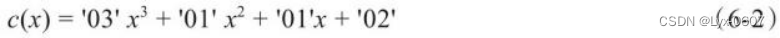
一. 介绍
在数据同步过程中,缓慢的同步速度和低效率的性能往往是令人头痛的问题。本文将介绍如何通过Kettle解决数据同步缓慢及性能效率问题,其中主要涉及数据同步利用时间戳解耦和通过配置优化提升性能高达90%的方法 。
在先前的博客文章中,我们配置了Kettle在Docker中的部署过程,以及如何配置和运行Sqlserver到Mysql的数据同步任务。同时结合Start定时任务,实现定时调度的功能,确保数据同步任务的稳定运行。
Kettle-Docker部署+Sqlserver数据同步Mysql+Start定时任务-CSDN博客![]() https://blog.csdn.net/m0_56659620/article/details/135816290?spm=1001.2014.3001.5501
https://blog.csdn.net/m0_56659620/article/details/135816290?spm=1001.2014.3001.5501
二. 数据同步-时间戳解耦
源数据表中有一个字段会记录数据的新增或修改时间,可以通过它对数据在时间维度上进行排序。通过中间表记录每次更新的时间戳,在下一个同步周期时,通过这个时间戳同步该时间戳以后的增量数据。这是时间戳增量同步。
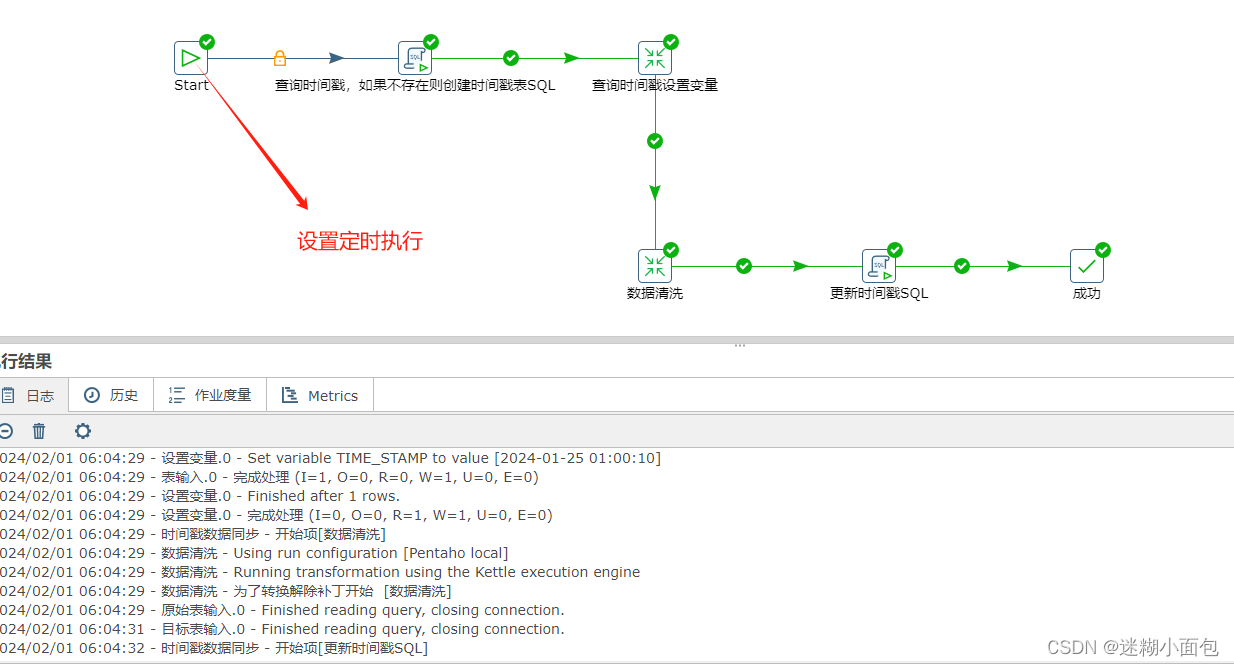
