文章目录
- 1、什么是布隆过滤器?
- 1.1 工作原理
- 1.2 布隆过滤器的优点
- 1.3 缺点
- 2、布隆过滤器的使用场景
- 3、布隆过滤器的原理
- 3.1 布隆过滤器的数据结构
- 3.2 初始化阶
- 3.3 插入元素过程
- 3.4 查询元素是否存在
- 3.5 元素删除
- 3.6 扩容
- 4、SpringBoot 整合 布隆过滤器
- 4.1 技术选型
- 4.2 依赖
- 4.3 配置布隆过滤器相关参数
- 4.4 布隆过滤器工具类
- 4.5 业务操作
- 4.5.1 基于JVM本地缓存的 BloomFilter
- 4.5.2 基于Redis的 RBloomFilter
- 4.6 布隆过滤器测试控制层
- 5、测试
- 5.1 项目启动,初始化布隆过滤器
- 5.2 测试数据是否存在
- 5.3 触发扩容
1、什么是布隆过滤器?
布隆过滤器(Bloom Filter)是一种空间效率极高的概率型数据结构,由 Burton Howard Bloom 在1970年提出。它主要用于判断一个元素是否可能属于某个集合,而不支持直接获取集合中的所有元素。
布隆过滤器的基本结构是一个固定长度的位数组和一组哈希函数。
1.1 工作原理
- 初始化时,位数组的所有位都被设置为0。
- 当要插入一个元素时,使用预先设定好的多个独立、均匀分布的哈希函数对元素进行哈希运算,每个哈希函数都会计算出一个位数组的索引位置。
- 将通过哈希运算得到的每个索引位置的位设置为1。
- 查询一个元素是否存在时,同样用相同的哈希函数对该元素进行运算,并检查对应位数组的位置是否都是1。如果所有位都为1,则认为该元素可能存在于集合中;如果有任何一个位为0,则可以确定该元素肯定不在集合中。
- 由于哈希碰撞的存在,当多位同时为1时,可能出现误报(False Positive),即报告元素可能在集合中,但实际上并未被插入过。但布隆过滤器不会出现漏报(False Negative),即如果布隆过滤器说元素不在集合中,则这个结论是绝对正确的。
1.2 布隆过滤器的优点
- 空间效率高:相比于精确存储所有元素的数据结构,布隆过滤器所需的内存空间小得多。
- 查询速度快:只需要执行几个哈希函数并检查位数组即可完成查询。

如何判断这个数据的真实性?很简单,你在设置好参数初始化布隆过滤器时,它会初始化一个位数组,这个容量是固定的且一次性申请对应容量的内存。
经过实际测试,基本与上述网站评估一致。另外和大家说个小 Tips,Redisson 布隆过滤器在 Redis 中是以字符串方式存储的,底层数据结构是 Redis 中的 BitSet(位图)。

1.3 缺点
- 不可删除:标准布隆过滤器不支持元素的删除操作,因为无法得知哪些位仅是因为当前查询的元素而置1的。
- 误报率:随着元素数量增加,误报率也会逐渐升高,但是可以通过调整位数组大小和哈希函数数量来控制误报率。
布隆过滤器广泛应用在数据库系统、网络爬虫去重、缓存穿透防护等场景中,尤其适合那些能容忍一定误判率的应用。
2、布隆过滤器的使用场景
布隆过滤器因其高效的空间占用和快速查询能力,在许多大规模数据处理和高性能系统中得到广泛应用,以下是一些典型的使用场景:
-
缓存穿透防护:
- 在分布式缓存系统如Redis或Memcached中,用于避免缓存穿透问题。当一个请求试图访问数据库中的某个不存在的键时,如果直接去数据库查询会增加数据库压力。通过在前端部署一个布隆过滤器,可以预先判断该键很可能不存在于数据库中,从而避免对数据库发起无效请求。
-
重复数据检测:
- 在爬虫抓取网页或者日志分析中,用于URL去重,确保不会重复抓取相同的页面或记录。
- 在大数据处理中,比如在Hadoop等框架中,用来过滤掉重复的数据块或者记录,减少计算和存储负担。
-
垃圾邮件过滤:
- 用于电子邮件系统的垃圾邮件地址库,快速判断收到的邮件是否可能来自已知的垃圾邮件发送者。
-
实时监控与报警系统:
- 当大量事件流经系统时,可以用于快速识别并过滤出已知异常事件,降低报警系统误报率。
-
推荐系统:
- 在个性化推荐系统中,用于快速排除用户已经浏览过或者不感兴趣的内容。
-
数据库索引优化:
- 对于大型数据库,可以利用布隆过滤器作为辅助索引结构,提前过滤掉大部分肯定不在结果集中的查询条件,减轻主索引的压力。
-
社交网络和互联网服务:
- 在社交网络中,用于快速检测用户上传的内容是否存在违规信息,或是检查用户ID、账号是否存在黑名单中。
-
数据分析与挖掘:
- 在大规模数据清洗阶段,用来剔除重复样本或无效数据。
-
网络安全:
- 网络防火墙和入侵检测系统中,用于过滤已知恶意IP或攻击特征。
总之,任何需要在高吞吐量下以一定的错误容忍度进行元素存在性检测且内存资源有限的场景,都可以考虑使用布隆过滤器。
3、布隆过滤器的原理
布隆过滤器(Bloom Filter)是一种空间效率极高的概率型数据结构,主要用于判断一个元素是否可能属于某个集合。它的基本原理是利用位数组(Bitmap)和一组哈希函数来实现快速且近似的存在性查询。
3.1 布隆过滤器的数据结构
