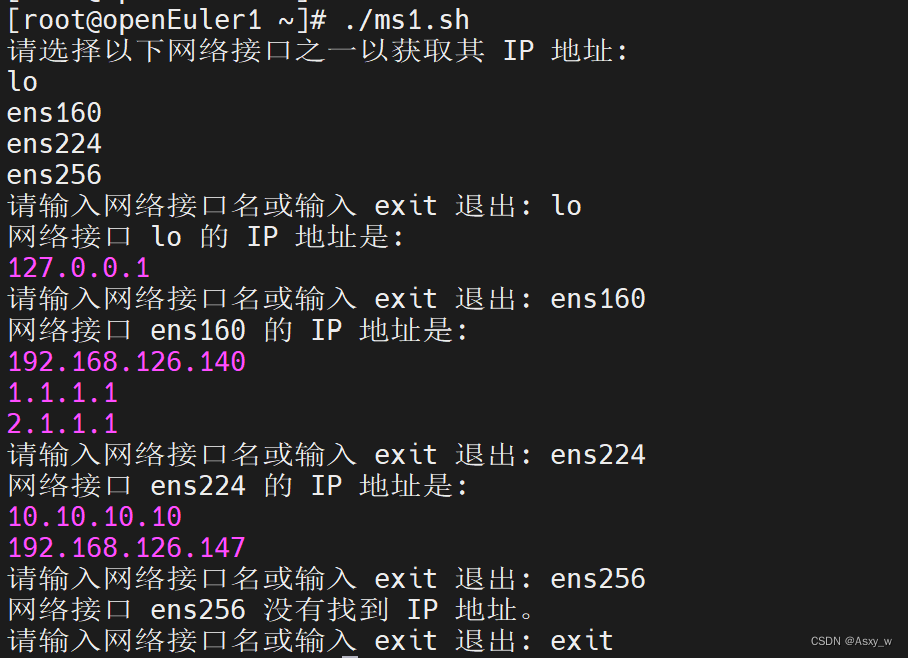
目录
一、树
二、二分搜索树
1.二叉树
2.二分搜索树
三、代码实现
1.树的构建
2.获取树中结点的个数
3.添加元素
4.查找元素
(1)查找元素是否存在
(2)查找最小元素
(3)查找最大元素
5.二分搜索树的遍历
(1)前序遍历:
(2)中序遍历:
(3)后序遍历:
(4)层序遍历:
6.删除操作
(1)删除最小元素
(2)删除最大元素
(3)删除任意元素
(4)删除根节点
一、树
树结构本身是一种天然的组织结构
是一个高效的查询内容的结构
二、二分搜索树
1.二叉树
特点:1.只有唯一的一个根节点
2.每个结点最多有两个孩子
3.每个结点最多有一个父亲
4.二叉树具有天然的递归结构(左右子树也是二叉树)
5.叶子结点出现在二叉树的最底层,除叶子结点之外的其它结点都有两个孩子结点。
2.二分搜索树
是特殊的二叉树
每个节点都大于左子树的所有结点,都小于右子树的所有结点
注意:存储的元素必须具有可比性
因为二分搜索树也是二叉树,也具有天然的递归结构,所以许多方法都可以使用递归的思想去实现
三、代码实现
1.树的构建
需要的元素有:根节点,结点,频率(如果添加的元素有重复元素),结点的值,索引,结点个数
//树的结点private static class Node<T> {private final T ele;//结点的值private int frequence;//频率private Node<T> left, right;//分别指向左右孩子的索引public Node(T ele) {this.ele = ele;this.left = this.right = null;}}//树对应的属性private Node<T> root;//树的根节点private int size;//结点的个数//构建树public BinearySeachTree() {this.root = null;this.size = 0;}在给元素添加泛型后,就不能直接比较,所以在开始就继承Comparable来实现元素的比较
public class BinearySeachTree<T extends Comparable<T>>{}2.获取树中结点的个数
//获取树中结点的个数public int getSize() {return this.size;}3.添加元素
将元素添加到二分搜索树的过程中,要注意将大的元素放在结点的右边,小的元素放在左边
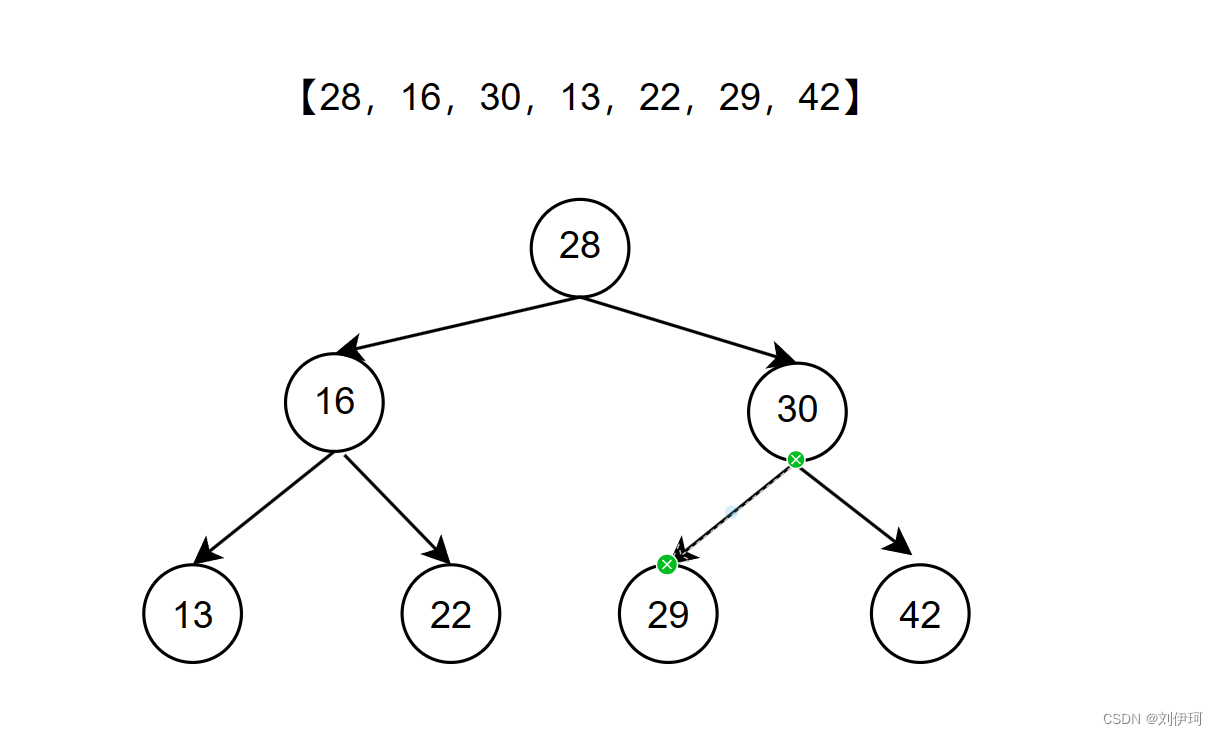
再添加元素时,需要找到对应的位置,则可以使用递归的思想。
如果添加的值小于结点的值,则查找结点左孩子,如果还是小于结点,则继续查找
//向树中添加结点public void add(T ele) {//更新根结点this.root = addDG(this.root, ele);}//语义:向以root为根的二分搜索树中添加元素eleprivate Node<T> addDG(Node<T> root, T ele) {//递归终止条件if (root == null) {this.size++;return new Node<T>(ele);}//递归操作if (root.ele.compareTo(ele) > 0) {root.left = addDG(root.left, ele);} else if (root.ele.compareTo(ele) < 0) {root.right = addDG(root.right, ele);} else {//更新频率root.frequence++;}return root;}4.查找元素
(1)查找元素是否存在
查找元素是否在二叉树中,查找每一个结点,如果查找元素比当前节点小,就在左子树里重新查找,如果查找元素比当前节点大,就在右子树里重新查找
