作者:来自 Elastic Akhilesh Pokhariyal, Cesar Munoz, Bryce Buchanan
适用于本机应用程序的 Elastic APM 提供传出 HTTP 请求和视图加载的自动检测,捕获自定义事件、错误和崩溃,并包括用于数据分析和故障排除目的的预构建仪表板。

适用于 iOS 和 Android 本机应用程序的 Elastic® APM 在堆栈版本 v8.12 中正式发布。 Elastic iOS 和 Android APM 代理是开源的,并且是在顶部开发的,即分别作为 OpenTelemetry Swift 和 Android SDK/API 的发行版。
移动 APM 解决方案概述
适用于 iOS 和 Android 的 OpenTelemetry SDK/API 支持自动检测 HTTP 请求、手动检测 API、基于 OpenTelemetry 语义约定的数据模型以及缓冲支持等功能。 此外,Elastic APM 代理发行版还支持更简单的初始化过程和新颖的功能,例如远程配置和基于用户会话的采样。 Elastic iOS 和 Android APM 代理的发行版是根据 Elastic 的标准支持条款和条件进行维护的。
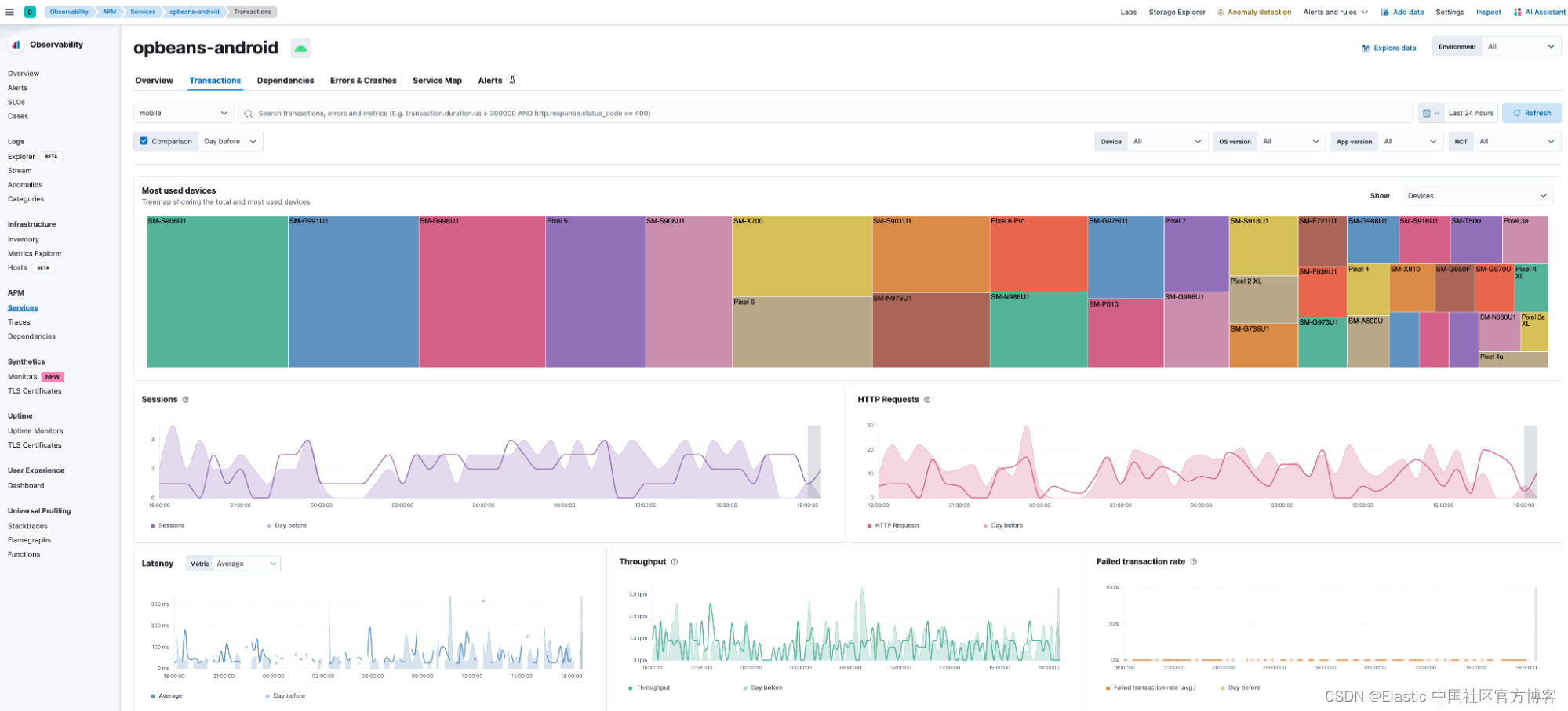
Kibana® 中提供了精选或预构建的仪表板,用于监控、数据分析和故障排除。 下面显示的 Sevice Overview 视图提供了相关的前端 KPI,例如崩溃率、http 请求、平均应用程序加载时间等,包括比较视图。