总体步骤如下:
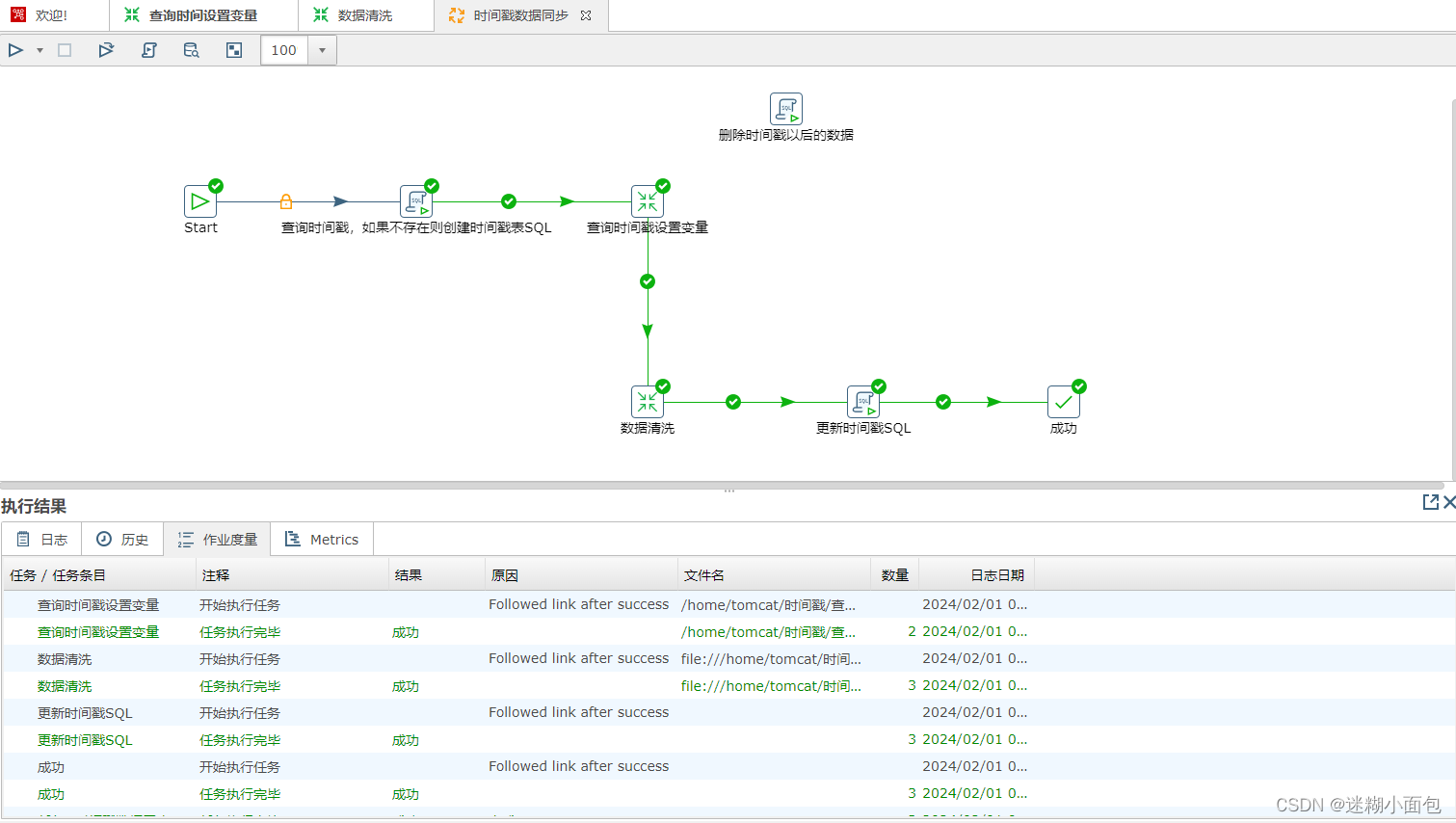
1. 为了解决当表数据同步之后再次执行效率低下问题,我们先创建一个时间戳表来保存每次插入最后一条数据时间 (如果表不存在的时候会创建,数据同步执行完成更新表里时间)
# sql 如下
CREATE TABLE IF NOT EXISTS etl_temp(id int primary key,time_stamp timestamp);
INSERT IGNORE INTO etl_temp (id,time_stamp) VALUES (1,'2018-05-22 00:00:00');

2. 新建一个转换,查询时间表里时间作为环境变量
