelmodel_121 = densenet([224, 224, 3], [6, 12, 24, 16]) # DenseNet-121
model_169 = densenet([224, 224, 3], [6, 12, 32, 32]) # DenseNet-169
model_201 = densenet([224, 224, 3], [6, 12, 48, 32]) # DenseNet-201
model_269 = densenet([224, 224, 3], [6, 12, 64, 48]) # DenseNet-269
model = model_121
model.summary()
网络结构结果如下:
Model: "model"
__________________________________________________________________________________________________Layer (type) Output Shape Param # Connected to
==================================================================================================input_1 (InputLayer) [(None, 224, 224, 3 0 [] )] conv2d (Conv2D) (None, 112, 112, 64 9408 ['input_1[0][0]'] ) batch_normalization (BatchNorm (None, 112, 112, 64 256 ['conv2d[0][0]'] alization) ) max_pooling2d (MaxPooling2D) (None, 56, 56, 64) 0 ['batch_normalization[0][0]'] activation (Activation) (None, 56, 56, 64) 0 ['max_pooling2d[0][0]'] activation_1 (Activation) (None, 56, 56, 64) 0 ['activation[0][0]'] conv2d_1 (Conv2D) (None, 56, 56, 128) 8192 ['activation_1[0][0]'] batch_normalization_2 (BatchNo (None, 56, 56, 128) 512 ['conv2d_1[0][0]'] rmalization) activation_2 (Activation) (None, 56, 56, 128) 0 ['batch_normalization_2[0][0]'] conv2d_2 (Conv2D) (None, 56, 56, 32) 36864 ['activation_2[0][0]'] concatenate (Concatenate) (None, 56, 56, 96) 0 ['max_pooling2d[0][0]', 'conv2d_2[0][0]'] activation_3 (Activation) (None, 56, 56, 96) 0 ['concatenate[0][0]'] activation_4 (Activation) (None, 56, 56, 96) 0 ['activation_3[0][0]'] conv2d_3 (Conv2D) (None, 56, 56, 128) 12288 ['activation_4[0][0]'] batch_normalization_4 (BatchNo (None, 56, 56, 128) 512 ['conv2d_3[0][0]'] rmalization) activation_5 (Activation) (None, 56, 56, 128) 0 ['batch_normalization_4[0][0]'] conv2d_4 (Conv2D) (None, 56, 56, 32) 36864 ['activation_5[0][0]'] concatenate_1 (Concatenate) (None, 56, 56, 128) 0 ['concatenate[0][0]', 'conv2d_4[0][0]'] activation_6 (Activation) (None, 56, 56, 128) 0 ['concatenate_1[0][0]'] activation_7 (Activation) (None, 56, 56, 128) 0 ['activation_6[0][0]'] conv2d_5 (Conv2D) (None, 56, 56, 128) 16384 ['activation_7[0][0]'] batch_normalization_6 (BatchNo (None, 56, 56, 128) 512 ['conv2d_5[0][0]'] rmalization) activation_8 (Activation) (None, 56, 56, 128) 0 ['batch_normalization_6[0][0]'] conv2d_6 (Conv2D) (None, 56, 56, 32) 36864 ['activation_8[0][0]'] concatenate_2 (Concatenate) (None, 56, 56, 160) 0 ['concatenate_1[0][0]', 'conv2d_6[0][0]'] activation_9 (Activation) (None, 56, 56, 160) 0 ['concatenate_2[0][0]'] activation_10 (Activation) (None, 56, 56, 160) 0 ['activation_9[0][0]'] conv2d_7 (Conv2D) (None, 56, 56, 128) 20480 ['activation_10[0][0]'] batch_normalization_8 (BatchNo (None, 56, 56, 128) 512 ['conv2d_7[0][0]'] rmalization) activation_11 (Activation) (None, 56, 56, 128) 0 ['batch_normalization_8[0][0]'] conv2d_8 (Conv2D) (None, 56, 56, 32) 36864 ['activation_11[0][0]'] concatenate_3 (Concatenate) (None, 56, 56, 192) 0 ['concatenate_2[0][0]', 'conv2d_8[0][0]'] activation_12 (Activation) (None, 56, 56, 192) 0 ['concatenate_3[0][0]'] activation_13 (Activation) (None, 56, 56, 192) 0 ['activation_12[0][0]'] conv2d_9 (Conv2D) (None, 56, 56, 128) 24576 ['activation_13[0][0]'] batch_normalization_10 (BatchN (None, 56, 56, 128) 512 ['conv2d_9[0][0]'] ormalization) activation_14 (Activation) (None, 56, 56, 128) 0 ['batch_normalization_10[0][0]'] conv2d_10 (Conv2D) (None, 56, 56, 32) 36864 ['activation_14[0][0]'] concatenate_4 (Concatenate) (None, 56, 56, 224) 0 ['concatenate_3[0][0]', 'conv2d_10[0][0]'] activation_15 (Activation) (None, 56, 56, 224) 0 ['concatenate_4[0][0]'] activation_16 (Activation) (None, 56, 56, 224) 0 ['activation_15[0][0]'] conv2d_11 (Conv2D) (None, 56, 56, 128) 28672 ['activation_16[0][0]'] batch_normalization_12 (BatchN (None, 56, 56, 128) 512 ['conv2d_11[0][0]'] ormalization) activation_17 (Activation) (None, 56, 56, 128) 0 ['batch_normalization_12[0][0]'] conv2d_12 (Conv2D) (None, 56, 56, 32) 36864 ['activation_17[0][0]'] concatenate_5 (Concatenate) (None, 56, 56, 256) 0 ['concatenate_4[0][0]', 'conv2d_12[0][0]'] batch_normalization_13 (BatchN (None, 56, 56, 256) 1024 ['concatenate_5[0][0]'] ormalization) activation_18 (Activation) (None, 56, 56, 256) 0 ['batch_normalization_13[0][0]'] conv2d_13 (Conv2D) (None, 56, 56, 128) 32768 ['activation_18[0][0]'] average_pooling2d (AveragePool (None, 28, 28, 128) 0 ['conv2d_13[0][0]'] ing2D) activation_19 (Activation) (None, 28, 28, 128) 0 ['average_pooling2d[0][0]'] activation_20 (Activation) (None, 28, 28, 128) 0 ['activation_19[0][0]'] conv2d_14 (Conv2D) (None, 28, 28, 128) 16384 ['activation_20[0][0]'] batch_normalization_15 (BatchN (None, 28, 28, 128) 512 ['conv2d_14[0][0]'] ormalization) activation_21 (Activation) (None, 28, 28, 128) 0 ['batch_normalization_15[0][0]'] conv2d_15 (Conv2D) (None, 28, 28, 32) 36864 ['activation_21[0][0]'] concatenate_6 (Concatenate) (None, 28, 28, 160) 0 ['average_pooling2d[0][0]', 'conv2d_15[0][0]'] activation_22 (Activation) (None, 28, 28, 160) 0 ['concatenate_6[0][0]'] activation_23 (Activation) (None, 28, 28, 160) 0 ['activation_22[0][0]'] conv2d_16 (Conv2D) (None, 28, 28, 128) 20480 ['activation_23[0][0]'] batch_normalization_17 (BatchN (None, 28, 28, 128) 512 ['conv2d_16[0][0]'] ormalization) activation_24 (Activation) (None, 28, 28, 128) 0 ['batch_normalization_17[0][0]'] conv2d_17 (Conv2D) (None, 