本篇博客是本人参加Datawhale组队学习第二次任务的笔记
【教程地址】
文章目录
- 基于价值算法和基于策略算法的比较
- 策略梯度算法
- 策略梯度算法的直观理解
- 策略梯度算法
- REINFORCE算法
- 基于平稳分布的策略梯度算法
- REINFORCE算法实现
- 策略函数设计
- 模型设计
- 更新函数设计
- 练习
- 总结
基于价值算法和基于策略算法的比较
-
基于价值的算法是通过学习价值函数来指导策略的,而基于策略的算法则是对策略进行优化,并且通过计算轨迹的价值期望来指导策略的更新
-
基于价值算法的缺点:
-
无法表示连续动作。由于 DQN \text{DQN} DQN 等算法是通过学习状态和动作的价值函数来间接指导策略的,因此它们只能处理离散动作空间的问题,无法表示连续动作空间的问题。而在一些问题中,比如机器人的运动控制问题,连续动作空间是非常常见的,比如要控制机器人的运动速度、角度等等,这些都是连续的量。
-
高方差。基于价值的方法通常都是通过采样的方式来估计价值函数,这样会导致估计的方差很高,从而影响算法的收敛性。尽管一些 DQN \text{DQN} DQN 改进算法,通过改善经验回放、目标网络等方式,可以在一定程度上减小方差,但是这些方法并不能完全解决这个问题。
-
探索与利用的平衡问题。 DQN \text{DQN} DQN 等算法在实现时通常选择贪心的确定性策略,而很多问题的最优策略是随机策略,即需要以不同的概率选择不同的动作。虽然可以通过 ϵ -greedy \epsilon\text{-greedy} ϵ-greedy 策略等方式来实现一定程度的随机策略,但是实际上这种方式并不是很理想,因为它并不能很好地平衡探索与利用的关系。
探索(Exploration):这一方面是关于尝试新的可能性。在算法层面,这意味着偶尔选择不是当前看起来最优的行为,以获得更多信息。
利用(Exploitation):这是基于目前已知信息去做最优决策的过程,即“赚取”阶段。
这两者之间需要权衡,因为过多的探索可能导致错过即时的奖励,而过多的利用则可能陷入局部最优而错过更好的选择。 -
-
相比于 DQN \text{DQN} DQN 之类的基于价值的算法,策略梯度算法的优缺点:
-
优点:
- 适配连续动作空间。将策略描述成一个带有参数 θ \theta θ的连续函数,该函数将某个状态作为输入,输出的不再是某个确定性( deterministic \text{deterministic} deterministic )的离散动作,而是对应的动作概率分布,通常用 π θ ( a ∣ s ) \pi_{\theta}(a|s) πθ(a∣s) 表示,称作随机性( stochastic \text{stochastic} stochastic )策略。
- 适配随机策略。由于策略梯度算法是基于策略函数的,因此可以适配随机策略,而基于价值的算法则需要一个确定的策略。此外其计算出来的策略梯度是无偏的,而基于价值的算法则是有偏的。
-
缺点:
- 采样效率低。由于使用的是蒙特卡洛估计,与基于价值算法的时序差分估计相比其采样速度必然是要慢很多的,这个问题在前面相关章节中也提到过。
- 高方差。虽然跟基于价值的算法一样都会导致高方差,但是策略梯度算法通常是在估计梯度时蒙特卡洛采样引起的高方差,这样的方差甚至比基于价值的算法还要高。