表输入
# sql如下
select date_format(time_stamp , '%Y-%m-%d %H:%i:%s') time_stamp from etl_temp where id='1'
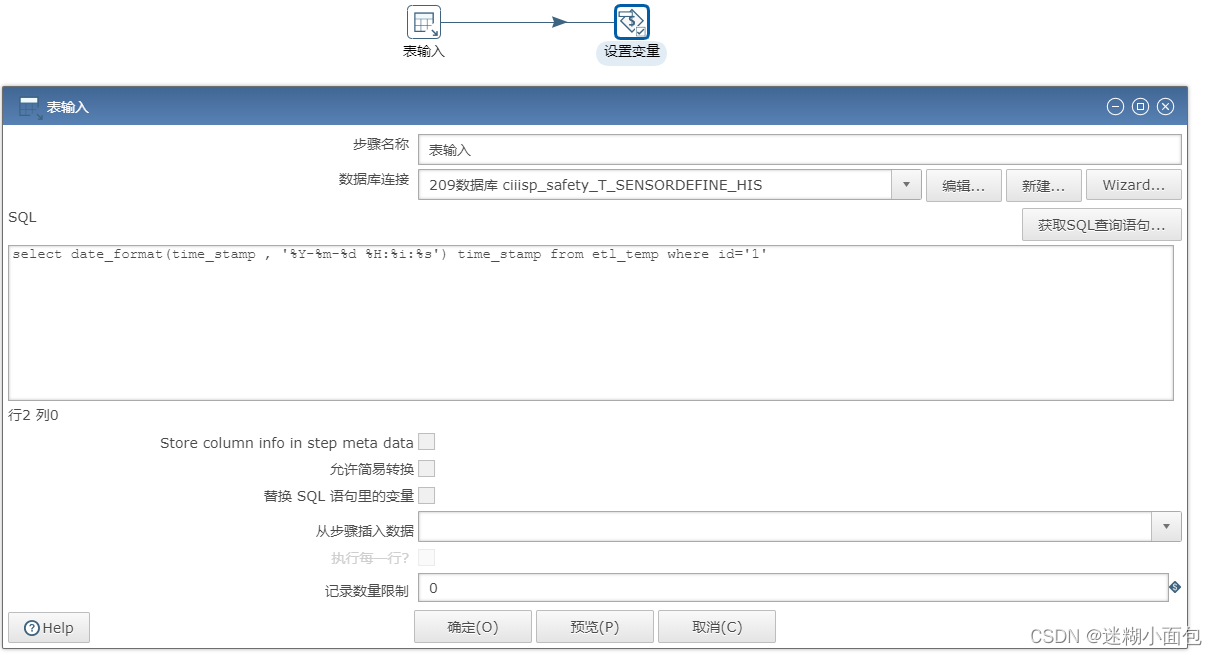
设置变量

将此转换保存到自定位位置,之后任务执行时候进行导入
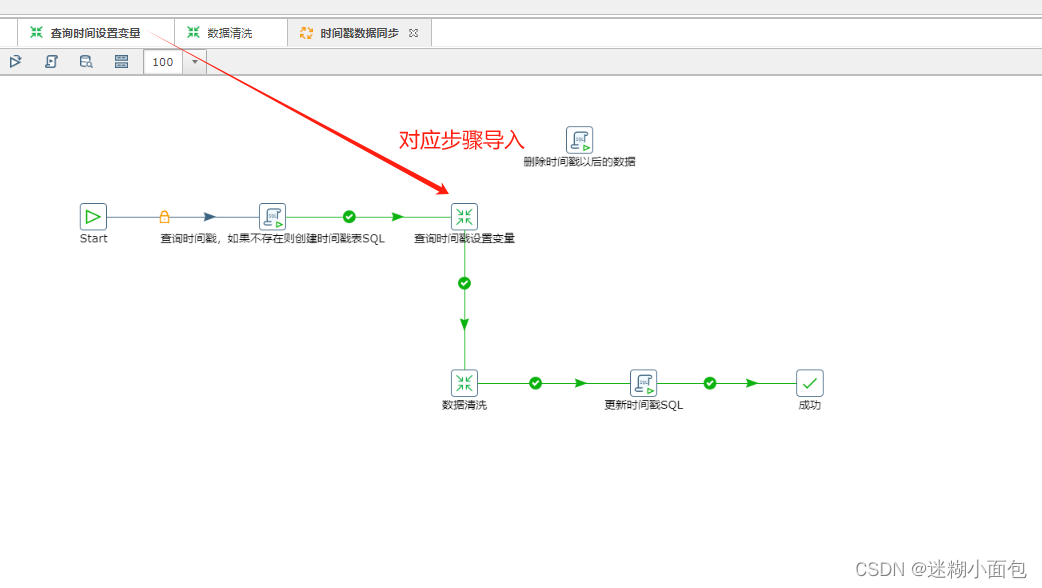
3. 新建数据同步转换(数据清洗)
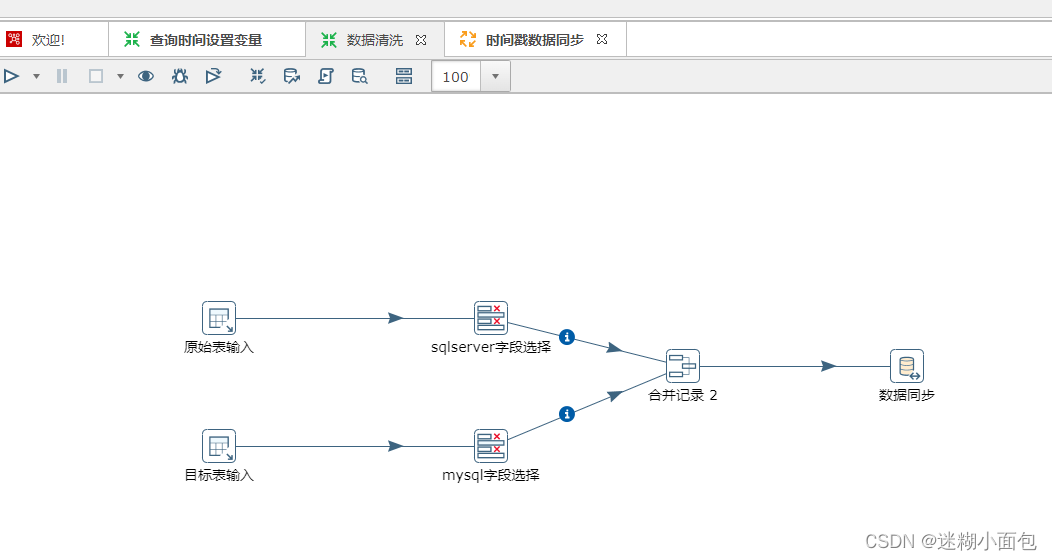
原始表输入