//查询的方法public boolean search(T ele) {return searchDG(this.root, ele);}//语义:从以root为根的二分搜索树中查找元素eleprivate boolean searchDG(Node<T> root, T ele) {//递归终止的条件if (root == null) {return false;}//递归操作if (root.ele.compareTo(ele) == 0) {return true;} else if (root.ele.compareTo(ele) > 0) {return searchDG(root.left, ele);} else {return searchDG(root.right, ele);}}(2)查找最小元素
二分搜索树中最左边的元素
//找树中的最小元素public T getMinValue() {if (this.isEmpty()) {return null;}Optional<Node<T>> optional = getMinNode();return optional.get().ele;}//直接查找
private Optional<Node<T>> getMinNode() {if (this.root == null) {return Optional.empty();}//一直向左查找Node<T> node = this.root;while (node.left != null) {node = node.left;}return Optional.of(node);}//利用递归方法查找//语义:在以Node为根结点的树中查找最小结点private Optional<Node<T>> getMinNode(Node<T> node) {if (node.left == null) {return Optional.of(node);}return getMinNode(node.left);}(3)查找最大元素
二分搜索树中最右边的元素
//找树中的最大元素public T getMaxValue() {if (this.isEmpty()) {return null;}Optional<Node<T>> optional = getMaxNode(this.root);return optional.get().ele;}//语义:在以Node为根结点的树中查找最大结点private Optional<Node<T>> getMaxNode(Node<T> node) {if (node.right == null) {return Optional.of(node);}return getMaxNode(node.right);}
5.二分搜索树的遍历
树的遍历有四种:前序遍历;中序遍历;后序遍历;层序遍历
(1)前序遍历:
首先打印根节点,然后遍历左子树,最后是右子树
【28,16,13,22,30,29,42】
//前序遍历public void preTravel() {List<AbstractMap.SimpleEntry<T, Integer>> list = new ArrayList<>();preTravelDG(this.root, list);String str = list.stream().map(item -> "[" + item.getKey() + ":" + item.getValue() + "]").collect(Collectors.joining("-"));System.out.println(str);}//前序遍历以root为根的树,讲解稿保存在list中private void preTravelDG(Node<T> root, List<AbstractMap.SimpleEntry<T, Integer>> list) {//递归终止条件if (root == null) {return;}//递归操作list.add(new AbstractMap.SimpleEntry<>(root.ele, root.frequence));//遍历左子树preTravelDG(root.left, list);//遍历右子树preTravelDG(root.right, list);}(2)中序遍历:
先遍历左子树,在打印中间结点,最后遍历右子树
【13,16,22,28,29,30,42】
