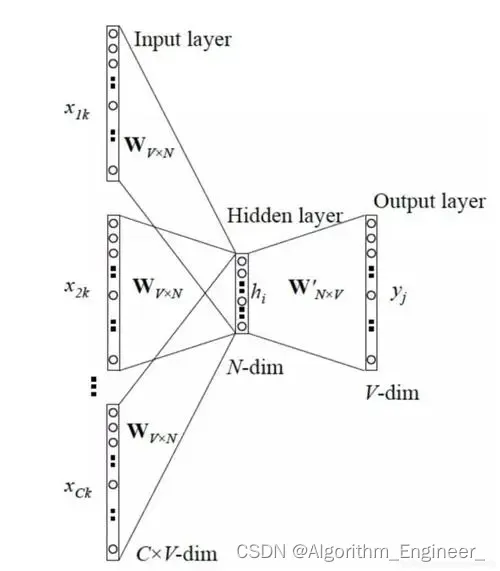
import logging
import os. path
import sys
from gensim. corpora import WikiCorpus
import jieba
import jieba. analyse
import codecs
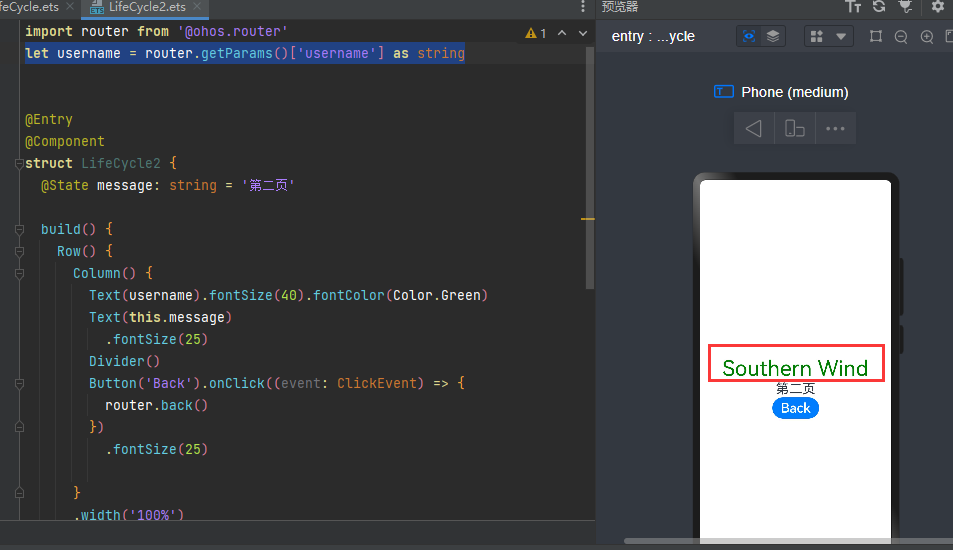
def process_wiki_text ( origin_file, target_file) : with codecs. open ( origin_file, 'r' , 'utf-8' ) as inp, codecs. open ( target_file, 'w' , 'utf-8' ) as outp: line = inp. readline( ) line_num = 1 while line: line_seg = " " . join( jieba. cut( line) ) outp. writelines( line_seg) line_num = line_num + 1 line = inp. readline( ) inp. close( ) outp. close( )
if __name__ == '__main__' : program = os. path. basename( sys. argv[ 0 ] ) logger = logging. getLogger( program) logging. basicConfig( format = '%(asctime)s: %(levelname)s: %(message)s' ) logging. root. setLevel( level= logging. INFO) logger. info( "running %s" % ' ' . join( sys. argv) ) if len ( sys. argv) < 3 : print ( globals ( ) [ '__doc__' ] % locals ( ) ) sys. exit( 1 ) inp, outp = sys. argv[ 1 : 3 ] space = " " i = 0 output = open ( outp, 'w' , encoding= 'utf-8' ) wiki = WikiCorpus( inp, lemmatize= False , dictionary= { } ) for text in wiki. get_texts( ) : output. write( space. join( text) + "\n" ) i = i + 1 if i % 200000 == 0 : logger. info( "Saved " + str ( i) + " articles" ) output. close( ) logger. info( "Finished Saved " + str ( i) + " articles" ) process_wiki_text( 'wiki.zh.txt' , 'wiki.zh.text.seg' )
