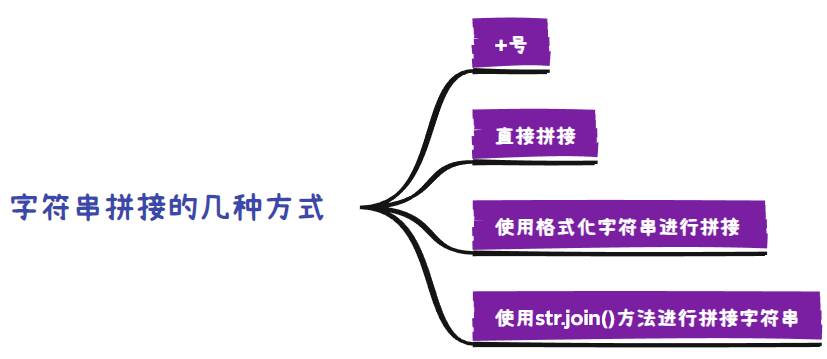
本文讨论一下 BUS 设计中的 DeadLock 死锁问题,或者叫做 Cyclic Dependency 循环依赖问题。其含义是指 A 的动作导致 B 的动作无法进行下去,同样 B 的动作导致 A 的动作无法进行下去,二者相互依赖,形成死锁。
1 AXI握手死锁
在学习 AXI 协议时,手册中提到了 AXI 握手死锁,即 VALID 信号和 READY 信号的握手死锁问题。AXI4 协议中说道:

这里的表述似乎说明,VALID 信号和 READY 信号相互之间不要依赖,即不要根据对方的状态来决定自己是否拉高或拉低。但是在后面的描述中,我们发现了更细致的描述:

不仅是 Write address channel,其他通道的 VALID 信号和 READY 信号也都有类似的规定,再结合前文,我们可以总结成一句话:VALID 和 READY 之间没有依赖关系,谁先谁后都可以,但是源端拉高 VALID 后必须保持住,直到终端拉高 READY。
2 AXI行为死锁
AXI 事务传输中,有两类经常出现的死锁:响应通道死锁和写通道死锁。这两类死锁在 NIC400 中提供了相应的解决方案。
2.1 响应通道死锁
先复习 AXI 顺序模型的两个概念:
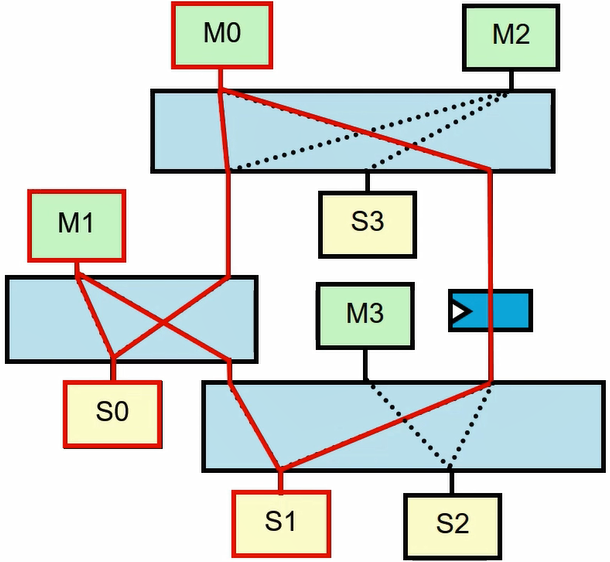
- Master 发出相同 ID 的事务,那么接收响应时必须按照顺序来接收。
- Slave 收到不同 ID 的访问,可以乱序回复响应。(例如DDR经常这样)