布隆过滤器(Bloom Filter)的数据结构主要由一个固定长度的位数组(Bit Array)和一组哈希函数(Hash Functions)组成。

位数组:
- 这是一个很长的二进制向量,所有位初始化为0。它的长度(m)是在创建布隆过滤器时根据预期要插入的元素数量、期望的错误率以及所使用的哈希函数数量计算得出的。
哈希函数组:
- 布隆过滤器通常使用k个独立且均匀分布的哈希函数。每个函数都能将输入元素映射到位数组的一个索引上。
- 当插入一个元素时,通过这k个哈希函数分别计算出该元素对应的k个不同的位数组索引,并将这些位置上的位设置为1。
- 查询时,同样应用这k个哈希函数来确定查询元素可能所在的位数组中的位置,如果所有这些位置上的位都是1,则认为该元素可能存在(存在误报的概率),若至少有一位是0,则可以确定该元素不在集合中。
因此,布隆过滤器的核心数据结构其实相当简单,但其巧妙之处在于利用多个哈希函数对数据进行分散存储,并通过牺牲绝对精确性换取了空间效率和查询速度的优势。
3.2 初始化阶
- 创建一个固定长度的二进制向量,所有位都被初始化为0。
- 选择k个不同的哈希函数,每个哈希函数都能将输入的元素映射到位数组的一个索引位置上。
3.3 插入元素过程
- 当需要将一个元素添加到布隆过滤器中时,使用这k个哈希函数分别计算出这个元素对应的k个位数组的索引。
- 将这些索引位置上的位都设置为1。
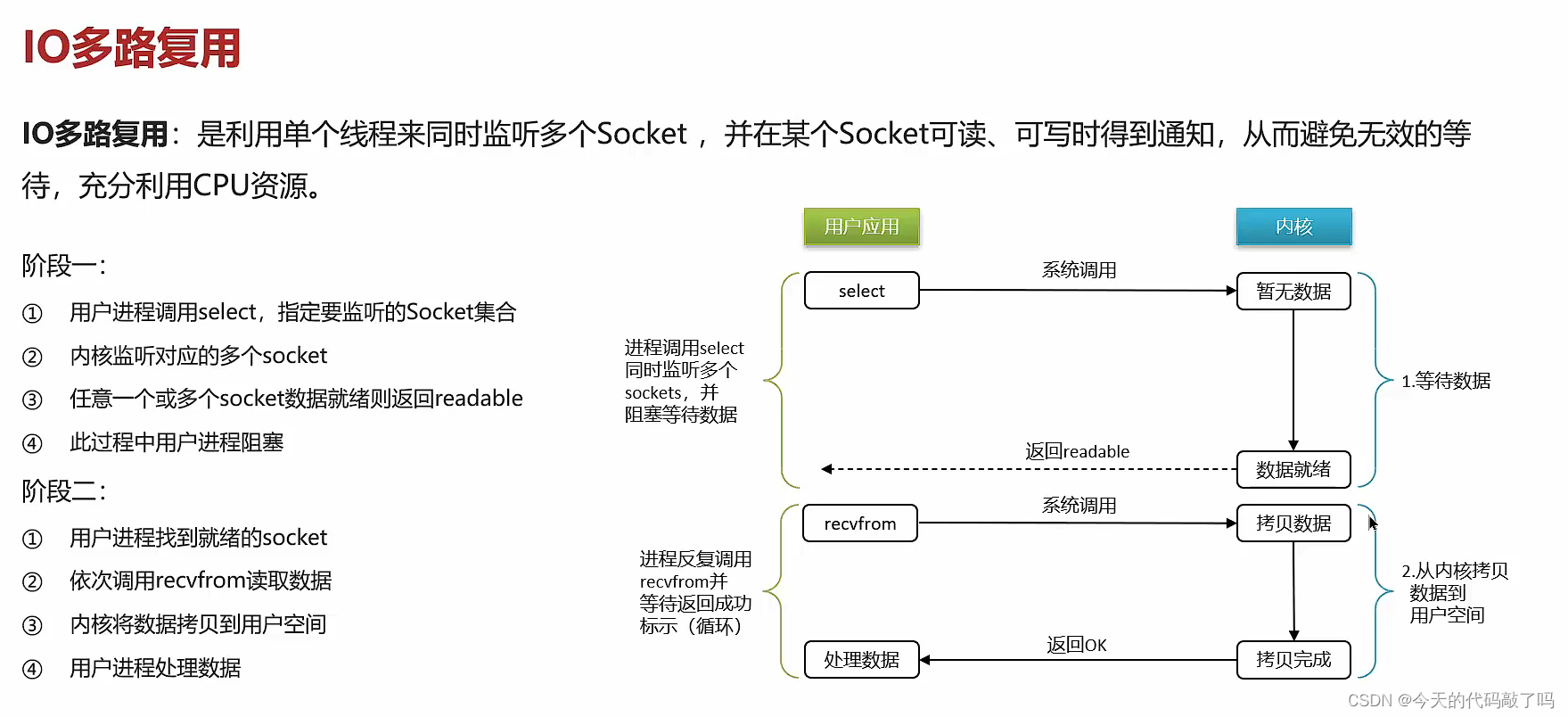
例如,key = Liziba,无偏hash函数的个数k=3,分别为hash1、hash2、hash3。三个hash函数计算后得到三个数组下标值,并将其值修改为1.

3.4 查询元素是否存在
- 对于查询操作,同样使用这k个哈希函数对目标元素进行哈希运算,得到相应的k个位数组索引。
- 检查这些索引位置上的位是否全为1。
- 如果有任何一个位置为0,则可以确定该元素一定不在集合中(零错误率)。
- 如果所有位置都是1,则认为该元素可能存在在集合中(存在误报的概率,即False Positive)。
例如我们查询 “cunzai” 这个值是否存在,哈希函数返回了 1、5、8三个值

由于哈希碰撞的存在,在实际应用中,随着更多元素被插入,相同哈希值对应的位会被多次置1,这就导致原本未出现过的元素经过哈希运算后也可能指向已经置1的位置,从而产生误报。不过,通过调整位数组大小、哈希函数的数量以及负载因子等参数,可以在误报率和存储空间之间取得平衡。
总之,布隆过滤器提供了一种空间效率极高但牺牲了精确性的解决方案,特别适合用于那些能够容忍一定误报率的大规模数据处理场景。
3.5 元素删除
在标准的布隆过滤器(Bloom Filter)实现中,包括基于Java实现的RBloomFilter或其他变体,元素一旦被添加到布隆过滤器中,是不能被精确删除的。这是因为布隆过滤器的设计原理决定了它是一种空间效率极高的概率型数据结构,用来测试一个元素是否“可能”存在于集合中。当向布隆过滤器插入元素时,会使用多个哈希函数将元素映射到位数组的特定位置上置1。由于位数组中没有关联元素值的信息,所以无法通过逆操作来还原或清除单个元素。
因此,在Java或者其他任何编程语言中的布隆过滤器实现,通常不会提供直接删除元素的方法。如果你需要支持删除操作,可能需要考虑其他的数据结构,比如计数布隆过滤器(Counting Bloom Filter)或者可逆/可更新布隆过滤器的变种,它们能够在一定程度上支持删除,但仍然存在一定的限制和复杂性,并且误报率可能会随着删除操作增加而提高。
对于RBloomFilter这个具体的类名,如果它是一个自定义实现并且确实提供了删除功能,则需要查阅该类库的具体文档或源代码以了解其如何处理删除操作。但在大多数标准布隆过滤器场景下,删除操作是不适用的。
3.6 扩容
布隆过滤器(Bloom Filter)在设计时,其容量是固定的,因此不支持直接扩容。传统的布隆过滤器一旦创建,它的位数组大小就无法改变,这意味着如果需要处理的数据量超过了初始化时预设的容量,将导致误报率增加,且无法通过简单地增大位数组来解决这个问题。
不过,在实际应用中,为了应对数据增长的需求,可以采用以下策略来进行扩容:
-
并行布隆过滤器:
- 可以维护多个独立的布隆过滤器,随着数据增长,当一个过滤器填满后,新加入的数据放入新的布隆过滤器中。
- 查询时,需要对所有布隆过滤器进行查询,只有当所有的过滤器都表明元素可能不存在时,才能确定元素肯定不在集合中。
-
可扩展布隆过滤器:
- 一些变种如 Scalable Bloom Filter 或 Dynamic Bloom Filter 允许添加额外的空间,并重新哈希已有数据到更大的位数组中,从而维持较低的误报率。
- 扩容过程通常涉及构造一个新的更大容量的布隆过滤器,然后迁移旧数据到新过滤器,并从这一刻起在新过滤器中插入新数据。
-
层次结构布隆过滤器:
- 创建一个多层的布隆过滤器结构,新数据首先被插入到最顶层(最小容量)的过滤器中,当某个层级的过滤器接近饱和时,再启用下一个容量更大的过滤器。
