文章目录
- 1.Pandas的map映射
- (1)映射
- (2)map充当运算工具
- 2.数据分组和透视
- (1)分组统计 - groupby功能 是pandas最重要的功能
- (2)聚合agg
- 3.透视表pivot_table
- (1)参数
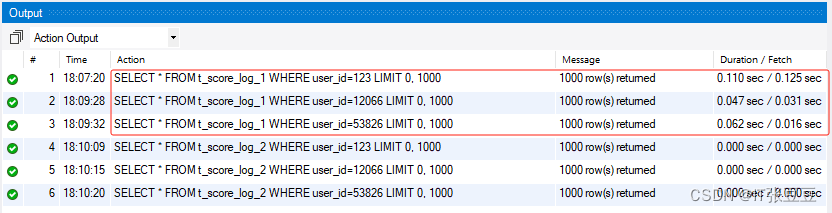
- (2)根据胜负字段进行数据的分组,然后对每组数据进行均值计算
- (3)根据主客场字段进行数据分类后,对分类后的得分字段求最大值、篮板字段求均值和助攻字段求累加和操作
- (3)#获取所有队主客场的总得分
- (4)查看主客场下的总得分都是哪些具体球队的得分构成的
- (5)#查看主客场下的总得分都是哪些具体球队的得分构成的,对于空值,用0填充
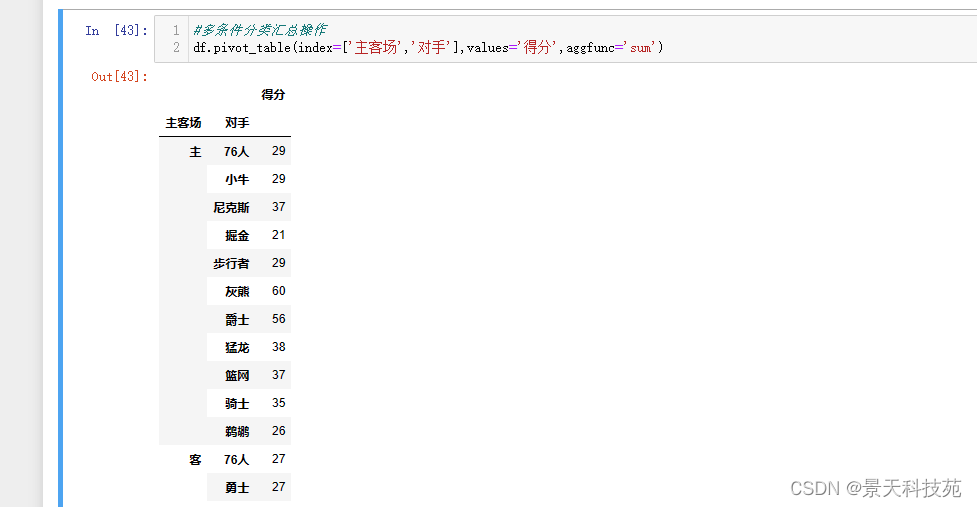
- (6)多条件分类汇总操作
1.Pandas的map映射
(1)映射
- 映射就是指给一组数据中的每一个元素绑定一个固定的数据
给Series中的一组数据提供另外一种表现方式,或者说给其绑定一组指定的标签或字符串
案例1:
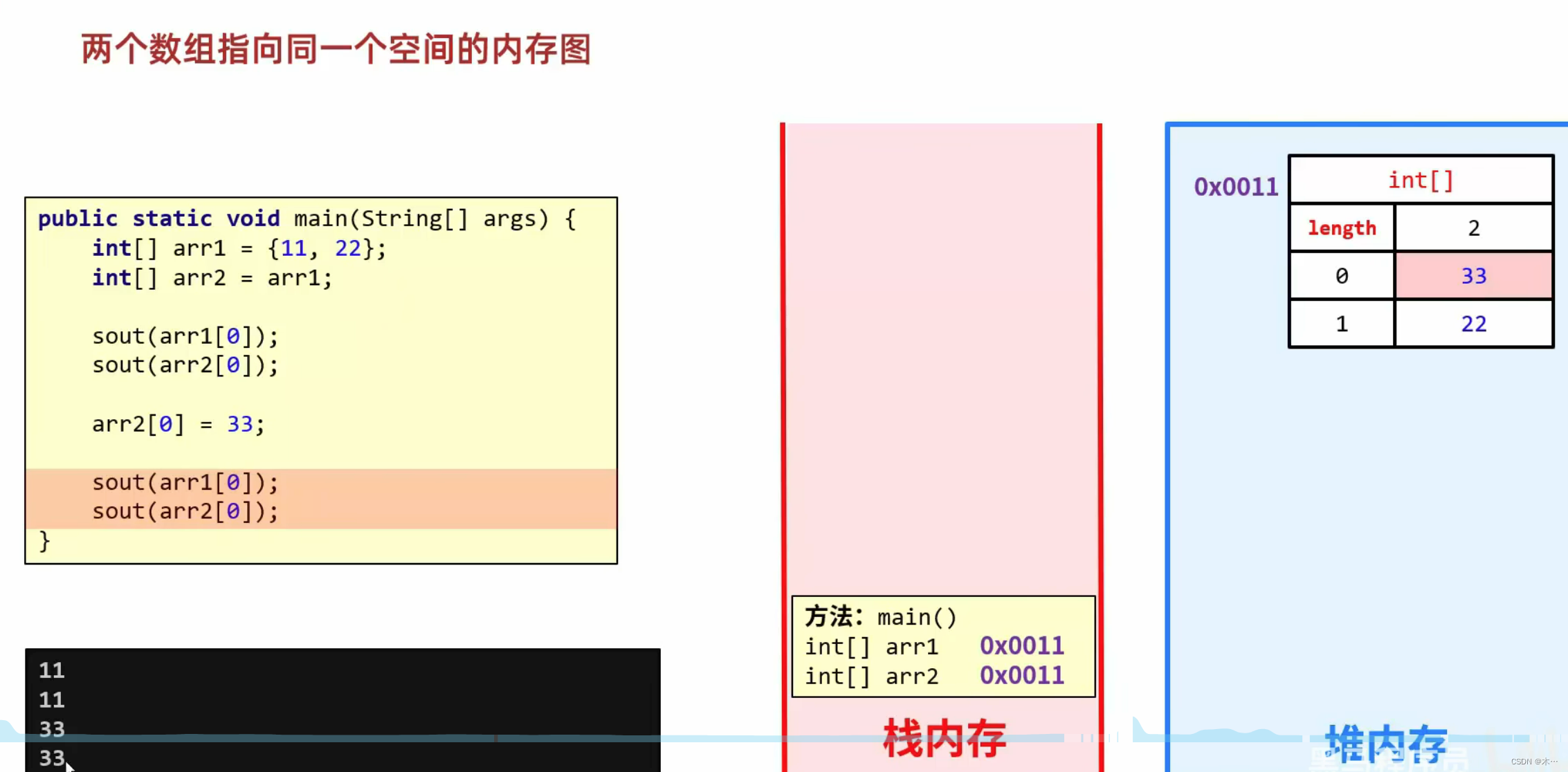
创建一个df,两列分别是姓名和薪资。然后给其名字起对应的英文名,然后将英文的性别统一转换为中文的性别
data = pd.DataFrame({“name”:[“tom”,“jeery”,“Alex”,“Jason”],“salary”:[10000,20000,15000,25000],“gender”:[“male”,“female”,“male”,“female”]})
data
做映射
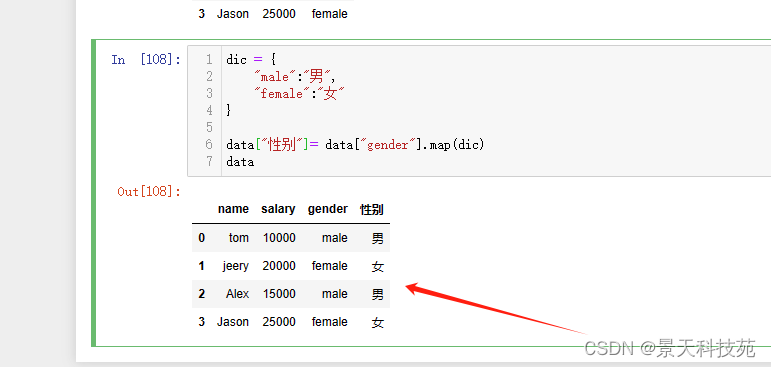
dic = {
“male”:“男”,
“female”:“女”
}
map可以将gender这组数据中的每个元素根据dic表示的关系,进行映射转换