(1)问题描述
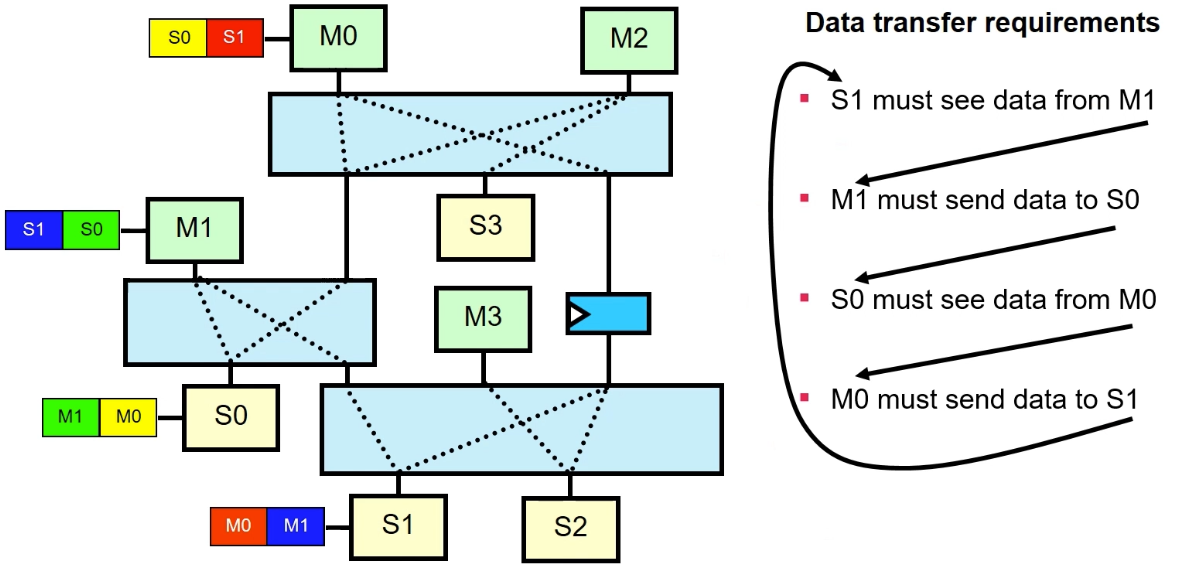
于是乎,在下图的蝴蝶结的结构中,由于 SlaveA 进行了乱序响应,就形成了死锁。

注意,除了读事务在这种结构中会出现死锁问题,写事务响应也同样会出现,因为写事务响应也是可以乱序或者加 RegSlice 的。
(2)解决方案
解决这类问题有两个思路:
- 不要出现蝴蝶形路由结构。
- 不要出现相同ID。
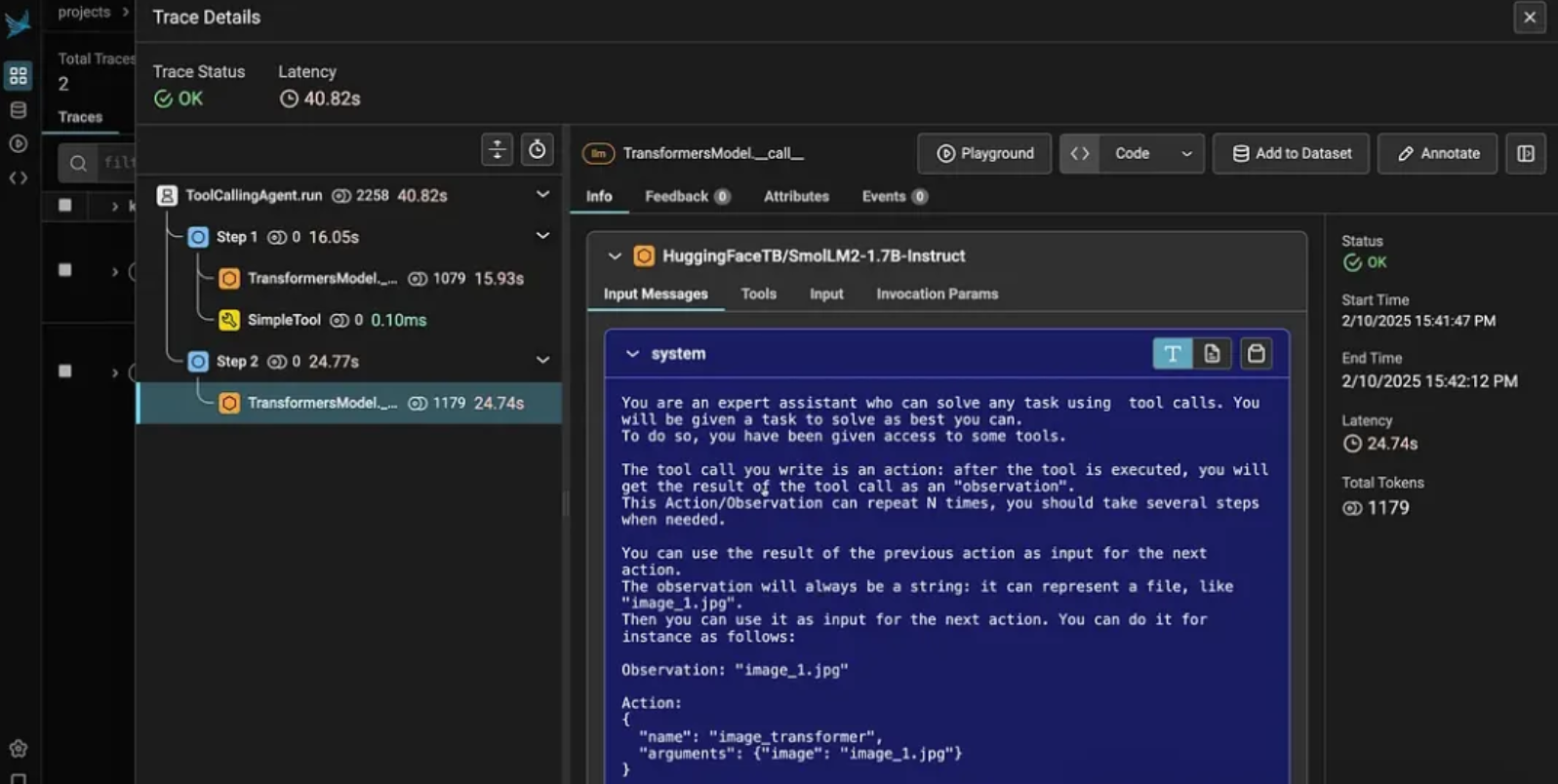
所谓蝴蝶形结构,高度概括一下是可以形成一个逻辑环,事务之间可以饶一个圈圈。这种蝴蝶形结构很容易出现,很多时候没有办法,除了上面画出的单个 Matrix 中会出现蝴蝶形结构,多个 Matrix 之间同样可能出现这种结构,如下图所示:
红色圈起来的部分,简化一下其实也就是上文说的蝴蝶形结构,它同样是形成了一个事务环。想要避免蝴蝶形结构比较难,除了上述看得到的 Slave,在互联中还有看不到的 Default Slave,同样可能构成蝴蝶形结构,真的防不胜防。
既然蝴蝶形结构难以避免,那么可以从“不要出现相同ID”的思路去解决,NIC400 中就此思路提供了两种解决方案:SSPID(Single Slave Per ID)或者 SS(Single Slave)。
- Single Slave Per ID,简称 SSPID,意思是:Master 发出的事务,同一个 ID 只能对应一个 Slave。当出现 Master 发出两个相同 ID 给不同的 SlaveA 和 SlaveB 时,NIC400 将 SlaveB 停滞住,等 SlaveA 的响应回来后,再发送 Slave B 事务,这样就不会出现死锁问题了。