无论采用哪种方式扩容,都需要权衡空间效率、查询性能和错误率之间的关系,并考虑如何处理现有数据的迁移问题。同时,扩容操作往往意味着更高的复杂性和一定的成本开销。
4、SpringBoot 整合 布隆过滤器
4.1 技术选型
- JDK 17
- SpringBoot 3.0.0
- Redis 3.2.100
4.2 依赖
<!--spring-boot-web--><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-web</artifactId><version>3.0.0</version></dependency><!--lombok--><dependency><groupId>org.projectlombok</groupId><artifactId>lombok</artifactId><version>1.18.26</version><optional>true</optional></dependency><!--spring-boot-test--><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-test</artifactId><version>3.0.0</version><scope>test</scope></dependency><!-- redis-starter --><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-data-redis</artifactId><version>3.0.0</version></dependency><!-- redis --><dependency><groupId>org.springframework.data</groupId><artifactId>spring-data-redis</artifactId><version>3.0.0</version></dependency><!-- 引入Redisson的Spring Boot启动器 --><dependency><groupId>org.redisson</groupId><artifactId>redisson-spring-boot-starter</artifactId><version>3.21.3</version></dependency>
4.3 配置布隆过滤器相关参数
bloomFilter:# 是否启用布隆过滤器bloomFilterFlag: true# 布隆过滤器的初始大小MIN_EXPECTED_INSERTIONS: 8# 布隆过滤器的错误率bloomFilterErrorRate: 0.01# 布隆过滤器的最大使用率maximumUtilization: 0.90# 布隆过滤器的最小使用率minimumUtilization: 0.40# 布隆过滤器的初始序列号RBloomFilterSequence: 1
4.4 布隆过滤器工具类
定义了一个名为BloomFilterUtil的Java类,该类用于管理布隆过滤器。类中使用了注解、依赖注入和定时任务等特性。类中的方法包括初始化本地缓存的布隆过滤器、初始化基于Redis的布隆过滤器、获取布隆过滤器、定时动态扩容布隆过滤器等。
import com.example.demo.config.redis.RedisKeyEnum;
import com.google.common.hash.BloomFilter;
import com.google.common.hash.Funnels;
import jakarta.annotation.PostConstruct;
import jakarta.annotation.Resource;
import lombok.extern.slf4j.Slf4j;
import org.redisson.api.RBloomFilter;
import org.redisson.api.RedissonClient;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.scheduling.annotation.Scheduled;
import org.springframework.stereotype.Component;import java.nio.charset.Charset;
import java.util.Arrays;
import java.util.List;/*** BloomFilterConfig : 布隆过滤器配置文件** @author zyw* @create 2024-01-10 14:43*/@Slf4j
@Component
