说明
假设Oracle A表B表 ,表字段不同,表名也不同, 通过存储过程 + 定时任务(Jobs), 定期去执行业务逻辑的增删改查 。
1、定时同步
-
创建一个存储过程,用于比较两张表中的数据,并根据状态决定需要同步的数据。
CREATE OR REPLACE PROCEDURE sync_data AS
BEGIN FOR src_rec IN (SELECT column1, column2, column3 FROM source_table) LOOP -- 查询目标表中状态为同步的记录 FOR dest_rec IN (SELECT column1, column2, column3 FROM destination_table WHERE status = 'SYNC') LOOP -- 如果源表和目标表中的记录状态相同,则不需要同步 IF src_rec.column1 = dest_rec.column1 AND src_rec.column2 = dest_rec.column2 AND src_rec.column3 = dest_rec.column3 THEN NULL; -- 否则,更新目标表中的记录 ELSE UPDATE destination_table SET column1 = src_rec.column1, column2 = src_rec.column2, column3 = src_rec.column3 WHERE column1 = dest_rec.column1 AND column2 = dest_rec.column2 AND column3 = dest_rec.column3; END IF; END LOOP; END LOOP;
END;-
创建一个定时任务,用于定期执行存储过程。
使用Oracle提供的 "DBMS_SCHEDULER" 包来创建定时任务,可以设置定时任务的执行时间、执行间隔和执行方式等。例如,下面的代码创建了一个名为 "SYNC_DATA_TASK" 的定时任务,每隔5分钟执行一次 "SYNC_DATA" 存储过程。
BEGIN DBMS_SCHEDULER.CREATE_JOB ( job_name => 'SYNC_DATA_TASK', job_type => 'PLSQL_BLOCK', job_action => 'BEGIN sync_data; END;', start_date =>SYSDATE, repeat_interval => 'FREQ=MINUTELY;INTERVAL=5;', end_date => NULL, enabled => TRUE);
END;具体实现方式需要根据实际需求进行调整。同时也可以根据实际需求,添加其他定时任务参数和条件。
2、定时添加
1、首先,需要确定要在源表中提取哪些数据,以及如何根据状态筛选数据。例如,如果您希望提取状态为 "STATE"的所有记录,则可以在查询中添加 " WHERE status = 'STATE' "条件。
2、然后,需要创建一个定时任务,以便在指定的时间间隔内执行数据提取和插入操作。还是使用Oracle提供的 "DBMS_SCHEDULER" 包来创建定时任务。例如,您可以创建一个名为 "SYNC_DATA_TASK" 的定时任务,并设置其执行时间间隔为每天一次。
3、在定时任务中,可以使用PL/SQL编写一个存储过程,该存储过程将从源表中选择所需的数据,并将其插入到目标表中。
CREATE OR REPLACE PROCEDURE sync_data AS
BEGIN -- 从源表中选择状态为ACTIVE的记录 FOR src_rec IN ( SELECT column1, column2, column3 FROM source_table WHERE status = 'ACTIVE' ) LOOP -- 如果目标表中不存在相同的记录,则将源表中的记录插入目标表 IF NOT EXISTS ( SELECT * FROM destination_table WHERE column1 = src_rec.column1 AND column2 = src_rec.column2 AND column3 = src_rec.column3 ) THEN INSERT INTO destination_table (column1, column2, column3) VALUES (src_rec.column1, src_rec.column2, src_rec.column3); END IF; END LOOP;
END;从源表中选择了状态为 "ACTIVE" 的记录。然后,检查目标表中是否已经存在与源表相同的记录,如果不存在,则将源表中的记录插入目标表。
注意: 以上存储过程会出现一个问题? 什么问题?
