优化器学习
把搭建好的模型拿来训练,得到最优的参数。
import torch.optim
import torchvision
from torch import nn
from torch.nn import Sequential, Conv2d, MaxPool2d, Flatten, Linear
from torch.utils.data import DataLoaderdataset = torchvision.datasets.CIFAR10("../data", train=False, transform=torchvision.transforms.ToTensor(),download=True)
dataloader = DataLoader(dataset, batch_size=1)
class Tudui(nn.Module):def __init__(self):super(Tudui, self).__init__()self.model1 = Sequential(Conv2d(3, 32, 5, padding=2),MaxPool2d(2),Conv2d(32, 32, 5, padding=2),MaxPool2d(2),Conv2d(32, 64, 5, padding=2),MaxPool2d(2),Flatten(),Linear(1024, 64),Linear(64, 10))def forward(self, x):x = self.model1(x)return x
#定义loss
loss = nn.CrossEntropyLoss()
tudui = Tudui()
#一开始时采用比较大的学习速率学习,后面用比较小的学习速率学习
optim = torch.optim.SGD(tudui.parameters(), lr=0.01)
for epoch in range(20):#在每一轮学习之前都把loss设置成0#在每一轮的学习过程中计算的loss都加上去#这个数据是表示,在每一轮的学习的过程中在这一轮的整体的loss的求和,整体误差总和running_loss = 0.0for data in dataloader:imgs, targets = dataoutputs = tudui(imgs)result_loss = loss(outputs, targets)optim.zero_grad()#得到每一个可调参数的梯度result_loss.backward()optim.step()#损失函数没有已知在变化,原因是只有单个循环下,只看了一次数据,这一次看到的数据对你下一次看到的数据预测的影响不大# print(result_loss)running_loss = running_loss + result_lossprint(running_loss)在debug的过程中选择最后三行,观察梯度变化
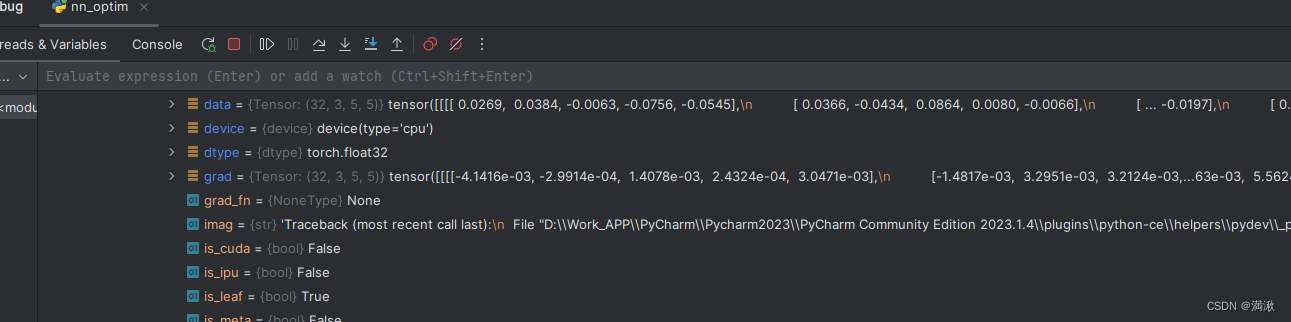 其中optim.step()会把每一步更新的梯度用于数据的更新
其中optim.step()会把每一步更新的梯度用于数据的更新
现有模型的使用和修改


参数:root (string) - ImageNet数据集的根目录。
split (string,可选)-数据集分割,支持train或val。
transform(可调用的,可选的)-一个函数/转换,接收PIL图像并返回转换后的版本。例如,变换。RandomCrop
target_transform (callable, optional) -一个函数/transform,接收目标并对其进行变换。
loader -加载给定路径的图像的函数。

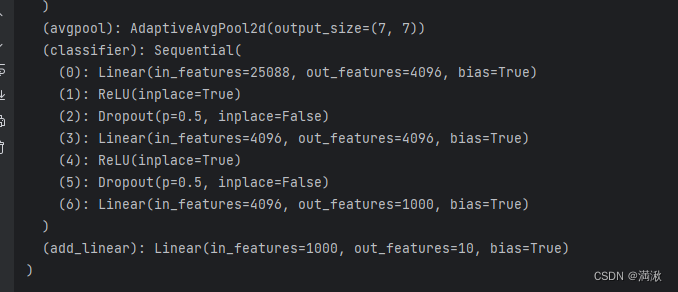
这边看看VGG16,因为它的预训练数据集太大了,不好下载,这边采用CIFAR10代替ImageNet的方法。