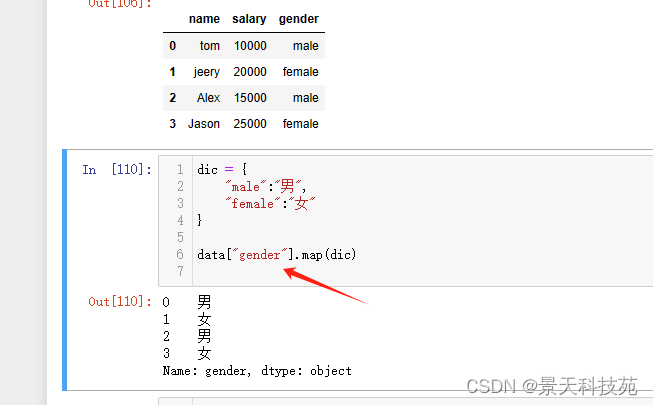
data[“性别”]= data[“gender”].map(dic)
data
案例2:
将文本中的名字映射出英文名字
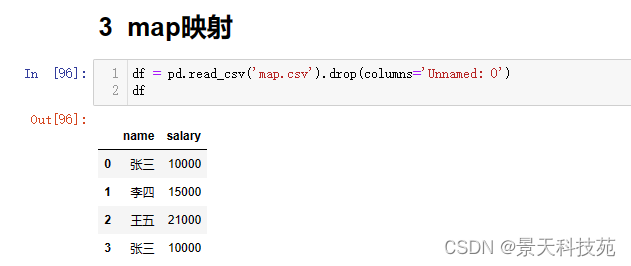
首先根据本地文件创建个df
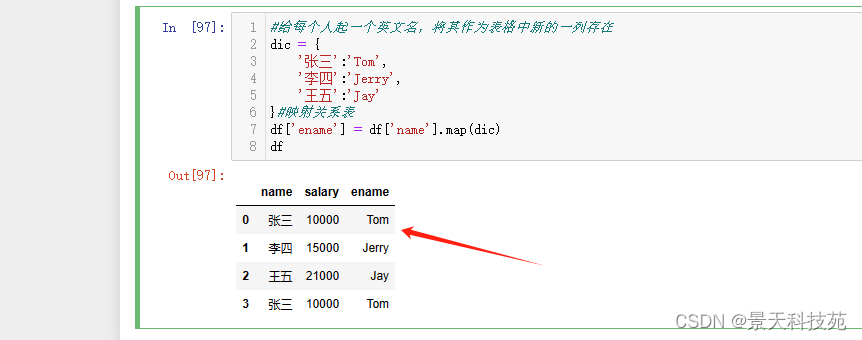
#给每个人起一个英文名,将其作为表格中新的一列存在
dic = {
‘张三’:‘Tom’,
‘李四’:‘Jerry’,
‘王五’:‘Jay’
}#映射关系表
df[‘ename’] = df[‘name’].map(dic)
df
(2)map充当运算工具
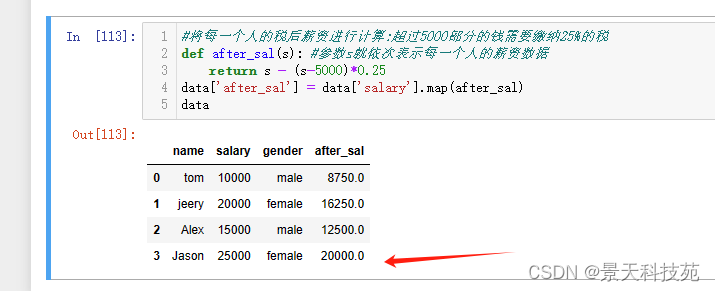
#将每一个人的税后薪资进行计算:超过5000部分的钱需要缴纳25%的税
def after_sal(s): #参数s就依次表示每一个人的薪资数据
return s - (s-5000)*0.25
data[‘after_sal’] = data[‘salary’].map(after_sal)
data
总结:map传入的参数是个字典,是做映射的。传入的是个函数名,是做运算用的
可以用匿名函数
#匿名函数写法
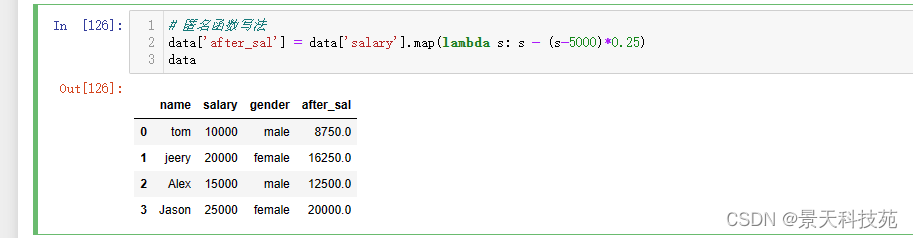
data[‘after_sal’] = data[‘salary’].map(lambda s: s - (s-5000)*0.25)
data
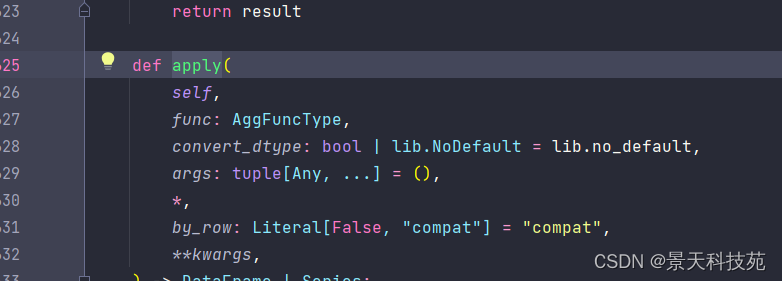
当然也可以用apply,新版的没有axis参数了
apply运算效率远远高于map,在数据数量级比较大的时候,经常用apply
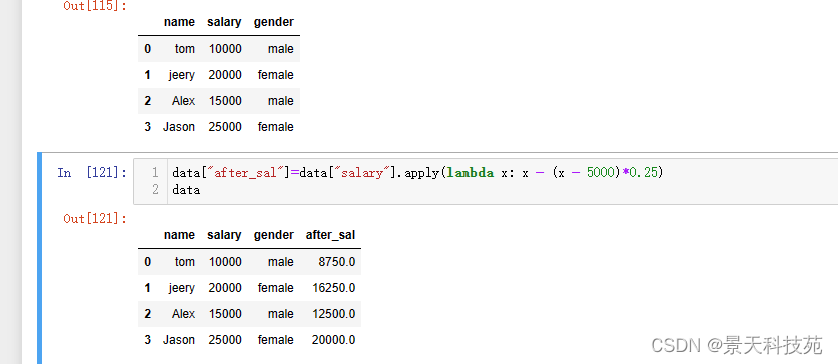
