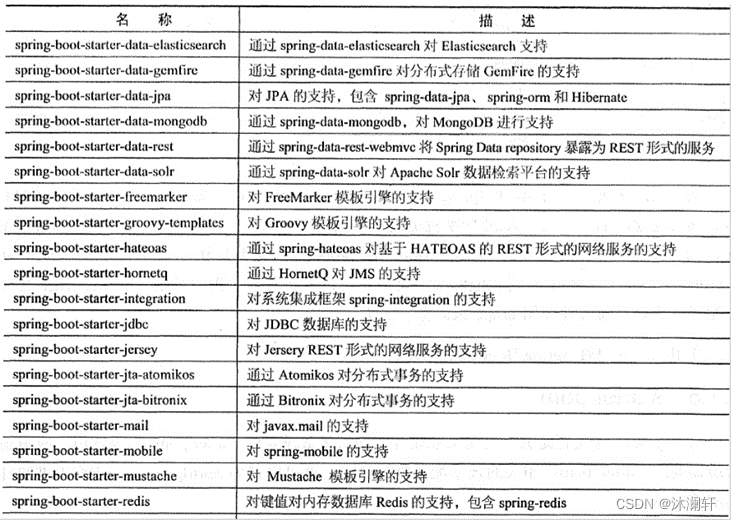
注意(Attending)
第一步是将一个文本序列中的词元与另一个序列中的每个词元对齐。假设前提是“我确实需要睡眠”,假设是“我累了”。由于语义上的相似性,我们不妨将假设中的“我”与前提中的“我”对齐,将假设中的“累”与前提中的“睡眠”对齐。同样,我们可能希望将前提中的“我”与假设中的“我”对齐,将前提中的“需要”和“睡眠”与假设中的“累”对齐。请注意,这种对齐是使用加权平均的“软”对齐,其中理想情况下较大的权重与要对齐的词元相关联。为了便于演示, 下图以“硬”对齐的方式显示了这种对齐方式。

现在,我们更详细地描述使用注意力机制的软对齐。

其中函数是在下面的
mlp函数中定义的多层感知机。输出维度由
mlp的num_hiddens参数指定。
def mlp(num_inputs, num_hiddens, flatten):net = []net.append(nn.Dropout(0.2))net.append(nn.Linear(num_inputs, num_hiddens))net.append(nn.ReLU())if flatten:net.append(nn.Flatten(start_dim=1))net.append(nn.Dropout(0.2))net.append(nn.Linear(num_hiddens, num_hiddens))net.append(nn.ReLU())if flatten:net.append(nn.Flatten(start_dim=1))return nn.Sequential(*net)值得注意的是,分别输入
和
,而不是将它们一对放在一起作为输入。这种分解技巧导致
只有
个次计算(线性复杂度),而不是
次计算(二次复杂度)。
我们计算假设中所有词元向量的加权平均值,以获得假设的表示,该假设与前提中索引的词元进行软对齐:

同样,我们计算假设中索引为的每个词元与前提词元的软对齐:

下面,我们定义Attend类来计算假设(beta)与输入前提A的软对齐以及前提(alpha)与输入假设B的软对齐。
class Attend(nn.Module):def __init__(self, num_inputs, num_hiddens, **kwargs):super(Attend, self).__init__(**kwargs)self.f = mlp(num_inputs, num_hiddens, flatten=False)def forward(self, A, B):# A/B的形状:(批量大小,序列A/B的词元数,embed_size)# f_A/f_B的形状:(批量大小,序列A/B的词元数,num_hiddens)f_A = self.f(A)f_B = self.f(B)# e的形状:(批量大小,序列A的词元数,序列B的词元数)e = torch.bmm(f_A, f_B.permute(0, 2, 1))# beta的形状:(批量大小,序列A的词元数,embed_size),# 意味着序列B被软对齐到序列A的每个词元(beta的第1个维度)beta = torch.bmm(F.softmax(e, dim=-1), B)# beta的形状:(批量大小,序列B的词元数,embed_size),# 意味着序列A被软对齐到序列B的每个词元(alpha的第1个维度)alpha = torch.bmm(F.softmax(e.permute(0, 2, 1), dim=-1), A)return beta, alpha