本章着重介绍 Hadoop 中的概念和组成部分,属于理论章节。如果你比较着急可以跳过。但作者不建议跳过,因为它与后面的章节息息相关。
Hadoop 整体设计
Hadoop 框架是用于计算机集群大数据处理的框架,所以它必须是一个可以部署在多台计算机上的软件。部署了 Hadoop 软件的主机之间通过套接字 (网络) 进行通讯。
Hadoop 主要包含 HDFS 和 MapReduce 两大组件,HDFS 负责分布储存数据,MapReduce 负责对数据进行映射、规约处理,并汇总处理结果。
Hadoop 框架最根本的原理就是利用大量的计算机同时运算来加快大量数据的处理速度。例如,一个搜索引擎公司要从上万亿条没有进行规约的数据中筛选和归纳热门词汇就需要组织大量的计算机组成集群来处理这些信息。如果使用传统数据库来处理这些信息的话,那将会花费很长的时间和很大的处理空间来处理数据,这个量级对于任何单计算机来说都变得难以实现,主要难度在于组织大量的硬件并高速地集成为一个计算机,即使成功实现也会产生昂贵的维护成本。
Hadoop 可以在多达几千台廉价的量产计算机上运行,并把它们组织为一个计算机集群。
一个 Hadoop 集群可以高效地储存数据、分配处理任务,这样会有很多好处。首先可以降低计算机的建造和维护成本,其次,一旦任何一个计算机出现了硬件故障,不会对整个计算机系统造成致命的影响,因为面向应用层开发的集群框架本身就必须假定计算机会出故障。
HDFS
Hadoop Distributed File System,Hadoop 分布式文件系统,简称 HDFS。
HDFS 用于在集群中储存文件,它所使用的核心思想是 Google 的 GFS 思想,可以存储很大的文件。
在服务器集群中,文件存储往往被要求高效而稳定,HDFS同时实现了这两个优点。
HDFS 高效的存储是通过计算机集群独立处理请求实现的。因为用户 (一半是后端程序) 在发出数据存储请求时,往往响应服务器正在处理其他请求,这是导致服务效率缓慢的主要原因。但如果响应服务器直接分配一个数据服务器给用户,然后用户直接与数据服务器交互,效率会快很多。
数据存储的稳定性往往通过"多存几份"的方式实现,HDFS 也使用了这种方式。HDFS 的存储单位是块 (Block) ,一个文件可能会被分为多个块储存在物理存储器中。因此 HDFS 往往会按照设定者的要求把数据块复制 n 份并存储在不同的数据节点 (储存数据的服务器) 上,如果一个数据节点发生故障数据也不会丢失。
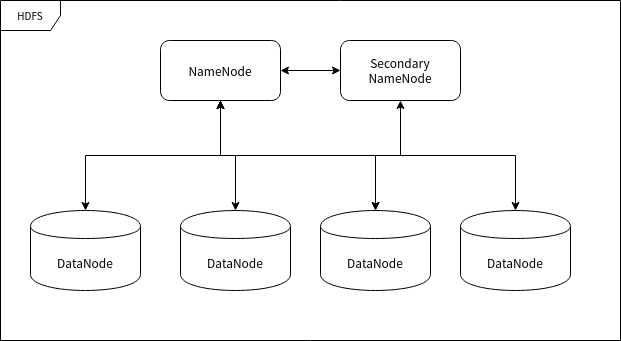
HDFS 的节点
HDFS 运行在许多不同的计算机上,有的计算机专门用于存储数据,有的计算机专门用于指挥其它计算机储存数据。这里所提到的"计算机"我们可以称之为集群中的节点。
命名节点 (NameNode)
命名节点 (NameNode) 是用于指挥其它节点存储的节点。任何一个"文件系统"(File System, FS) 都需要具备根据文件路径映射到文件的功能,命名节点就是用于储存这些映射信息并提供映射服务的计算机,在整个 HDFS 系统中扮演"管理员"的角色,因此一个 HDFS 集群中只有一个命名节点。
数据节点 (DataNode)
数据节点 (DataNode) 使用来储存数据块的节点。当一个文件被命名节点承认并分块之后将会被储存到被分配的数据节点中去。数据节点具有储存数据、读写数据的功能,其中存储的数据块比较类似于硬盘中的"扇区"概念,是 HDFS 存储的基本单位。
副命名节点 (Secondary NameNode)
副命名节点 (Secondary NameNode) 别名"次命名节点",是命名节点的"秘书"。这个形容很贴切,因为它并不能代替命名节点的工作,无论命名节点是否有能力继续工作。它主要负责分摊命名节点的压力、备份命名节点的状态并执行一些管理工作,如果命名节点要求它这样做的话。如果命名节点坏掉了,它也可以提供备份数据以恢复命名节点。副命名节点可以有多个。
MapReduce
MapReduce 的含义就像它的名字一样浅显:Map 和 Reduce (映射和规约) 。
大数据处理
大量数据的处理是一个典型的"道理简单,实施复杂"的事情。之所以"实施复杂",主要是大量的数据使用传统方法处理时会导致硬件资源 (主要是内存) 不足。