data[“after_sal”]=data[“salary”].apply(lambda x: x - (x - 5000)*0.25)
data
案例3:
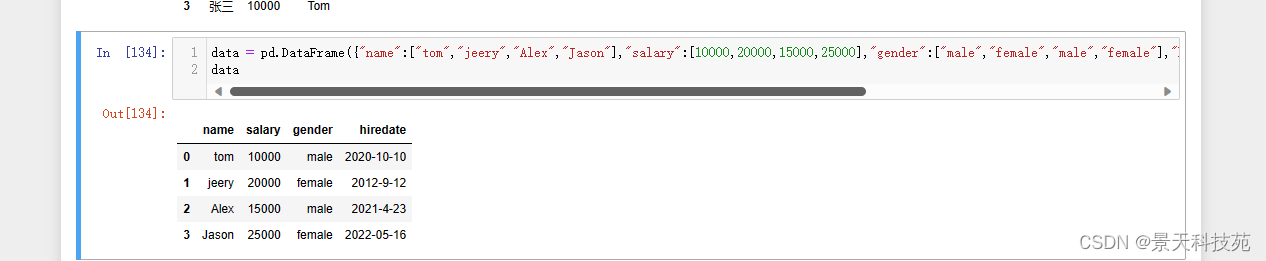
将每个人的入职日期加两年,目前入职日期是字符串类型数据
data = pd.DataFrame({“name”:[“tom”,“jeery”,“Alex”,“Jason”],“salary”:[10000,20000,15000,25000],“gender”:[“male”,“female”,“male”,“female”],“hiredate”:[“2020-10-10”,“2012–9-12”,“2021–4-23”,“2022-05-16”]})
data
我们用apply来做
获取入职日期,根据- 做切分得到年份,加2
def get_date(x):
year,month,day = x.split(“-”)
year = int(year)+2
return str(year)+“-”+month+“-”+day
data[‘hiredate’] = data[‘hiredate’].apply(get_date)
data
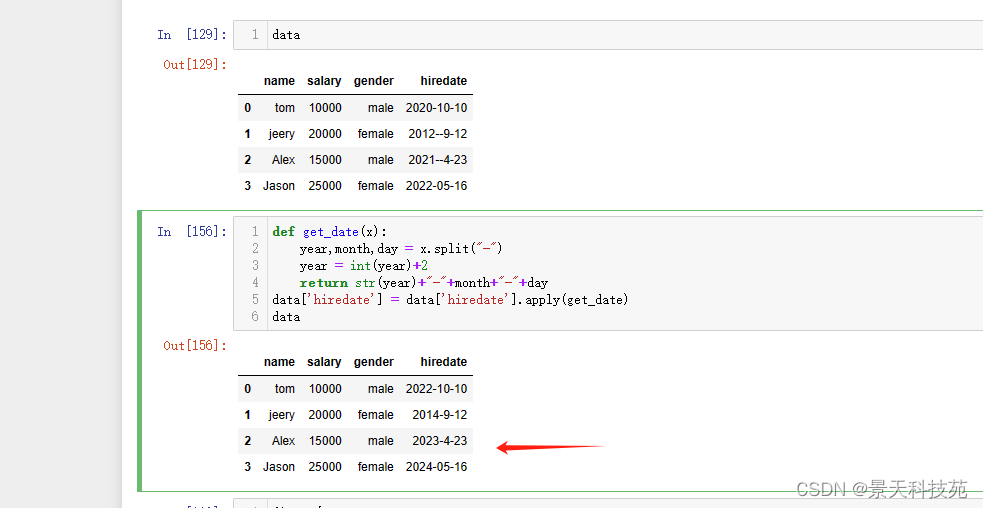
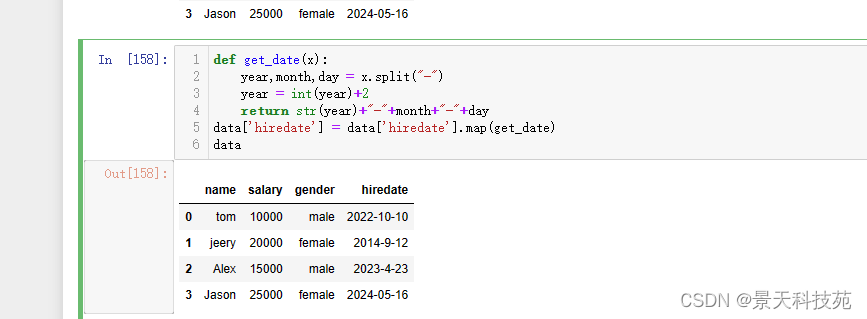
用map也可以
def get_date(x):
year,month,day = x.split(“-”)
year = int(year)+2
return str(year)+“-”+month+“-”+day
data[‘hiredate’] = data[‘hiredate’].map(get_date)
data
2.数据分组和透视
分组与聚合通常是分析数据的一种方式,通常与一些统计函数一起使用,查看数据的分组情况
