关注 +点赞 不错过精彩内容
大家好,我是硬核王同学,最近在做免费的嵌入式知识分享,帮助对嵌入式感兴趣的同学学习嵌入式、做项目、找工作!
Hello,大家好我是硬核王同学,是一名刚刚工作一年多的Linux工程师,很感谢EEWorld的本次活动,让我有机会参与评测这本和Linux内核相关的的这本书。
在嵌入式系统开发中,大小端字节序问题是必须重视的关键问题之一。这篇文章我们就一起来剖析一下大小端字节序的问题,深入探讨大小端字节序的概念、原因、应用以及如何解决这个问题。
一、什么是字节序?什么是大小端字节序?
(1)什么是字节序?
字节序(Byte Order)指的是在多字节数据存储时,字节的顺序排列方式。它决定了数据在内存中的存储方式和读取方式。字节序分为两种:大端字节序(Big-Endian)和小端字节序(Little-Endian)。
在计算机中,数据是以字节(Byte)为单位进行存储和处理的。而多字节数据,例如整数、浮点数等,由多个字节组成。由于计算机存储器是以字节为基本单位进行寻址的,对于多字节数据的存储,就需要确定各个字节在内存中的存储位置。
(2)什么是大小端字节序?
大小端字节序是指在进行多字节数据存储时,字节的顺序排列方式。具体而言,大小端字节序规定了在内存中数据字节存储的顺序,即哪个字节保存在内存的低地址处,哪个字节保存在内存的高地址处。
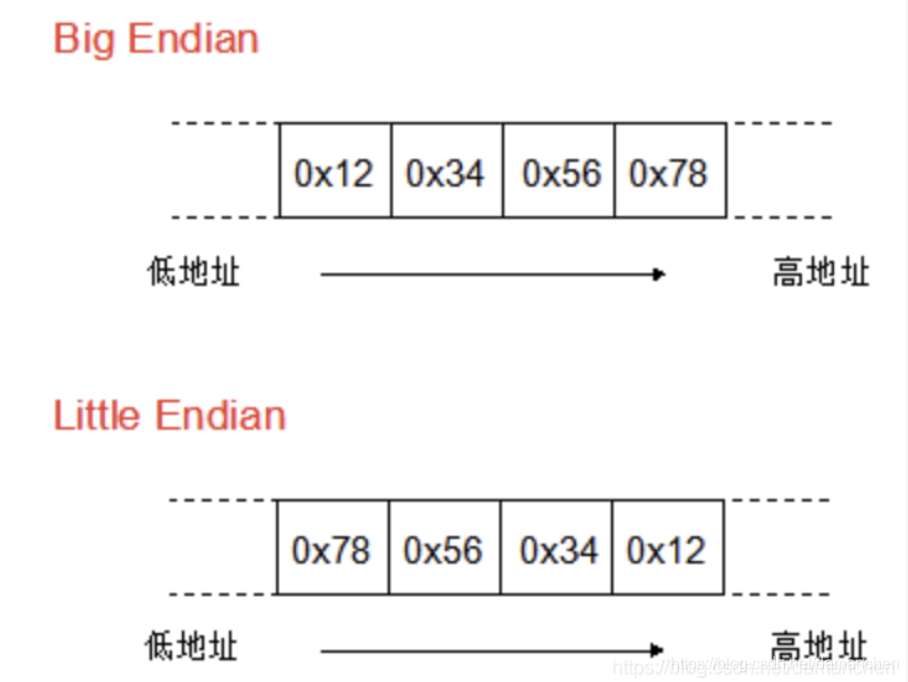
大端字节序要求将多字节数据的高字节保存在内存的低地址处,低字节保存在内存的高地址处。这种排列方式类似于我们阅读数字的方式,先读高位再读低位。例如,16位整数0x1234在大端字节序中存储为0x12(高字节) 0x34(低字节)。
小端字节序则相反,要求将多字节数据的低字节保存在内存的低地址处,高字节保存在内存的高地址处。这种排列方式与大端字节序相反,先读低位再读高位。例如,16位整数0x1234在小端字节序中存储为0x34(低字节) 0x12(高字节)。
需要注意的是,大小端字节序只针对于多字节数据,单字节数据(如字符)在存储时不存在字节序问题,因为它们只占用一个字节。
不同的处理器架构和操作系统可能对字节序的要求不同。因此,在进行数据交互、协议通信或不同平台之间的数据传输时,需要考虑字节序的匹配问题,以确保数据的正确解析和兼容性。
二、大小端字节序的原因
大小端字节序的原因主要有两方面:
- 处理器架构:不同的处理器架构对于字节序的要求是不同的。一些处理器架构采用大端字节序,例如Motorola 68000系列,而另一些处理器架构采用小端字节序,例如x86系列。这是由于处理器在设计时对于字节序的选择有不同的考虑,例如数据的读取和存储方式,指令的解码等。
- 网络协议:在网络通信中,不同的设备和平台之间需要进行数据的交互和传输。为了保证数据的正确解析和传递,网络协议通常要求统一使用一种字节序。因此,协议规定了具体的字节序要求,发送方在发送数据时需要按照协议规定的字节序进行字节的排列,接收方在接收数据时也需要按照相同的字节序进行解析。