错误:PLS-00204: 函数或伪列 'EXISTS' 只能在 SQL 语句中使用 IF NOT EXISTS
思路:
使用 COUNT 函数:如果 IF NOT EXISTS 语句是用于检查表中是否存在记录,可以使用 COUNT 函数来检查记录的数量。如果记录数量为 0,则表示它不存在。
SELECT COUNT(*) FROM 表名 WHERE 条件;
IF COUNT = 0 THEN -- 执行某些操作
END IF;
解决:
CREATE OR REPLACE PROCEDURE sync_data AS vo_count number; --声明变量
BEGIN -- 从源表中选择状态为ACTIVE的记录 FOR src_rec IN ( SELECT column1, column2, column3 FROM source_table WHERE status = 'ACTIVE' ) LOOP -- 不能直接用IF NOT EXISTS,那就抽出来SELECT COUNT(*) INTO vo_countFROM destination_tableWHERE column1 = src_rec.column1AND column2 = src_rec.column2AND column3 = src_rec.column3-- 如果目标表中不存在相同的记录,则将源表中的记录插入目标表 IF vo_count = 0 THEN INSERT INTO destination_table (column1, column2, column3) VALUES (src_rec.column1, src_rec.column2, src_rec.column3); END IF; END LOOP;
END;4、 最后,需要使用 DBMS_SCHEDULER 包将存储过程调度为定时任务。
BEGIN DBMS_SCHEDULER.CREATE_JOB ( job_name => 'SYNC_DATA_TASK', job_type => 'PLSQL_BLOCK', job_action => 'BEGIN sync_data; END;', start_date => SYSDATE, repeat_interval => 'FREQ=DAILY;INTERVAL=1;', end_date => NULL, enabled => TRUE);
END;- DBMS_SCHEDULER.CREATE_JOB:这是一个Oracle数据库提供的存储过程,用于创建定时器任务。
- job_name:指定定时器任务的名称,可以自定义。
- job_type:指定任务类型,这里选择的是"PLSQL_BLOCK",表示要执行的的任务是一个PL/SQL存储过程。
- job_action:指定要执行的任务操作,这里指定为存储过程名。
- start_date:指定任务的开始日期和时间,这里使用SYSDATE表示当前时间。
- repeat_interval:指定任务的重复执行间隔,这里使用'FREQ=DAILY;INTERVAL=1;'表示每天执行一次。
- end_date:指定任务的结束日期和时间,这里设置为NULL表示任务将一直执行直到被取消。
- enabled:指定任务是否启用,这里设置为TRUE表示启用任务。
3、定时删除
- 创建一个存储过程,用于比较两张表中的数据,并根据状态决定需要删除的数据。