数据分类处理的核心:
groupby()函数
groups属性查看分组情况
(1)分组统计 - groupby功能 是pandas最重要的功能
① 根据某些条件将数据拆分成组
② 对每个组独立应用函数
③ 将结果合并到一个数据结构中
Dataframe在行(axis=0)或列(axis=1)上进行分组,将一个函数应用到各个分组并产生一个新值,然后函数执行结果被合并到最终的结果对象中。
df.groupby(by=None, axis=0, level=None, as_index=True, sort=True, group_keys=True, squeeze=False, **kwargs)
api:
学习要善于掌握规律,你不管学什么函数,都要先学习其功能,参数,返回值都是啥。这样才能比较清晰的运用
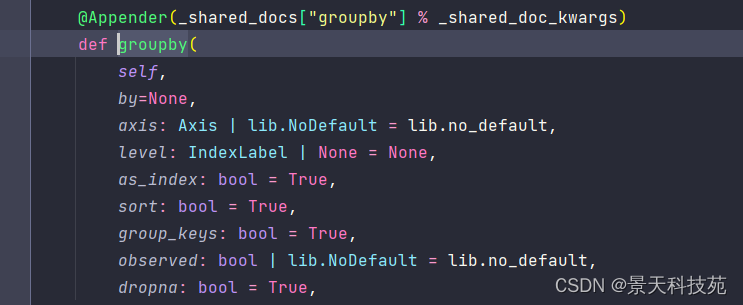
参数详解:
by参数用于指定要进行分组的列名,可以是一个列名或者多个列名的列表
axis参数用于指定分组方向,0表示行方向,1表示列方向
level参数用于指定分组级别
as_index参数用于指定分组后的结果是否作为DataFrame的索引
sort参数用于指定分组结果是否按照分组列进行排序
group_keys参数用于指定分组后是否保留分组键
squeeze参数用于指定是否移除单元素的分组
observed参数用于指定是否观察数据的层次结构
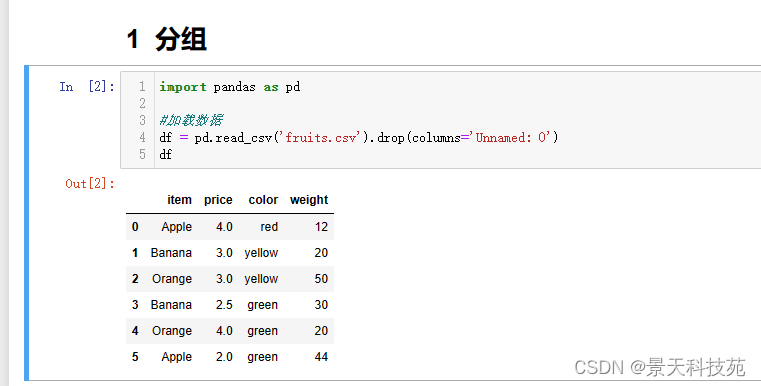
import pandas as pd
#加载数据
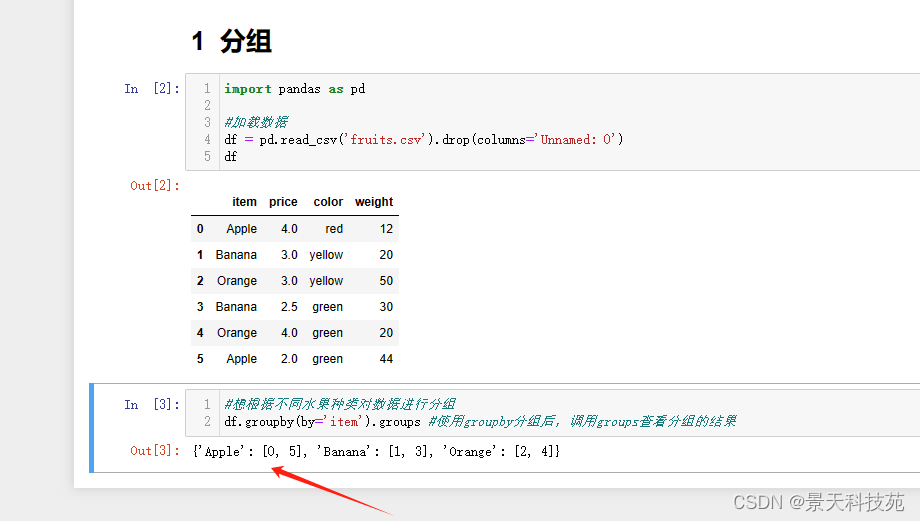
df = pd.read_csv(‘fruits.csv’).drop(columns=‘Unnamed: 0’)
df
#想根据不同水果种类对数据进行分组
df.groupby(by=‘item’).groups #使用groupby分组后,调用groups查看分组的结果
