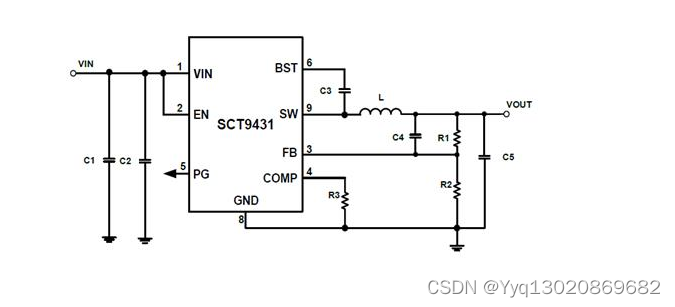
什么是hook?
钩子函数(hook function),可以理解是一个挂钩,作用是有需要的时候挂一个东西上去。具体的解释是:钩子函数是把我们自己实现的hook函数在某一时刻挂接到目标挂载点上。
hook应用场景(一)
相信你对钩子函数并不陌生。我在 requests 和 mitmproxy 都有看到类似的设计。
requests 使用hook
例如 requests 中需要打印状态码:
# requests_hooks.py
import requestsr = requests.get("https://httpbin.org/get")
print(f"status doce: {r.status_code}")
打印状态码,这个动作,我们可以封装到一个函数里,然后作为钩子函数传给requests 使用。
# requests_hooks.py
import requestsdef status_code(response, *args, **kwargs):print(f"hook status doce: {response.status_code}")r = requests.get("https://httpbin.org/get", hooks={"response": status_code})
代码说明:
把打印状态码封装到一个status_code() 函数中,在requests.get() 方法中通过hooks 参数接收钩子函数status_code()。
运行结果:
> python requests_hooks.py
hook status doce: 200
status_code() 作为一个函数,可以做的事情很多,比如,进一步判断状态码,打印响应的数据,甚至对相应的数据做加解密等处理。
mitmproxy 中的hook
mitmproxy是一个代理工具,我们这之前的文章也有做过介绍。在抓包的过程中,同样需要用到 hooks 去对request请求或response响应做一些额外的处理。
# anatomy.py
"""
Basic skeleton of a mitmproxy addon.Run as follows: mitmproxy -s anatomy.py
"""
import loggingclass Counter:def __init__(self):self.num = 0def request(self, flow):self.num = self.num + 1logging.info("We've seen %d flows" % self.num)addons = [Counter()]
运行mitmproxy
> mitmproxy -s anatomy.py
自己实现hook
什么情况下需要实现hook,就是一个功能(类/方法)自身无法满足所有需求,那么可以通过hook 就提供扩展自身能力的可能。
实现hook 并不难,看例子:
import timeclass Programmer(object):"""程序员"""def __init__(self, name, hook=None):self.name = nameself.hooks_func = hookself.now_date = time.strftime("%Y-%m-%d")def get_to_eat(self):print(f"{self.name} - {self.now_date}: eat.")def go_to_code(self):print(f"{self.name} - {self.now_date}: code.")def go_to_sleep(self):print(f"{self.name} - {self.now_date}: sleep.")def everyday(self):# 程序员日常三件事self.get_to_eat()self.go_to_code()self.go_to_sleep()# check the register_hook(hooked or unhooked)# hookedif self.hooks_func is not None:self.hooks_func(self.name)def play_game(name):now_date = time.strftime("%Y-%m-%d")print(f"{name} - {now_date}: play game.")def shopping(name):now_date = time.strftime("%Y-%m-%d")print(f"{name} - {now_date}: shopping.")if __name__ == "__main__":# hook 作为参数传入tom = Programmer("Tom", hook=play_game)jerry = Programmer("Jerry", hook=shopping)spike = Programmer("Spike")# 今日事情tom.everyday()jerry.everyday()spike.everyday()
代码说明:
在上面的例子中Programmer类实现三个功能:eat、code、sleep,但程序员也是普通人,不能每天都只吃饭、编码、睡觉,于是通过register_hook() 提供了做别的事情的能力。
那么,看看Tom、Jerry、Spike三位主角,今天都干了什么吧!
运行结果:
Tom - 2022-12-01: eat.
Tom - 2022-12-01: code.
Tom - 2022-12-01: sleep.
Tom - 2022-12-01: play game.
Jerry - 2022-12-01: eat.
Jerry - 2022-12-01: code.
Jerry - 2022-12-01: sleep.
Jerry - 2022-12-01: shopping.
Spike - 2022-12-01: eat.
Spike - 2022-12-01: code.
Spike - 2022-12-01: sleep.
hook应用场景(二)
如果把hook理解为:定义一个函数,然后作为参数塞到另一个类/方法里。 显然,这只是一种用法。我重新想了一下。httpRunner 的 debugtalk.py 文件; pytest 的 conftest.py 文件,他们本身也是拥有特殊名字的 hook文件。程序在执行的过程中,调用这些文件中的钩子函数完成一些特殊的任务。
以pytest为例子
└───project├───conftest.py└───test_sample.py
- conftest.py
import pytest@pytest.fixture()
def baidu_url():"""定义钩子函数"""return "https://www.baidu.com"- test_sample.py
import webbrowserdef test_open_url(baidu_url):# 调用 baidu_url 钩子函数# 调用 浏览器 访问 baidu_urlwebbrowser.open_new(baidu_url)两个文件看似没有直接的调用关系,在执行 test_sample.py 文件时,可以间接的调用 conftest.py 文件中的baidu_url()钩子函数。
执行测试
> pytest -q test_sample.py
实现动态调用hook
接下来,我们来试试做个类似的功能出来。
└───project├───run_conf.py├───loader.py└───run.py
- run_conf.py
def baidu_url():"""定义钩子函数"""name = "https://www.baidu.com"return name
与 conftest.py 文件类似,在这个文件中实现钩子函数。
- loader.py
import os
import inspect
import importlibdef loader(name):"""动态执行 hook 函数"""# 被调用文件的目录stack_t = inspect.stack()ins = inspect.getframeinfo(stack_t[1][0])file_dir = os.path.dirname(os.path.abspath(ins.filename))# 被调用文件目录下面 *_conf.py 文件all_hook_files = list(filter(lambda x: x.endswith("_conf.py"), os.listdir(file_dir)))all_hook_module = list(map(lambda x: x.replace(".py", ""), all_hook_files))# 动态加载 *_config.pyhooks = []for module_name in all_hook_module:hooks.append(importlib.import_module(module_name))# 根据传过来的 name 函数名,从 *_conf.py 文件查找并执行。for per_hook in hooks:# 动态执行 process 函数func = getattr(per_hook, name)return func()
这个东西就比较复杂了,他的作用就是丢给他一个的函数名, 他能通过*_conf.py文件中查找对应的函数名,并将函数执行结果返回。
loader() 函数是一个通用的东西,你可以把他放到任何位置使用。
- run.py
import webbrowser
from loader import loaderdef test_open_url():# 调用 baidu_url 钩子函数# 调用 浏览器 访问 baidu_urlurl = loader("baidu_url")webbrowser.open_new(url)if __name__ == '__main__':test_open_url()
通过loader() 函数执行baidu_url 钩子函数,并拿到 url。
注意,我们不需要像传统的方式一样from run_conf import baidu_url 导入模块,只要知道钩子函数的名字即可。
这里的实现并没有 pytest 那么优雅,但也比较接近了。