CREATE OR REPLACE PROCEDURE delete_data AS
vo_count number; --声明变量
BEGIN -- 查询需要删除的记录 FOR dest_rec IN ( SELECT column1, column2, column3 FROM destination_table WHERE status != 'DELETED' ) LOOP -- 使用 COUNT 函数来检查记录的数量。如果记录数量为 0,则表示它不存在。SELECTCOUNT(*) INTO vo_countFROMsource_table WHERE column1 = dest_rec.column1 AND column2 = dest_rec.column2 AND column3 = dest_rec.column3-- 检查源表中是否存在相同的记录,如果不存在,则删除目标表中的记录 IF vo_count = 0 THEN DELETE FROM destination_table WHERE column1 = dest_rec.column1 AND column2 = dest_rec.column2 AND column3 = dest_rec.column3; END IF; END LOOP;
END; 首先查询状态不为 "DELETED" 的记录,并使用循环逐行处理这些记录。然后,检查源表中是否存在与目标表相同的记录,如果不存在,则删除目标表中的记录。
- 创建一个定时任务,用于定期执行存储过程。
BEGIN DBMS_SCHEDULER.CREATE_JOB ( job_name => 'DELETE_DATA_TASK', job_type => 'PLSQL_BLOCK', job_action => 'BEGIN delete_data; END;', start_date => SYSDATE, repeat_interval => 'FREQ=DAILY;INTERVAL=1;', end_date => NULL, enabled => TRUE);
END;创建了一个为 "DELETE_DATA_TASK" 的定时任务,并将其调度为每天执行一次。然后,我们指定要执行的存储过程为 "delete_data" ,并设置其执行时间为当前时间。还设置了重复间隔为1天,表示该任务将每隔一天执行一次,直到任务被取消。
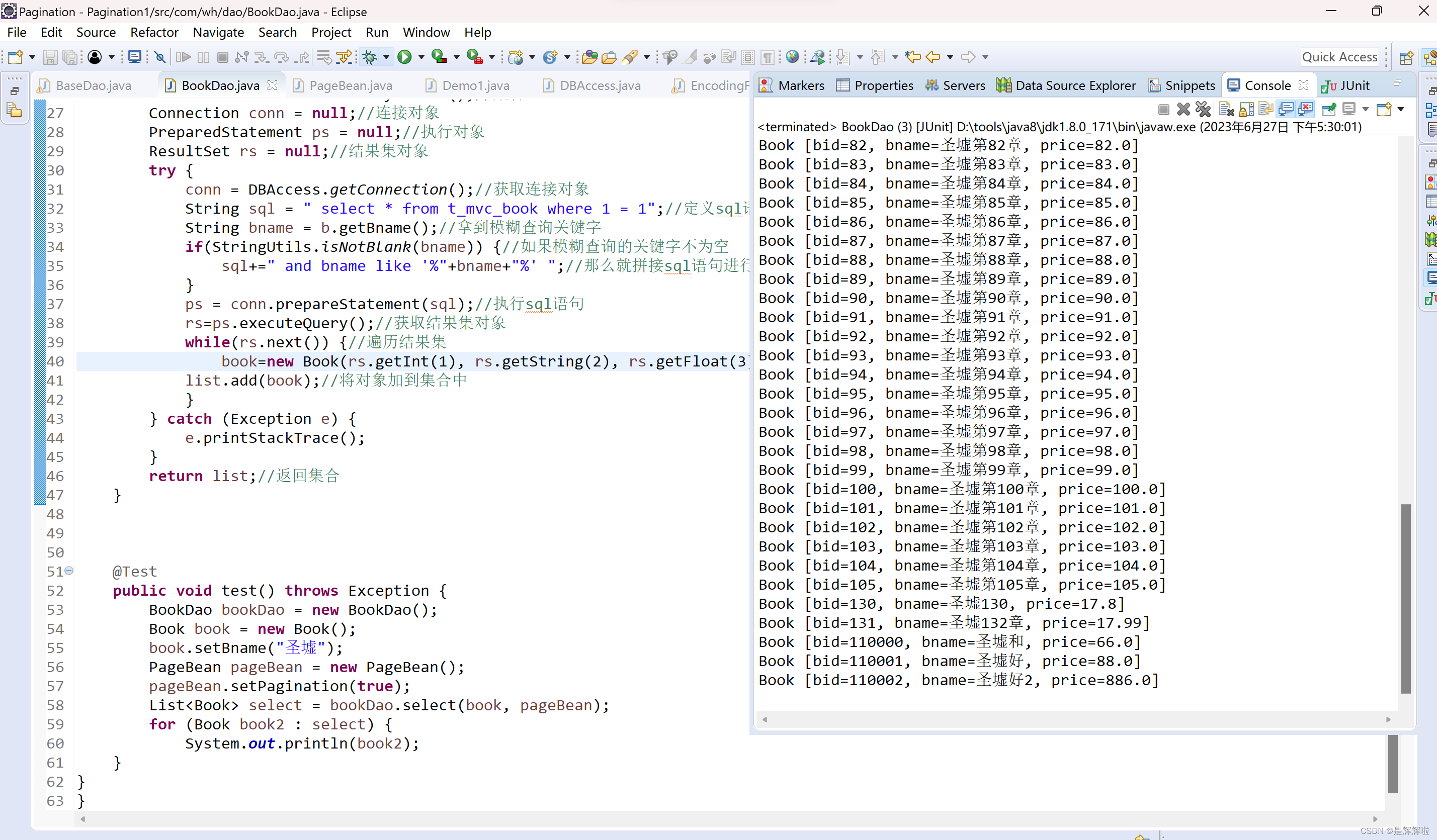
4、演示
1、建表语句
create table XIAO
(id VARCHAR2(32),name VARCHAR2(32),x VARCHAR2(32),time DATE,state VARCHAR2(32)
)
tablespace DBLTpctfree 10initrans 1maxtrans 255storage(initial 64Knext 8Mminextents 1maxextents unlimited);create table JIAN
(ids VARCHAR2(32),names VARCHAR2(32),j VARCHAR2(32),state VARCHAR2(32)
)
tablespace DBLTpctfree 10initrans 1maxtrans 255storage(initial 64Knext 8Mminextents 1maxextents unlimited);2、添加数据