//中序遍历public void midTravel() {List<AbstractMap.SimpleEntry<T, Integer>> list = new ArrayList<>();midTravelDG(this.root, list);String str = list.stream().map(item -> item.toString()).collect(Collectors.joining("-"));System.out.println(str);}//中序遍历以root为根的树,讲解稿保存在list中private void midTravelDG(Node<T> root, List<AbstractMap.SimpleEntry<T, Integer>> list) {//递归终止条件if (root == null) {return;}//递归操作//遍历左子树preTravelDG(root.left, list);list.add(new AbstractMap.SimpleEntry<>(root.ele, root.frequence));//遍历右子树preTravelDG(root.right, list);}(3)后序遍历:
先遍历左子树,在遍历右子树,最后在打印中间结点
【13,22,16,29,42,30,28】
//后序遍历public void sufTravel() {List<AbstractMap.SimpleEntry<T, Integer>> list = new ArrayList<>();sufTravelDG(this.root, list);String str = list.stream().map(item -> item.toString()).collect(Collectors.joining("-"));System.out.println(str);}//后序遍历以root为根的树,讲解稿保存在list中private void sufTravelDG(Node<T> root, List<AbstractMap.SimpleEntry<T, Integer>> list) {//递归终止条件if (root == null) {return;}//递归操作//遍历左子树preTravelDG(root.left, list);//遍历右子树preTravelDG(root.right, list);list.add(new AbstractMap.SimpleEntry<>(root.ele, root.frequence));}可以看到,先中后序遍历的代码区别只是在递归最后将元素添加到list的位置不同而已
(4)层序遍历:
一层一层的打印
【28,16,30,13,22,29,42】
//层序遍历public void levelTravel() {//判断树是否为空if (this.isEmpty()) {return;}Queue<AbstractMap.SimpleEntry<Node<T>, Integer>> queue = new LinkedList<>();//1.先将根结点入队queue.add(new AbstractMap.SimpleEntry<>(this.root, 1));//2.遍历队列while (!queue.isEmpty()) {//2-1.出队AbstractMap.SimpleEntry<Node<T>, Integer> pair = queue.poll();//结点Node<T> node = pair.getKey();//层int level = pair.getValue();;System.out.println("[val:" + node.ele + ",level:" + level + "]");//2-2.判断左右子树是否为空if (node.left != null) {queue.add(new AbstractMap.SimpleEntry<>(node.left, level + 1));}if (node.right != null) {queue.add(new AbstractMap.SimpleEntry<>(node.right, level + 1));}}}
6.删除操作
删除的操作中,需要注意删除后二分搜索树也会因此改变,所以要分情况讨论
(1)删除最小元素
删除最小元素并不需要改变树,只需要失去关联关系即可
