文章目录
- 1. 参考
- 2. ChatGLM3 介绍
- 3. 本地运行
- 3.1 硬件配置
- 3.2 下载ChatGLM3代码
- 3.3 量化模型
- 3.4 编译和运行
- 3.4.1 编译
- 3.4.12 运行
- 4. python绑定
- 4.1 安装
- 4.2 使用预先转换的 GGML 模型
- 总结
前面两章分别有讲到基于MacBook Pro M1芯片运行chatglm2-6b大模型和如何在本地部署chatGLM3,但是如果你的Mac的配置比较低,也没有足够的内存,然后还想运行大模型的话,那么接下来就给大家带来 基于ChatGLM.cpp实现低成本对ChatGLM3-6B的量化加速。
1. 参考
- ChatGLM.cpp
- conda安装
2. ChatGLM3 介绍
ChatGLM-6B、ChatGLM2-6B、ChatGLM3-6B 和更多 LLM 的 C++ 实现,可在 MacBook 上进行实时聊天,是通过基于c++来实现的可以跑在Mac甚至windows环境下,特点如下:
- 基于ggml的纯C++实现,工作方式与llama.cpp相同。
- 通过 int4/int8 量化、优化的 KV 缓存和并行计算加速内存高效的 CPU 推理。
- 具有打字机效果的流式生成。
- Python 绑定、Web demo、API server和更多可能性。
同时支持的如下硬件平台和模型:
- 硬件:x86/arm CPU、NVIDIA GPU、Apple Silicon GPU
- 平台:Linux、MacOS、Windows
- 模型:ChatGLM-6B, ChatGLM2-6B, ChatGLM3-6B, CodeGeeX2, Baichuan-13B, Baichuan-7B, Baichuan-13B, Baichuan2, InternLM
详细介绍参考官方README介绍。
3. 本地运行
3.1 硬件配置
- 芯片:Apple M1 Pro
- 内存:32 GB
3.2 下载ChatGLM3代码
cd /Users/joseph.wang/llm
git clone --recursive https://github.com/li-plus/chatglm.cpp.git
cd chatglm.cpp
3.3 量化模型
安装加载和量化拥模型所需的软件包
conda create -n ChatGLM3 python=3.11
conda activate chatglm2vi m
python3 -m pip install -U pip
python3 -m pip install torch tabulate tqdm transformers accelerate sentencepiece
使用convert.py转化ChatGLM3为量化的GGML格式,如将fp16原始模型转换为q4_0(量化int4) GGML模型,运行命令如下:
python3 chatglm_cpp/convert.py -i ../chatglm3-6b/ -t q8_0 -o chatglm3-ggml-q8.bin
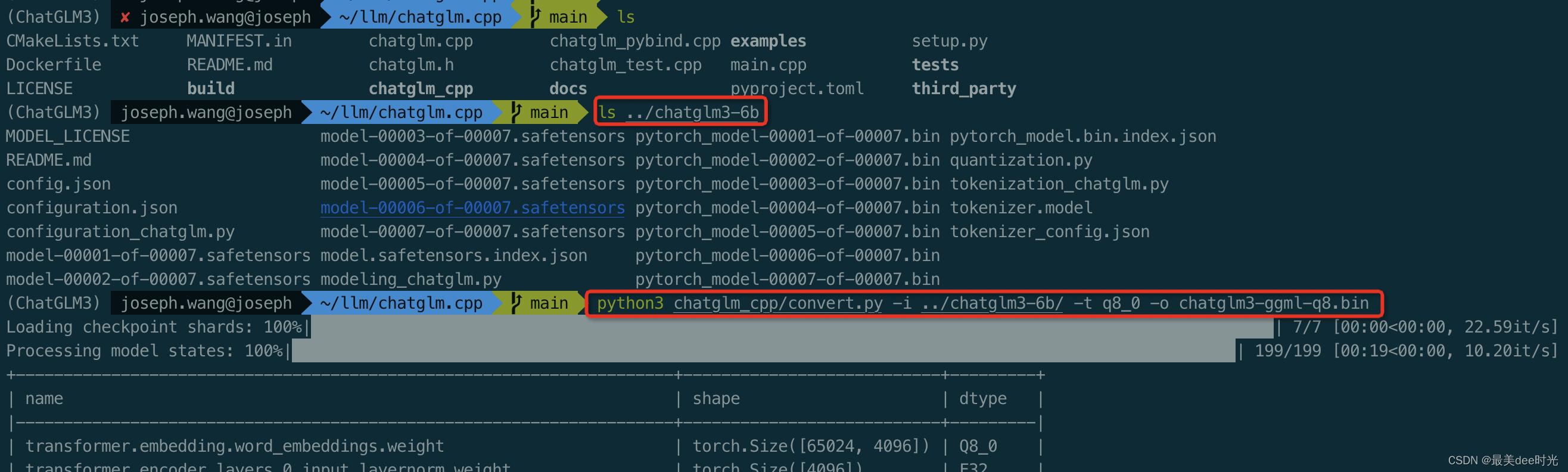

关于转换的具体参数:
- -i:指加载模型的路径
- ChatGLM-6B: THUDM/chatglm-6b, THUDM/chatglm-6b-int8, THUDM/chatglm-6b-int4
- ChatGLM2-6B: THUDM/chatglm2-6b, THUDM/chatglm2-6b-int4
- ChatGLM3-6B: THUDM/chatglm3-6b
- CodeGeeX2: THUDM/codegeex2-6b, THUDM/codegeex2-6b-int4
- Baichuan & Baichuan2: baichuan-inc/Baichuan-13B-Chat, baichuan-inc/Baichuan2-7B-Chat, baichuan-inc/Baichuan2-13B-Chat
- -t:指量化类型
- q4_0: 4-bit integer quantization with fp16 scales.