- Single Slave,简称 SS。意思是:不管是啥 ID,总之先完成第一笔事务前,停滞后面的事务,等第一笔事务完成后再发出下一笔事务。简单粗暴,面积小,时序收敛影响小,但是牺牲了 AXI 并发性能,适用于对并发性能无要求的配置通路上。
2.2 写通道死锁
再复习一下 AXI 顺序模型的一个概念:
- AXI3 有 WID,支持交织,但是 WDATA 的第一笔必须和 AW 顺序一致。
- AXI4 没有 WID,不支持交织,WDATA 必须和 AW 顺序一致。
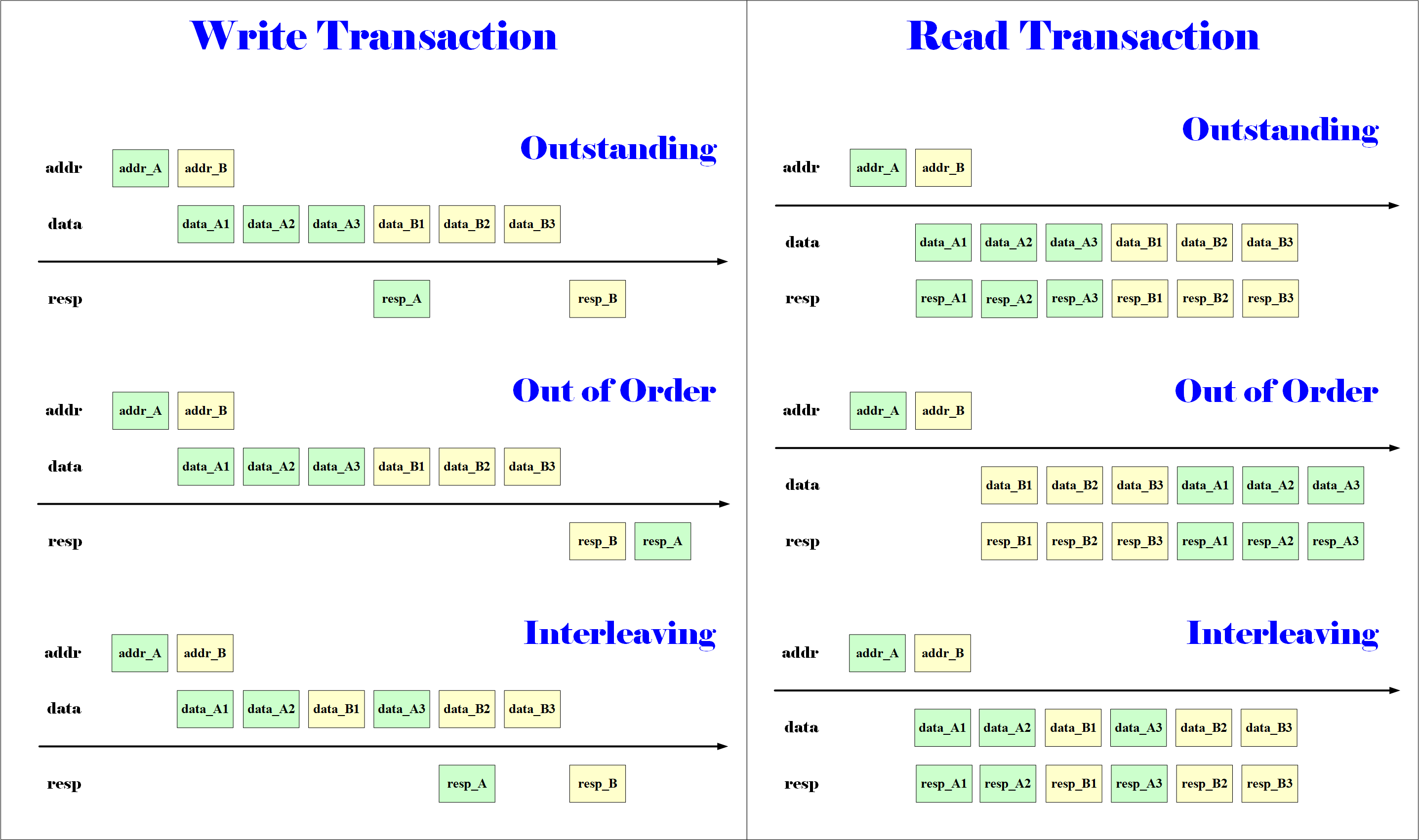
(1)问题描述
不管是 AXI3 还是 AXI4,WDATA 的第一笔必须和 AW 顺序一致,这在某些情况下就会出现死锁问题。
在某次传输中,Master 发出 cmd_A 和 cmd_B,然后发出 data_A 和 data_B,但是 cmd_A 可能由于某种原因出现延迟(例如 SMMU redirect 场景),反而更晚到 Slave,如下所示:
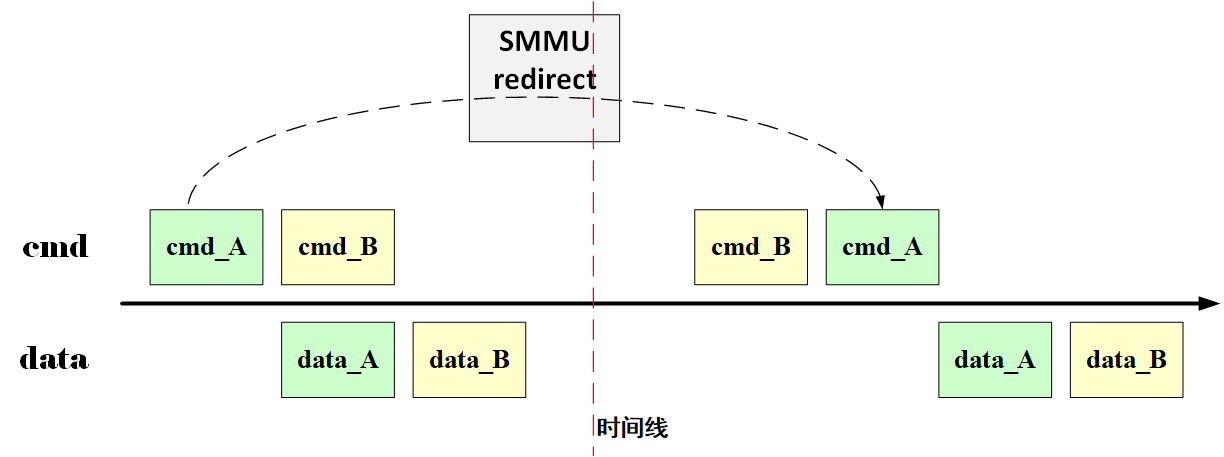
而 Slave 那边要遵循 AXI 协议规定,先收到 cmd_B 自然要先接收 data_B,可是它先得到的又是 data_A,这就出问题了。