//从树中删除最小的结点public T removeMinNode() {T result = getMinValue();if (result == null) {return null;}//更新根结点this.root = removeMinNode(this.root);return result;}//语义:从以Node为根的二分搜索树中删除元素最小的结点private Node<T> removeMinNode(Node<T> node) {//递归终止条件if (node.left == null) {//删除操作//1.记录右子树Node<T> rightTree = node.right;//失去关联关系node.right = null;//3.跟新sizethis.size--;return rightTree;}//递归操作node.left = removeMinNode(node.left);return node;}
(2)删除最大元素
跟删除最小元素一样,只需要失去关联关系即可
//从树中删除最大的结点public T removeMaxNode() {T result = getMaxValue();if (result == null) {return null;}//更新根结点this.root = removeMaxNode(this.root);return result;}//语义:从以Node为根的二分搜索树中删除元素最大的结点private Node<T> removeMaxNode(Node<T> node) {//递归终止条件if (node.right == null) {//删除操作//1.记录左子树Node<T> leftTree = node.left;//失去关联关系node.left = null;//3.跟新sizethis.size--;return leftTree;}//递归操作node.right = removeMaxNode(node.right);return node;}
(3)删除任意元素
在删除任意元素中,需要考虑删除结点有没有左右子树
//语义:从以Node为根的二分搜索树中删除值为ele的结点private Node<T> remove(Node<T> node, T ele) {//递归终止的条件//没有找到if (node == null) {return null;}//找到了if (node.ele.compareTo(ele) == 0) {this.size--;//Node就是要删除的结点if (node.left == null) {Node<T>rightNode=node.right;node.right=null;return rightNode;} else if (node.right == null) {Node<T>leftNode=node.left;node.left=null;return leftNode;} else {Node<T> suffixNode = getMinNode(node.right).get();suffixNode.right=removeMinNode(node.right);suffixNode.left=node.left;this.size++;//失去关联关系node.left=node.right=null;return suffixNode;}}//递归操作if (node.ele.compareTo(ele) > 0) {node.left = remove(node.left, ele);} else {node.right = remove(node.right, ele);}return node;}
(4)删除根节点
直接删除关联关系即可
//删除根节点public void removeRoot(){if(this.root==null){return;}remove(this.root.ele);}四、完整代码
package com.algo.lesson.lesson04;import java.util.*;
import java.util.stream.Collectors;//二分搜索树
/*
