DataX源码分析
- 一、总体流程
- 二、程序入口
- 1.datax.py
- 2.com.alibaba.datax.core.Engine.java
- 3.切分的逻辑
- 并发数的确认
- 3.调度
- 3.1 确定组数和分组算法
- 3.2 数据传输
- 三、DataX性能优化
- 1.关键参数
- 2.优化:提升每个 channel 的速度
- 3.优化:提升 DataX Job 内 Channel 并发数
- 3.1 配置全局 Byte 限速以及单 Channel Byte 限速
- 3.2 配置全局 Record 限速以及单 Channel Record 限速
- 3.3 直接配置 Channel 个数
- 3.提高 JVM 堆内存
一、总体流程
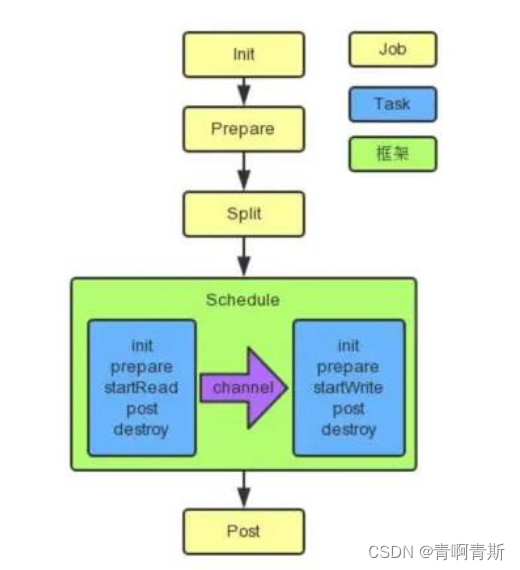
- 黄色: Job 部分的执行阶段
- 蓝色: Task 部分的执行阶段
- 绿色:框架执行阶段。
二、程序入口
1.datax.py
ENGINE_COMMAND = "java -server ${jvm} %s -classpath %s ${params} com.alibaba.datax.core.Engine -mode ${mode} -jobid ${jobid} -job ${job}" % (DEFAULT_PROPERTY_CONF, CLASS_PATH)
- 从这里看出来,java的入口是:
com.alibaba.datax.core.Engine
2.com.alibaba.datax.core.Engine.java
- 路径是:datax/core/src/main/java/com/alibaba/datax/core/Engine.java
参数加载、容器创建、容器启动
public void start(Configuration allConf) {// 绑定column转换信息ColumnCast.bind(allConf);/*** 初始化PluginLoader,可以获取各种插件配置*/LoadUtil.bind(allConf);boolean isJob = !("taskGroup".equalsIgnoreCase(allConf.getString(CoreConstant.DATAX_CORE_CONTAINER_MODEL)));//JobContainer会在schedule后再行进行设置和调整值int channelNumber =0;AbstractContainer container;long instanceId;int taskGroupId = -1;if (isJob) {// 如果是作业,创建作业容器allConf.set(CoreConstant.DATAX_CORE_CONTAINER_JOB_MODE, RUNTIME_MODE);container = new JobContainer(allConf);instanceId = allConf.getLong(CoreConstant.DATAX_CORE_CONTAINER_JOB_ID, 0);} else {// 如果不是作业容器,创建作业组容器container = new TaskGroupContainer(allConf);instanceId = allConf.getLong(CoreConstant.DATAX_CORE_CONTAINER_JOB_ID);taskGroupId = allConf.getInt(CoreConstant.DATAX_CORE_CONTAINER_TASKGROUP_ID);channelNumber = allConf.getInt(CoreConstant.DATAX_CORE_CONTAINER_TASKGROUP_CHANNEL);}//缺省打开perfTraceboolean traceEnable = allConf.getBool(CoreConstant.DATAX_CORE_CONTAINER_TRACE_ENABLE, true);boolean perfReportEnable = allConf.getBool(CoreConstant.DATAX_CORE_REPORT_DATAX_PERFLOG, true);//standalone模式的 datax shell任务不进行汇报if(instanceId == -1){perfReportEnable = false;}Configuration jobInfoConfig = allConf.getConfiguration(CoreConstant.DATAX_JOB_JOBINFO);//初始化PerfTracePerfTrace perfTrace = PerfTrace.getInstance(isJob, instanceId, taskGroupId, traceEnable);perfTrace.setJobInfo(jobInfoConfig,perfReportEnable,channelNumber);container.start();}
容器启动的执行过程
@Override
public void start() {LOG.info("DataX jobContainer starts job.");boolean hasException = false;boolean isDryRun = false;try {this.startTimeStamp = System.currentTimeMillis();isDryRun = configuration.getBool(CoreConstant.DATAX_JOB_SETTING_DRYRUN, false);if(isDryRun) {LOG.info("jobContainer starts to do preCheck ...");this.preCheck();} else {userConf = configuration.clone();LOG.debug("jobContainer starts to do preHandle ...");//Job 前置操作this.preHandle();LOG.debug("jobContainer starts to do init ...");//初始化 reader 和 writerthis.init();LOG.info("jobContainer starts to do prepare ...");//全局准备工作,比如 odpswriter 清空目标表this.prepare();LOG.info("jobContainer starts to do split ...");// 拆分task是重点要看的this.totalStage = this.split();LOG.info("jobContainer starts to do schedule ...");// 调度是重点要看的this.schedule();LOG.debug("jobContainer starts to do post ...");this.post();LOG.debug("jobContainer starts to do postHandle ...");this.postHandle();LOG.info("DataX jobId [{}] completed successfully.", this.jobId);this.invokeHooks();}} catch (Throwable e) {...} finally {...}
}
3.切分的逻辑
