要在Spring Boot应用中使用Redis作为缓存,你需要遵循一些步骤来配置和使用Redis。以下是使用Spring Cache抽象与Redis进行整合的详细说明:
1. 添加依赖
首先,需要在pom.xml中添加Spring Boot的Redis starter依赖以及缓存的starter依赖。这会自动引入Spring Data Redis和相关的库。
<dependencies><!-- Spring Boot Redis Starter --><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-data-redis</artifactId></dependency><!-- Spring Boot Cache Starter --><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-cache</artifactId></dependency>
</dependencies>
2. 配置Redis
接下来,需要在application.properties或application.yml文件中配置Redis服务器的连接信息。
# Redis配置
spring.redis.host=localhost
spring.redis.port=6379
# 如果Redis设置了密码,还需要配置密码
# spring.redis.password=yourpassword
3. 启用缓存支持
在Spring Boot的主配置类上添加@EnableCaching注解以启用缓存支持。
@SpringBootApplication
@EnableCaching
public class Application {public static void main(String[] args) {SpringApplication.run(Application.class, args);}
}
4. 使用缓存注解
现在,你可以在服务层或其他组件中使用@Cacheable、@CacheEvict和@CachePut注解来操作缓存。
@Service
public class UserService {@Cacheable(value = "users", key = "#userId")public User getUserById(String userId) {// 从数据库或其他地方获取用户信息return new User(userId, "Example User");}@CachePut(value = "users", key = "#user.id")public User updateUser(User user) {// 更新用户信息逻辑return user;}@CacheEvict(value = "users", key = "#userId")public void deleteUser(String userId) {// 删除用户逻辑}
}
5. 配置缓存管理器(可选)
虽然Spring Boot为Redis提供了自动配置,但你可能需要自定义缓存管理器以调整其行为。你可以通过配置一个CacheManager Bean来实现这一点。
@Configuration