- q4_1: 4-bit integer quantization with fp16 scales and minimum values.
- q5_0: 5-bit integer quantization with fp16 scales.
- q5_1: 5-bit integer quantization with fp16 scales and minimum values.
- q8_0: 8-bit integer quantization with fp16 scales.
- f16: half precision floating point weights without quantization.
- f32: single precision floating point weights without quantization.
- -l:指将LoRA 权重合并到基本模型中。
3.4 编译和运行
3.4.1 编译
cd /Users/joseph.wang/llm/chatglm.cpp
cmake -B build
cmake --build build -j --config Release
3.4.12 运行
#单句提问
./build/bin/main -m chatglm3-ggml-q8.bin -p 你好
#交互提问
./build/bin/main -m chatglm3-ggml-q8.bin -i

Function调用

Code 解释器
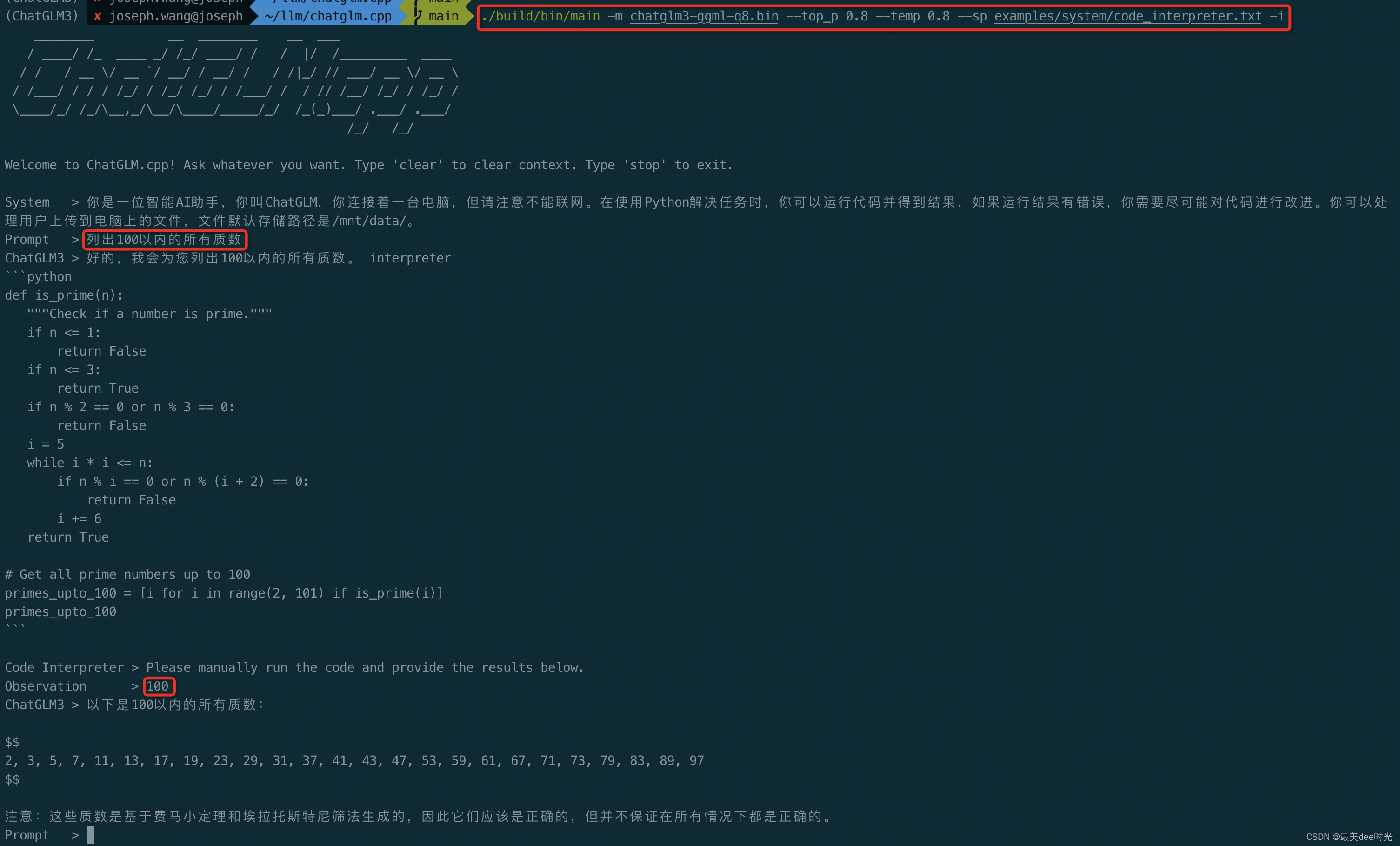
4. python绑定
Python 绑定提供了类似于原始 Hugging Face ChatGLM(2)-6B 的高级聊天和stream_chat 接口。
4.1 安装
#苹果芯片
CMAKE_ARGS="-DGGML_METAL=ON" pip install -U chatglm-cpp
或者
# install from the latest source hosted on GitHub
pip install git+https://github.com/li-plus/chatglm.cpp.git@main
# or install from your local source after git cloning the repo
pip install .
