DETR 个人理解
目录
DETR 个人理解
概念说明
transformer网络结构
整体流程
损失计算
整体理解
结果说明
论文
代码
参考链接
个人拙见,仅供参考,欢迎指正交流
这篇论文还是挺重要的,因为是transforms用于目标检测的第一篇论文,之后很多的论文都是再此基础上写的,大体的流程是相近的。

概念说明
DETR的输入是单张图像,输出是此图像的检测结果。
positional encoding 是对像素在图像中位置进行的一个编码,方法有很多,也可以参考论文Attention Is All You Need
object queries 这个东西有些类似有anchor目标检测里的anchor,就是蒙的框,论文中对应的是初始的N个输出的y
FFN 就是前馈神经网络,个人理解就是全连接层或者MLP
transformer网络结构
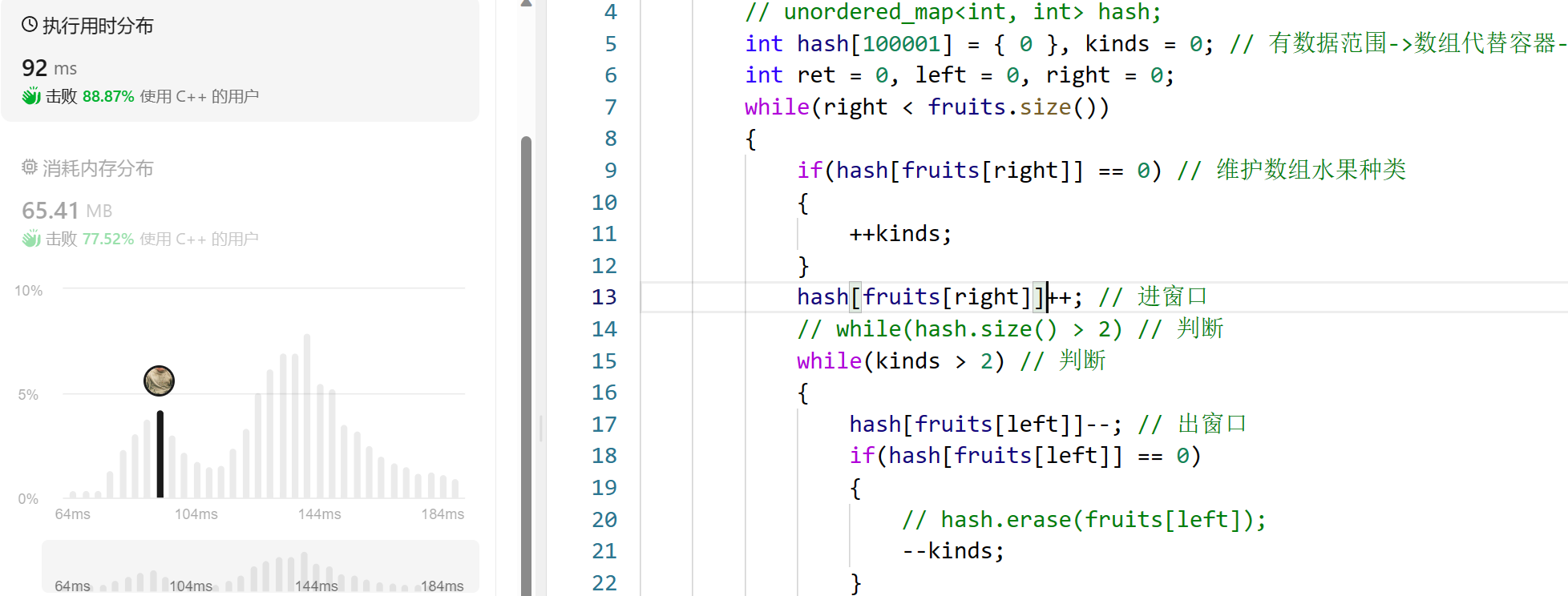
transformer详细的网络结构见下图,其实是有N个Encoder和M个decoder,并且每一个decoder都可以进行输出,然后去算损失
至于为什么每一个中间的decoder都可以进行输出,去算损失??
个人理解这个位置就像是啥呢,就像是你想让你的儿子考清华,最后一个decoder对应高考。你儿子要想考上清华,最稳妥的一个形式就是,你儿子从小到大每一次考试都能考第一,这样他最后高考时,考上清华的可能性才是最高。同理,你想要你最后一个decoder输出的结果最好,最稳妥的方式就是之前每一个decoder输出的结果都很好。

