项目说明
#项目: 对鸢尾花进行分类预测
#实例数量150个(3类各50个)
#属性数量:4(数值型,数值型,帮助预测的属性和类)
#特征:花萼长度,花萼宽度,花瓣长度,花瓣宽度 单位:厘米
#类别:山鸢尾,变色鸢尾,维吉尼亚鸢尾
导包
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.neighbors import KNeighborsClassifier
from sklearn.model_selection import GridSearchCV
from sklearn.tree import DecisionTreeClassifier,export_graphviz
用KNN算法对鸢尾花进行分类
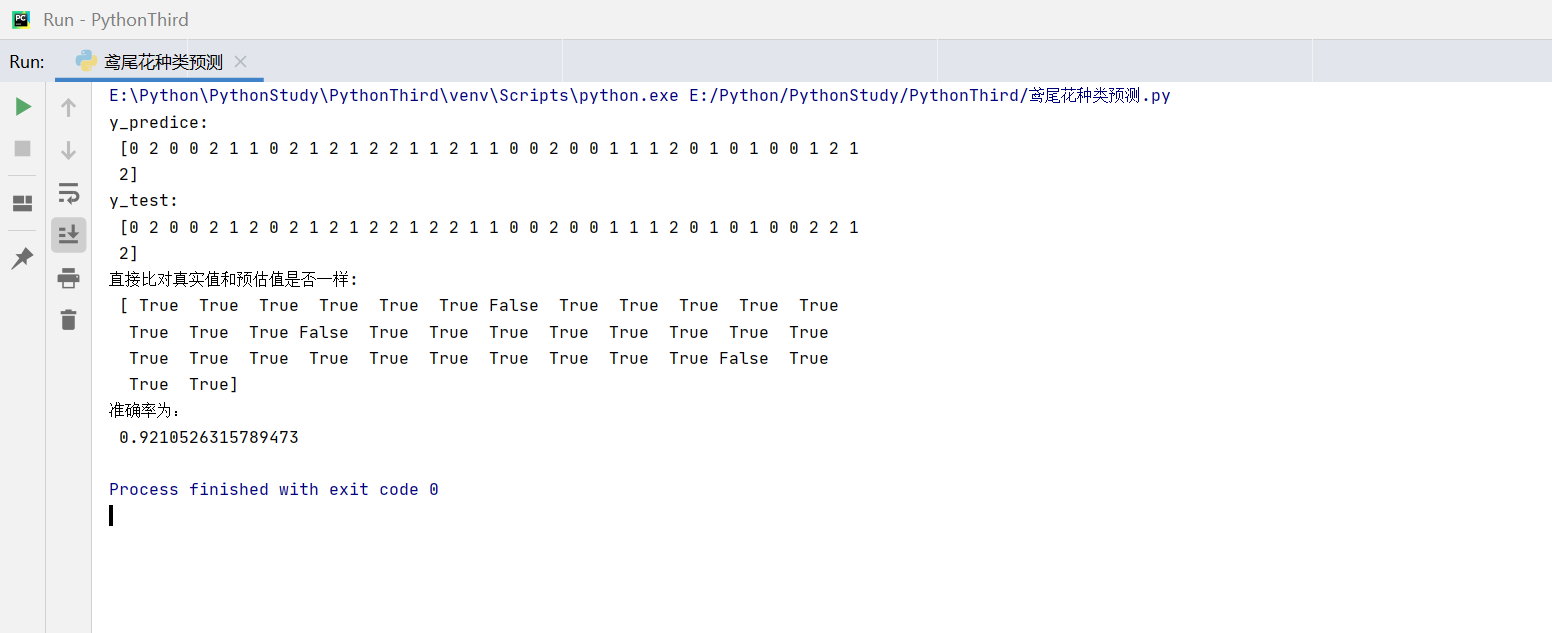
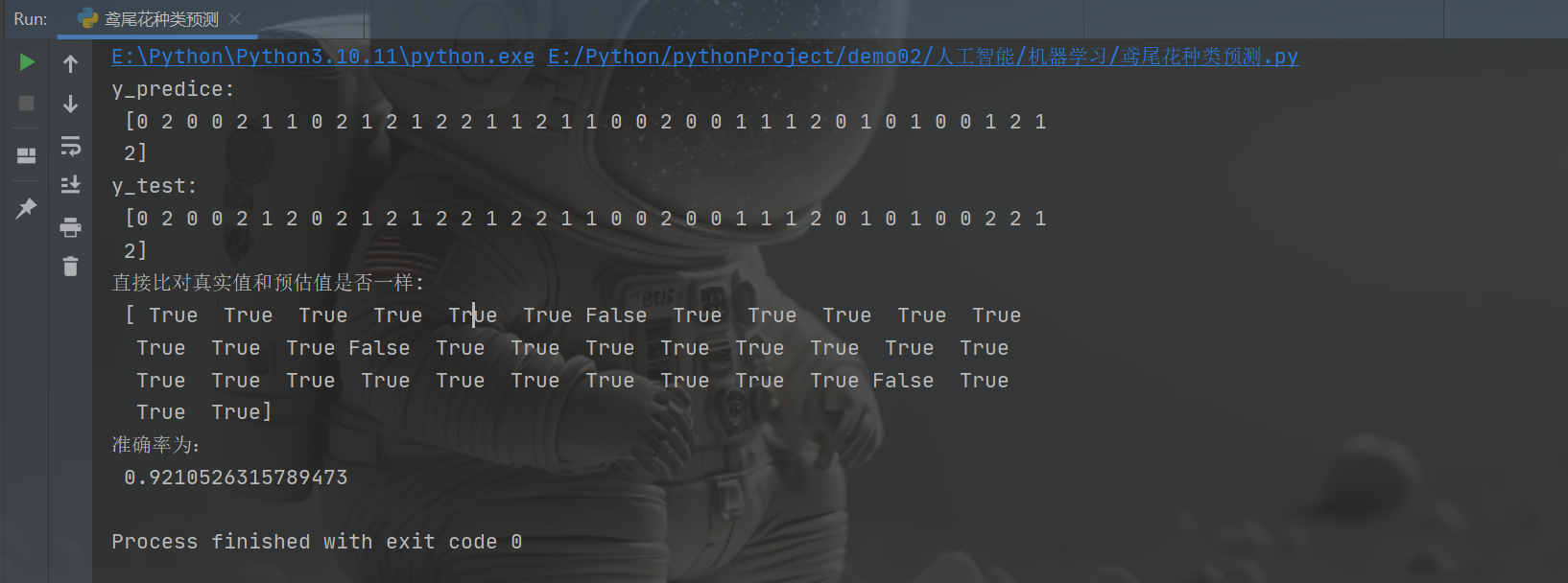
def knn_iris():"""用KNN算法对鸢尾花进行分类:return:""""""1.获取数据"""iris = load_iris()"""2.数据集划分"""# train_test_split(要分割的数据集【可以是一个或多个数组,每个数组代表一个特征或标签】,测试集的大小,训练集的大小,随机数种子【用于控制数据的随机分割】,是否在分割数据前进行洗牌)# 把iris.data和iris.target按照相同的随机种子6进行随机分割,生成训练集和测试集x_train,x_test,y_train,y_test = train_test_split(iris.data,iris.target,random_state=6) # 