此外,用户流量的地理分布可在国家和地区级别的地图上获得。 服务概览仪表板还显示吞吐量、延迟、交易失败率以及按设备型号、网络连接类型和应用程序版本划分的流量分布等指标趋势。
下面显示的事务视图突出显示了不同事务组的性能,包括各个 transaction 的端到端分布式跟踪以及关联跨度、错误和崩溃的链接。 此外,用户可以一目了然地看到按设备品牌和型号、应用程序版本和操作系统版本划分的流量分布情况。
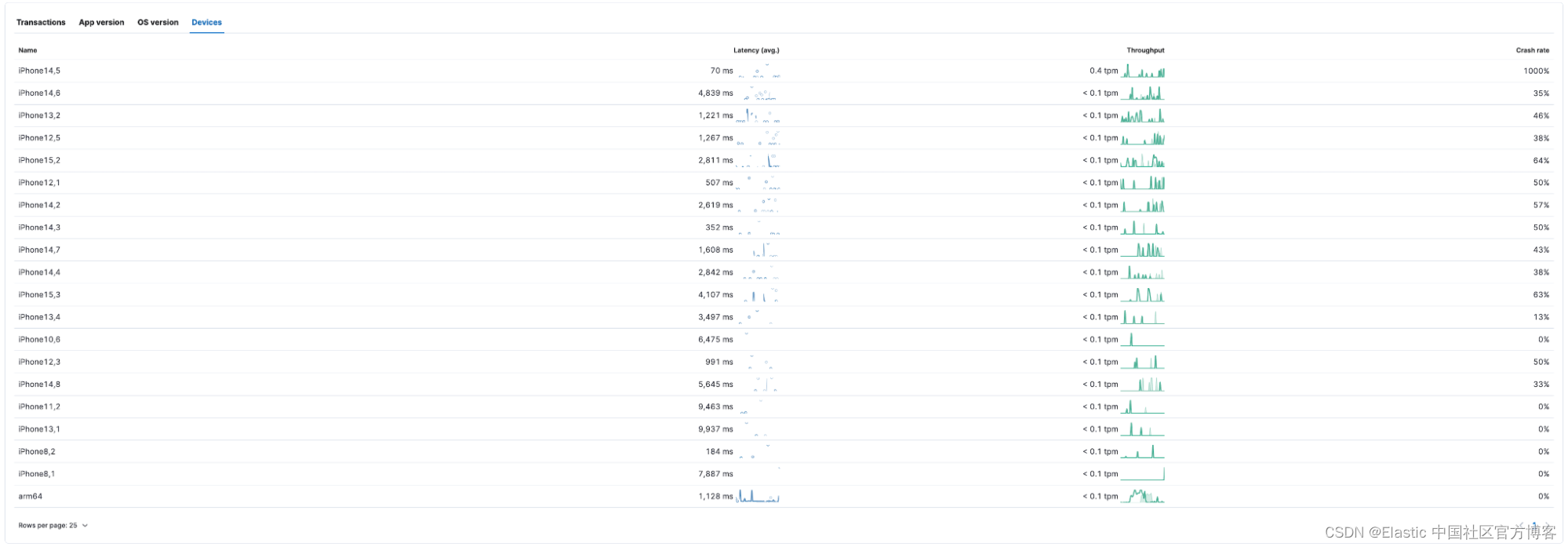
表格视图(例如下面突出显示的位于 “transactions” 选项卡底部的表格视图)可以相对轻松地查看设备制造商和型号、应用程序版本等如何影响延迟和崩溃率。
下面显示的 Errors & Crashes 视图可用于分析不同的错误和崩溃组。 此视图中还提供了单个错误或崩溃实例的未符号化 (iOS) 或模糊化 (Android) 堆栈跟踪。

下面显示的 Service Map 视图提供了端到端服务相互依赖关系的可视化,包括任何第三方 API、代理服务器和数据库。

用于观察 Kibana 中的移动前端的全面预构建仪表板提供了对错误、崩溃和瓶颈来源的可见性,从而简化了生产环境中问题的故障排除。 底层 Elasticsearch® 平台还支持查询原始数据、构建自定义指标和自定义仪表板、警报、SLO 和异常检测的功能。 总而言之,该平台提供了一套全面的工具来加快根本原因分析和修复,从而促进高速创新。
一些错误场景的调试工作流程演练