- 收敛性差。容易陷入局部最优,策略梯度方法并不保证全局最优解,因为它们可能会陷入局部最优点。策略空间可能非常复杂,存在多个局部最优点,因此算法可能会在局部最优点附近停滞。
- 难以处理高维离散动作空间:对于离散动作空间,采样的效率可能会受到限制,因为对每个动作的采样都需要计算一次策略。当动作空间非常大时,这可能会导致计算成本的急剧增加。
-
策略梯度算法
策略梯度算法的直观理解
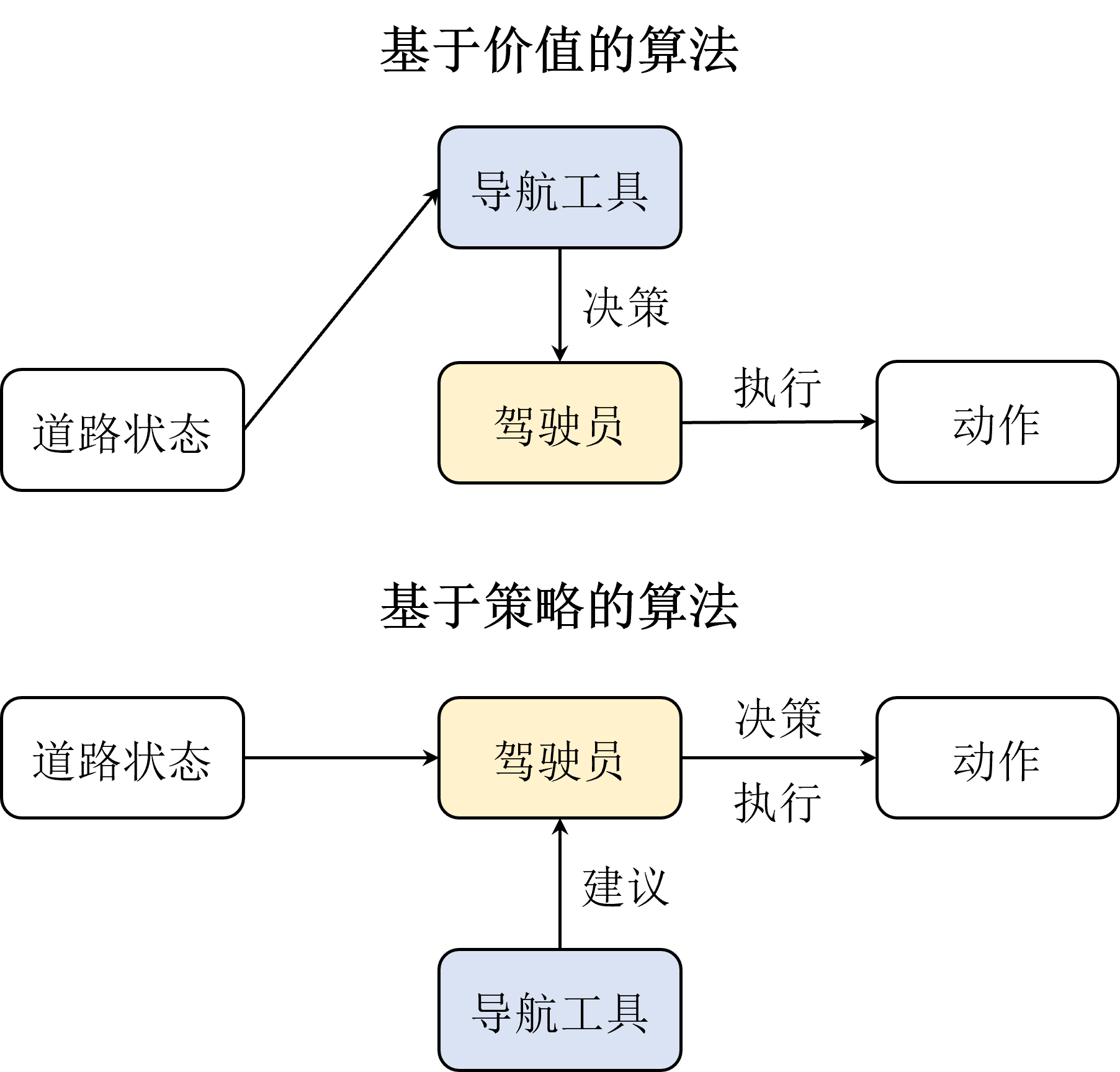
-
基于价值的算法相当于是在学一个地图导航工具,它会告诉并指导驾驶员从当前位置到目的地的最佳路径。但是这样会出现一个问题,就是当地图导航工具在学习过程中产生偏差时会容易一步错步步错,也就是估计价值的方差会很高,从而影响算法的收敛性。
-
而基于策略的算法则是直接训练驾驶员自身,并且同时也在学地图导航,只是这个时候地图导航只会告诉驾驶员当前驾驶的方向是不是对的,而不会直接让驾驶员去做什么。换句话说,这个过程,驾驶员和地图导航工具的训练是相互独立的,地图导航工具并不会干涉驾驶员的决策,只是会给出建议。这样的好处就是驾驶员可以结合经验自己去探索,当导航工具出现偏差的时候也可以及时纠正,反过来当驾驶员决策错误的时候,导航工具也可以及时矫正错误。
策略梯度算法
以下内容仅仅考虑算法流程的完整性,证明过程请参考原书第九章:策略梯度。
我们对生成每条轨迹的概率和相应的奖励的乘积进行求和,可以得到价值期望,我们的目标就是最大化策略的价值期望 。
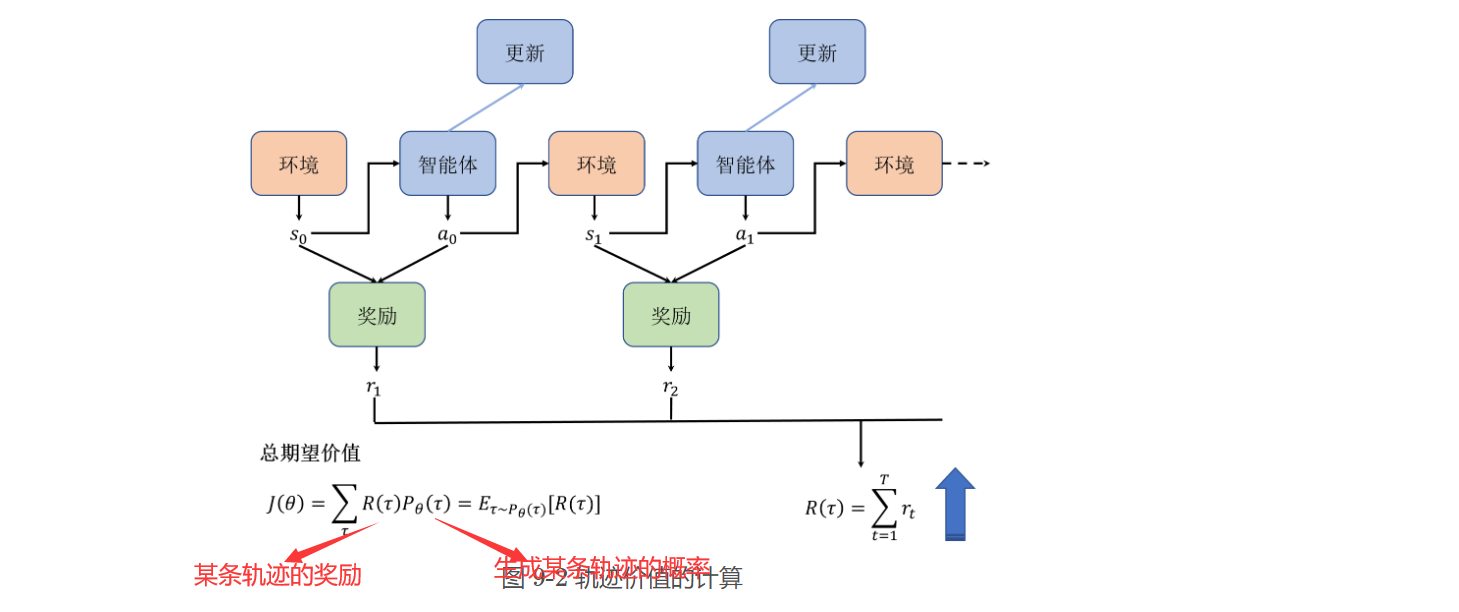
由于我们的目标是最大化目标函数,因此我们使用梯度上升的方法,之后进行一系列计算得到了梯度:
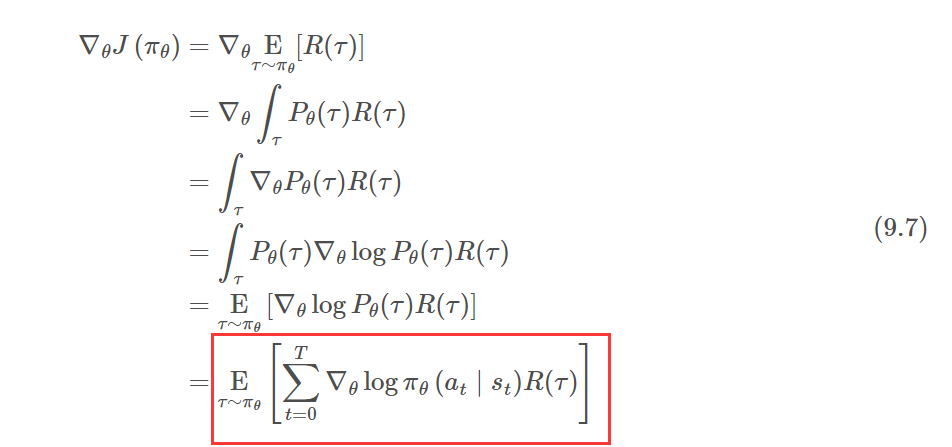
REINFORCE算法
由于采样的轨迹是无限多的,难以进行计算,因此采用蒙特卡洛的方法近似求解,采样一部分且数量足够多的轨迹,然后利用这些轨迹的平均值来近似求解目标函数的梯度。这种方法就是蒙特卡洛策略梯度算法,也称作
REINFORCE \text{REINFORCE} REINFORCE算法
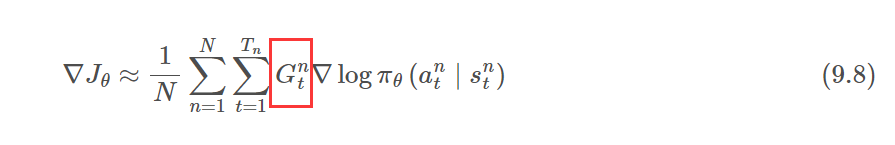
其中 N N N 理论上越大越好,但实际上我们可能只采样几个回合的轨迹就能近似求解梯度了。此外,注意这里我们把奖励函数换成了带有折扣因子的回报 G t n = ∑ k = t T n γ k − t r k n G_{t}^{n}=\sum_{k=t}^{T_{n}} \gamma^{k-t} r_{k}^{n} Gtn=∑k=tTnγk−trkn,其中 T n T_n Tn 表示第 n n n 条轨迹的长度, γ \gamma γ 表示折扣因子, r k n r_{k}^{n} rkn 表示第 n n n 条轨迹在第 k k k 步的奖励。尽管回报计算起来麻烦,但可以结合前面章节讲到的贝尔曼公式将当前时刻和下一时刻的回报联系起来,从而在一定程度上简化计算。
G t = ∑ k = t + 1 T γ k − t − 1 r k = r t + 1 + γ G t + 1 \begin{aligned} G_{t} &=\sum_{k=t+1}^{T} \gamma^{k-t-1} r_{k} \\ &=r_{t+1}+\gamma G_{t+1} \end{aligned} Gt=k=t+1∑Tγk−t−1rk=rt+1+γGt+1