此处数据集划分不一样对结果影响不一样,划分为6时,准确率约为0.92#x_train【训练模型的鸢尾花数据集的特征】,x_test【测试模型的鸢尾花数据集的特征】,y_train【训练集标签】,y_test【测试集标签】#X_train 中的数据是来自原始 X 数据集的随机选择的 6 行数据,而 X_test 中的数据则是剩下的 2 行数据。# 这种分割方法确保了训练集和测试集的数据是随机且保持了原始数据的分布特性,从而可以用来训练模型和评估模型的泛化能力""" 3.特征工程:无量纲化(标准化)"""transfer = StandardScaler()x_train = transfer.fit_transform(x_train)x_test = transfer.transform(x_test) #用训练集特征中的平均值和标准差对测试集数据进行标准化#print("无量纲化后的x_train:\n",x_train)#print("无量纲化后的x_test:\n",x_test)"""4.训练 KNN预估"""estimator = KNeighborsClassifier(n_neighbors=3)estimator.fit(x_train,y_train)"""5.模型评估"""#方法1:直接比对真实值和预估值y_predict = estimator.predict(x_test)print("y_predice:\n",y_predict)print("y_test:\n",y_test)print("直接比对真实值和预估值是否一样:\n",y_test == y_predict)#方法2:计算准确率score = estimator.score(x_test,y_test)print("准确率为:\n",score)return Noneif __name__ == "__main__":# 用KNN算法对鸢尾花进行分类knn_iris()
效果:
KNN算法加入网格搜索交叉验证
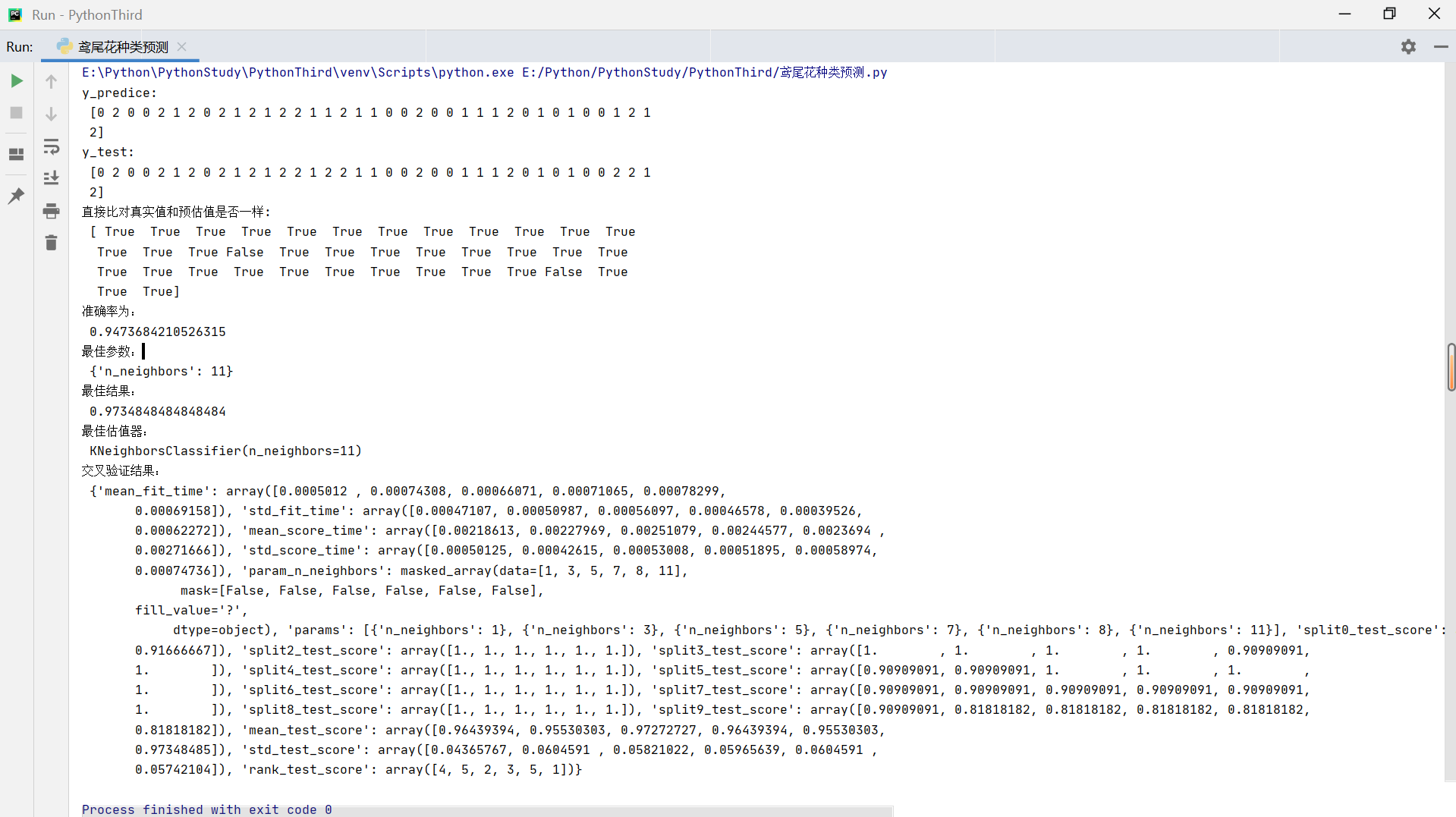
def knn_iris_gscs():"""用KNN算法对鸢尾花进行分类,添加网格搜索交叉验证:return:""""""1.获取数据"""iris = load_iris()"""2.数据集划分"""x_train, x_test, y_train, y_test = train_test_split(iris.data, iris.target, random_state=6)""" 3.特征工程:无量纲化(标准化)"""transfer = StandardScaler()x_train = transfer.fit_transform(x_train)x_test = transfer.transform(x_test) # 用训练集特征中的平均值和标准差对测试集数据进行标准化# print("无量纲化后的x_train:\n", x_train)# print("无量纲化后的x_test:\n", x_test)"""4.训练 KNN预估"""estimator = KNeighborsClassifier(n_neighbors=3)"""5.