# '${TIME_STAMP}' 为配置的时间戳表内的时间,我们将它作为了环境变量
WHERE CREATETIME > '${TIME_STAMP}';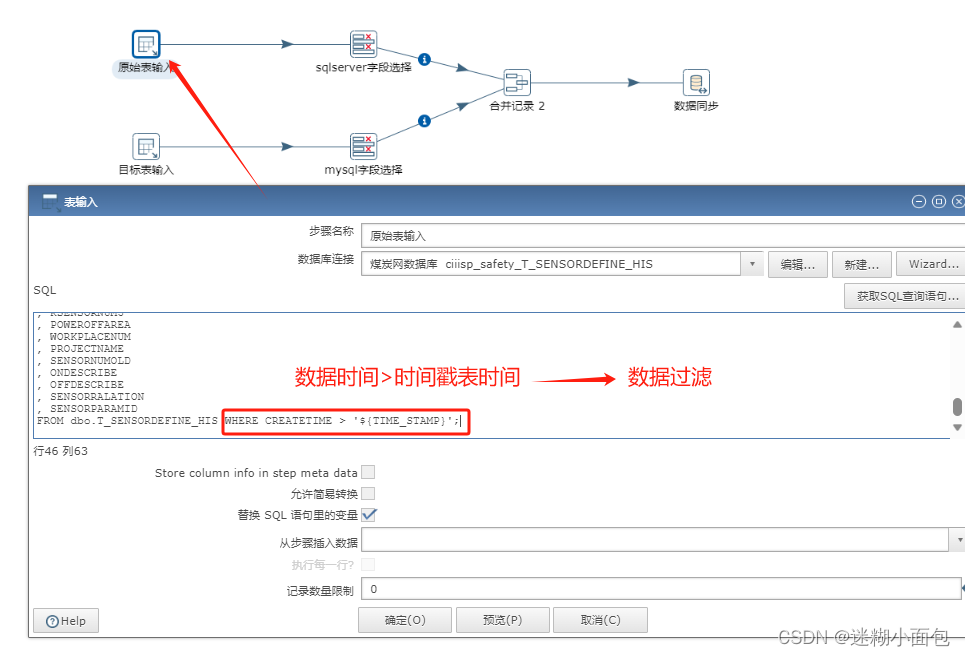
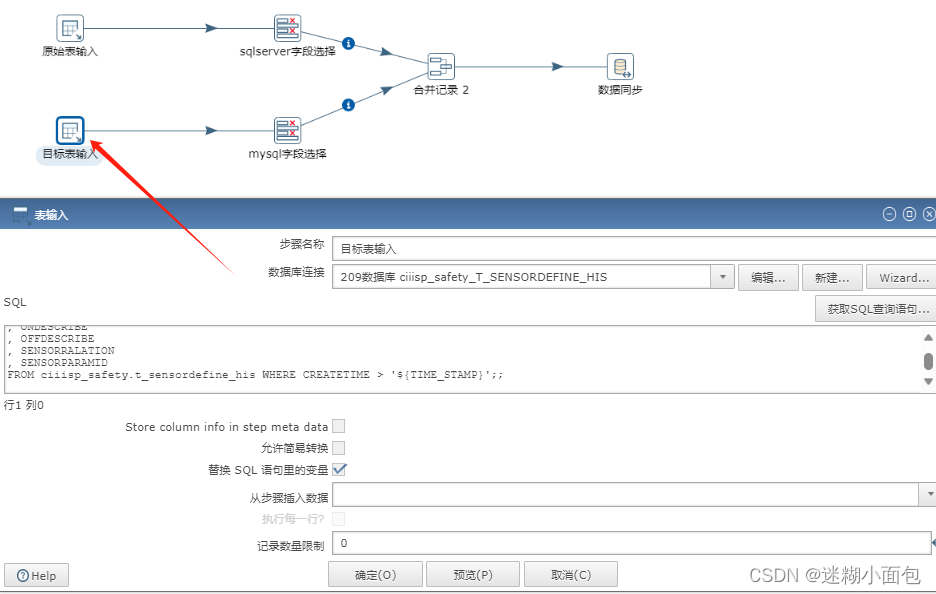
目标表同理
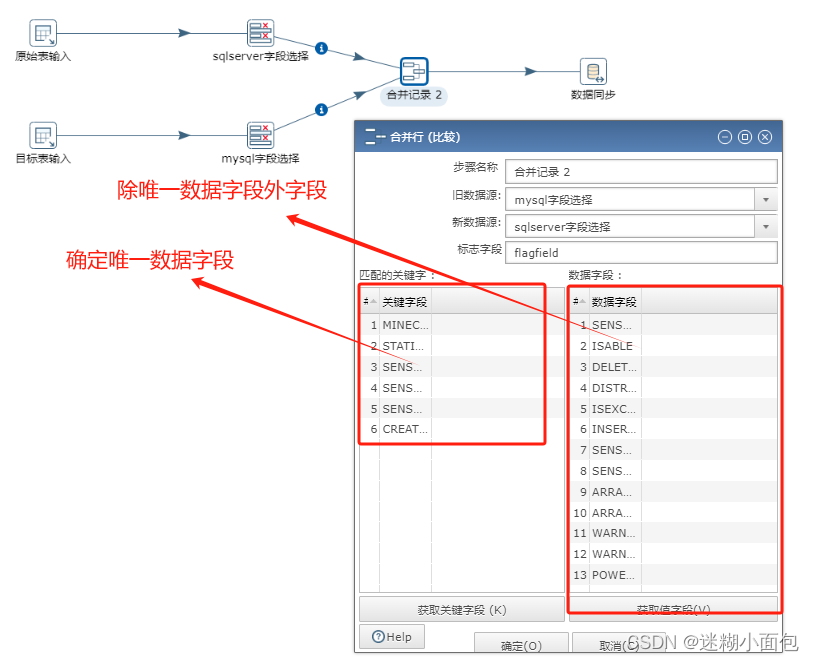
字段选择步骤

合并记录步骤
数据同步步骤
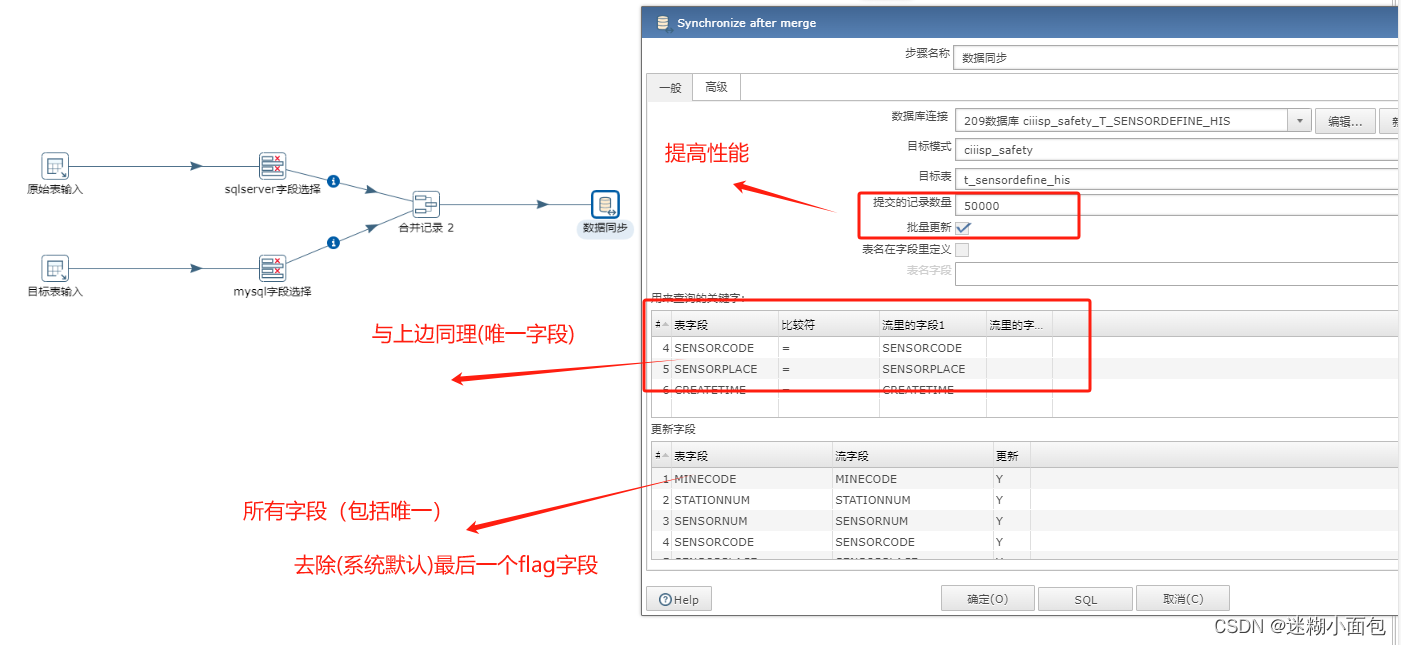
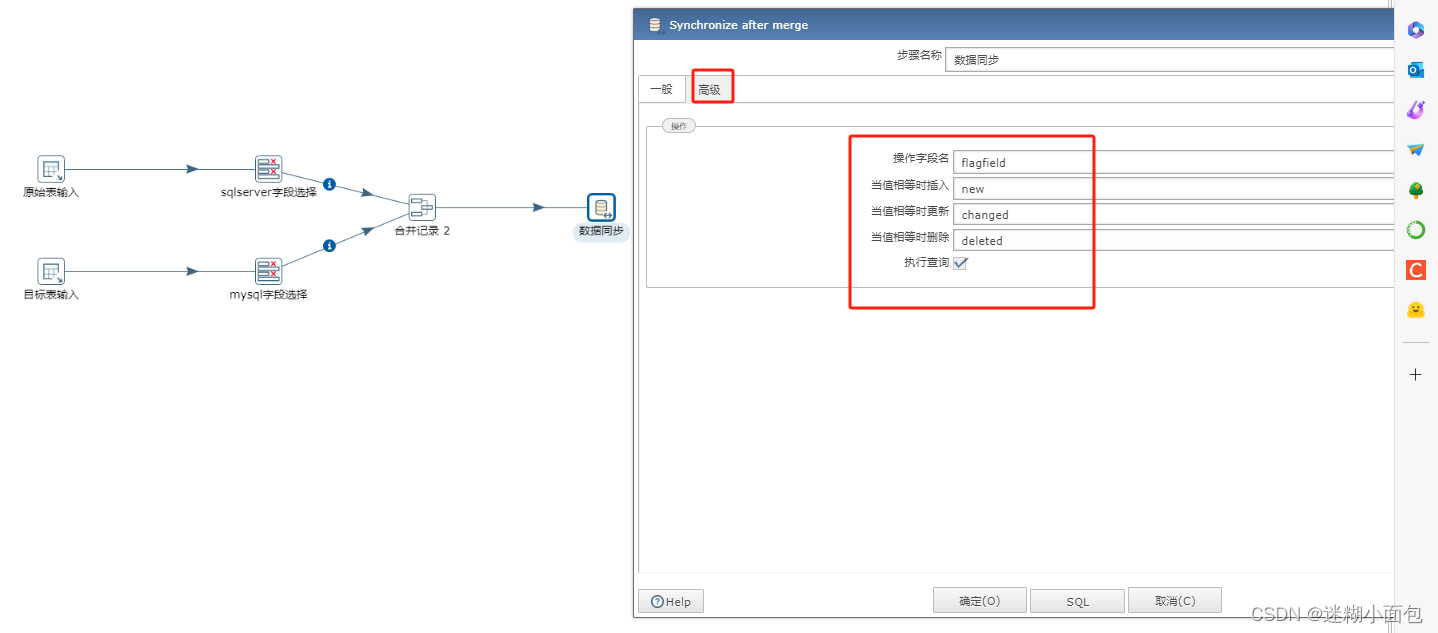
将此转换保存到自定位位置,之后任务执行时候进行导入
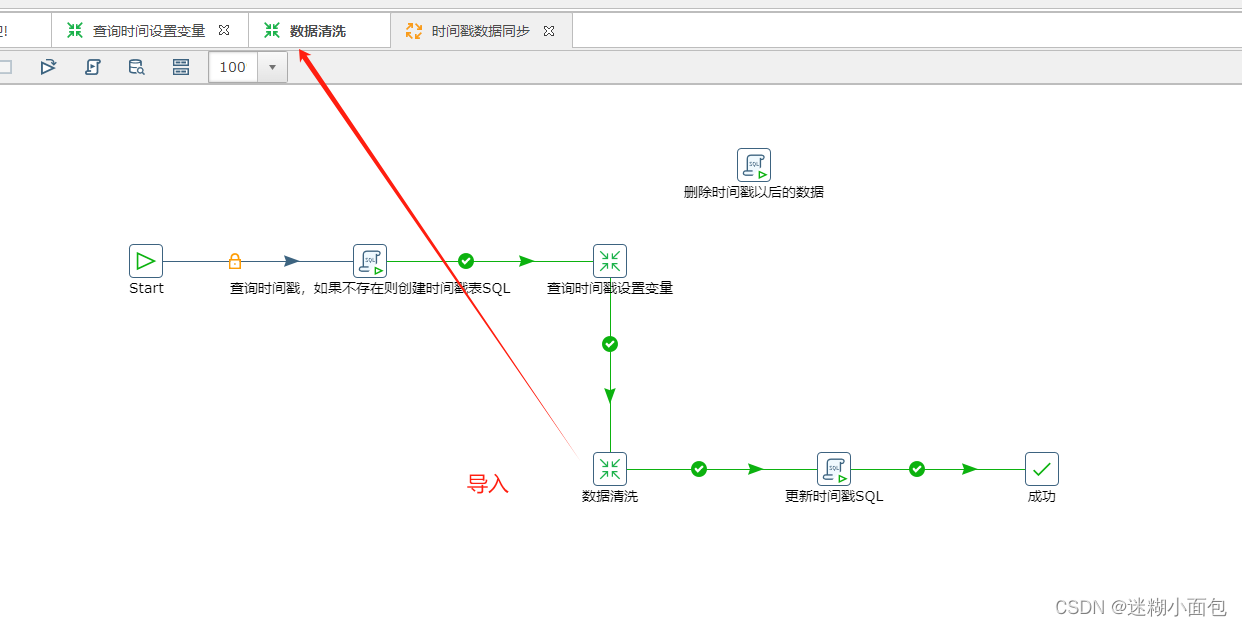