Apple是 第0行和第5行。Banada 是第1行和第3行。Orange是第2行和第4行
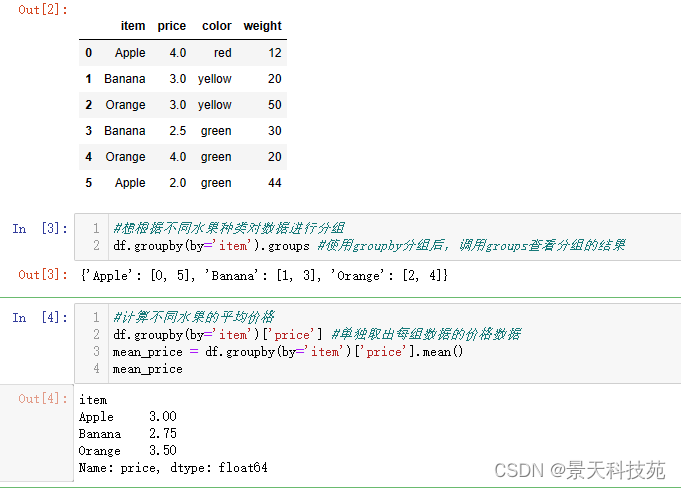
#计算不同水果的平均价格
df.groupby(by=‘item’)[‘price’] #单独取出每组数据的价格数据
mean_price = df.groupby(by=‘item’)[‘price’].mean() #求均值
mean_price
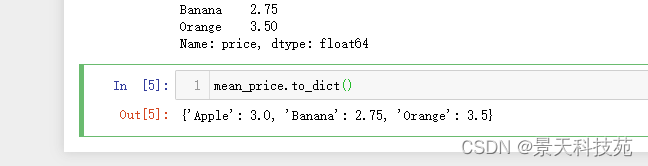
to_dict() 可以将dataframe转换为dict
mean_price.to_dict()
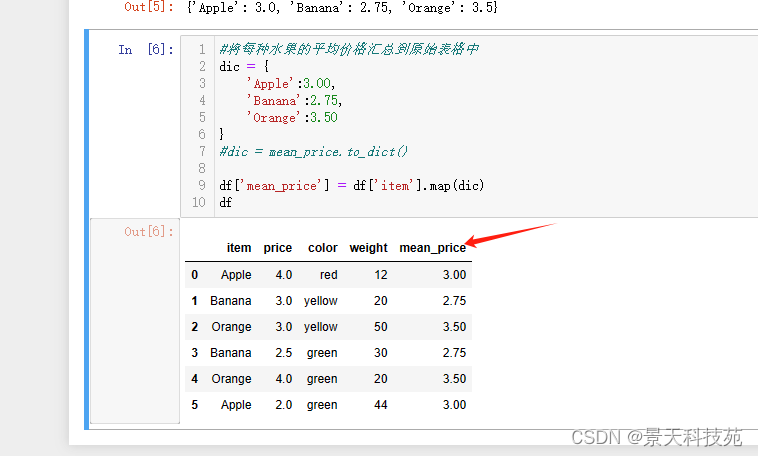
#将每种水果的平均价格汇总到原始表格中
现在无法直接将平均价格series数据直接插入到原始数据,因为数据结构不一样
此时就可以用到我们之前学的map
dic = {
‘Apple’:3.00,
‘Banana’:2.75,
‘Orange’:3.50
}
#dic = mean_price.to_dict()
df[‘mean_price’] = df[‘item’].map(dic)
df
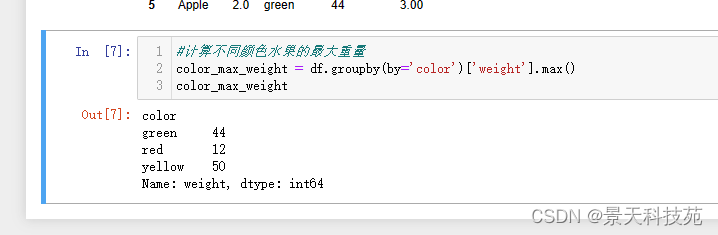
#计算不同颜色水果的最大重量
color_max_weight = df.groupby(by=‘color’)[‘weight’].max()
color_max_weight
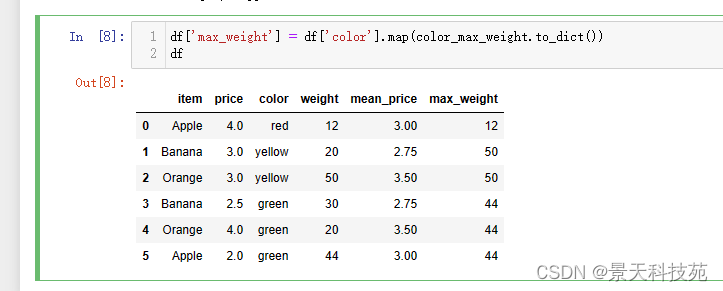
将不同颜色水果的最大重量也汇总到原始数据中
df[‘max_weight’] = df[‘color’].map(color_max_weight.to_dict())
df