这是同一个 Slave 的场景,但是多个 Slave 构成的场景中也可能出现这个问题,例如上面的那个多 Matrix 情况,M0 本来先发送命令到 S1,再发送命令到 S0,但是 M0 到 S1 的路径上存在 RegSlice,导致命令晚于 M1 给 S1 的命令,结果出现死锁。
(2)解决方案
解决这类问题有个思路是:写传输路径添加 ReOrder Buffer,数据到终端前,数据按照 Slave 实际接收的命令顺序传下去。但是弊端是太浪费面积了,ReOrder Buffer 面积很大,得不偿失。
NIC400 中提供了 SAS 和 SS 两种解决方案:
- Single Active Slave,简称 SAS,意思是:上一笔写事务的写数据下发完后,才能发送下一笔写事务的写命令。从而针对性的避免了写通道的死锁问题。
- Single Slave,简称 SS。意思是:不管是啥 ID,总之先完成第一笔事务前,停滞后面的事务,等第一笔事务完成后再发出下一笔事务。简单粗暴,面积小,时序收敛影响小,但是牺牲了 AXI 并发性能,适用于对并发性能无要求的配置通路上。
Single Slave(SS)既可以解决响应通道的死锁问题,也能够解决写通道的死锁问题,就是太暴力了,对性能影响大。
3 拓扑结构死锁
由于 AXI 的信号要求,出现了 AXI 行为死锁,而在 NOC 设计中,会将 AXI 转换为内部的 Packet 包,从而避免单 Matrix 中出现的 AXI 行为死锁。但是 NOC 不是万能的,仍然面临拓扑结构型的死锁。下面列举几种常见的拓扑结构死锁。
3.1 迂回形死锁