保存到结点中的元素值必须具有可比性*/
public class BinearySeachTree<T extends Comparable<T>> {//树的结点private static class Node<T> {private final T ele;//结点的值private int frequence;//频率private Node<T> left, right;//分别指向左右孩子的索引public Node(T ele) {this.ele = ele;this.left = this.right = null;}}//树对应的属性private Node<T> root;//树的根节点private int size;//结点的个数//构建树public BinearySeachTree() {this.root = null;this.size = 0;}//获取树中结点的个数public int getSize() {return this.size;}//向树中添加结点public void add(T ele) {//更新根结点this.root = addDG(this.root, ele);}//语义:向以root为根的二分搜索树中添加元素eleprivate Node<T> addDG(Node<T> root, T ele) {//递归终止条件if (root == null) {this.size++;return new Node<T>(ele);}//递归操作if (root.ele.compareTo(ele) > 0) {root.left = addDG(root.left, ele);} else if (root.ele.compareTo(ele) < 0) {root.right = addDG(root.right, ele);} else {//更新频率root.frequence++;}return root;}//查询的方法public boolean search(T ele) {return searchDG(this.root, ele);}//语义:从以root为根的二分搜索树中查找元素eleprivate boolean searchDG(Node<T> root, T ele) {//递归终止的条件if (root == null) {return false;}//递归操作if (root.ele.compareTo(ele) == 0) {return true;} else if (root.ele.compareTo(ele) > 0) {return searchDG(root.left, ele);} else {return searchDG(root.right, ele);}}//二分搜索树的遍历//前序遍历public void preTravel() {List<AbstractMap.SimpleEntry<T, Integer>> list = new ArrayList<>();preTravelDG(this.root, list);String str = list.stream().map(item -> "[" + item.getKey() + ":" + item.getValue() + "]").collect(Collectors.joining("-"));System.out.println(str);}//中序遍历public void midTravel() {List<AbstractMap.SimpleEntry<T, Integer>> list = new ArrayList<>();midTravelDG(this.root, list);String str = list.stream().map(item -> item.toString()).collect(Collectors.joining("-"));System.out.println(str);}//后序遍历public void sufTravel() {List<AbstractMap.SimpleEntry<T, Integer>> list = new ArrayList<>();sufTravelDG(this.root, list);String