4. 当我们执行完数据同步(清洗)步骤,把同步完数据表最后一条数据更新到时间戳表,通过这个时间戳同步该时间戳以后的增量数据。
# sql 如下
set @new_etl_start_time_stamp = (SELECT CREATETIME FROM ciiisp_safety.t_sensordefine_his ORDER BY CREATETIME DESC LIMIT 1);
update etl_temp set time_stamp=@new_etl_start_time_stamp where id='1';
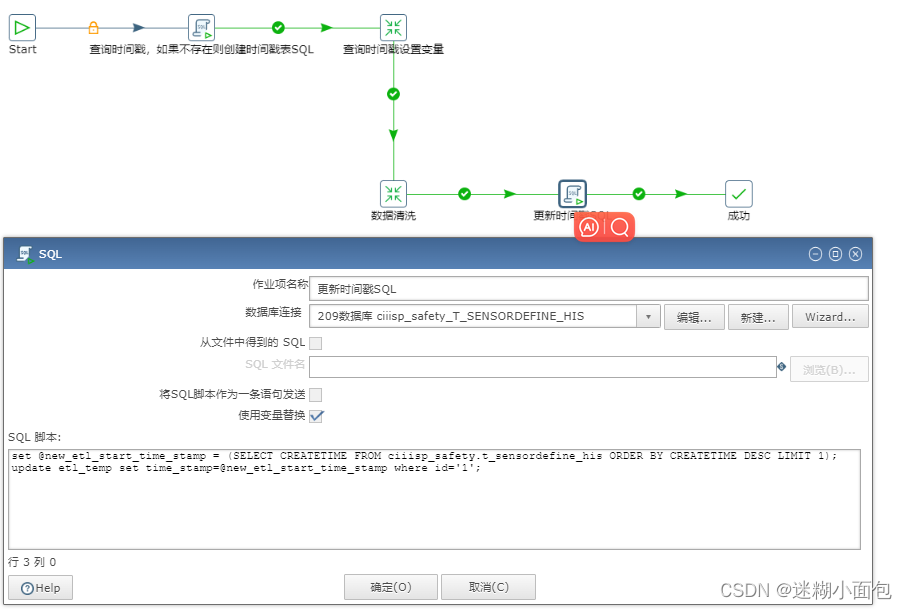