28, 28, 32) 36864 ['activation_24[0][0]'] concatenate_7 (Concatenate) (None, 28, 28, 192) 0 ['concatenate_6[0][0]', 'conv2d_17[0][0]'] activation_25 (Activation) (None, 28, 28, 192) 0 ['concatenate_7[0][0]'] activation_26 (Activation) (None, 28, 28, 192) 0 ['activation_25[0][0]'] conv2d_18 (Conv2D) (None, 28, 28, 128) 24576 ['activation_26[0][0]'] batch_normalization_19 (BatchN (None, 28, 28, 128) 512 ['conv2d_18[0][0]'] ormalization) activation_27 (Activation) (None, 28, 28, 128) 0 ['batch_normalization_19[0][0]'] conv2d_19 (Conv2D) (None, 28, 28, 32) 36864 ['activation_27[0][0]'] concatenate_8 (Concatenate) (None, 28, 28, 224) 0 ['concatenate_7[0][0]', 'conv2d_19[0][0]'] activation_28 (Activation) (None, 28, 28, 224) 0 ['concatenate_8[0][0]'] activation_29 (Activation) (None, 28, 28, 224) 0 ['activation_28[0][0]'] conv2d_20 (Conv2D) (None, 28, 28, 128) 28672 ['activation_29[0][0]'] batch_normalization_21 (BatchN (None, 28, 28, 128) 512 ['conv2d_20[0][0]'] ormalization) activation_30 (Activation) (None, 28, 28, 128) 0 ['batch_normalization_21[0][0]'] conv2d_21 (Conv2D) (None, 28, 28, 32) 36864 ['activation_30[0][0]'] concatenate_9 (Concatenate) (None, 28, 28, 256) 0 ['concatenate_8[0][0]', 'conv2d_21[0][0]'] activation_31 (Activation) (None, 28, 28, 256) 0 ['concatenate_9[0][0]'] activation_32 (Activation) (None, 28, 28, 256) 0 ['activation_31[0][0]'] conv2d_22 (Conv2D) (None, 28, 28, 128) 32768 ['activation_32[0][0]'] batch_normalization_23 (BatchN (None, 28, 28, 128) 512 ['conv2d_22[0][0]'] ormalization) activation_33 (Activation) (None, 28, 28, 128) 0 ['batch_normalization_23[0][0]'] conv2d_23 (Conv2D) (None, 28, 28, 32) 36864 ['activation_33[0][0]'] concatenate_10 (Concatenate) (None, 28, 28, 288) 0 ['concatenate_9[0][0]', 'conv2d_23[0][0]'] activation_34 (Activation) (None, 28, 28, 288) 0 ['concatenate_10[0][0]'] activation_35 (Activation) (None, 28, 28, 288) 0 ['activation_34[0][0]'] conv2d_24 (Conv2D) (None, 28, 28, 128) 36864 ['activation_35[0][0]'] batch_normalization_25 (BatchN (None, 28, 28, 128) 512 ['conv2d_24[0][0]'] ormalization) activation_36 (Activation) (None, 28, 28, 128) 0 ['batch_normalization_25[0][0]'] conv2d_25 (Conv2D) (None, 28, 28, 32) 36864 ['activation_36[0][0]'] concatenate_11 (Concatenate) (None, 28, 28, 320) 0 ['concatenate_10[0][0]', 'conv2d_25[0][0]'] activation_37 (Activation) (None, 28, 28, 320) 0 ['concatenate_11[0][0]'] activation_38 (Activation) (None, 28, 28, 320) 0 ['activation_37[0][0]'] conv2d_26 (Conv2D) (None, 28, 28, 128) 40960 ['activation_38[0][0]'] batch_normalization_27 (BatchN (None, 28, 28, 128) 512 ['conv2d_26[0][0]'] ormalization) activation_39 (Activation) (None, 28, 28, 128) 0 ['batch_normalization_27[0][0]'] conv2d_27 (Conv2D) (None, 28, 28, 32) 36864 ['activation_39[0][0]'] concatenate_12 (Concatenate) (None, 28, 28, 352) 0 ['concatenate_11[0][0]', 'conv2d_27[0][0]'] activation_40 (Activation) (None, 28, 28, 352) 0 ['concatenate_12[0][0]'] activation_41 (Activation) (None, 28, 28, 352) 0 ['activation_40[0][0]'] conv2d_28 (Conv2D) (None, 28, 28, 128) 45056 ['activation_41[0][0]'] batch_normalization_29 (BatchN (None, 28, 28, 128) 512 ['conv2d_28[0][0]'] ormalization) activation_42 (Activation) (None, 28, 28, 128) 0 ['batch_normalization_29[0][0]'] conv2d_29 (Conv2D) (None, 28, 28, 32) 36864 ['activation_42[0][0]'] concatenate_13 (Concatenate) (None, 28, 28, 384) 0 ['concatenate_12[0][0]', 'conv2d_29[0][0]'] activation_43 (Activation) (None, 28, 28, 384) 0 ['concatenate_13[0][0]'] activation_44 (Activation) (None, 28, 28, 384) 0 ['activation_43[0][0]'] conv2d_30 (Conv2D) (None, 28, 28, 128) 49152 ['activation_44[0][0]'] batch_normalization_31 (BatchN (None, 28, 28, 128) 512 ['conv2d_30[0][0]'] ormalization) activation_45 (Activation) (None, 28, 28, 128) 0 ['batch_normalization_31[0][0]'] conv2d_31 (Conv2D) (None, 28, 28, 32) 36864 ['activation_45[0][0]'] concatenate_14 (Concatenate) (None, 28, 28, 416) 0 ['concatenate_13[0][0]', 'conv2d_31[0][0]'] activation_46 (Activation) (None, 28, 28, 416) 0 ['concatenate_14[0][0]'] activation_47 (Activation) (None, 28, 28, 416) 0 ['activation_46[0][0]'] conv2d_32 (Conv2D) (None, 28, 28, 128) 53248 ['activation_47[0][0]'] batch_normalization_33 (BatchN (None, 28, 28, 128) 512 ['conv2d_32[0][0]'] ormalization) activation_48 (Activation) (None, 28, 28, 128) 0 ['batch_normalization_33[0][0]'] conv2d_33 (Conv2D) (None, 28, 28, 32) 36864 ['activation_48[0][0]'] concatenate_15 (Concatenate) (None, 28, 28, 448) 0 ['concatenate_14[0][0]', 'conv2d_33[0][0]'] activation_49 (Activation) (None, 28, 28, 448) 0 ['concatenate_15[0][0]'] activation_50 (Activation) (None, 28, 28, 448) 0 ['activation_49[0][0]'] conv2d_34 (Conv2D) (None, 28, 28, 128) 57344 ['activation_50[0][0]'] batch_normalization_35 (BatchN (None, 28, 28, 128) 512 ['conv2d_34[0][0]'] ormalization) activation_51 (Activation) (None, 28, 28, 128) 0 ['batch_normalization_35[0][0]'] conv2d_35 (Conv2D) (None, 28, 28, 32) 36864 ['activation_51[0][0]'] concatenate_16 (Concatenate) (None, 28, 28, 480) 0 ['concatenate_15[0][0]', 'conv2d_35[0][0]'] activation_52 (Activation) (None, 28, 28, 480) 0 ['concatenate_16[0][0]'] activation_53 (Activation) (None, 28, 28, 480) 0 ['activation_52[0][0]'] conv2d_36 (Conv2D) (None, 28, 28, 128) 61440 ['activation_53[0][0]'] batch_normalization_37 (BatchN (None, 28, 28, 128) 512 ['conv2d_36[0][0]'] ormalization) activation_54 (Activation) (None, 28, 28, 128) 0 ['batch_normalization_37[0][0]'] conv2d_37 (Conv2D) (None, 28, 28, 32) 36864 ['activation_54[0][0]'] concatenate_17 (Concatenate) (None, 28, 28, 512) 0 ['concatenate_16[0][0]', 'conv2d_37[0][0]'] batch_normalization_38 (BatchN (None, 28, 28, 512) 2048 ['concatenate_17[0][0]'] ormalization) activation_55 (Activation) (None, 28, 28, 512) 0 ['batch_normalization_38[0][0]'] conv2d_38 (Conv2D) (None, 28, 28, 256) 131072 ['activation_55[0][0]'] average_pooling2d_1 (AveragePo (None, 14, 14, 256) 0 ['conv2d_38[0][0]'] oling2D) activation_56 (Activation) (None, 14, 14, 256) 0 ['average_pooling2d_1[0][0]'] activation_57 (Activation) (None, 14, 14, 256) 0 ['activation_56[0][0]'] conv2d_39 (Conv2D) (None, 14, 14, 128) 32768 ['activation_57[0][0]'] batch_normalization_40 (BatchN (None, 14, 14, 128) 512 ['conv2d_39[0][0]'] ormalization) activation_58 (Activation) (None, 14, 14, 128) 0 ['batch_normalization_40[0][0]'] conv2d_40 (Conv2D) (None, 14, 14, 32) 36864 ['activation_58[0][0]'] concatenate_18 (Concatenate) (None, 14, 14, 288) 0 ['average_pooling2d_1[0][0]', 'conv2d_40[0][0]'] activation_59 (Activation) (None, 14, 14, 288) 0 ['concatenate_18[0][0]'] activation_60 (Activation) (None, 14, 14, 288) 0 ['activation_59[0][0]'] conv2d_41 (Conv2D) (None, 14, 14, 128) 36864 ['activation_60[0][0]'] batch_normalization_42 (BatchN (None, 14, 14, 128) 512 ['conv2d_41[0][0]'] ormalization) activation_61 (Activation) (None, 14, 14, 128) 0 ['batch_normalization_42[0][0]'] conv2d_42 (Conv2D) (None, 14, 14, 32) 36864 ['activation_61[0][0]'] concatenate_19 (Concatenate) (None, 14, 14, 320) 0 ['concatenate_18[0][0]', 'conv2d_42[0][0]'] activation_62 (Activation) (None, 14, 14, 320) 0 ['concatenate_19[0][0]'] activation_63 (Activation) (None, 14, 14, 320) 0 ['activation_62[0][0]'] conv2d_43 (Conv2D) (None, 14, 14, 128) 40960 ['activation_63[0][0]'] batch_normalization_44 (BatchN (None, 14, 14, 128) 512 ['conv2d_43[0][0]'] ormalization) activation_64 (Activation) (None, 14, 14, 128) 0 ['batch_normalization_44[0][0]'] conv2d_44 (Conv2D) (None, 14, 14, 32) 36864 ['activation_64[0][0]'] concatenate_20 (Concatenate) (None, 14, 14, 352) 0 ['concatenate_19[0][0]', 'conv2d_44[0][0]'] activation_65 (Activation) (None, 14, 14, 352) 0 ['concatenate_20[0][0]'] activation_66 (Activation) (None, 14, 14, 352) 0 ['activation_65[0][0]'] conv2d_45 (Conv2D) (None, 14, 14, 128) 45056 ['activation_66[0][0]'] batch_normalization_46 (BatchN (None, 14, 14, 128) 512 ['conv2d_45[0][0]'] ormalization) activation_67 (Activation) (None, 14, 14, 128) 0 ['batch_normalization_46[0][0]'] conv2d_46 (Conv2D) (None, 14, 14, 32) 36864 ['activation_67[0][0]'] concatenate_21 (Concatenate) (None, 14, 14, 384) 0 ['concatenate_20[0][0]', 'conv2d_46[0][0]'] activation_68 (Activation) (None, 14, 14, 384) 0 ['concatenate_21[0][0]'] activation_69 (Activation) (None, 14, 14, 384) 0 ['activation_68[0][0]'] conv2d_47 (Conv2D) (None, 14, 14, 128) 49152 ['activation_69[0][0]'] batch_normalization_48 (BatchN (None, 14, 14, 128) 512 ['conv2d_47[0][0]'] ormalization) activation_70 (Activation) (None, 14, 14, 128) 0 ['batch_normalization_48[0][0]'] conv2d_48 (Conv2D) (None, 14, 14, 32) 36864 ['activation_70[0][0]'] concatenate_22 (Concatenate) (None, 14, 14, 416) 0 ['concatenate_21[0][0]', 'conv2d_48[0][0]'] activation_71 (Activation) (None, 14, 14, 416) 0 ['concatenate_22[0][0]'] activation_72 (Activation) (None, 14, 14, 416) 0 ['activation_71[0][0]'] conv2d_49 (Conv2D) (None, 14, 14, 128) 53248 ['activation_72[0][0]'] batch_normalization_50 (BatchN (None, 14, 14, 128) 512 ['conv2d_49[0][0]'] ormalization) activation_73 (Activation) (None, 14, 14, 128) 0 ['batch_normalization_50[0][0]'] conv2d_50 (Conv2D) (None, 14, 14, 32) 36864 ['activation_73[0][0]'] concatenate_23 (Concatenate) (None, 14, 14, 448) 0 ['concatenate_22[0][0]', 'conv2d_50[0][0]'] activation_74 (Activation) (None, 14, 14, 448) 0 ['concatenate_23[0][0]'] activation_75 (Activation) (None, 14, 14, 448) 0 ['activation_74[0][0]'] conv2d_51 (Conv2D) (None, 14, 14, 128) 57344 ['activation_75[0][0]'] batch_normalization_52 (BatchN (None, 14, 14, 128) 512 ['conv2d_51[0][0]'] ormalization) activation_76 (Activation) (None, 14, 14, 128) 0 ['batch_normalization_52[0][0]'] conv2d_52 (Conv2D) (None, 14, 14, 32) 36864 ['activation_76[0][0]'] concatenate_24 (Concatenate) (None, 14, 14, 480) 0 ['concatenate_23[0][0]', 'conv2d_52[0][0]'] activation_77 (Activation) (None, 14, 14, 480) 0 ['concatenate_24[0][0]'] activation_78 (Activation) (None, 14, 14, 480) 0 ['activation_77[0][0]'] conv2d_53 (Conv2D) (None, 14, 14, 128) 61440 ['activation_78[0][0]'] batch_normalization_54 (BatchN (None, 14, 14, 128) 512 ['conv2d_53[0][0]'] ormalization) activation_79 (Activation) (None, 14, 14, 128) 0 ['batch_normalization_54[0][0]'] conv2d_54 (Conv2D) (None, 14, 14, 32) 36864 ['activation_79[0][0]'] concatenate_25 (Concatenate) (None, 14, 14, 512) 0 ['concatenate_24[0][0]', 'conv2d_54[0][0]'] activation_80 (Activation) (None, 14, 14, 512) 0 ['concatenate_25[0][0]'] activation_81 (Activation) (None, 14, 14, 512) 0 ['activation_80[0][0]'] conv2d_55 (Conv2D) (None, 14, 14, 128) 65536 ['activation_81[0][0]'] batch_normalization_56 (BatchN (None, 14, 14, 128) 512 ['conv2d_55[0][0]'] ormalization) activation_82 (Activation) (None, 14, 14, 128) 0 ['batch_normalization_56[0][0]'] conv2d_56 (Conv2D) (None, 14, 14, 32) 36864 ['activation_82[0][0]'] concatenate_26 (Concatenate) (None, 14, 14, 544) 0 ['concatenate_25[0][0]', 'conv2d_56[0][0]'] activation_83 (Activation) (None, 14, 14, 544) 0 ['concatenate_26[0][0]'] activation_84 (Activation) (None, 14, 14, 544) 0 ['activation_83[0][0]'] conv2d_57 (Conv2D) (None, 14, 14, 128) 69632 ['activation_84[0][0]'] batch_normalization_58 (BatchN (None, 14, 14, 128) 512 ['conv2d_57[0][0]'] ormalization) activation_85 (Activation) (None, 14, 14, 128) 0 ['batch_normalization_58[0][0]'] conv2d_58 (Conv2D) (None, 14, 14, 32) 36864 ['activation_85[0][0]'] concatenate_27 (Concatenate) (None, 14, 14, 576) 0 ['concatenate_26[0][0]', 'conv2d_58[0][0]'] activation_86 (Activation) (None, 14, 14, 576) 0 ['concatenate_27[0][0]'] activation_87 (Activation) (None, 14, 14, 576) 0 ['activation_86[0][0]'] conv2d_59 (Conv2D) (None, 14, 14, 128) 73728 ['activation_87[0][0]'] batch_normalization_60 (BatchN (None, 14, 14, 128) 512 ['conv2d_59[0][0]'] ormalization) activation_88 (Activation) (None, 14, 14, 128) 0 ['batch_normalization_60[0][0]'] conv2d_60 (Conv2D) (None, 14, 14, 32) 36864 ['activation_88[0][0]'] concatenate_28 (Concatenate) (None, 14, 14, 608) 0 ['concatenate_27[0][0]', 'conv2d_60[0][0]'] activation_89 (Activation) (None, 14, 14, 608) 0 ['concatenate_28[0][0]'] activation_90 (Activation) (None, 14, 14, 608) 0 ['activation_89[0][0]'] conv2d_61 (Conv2D) (None, 14, 14, 128) 77824 ['activation_90[0][0]'] batch_normalization_62 (BatchN (None, 14, 14, 128) 512 ['conv2d_61[0][0]'] ormalization) activation_91 (Activation) (None, 14, 14, 128) 0 ['batch_normalization_62[0][0]'] conv2d_62 (Conv2D) (None, 14, 14, 32) 36864 ['activation_91[0][0]'] concatenate_29 (Concatenate) (None, 14, 14, 640) 0 ['concatenate_28[0][0]', 'conv2d_62[0][0]'] activation_92 (Activation) (None, 14, 14, 640) 0 ['concatenate_29[0][0]'] activation_93 (Activation) (None, 14, 14, 640) 0 ['activation_92[0][0]'] conv2d_63 (Conv2D) (None, 14, 14, 128) 81920 ['activation_93[0][0]'] batch_normalization_64 (BatchN (None, 14, 14, 128) 512 ['conv2d_63[0][0]'] ormalization) activation_94 (Activation) (None, 14, 14, 128) 0 ['batch_normalization_64[0][0]'] conv2d_64 (Conv2D) (None, 14, 14, 32) 36864 ['activation_94[0][0]'] concatenate_30 (Concatenate) (None, 14, 14, 672) 0 ['concatenate_29[0][0]', 'conv2d_64[0][0]'] activation_95 (Activation) (None, 14, 14, 672) 0 ['concatenate_30[0][0]'] activation_96 (Activation) (None, 14, 14, 672) 0 ['activation_95[0][0]'] conv2d_65 (Conv2D) (None, 14, 14, 128) 86016 ['activation_96[0][0]'] batch_normalization_66 (BatchN (None, 14, 14, 128) 512 ['conv2d_65[0][0]'] ormalization) activation_97 (Activation) (None, 14, 14, 128) 0 ['batch_normalization_66[0][0]'] conv2d_66 (Conv2D) (None, 14, 14, 32) 36864 ['activation_97[0][0]'] concatenate_31 (Concatenate) (None, 14, 14, 704) 0 ['concatenate_30[0][0]', 'conv2d_66[0][0]'] activation_98 (Activation) (None, 14, 14, 704) 0 ['concatenate_31[0][0]'] activation_99 (Activation) (None, 14, 14, 704) 0 ['activation_98[0][0]'] conv2d_67 (Conv2D) (None, 14, 14, 128) 90112 ['activation_99[0][0]'] batch_normalization_68 (BatchN (None, 14, 14, 128) 512 ['conv2d_67[0][0]'] ormalization) activation_100 (Activation) (None, 14, 14, 128) 0 ['batch_normalization_68[0][0]'] conv2d_68 (Conv2D) (None, 14, 14, 32) 36864 ['activation_100[0][0]'] concatenate_32 (Concatenate) (None, 14, 14, 736) 0 ['concatenate_31[0][0]', 'conv2d_68[0][0]'] activation_101 (Activation) (None, 14, 14, 736) 0 ['concatenate_32[0][0]'] activation_102 (Activation) (None, 14, 14, 736) 0 ['activation_101[0][0]'] conv2d_69 (Conv2D) (None, 14, 14, 128) 94208 ['activation_102[0][0]'] batch_normalization_70 (BatchN (None, 14, 14, 128) 512 ['conv2d_69[0][0]'] ormalization) activation_103 (Activation) (None, 14, 14, 128) 0 ['batch_normalization_70[0][0]'] conv2d_70 (Conv2D) (None, 14, 14, 32) 36864 ['activation_103[0][0]'] concatenate_33 (Concatenate) (None, 14, 14, 768) 0 ['concatenate_32[0][0]', 'conv2d_70[0][0]'] activation_104 (Activation) (None, 14, 14, 768) 0 ['concatenate_33[0][0]'] activation_105 (Activation) (None, 14, 14, 768) 0 ['activation_104[0][0]'] conv2d_71 (Conv2D) (None, 14, 14, 128) 98304 ['activation_105[0][0]'] batch_normalization_72 (BatchN (None, 14, 14, 128) 512 ['conv2d_71[0][0]'] ormalization) activation_106 (Activation) (None, 14, 14, 128) 0 ['batch_normalization_72[0][0]'] conv2d_72 (Conv2D) (None, 14, 14, 32) 36864 ['activation_106[0][0]'] concatenate_34 (Concatenate) (None, 14, 14, 800) 0 ['concatenate_33[0][0]', 'conv2d_72[0][0]'] activation_107 (Activation) (None, 14, 14, 800) 0 ['concatenate_34[0][0]'] activation_108 (Activation) (None, 14, 14, 800) 0 ['activation_107[0][0]'] conv2d_73 (Conv2D) (None, 14, 14, 128) 102400 ['activation_108[0][0]'] batch_normalization_74 (BatchN (None, 14, 14, 128) 512 ['conv2d_73[0][0]'] ormalization) activation_109 (Activation) (None, 14, 14, 128) 0 ['batch_normalization_74[0][0]'] conv2d_74 (Conv2D) (None, 14, 14, 32) 36864 ['activation_109[0][0]'] concatenate_35 (Concatenate) (None, 14, 14, 832) 0 ['concatenate_34[0][0]', 'conv2d_74[0][0]'] activation_110 (Activation) (None, 14, 14, 832) 0 ['concatenate_35[0][0]'] activation_111 (Activation) (None, 14, 14, 832) 0 ['activation_110[0][0]'] conv2d_75 (Conv2D) (None, 14, 14, 128) 106496 ['activation_111[0][0]'] batch_normalization_76 (BatchN (None, 14, 14, 128) 512 ['conv2d_75[0][0]'] ormalization) activation_112 (Activation) (None, 14, 14, 128) 0 ['batch_normalization_76[0][0]'] conv2d_76 (Conv2D) (None, 14, 14, 32) 36864 ['activation_112[0][0]'] concatenate_36 (Concatenate) (None, 14, 14, 864) 0 ['concatenate_35[0][0]', 'conv2d_76[0][0]'] activation_113 (Activation) (None, 14, 14, 864) 0 ['concatenate_36[0][0]'] activation_114 (Activation) (None, 14, 14, 864) 0 ['activation_113[0][0]'] conv2d_77 (Conv2D) (None, 14, 14, 128) 110592 ['activation_114[0][0]'] batch_normalization_78 (BatchN (None, 14, 14, 128) 512 ['conv2d_77[0][0]'] ormalization) activation_115 (Activation) (None, 14, 14, 128) 0 ['batch_normalization_78[0][0]'] conv2d_78 (Conv2D) (None, 14, 14, 32) 36864 ['activation_115[0][0]'] concatenate_37 (Concatenate) (None, 14, 14, 896) 0 ['concatenate_36[0][0]', 'conv2d_78[0][0]'] activation_116 (Activation) (None, 14, 14, 896) 0 ['concatenate_37[0][0]'] activation_117 (Activation) (None, 14, 14, 896) 0 ['activation_116[0][0]'] conv2d_79 (Conv2D) (None, 14, 14, 128) 114688 ['activation_117[0][0]'] batch_normalization_80 (BatchN (None, 14, 14, 128) 512 ['conv2d_79[0][0]'] ormalization) activation_118 (Activation) (None, 14, 14, 128) 0 ['batch_normalization_80[0][0]'] conv2d_80 (Conv2D) (None, 14, 14, 32) 36864 ['activation_118[0][0]'] concatenate_38 (Concatenate) (None, 14, 14, 928) 0 ['concatenate_37[0][0]', 'conv2d_80[0][0]'] activation_119 (Activation) (None, 14, 14, 928) 0 ['concatenate_38[0][0]'] activation_120 (Activation) (None, 14, 14, 928) 0 ['activation_119[0][0]'] conv2d_81 (Conv2D) (None, 14, 14, 128) 118784 ['activation_120[0][0]'] batch_normalization_82 (BatchN (None, 14, 14, 128) 512 ['conv2d_81[0][0]'] ormalization) activation_121 (Activation) (None, 14, 14, 128) 0 ['batch_normalization_82[0][0]'] conv2d_82 (Conv2D) (None, 14, 14, 32) 36864 ['activation_121[0][0]'] concatenate_39 (Concatenate) (None, 14, 14, 960) 0 ['concatenate_38[0][0]', 'conv2d_82[0][0]'] activation_122 (Activation) (None, 14, 14, 960) 0 ['concatenate_39[0][0]'] activation_123 (Activation) (None, 14, 14, 960) 0 ['activation_122[0][0]'] conv2d_83 (Conv2D) (None, 14, 14, 128) 122880 ['activation_123[0][0]'] batch_normalization_84 (BatchN (None, 14, 14, 128) 512 ['conv2d_83[0][0]'] ormalization) activation_124 (Activation) (None, 14, 14, 128) 0 ['batch_normalization_84[0][0]'] conv2d_84 (Conv2D) (None, 14, 14, 32) 36864 ['activation_124[0][0]'] concatenate_40 (Concatenate) (None, 14, 14, 992) 0 ['concatenate_39[0][0]', 'conv2d_84[0][0]'] activation_125 (Activation) (None, 14, 14, 992) 0 ['concatenate_40[0][0]'] activation_126 (Activation) (None, 14, 14, 992) 0 ['activation_125[0][0]'] conv2d_85 (Conv2D) (None, 14, 14, 128) 126976 ['activation_126[0][0]'] batch_normalization_86 (BatchN (None, 14, 14, 128) 512 ['conv2d_85[0][0]'] ormalization) activation_127 (Activation) (None, 14, 14, 128) 0 ['batch_normalization_86[0][0]'] conv2d_86 (Conv2D) (None, 14, 14, 32) 36864 ['activation_127[0][0]'] concatenate_41 (Concatenate) (None, 14, 14, 1024 0 ['concatenate_40[0][0]', ) 'conv2d_86[0][0]'] batch_normalization_87 (BatchN (None, 14, 14, 1024 4096 ['concatenate_41[0][0]'] ormalization) ) activation_128 (Activation) (None, 14, 14, 1024 0 ['batch_normalization_87[0][0]'] ) conv2d_87 (Conv2D) (None, 14, 14, 512) 524288 ['activation_128[0][0]'] average_pooling2d_2 (AveragePo (None, 7, 7, 512) 0 ['conv2d_87[0][0]'] oling2D) activation_129 (Activation) (None, 7, 7, 512) 0 ['average_pooling2d_2[0][0]'] activation_130 (Activation) (None, 7, 7, 512) 0 ['activation_129[0][0]'] conv2d_88 (Conv2D) (None, 7, 7, 128) 65536 ['activation_130[0][0]'] batch_normalization_89 (BatchN (None, 7, 7, 128) 512 ['conv2d_88[0][0]'] ormalization) activation_131 (Activation) (None, 7, 7, 128) 0 ['batch_normalization_89[0][0]'] conv2d_89 (Conv2D) (None, 7, 7, 32) 36864 ['activation_131[0][0]'] concatenate_42 (Concatenate) (None, 7, 7, 544) 0 ['average_pooling2d_2[0][0]', 'conv2d_89[0][0]'] activation_132 (Activation) (None, 7, 7, 544) 0 ['concatenate_42[0][0]'] activation_133 (Activation) (None, 7, 7, 544) 0 ['activation_132[0][0]'] conv2d_90 (Conv2D) (None, 7, 7, 128) 69632 ['activation_133[0][0]'] batch_normalization_91 (BatchN (None, 7, 7, 128) 512 ['conv2d_90[0][0]'] ormalization) activation_134 (Activation) (None, 7, 7, 128) 0 ['batch_normalization_91[0][0]'] conv2d_91 (Conv2D) (None, 7, 7, 32) 36864 ['activation_134[0][0]'] concatenate_43 (Concatenate) (None, 7, 7, 576) 0 ['concatenate_42[0][0]', 'conv2d_91[0][0]'] activation_135 (Activation) (None, 7, 7, 576) 0 ['concatenate_43[0][0]'] activation_136 (Activation) (None, 7, 7, 576) 0 ['activation_135[0][0]'] conv2d_92 (Conv2D) (None, 7, 7, 128) 73728 ['activation_136[0][0]'] batch_normalization_93 (BatchN (None, 7, 7, 128) 512 ['conv2d_92[0][0]'] ormalization) activation_137 (Activation) (None, 7, 7, 128) 0 ['batch_normalization_93[0][0]'] conv2d_93 (Conv2D) (None, 7, 7, 32) 36864 ['activation_137[0][0]'] concatenate_44 (Concatenate) (None, 7, 7, 608) 0 ['concatenate_43[0][0]', 'conv2d_93[0][0]'] activation_138 (Activation) (None, 7, 7, 608) 0 ['concatenate_44[0][0]'] activation_139 (Activation) (None, 7, 7, 608) 0 ['activation_138[0][0]'] conv2d_94 (Conv2D) (None, 7, 7, 128) 77824 ['activation_139[0][0]'] batch_normalization_95 (BatchN (None, 