迂回型死锁,即 Roundabout 型死锁,指的是进入 Switch 的 Packet 以循环方式互相阻塞住,原本要出去的包和新的进来的包之间具有依赖性,如下所示:
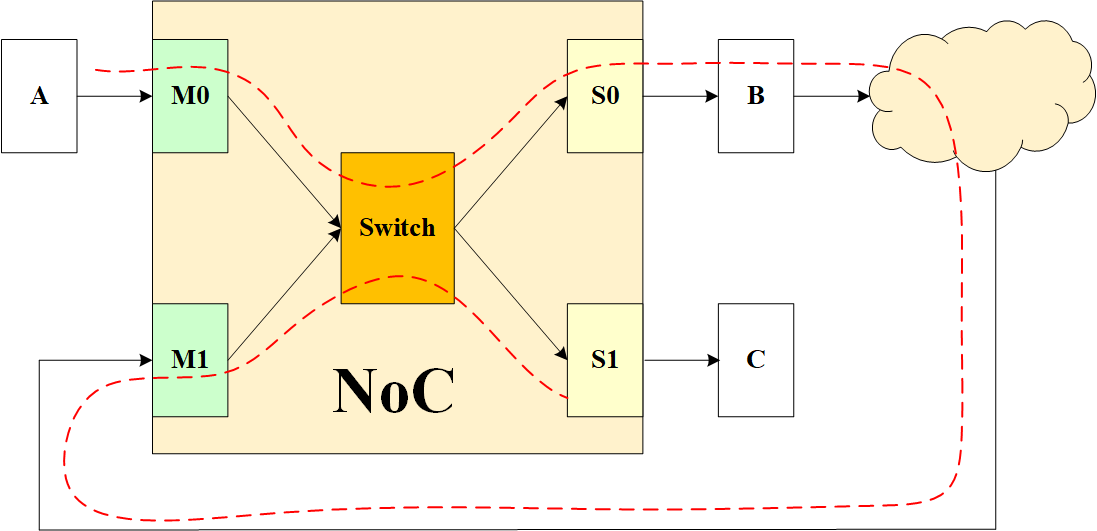
A 发送数据到 NoC 的 M0 端,然后经过 Switch 路由到 S0 端,再给到 B。但是 B 之后经过一系列别的路由,饶了一圈到 NoC 的 M1 端,然后经过 Switch,到达 S1 端,最后到达目的地 C。这种结构会出现死锁,原因是 M0 到 Switch 的 VALID 信号会占住 Switch,使得后面 M1 要使用 Switch 时无法抢占。S0 出去和 M1 进来之间形成依赖,造成死锁。
3.2 拆分重组死锁
拆分重组死锁,即事务被拆分后,Response 的拆分段会锁住一个等待其他 Response 段的响应路径的 Switch,如下所示:
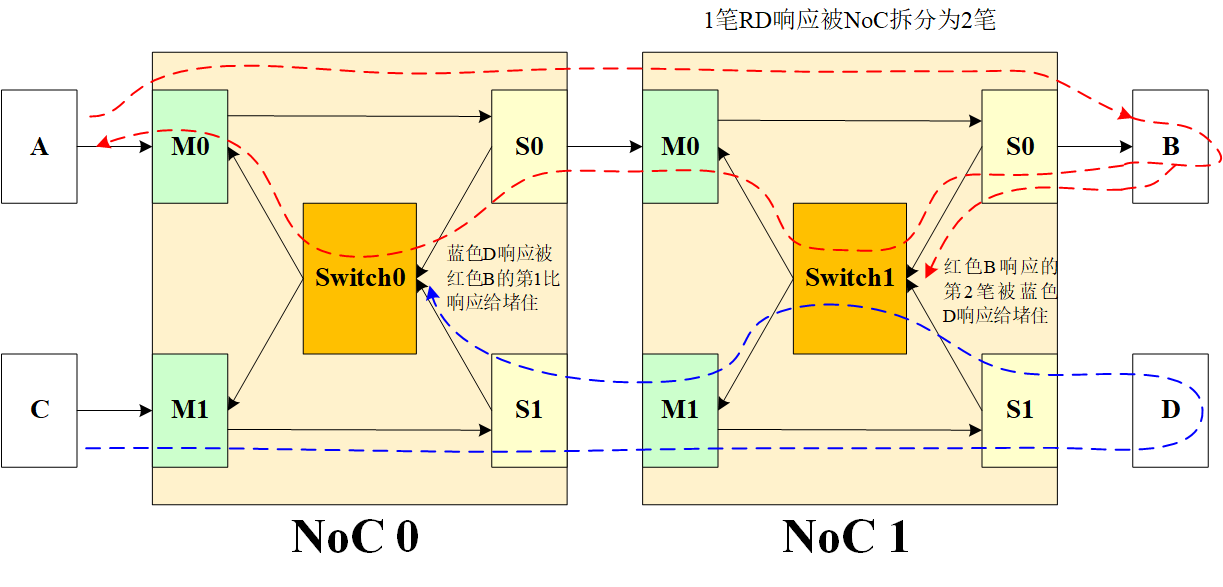
A 的路径为红色,经过 NoC 0 和 NoC 1 到达 B,但是中途经过 NoC 时,原本 1 笔读命令被拆分为 2 笔读命令(NoC 特性,是否拆分读响应看情况,有它的一套规则),于是 B 要回复两笔读响应。此时 C 也发送数据,路径为蓝色,经过 NoC 0 和 NoC 1 后到达 D,然后 D 回复响应。可是在某种情况下,这会形成死锁,在 Switch0 处,B 响应的第 1 笔占到了仲裁,D 响应于是在这里等待。但是在 Switch1 处,D 响应占到了仲裁,B 响应的第 2 笔无法通过。于是乎,A 在等待第二笔读响应,也就是 Switch0 在等待第 2 笔读响应前不会释放仲裁,但是 D 响应由于没有达到 C,就一直占着 Switch1,于是形成了死锁。
