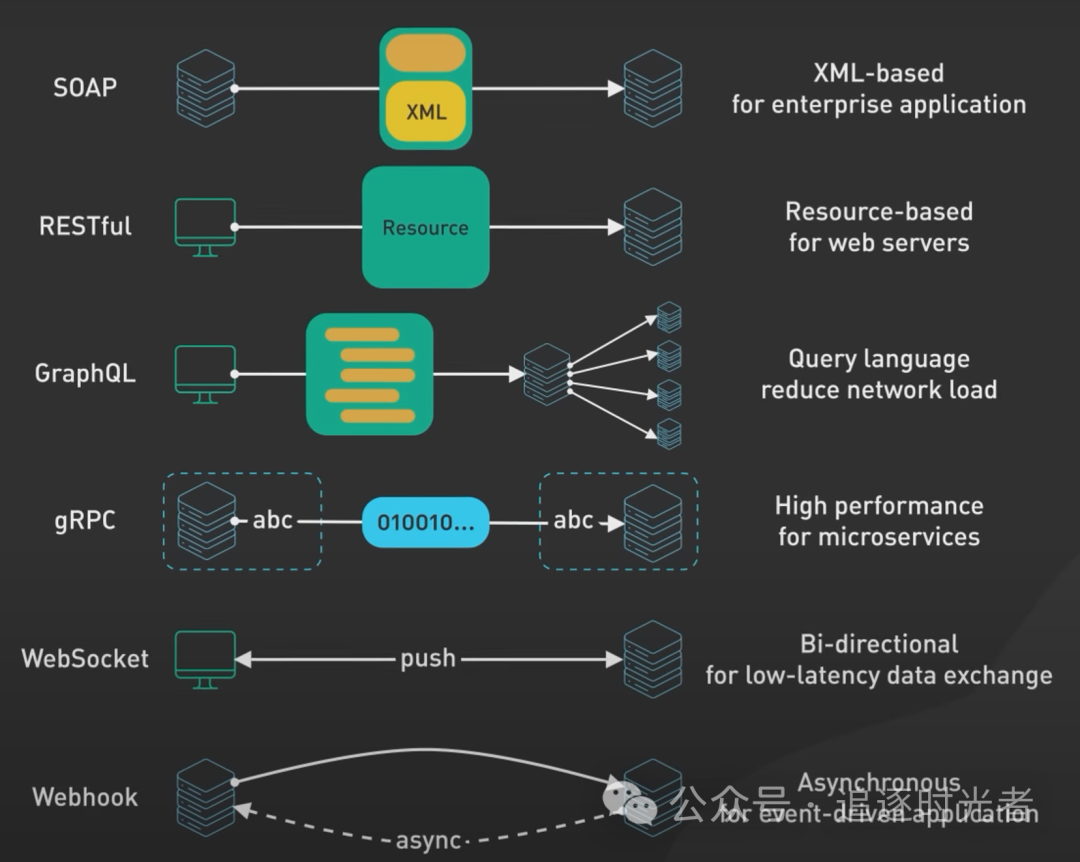
文章目录
- 1.RDD持久化
- 1.1 RDD Cache 缓存
- 1.2 RDD CheckPoint 检查点
- 1.3 缓存和检查点区别
- 2.RDD分区器
- 2.1 Hash 分区:
- 2.2 Range 分区:
- 2.3 用户自定义分区
1.RDD持久化
在Spark中,持久化是将RDD存储在内存中,以便在多次计算之间重复使用。这可以显著减少不必要的计算,提高Spark应用程序的性能。
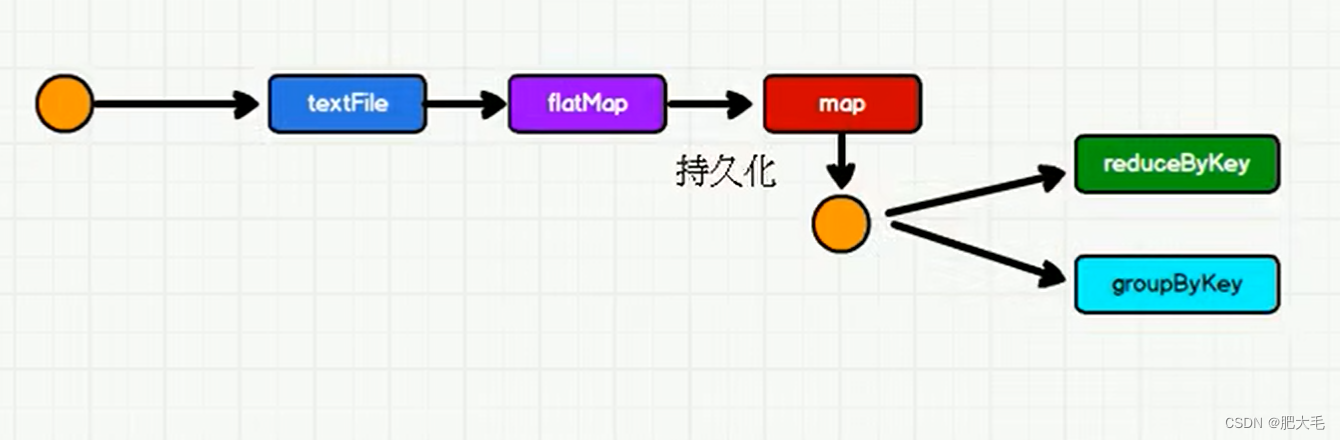
val lines = context.textFile("D:\\learnSoftWare\\IdeaProject\\Spark_Demo\\Spark_Core\\src\\main\\com.mao\\datas\\1.txt")//执行扁平化操作//扁平化就是将多个集合打散为一个集合val words = lines.flatMap((a: String) => a.split(" "))//对每个单词进行改造(hello,1)val wordMap = words.map(word => {println("@@@@@@@@@@@@@@@@@")(word, 1)})//reduceByKey要使用wordMapval wordToCount=wordMap.reduceByKey((t1,t2)=>t1+t2)wordToCount.collect().foreach(println)//groupByKey要使用wordMapval wordToGroup = wordMap.groupByKey()wordToGroup.collect().foreach(println)

如上述代码,reduceByKey和groupByKey都要是用wordMap的结果,由于RDD中是不存储数据的,在reduceByKey使用完成之后,groupByKey想要再次使用的时候,需要查找血缘关系,从头开始一步一步的执行,如果数据量大的情况下,会造成很大的成本上的浪费。
1.1 RDD Cache 缓存
RDD 通过 Cache 或者 Persist 方法将前面的计算结果缓存,默认情况下会把数据以缓存在 JVM 的堆内存中。 但是并不是这两个方法被调用时立即缓存,而是触发后面的 action 算子时,该 RDD 将会被缓存在计算节点的内存中,并供后面重用。
可以通过设置persist来将数据存储到内存或者磁盘中。
// 数据缓存。wordMap.cache()// 可以更改存储级别//wordMap.persist(StorageLevel.MEMORY_AND_DISK_2)
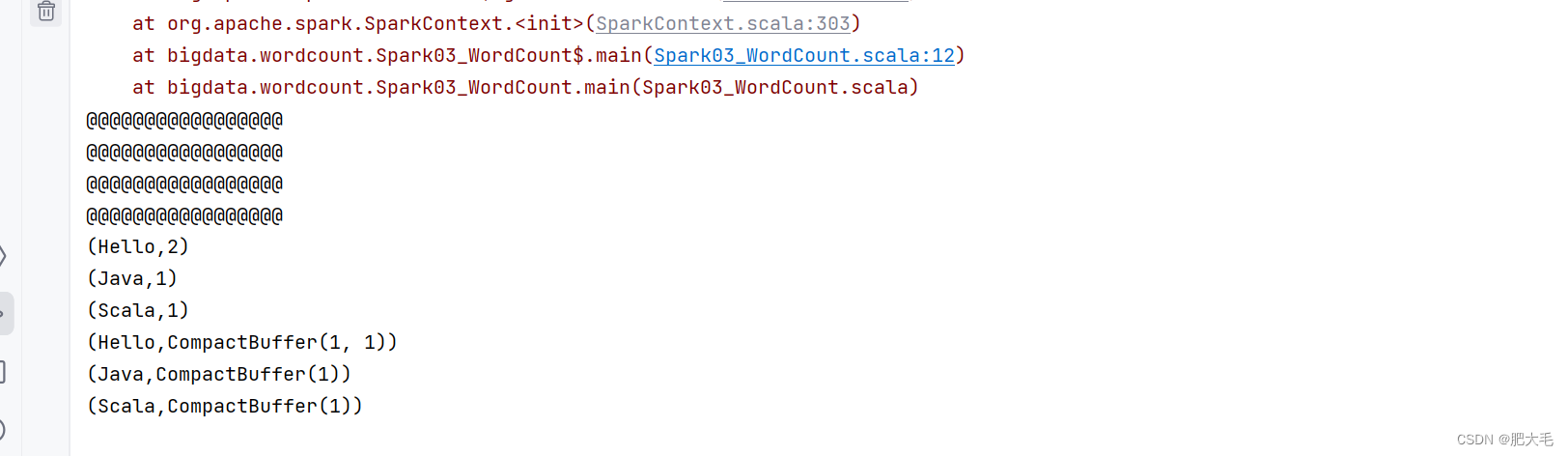
