目录
一. 项目介绍
整体流程:
项目建设目的:
学习安排:
技术选型:
技术架构:
项目架构:
二 . 名词解释
一. 项目介绍
整体流程:
项目介绍-elasticSearch-业务数据源导入-离线指标开发-Flume实时采集-Nginx日志埋点数据-
结构化流实时指标 - 制作报表
| 数仓开发 | 用户画像 | 实时开发 |
| hive-spark | 数据挖掘 | 结构化流-Flume-Kafka-Flink |
| 标签开发,挖掘类,统计类 规则类,标签可视化平台, 用户画像系统构建 |
项目建设目的:
用户画像项目,用户画像:为用户提供标签系统,更进一步了解用户需求,在大数据时代下,人们产生、获取、处理和存储的数据量呈指数级增长,过去基于统计模型的决策 无法满足人们的个性化要求。逐步演变为 基于数据驱动的决策 ,即如何 使用算法模型实现用户画像中的 用户行为预测,如何利用大数据技术从海量的数据中为客户提取有价值的信息,已经成为各行各业产品经理及公司企业的运营管理人员的关注重点,因此我们为此提供了画像系统这样的解决方案。
项目建设的目的是:
因此1- 从公司角度出发:
1- 对客户进行分群,进行精准营销
2- 对用户分群和统计,私域流量
3- 找到用户和商品之间的连接,对用户打标签并量化表示
4- 减少公司的获客成本
2- 从用户角度出发:
1- 从海量的产品和数据中,为客户推荐感兴趣的内容
学习安排:
白天: 电商行业的用户画像
晚上:保险行业的用户画像
技术选型:
Elasticsearch是一个分布式的全文搜索引擎,具有高性能、可扩展性和数据可靠性等特点。它使用Lucene作为底层引擎,支持快速地存储、搜索和分析大量的数据。
1- ElasticSearch是专门用来做搜索引擎的,一般用在JAVAEE的,它具有几个优点:
1- 分布式
2- 单条数据快速的CRUD
CRUD操作(create 添加数据read读取数据 update 修改数据delete删除数据)
3- 海量数据存储
1.为什么画像数据接入选择ES?
es支持海量数据插入与更新 es支持与hadoop、hive、spark集成,方案成熟 es-hadoop可直接解决,
通过sql方式把数据从hive数仓中导入es中
2.为什么画像结果数据写入ES?
1. 结果数据写入es,es扩展性强,广泛支持hadoop生态圈技术,
2. es-sql支持sql化方式操作es索引数据,可视化非常方便,后期开发标签体系的搜索引擎或知识图谱系统是es可以直接作为数据源与其他组件集成。
3. es支持upsert语法,数据插入和更新可以使用upsert操作,根据主键或文档id判断该文档是否存在,存在就更新,
否则就插入,对于画像业务逻辑中新的标签和旧的标签数据合并非常实用。
2- 为啥选择Spark SQL的DSL方案呢?
计算组件如 HIVE presto flink 都可以计算
1- Spark SQL是基于内存进行计算, 相对于HIVE来说, 计算效率更高
2- Spark 可以更好的和其他的组件进行集成工作, 比如和MySQL. hive, es ...
3- 在画像标签中, 有挖掘性标签, 此部分标签需要使用MLlib机器学习库, 采用相关的算法,而Hive并不支持, Flink相对成熟度没有Spark高
4- 在开发标签的过程中, 需要进行大量的规则匹配处理, 涉及到需要通过代码方式来处理, 此时DSL方案会更加的合适3- 为什么不用Hive做标签计算
完成挖掘类标签的时候使用Hive无法完成,标签调度不方便
Hive计算完画像结果存储在其他介质不方便
Hive 来计算标签不方便管理和维护
因此可以使用 Spark Job 的方式来计算.
Spark Job 的方式来计算.