整体流程
单张图像进来之后首先经过一个backbone,提取图像特征,然后和positional encoding提取到的特征相结合,这样得到的特征图既有他在图像中的位置信息,又有他附近的一片像素信息。然后将这个特征图去过transformer的encoder,得到一个新的特征图,这个位置得到的东西其实是Multi-Head Attention里需要的K和V。object queries进来之后首先经过一个Multi-Head Self-Attention,就是你蒙的框不一定准,你自己先反思反思,学习学习,不要跟图像特征参乎,自己学学怎么用图像特征。object queries自己卷积完之后作为Multi-Head Attention里需要的Q,进行输出。最后在Multi-Head Attention里图像生成的特征K、V和你想让图像生成的特征结果Q相结合了,就能生成预测结果了。
损失计算
有预测结果了,然后我们还有真实标签,这个时候就可以计算损失了。
object queries这个位置我们蒙了N个框,最后Transformer decoder就会输出N个预测结果。N是一个远大于图像中可能具有最多目标数的一个数,论文中取了100。我们预测了N个框,但是我图像中的目标可能没有这么多,那怎么办呢,我向图像中补背景,让框的类别是没有意义的背景,这样你预测框的数量就和真实框一样多了,也解决了有的图像目标多,有的图像目标少的问题,你目标再多也不可能比N多。然后我让预测的N个框和真实的N个框去做1对1的匹配,就像是双射,相互对应并且唯一。匹配的算法是多目标最优匹配的匈牙利算法,最后使用相互匹配上的框去计算损失。
整体理解
使用transformer去学习,就像是啥呢,就像是你要上大学。开始你也不知道自己的天赋咋样,自己能学成啥样,然后就默默给自己定一个目标,比如说是辽宁大学,辽宁大学就对应transformer里的object queries,就是一个初始的目标。
你有了初始目标之后,没开始上小学之前,你啥也不懂,也不知道辽宁大学咋样,你就问你爸说:我想给自己定一个目标大学,你觉得辽宁大学咋样。结果你爸说,你爸我是东北大学毕业的,你敢定辽宁大学我就打死你。然后你就学到了一些关于大学的信息,觉得自己也应该有这个天赋,把初始的大学目标定在了东北大学,这个对初始目标修改的一个过程就对应decoder里object queries进来之后首先经过的Multi-Head Self-Attention。
然后你就开始学习了,这个学习的过程就对应transformer里的encoder(其实还有backbone,忽略这个位置吧)
一个学期上完,你学到了很多知识,你也不知道自己学的对不对,不知道自己定的目标合不合理,就需要进行一次期末考试,这个考试呢就对应decoder里的Multi-Head Attention和之后的过程。
考完试呢你只有一个考试成绩,但是这个成绩并不能完全代表你学的咋样,比如说试卷特别难,大家都考60,结果你考了80,或者说试卷特别简单,大家都考90,结果你考了80,你能不能上东北大学,严格意义上说并不取决于你考了多少分,而取决于你在全省的排名,这个排名呢就对应transformer里的损失,这个排名呢就会定义你这一年学的咋样。
开始你也不太会学习,你的排名就没有很好,但是你经过排名呢,就对自己过去的一些学习方法和自己定的这个目标就有数,然后呢你就不断的优化自己的学习方法,让自己学的更好,这个位置就是优化encoder的过程。
你通过优化自己的学习方法使自己的排名提高了,你发现你开始定的大学不合理,你完全可以定一个更好的大学,定一个更好的目标,这个位置就对应decoder中优化object queries的过程。
你通过不断地优化自己的学习方法,和自己想要考取的目标大学,不断地进步,最终你把目标定在了清华大学,最后高考就对应transformer里的最后一个decoder,至于你能不能考上,就取决于你最后一个decoder出来的模型收不收敛了。
结果说明
经过训练之后,最终的object queries结果如下图

这个位置怎么理解呢,就是anchors蒙的是一个框,object queries蒙的是一张图像的所有框,框数不限,蒙了100种可能
论文
https://arxiv.org/abs/2005.12872
代码
https://github.com/facebookresearch/detr
参考链接
Attention Is All You Need
https://arxiv.org/abs/1706.03762
Attention Is All You Need 英文讲解
The Illustrated Transformer – Jay Alammar – Visualizing machine learning one concept at a time.
Attention Is All You Need 中文讲解
详解Transformer (Attention Is All You Need) - 知乎
Attention
史上最小白之Attention详解_target attention-CSDN博客
Self-Attention
动图轻松理解Self-Attention(自注意力机制) - 知乎
transformer
史上最小白之Transformer详解_transformer最小白-CSDN博客
B站论文讲解视频
二、transformer核心项目-DeformableDetr算法解读_哔哩哔哩_bilibili