public class BloomFilterUtil {// 布隆过滤器的初始大小@Value("${bloomFilter.MIN_EXPECTED_INSERTIONS}")private int MIN_EXPECTED_INSERTIONS;//预期插入数据量private int EXPECTED_INSERTIONS;//布隆过滤器的错误率@Value("${bloomFilter.bloomFilterErrorRate}")private double FPP;//布隆过滤器的最大使用率@Value("${bloomFilter.maximumUtilization}")private double maximumUtilization;//布隆过滤器的最小使用率@Value("${bloomFilter.minimumUtilization}")private double minimumUtilization;// 布隆过滤器的初始序列号@Value("${bloomFilter.RBloomFilterSequence}")public int RBloomFilterSequence;// 布隆过滤器的容量自适应定时任务频率private static final String CRON_EXPANSION = "0 0/5 * * * ?";public BloomFilter<String> bloomFilter;public RBloomFilter<String> rBloomFilter;@Resourceprivate RedissonClient redissonClient;/*** 初始化基于JVM本地缓存构建布隆过滤器*/@PostConstructpublic void builBloomFilter() {EXPECTED_INSERTIONS = MIN_EXPECTED_INSERTIONS;// 创建并返回BloomFilter对象bloomFilter = BloomFilter.create(Funnels.stringFunnel(Charset.forName("UTF-8")), EXPECTED_INSERTIONS, FPP);}/*** 初始化基于Redis防止数据库查询的布隆过滤器** @return RBloomFilter<String> 布隆过滤器*/@PostConstructpublic void buidUserRegisterCachePenetrationBloomFilter() {EXPECTED_INSERTIONS = MIN_EXPECTED_INSERTIONS;RBloomFilter<String> cachePenetrationBloomFilter = getRBloomFilter();cachePenetrationBloomFilter.tryInit(EXPECTED_INSERTIONS, FPP);initRBloomFilter(cachePenetrationBloomFilter);rBloomFilter = cachePenetrationBloomFilter;}/*** 布隆过滤器初始化*/private void initRBloomFilter(RBloomFilter<String> cachePenetrationBloomFilter) {List<String> names = Arrays.asList("黄袁哲", "杨清涵", "陈国宇", "李康", "舒适玉", "王昊", "王浩然");names.parallelStream().forEach(cachePenetrationBloomFilter::add);}/*** 获取布隆过滤器*/public RBloomFilter<String> getRBloomFilter() {try {RBloomFilter<String> bloomFilter;//布隆过滤器序号判断if (RBloomFilterSequence == 1) {bloomFilter = redissonClient.getBloomFilter(RedisKeyEnum.USER_REGISTER_CACHE_PENETRATION_BLOOM_FILTER_1.getKey());} else {bloomFilter = redissonClient.getBloomFilter(RedisKeyEnum.USER_REGISTER_CACHE_PENETRATION_BLOOM_FILTER_2.getKey());}if (bloomFilter == null) {throw new IllegalStateException("布隆过滤器不存在于Redis中");}return bloomFilter;} catch (Exception e) {log.error("从Redis获取布隆过滤器失败", e);throw new IllegalStateException("从Redis获取布隆过滤器失败", e);}}/*** 定时动态扩容任务配置*/@Scheduled(cron = CRON_EXPANSION)public void dilatation() {// 获取当前布隆过滤器实例RBloomFilter<String> cachePenetrationBloomFilter = getRBloomFilter();// 计算当前装载因子long count = cachePenetrationBloomFilter.count();double loadFactor = (double) count / EXPECTED_INSERTIONS;// 检查是否需要扩容if (loadFactor > maximumUtilization) {log.info("布隆过滤器开始进行扩容", "插入元素数", count, "期望插入元素数", EXPECTED_INSERTIONS);// 将期望插入元素数翻倍EXPECTED_INSERTIONS *= 2;try {// 更新布隆过滤器序列号RBloomFilterSequence = RBloomFilterSequence == 1 ? 2 : 1;//获取新布隆过滤器实例RBloomFilter<String> newRBloomFilter = getRBloomFilter();// 尝试使用新的期望插入元素数初始化布隆过滤器newRBloomFilter.tryInit(EXPECTED_INSERTIONS, FPP);//数据初始化initRBloomFilter(newRBloomFilter);//切换成新布隆过滤器rBloomFilter = newRBloomFilter;//清除旧的缓存数据cachePenetrationBloomFilter.delete();log.info("当前布隆过滤器序号:" + RBloomFilterSequence);} catch (Exception e) {log.error("布隆过滤器初始化过程中出现异常", e);}log.info("布隆过滤器完成扩容,新容量为:" + EXPECTED_INSERTIONS);} else {log.info("当前布隆过滤器未达到扩容/缩容条件");}}
}
4.5 业务操作
4.5.1 基于JVM本地缓存的 BloomFilter
import com.example.demo.config.filter.BloomFilterUtil;
import jakarta.annotation.Resource;
import org.springframework.stereotype.Service;/*** BloomFilter :** @author zyw* @create 2024-01-10 14:47*/@Service
public class BloomFilterService {/*** 私有的不可变的BloomFilter对象*/@Resourceprivate BloomFilterUtil bloomFilterUtil;/*** 向BloomFilter中添加元素* @param element*/public void add(String element) {bloomFilterUtil.bloomFilter.put(element);}/*** 检查BloomFilter中是否存在元素* @param element* @return*/public String check(String element) {// 如果BloomFilter判断元素可能存在if (bloomFilterUtil.bloomFilter.mightContain(element)) {return element + " 可能存在于集合中";} else {return element + " 不可能存在于集合中";}}}
4.5.2 基于Redis的 RBloomFilter
import com.example.demo.config.filter.BloomFilterUtil;
import jakarta.annotation.Resource;
import lombok.extern.slf4j.Slf4j;
import org.springframework.stereotype.Service;/*** RBloomFilterService : 基于Redis的布隆过滤器服务** @author zyw* @create 2024-01-10 15:38*/@Service
@Slf4j
public class RBloomFilterService {@Resourceprivate BloomFilterUtil bloomFilterUtil;/*** 新增数据到布隆过滤器中** @param element*/public String add(String element) {return bloomFilterUtil.rBloomFilter.add(element) ? "插入成功" : "插入失败";}/*** 检查数据是否存在布隆过滤器中** @param element* @return*/public String check(String element) {log.info("序号:{}", bloomFilterUtil.RBloomFilterSequence);log.info("元素个数:{}", bloomFilterUtil.rBloomFilter.count());log.info("期望插入数:{}", bloomFilterUtil.rBloomFilter.getExpectedInsertions());log.info("假阳性概率:{}", bloomFilterUtil.rBloomFilter.getFalseProbability());return bloomFilterUtil.rBloomFilter.contains(element) ? "存在" : "不存在";}