REINFORCE \text{REINFORCE} REINFORCE算法的缺点:
- 最后推导出来的公式实际上不可求,因为理论上有无限条轨迹,所以只能用近似的方法。
- 我们假定了目标是使得每回合的累积价值最大,每回合的累积奖励或回报会受到很多因素的影响,比如回合的长度、奖励的稀疏性等等,泛化性不够。
基于平稳分布的策略梯度算法
基于平稳分布的策略梯度算法克服了 REINFORCE \text{REINFORCE} REINFORCE算法的缺点,在正式介绍它之前先介绍一下平稳的马尔可夫过程。
对于任意马尔可夫链,如果满足以下两个条件:
- 非周期性:由于马尔可夫链需要收敛,那么就一定不能是周期性的,实际上我们处理的问题基本上都是非周期性的,这点不需要做过多的考虑。
- 状态连通性:即存在概率转移矩阵 P P P,能够使得任意状态 s 0 s_0 s0经过有限次转移到达状态 s s s,反之亦然。
\qquad 这样我们就可以得出结论,即该马氏链一定存在一个平稳分布,我们用 d π ( s ) d^{\pi}(s) dπ(s)表示。
d π ( s ) = lim t → ∞ P ( s t = s ∣ s 0 , π θ ) d^\pi(s)=\lim _{t \rightarrow \infty} P\left(s_t=s \mid s_0, \pi_\theta\right) dπ(s)=t→∞limP(st=s∣s0,πθ)
一言以蔽之就是无论初始状态是什么,经过多次概率转移之后都会存在一个稳定的状态分布。

REINFORCE算法实现
最基础的策略梯度算法就是REINFORCE算法,又称作Monte-Carlo Policy Gradient算法。我们策略优化的目标如下:
J θ = Ψ π ∇ θ log π θ ( a t ∣ s t ) J_{\theta}= \Psi_{\pi} \nabla_\theta \log \pi_\theta\left(a_t \mid s_t\right) Jθ=Ψπ∇θlogπθ(at∣st)
其中 Ψ π \Psi_{\pi} Ψπ在REINFORCE算法中表示衰减的回报(具体公式见伪代码),也可以用优势来估计,也就是我们熟知的A3C算法,这个在后面包括GAE算法中都会讲到。
策略函数设计
既然策略梯度是直接对策略函数进行梯度计算,有两种设计方式:
softmax函数:用于离散动作空间
高斯分布 N ( ϕ ( s ) π θ , σ 2 ) \mathbb{N}\left(\phi(\mathbb{s})^{\mathbb{\pi}} \theta, \sigma^2\right) N(ϕ(s)πθ,σ2):多用于连续动作空间
softmax函数可以表示为:
π θ ( s , a ) = e ϕ ( s , a ) T θ ∑ b e ϕ ( s , b ) T T \pi_\theta(s, a)=\frac{e^{\phi(s, a)^{T_\theta}}}{\sum_b e^{\phi(s, b)^{T^T}}} πθ(s,a)=∑beϕ(s,b)TTeϕ(s,a)Tθ
对应的梯度为:
