在进行大数据分析或者开发的时候,难免用到Hive进行数据查询分析,Hive内置很多函数,但是会有一部分需求需要自己开发,这个时候就需要自定义函数了,Hive的自定义函数开发非常方便,今天首先讲一下UDF的入门开发。
UDF开发
简单实现将字符串小写化的功能。
环境版本
- Hive 3.1.0.X
- JDK 8
- Maven 3.8.1
开发步骤
首先Maven创建
引入Jar包
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"><modelVersion>4.0.0</modelVersion><groupId>com.hive.tutorial</groupId><artifactId>low-str</artifactId><version>1.0.0</version><packaging>jar</packaging><properties><maven.compiler.source>8</maven.compiler.source><maven.compiler.target>8</maven.compiler.target></properties><dependencies><dependency><groupId>org.apache.hive</groupId><artifactId>hive-exec</artifactId><version>3.1.0</version></dependency><dependency><groupId>org.apache.hadoop</groupId><artifactId>hadoop-common</artifactId><version>3.1.0</version></dependency></dependencies>
</project>
编写UDF函数
package com.hive.tutorial.udf;import org.apache.hadoop.hive.ql.exec.UDFArgumentException;
import org.apache.hadoop.hive.ql.metadata.HiveException;
import org.apache.hadoop.hive.ql.udf.generic.GenericUDF;
import org.apache.hadoop.hive.serde2.objectinspector.ObjectInspector;
import org.apache.hadoop.hive.serde2.objectinspector.primitive.PrimitiveObjectInspectorFactory;
import org.apache.hadoop.hive.serde2.objectinspector.primitive.StringObjectInspector;
import org.apache.hadoop.io.Text;/*** @author panlf* @date 2024/1/3*/
public class LowStr extends GenericUDF {StringObjectInspector stringObjectInspector;@Overridepublic ObjectInspector initialize(ObjectInspector[] arguments) throws UDFArgumentException {if(arguments == null || arguments.length != 1){throw new UDFArgumentException("该方法只接受一个参数");}ObjectInspector a = arguments[0];if (!