7, 7, 128) 512 ['conv2d_94[0][0]'] ormalization) activation_140 (Activation) (None, 7, 7, 128) 0 ['batch_normalization_95[0][0]'] conv2d_95 (Conv2D) (None, 7, 7, 32) 36864 ['activation_140[0][0]'] concatenate_45 (Concatenate) (None, 7, 7, 640) 0 ['concatenate_44[0][0]', 'conv2d_95[0][0]'] activation_141 (Activation) (None, 7, 7, 640) 0 ['concatenate_45[0][0]'] activation_142 (Activation) (None, 7, 7, 640) 0 ['activation_141[0][0]'] conv2d_96 (Conv2D) (None, 7, 7, 128) 81920 ['activation_142[0][0]'] batch_normalization_97 (BatchN (None, 7, 7, 128) 512 ['conv2d_96[0][0]'] ormalization) activation_143 (Activation) (None, 7, 7, 128) 0 ['batch_normalization_97[0][0]'] conv2d_97 (Conv2D) (None, 7, 7, 32) 36864 ['activation_143[0][0]'] concatenate_46 (Concatenate) (None, 7, 7, 672) 0 ['concatenate_45[0][0]', 'conv2d_97[0][0]'] activation_144 (Activation) (None, 7, 7, 672) 0 ['concatenate_46[0][0]'] activation_145 (Activation) (None, 7, 7, 672) 0 ['activation_144[0][0]'] conv2d_98 (Conv2D) (None, 7, 7, 128) 86016 ['activation_145[0][0]'] batch_normalization_99 (BatchN (None, 7, 7, 128) 512 ['conv2d_98[0][0]'] ormalization) activation_146 (Activation) (None, 7, 7, 128) 0 ['batch_normalization_99[0][0]'] conv2d_99 (Conv2D) (None, 7, 7, 32) 36864 ['activation_146[0][0]'] concatenate_47 (Concatenate) (None, 7, 7, 704) 0 ['concatenate_46[0][0]', 'conv2d_99[0][0]'] activation_147 (Activation) (None, 7, 7, 704) 0 ['concatenate_47[0][0]'] activation_148 (Activation) (None, 7, 7, 704) 0 ['activation_147[0][0]'] conv2d_100 (Conv2D) (None, 7, 7, 128) 90112 ['activation_148[0][0]'] batch_normalization_101 (Batch (None, 7, 7, 128) 512 ['conv2d_100[0][0]'] Normalization) activation_149 (Activation) (None, 7, 7, 128) 0 ['batch_normalization_101[0][0]']conv2d_101 (Conv2D) (None, 7, 7, 32) 36864 ['activation_149[0][0]'] concatenate_48 (Concatenate) (None, 7, 7, 736) 0 ['concatenate_47[0][0]', 'conv2d_101[0][0]'] activation_150 (Activation) (None, 7, 7, 736) 0 ['concatenate_48[0][0]'] activation_151 (Activation) (None, 7, 7, 736) 0 ['activation_150[0][0]'] conv2d_102 (Conv2D) (None, 7, 7, 128) 94208 ['activation_151[0][0]'] batch_normalization_103 (Batch (None, 7, 7, 128) 512 ['conv2d_102[0][0]'] Normalization) activation_152 (Activation) (None, 7, 7, 128) 0 ['batch_normalization_103[0][0]']conv2d_103 (Conv2D) (None, 7, 7, 32) 36864 ['activation_152[0][0]'] concatenate_49 (Concatenate) (None, 7, 7, 768) 0 ['concatenate_48[0][0]', 'conv2d_103[0][0]'] activation_153 (Activation) (None, 7, 7, 768) 0 ['concatenate_49[0][0]'] activation_154 (Activation) (None, 7, 7, 768) 0 ['activation_153[0][0]'] conv2d_104 (Conv2D) (None, 7, 7, 128) 98304 ['activation_154[0][0]'] batch_normalization_105 (Batch (None, 7, 7, 128) 512 ['conv2d_104[0][0]'] Normalization) activation_155 (Activation) (None, 7, 7, 128) 0 ['batch_normalization_105[0][0]']conv2d_105 (Conv2D) (None, 7, 7, 32) 36864 ['activation_155[0][0]'] concatenate_50 (Concatenate) (None, 7, 7, 800) 0 ['concatenate_49[0][0]', 'conv2d_105[0][0]'] activation_156 (Activation) (None, 7, 7, 800) 0 ['concatenate_50[0][0]'] activation_157 (Activation) (None, 7, 7, 800) 0 ['activation_156[0][0]'] conv2d_106 (Conv2D) (None, 7, 7, 128) 102400 ['activation_157[0][0]'] batch_normalization_107 (Batch (None, 7, 7, 128) 512 ['conv2d_106[0][0]'] Normalization) activation_158 (Activation) (None, 7, 7, 128) 0 ['batch_normalization_107[0][0]']conv2d_107 (Conv2D) (None, 7, 7, 32) 36864 ['activation_158[0][0]'] concatenate_51 (Concatenate) (None, 7, 7, 832) 0 ['concatenate_50[0][0]', 'conv2d_107[0][0]'] activation_159 (Activation) (None, 7, 7, 832) 0 ['concatenate_51[0][0]'] activation_160 (Activation) (None, 7, 7, 832) 0 ['activation_159[0][0]'] conv2d_108 (Conv2D) (None, 7, 7, 128) 106496 ['activation_160[0][0]'] batch_normalization_109 (Batch (None, 7, 7, 128) 512 ['conv2d_108[0][0]'] Normalization) activation_161 (Activation) (None, 7, 7, 128) 0 ['batch_normalization_109[0][0]']conv2d_109 (Conv2D) (None, 7, 7, 32) 36864 ['activation_161[0][0]'] concatenate_52 (Concatenate) (None, 7, 7, 864) 0 ['concatenate_51[0][0]', 'conv2d_109[0][0]'] activation_162 (Activation) (None, 7, 7, 864) 0 ['concatenate_52[0][0]'] activation_163 (Activation) (None, 7, 7, 864) 0 ['activation_162[0][0]'] conv2d_110 (Conv2D) (None, 7, 7, 128) 110592 ['activation_163[0][0]'] batch_normalization_111 (Batch (None, 7, 7, 128) 512 ['conv2d_110[0][0]'] Normalization) activation_164 (Activation) (None, 7, 7, 128) 0 ['batch_normalization_111[0][0]']conv2d_111 (Conv2D) (None, 7, 7, 32) 36864 ['activation_164[0][0]'] concatenate_53 (Concatenate) (None, 7, 7, 896) 0 ['concatenate_52[0][0]', 'conv2d_111[0][0]'] activation_165 (Activation) (None, 7, 7, 896) 0 ['concatenate_53[0][0]'] activation_166 (Activation) (None, 7, 7, 896) 0 ['activation_165[0][0]'] conv2d_112 (Conv2D) (None, 7, 7, 128) 114688 ['activation_166[0][0]'] batch_normalization_113 (Batch (None, 7, 7, 128) 512 ['conv2d_112[0][0]'] Normalization) activation_167 (Activation) (None, 7, 7, 128) 0 ['batch_normalization_113[0][0]']conv2d_113 (Conv2D) (None, 7, 7, 32) 36864 ['activation_167[0][0]'] concatenate_54 (Concatenate) (None, 7, 7, 928) 0 ['concatenate_53[0][0]', 'conv2d_113[0][0]'] activation_168 (Activation) (None, 7, 7, 928) 0 ['concatenate_54[0][0]'] activation_169 (Activation) (None, 7, 7, 928) 0 ['activation_168[0][0]'] conv2d_114 (Conv2D) (None, 7, 7, 128) 118784 ['activation_169[0][0]'] batch_normalization_115 (Batch (None, 7, 7, 128) 512 ['conv2d_114[0][0]'] Normalization) activation_170 (Activation) (None, 7, 7, 128) 0 ['batch_normalization_115[0][0]']conv2d_115 (Conv2D) (None, 7, 7, 32) 36864 ['activation_170[0][0]'] concatenate_55 (Concatenate) (None, 7, 7, 960) 0 ['concatenate_54[0][0]', 'conv2d_115[0][0]'] activation_171 (Activation) (None, 7, 7, 960) 0 ['concatenate_55[0][0]'] activation_172 (Activation) (None, 7, 7, 960) 0 ['activation_171[0][0]'] conv2d_116 (Conv2D) (None, 7, 7, 128) 122880 ['activation_172[0][0]'] batch_normalization_117 (Batch (None, 7, 7, 128) 512 ['conv2d_116[0][0]'] Normalization) activation_173 (Activation) (None, 7, 7, 128) 0 ['batch_normalization_117[0][0]']conv2d_117 (Conv2D) (None, 7, 7, 32) 36864 ['activation_173[0][0]'] concatenate_56 (Concatenate) (None, 7, 7, 992) 0 ['concatenate_55[0][0]', 'conv2d_117[0][0]'] activation_174 (Activation) (None, 7, 7, 992) 0 ['concatenate_56[0][0]'] activation_175 (Activation) (None, 7, 7, 992) 0 ['activation_174[0][0]'] conv2d_118 (Conv2D) (None, 7, 7, 128) 126976 ['activation_175[0][0]'] batch_normalization_119 (Batch (None, 7, 7, 128) 512 ['conv2d_118[0][0]'] Normalization) activation_176 (Activation) (None, 7, 7, 128) 0 ['batch_normalization_119[0][0]']conv2d_119 (Conv2D) (None, 7, 7, 32) 36864 ['activation_176[0][0]'] concatenate_57 (Concatenate) (None, 7, 7, 1024) 0 ['concatenate_56[0][0]', 'conv2d_119[0][0]'] batch_normalization_120 (Batch (None, 7, 7, 1024) 4096 ['concatenate_57[0][0]'] Normalization) activation_177 (Activation) (None, 7, 7, 1024) 0 ['batch_normalization_120[0][0]']global_average_pooling2d (Glob (None, 1024) 0 ['activation_177[0][0]'] alAveragePooling2D) dense (Dense) (None, 1000) 1025000 ['global_average_pooling2d[0][0]'] ==================================================================================================
Total params: 7,936,424
Trainable params: 7,915,816
Non-trainable params: 20,608
__________________________________________________________________________________________________
3.10.编译模型
#设置初始学习率
initial_learning_rate = 1e-4
opt = tf.keras.optimizers.Adam(learning_rate=initial_learning_rate)
model.compile(optimizer=opt,loss='sparse_categorical_crossentropy',metrics=['accuracy'])3.11.训练模型
'''训练模型'''
epochs = 10
history = model.fit(train_ds,validation_data=val_ds,epochs=epochs
)
训练记录如下:
Epoch 1/10
15/15 [==============================] - ETA: 0s - loss: 5.4243 - accuracy: 0.4336
Epoch 1: val_accuracy improved from -inf to 0.33628, saving model to best_model.h5
15/15 [==============================] - 14s 251ms/step - loss: 5.4243 - accuracy: 0.4336 - val_loss: 5.9027 - val_accuracy: 0.3363
Epoch 2/10
14/15 [===========================>..] - ETA: 0s - loss: 2.7611 - accuracy: 0.7366
Epoch 2: val_accuracy improved from 0.33628 to 0.41372, saving model to best_model.h5
15/15 [==============================] - 3s 199ms/step - loss: 2.7560 - accuracy: 0.7367 - val_loss: 5.6493 - val_accuracy: 0.4137
Epoch 3/10
15/15 [==============================] - ETA: 0s - loss: 1.3179 - accuracy: 0.8319
Epoch 3: val_accuracy did not improve from 0.41372
15/15 [==============================] - 3s 181ms/step - loss: 1.3179 - accuracy: 0.8319 - val_loss: 5.2275 - val_accuracy: 0.4071
Epoch 4/10
15/15 [==============================] - ETA: 0s - loss: 0.7476 - accuracy: 0.8562
Epoch 4: val_accuracy improved from 0.41372 to 0.45354, saving model to best_model.h5
15/15 [==============================] - 3s 204ms/step - loss: 0.7476 - accuracy: 0.8562 - val_loss: 4.9389 - val_accuracy: 0.4535
Epoch 5/10
15/15 [==============================] - ETA: 0s - loss: 0.4224 - accuracy: 0.9181
Epoch 5: val_accuracy did not improve from 0.45354
15/15 [==============================] - 3s 184ms/step - loss: 0.4224 - accuracy: 0.9181 - val_loss: 4.4976 - val_accuracy: 0.4137
Epoch 6/10
15/15 [==============================] - ETA: 0s - loss: 0.2802 - accuracy: 0.9447
Epoch 6: val_accuracy improved from 0.45354 to 0.57743, saving model to best_model.h5
15/15 [==============================] - 3s 197ms/step - loss: 0.2802 - accuracy: 0.9447 - val_loss: 3.8567 - val_accuracy: 0.5774
Epoch 7/10
15/15 [==============================] - ETA: 0s - loss: 0.2048 - accuracy: 0.9558
Epoch 7: val_accuracy did not improve from 0.57743
15/15 [==============================] - 3s 183ms/step - loss: 0.2048 - accuracy: 0.9558 - val_loss: 3.4727 - val_accuracy: 0.4801
Epoch 8/10
15/15 [==============================] - ETA: 0s - loss: 0.1514 - accuracy: 0.9690
Epoch 8: val_accuracy did not improve from 0.57743
15/15 [==============================] - 3s 184ms/step - loss: 0.1514 - accuracy: 0.9690 - val_loss: 2.5986 - val_accuracy: 0.5619
Epoch 9/10
15/15 [==============================] - ETA: 0s - loss: 0.0868 - accuracy: 0.9912
Epoch 9: val_accuracy did not improve from 0.57743
15/15 [==============================] - 3s 181ms/step - loss: 0.0868 - accuracy: 0.9912 - val_loss: 2.1531 - val_accuracy: 0.5619
Epoch 10/10
15/15 [==============================] - ETA: 0s - loss: 0.0547 - accuracy: 0.9889
Epoch 10: val_accuracy did not improve from 0.57743
15/15 [==============================] - 3s 181ms/step - loss: 0.0547 - accuracy: 0.9889 - val_loss: 1.9243 - val_accuracy: 0.52433.12.模型评估
'''模型评估'''
acc = history.history['accuracy']