import logging
import os. path
import sys
import multiprocessing
import gensim
from gensim. models import Word2Vec
from gensim. models. word2vec import LineSentence
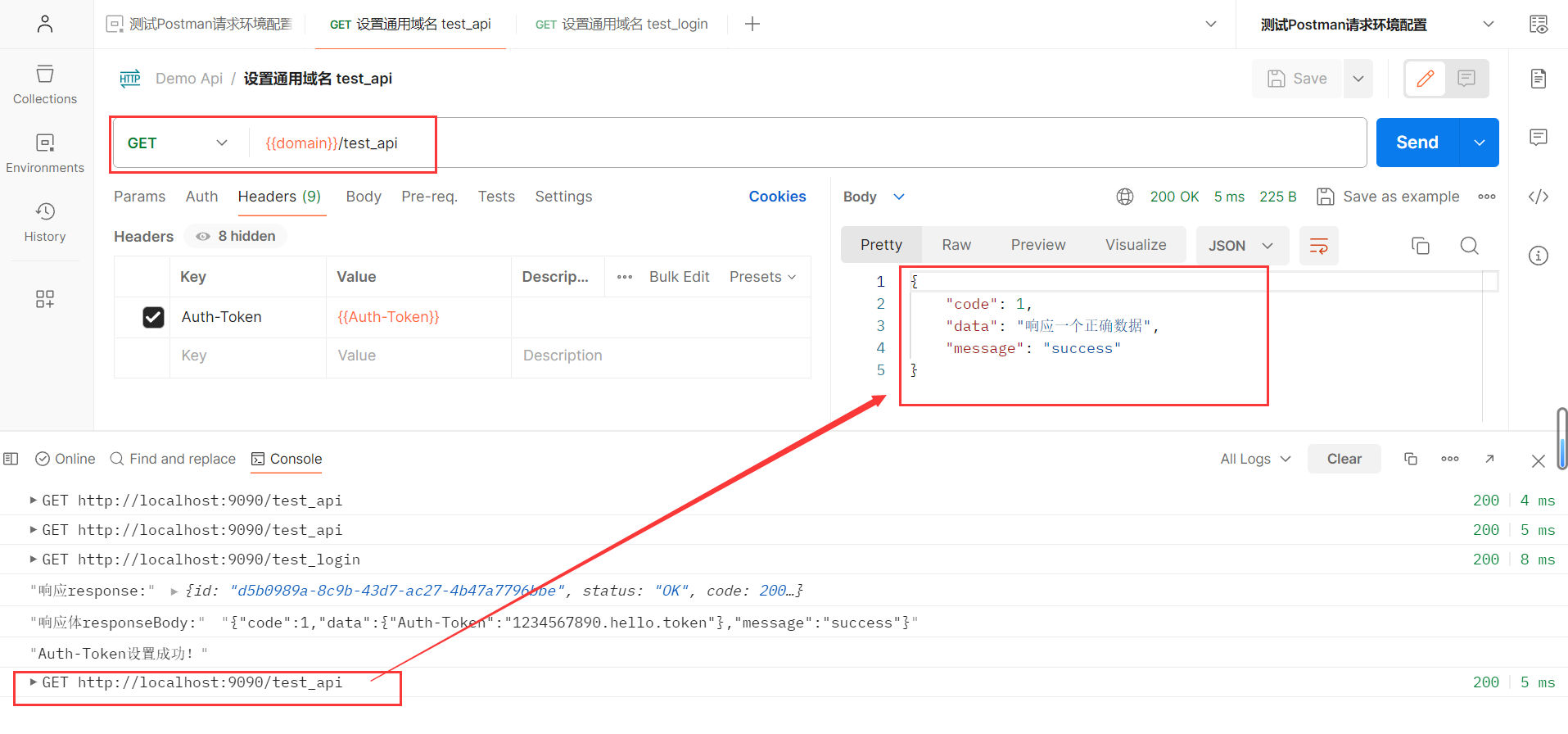
if __name__ == '__main__' : if len ( sys. argv) < 4 : print ( globals ( ) [ '__doc__' ] % locals ( ) ) sys. exit( 1 ) inp, outp1, outp2 = sys. argv[ 1 : 4 ] """LineSentence(inp):格式简单:一句话=一行; 单词已经过预处理并被空格分隔。size:是每个词的向量维度; window:是词向量训练时的上下文扫描窗口大小,窗口为5就是考虑前5个词和后5个词; min-count:设置最低频率,默认是5,如果一个词语在文档中出现的次数小于5,那么就会丢弃; workers:是训练的进程数(需要更精准的解释,请指正),默认是当前运行机器的处理器核数。这些参数先记住就可以了。sg ({0, 1}, optional) – 模型的训练算法: 1: skip-gram; 0: CBOWalpha (float, optional) – 初始学习率 iter (int, optional) – 迭代次数,默认为5""" lineSentence = LineSentence( inp, max_sentence_length= 10000 ) model = Word2Vec( lineSentence, size= 100 , window= 5 , min_count= 5 , workers= multiprocessing. cpu_count( ) ) model. save( outp1) model. wv. save_word2vec_format( outp2, binary= False )
import gensim
model = gensim. models. Word2Vec. load( "wiki.zh.text.model" )
count = 0
for word in model. wv. index2word: count += 1 if count == 20 : print ( word, model[ word] ) break
result = model. most_similar( u"分词" )
for e in result: print ( e)