4.2 使用预先转换的 GGML 模型
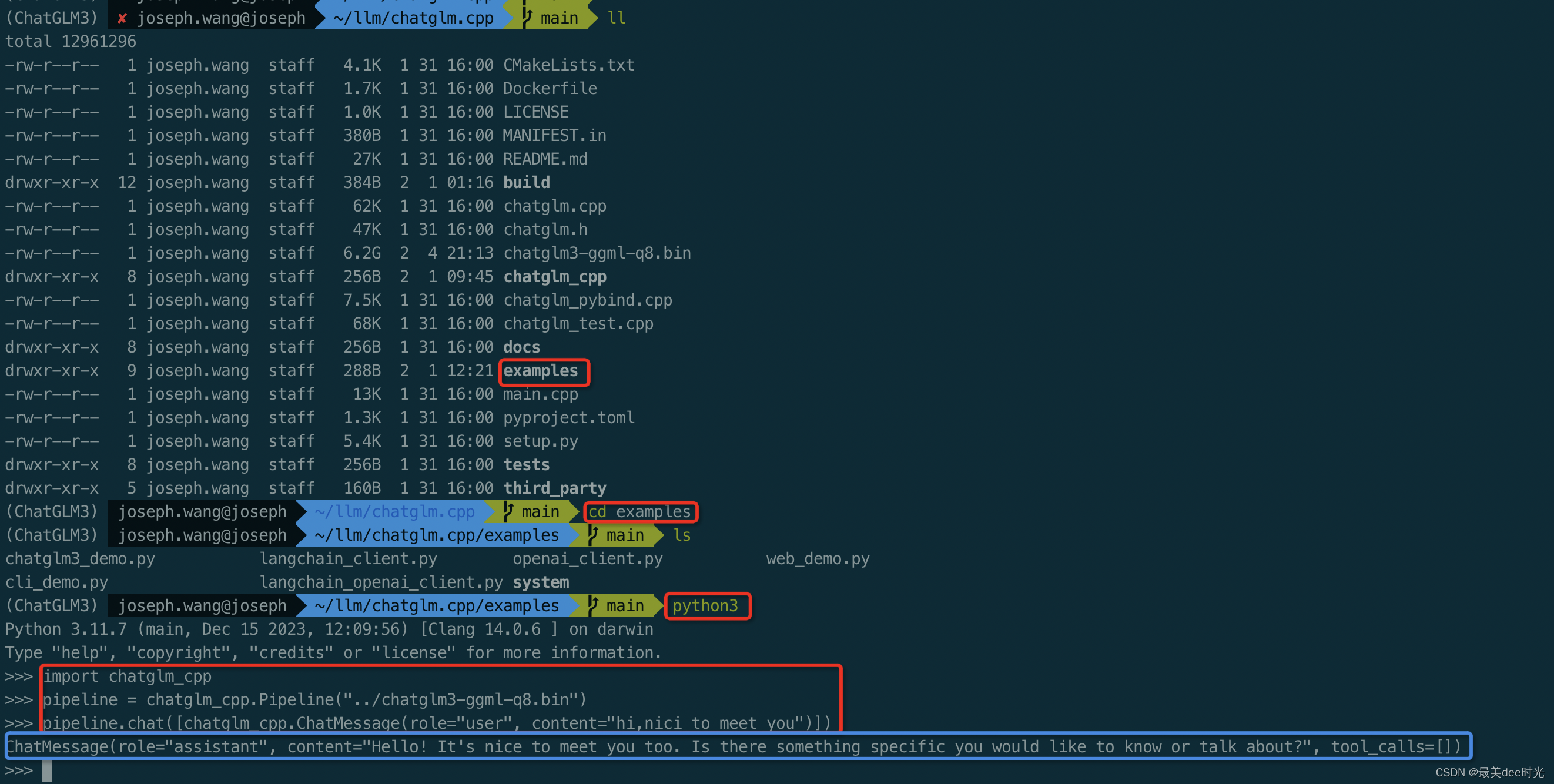
cd ~/llm/chatglm.cpp/examples
命令行键入python3进入python环境,输入如下命令
import chatglm_cpp
pipeline = chatglm_cpp.Pipeline("../chatglm3-ggml-q8.bin")