INSERT INTO XIAO ( id, NAME, state )
VALUES( '10001', '赵', '1' );
INSERT INTO XIAO ( id, NAME, state )
VALUES( '10002', '钱', '1' );
INSERT INTO XIAO ( id, NAME, state )
VALUES( '10003', '孙', '1' );
INSERT INTO XIAO ( id, NAME, state )
VALUES( '10004', '李', '1' );
INSERT INTO XIAO ( id, NAME, state )
VALUES( '10005', '周', '1' );
INSERT INTO XIAO ( id, NAME, state )
VALUES( '10006', '吴', '1' );
INSERT INTO XIAO ( id, NAME, state )
VALUES( '10007', '郑', '1' );
INSERT INTO XIAO ( id, NAME, state )
VALUES( '10008', '王', '1' );3、创建存储过程
CREATE OR REPLACE PROCEDURE sync_data_xj ASvo_count number;
BEGIN-- 从源表中选择状态为ACTIVE的记录 FOR src_rec IN ( SELECT id, name, state FROM XIAO WHERE state = '1' ) LOOP SELECT COUNT(*) INTO vo_countFROM JIANWHERE ids = src_rec.idAND names = src_rec.nameAND state = src_rec.state;-- 如果目标表中不存在相同的记录,则将源表中的记录插入目标表 IF vo_count = 0 THEN INSERT INTO JIAN (ids, names, state) VALUES (src_rec.id, src_rec.name, src_rec.state); END IF; END LOOP;
END;
4、创建定时器
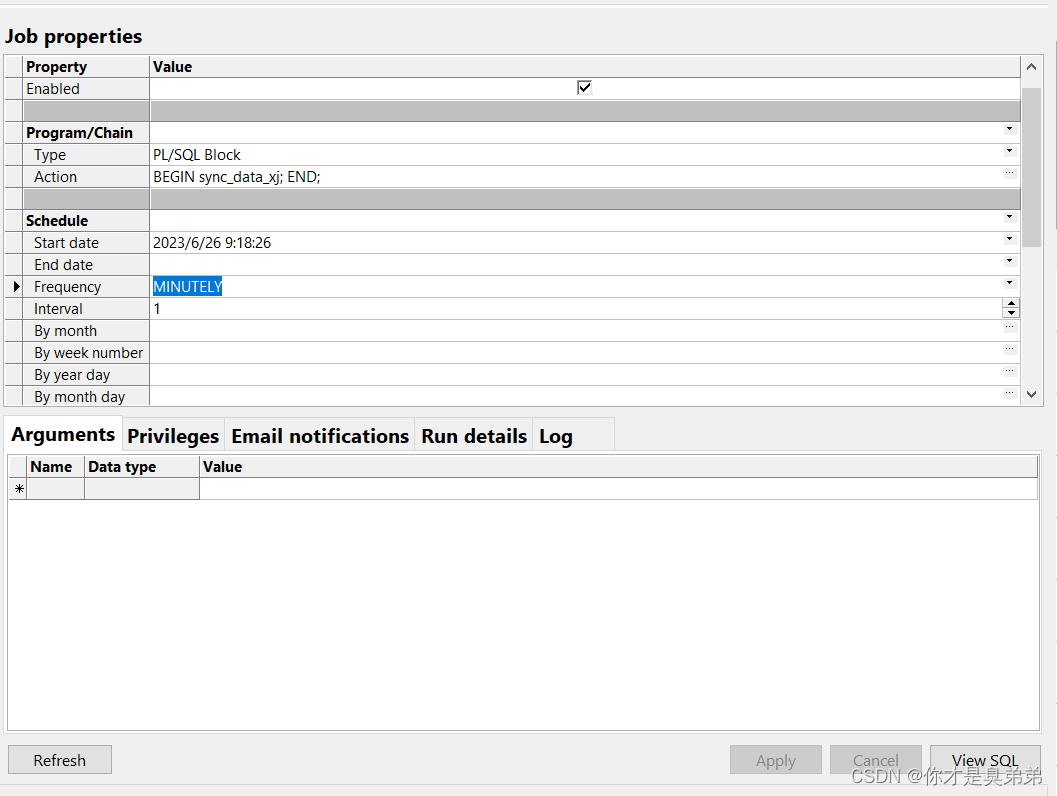
BEGIN DBMS_SCHEDULER.CREATE_JOB ( job_name => 'SYNC_DATA_TASK', job_type => 'PLSQL_BLOCK', job_action => 'BEGIN sync_data_xj; END;', start_date =>SYSDATE, repeat_interval => 'FREQ=MINUTELY;INTERVAL=1;', end_date => NULL, enabled => TRUE);
END;为了演示创建一个名为 SYNC_DATA_TASK 的定时任务,每隔1分钟执行一次 SYNC_DATA_XJ 存储过程。
5、查看执行结果

6、查看定时器
- 查找定时器

- 编辑定时器
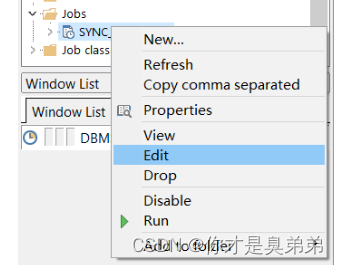
- 可根据业务去修改参数