(a instanceof StringObjectInspector)) {throw new UDFArgumentException("该方法的参数必须是字符串");}//检查通过后,将参数赋值给成员变量ObjectInspector,为了在evaluate()中使用this.stringObjectInspector = (StringObjectInspector) a;//用工厂类生成用于表示返回值的ObjectInspectorreturn PrimitiveObjectInspectorFactory.javaStringObjectInspector;}@Overridepublic Object evaluate(DeferredObject[] arguments) throws HiveException {String v = stringObjectInspector.getPrimitiveJavaObject(arguments[0].get());return new Text(v.toLowerCase());}@Overridepublic String getDisplayString(String[] children) {return "将输入的字符串小写化";}
}
注意很多网上资料其实是继承UDF这个类的,但是这个类已过时了,建议使用GenericUDF 。
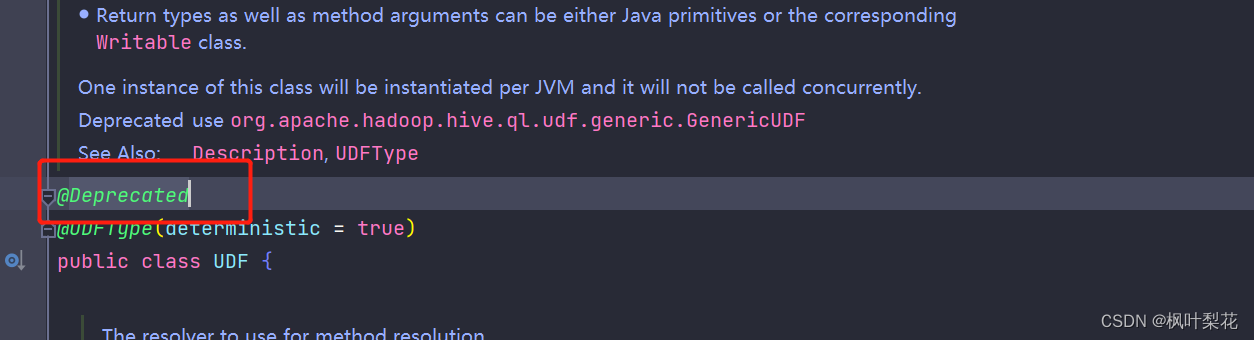
GenericUDF和UDF都是Hive中的用户自定义函数,但两者在处理数据类型和灵活性上有所不同。基础的UDF接口适合于简单的数据类型,如文本、整数等,而复杂的GenericUDF则可以处理更复杂的数据类型,包括Map、List和Set。
具体来说,以下是GenericUDF相对于UDF的优势:
- 处理复杂数据类型:GenericUDF不仅可以处理Hadoop和Hive的基本类型,如Text、IntWritable、LongWritable、DoubleWritable等,还可以处理复杂的数据结构,如Array、Map、Struct等。
- 灵活性:相比于UDF,GenericUDF提供了更多的灵活性。例如,它可以在函数开始之前和结束之后执行一些初始化和清理操作。此外,GenericUDF允许用户重载evaluate()方法,使其具有更强的功能。
因此,当您需要处理的数据类型比较复杂或需要进行一些特定的初始化和清理操作时,建议使用GenericUDF而不是UDF。
打包
mvn clean package
部署到Hive
Jar上传至服务器
首先将Jar传到服务器,我是传到服务器的/data/temp_data/文件夹下
HDFS将Jar传入到Hadoop
通过HDFS命令将Jar包传到Hadoop上
> hdfs dfs -put /data/temp_data/low-str-1.0.0.jar /hivejar/hiveudf
Hive客户端操作,添加Jar包
运行Hive cli,进入Hive客户端
运行以下命令
hive > add jar hdfs://172.23.39.9:8020/hivejar/hiveudf/low-str-1.0.0.jar;

建函数
临时函数
create temporary function low_str as 'com.hive.tutorial.udf.LowStr';
然后即可使用
select low_str('AAAA');
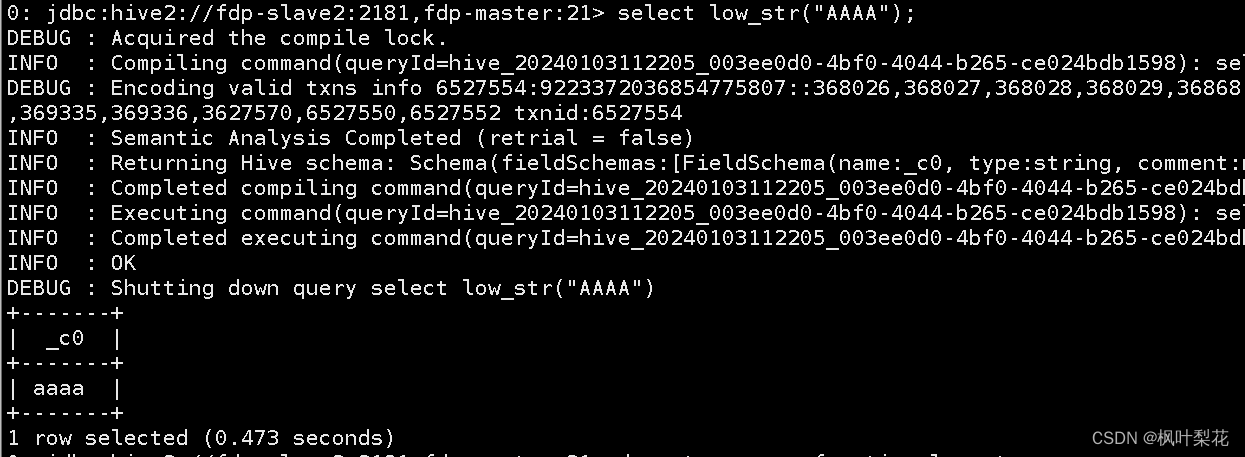
注意
Hive的UDF临时函数在会话结束时失效
永久函数
create function sys.low_str as 'com.hive.tutorial.udf.LowStr' using jar 'hdfs://172.23.39.9:8020/hivejar/hiveudf/low-str-1.0.0.jar';
注意sys.low_str 中的sys代表的是库名,如果没有指定的话,默认是default
销毁函数
drop function low_str;
查看函数
//查看全部函数
show functions;### 查看某个函数
describe function low_str;
Java中使用永久函数
我在Java的程序中调用该永久函数,发生以下错误,就是无法识别出注册的函数。
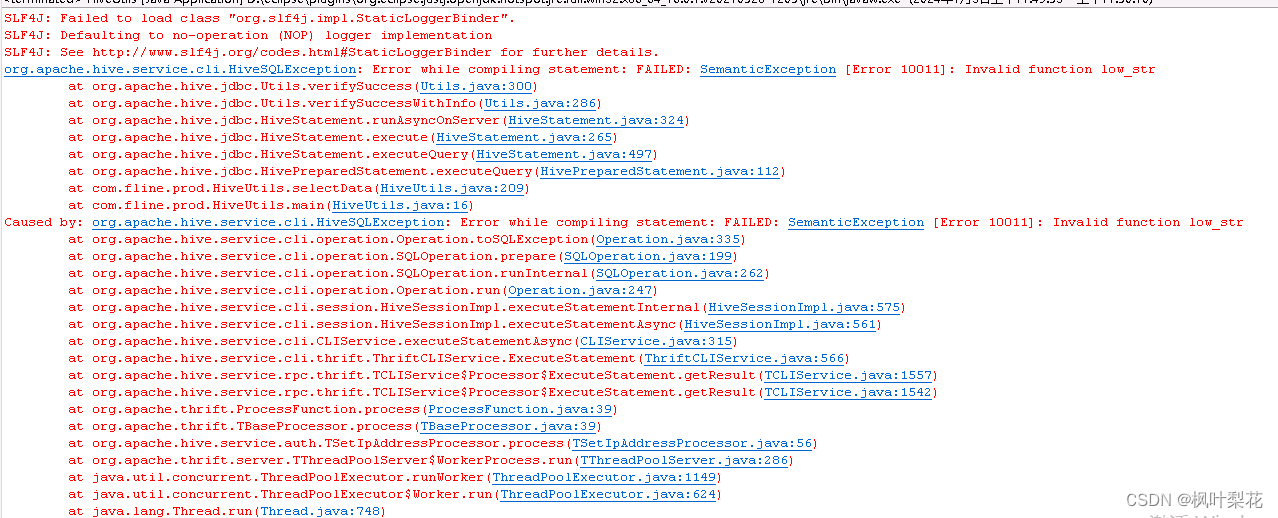
我通过查资料发现以下方法可解决(包括且不限于)
- 调用函数的时候,是否带上了库名(我第一次建立在default下面,我在Hive客户端是不带default就能直接使用函数,所以我以为Java程序中也能直接写,但是测试发现Java程序中需要使用
default.low_str) - 使用
RELOAD FUNCTIONS,重刷FUNCTIONS信息 - 重启Hive
。。。。