接下来,我们将演练 iOS 和 Android 本机应用程序中的几个错误场景的配置详细信息和故障排除工作流程。
场景1
在此示例中,我们将使用 Apple 的崩溃报告 symbolication以 及 breadcrumbs 来调试异步方法中的崩溃,以推断崩溃的原因。
Symbolication
在这种情况下,用户注意到 “Errors & Crashes” 选项卡中特定崩溃组的崩溃发生次数激增,并决定进一步调查。 “Crashes” 选项卡上出现新的崩溃,开发人员按照以下步骤在本地表示崩溃报告。
1. 通过 UI 复制崩溃并将其粘贴到具有以下名称格式 , 例如,<AppBinaryName>_<DateTime>. For example, “opbeans-swift_2024-01-18-114211.ips。
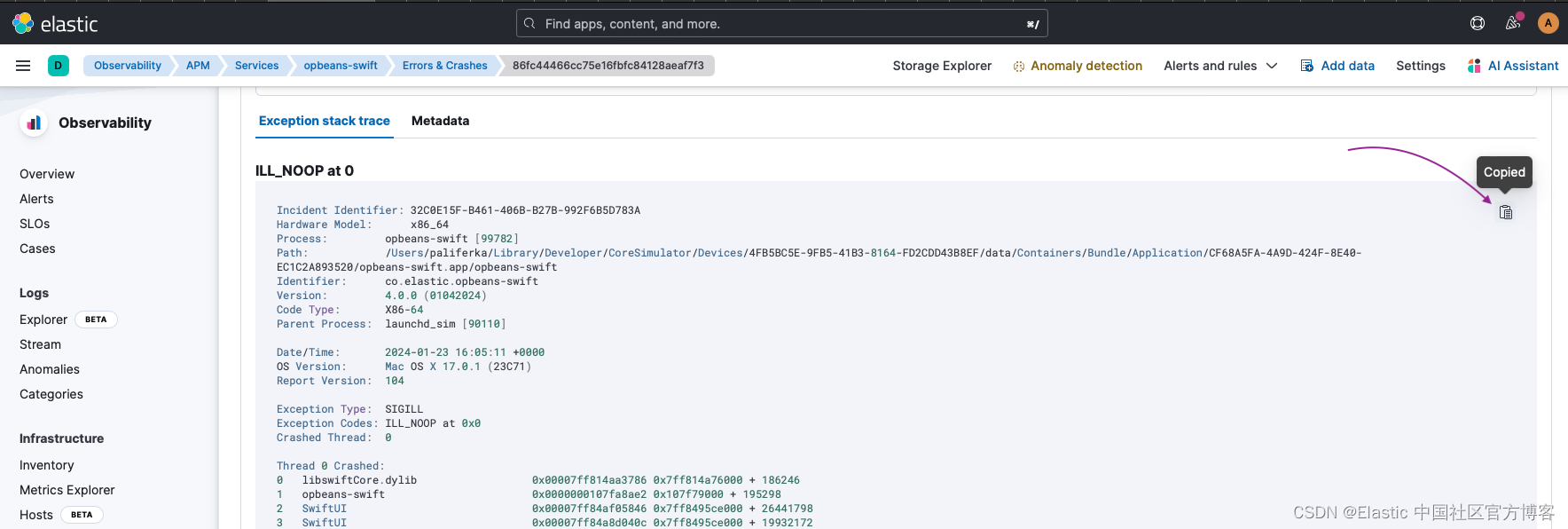
2. Apple 提供了有关如何通过 Xcode 自动或使用命令行手动在本地符号化此文件的详细说明。
Breadcrumbs
第一个线程的第二帧显示崩溃发生在 Worker 实例中。
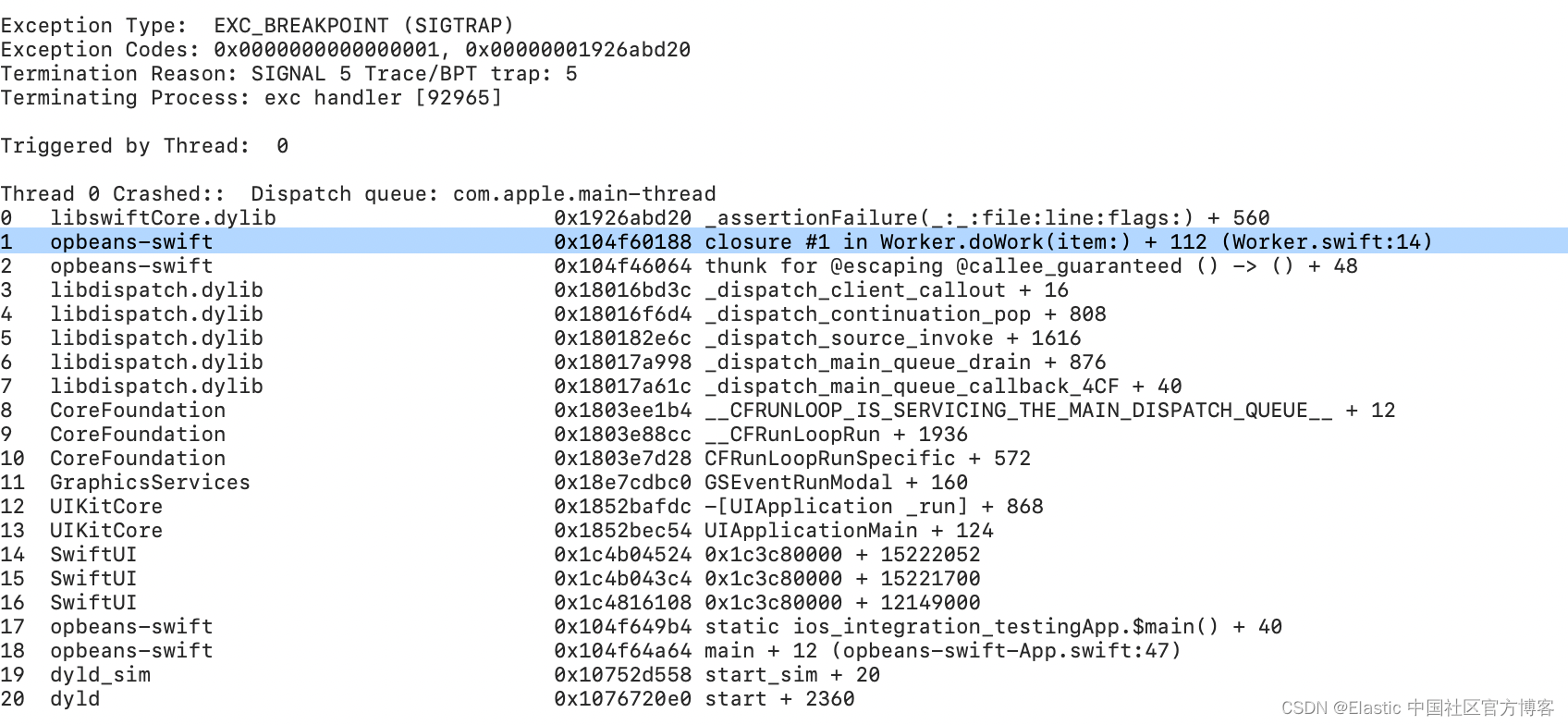
这个实例实际上在很多地方都有使用,并且由于这个函数的异步特性,不可能立即确定这个调用来自哪里。 尽管如此,我们可以利用开放遥测 SDK 的功能为这些崩溃添加更多上下文,然后将各个部分组合在一起以找到崩溃的位置。
通过在该 Worker 实例周围添加 “breadcrumbs”,可以追踪哪些对 Worker 的调用实际上与此次崩溃相关。
例子:
在 Worker 类中创建一个 loggerprovider 作为公共变量以便于访问,如下所示:

在调用 Worker.doWork() 函数的地方创建 breadcrumbs:

每个 breadcrumbs 都将使用相同的事件 name “worker_breadcrumb”,以便可以一致地查询它们,并且将使用 “source” 属性来完成区分。
在此示例中,Worker.doWork() 函数是从 CustomerRow 结构(执行 “onTapGesture” 的表行)调用的。 如果你要从 CustomerRow 结构中的多个位置调用此方法,你还可以向 “source” 属性值添加其他区别,例如关联函数(例如 “CustomerRow#onTapGesture”)。
现在应用程序正在报告这些 breadcrumbs,我们可以使用 Discover 来 query 它们,如下所示:

注意:代理发送的事件 names 将转换为 Elastic 通用架构 (ECS) 中的事件操作,因此请确保查询使用此字段。
- 你可以添加一个过滤器:`event.action: “worker_breadcrumb”`,它会显示从这个新 breadcrumb 生成的所有事件。
- 你还可以查看各种来源:ProductRow、CustomerRow、CartRow 等。
- 如果将 error.type: crash 添加到查询中,你可以在 breadcrumbs 旁边看到崩溃:

时间线中彼此相邻的崩溃和 breadcrumb 可能来自完全不同的设备,因此我们需要另一个区分器。 对于每次崩溃,我们都有包含与崩溃关联的 session.id 的元数据,可以从 “Metadata” 选项卡查看。 我们可以使用此 session.id 进行查询,以确保我们在 Discover 中查看的唯一数据来自导致崩溃的单个用户会话(即单个设备)。
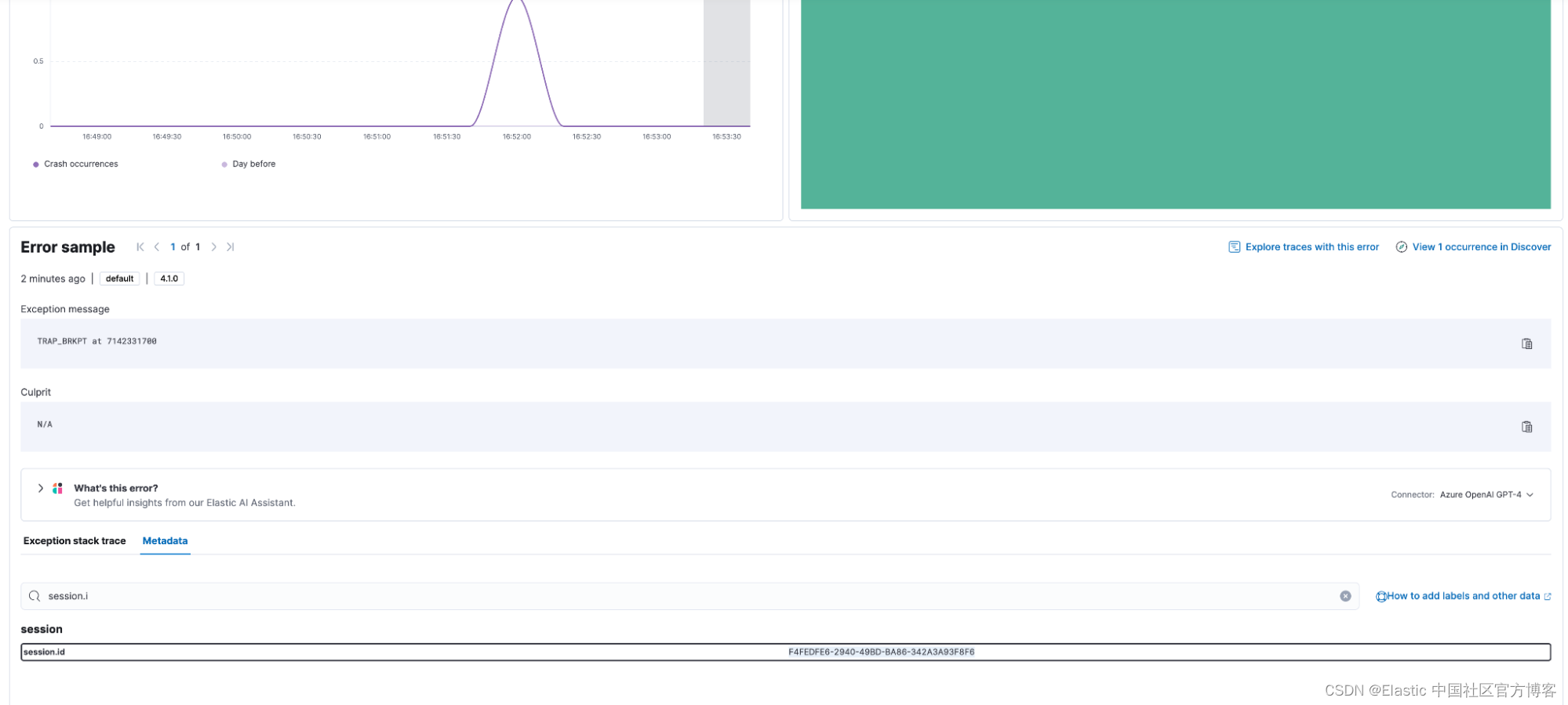
在 Discover 中,我们现在可以通过 breadcrumbs 在单个设备上查看有关崩溃的会话事件流,如下所示:

场景 2
注意:此场景需要 Elastic Android 代理版本 “0.14.0” 或更高版本。
Android 示例应用程序有一个由两个屏幕组成的表单,这两个屏幕是使用两个片段(“FirstPage” 和 “SecondPage”)创建的。 在第一个屏幕中,应用程序进行后端 API 调用以获取标识表单提交的密钥。 该密钥存储在应用程序的内存中,并且必须在发送表单的最后一个屏幕上可用; 密钥必须与表单数据一起发送。

问题
当用户单击 “FINISH” 按钮时,我们开始在 “Errors & Crashes” 选项卡中看到 Kibana 中的崩溃发生率激增(空指针异常),这些崩溃似乎总是发生在表单的最后一个屏幕上。 然而,这并不总是可重现的,因此仅通过查看崩溃的堆栈跟踪并不清楚根本原因。 它看起来是这样的:

当我们查看堆栈跟踪中引用的代码时,我们可以看到以下内容:
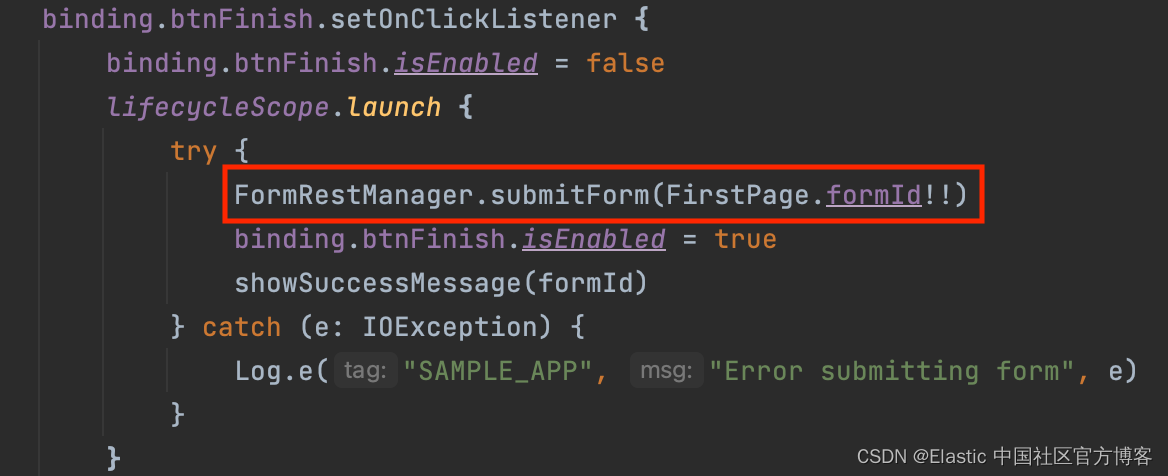