可以看出将中间结果放入缓存中后,第二次使用中间结果的时候,将不会从头再执行一遍,而是直接从缓存中读取数据,
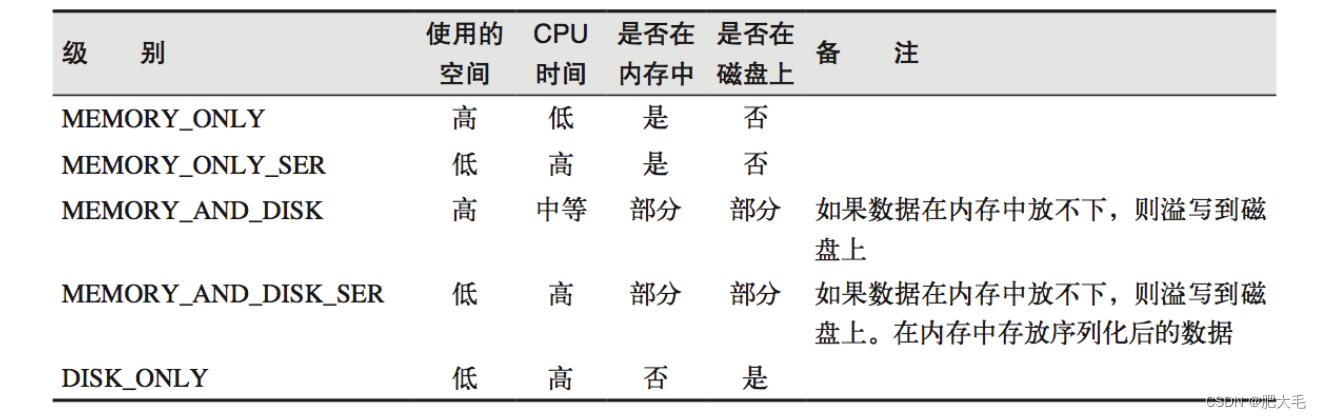
存储级别:
object StorageLevel {val NONE = new StorageLevel(false, false, false, false)val DISK_ONLY = new StorageLevel(true, false, false, false)val DISK_ONLY_2 = new StorageLevel(true, false, false, false, 2)val MEMORY_ONLY = new StorageLevel(false, true, false, true)val MEMORY_ONLY_2 = new StorageLevel(false, true, false, true, 2)val MEMORY_ONLY_SER = new StorageLevel(false, true, false, false)val MEMORY_ONLY_SER_2 = new StorageLevel(false, true, false, false, 2)val MEMORY_AND_DISK = new StorageLevel(true, true, false, true)val MEMORY_AND_DISK_2 = new StorageLevel(true, true, false, true, 2)val MEMORY_AND_DISK_SER = new StorageLevel(true, true, false, false)val MEMORY_AND_DISK_SER_2 = new StorageLevel(true, true, false, false, 2)val OFF_HEAP = new StorageLevel(true, true, true, false, 1)
Spark 会自动对一些 Shuffle 操作的中间数据做持久化操作(比如:reduceByKey)。这样做的目的是为了当一个节点 Shuffle 失败了避免重新计算整个输入。但是,在实际使用的时候,如果想重用数据,仍然建议调用persist 或 cache。
1.2 RDD CheckPoint 检查点
检查点其实就是通过将 RDD 中间结果写入磁盘
由于血缘依赖过长会造成容错成本过高,这样就不如在中间阶段做检查点容错,如果检查点之后有节点出现问题,可以从检查点开始重做血缘,减少了开销。
对 RDD 进行 checkpoint 操作并不会马上被执行,必须执行 Action 操作才能触发。
检查点的数据需要进行落盘,当作业执行结束后,不会被删除。检查点数据一般都是存储在hdfs上。