任务执行完成
三. 性能配置优化
-
索引优化: 确保数据库表的关键字段建立了合适的索引,加速数据检索和更新操作,提升同步性能。
-
缓存机制: 使用Kettle的缓存机制,将常用的数据缓存在内存中,减少对数据库的频繁访问,提高同步效率。
(1)配置修改:数据库选项修改提升性能
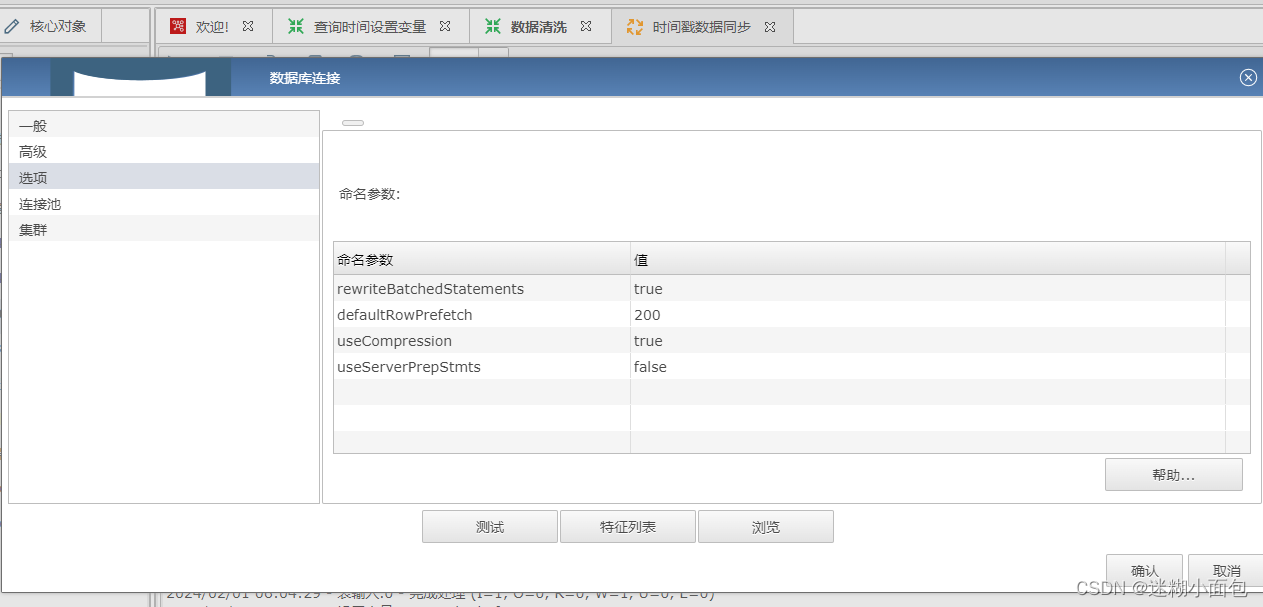
| 命名参数 | 值 |
| rewriteBatchedStatements | true |
| defaultRowPrefetch | 200 |
| useCompression | true |
| useServerPrepStmts | false |