3.3 回环死锁
NoC 可以设计为 Ring 结构,每一个 Switch 上都挂有 Master 和 Slave,如下所示:
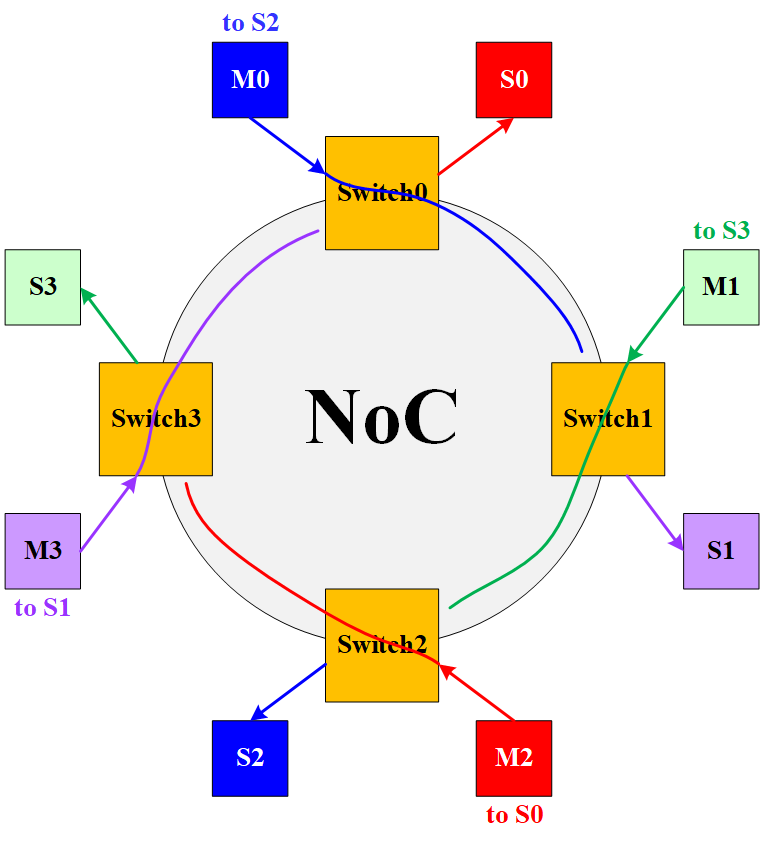
如果每个 Master 发出的包都很长,则会出现死锁,因为每个包都在走,但是都走不完,被阻塞住了。
Ring 结构是一种比较极端的拓扑结构,其实不需要 Ring 结构,我们衍生一下,其他拓扑结构也可能出现类似问题,例如其中一条通路的事务无法完成(可能Slave Buffer设计不合理,满了),从而影响到了另一条通路的事务无法完成,这在实际项目中也是常见的
3.4 解决方案
这类拓扑结构型死锁,目前没有很好的解决方案,有一种方案是将所有项目中的所有总线做在同一个 BUS 工程上,然后用 BUS 工具内部的 DeadLock 检测算法去检查死锁,其内部的检测算法究竟是怎么做的不得而知。
可是如果真的这样做,至少会带来两个问题:一是当出现某处改动时,往往牵一发而动全身,重新生成总线后,需要各个 Sys Owner 重新集成各自的总线模块,消耗大量人力。二是如此巨大的 BUS 工程,那么多的 Master 和 Slave,容易造成 BUS 工具的 GUI 界面卡死,破坏心情。
4 读写依赖死锁
