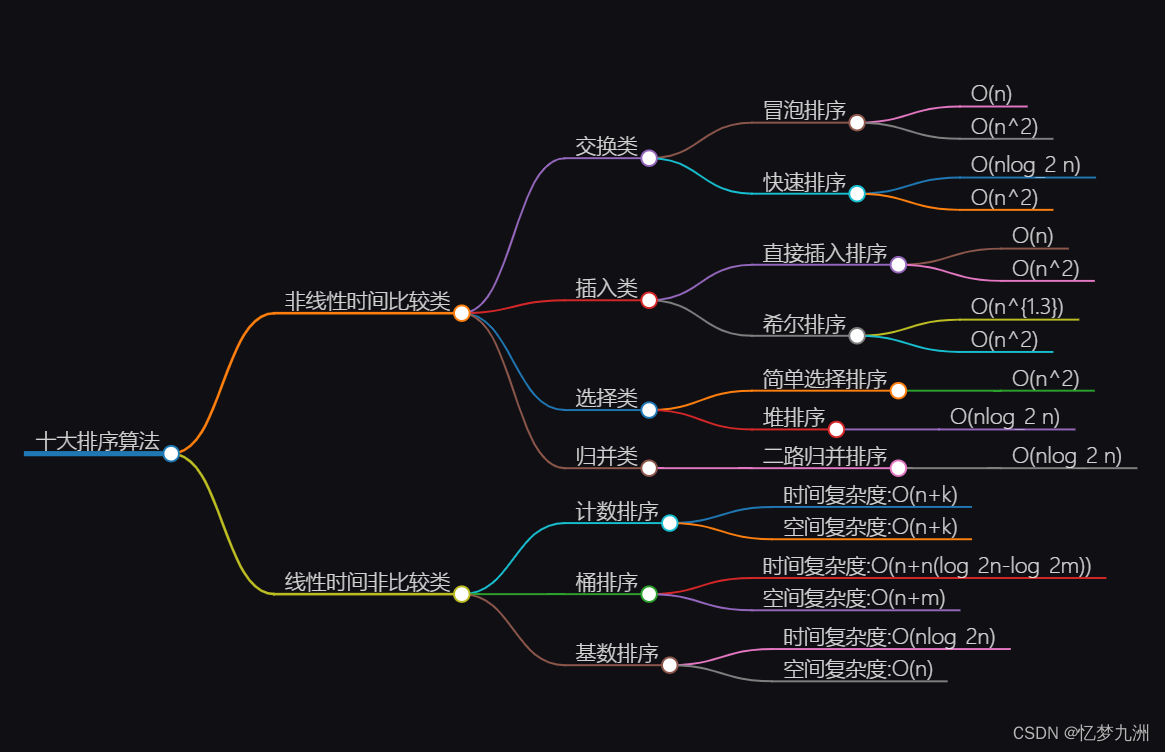
1.基本概念及应用场景
回归分析是一种预测性的建模技术,数学建模中常用回归分析技术寻找存在相关关系的变量间的数学表达式,并进行统计推断。例如,司机的鲁莽驾驶与交通事故的数量之间的关系就可以用回归分析研究。回归分析根据变量的数目分为一元回归和多元回归,根据自变量和因变量的表现形式分为线性和非线性。
回归模型:描述因变量y如何依赖于自变量x和误差项e的方程。
回归方程:描述因变量y如何依赖于自变量x的方程。
2.回归分析的一般步骤
- 确定回归方程中的解释变量和被解释变量
- 确定回归模型,建立回归方程
- 对回归方程进行各种检验
- 用回归方程进行预测
3.一元线性回归分析
1.概念
例子:
- 人均收入是否显著影响人均食品消费支出
- 贷款余额是否影响到不良贷款
- 航班正点率是否对顾客投诉次数有显著影响
回归模型:
:截距
:斜率
:误差项,反映随机因数对y的影响,是不可避免的
回归方程:
若回归方程中的未知参数已知,则对于给定的x值,可计算出y的期望值。
用样本统计量代替未知参数,就得到估计的回归方程,称回归直线。
2.最小二乘法求参数
常用最小二乘法,即使残差(因变量的观察值与估计值的离差)平方和达到最小求参数:
展开:
求偏导并整理:
代入数据即可得到及
3.点估计
将x的值代入回归方程即可得对应的点估计值。
4.区间估计
估计标准误差:
估计标准误差越小,则数据点围绕回归直线的分散程度越小,回归方程的代表性越大,可靠性越高。
置信区间:
预测区间:
:显著性水平
:置信水平
:即
,n-k为残差自由度(样本容量-回归系数的数量),一元线性回归方程中k=2
模型建立和求解的Python代码:
import numpy as np
import statsmodels.api as sm
import scipy.stats as stats
import matplotlib.pyplot as plt
plt.rc('font', family='SimHei') # 用来正常显示中文标签
plt.rc('axes', unicode_minus=False) # 用来正常显示负号# 输入数据
x = np.array([143, 145, 146, 147, 149, 150, 153, 154, 155, 156, 157, 158, 159, 160, 162, 164])
y = np.array([88, 85, 88, 91, 92, 93, 93, 95, 96, 98, 97, 96, 98, 99, 100, 102])# 添加截距项
X = sm.add_constant(x)# 求参数值
model = sm.OLS(y, X).fit()
beta = model.params
print("参数值:")
print("beta0 =", beta[0])
print("beta1 =", beta[1])# 点估计
x0 = float(input("x="))
y_pred = beta[0] + beta[1] * x0
print("点估计预测值:", y_pred)# 计算标准误差
se = np.sqrt(model.mse_resid)# 自由度
n = len(x)
df = n - model.df_model - 1# 置信水平和 t 分位数
alpha = 0.05
t = np.abs(stats.t.ppf(alpha/2, df))# 计算置信区间和预测区间
x_mean = np.mean(x)
x_var = np.sum((x - x_mean)**2)
conf_interval = t * se * np.sqrt(1/n + (x - x_mean)**2 / x_var)
pred_interval = t * se * np.sqrt(1 + 1/n + (x - x_mean)**2 / x_var)# 绘制原始数据和回归直线
plt.scatter(x, y, color='blue', marker='*', label='原始数据')
plt.plot(x, model.fittedvalues, color='red', label='回归直线')
plt.xlabel('x')
plt.ylabel('y')# 绘制置信区间和预测区间
plt.fill_between(x, model.fittedvalues - conf_interval, model.fittedvalues + conf_interval, color='gray', alpha=0.3, label='置信区间')
plt.fill_between(x, model.fittedvalues - pred_interval, model.fittedvalues + pred_interval, color='yellow', alpha=0.3, label='预测区间')plt.legend()
plt.show()
5.模型检验
1.回归直线的拟合优度
回归直线与各观测点的接近程度称为回归直线对数据的拟合优度。
评价拟合优度的指标:
- 总平方和(TSS):反映因变量的n个观测值与其均值的总离差
- 回归平方和(ESS):反映了y的总变差中,由于x与y之间的线性关系引起的y的变化部分
- 残差平方和(RSS):反映了其他因素对y变差的作用,是不能由回归直线来解释的y的变差部分
99