这是发生崩溃的行,因此在执行此代码时,变量 “formId”(位于 “FirstPage” 中的静态字符串)似乎为空,导致引发空指针异常。 后端请求完成以检索 id 后,此变量在 “FirstPage” 片段中设置。 到达 “SecondPage” 的唯一方法是穿过 “FirstPage”。 因此,单独的堆栈跟踪并没有多大帮助,因为页面必须按顺序打开,并且第一个页面始终会设置 “formId” 变量。 因此,“SecondPage” 中的 formId 似乎不太可能为空。
寻找根本原因
除了查看崩溃的堆栈跟踪之外,查看补充数据也很有用,这些数据有助于将各个部分组合在一起,并更全面地了解崩溃发生时我们的应用程序运行时发生的其他事情。 对于这种情况,我们知道表单 ID 必须来自我们的后端服务,因此我们可以首先排除后端调用存在错误。 我们通过在事务详细信息视图中检查执行表单 ID 请求的 FirstPage 片段创建过程中的跟踪来完成此操作:
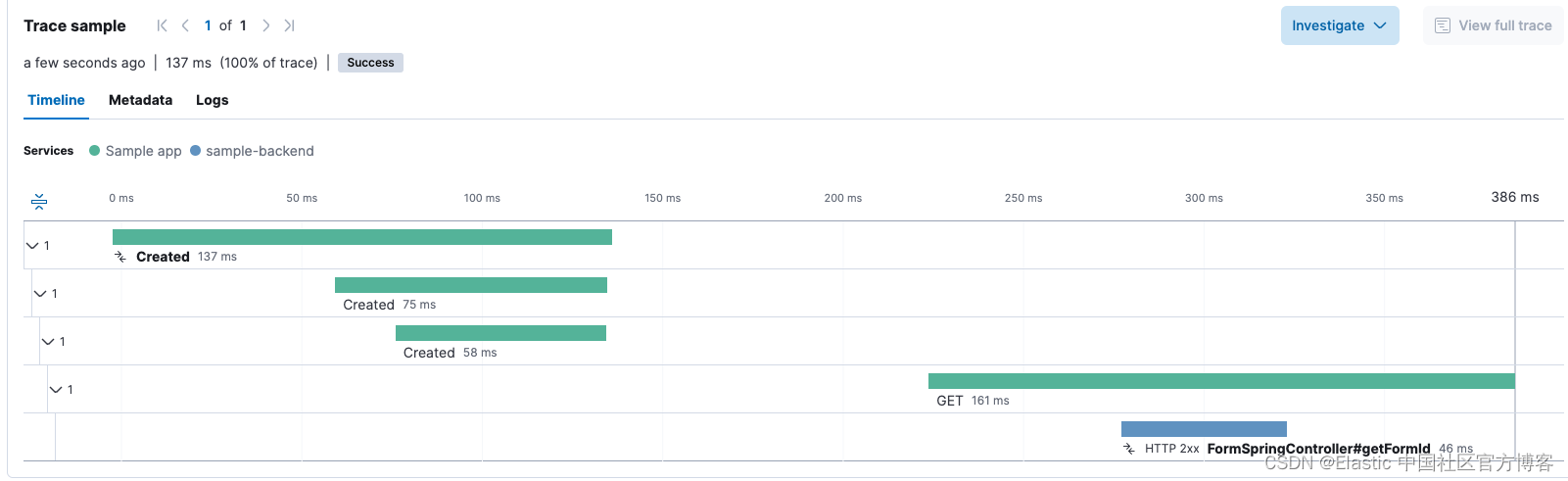
"Created” span 表示创建第一个片段所花费的时间。 最上面的显示了 Activity 创建,然后是 NavHostFragment,最后是 “FirstScreen”。 创建后不久,我们看到向后端发出了 GET HTTP 请求来检索表单 ID,并且根据跟踪,GET 请求成功。 因此,我们可以排除该问题是后端通信存在问题。