使用groupby分组后,也可以使用功能transform和apply提供自定义函数实现更多运算
apply和transform的区别:
transform返回的结果是经过映射后的结果
apply返回的是没经过映射的结果
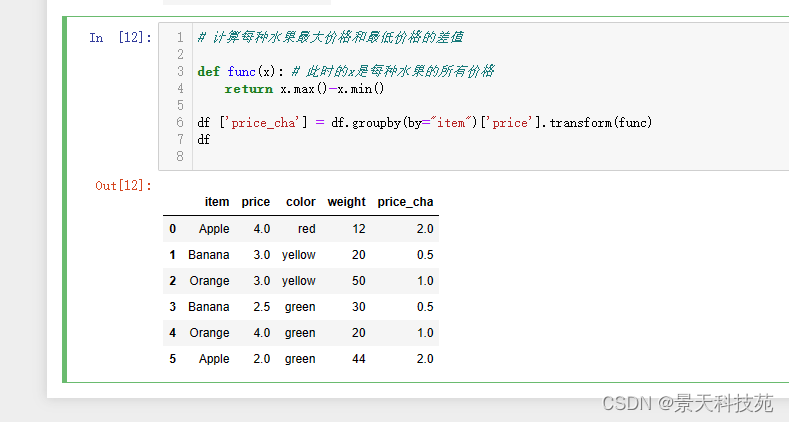
案例:
计算每种水果最大价格和最低价格的差值
def func(x): # 此时的x是每种水果的所有价格
return x.max()-x.min()
df [‘price_cha’] = df.groupby(by=“item”)[‘price’].transform(func)
df
此时,用apply就得不到值
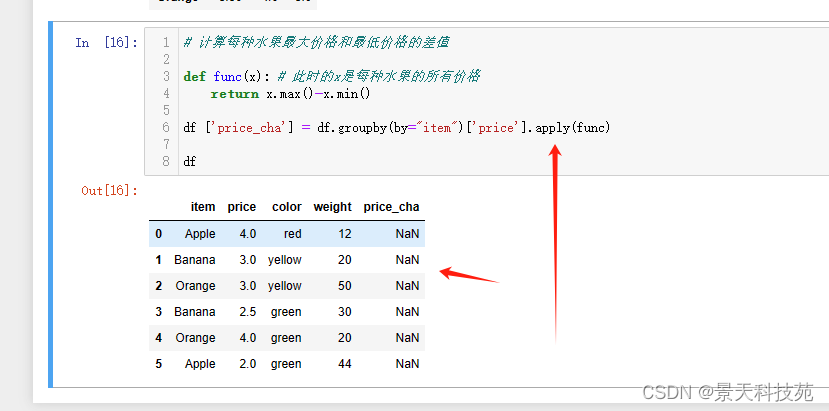
apply得到的值是:
#计算每种水果最大价格和最低价格的差值
def func(x): # 此时的x是每种水果的所有价格
return x.max()-x.min()
df.groupby(by=‘item’)[‘price’].apply(func)
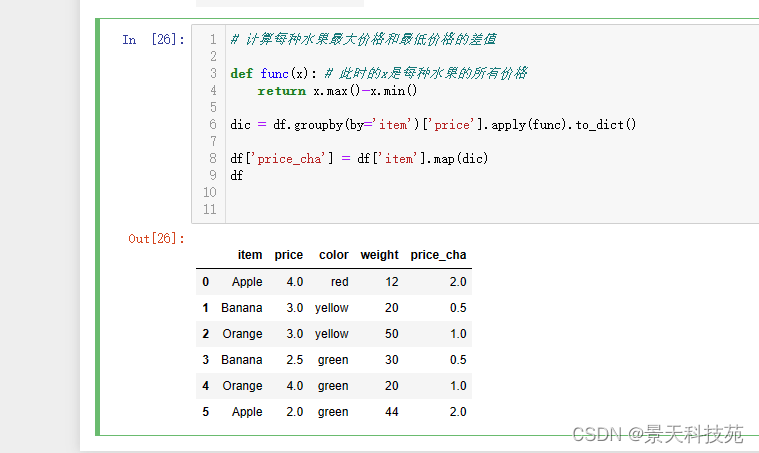
能得到结果,但是没经过映射,没法直接添加到原始数据。还需要转化成字典,使用map才能映射
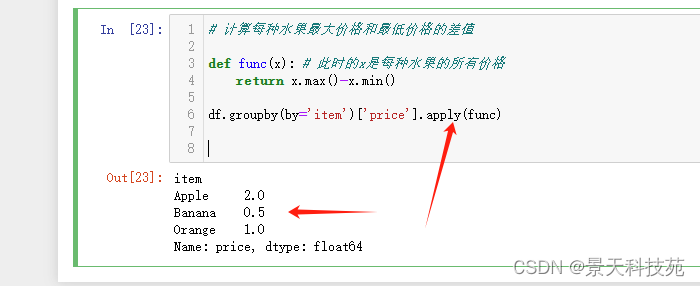
#计算每种水果最大价格和最低价格的差值
def func(x): # 此时的x是每种水果的所有价格
return x.max()-x.min()
dic = df.groupby(by=‘item’)[‘price’].apply(func).to_dict()
df[‘price_cha’] = df[‘item’].map(dic)
df
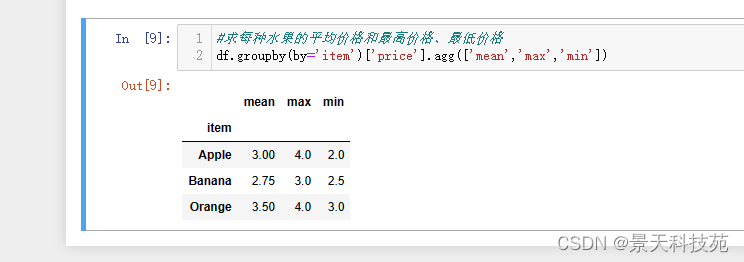
(2)聚合agg
对分组后的结果进行多种不同形式的聚合操作