测试结果 (平均每秒接近三万,跟网速带宽有影响)

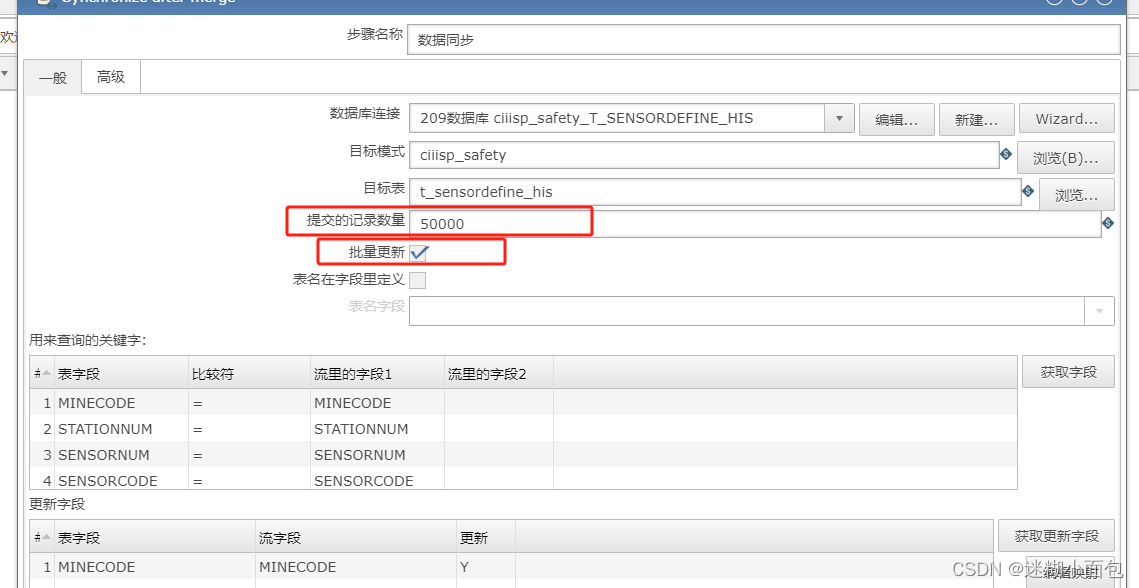
(2)批处理优化:调整同步任务的批处理大小,合理配置每批次同步的数据量,以减小数据库负载和提高同步效率
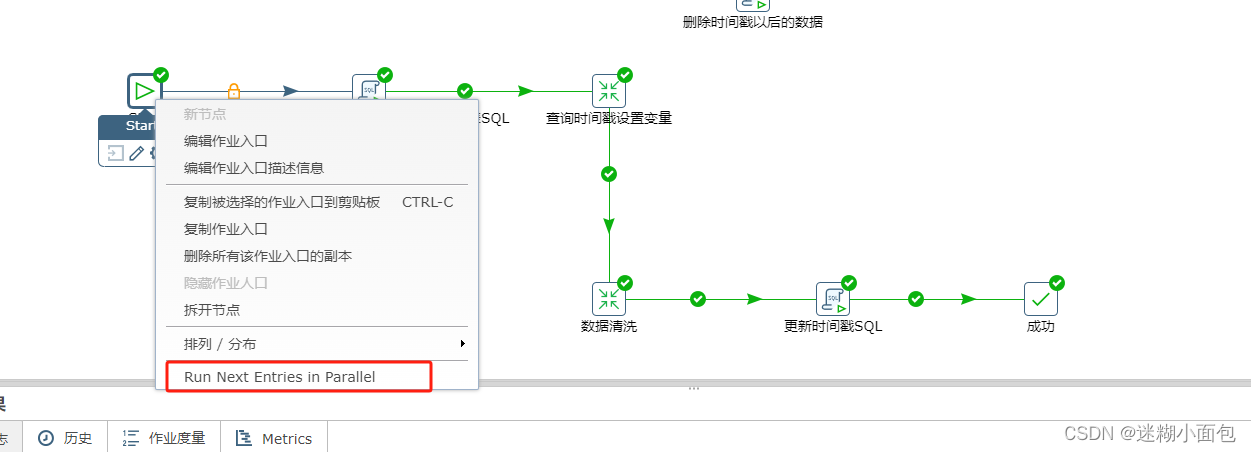
(3) 并行处理: 利用Kettle的并行处理能力,将同步任务拆分成多个子任务并行执行,充分利用系统资源,提升同步速度。
总体而言,Kettle作为一款强大的ETL工具,在数据同步方面具有丰富的功能和配置选项,通过巧妙地利用时间戳解耦和配置优化,我们能够更好地应对数据同步的挑战,提高同步效率,保障数据的及时性和准确性。