🧡💛💚TensorFlow2实战-系列教程 总目录
有任何问题欢迎在下面留言
本篇文章的代码运行界面均在Jupyter Notebook中进行
本篇文章配套的代码资源已经上传
1、迁移学习
- 用已经训练好模型的权重参数当做自己任务的模型权重初始化
- 一般全连接层需要自己训练,可以选择是否训练已经训练好的特征提取层
一般情况下根据自己的任务,选择对那些网络进行微调和重新训练:
如果预训练模型的任务和自己任务非常接近,那可能只需要把最后的全连接层重新训练即可
如果自己任务的数据量比较小,那么应该选择重新训练少数层
如果自己任务的数据量比较大,可以适当多选择几层进行训练
2、猫狗识别
import os
import warnings
warnings.filterwarnings("ignore")
import matplotlib.pyplot as plt
import tensorflow as tf
from tensorflow.keras.optimizers import Adam
from tensorflow.keras.preprocessing.image import ImageDataGenerator
from tensorflow.keras import layers
from tensorflow.keras import Model
base_dir = './data/cats_and_dogs'
train_dir = os.path.join(base_dir, 'train')
validation_dir = os.path.join(base_dir, 'validation')train_cats_dir = os.path.join(train_dir, 'cats')
train_dogs_dir = os.path.join(train_dir, 'dogs')validation_cats_dir = os.path.join(validation_dir, 'cats')
validation_dogs_dir = os.path.join(validation_dir, 'dogs')
前面的内容和TensorFlow2实战-系列教程3:猫狗识别1完全一样
3、加载预训练模型
from tf.keras.applications.resnet import ResNet50
from tensorflow.keras.applications.resnet import ResNet101
from tensorflow.keras.applications.inception_v3 import InceptionV3
从keras中导入预训练模型,在TensorFlow的keras模块,有很多可以直接导入的预训练权重。
pre_trained_model = ResNet101(input_shape = (75, 75, 3), include_top = False, weights = 'imagenet')
- 加载导入的模型
- input_shape 为输入大小
- include_top为False就是表示不要最后的全连接层
- 这段代码执行后,会自动进行下载
downloading data from
https://storage.googleapis.com/tensorflow/kerasapplications/resnet/resnet101_weights_tf_dim_ordering_tf_kernels_notop.h5
171446536/171446536 [==============================] - 15s 0us/step
for layer in pre_trained_model.layers:layer.trainable = False
选择要进行重新训练的层
4、callback模块
在 TensorFlow 中,回调(Callbacks)是一个强大的工具,用于在训练的不同阶段(例如在每个时代的开始和结束、在每个批次的处理前后)自定义和控制模型的行为,相当于一个监视器:
4.1 callback示例
callbacks = [
# 如果连续两个epoch还没降低就停止:tf.keras.callbacks.EarlyStopping(patience=2, monitor='val_loss'),
# 可以动态改变学习率:tf.keras.callbacks.LearningRateScheduler
# 保存模型:tf.keras.callbacks.ModelCheckpoint
# 自定义方法:tf.keras.callbacks.Callback
]
上面是一个模板,继续我们的猫狗识别的迁移学习项目:
4.2 定义callback
class myCallback(tf.keras.callbacks.Callback):def on_epoch_end(self, epoch, logs={}):if(logs.get('acc')>0.95):print("\nReached 95% accuracy so cancelling training!")self.model.stop_training = True
- 定义一个类,继承Callback
- 定义一个函数,传入epoch值和日志
- 从当前epoch的日志中取出准确率,如果准确率大于95%
- 打印信息
- 停止训练
from tensorflow.keras.optimizers import Adam
x = layers.Flatten()(pre_trained_model.output)
x = layers.Dense(1024, activation='relu')(x)
x = layers.Dropout(0.2)(x)
x = layers.Dense(1, activation='sigmoid')(x)
model = Model(pre_trained_model.input, x)
model.compile(optimizer = Adam(lr=0.001), loss = 'binary_crossentropy', metrics = ['acc'])
- 导入优化器
- 将预训练模型的输出展平为一维
- 定义一个1024的全连接层
- 在这层加入dropout
- 输出全连接层
- 构建模型
- 指定优化器、损失函数、验证方法等配置训练器
5、模型训练
定义需要重新训练的层
train_datagen = ImageDataGenerator(rescale = 1./255.,rotation_range = 40,width_shift_range = 0.2,height_shift_range = 0.2,shear_range = 0.2,zoom_range = 0.2,horizontal_flip = True)test_datagen = ImageDataGenerator( rescale = 1.0/255. )train_generator = train_datagen.flow_from_directory(train_dir,batch_size = 20,class_mode = 'binary', target_size = (75, 75)) validation_generator = test_datagen.flow_from_directory( validation_dir,batch_size = 20,class_mode = 'binary', target_size = (75, 75))
前面的内容和TensorFlow2实战-系列教程3:猫狗识别1一样,制作数据
callbacks = myCallback()
history = model.fit_generator(train_generator,validation_data = validation_generator,steps_per_epoch = 100,epochs = 100,validation_steps = 50,verbose = 2,callbacks=[callbacks])
指定训练参数、数据、加入callback模块到模型中,执行训练,verbose = 2表示每次epoch记录一次日志
打印结果:
Epoch 99/100 100/100 - 76s - loss: 0.6138 - acc: 0.6655 - val_loss: 0.6570 - val_acc: 0.6900
Epoch 100/100 100/100 - 76s - loss: 0.5993 - acc: 0.6735 - val_loss: 0.7176 - val_acc: 0.6910
6、预测效果展示
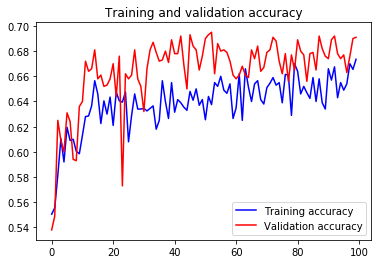
import matplotlib.pyplot as plt
acc = history.history['acc']
val_acc = history.history['val_acc']
loss = history.history['loss']
val_loss = history.history['val_loss']epochs = range(len(acc))plt.plot(epochs, acc, 'b', label='Training accuracy')
plt.plot(epochs, val_acc, 'r', label='Validation accuracy')
plt.title('Training and validation accuracy')
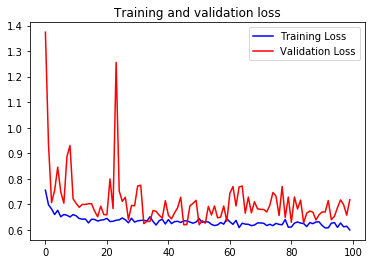
plt.legend()plt.figure()plt.plot(epochs, loss, 'b', label='Training Loss')
plt.plot(epochs, val_loss, 'r', label='Validation Loss')
plt.title('Training and validation loss')
plt.legend()
plt.show()