∇ θ log π θ ( s , a ) = ϕ ( s , a ) − E π θ [ ϕ ( s , ) \nabla_\theta \log \pi_\theta(s, a)=\phi(s, a)-\mathbb{E}_{\pi_\theta}[\phi(s,) ∇θlogπθ(s,a)=ϕ(s,a)−Eπθ[ϕ(s,)
高斯分布对应的梯度为:
∇ θ log π θ ( s , a ) = ( a − ϕ ( s ) T θ ) ϕ ( s ) σ 2 \nabla_\theta \log \pi_\theta(s, a)=\frac{\left(a-\phi(s)^T \theta\right) \phi(s)}{\sigma^2} ∇θlogπθ(s,a)=σ2(a−ϕ(s)Tθ)ϕ(s)
但是对于一些特殊的情况,例如在本次演示中动作维度=2且为离散空间,这个时候可以用伯努利分布来实现,这种方式其实是不推荐的,这里给大家做演示也是为了展现一些特殊情况,启发大家一些思考,例如Bernoulli,Binomial,Gaussian分布之间的关系。简单说来,Binomial分布, n = 1 n = 1 n=1时就是Bernoulli分布, n → ∞ n \rightarrow \infty n→∞时就是Gaussian分布。
模型设计
前面讲到,尽管本次演示是离散空间,但是由于动作维度等于2,此时就可以用特殊的高斯分布来表示策略函数,即伯努利分布。伯努利的分布实际上是用一个概率作为输入,然后从中采样动作,伯努利采样出来的动作只可能是0或1,就像投掷出硬币的正反面。在这种情况下,我们的策略模型就需要在MLP的基础上,将状态作为输入,将动作作为倒数第二层输出,并在最后一层增加激活函数来输出对应动作的概率。不清楚激活函数作用的同学可以再看一遍深度学习相关的知识,简单来说其作用就是增加神经网络的非线性。既然需要输出对应动作的概率,那么输出的值需要处于0-1之间,此时sigmoid函数刚好满足我们的需求,实现代码参考如下。
import torch
import torch.nn as nn
import torch.nn.functional as F
class PGNet(nn.Module):def __init__(self, input_dim,output_dim,hidden_dim=128):""" 初始化q网络,为全连接网络input_dim: 输入的特征数即环境的状态维度output_dim: 输出的动作维度"""super(PGNet, self).__init__()self.fc1 = nn.Linear(input_dim, hidden_dim) # 输入层self.fc2 = nn.Linear(hidden_dim,hidden_dim) # 隐藏层self.fc3 = nn.Linear(hidden_dim, output_dim) # 输出层def forward(self, x):x = F.relu(self.fc1(x))x = F.relu(self.fc2(x))x = torch.sigmoid(self.fc3(x))return x
更新函数设计
前面提到我们的优化目标也就是策略梯度算法的损失函数如下:
J θ = Ψ π ∇ θ log π θ ( a t ∣ s t ) J_{\theta}= \Psi_{\pi} \nabla_\theta \log \pi_\theta\left(a_t \mid s_t\right) Jθ=Ψπ∇θlogπθ(at∣st)