str = list.stream().map(item -> item.toString()).collect(Collectors.joining("-"));System.out.println(str);}//前序遍历以root为根的树,讲解稿保存在list中private void preTravelDG(Node<T> root, List<AbstractMap.SimpleEntry<T, Integer>> list) {//递归终止条件if (root == null) {return;}//递归操作list.add(new AbstractMap.SimpleEntry<>(root.ele, root.frequence));//遍历左子树preTravelDG(root.left, list);//遍历右子树preTravelDG(root.right, list);}//中序遍历以root为根的树,讲解稿保存在list中private void midTravelDG(Node<T> root, List<AbstractMap.SimpleEntry<T, Integer>> list) {//递归终止条件if (root == null) {return;}//递归操作//遍历左子树preTravelDG(root.left, list);list.add(new AbstractMap.SimpleEntry<>(root.ele, root.frequence));//遍历右子树preTravelDG(root.right, list);}//后序遍历以root为根的树,讲解稿保存在list中private void sufTravelDG(Node<T> root, List<AbstractMap.SimpleEntry<T, Integer>> list) {//递归终止条件if (root == null) {return;}//递归操作//遍历左子树preTravelDG(root.left, list);//遍历右子树preTravelDG(root.right, list);list.add(new AbstractMap.SimpleEntry<>(root.ele, root.frequence));}//判断树是否为空public boolean isEmpty() {return this.size == 0;}//层序遍历public void levelTravel() {//判断树是否为空if (this.isEmpty()) {return;}Queue<AbstractMap.SimpleEntry<Node<T>, Integer>> queue = new LinkedList<>();//1.先将根结点入队queue.add(new AbstractMap.SimpleEntry<>(this.root, 1));//2.遍历队列while (!queue.isEmpty()) {//2-1.出队AbstractMap.SimpleEntry<Node<T>, Integer> pair = queue.poll();//结点Node<T> node = pair.getKey();//层int level = pair.getValue();;System.out.println("[val:" + node.ele + ",level:" + level + "]");//2-2.判断左右子树是否为空if (node.left != null) {queue.add(new AbstractMap.SimpleEntry<>(node.left, level + 1));}if (node.right != null) {queue.add(new AbstractMap.SimpleEntry<>(node.right, level + 1));}}}//找树中的最小元素public T getMinValue() {if (this.isEmpty()) {return null;}Optional<Node<T>> optional = getMinNode();return optional.get().ele;}//找树中的最大元素public