然后发现他的线性层输出的特征是1000,也是分1000个类,而CIFAR10只有10个类,这需要对网络模型进行修改,两种思路进行修改。
(1)直接修改最后一个线性层(6),将输出特征改为10
(2)加个线性层(7),输入设置为1000,而输出设置为10
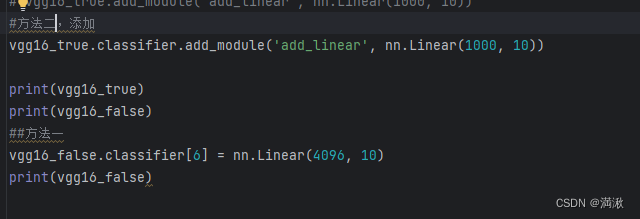
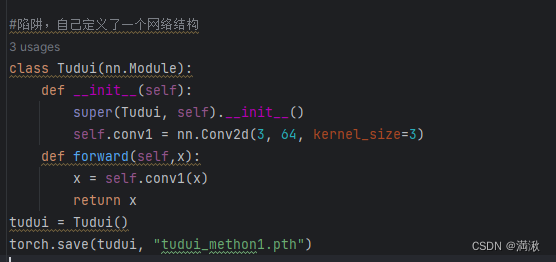
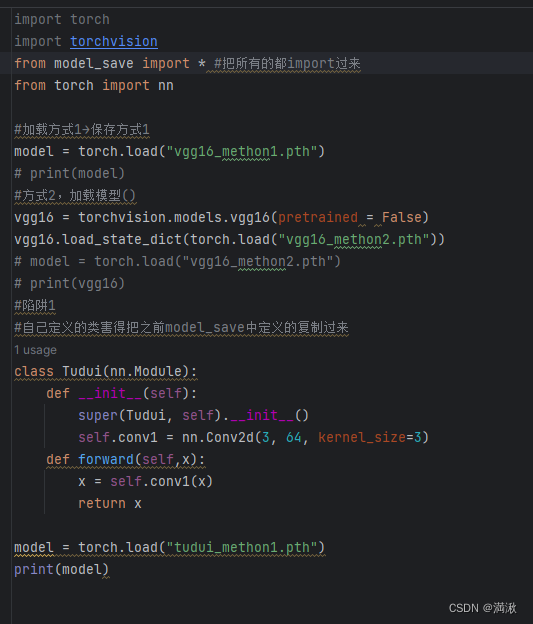
模型的保存和模型的加载
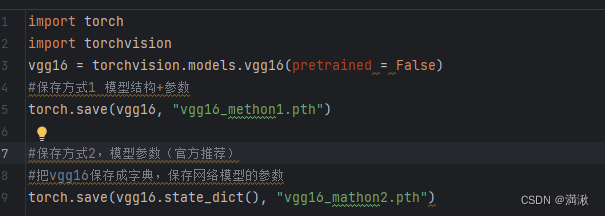
官方推荐的保存下来文件比较小
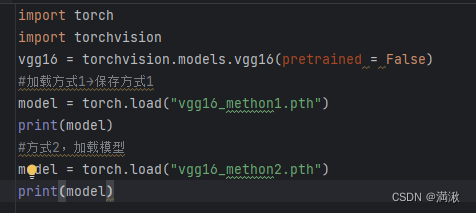
方式2输出的是一个字典形式,要恢复成网络结构,要新建这个模型,然后还要通过字典的形式重建。
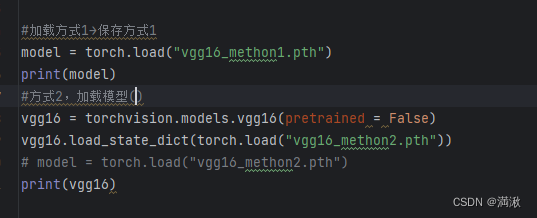
另外要注意用方式1(陷阱)保存的时候要在加载的部分引入你定义的结构否则会报错