现在有一段文字 (真实环境下这个字符串可能长达 1 PB 甚至更多) ,我们执行一个简单的"数字符"统计,即统计出这段文字中所有出现过的字符出现的数量:
AABABCABCDABCDE
统计之后的结果应该是:
| 字符 | 出现次数 |
|---|---|
| A | 5 |
| B | 4 |
| C | 3 |
| D | 2 |
| E | 1 |
统计的过程实际上很简单,就是每读取一个字符就要检查表中是否已经有相同的字符,如果没有就添加一条记录并将记录值设置为 1 ,如果有的话就直接将记录值增加 1。
但是如果我们将这里的统计对象由"字符"变成"词",那么样本容量就瞬间变得非常大,以至于一台计算机可能难以统计数十亿用户一年来用过的"词"。
在这种情况下我们依然有办法完成这项工作——我们先把样本分成一段段能够令单台计算机处理的规模,然后一段段地进行统计,每执行完一次统计就对映射统计结果进行规约处理,即将统计结果合并到一个更庞大的数据结果中去,最终就可以完成大规模的数据规约。
在以上的案例中,第一阶段的整理工作就是"映射",把数据进行分类和整理,到这里为止,我们可以得到一个相比于源数据小很多的结果。第二阶段的工作往往由集群来完成,整理完数据之后,我们需要将这些数据进行总体的归纳,毕竟有可能多个节点的映射结果出现重叠分类。这个过程中映射的结果将会进一步缩略成可获取的统计结果。
MapReduce 概念
我在 IBM 的网站上找到了一篇 MapReduce 文章,地址:What is Apache MapReduce? | IBM 。现在我改编其中的一个 MapReduce 的处理案例来介绍 MapReduce 的原理细节以及相关概念。
这是一个非常简单的 MapReduce 示例。无论需要分析多少数据,关键原则都是相同的。
假设有 5 个文件,每个文件包含两列,分别记录一个城市的名称以及该城市在不同测量日期记录的相应温度。城市名称是键 (Key) ,温度是值 (Value) 。例如:(厦门,20)。现在我们要在所有数据中找到每个城市的最高温度 (请注意,每个文件中可能出现相同的城市)。
使用 MapReduce 框架,我们可以将其分解为 5 个映射任务,其中每个任务负责处理五个文件中的一个。每个映射任务会检查文件中的每条数据并返回该文件中每个城市的最高温度。
例如,对于以下数据:
| 城市 | 温度 |
|---|---|
| 厦门 | 12 |
| 上海 | 34 |
| 厦门 | 20 |
| 上海 | 15 |
| 北京 | 14 |
| 北京 | 16 |
| 厦门 | 24 |
上述数据的一个映射任务产生的结果如下所示:
| 城市 | 最高温度 |
|---|---|
| 厦门 | 24 |
| 上海 | 34 |
| 北京 | 16 |
假设其他四个映射器任务产生以下结果:
| 城市 | 最高温度 |
|---|---|
| 厦门 | 17 |
| 杭州 | 25 |
| 上海 | 29 |
| 北京 | 36 |
| 厦门 | 30 |
| 杭州 | 17 |
| 上海 | 31 |
| 北京 | 35 |
| 厦门 | 18 |
| 杭州 | 17 |
| 上海 | 17 |
| 北京 | 27 |
| 厦门 | 28 |
| 杭州 | 18 |
| 上海 | 14 |
| 北京 | 27 |
所有这 5 个结果将被输入到 Reduce 任务中,该任务组合输入结果并输出每个城市的单个值,产生如下的最终结果:
| 城市 | 最高温度 |
|---|---|
| 厦门 | 30 |
| 上海 | 34 |
| 北京 | 36 |
| 杭州 | 25 |
打个比方,你可以把 MapReduce 想象成人口普查,人口普查局会把若干个调查员派到每个城市。每个城市的每个人口普查人员都将统计该市的部分人口数量,然后将结果汇总返回首都。在首都,每个城市的统计结果将被规约到单个计数(各个城市的人口),然后就可以确定国家的总人口。这种人到城市的映射是并行的,然后合并结果(Reduce)。这比派一个人以连续的方式清点全国中的每一个人效率高得多。
希望你也学会了,更多编程源码模板请来二当家的素材网:https://www.erdangjiade.com