总结起来,大小端字节序的原因主要是由于不同的处理器架构和网络通信协议对字节序的不同要求。不同的处理器架构使用不同的字节序,导致数据在不同系统之间的传递和解析可能出现问题。为了保证数据的正确解析和传输,需要统一规定一种字节序,并且在数据的发送和接收过程中进行相应的字节序转换。
三、如何判断处理器是大端模式还是小端模式?
要判断一个处理器是大端模式还是小端模式,可以使用以下两种方法:
- 使用联合体(Union)进行字节序判断:联合体是一种特殊的数据结构,它的所有成员共享同一块内存空间,而且成员的存放顺序是所有成员都从低地址开始存放。所有可以定义一个包含一个整数和一个字节数组的联合体,并将整数初始化为一个已知的值。然后,通过访问字节数组的第一个元素来判断处理器的字节序。如果第一个字节是最高有效字节(高位字节),则表示处理器是大端模式;如果第一个字节是最低有效字节(低位字节),则表示处理器是小端模式。
#include <stdio.h>int isLittleEndian() {union {int i;char c[sizeof(int)];} u;u.i = 1;return u.c[0] == 1; // 返回1表示小端模式,返回0表示大端模式
}int main() {if (isLittleEndian()) {printf("Little endian\n");} else {printf("Big endian\n");}return 0;
}- 使用位操作进行字节序判断:通过创建一个整数值,然后使用位移操作将其划分为不同的字节,然后检查第一个字节的值。如果处理器是小端模式,则第一个字节的值应该最低,如果是大端模式,则第一个字节值应该最高。
#include <stdio.h>int isLittleEndian() {union {int i;char c[sizeof(int)];} u;u.i = 1;return u.c[0] == 1; // 返回1表示小端模式,返回0表示大端模式
}int main() {if (isLittleEndian()) {printf("Little endian\n");} else {printf("Big endian\n");}return 0;
}四、大小端字节序在嵌入式系统中的应用
在嵌入式系统中,大小端字节序的应用主要体现在以下几个方面:
- 数据存储与传输:嵌入式系统中的处理器、存储器和外设通常都具有特定的字节序要求。因此,在嵌入式系统中进行数据存储和传输时,需要根据具体的硬件平台和协议要求来确定使用的字节序。例如,如果使用的处理器采用小端字节序,那么在嵌入式系统中对于数据的读取和存储就需要考虑字节序的转换。
- 网络通信:嵌入式系统中的网络通信常常涉及到与其他设备或系统的数据交互。在进行网络通信时,往往需要使用特定的网络协议,这些协议通常规定了数据的字节序要求。因此,嵌入式系统中的网络通信需要根据协议规定的字节序进行数据的打包和解包,以确保通信的正确性。
- 数据格式和文件系统:嵌入式系统中的数据格式和文件系统也可能涉及到字节序的问题。例如,在使用文件系统读取或写入文件时,需要处理数据的字节序以适应文件系统的要求。此外,一些特定的数据格式,如图像、音频和视频等,也可能对字节序有特定的要求,嵌入式系统需要进行字节序的转换以解析和处理这些数据。