//建立与Spark框架的连接val wordCount = new SparkConf().setMaster("local").setAppName("WordCount")//配置文件val context = new SparkContext(wordCount)//读取配置文件// 设置检查点路径//这里选择将数据落盘在本地context.setCheckpointDir("./checkpoint1")//执行业务操作val lines = context.textFile("D:\\learnSoftWare\\IdeaProject\\Spark_Demo\\Spark_Core\\src\\main\\com.mao\\datas\\1.txt")//执行扁平化操作//扁平化就是将多个集合打散为一个集合val words = lines.flatMap((a: String) => a.split(" "))//对每个单词进行改造(hello,1)val wordMap = words.map(word => {println("@@@@@@@@@@@@@@@@@")(word, 1)})// 数据缓存。wordMap.cache()// 数据检查点:针对 wordToOneRdd 做检查点计算wordMap.checkpoint()//reduceByKey要使用wordMapval wordToCount=wordMap.reduceByKey((t1,t2)=>t1+t2)wordToCount.collect().foreach(println)//groupByKey要使用wordMapval wordToGroup = wordMap.groupByKey()wordToGroup.collect().foreach(println)//关闭连接context.stop()
1.3 缓存和检查点区别
1)Cache 缓存只是将数据保存起来,不切断血缘依赖,即Cache相当于增加一个依赖关系。Checkpoint 检查点切断血缘依赖。
2)Cache 缓存的数据通常存储在磁盘、内存等地方,可靠性低。Checkpoint 的数据通常存
储在 HDFS 等容错、高可用的文件系统,可靠性高。
3)建议对 checkpoint()的 RDD 使用 Cache 缓存,这样 checkpoint 的 job 只需从 Cache 缓存
中读取数据即可,否则需要再从头计算一次 RDD。
2.RDD分区器
Spark 目前支持 Hash 分区和 Range 分区,和用户自定义分区。Hash 分区为当前的默认分区。分区器直接决定了 RDD 中分区的个数、RDD 中每条数据经过 Shuffle 后进入哪个分区,进而决定了 Reduce 的个数。