val_acc = history.history['val_accuracy']
loss = history.history['loss']
val_loss = history.history['val_loss']
epochs_range = range(len(loss))
plt.figure(figsize=(12, 4))
plt.subplot(1, 2, 1)
plt.plot(epochs_range, acc, label='Training Accuracy')
plt.plot(epochs_range, val_acc, label='Validation Accuracy')
plt.legend(loc='lower right')
plt.title('Training and Validation Accuracy')
plt.subplot(1, 2, 2)
plt.plot(epochs_range, loss, label='Training Loss')
plt.plot(epochs_range, val_loss, label='Validation Loss')
plt.legend(loc='upper right')
plt.title('Training and Validation Loss')
plt.show()
3.13.图像预测
'''指定图片进行预测'''
# 采用加载的模型(new_model)来看预测结果
plt.figure(figsize=(10, 5)) # 图形的宽为10高为5
plt.suptitle("预测结果展示", fontsize=10)
for images, labels in val_ds.take(1):for i in range(8):ax = plt.subplot(2, 4, i + 1)# 显示图片plt.imshow(images[i].numpy().astype("uint8"))# 需要给图片增加一个维度img_array = tf.expand_dims(images[i], 0)# 使用模型预测图片中的人物predictions = model.predict(img_array)plt.title(class_names[np.argmax(predictions)], fontsize=10)plt.axis("off")
plt.show()

4 知识点详解
4.1 DenseNet算法详解
4.1.1 前言
在计算机视觉领域,卷积神经网络(CNN)已经成为最主流的方法,比如GoogleNet,VGG-16,Incepetion等模型。CNN史上的一个里程碑事件是ResNet模型的出现,ResNet可以训练出更深的CNN模型,从而实现更高的准确率。ResNet模型的核心是通过建立前面层与后面层之间的“短路连接”(shortcut, skip connection),进而训练出更深的CNN网络。
DenseNet模型的基本思路与ResNet一致,但是它建立的是前面所有层与后面层的紧密连接(dense connection),它的名称也是由此而来。DenseNet的另一大特色是通过特征在channel上的的连接来实现特征重用(feature reuse)。这些特点让DenseNet在参数和计算成本更少的情形下实现比ResNet更优的性能,DenseNet也因此斩获CVPR2017的最佳论文奖。
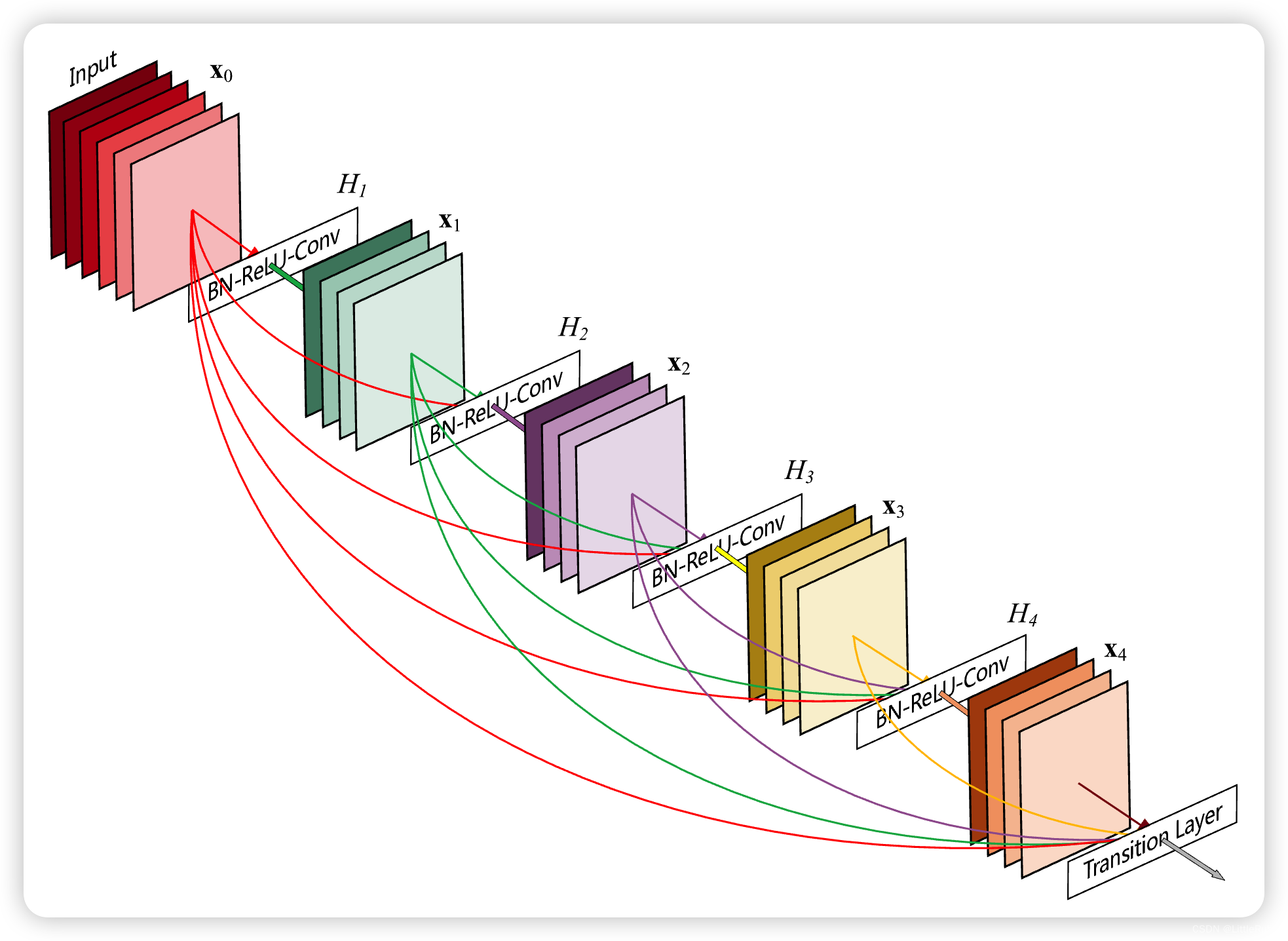
其中DenseNet论文原文地址为:https://arxiv.org/pdf/1608.06993v5.pdf
4.1.2 设计理念
相比ResNet,DenseNet提出了一个更激进的密集连接机制:即互相连接所有的层,具体来说就是每个层都会接受前面所有层作为额外的输入。
图3为ResNet网络的残差连接机制,作为对比,图4为DenseNet的密集连接机制。可以看到,ResNet是每个层与前面的某层(一般是2~4层)短路连接在一起,连接方式是通过元素相加。而在DenseNet中,每个层都会与前面所有层在channel维度上链接(concat)在一起(即元素叠加),并作为下一层的输入。
对于一个 L L L层的网络,DenseNet共包含 L ( L + 1 ) 2 \frac{L(L+1)}{2} 2L(L+1)个连接,相比ResNet,这是一种密集连接。而且DenseNet是直接concat来自不同层的特征图,这可以实现特征重用,提升效率,这一特点是DenseNet与ResNet最主要的区别。
4.1.2.1 标准神经网络

图2是一个标准的神经网络传播过程示意图,输入和输出的公式是 X l = H l ( X l − 1 ) X_l=H_l(X_{l-1}) Xl=Hl(Xl−1),其中 H l H_l Hl是一个组合函数,通常包括BN、ReLu、Pooling、Conv等操作, X l − 1 X_{l-1} Xl−1是第 l l l层的输入的特征图(来自于l-1层的输出), X l X_l Xl是第 l l l层的输出的特征图。
4.1.2.2 ResNet
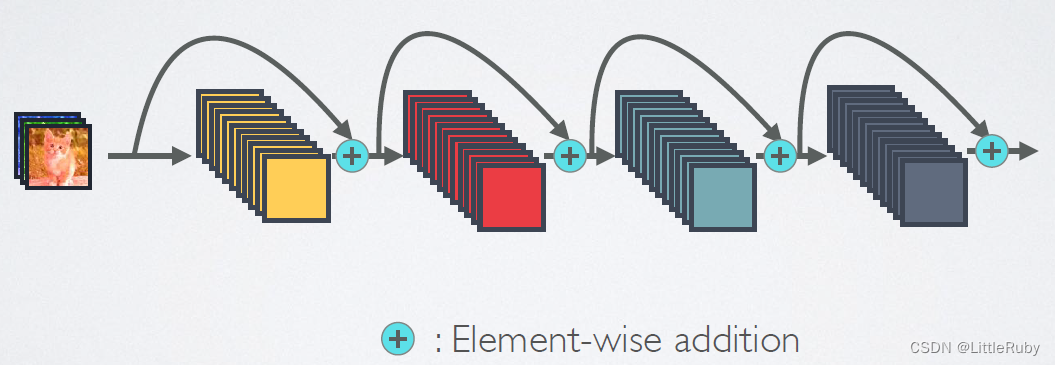
图3是ResNet的网络连接机制,由图可知是跨层相加,输入和输出的公式是 X l = H l ( X l − 1 ) + X l − 1 X_l=H_l(X_{l-1})+X_{l-1} Xl=Hl(Xl−1)+Xl−1
4.1.2.3 DenseNet
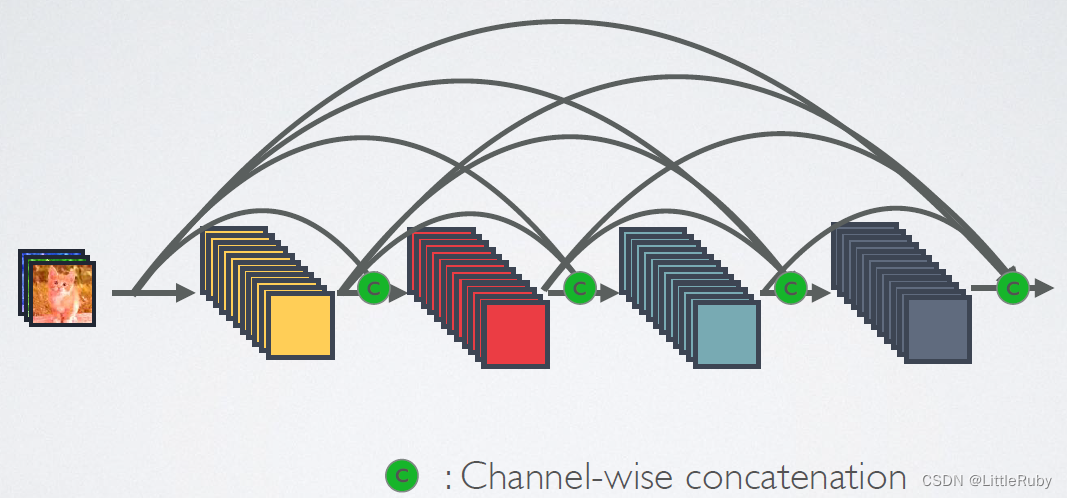
图4为DenseNet的连接机制,采用跨通道的concat的形式连接,会连接前面所有层作为输入,输入和输出的公式是 X l = H l ( X 0 , X 1 , . . . , X l − 1 ) X_l=H_l(X_0,X_1,...,X_{l-1}) Xl=Hl(X0,X1,...,Xl−1)。这里要注意所有层的输入都来源于前面所有层在channel维度的concat,以下动图形象表示这一操作。
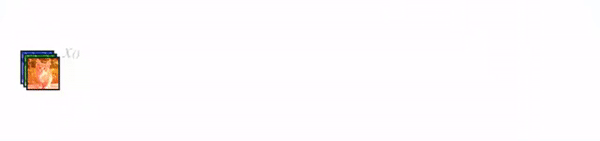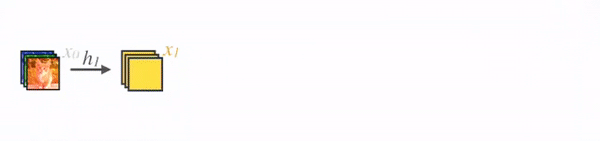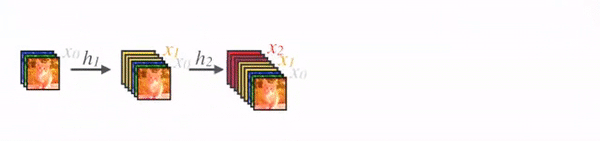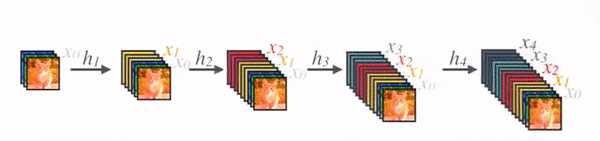
4.1.3 网络结构
网络的具体实现细节如图6所示。
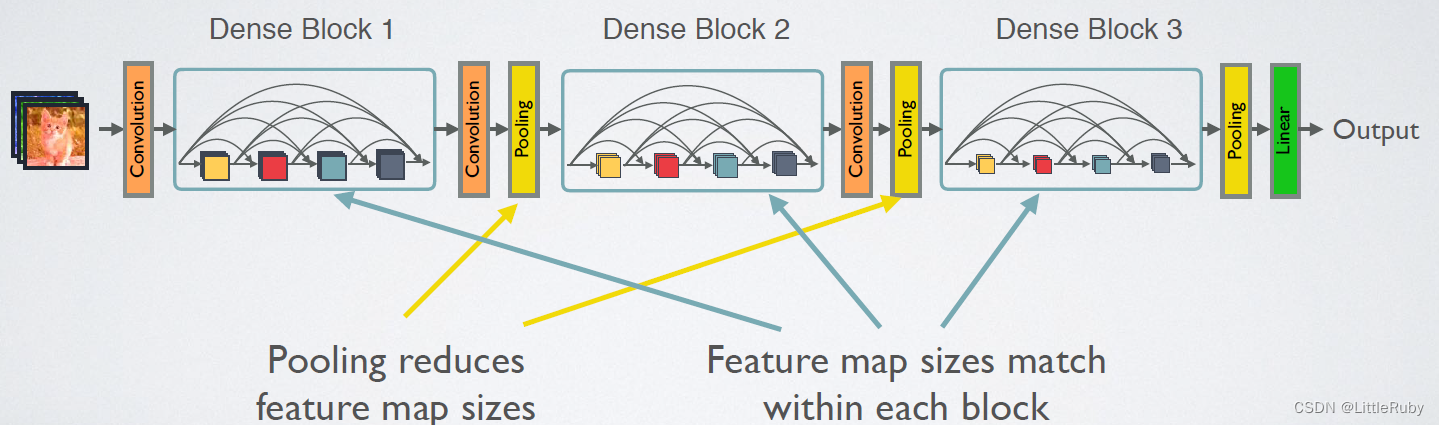
CNN网络一般要经过Pooling或者stride>1的Conv来降低特征图的大小,而DenseNet的密集连接方式需要特征图大小保持一致。为了解决这个问题,DenseNet网络中使用DenseBlock+Transition的结构,其中DenseBlock是包含很多层的模块,每个层的特征图大小相同,层与层之间采用密集连接方式。而Transition层是连接两个相邻的DenseBlock,并且通过Pooling使特征图大小降低。图7给出了DenseNet的网络结构,它共包含4个DenseBlock,各个DenseBlock之间通过Transition层连接在一起。
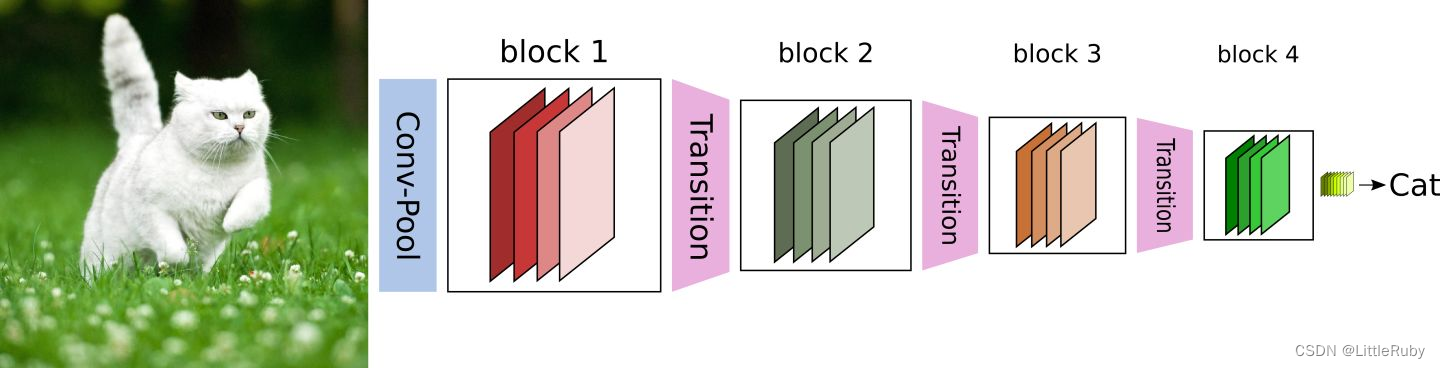
在DenseBlock中,各个层的特征图大小一致,可以在channel维度上连接。DenseBlock中的非线性组合函数 H ( ⋅ ) H(\cdot) H(⋅)的是BN+ReLU+3x3Conv的结构,如图8所示。另外,与ResNet不同,所有DenseBlock中各个层卷积之后均输出k个特征图,即得到的特征图的channel数为k,或者说采用k个卷积核。k在DenseNet称为growth rate,这是一个超参数。一般情况下使用较小的k(比如12),就可以得到较佳的性能。假定输入层的特征图的channel数为 k 0 k_0 k0,那么 l l l层输入的channel数为 k 0 + k ( 1 , 2 , . . . , l − 1 ) k_0+k_{(1,2,...,l-1)} k0+k(1,2,...,l−1),因此随着层数的增加,尽管设定的较小,DenseBlock的输入会非常多,不过这是由于特征重用所造成的,每个层仅有个k特征是自己独有的。

由于后面层的输入会非常大,DenseBlock内部采用bottleneck层来减少计算量,主要是原有的结构中增加1x1Conv,如图9所示,即BN+ReLU+1x1Conv+BN+ReLU+3x3Conv,称为DenseNet-B结构。其中1x1Conv得到4k个特征图,它起到的作用是降低特征数量,从而提升计算效率。
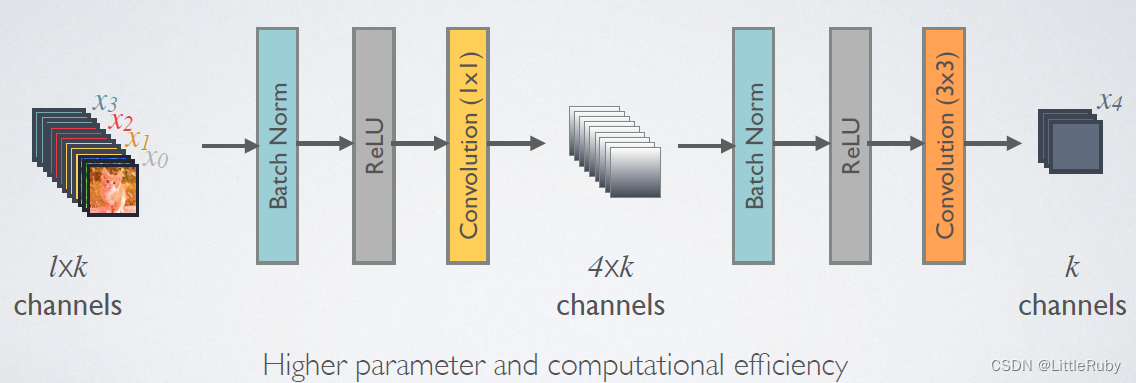
对于Trasition层,它主要是连接两个相邻的DenseBlock,并且降低特征图大小。Transition层包括一个1x1的卷积和2x2的AvgPooling,结构为BN+ReLU+1x1Conv+2x2AvgPooling。另外,Transition层可以起到压缩模型的作用。假定Transition层的上接DenseBlock得到特征图channels数为 m m m,Transition层可以产生个 ⌊ θ m ⌋ \lfloor\theta_m\rfloor ⌊θm⌋特征(通过卷积层),其中 θ ∈ ( 0 , 1 ] \theta\in(0,1] θ∈(0,1]是压缩系数(compression rate)。当 θ < = 1 \theta<=1 θ<=1时,特征个数经过Transition层没有变化,即无压缩,而当压缩系数小于1时,这种结构称为DenseNet-C,文中使用 θ = 0.5 \theta=0.5 θ=0.5。对于使用bootleneck层的DenseBlock结构和压缩系数小于1的Transition组合机构称为DenseNet-BC。
对于ImageNet数据集,图片输入大小为224x224,网络结构采用包含4个DenseBlock的DenseNet-BC,其首先是一个stride=2的7x7卷积层,然后是一个stride=2的3x3MaxPooling层,后面才进入DenseBlock。ImageNet数据集所采用的网络配置如表1所示:
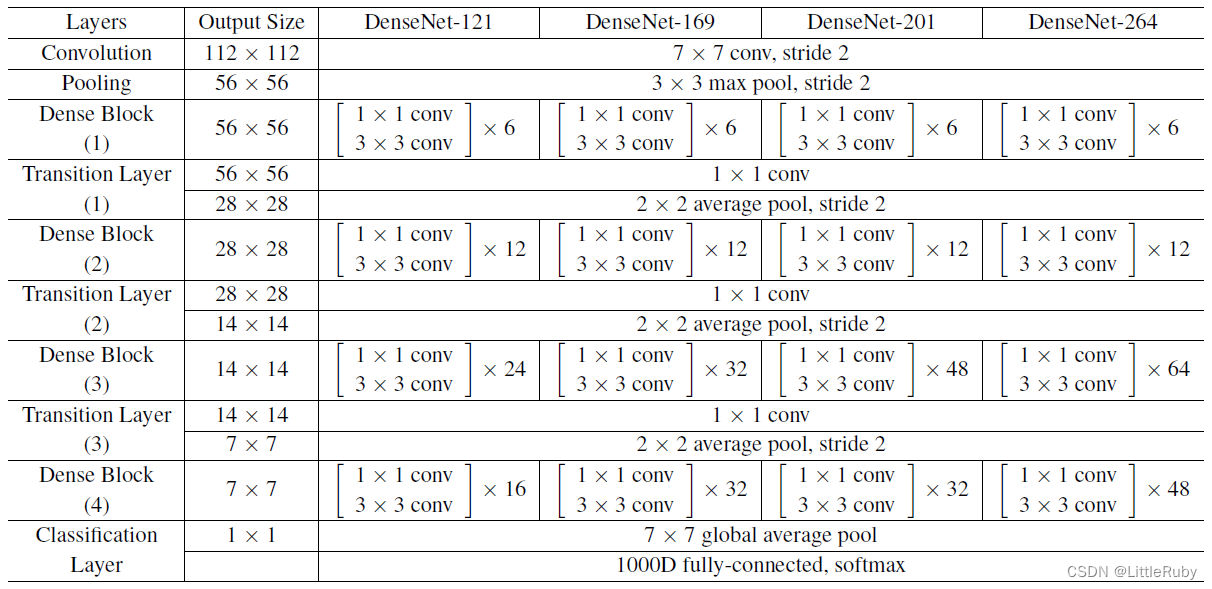
4.1.4 效果对比
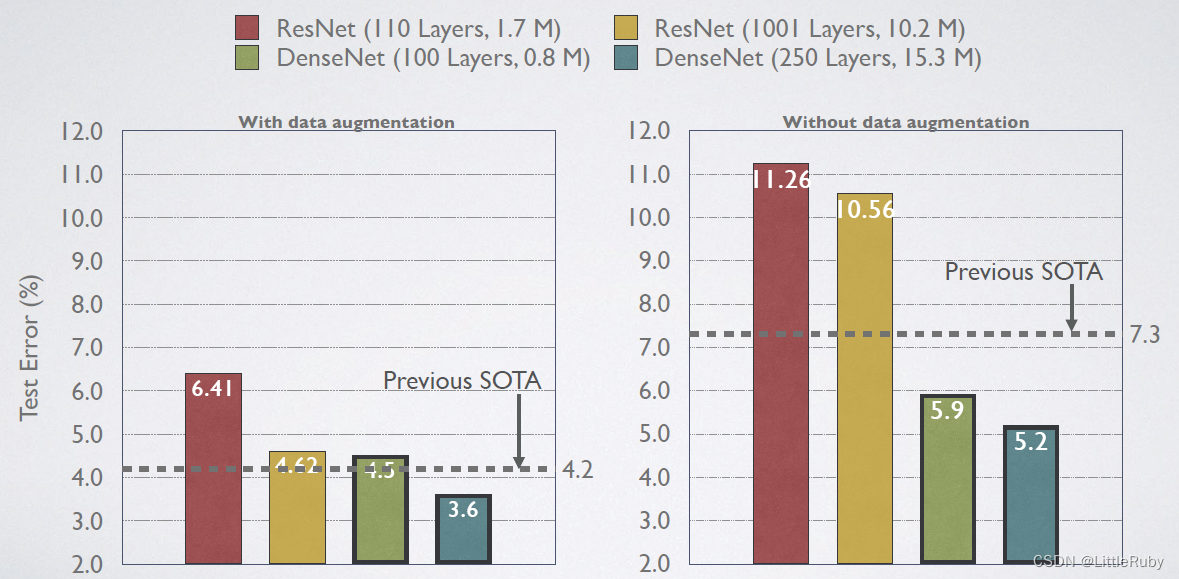
4.1.5 使用Pytroch实现DenseNet121
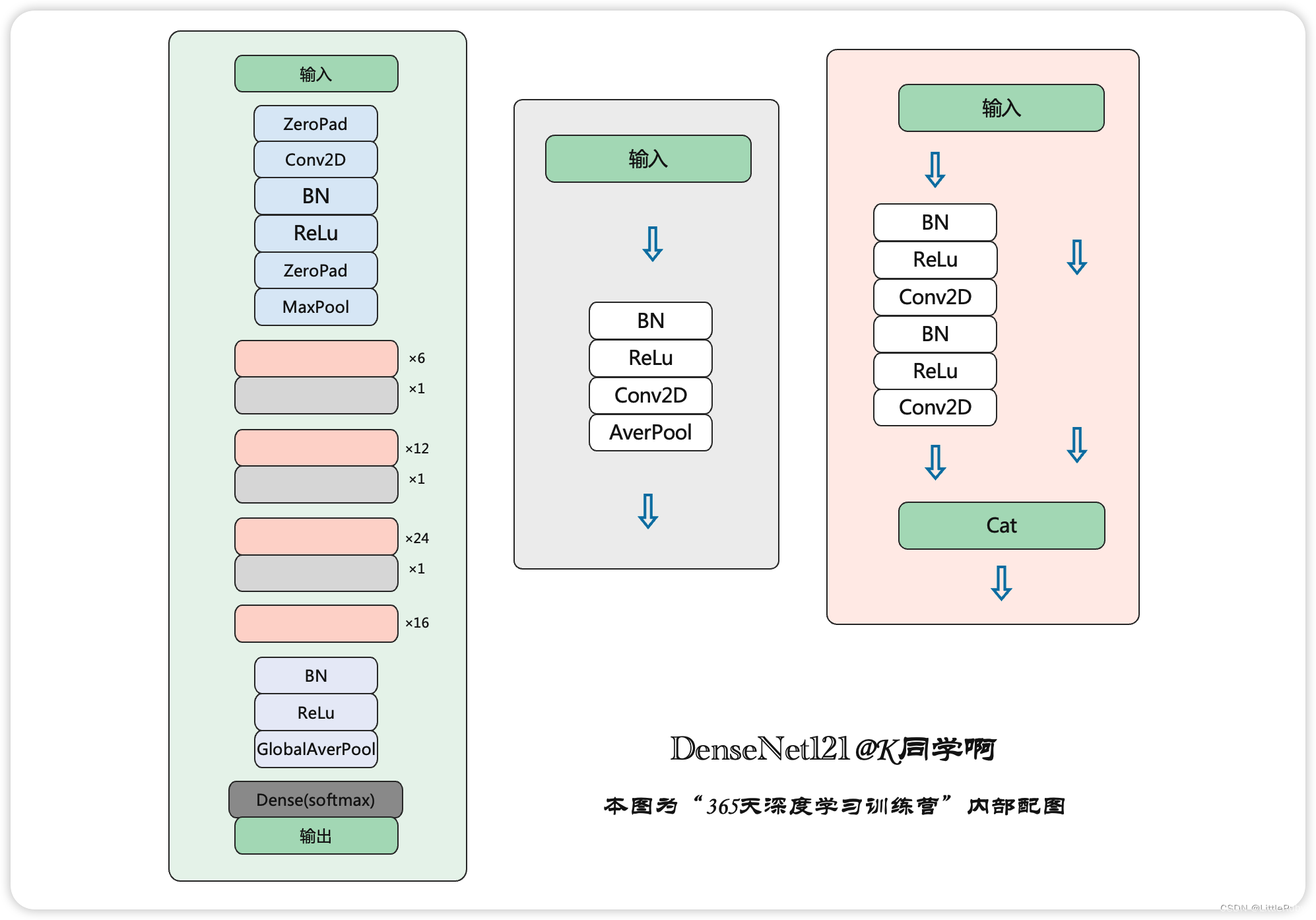
图11为DenseNet121的具体网络结构,它与表1中的DenseNet121相对应。左边是整个DenseNet121的网络结构,其中粉色为DenseBlock,最右侧为其详细结构,灰色为Transition,中间为其详细结构。
这里我们采用Pytorch框架来实现DenseNet,首先实现DenseBlock中的内部结构,这里是BN+ReLU+1x1Conv+BN+ReLU+3x3Conv结构,最后也加入dropout层以用于训练过程。
选择不同网络参数,就可以实现不同深度的DenseNet。
DenseNet121网络结构图

总结
通过本文的学习,分别采用pytorch和tensorflow框架实现desennet算法,发现采用pytorch可以实现很高的识别率,而tenserflow只能达到50%左右,经过查阅相关资料,发现有可能是tensorflow框架中BatchNormalization层有问题,测试数据采用训练数据,发现在屏蔽BatchNormalization层后,测试精度与训练精度差不多,而保留BatchNormalization层,测试精度就很低,可以确定就是BatchNormalization的原因。之前就有看到tensorflow 2.3版本BN层有问题,而tensorflow 1.x则正常。因此在需要使用tensorflow 搭建网络时,尽量选择1.x版本,本人未对该结果进行验证。



![[概率论]四小时不挂猴博士](https://img-blog.csdnimg.cn/direct/7e6584ae35264f999035dc71194491e7.png)