网格搜索交叉验证"""#参数准备param_dict = {"n_neighbors":[1,3,5,7,8,11]}estimator = GridSearchCV(estimator,param_grid=param_dict,cv=10)estimator.fit(x_train,y_train)"""6.模型评估"""# 方法1:直接比对真实值和预估值y_predict = estimator.predict(x_test)print("y_predice:\n", y_predict)print("y_test:\n", y_test)print("直接比对真实值和预估值是否一样:\n", y_test == y_predict)# 方法2:计算准确率score = estimator.score(x_test, y_test)print("准确率为:\n", score)print("最佳参数:\n",estimator.best_params_)print("最佳结果:\n",estimator.best_score_)print("最佳估值器:\n",estimator.best_estimator_)print("交叉验证结果:\n",estimator.cv_results_)return None
if __name__ == "__main__":# 用KNN算法对鸢尾花进行分类,添加网格搜索和交叉验证knn_iris_gscs()效果:
决策树算法对鸢尾花进行分类
def decision_iris():"""用决策树对鸢尾花进行分类:return:""""""1.获取数据"""iris = load_iris()"""2.划分数据集"""x_train,x_test,y_train,y_test = train_test_split(iris.data,iris.target,random_state=6)"""3.决策树预估器"""estimator = DecisionTreeClassifier(criterion="entropy") #按entropy信息增益进行分类estimator.fit(x_train,y_train)"""4.模型评估"""# 方法1:直接比对真实值和预估值y_predict = estimator.predict(x_test)print("y_predice:\n", y_predict)print("y_test:\n", y_test)print("直接比对真实值和预估值是否一样:\n", y_test == y_predict)# 方法2:计算准确率score = estimator.score(x_test, y_test)print("准确率为:\n", score)return Noneif __name__ == "__main__":#用决策树对鸢尾花进行分类decision_iris()效果
决策树对鸢尾花分类可视化
先保存树的结构到dot文件

方法def decision_iris()末尾加入代码运行
#可视化决策树
export_graphviz(estimator,out_file="iris.tree.dot")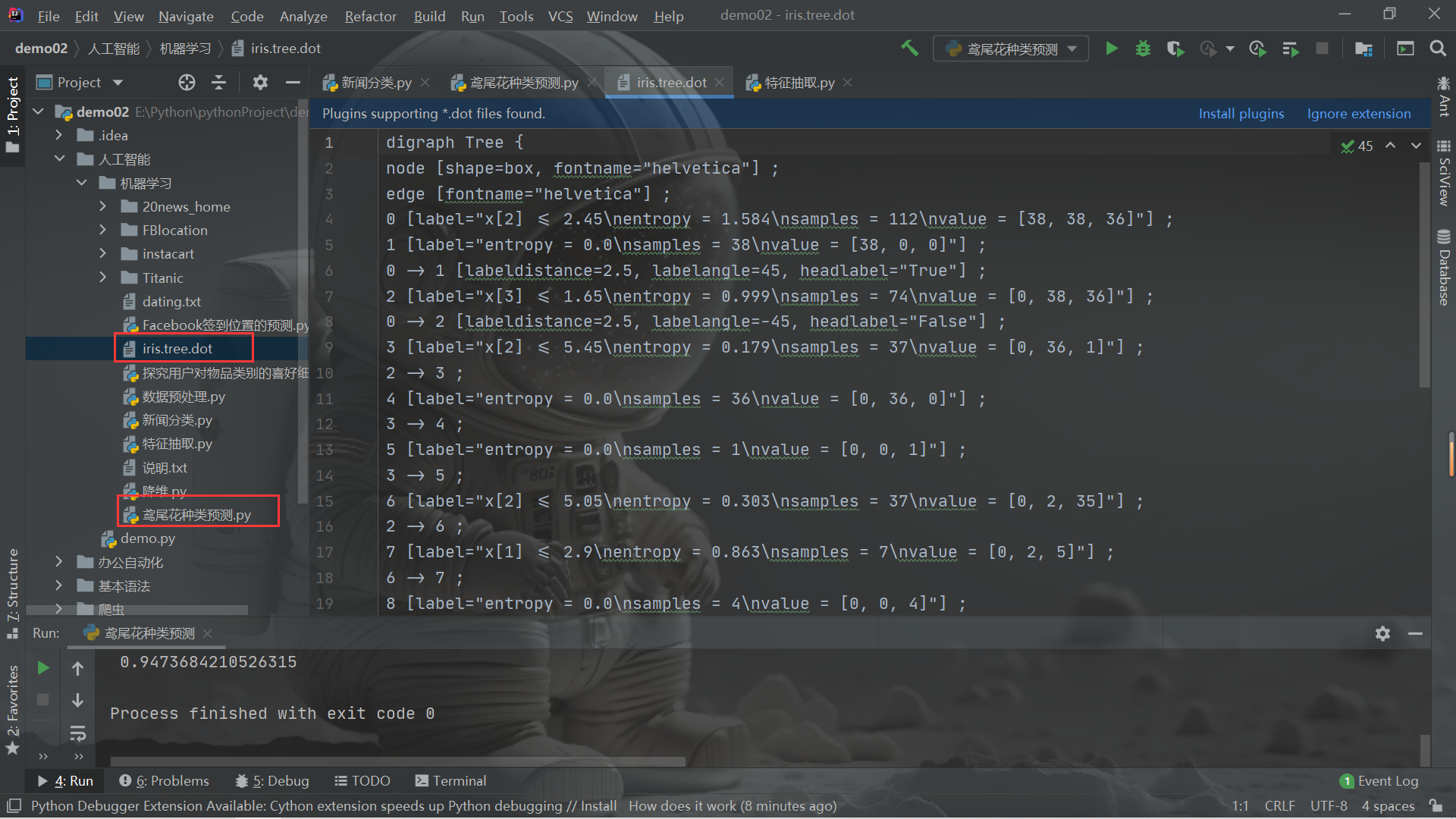
然后可以在线可视化dot文件或者下载可视化工具可视化决策树