#求每种水果的平均价格和最高价格、最低价格
df.groupby(by=‘item’)[‘price’].agg([‘mean’,‘max’,‘min’])
3.透视表pivot_table
透视表是一种可以对数据动态排布并且分类汇总的表格格式。
或许大多数人都在Excel使用过数据透视表,也体会到它的强大功能,而在pandas中它被称作pivot_table。
(1)参数
values:被计算的数据项,设定需要被聚合操作的列(需要显示的列) 对哪个值进行计算
index:每个pivot_table必须拥有一个index,必选参数,设定数据的行索引,可以设置多层索引,多次索引时按照需求确定索引顺序。 根据什么分类
columns:必选参数,设定列索引,用来显示字符型数据,和fill_value搭配使用。
aggfunc:聚合函数, pivot_table后新dataframe的值都会通过aggfunc进行运算。默认numpy.mean求平均。
fill_values:填充NA值(设定缺省值)。默认不填充,可以指定。
margins:添加行列的总计,默认FALSE不显示。TRUE显示。
dropna:如果整行都为NA值,则进行丢弃,默认TRUE丢弃。FALSE时,被保留。
margins_name:margins = True 时,设定margins 行/列的名称。‘all’ 默认值
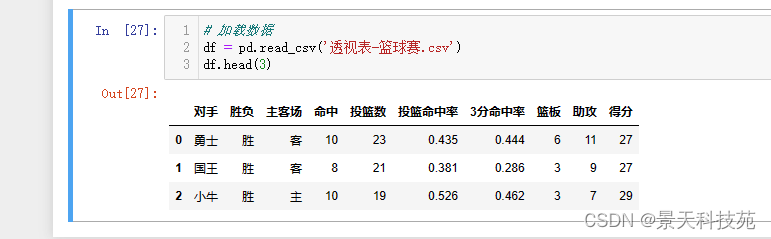
#加载数据
df = pd.read_csv(‘透视表-篮球赛.csv’)
df.head(3)
#根据对手分类,计算每个球队的平均分
新版的不能对字符串的列进行计算
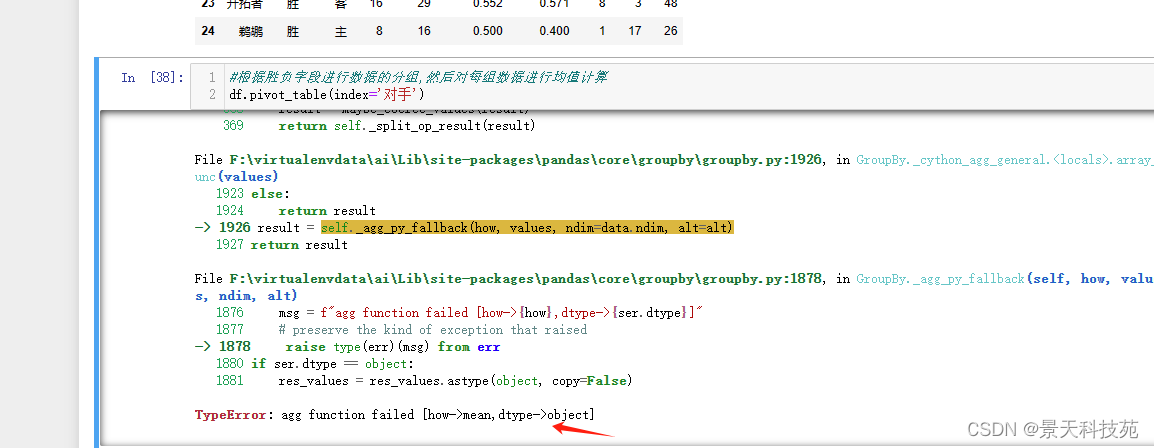
必须指定数字的列
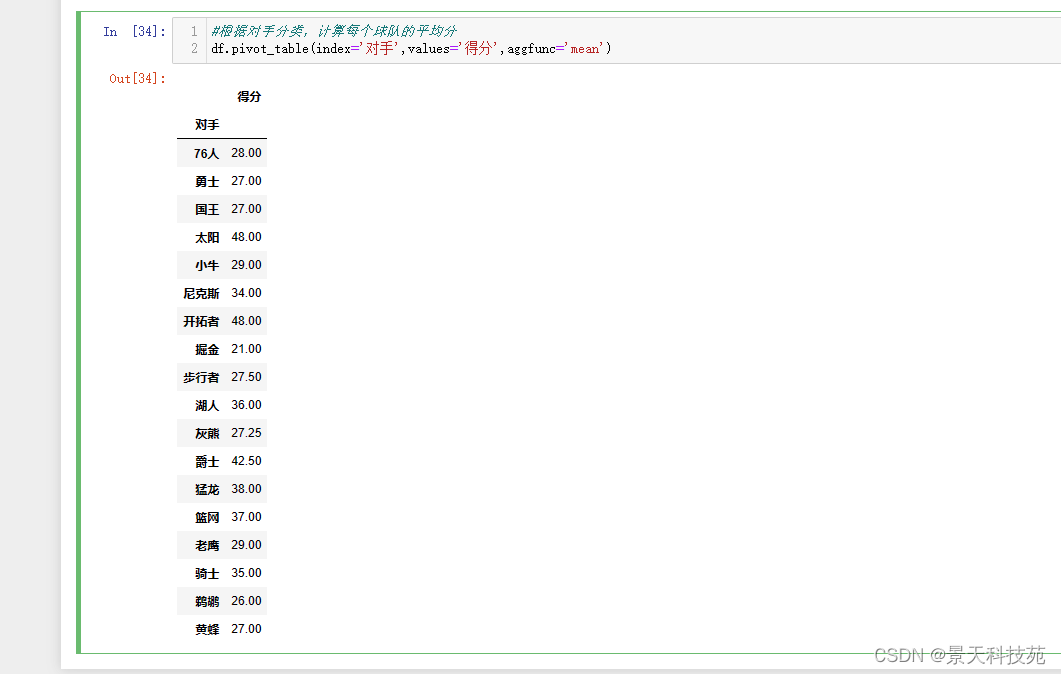