只有 Key-Value 类型的 RDD 才有分区器,非 Key-Value 类型的 RDD 分区的值是 None
每个 RDD 的分区 ID 范围:0 ~ (numPartitions - 1),决定这个值是属于那个分区的。
val dataRdd=sparkRdd.makeRDD(List(1,2,3,4),2)
在上述代码中创建的dataRDD是没有分区器的,但是Spark会根据指定的分区数(在这个例子中是2)来将数据分布到不同的分区中,但这种分布并不是由分区器控制的。而是根据数据的本地性(locality)或者简单的轮询(round-robin)方式来分配的。
2.1 Hash 分区:
对于给定的 key,计算其 hashCode,并除以分区个数取余
2.2 Range 分区:
将一定范围内的数据映射到一个分区中,尽量保证每个分区数据均匀,而且分区间有序
2.3 用户自定义分区
自定义分区器,实现将王同学分到一个分区,张同学分到另一个分区
package bigdata.wordcount.RDDimport org.apache.spark.rdd.RDD
import org.apache.spark.{Partitioner, SparkConf, SparkContext}/*** 自定义分区器*/
object SelfPartitioner {def main(args: Array[String]): Unit = {//建立与Spark框架的连接val rdd = new SparkConf().setMaster("local[*]").setAppName("RDD") //配置文件val sparkRdd = new SparkContext(rdd) //读取配置文件val dataRDD: RDD[(String, String)] = sparkRdd.makeRDD(List(("小王", "xxxxxxxxx"),("小张", "xxxxxxxxx"),("小王", "xxxxxxxxx"),), 2)//采用自定义分区器val dataRes: RDD[(String, String)] = dataRDD.partitionBy(new MyPartitioner)dataRes.saveAsTextFile("output0")sparkRdd.stop()}}/*** 自定义分区器* 1.继承Partitioner* 2.重写相关方法*/
class MyPartitioner extends Partitioner
{//设置分区数量override def numPartitions: Int = 2//根据得到的key值获取到分区的索引(从0开始)override def getPartition(key: Any): Int = {key match {case "小王" => 0case "小张" => 1}}
}