T getMaxValue() {if (this.isEmpty()) {return null;}Optional<Node<T>> optional = getMaxNode(this.root);return optional.get().ele;}private Optional<Node<T>> getMinNode() {if (this.root == null) {return Optional.empty();}//一直向左查找Node<T> node = this.root;while (node.left != null) {node = node.left;}return Optional.of(node);}//递归//语义:在以Node为根结点的树中查找最小结点private Optional<Node<T>> getMinNode(Node<T> node) {if (node.left == null) {return Optional.of(node);}return getMinNode(node.left);}//语义:在以Node为根结点的树中查找最大结点private Optional<Node<T>> getMaxNode(Node<T> node) {if (node.right == null) {return Optional.of(node);}return getMaxNode(node.right);}//删除操作//从树中删除最小的结点public T removeMinNode() {T result = getMinValue();if (result == null) {return null;}//更新根结点this.root = removeMinNode(this.root);return result;}//语义:从以Node为根的二分搜索树中删除元素最小的结点private Node<T> removeMinNode(Node<T> node) {//递归终止条件if (node.left == null) {//删除操作//1.记录右子树Node<T> rightTree = node.right;//失去关联关系node.right = null;//3.跟新sizethis.size--;return rightTree;}//递归操作node.left = removeMinNode(node.left);return node;}//删除操作//从树中删除最大的结点public T removeMaxNode() {T result = getMaxValue();if (result == null) {return null;}//更新根结点this.root = removeMaxNode(this.root);return result;}//语义:从以Node为根的二分搜索树中删除元素最大的结点private Node<T> removeMaxNode(Node<T> node) {//递归终止条件if (node.right == null) {//删除操作//1.记录左子树Node<T> leftTree = node.left;//失去关联关系node.left = null;//3.跟新sizethis.size--;return leftTree;}//递归操作node.right = removeMaxNode(node.right);return node;}//删除任意结点public void remove(T ele) {//根据值查找结点this.root = remove(this.root, ele);}//语义:从以Node为根的二分搜索树中删除值为ele的结点private Node<T> remove(Node<T> node, T ele) {//递归终止的条件//没有找到if (node == null) {return null;}//找到了if (node.ele.compareTo(ele) == 0) {this.size--;//Node就是要删除的结点if (node.left == null) {Node<T>rightNode=node.right;node.right=null;return