我们需要拆开成两个部分 Ψ π \Psi_{\pi} Ψπ和 ∇ θ log π θ ( a t ∣ s t ) \nabla_\theta \log \pi_\theta\left(a_t \mid s_t\right) ∇θlogπθ(at∣st)分开计算,首先看值函数部分 Ψ π \Psi_{\pi} Ψπ,在REINFORCE算法中值函数是从当前时刻开始的衰减回报,如下:
G ← ∑ k = t + 1 T γ k − 1 r k G \leftarrow \sum_{k=t+1}^{T} \gamma^{k-1} r_{k} G←k=t+1∑Tγk−1rk
这个实际用代码来实现的时候可能有点绕,我们可以倒过来看,在同一回合下,我们的终止时刻是 T T T,那么对应的回报 G T = γ T − 1 r T G_T=\gamma^{T-1}r_T GT=γT−1rT,而对应的 G T − 1 = γ T − 2 r T − 1 + γ T − 1 r T G_{T-1}=\gamma^{T-2}r_{T-1}+\gamma^{T-1}r_T GT−1=γT−2rT−1+γT−1rT,在这里代码中我们使用了一个动态规划的技巧,如下:
running_add = running_add * self.gamma + reward_pool[i] # running_add初始值为0
这个公式也是倒过来循环的,第一次的值等于:
r u n n i n g _ a d d = r T running\_add = r_T running_add=rT
第二次的值则等于:
r u n n i n g _ a d d = r T ∗ γ + r T − 1 running\_add = r_T*\gamma+r_{T-1} running_add=rT∗γ+rT−1
第三次的值等于:
r u n n i n g _ a d d = ( r T ∗ γ + r T − 1 ) ∗ γ + r T − 2 = r T ∗ γ 2 + r T − 1 ∗ γ + r T − 2 running\_add = (r_T*\gamma+r_{T-1})*\gamma+r_{T-2} = r_T*\gamma^2+r_{T-1}*\gamma+r_{T-2} running_add=(rT∗γ+rT−1)∗γ+rT−2=rT∗γ2+rT−1∗γ+rT−2
import torch
from torch.distributions import Bernoulli
from torch.autograd import Variable
import numpy as npclass PolicyGradient:def __init__(self, model,memory,cfg):self.gamma = cfg['gamma']self.device = torch.device(cfg['device']) self.memory = memoryself.policy_net = model.to(self.device)self.optimizer = torch.optim.RMSprop(self.policy_net.parameters(), lr=cfg['lr'])def