pipeline.chat([chatglm_cpp.ChatMessage(role="user", content="hi,nici to meet you")])
在stream中聊天,请运行以下 Python 示例
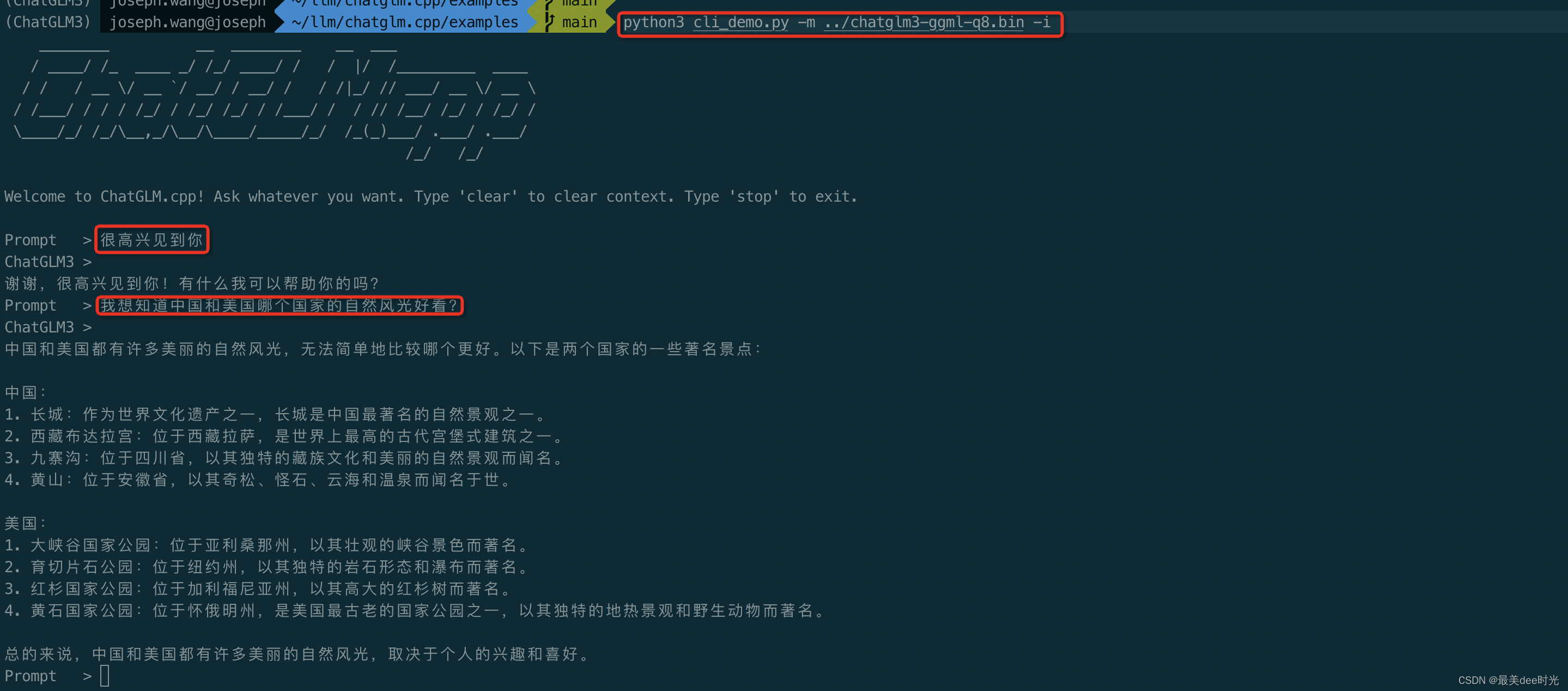
cd ~/llm/chatglm.cpp/examples
python3 cli_demo.py -m ../chatglm3-ggml-q8.bin -i
启动一个web端在浏览器中展示
