使用 bert-base-chinese 预训练模型做词嵌入(文本转向量)
模型下载:bert预训练模型下载-CSDN博客
参考文章:使用bert提取词向量
下面这段代码是一个传入句子转为词向量的函数
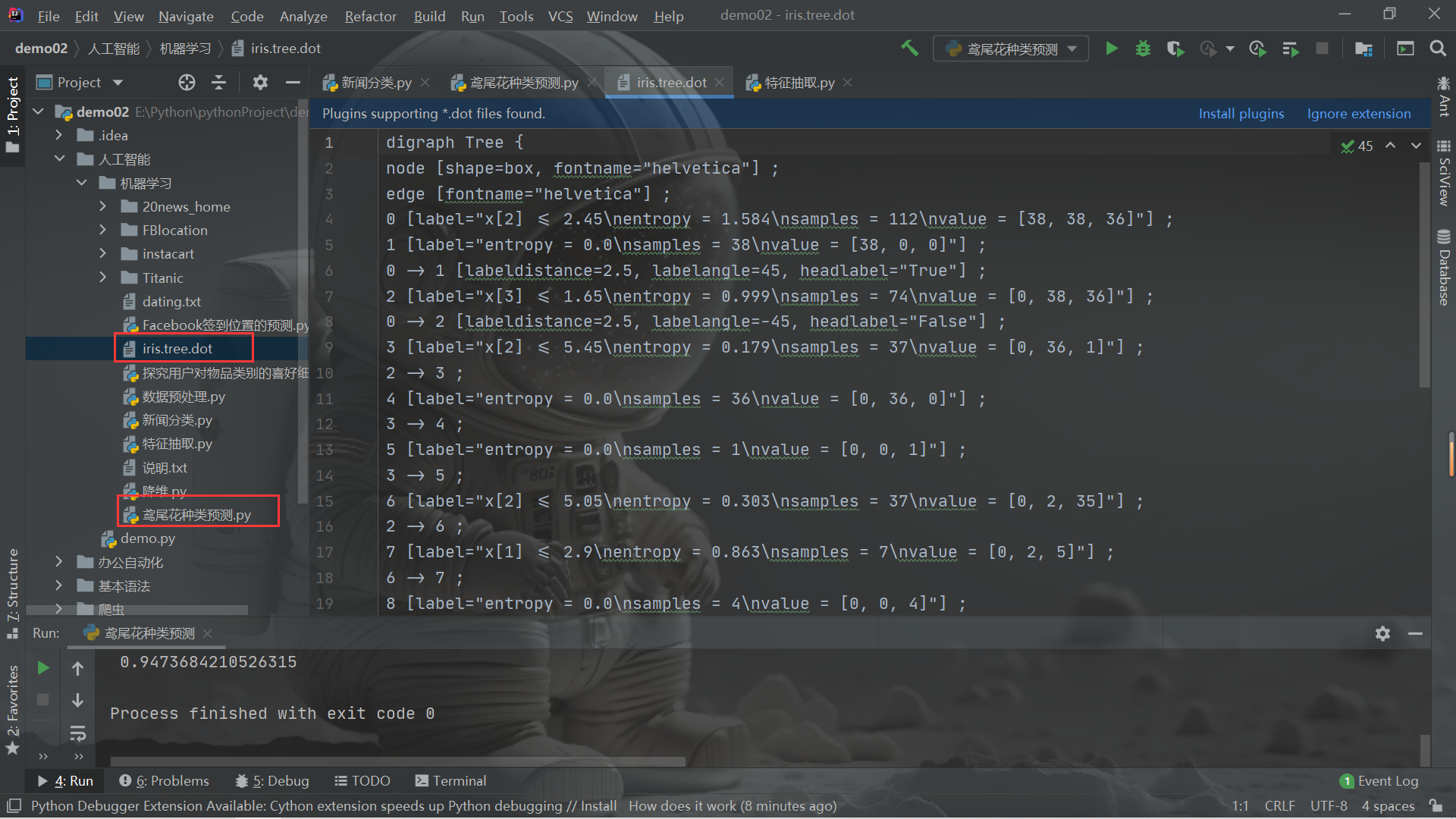
from transformers import BertTokenizer, BertModel
import torch# 加载中文 BERT 模型和分词器
model_name = "../bert-base-chinese"
tokenizer = BertTokenizer.from_pretrained(model_name)
model = BertModel.from_pretrained(model_name)def get_word_embedding(sentence):# 分词tokens = tokenizer.tokenize(sentence)# 添加特殊标记 [CLS] 和 [SEP]tokens = ['[CLS]'] + tokens + ['[SEP]']# 将分词转换为对应的编号input_ids = tokenizer.convert_tokens_to_ids(tokens)# 转换为 PyTorch tensor 格式input_ids = torch.tensor([input_ids])# 获取词向量outputs = model(input_ids)# outputs[0]是词嵌入表示embedding = outputs[0]# 去除头尾标记的向量值word_embedding = embedding[:, 1:-1, :]return word_embeddingembedding[:, 1:-1, :] 这一行的意是以下,数据类型张量
[batch_size, sequence_length, hidden_size],其中:
batch_size是输入文本的批次大小,即一次输入的文本样本数量。sequence_length是输入文本序列的长度,即编码器输入的词的数量。hidden_size是隐藏状态的维度大小,是 BERT 模型的超参数,通常为 768 或 1024。
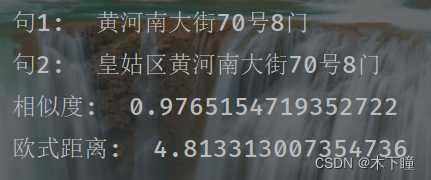
比较两文本相似度
def compare_sentence(sentence1, sentence2):# 分词tokens1 = tokenizer.tokenize(sentence1)tokens2 = tokenizer.tokenize(sentence2)# 添加特殊标记 [CLS] 和 [SEP]tokens1 = ['[CLS]'] + tokens1 + ['[SEP]']tokens2 = ['[CLS]'] + tokens2 + ['[SEP]']# 将分词转换为对应的词表中的索引input_ids1 = tokenizer.convert_tokens_to_ids(tokens1)input_ids2 = tokenizer.convert_tokens_to_ids(tokens2)# 转换为 PyTorch tensor 格式input_ids1 = torch.tensor([input_ids1])input_ids2 = torch.tensor([input_ids2])# 获取词向量outputs1 = model(input_ids1)outputs2 = model(input_ids2)# outputs[0]是词嵌入表示embedding1 = outputs1[0]embedding2 = outputs2[0]# 提取 [CLS] 标记对应的词向量作为整个句子的表示sentence_embedding1 = embedding1[:, 0, :]sentence_embedding2 = embedding2[:, 0, :]# 计算词的欧氏距离# 计算p范数距离的函数,其中p设置为2,这意味着它将计算的是欧几里得距离(L2范数)euclidean_distance = torch.nn.PairwiseDistance(p=2)distance = euclidean_distance(sentence_embedding1, sentence_embedding2)# 计算余弦相似度# dim=1 表示将在第一个维度(通常对应每个样本的特征维度)上计算余弦相似度;eps=1e-6 是为了数值稳定性而添加的一个很小的正数,以防止分母为零cos = torch.nn.CosineSimilarity(dim=1, eps=1e-6)similarity = cos(sentence_embedding1, sentence_embedding2)print("句1: ", sentence1)print("句2: ", sentence2)print("相似度: ", similarity.item())print("欧式距离: ", distance.item())compare_sentence("黄河南大街70号8门", "皇姑区黄河南大街70号8门")