sample_action(self,state):state = torch.from_numpy(state).float()state = Variable(state)probs = self.policy_net(state)m = Bernoulli(probs) # 伯努利分布action = m.sample()action = action.data.numpy().astype(int)[0] # 转为标量return actiondef predict_action(self,state):state = torch.from_numpy(state).float()state = Variable(state)probs = self.policy_net(state)m = Bernoulli(probs) # 伯努利分布action = m.sample()action = action.data.numpy().astype(int)[0] # 转为标量return actiondef update(self):state_pool,action_pool,reward_pool= self.memory.sample()state_pool,action_pool,reward_pool = list(state_pool),list(action_pool),list(reward_pool)# Discount rewardrunning_add = 0for i in reversed(range(len(reward_pool))):if reward_pool[i] == 0:running_add = 0else:running_add = running_add * self.gamma + reward_pool[i]reward_pool[i] = running_add# Normalize rewardreward_mean = np.mean(reward_pool)reward_std = np.std(reward_pool)for i in range(len(reward_pool)):reward_pool[i] = (reward_pool[i] - reward_mean) / reward_std# Gradient Desentself.optimizer.zero_grad()for i in range(len(reward_pool)):state = state_pool[i]action = Variable(torch.FloatTensor([action_pool[i]]))reward = reward_pool[i]state = Variable(torch.from_numpy(state).float())probs = self.policy_net(state)m = Bernoulli(probs)loss = -m.log_prob(action) * reward # Negtive score function x reward# print(loss)loss.backward()self.optimizer.step()self.memory.clear()
练习
- 基于价值和基于策略的算法各有什么优缺点?