另一种选择可能是查看发生崩溃的应用程序中整个会话期间发送的日志(我们也可以查看来自我们应用程序的所有日志,但它们太多,无法分析这一问题)。 为此,我们首先复制一个跨度的 “session.id” 值(任何 span 都可以工作,因为在崩溃发生期间从我们的应用程序发送的所有数据中都可以使用相同的会话 ID) 在跨度详细信息弹出窗口中。

注意:在崩溃元数据中也可以找到相同的会话 ID。
现在我们已经确定了会话,我们可以打开日志资源管理器视图并查看同一会话中应用程序的所有日志,如下所示:
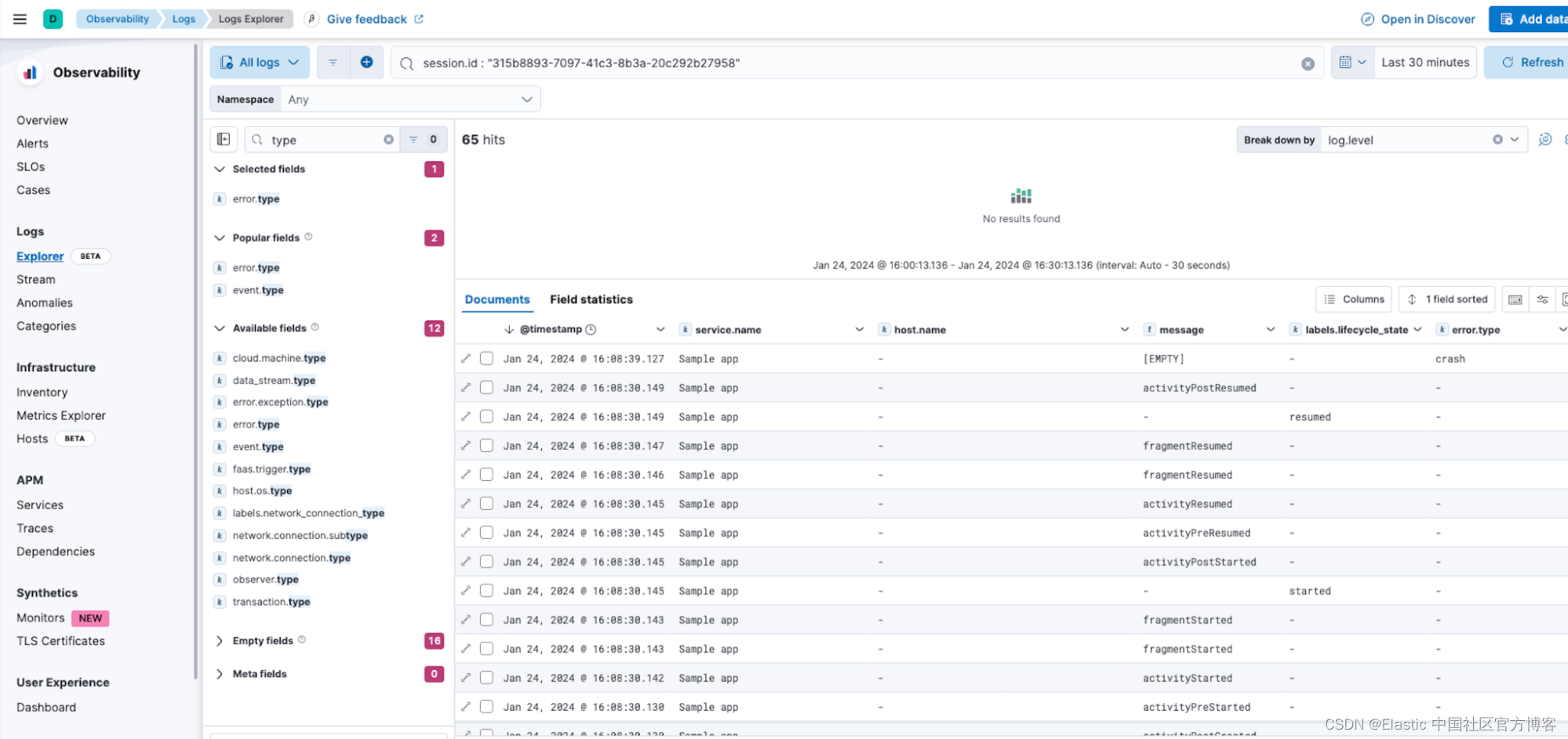
通过查看日志并添加一些字段来显示应用程序的生命周期状态和错误类型,我们可以看到从应用程序自动收集的日志事件。 我们可以看到列表顶部的崩溃事件是最新的。 我们还可以看到应用程序的生命周期事件,如果继续滚动,我们将看到一些生命周期事件,这些事件将有助于找到根本原因:

我们可以看到有几个生命周期事件告诉我们应用程序在会话期间重新启动。 这是一个重要的提示,因为它意味着 Android 操作系统在某个时刻杀死了我们的应用程序,当应用程序在后台停留一段时间时,这种情况很常见。 有了这些信息,我们可以尝试通过强制操作系统在后台终止我们的应用程序来重现该问题,然后查看它从最近打开的应用程序菜单重新打开时的行为。
尝试后,我们可以重现该问题,我们发现应用程序重新启动时静态 “formId” 变量丢失,导致当 SecondPage 片段请求它时它为空。 我们现在可以研究将参数传递给片段的最佳实践,这样我们就可以更改代码以防止依赖静态字段,而是在屏幕之间存储和共享值,从而防止再次发生这种崩溃。