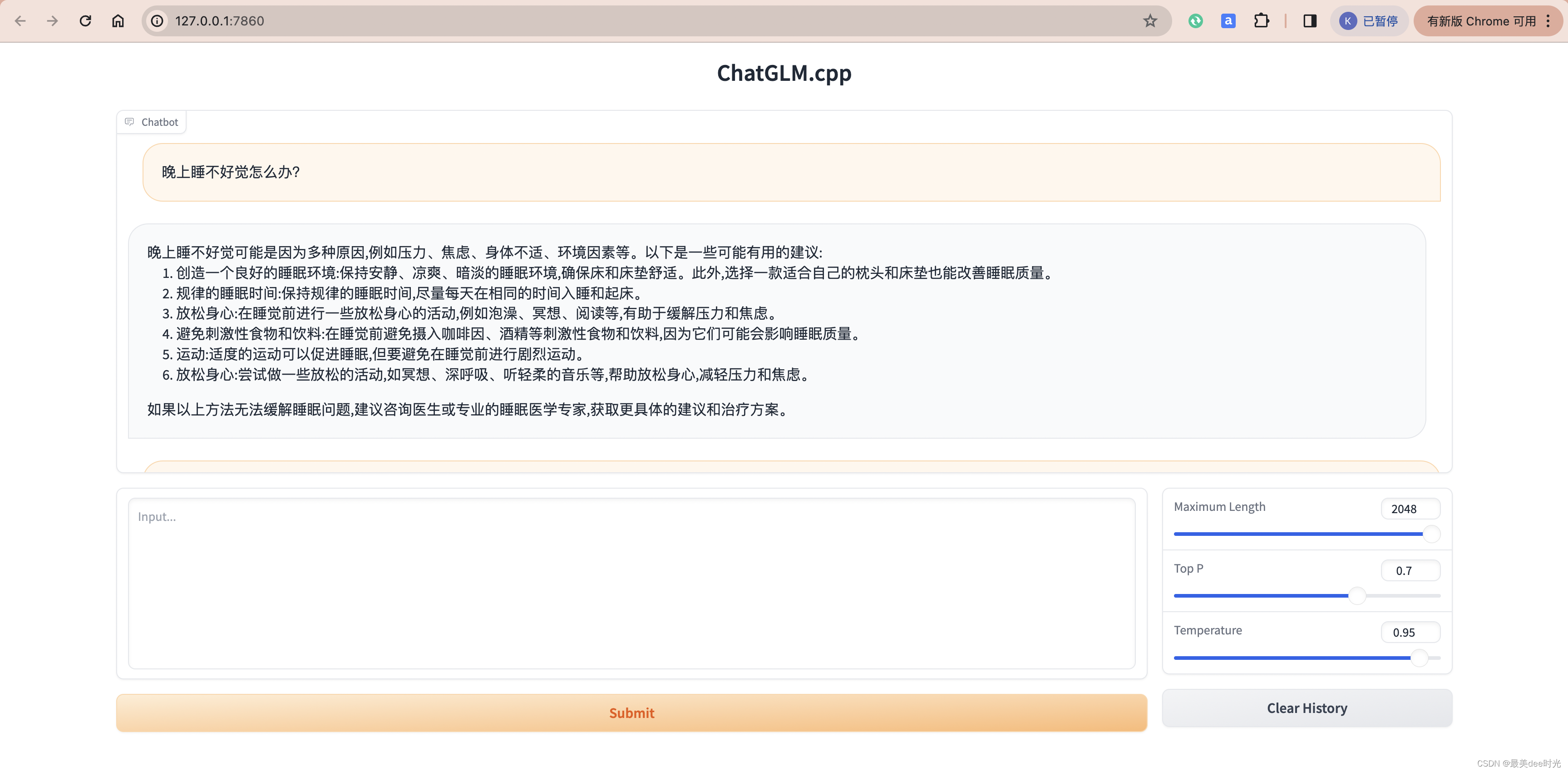
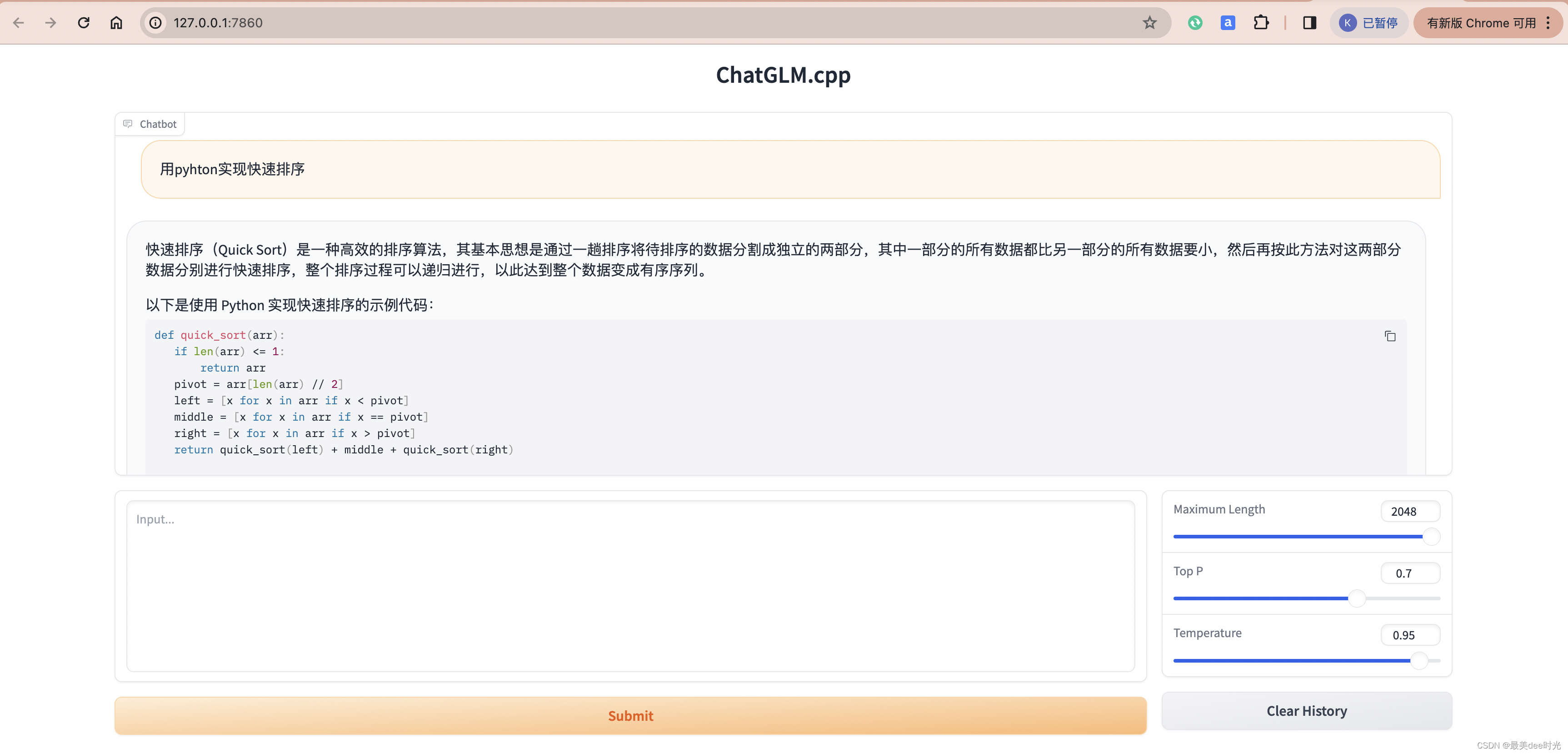
更高级的web展示
pip3 install streamlit jupyter_client ipython ipykernel
ipython kernel install --name chatglm3-demo --user
修改chatglm3_demo.py脚本中的model path
...