五、如何解决大小端字节序问题
解决大小端字节序问题可以通过以下几种方法:
- 使用特定字节序函数:许多编程语言和操作系统提供了特定字节序转换的函数或库,例如htons、htonl、ntohs、ntohl等。这些函数可以将数据从主机字节序转换为网络字节序(大端字节序)或者反过来,简化了字节序转换的操作。开发者可以根据具体的需求,使用适当的函数来进行字节序的转换。
- 手动转换字节序:如果没有特定字节序函数可用,开发者可以手动实现字节序的转换。对于32位整数,可以按照字节的反序排列。例如,将4个字节按照从低到高的顺序依次存放在一个字符数组中,然后再读取时按照从高到低的顺序组合成32位整数。需要注意的是,手动转换字节序的方法要求开发者对字节操作有一定的了解,同时也需要注意处理边界条件和错误处理。
- 使用统一的字节序:为了避免字节序的问题,有些嵌入式系统和协议规定了统一的字节序,例如网络协议中规定的大端字节序。在这种情况下,开发者只需要确保数据按照规定字节序进行传输和解析,无需进行额外的字节序转换。
需要根据具体的应用场景和需求选择适用的解决方法。在进行字节序转换时,要注意数据的正确性和性能的影响。同时,还需要考虑对齐和数据结构的内存布局等因素,以避免潜在的问题。
六、如何选择合适的字节序
选择合适的字节序取决于以下几个因素:
- 硬件平台要求:首先需要根据使用的处理器和其他相关硬件平台的字节序要求来选择合适的字节序。大多数嵌入式处理器使用的是小端字节序,但也有一些处理器使用大端字节序或可配置字节序。根据硬件平台的要求,确保使用的字节序与硬件平台兼容。
- 协议规范:如果嵌入式系统与其他设备或系统进行数据交互,需要根据相应的协议规范来选择合适的字节序。一些网络协议规定了使用大端字节序,如TCP/IP协议,因此在进行网络通信时需要使用大端字节序。在选择字节序时,要仔细阅读相关协议文档,确保遵守协议的字节序要求。
- 数据格式要求:对于特定的数据格式,如图像、音频和视频等,可能有特定的字节序要求。开发者需要了解所使用的数据格式的字节序要求,并相应地选择合适的字节序。
- 开发者经验和习惯:开发者在选择字节序时,可以根据自己的经验和习惯进行选择。如果开发者对某种字节序比较熟悉,或者已经使用过相关的函数和库来处理字节序,那么可以选择与之兼容的字节序。
需要注意的是,选择字节序时要保持一致性。在一个系统中,应尽可能统一使用相同的字节序,以确保数据在不同组件之间的传输和解析的正确性。同时,在处理多字节数据时,要注意对齐和字节序的影响,以避免潜在的问题。
结语:
在嵌入式系统中,处理不同字节序的数据是一个常见的问题。为了正确地处理字节序问题,开发者可以选择使用特定字节序函数、手动转换字节序或遵守统一的字节序规范。选择合适的字节序取决于硬件平台要求、协议规范、数据格式要求以及开发者的经验和习惯。在选择字节序时,要保持一致性,并注意对齐和字节序的影响。通过正确处理字节序问题,可以确保数据的正确性和系统的稳定性。
如果觉得有用请点个免费的赞,您的支持就是我最大的动力,这对我很重要!!!
作 者 :硬核王同学
----- END -----
关注公众号回复“加群”按规则加入技术交流群
回复“1024”查看更多内容