每一个 Job 计算一个指标, 最终合并进一张画像表。
能够利用SparkMllib完成挖掘类标签的构建(SparkSQL+SparkMllib)
技术选型: 使用Spark完成指标计算,每个指标一个Job,合并画像表
技术架构:
主要采用Apache原生版本方案构建整个画像项目, 整个项目主要涉及组件有: Hadoop HIVE Spark oozie persto ES等相关的大数据组件
其中基于HDFS完成基础数据的存储,通过ES来存储业务数据以及存储标签结果数据
通过Spark实现标签计算和实时用户行为统计分析工作, 并将相关结果导入到ES和MySQL中
最终基于FineBI实现报表展示工作, 整个项目是基于Oozie完成定时调度
项目架构:
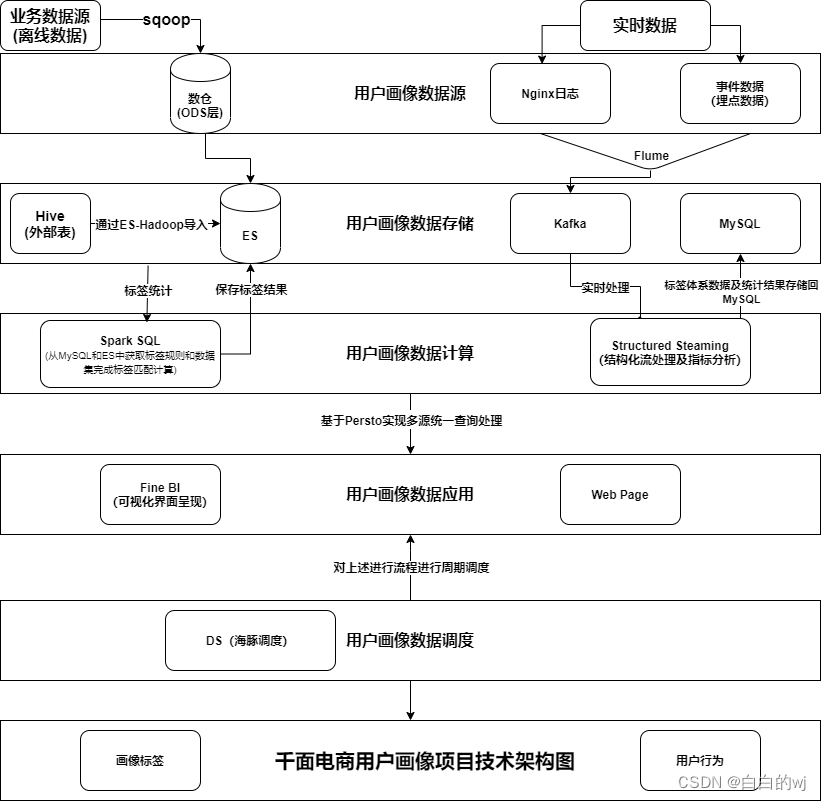
mysql业务数据表->datax ->数仓ods -> 确定业务场景 -> Sparksql开发 ->建立标签 -> 使用ES标签搜索 -mysql标签规则 -> 提交定时任务 -> 作业提交
数据流转:
整个画像的数据来源有二个方向, 一个是数仓平台的ODS层基础业务数据 一个是Nginx日志数据和埋点数据集
首先对于ODS层业务数据,主要是基于ES-HADOOP的方式将HIVE中数据导入到ES中, 对于Nginx日志数据和埋点数据集主要是基于Flume将数据采集到Kafka中,
完成基础数据存储后, 接着基于Spark进行标签统计和用户行为分析的工作这里面主要采用Spark SQL、SparkMLlib 和 structured Steaming实现的, 其中Spark SQL负责标签统计计算,SparkMLlib主要负责完成挖掘类标签计算, structured Streaming负责用户行为指标统计计算, 将整个结果结果导入到ES和MySQL中, 其中ES导入的标签结果数据, MySQL导入的是用户行为指标结果数据集,
完成整个统计计算后, 后续基于FINEBI进行画像报表展示, 由于数据源有多个, 引入了persto完成多源统一访问, 最终形成画像报表. 整个项目是基于标签管理平台, 进行标签管理, 对标签进行增删改查以及定时调度, 其底层调度采用Oozie处理的
二 . 名词解释
埋点数据:
前端埋点: JavaEE/安卓/ios后端
后端埋点: Flume+Kafka
CRM:客户关系管理系统
ERP: 企业资源管理计划系统