}
4.6 布隆过滤器测试控制层
import com.example.demo.config.filter.BloomFilterUtil;
import com.example.demo.filter.BloomFilterService;
import com.example.demo.filter.RBloomFilterService;
import io.swagger.v3.oas.annotations.Operation;
import io.swagger.v3.oas.annotations.tags.Tag;
import jakarta.annotation.Resource;
import lombok.extern.slf4j.Slf4j;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RequestParam;
import org.springframework.web.bind.annotation.RestController;/*** BloomFilterController :** @author zyw* @create 2024-01-10 14:58*/@Slf4j
@RestController
@Tag(name = "布隆过滤器测试控制器")
@RequestMapping("bloom")
public class BloomFilterController {@Resourceprivate BloomFilterService bloomFilterService;@Resourceprivate RBloomFilterService rBloomFilterService;@Resourceprivate BloomFilterUtil bloomFilterConfig;@GetMapping("/add")@Operation(summary = "基于JVM本地缓存布隆过滤器-添加")public void add(@RequestParam String element){bloomFilterService.add(element);}@GetMapping("/check")@Operation(summary = "基于JVM本地缓存布隆过滤器-检查")public String check(@RequestParam String element){return bloomFilterService.check(element);}@GetMapping("/addR")@Operation(summary = "基于Redis布隆过滤器-添加")public void addR(@RequestParam String element){rBloomFilterService.add(element);}@GetMapping("/checkR")@Operation(summary = "基于Redis布隆过滤器-检查")public String checkR(@RequestParam String element){return rBloomFilterService.check(element);}@GetMapping("/dilatationR")@Operation(summary = "基于Redis布隆过滤器-手动扩容")public void dilatationR(){bloomFilterConfig.dilatation();}
}
5、测试
5.1 项目启动,初始化布隆过滤器

5.2 测试数据是否存在


5.3 触发扩容
- 我们插入一条数据,使 cachePenetrationBloomFilter.count() 元素达到8个
- 我们的期望插入数据量EXPECTED_INSERTIONS为8,此时布隆过滤器的使用率为 count / EXPECTED_INSERTIONS = 1
- 超过我们设定的布隆过滤器的最大使用率maximumUtilization 0.9
- 我们计算出新的期望插入数据量EXPECTED_INSERTIONS为8*2=16,并构建,初始化
- 初始化完成后,再替换旧的布隆过滤器,随机删除之前缓存的数据。
- 以此防止数据量过大时,初始化数据执行时间过长而影响过滤器的正常使用

在Redis可视化工具中,我们可以看到扩容后的过滤器