很多 NoC IP 在设计时,都会采用读写共用通道,这在不会同时出现大量并发的读操作和写操作时,对节省走线是有巨大帮助的。然而如果 Master 或 Slave 的读写存在某种依赖,则会导致共用读写通道的 NoC 总线出现死锁现象。
4.1 NoC+Master型
某些 Master IP 在设计时,读写 Buffer 共享(如某些 DMA),只有 Buffer 里读到有一定数据时,才能够允许发送写数据。某次传输时,Master IP 发送了过多的读命令,而其 Buffer 深度不足以存储所有的读数据,但是它可以继续发写命令,这可以让 Buffer 释放一些空间,但是 NoC 采用了读写共用通道,也就是说此时 NoC 里都是读命令,无法接收写命令,于是卡死在这了,形成了 DeadLock。
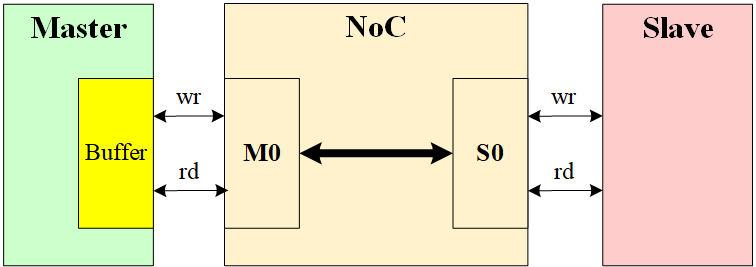
4.2 NoC+Slave型
某些 Slave IP 在设计时,读写 Buffer 共享(如 DDR),只有Slave Buffer 里的读数据往上游排出,才能接收写数据。NoC + Slave 型死锁出现了,例如这时恰好 NoC 里都是写命令和写数据,但是下游 Slave 接收不了,必须先读走,NoC 又正在传输写数据,无法读走 Slave 提供的读数据,于是卡死在这了,形成了 DeadLock。实际情况中如果上游是连续读,可能中间不会出现写命令和写数据,但是读得差不多了,Master 开始发送写命令和写数据,此时 NoC 需要等读数据完全回给上游后,才能腾出通道处理写命令和写数据,这就会造成带宽下降。