...
MODEL_PATH = Path(__file__).resolve().parent.parent / "chatglm3-ggml-q8.bin"
...
...
streamlit run chatglm3_demo.py
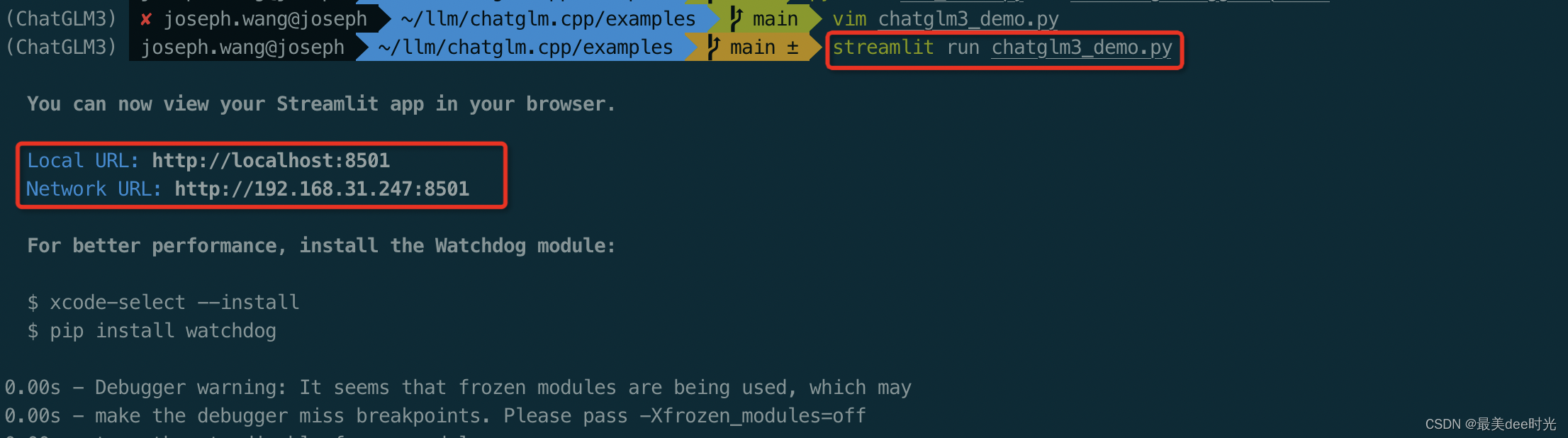