- 基于价值的算法:
- 优点有:简单易用:通常只需要学习一个值函数,往往收敛性也会更好。保守更新:更新策略通常是隐式的,通过更新价值函数来间接地改变策略,这使得学习可能更加稳定。
- 缺点有:受限于离散动作;可能存在多个等价最优策略:当存在多个等效的最优策略时,基于价值的方法可能会在它们之间不停地切换。
- 基于策略的算法:
- 后者的优点有:直接优化策略:由于这些算法直接操作在策略上,所以它们可能更容易找到更好的策略;适用于连续动作空间;更高效的探索:通过调整策略的随机性,基于策略的方法可能会有更高效的探索策略。
- 缺点有:高方差:策略更新可能会带来高方差,这可能导致需要更多的样本来学习。可能会收敛到局部最优:基于策略的方法可能会收敛到策略的局部最优,而不是全局最优,且收敛较缓慢。在实践中,还存在结合了基于价值和基于策略方法的算法,即
Actor-Critic \text{Actor-Critic} Actor-Critic 算法,试图结合两者的优点来克服各自的缺点。选择哪种方法通常取决于具体的应用和其特点。
- 马尔可夫平稳分布需要满足什么条件?
状态连通性:从任何一个状态可以在有限的步数内到达另一个状态;
非周期性:由于马尔可夫链需要收敛,那么就一定不能是周期性的。
- REINFORCE \text{REINFORCE} REINFORCE 算法会比 Q-learning \text{Q-learning} Q-learning 算法训练速度更快吗?为什么?
两者的速度不能一概而论,尽管前者往往会比后者慢。主要考虑几个因素:
- 样本效率:因为 REINFORCE \text{REINFORCE} REINFORCE 算法是一个无偏的估计,但其方差可能很高,这意味着为了得到一个稳定和准确的策略更新,它可能需要与环境交互更多的样本,如果与环境交互的成本很高, REINFORCE \text{REINFORCE} REINFORCE
算法将会显得更加劣势。- 稳定性与收敛: Q-learning \text{Q-learning} Q-learning 和其他基于值的方法,特别是当与深度神经网络结合时,可能会遇到训练不稳定的问题。这可能会影响其训练速度。
- 确定性策略与随机性策略的区别?
- 对于同一个状态,确定性策略会给出一个明确的、固定的动作,随机性策略则会为每一个可能的动作(legal action)提供一个概率分布。
- 前者在训练中往往需要额外的探索策略,后者则只需要调整动作概率。
- 但前者相对更容易优化,因为不需要考虑所有可能的动作,但也容易受到噪声的影响。后者则相对更加鲁棒,适用面更广,因为很多的实际问题中,我们往往无法得到一个确定的最优策略,而只能得到一个概率分布,尤其是在博弈场景中。
总结
本文从对比基于价值的算法和基于梯度的算法,分析了它们各自的优缺点,之后用一个直观的例子引入了策略梯度算法,REINFORCE算法用来解决轨迹无限多而无法计算的问题,但是这个算法由于假定了目标是使得每回合的累积价值最大,而每回合的累积奖励或回报会受到很多因素的影响,比如回合的长度、奖励的稀疏性等等,从而泛化性不够。为了解决这个问题,提出了基于平稳分布的策略梯度算法。最后介绍了一下策略函数的实现。