额外的好处:对于这个场景,我们依靠 APM 代理自动发送的事件就足够了; 但是,如果这些对于其他情况还不够,我们始终可以通过 OpenTelemetry 事件 API 在想要跟踪应用程序状态更改的位置发送自定义事件,如下面的代码片段所示:

充分利用你的 Elastic APM 体验
在这篇文章中,我们回顾了 Elastic 8.12 中提供的新移动 APM 解决方案。 新解决方案使用 Elastic 的新 iOS 和 Android APM 代理,这些代理是开源的,并且是在顶部开发的,即分别作为 OpenTelemetry Swift 和 Android SDK/API 的发行版。
我们还审查了 iOS 和 Android 本机应用程序中两种错误场景的配置详细信息和故障排除工作流程。
- iOS 场景:使用 Apple 的崩溃报告符号和面包屑来调试异步方法中的崩溃,以推断崩溃的原因。
- Android 场景:分析为什么用户点击表单的 “FINISH” 按钮时,最后一屏出现空指针异常。 通过查看崩溃的堆栈跟踪来分析这一点并不总是很清楚,而且不容易重现。
在这两种情况下,我们都使用移动设备的分布式跟踪以及相关日志找到了崩溃的根本原因。 希望本博客回顾了 Elastic 如何帮助管理和监控移动本机应用程序。
Elastic 邀请 SRE 和开发人员亲身体验我们的移动 APM 解决方案,并开启他们数据任务的新视野。 今天就尝试一下 https://ela.st/free-Trial。
原文:Elastic APM for iOS and Android Native apps | Elastic Blog