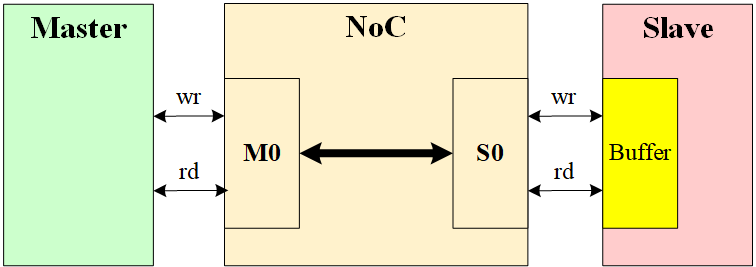
4.3 验证方法
读写依赖死锁可以在验证时发现,具体可以这样做:
- 连续发送足够多的写命令,直到下游无法继续接收写命令(AW_READY=0),立即将 B_READY=0,然后发送读命令,观察是否能完成。
- 连续发送足够多的读命令,直到下游无法继续接收读命令(AR_READY=0),立即将 R_READY=0,然后发送写命令,观察是否能完成。
4.4 解决方案
Master、NoC、Slave,三者单独的读写共享都没有违反 AXI 协议规定,都没有什么问题,但是三者中的任意两个连在一起,就会形成读写依赖死锁。解决方案有以下几种:
- 修改 Master 和 Slave 的读写依赖性。某些情况下可能难以做到,例如有些设计本身就是要先读回数据,运算后再写出去。那么可以这么做:
- 增大共享 Buffer,缺点是有时候开销过大。
- 读数据未完成前,不要发送写命令。
- 修改总线设计,不采用读写共用通道,解决死锁或带宽下降问题。
- 修改 NoC 设计,不管是 FlexNoC 还是 NI-700,都可以将读写共用通道修改为读写分开通道,当然这会增加走线和开销。
- 弃用 NoC 设计,改用 NIC400 等读写分开通道的 BUS IP。
参考资料:
[1] AMBA® AXI™ and ACE™ Protocol Specification
[2] SOC常见问题-axi deadlock
[3] NIC400总线死锁成因及解决方法
[4] 移知课程:AXI课程