df.pivot_table(index=‘对手’,values=‘得分’,aggfunc=‘mean’) #aggfunc默认是mean,求平均
(2)根据胜负字段进行数据的分组,然后对每组数据进行均值计算
df.pivot_table(index=‘对手’,values=[‘命中’,‘投篮数’,‘投篮命中率’,‘3分命中率’,‘篮板’,‘助攻’,‘得分’])
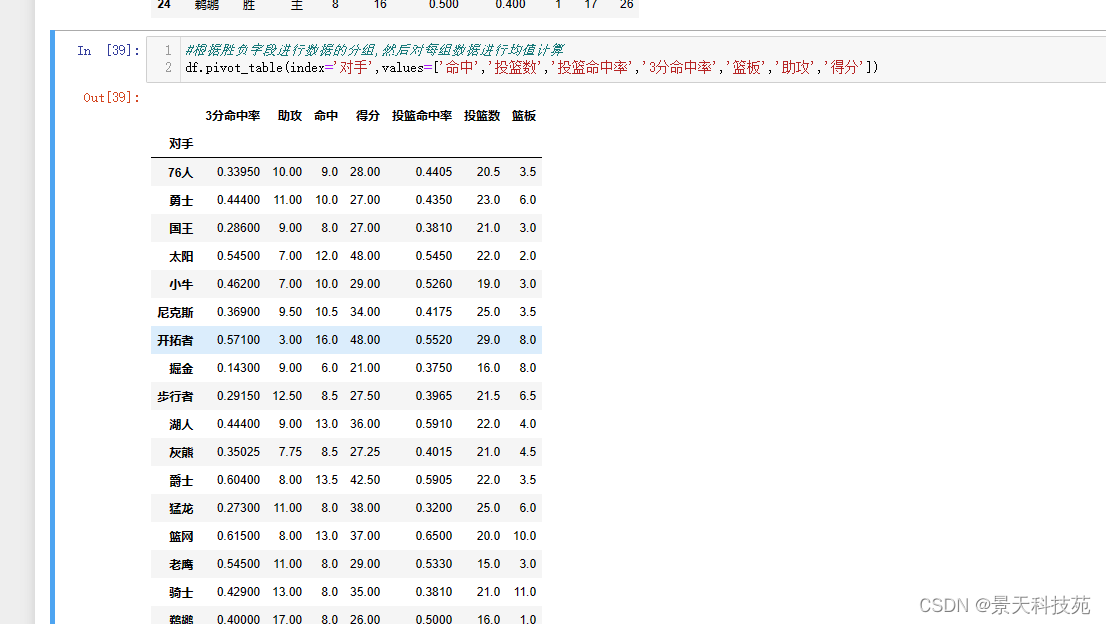
默认aggfunc只能举个一个参数,要想聚合多个参数,使用字典 。values这个字段就不要了
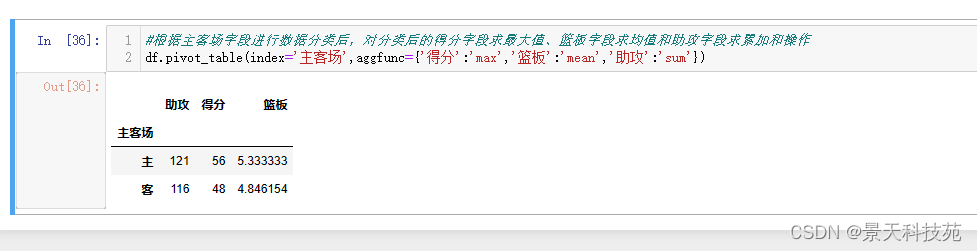
(3)根据主客场字段进行数据分类后,对分类后的得分字段求最大值、篮板字段求均值和助攻字段求累加和操作
df.pivot_table(index=‘主客场’,aggfunc={‘得分’:‘max’,‘篮板’:‘mean’,‘助攻’:‘sum’})
(3)#获取所有队主客场的总得分
df.pivot_table(index=‘主客场’,values=‘得分’,aggfunc=‘sum’)

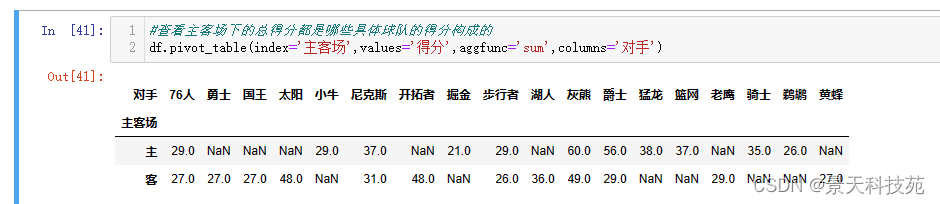
(4)查看主客场下的总得分都是哪些具体球队的得分构成的
df.pivot_table(index=‘主客场’,values=‘得分’,aggfunc=‘sum’,columns=‘对手’)
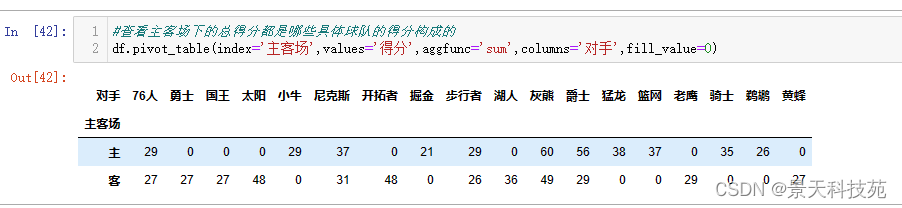
(5)#查看主客场下的总得分都是哪些具体球队的得分构成的,对于空值,用0填充
df.pivot_table(index=‘主客场’,values=‘得分’,aggfunc=‘sum’,columns=‘对手’,fill_value=0)
(6)多条件分类汇总操作
df.pivot_table(index=[‘主客场’,‘对手’],values=‘得分’,aggfunc=‘sum’)