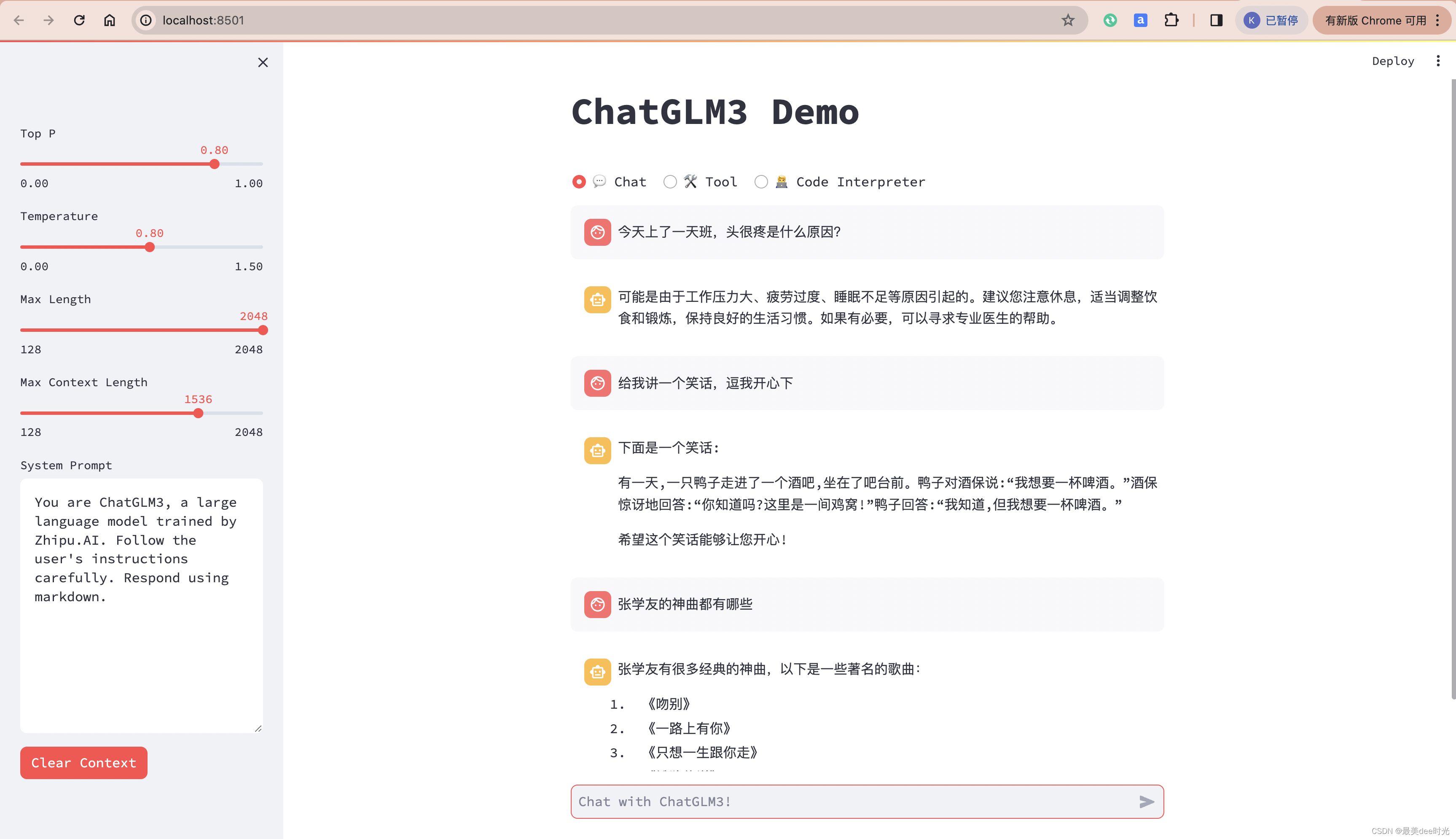
聊天模式
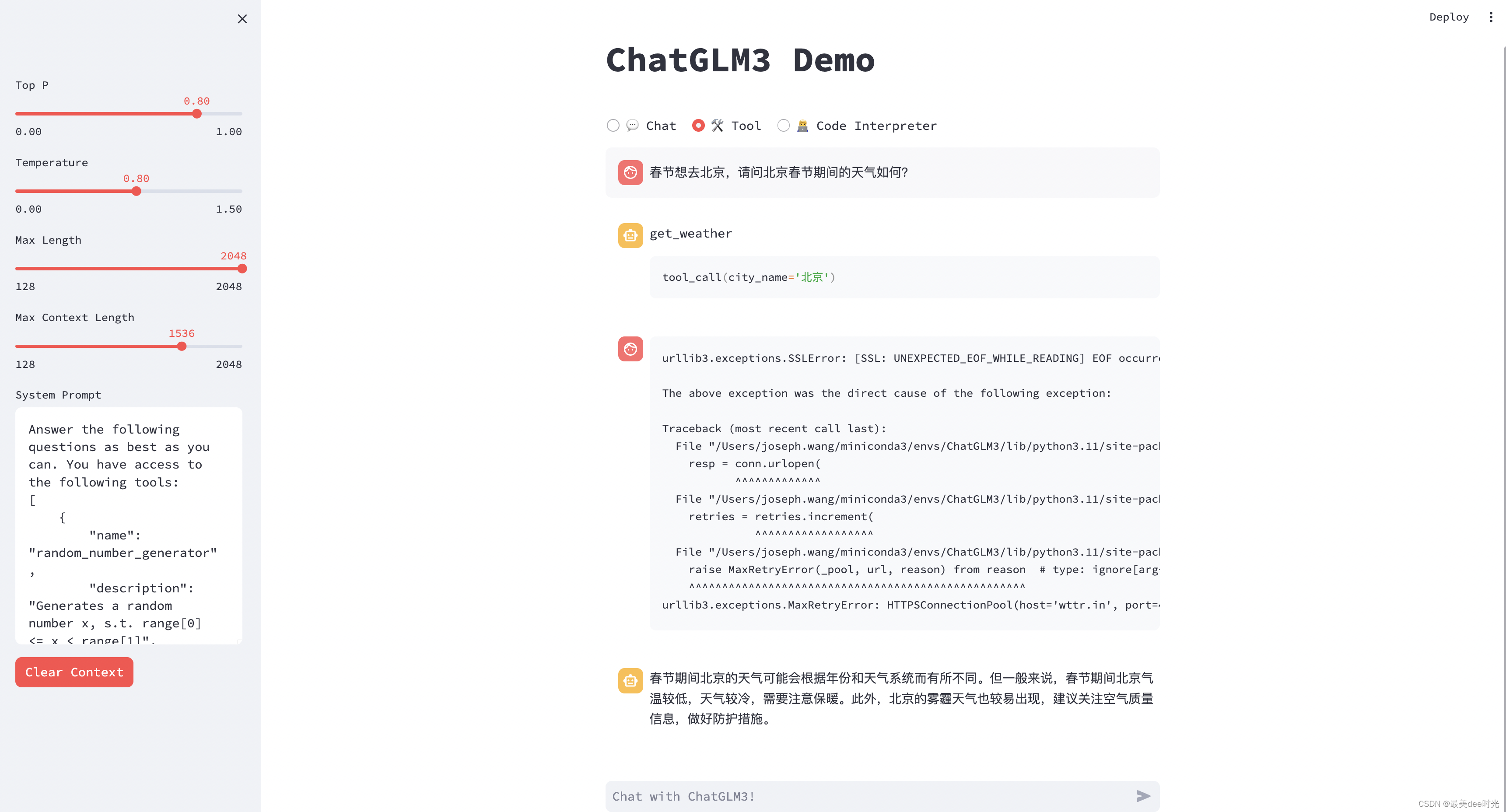
工具调用
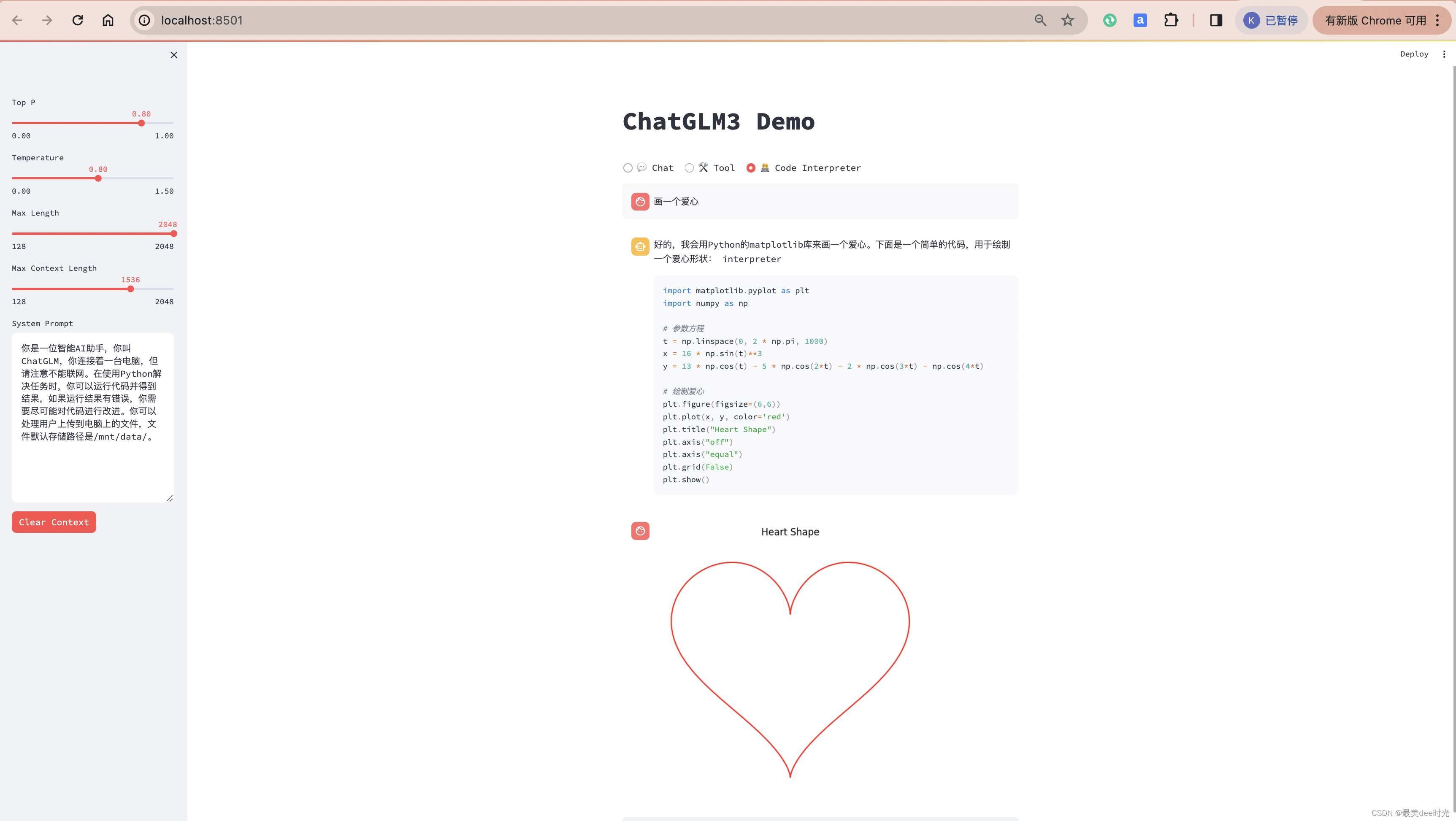
画爱心
总结
整体用下来,感觉和如何在本地部署chatGLM3的效果是一样的,速度上感觉还会更快一些,更重要的是资源使用很划算的,机器的内存也不会爆。


![[职场] 老教师对年轻教师的肺腑之言 #媒体#笔记](https://img-blog.csdnimg.cn/img_convert/1da49573bcdb10c691682dfadb2f3109.jpeg)