public class RedisConfig {@Beanpublic CacheManager cacheManager(RedisConnectionFactory connectionFactory) {RedisCacheConfiguration config = RedisCacheConfiguration.defaultCacheConfig().entryTtl(Duration.ofHours(1)) // 设置缓存有效期为1小时.disableCachingNullValues(); // 不缓存空值return RedisCacheManager.builder(connectionFactory).cacheDefaults(config).build();}
}
6. 运行和测试
一旦完成上述配置,你的Spring Boot应用就已经配置好了Redis缓存。当你调用使用了缓存注解的方法时,Spring会自动处理缓存的读取和更新,将数据存储在Redis中。
注意事项
- 确保Redis服务器正在运行,并且连接信息配置正确。
- 根据需要调整缓存的各种设置,例如缓存的有效期、序列化机制等。
- 考虑到Redis是基于内存的存储系统,确保你的Redis实例有足够的内存来存储缓存数据。
通过以上步骤,你可以在Spring Boot应用中轻松地使用Redis进行高效的数据缓存和访问。
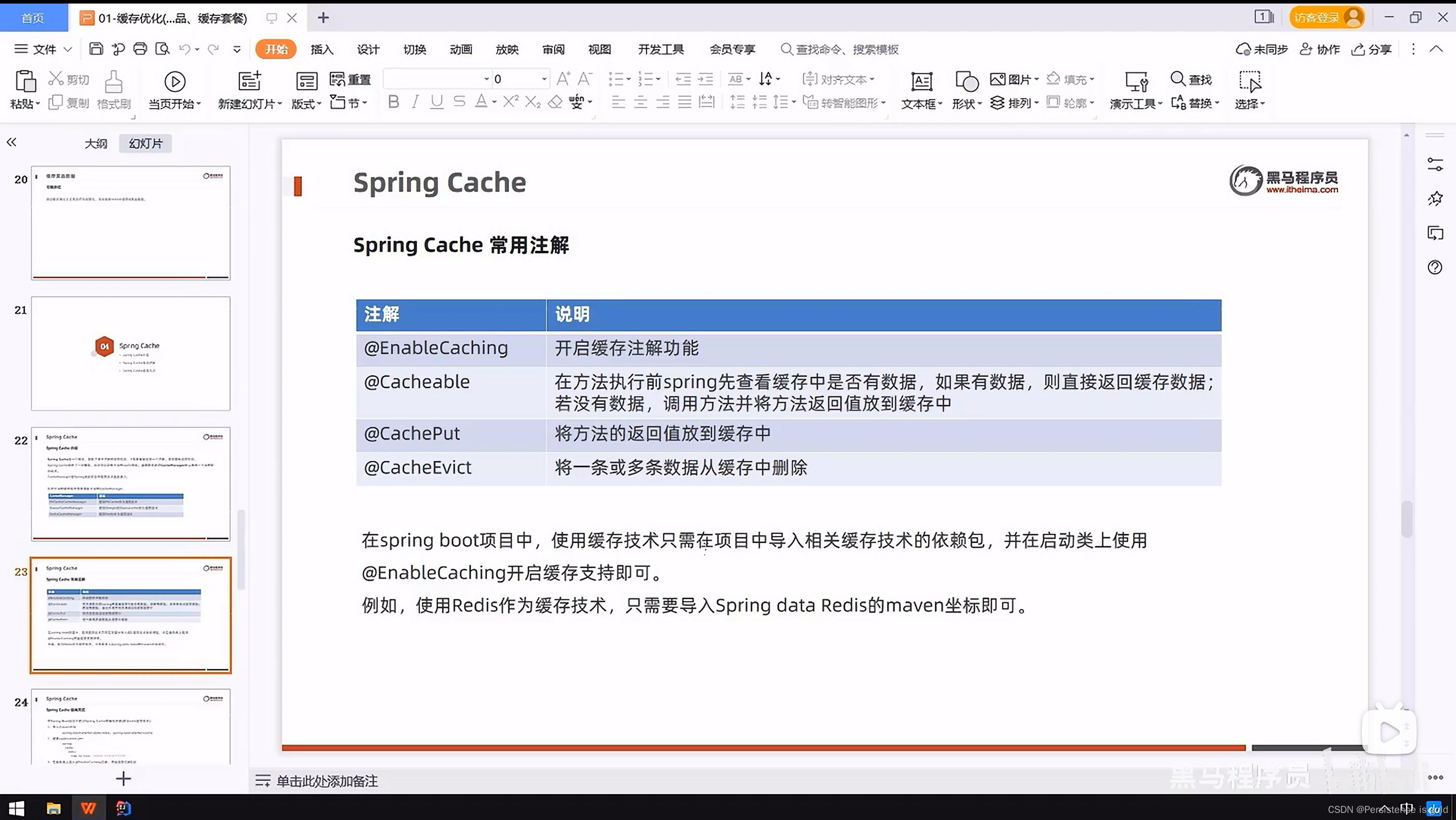
@Cacheable是Spring Cache提供的一个注解,用于声明某个方法的返回值是可以被缓存的。当标记了@Cacheable的方法被调用时,Spring Cache会首先检查缓存中是否存在已经缓存的数据。如果缓存中存在对应的数据,则直接返回缓存的数据,而不需要执行方法本身。如果缓存中没有对应的数据,那么会执行方法本身,然后将方法的返回值放入缓存中。
在给出的示例中:
@Cacheable(value = "users", key = "#userId")
public User getUserById(String userId) {// 从数据库或其他地方获取用户信息return new User(userId, "Example User");
}
@Cacheable(value = "users", key = "#userId"): 这里的@Cacheable注解表示getUserById方法的返回值是可缓存的。value = "users": 指定缓存的名称为"users"。在配置缓存实现时,可以根据这个名称来设置不同缓存的不同参数,例如过期时间、最大容量等。在同一个应用中,不同的缓存名称对应不同的缓存区域。key = "#userId": 指定缓存的key。这里使用的是Spring Expression Language (SpEL) 表达式#userId,它表示方法的参数userId的值将被用作缓存的key。这意味着,对于相同的userId参数值,方法只会在第一次被调用时执行并缓存结果;之后相同userId值的调用将直接返回缓存中的数据。
在实际执行时,如果你第一次调用getUserById("123"),方法会执行,查询数据库或其他数据源获取用户信息,并将结果(假设是new User("123", "Example User"))缓存到名为"users"的缓存中,其中key为"123"。当你再次调用getUserById("123")时,Spring Cache会检查"users"缓存中是否存在key为"123"的缓存项。由于该缓存项存在,Spring Cache会直接返回缓存中的数据,而不是再次执行方法体内的代码。
这种方式显著提高了性能,特别是在获取用户信息这样的操作中,通常涉及到对数据库的访问,这可能是一个相对较慢的操作。通过缓存这些操作的结果,可以减少对数据库的访问次数,从而提高应用程序的响应速度和整体性能。