rightNode;} else if (node.right == null) {Node<T>leftNode=node.left;node.left=null;return leftNode;} else {Node<T> suffixNode = getMinNode(node.right).get();suffixNode.right=removeMinNode(node.right);suffixNode.left=node.left;this.size++;//失去关联关系node.left=node.right=null;return suffixNode;}}//递归操作if (node.ele.compareTo(ele) > 0) {node.left = remove(node.left, ele);} else {node.right = remove(node.right, ele);}return node;}//删除根节点public void removeRoot(){if(this.root==null){return;}remove(this.root.ele);}}
五、例题
1.700. 二叉搜索树中的搜索
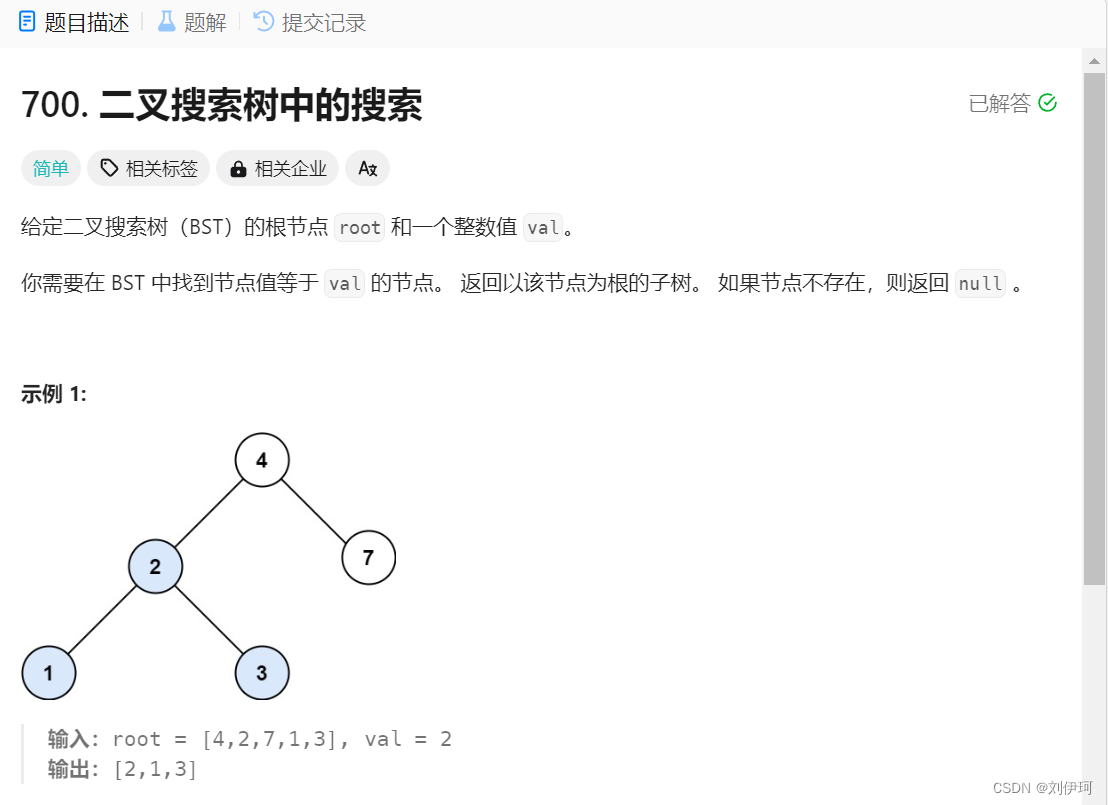
class Solution {public TreeNode searchBST(TreeNode root, int val) {if(root==null){return null;}if(val==root.val){return root;}return searchBST(val<root.val?root.left:root.right,val);}
}2.力扣(LeetCode)官网 - 全球极客挚爱的技术成长平台
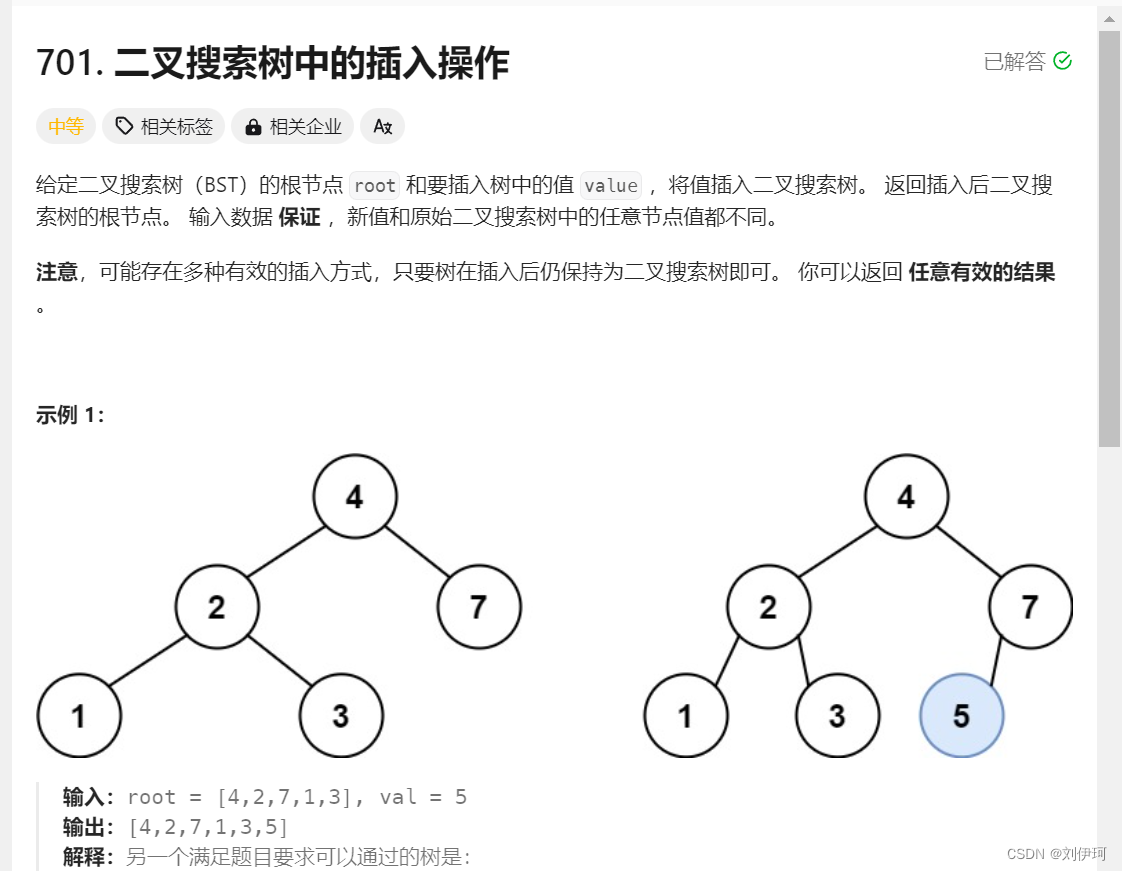
class Solution {public TreeNode insertIntoBST(TreeNode root, int val) {
//更新根结点return root = addDG(root, val);}//语义:向以root为根的二分搜索树中添加元素eleprivate TreeNode addDG(TreeNode root, int val) {//递归终止条件if (root == null) {return new TreeNode(val);}//递归操作if (root.val>val) {root.left = addDG(root.left, val);} else if (root.val<val) {root.right = addDG(root.right, val);}return root;}
}3.力扣(LeetCode)官网 - 全球极客挚爱的技术成长平台
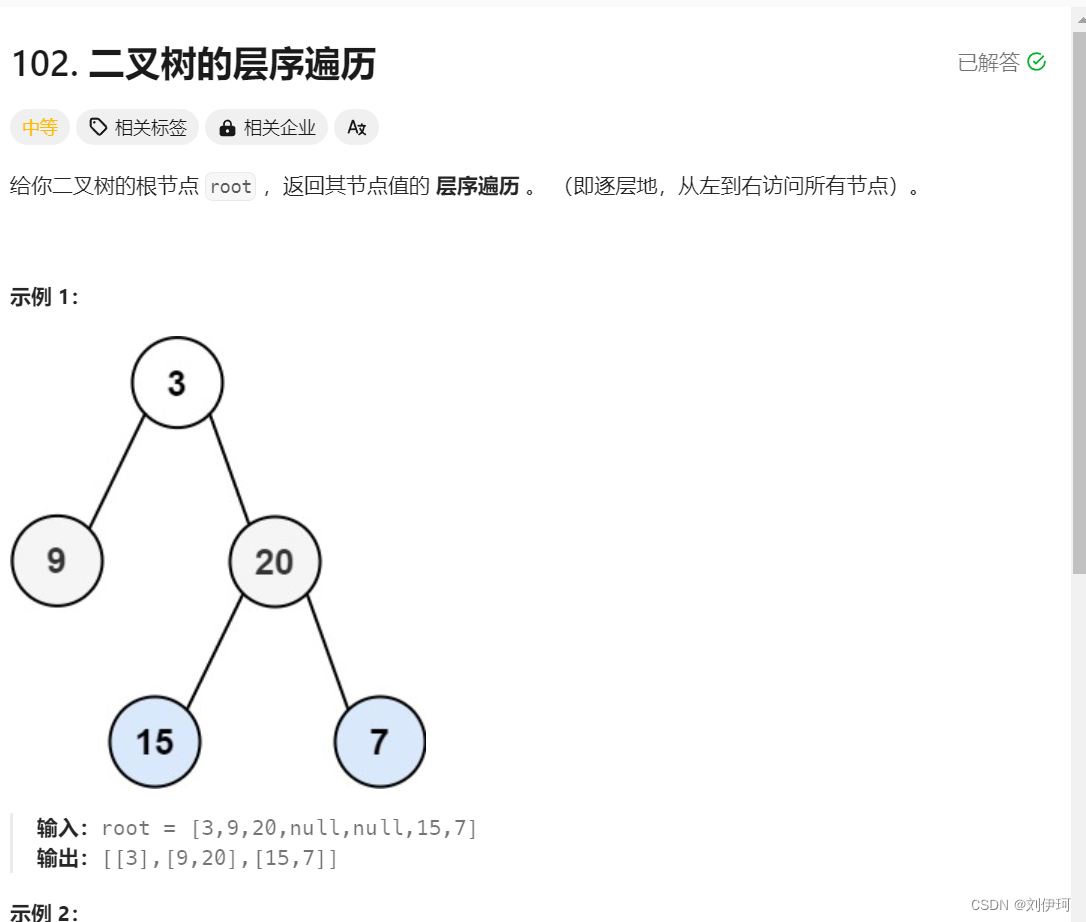
class Solution {public List<List<Integer>> levelOrder(TreeNode root) {List<List<Integer>> list = new ArrayList<List<Integer>>();if (root == null) {return list;}Queue<TreeNode> queue = new LinkedList<TreeNode>();queue.offer(root);while (!queue.isEmpty()) {List<Integer> level = new ArrayList<Integer>();int temp = queue.size();for (int i = 1; i <= temp; i++) {TreeNode node = queue.poll();level.add(node.val);if (node.left != null) {queue.offer(node.left);}if (node.right != null) {queue.offer(node.right);}}list.add(level);}return list;}
}