private int split() {// 调整channel数量this.adjustChannelNumber();if (this.needChannelNumber <= 0) {this.needChannelNumber = 1;}// 切分逻辑:读和写的数量必须要对应。自己写插件的时候需要注意List<Configuration> readerTaskConfigs = this.doReaderSplit(this.needChannelNumber);int taskNumber = readerTaskConfigs.size();List<Configuration> writerTaskConfigs = this.doWriterSplit(taskNumber);List<Configuration> transformerList = this.configuration.getListConfiguration(CoreConstant.DATAX_JOB_CONTENT_TRANSFORMER);LOG.debug("transformer configuration: "+ JSON.toJSONString(transformerList));/*** 输入是reader和writer的parameter list,输出是content下面元素的list*/List<Configuration> contentConfig = mergeReaderAndWriterTaskConfigs(readerTaskConfigs, writerTaskConfigs, transformerList);LOG.debug("contentConfig configuration: "+ JSON.toJSONString(contentConfig));this.configuration.set(CoreConstant.DATAX_JOB_CONTENT, contentConfig);return contentConfig.size();}
并发数的确认
private void adjustChannelNumber() {int needChannelNumberByByte = Integer.MAX_VALUE;int needChannelNumberByRecord = Integer.MAX_VALUE;// 每秒传输的字节数的上限// 配置在json文件的 job.setting.speed.byteboolean isByteLimit = (this.configuration.getInt(CoreConstant.DATAX_JOB_SETTING_SPEED_BYTE, 0) > 0);if (isByteLimit) {long globalLimitedByteSpeed = this.configuration.getInt(CoreConstant.DATAX_JOB_SETTING_SPEED_BYTE, 10 * 1024 * 1024);// 在byte流控情况下,单个Channel流量最大值必须设置,否则报错!Long channelLimitedByteSpeed = this.configuration.getLong(CoreConstant.DATAX_CORE_TRANSPORT_CHANNEL_SPEED_BYTE);if (channelLimitedByteSpeed == null || channelLimitedByteSpeed <= 0) {throw DataXException.asDataXException(FrameworkErrorCode.CONFIG_ERROR,"在有总bps限速条件下,单个channel的bps值不能为空,也不能为非正数");}needChannelNumberByByte =(int) (globalLimitedByteSpeed / channelLimitedByteSpeed);needChannelNumberByByte =needChannelNumberByByte > 0 ? needChannelNumberByByte : 1;LOG.info("Job set Max-Byte-Speed to " + globalLimitedByteSpeed + " bytes.");}//这个参数用于设置总TPS(记录每秒)限速。// 配置在json文件的 job.setting.speed.recordboolean isRecordLimit = (this.configuration.getInt(CoreConstant.DATAX_JOB_SETTING_SPEED_RECORD, 0)) > 0;if (isRecordLimit) {long globalLimitedRecordSpeed = this.configuration.getInt(CoreConstant.DATAX_JOB_SETTING_SPEED_RECORD, 100000);Long channelLimitedRecordSpeed = this.configuration.getLong(CoreConstant.DATAX_CORE_TRANSPORT_CHANNEL_SPEED_RECORD);if (channelLimitedRecordSpeed == null || channelLimitedRecordSpeed <= 0) {throw DataXException.asDataXException(FrameworkErrorCode.CONFIG_ERROR,"在有总tps限速条件下,单个channel的tps值不能为空,也不能为非正数");}needChannelNumberByRecord =(int) (globalLimitedRecordSpeed / channelLimitedRecordSpeed);needChannelNumberByRecord =needChannelNumberByRecord > 0 ? needChannelNumberByRecord : 1;LOG.info("Job set Max-Record-Speed to " + globalLimitedRecordSpeed + " records.");}// 取较小值this.needChannelNumber = needChannelNumberByByte < needChannelNumberByRecord ?needChannelNumberByByte : needChannelNumberByRecord;// 如果从byte或record上设置了needChannelNumber则退出if (this.needChannelNumber < Integer.MAX_VALUE) {return;}// 这个参数用于设置DataX Job内Channel的并发数。// 配置在json文件的 job.setting.speed.channelboolean isChannelLimit = (this.configuration.getInt(CoreConstant.DATAX_JOB_SETTING_SPEED_CHANNEL, 0) > 0);if (isChannelLimit) {this.needChannelNumber = this.configuration.getInt(CoreConstant.DATAX_JOB_SETTING_SPEED_CHANNEL);LOG.info("Job set Channel-Number to " + this.needChannelNumber+ " channels.");return;}throw DataXException.asDataXException(FrameworkErrorCode.CONFIG_ERROR,"Job运行速度必须设置");}
3.调度
3.1 确定组数和分组算法
- datax/core/src/main/java/com/alibaba/datax/core/job/JobContainer.java
private void schedule() {/*** 这里的全局speed和每个channel的速度设置为B/s*/int channelsPerTaskGroup = this.configuration.getInt(CoreConstant.DATAX_CORE_CONTAINER_TASKGROUP_CHANNEL, 5);int taskNumber = this.configuration.getList(CoreConstant.DATAX_JOB_CONTENT).size();// this.needChannelNumber参数在split里面计算出来的,和taskNumber任务数 取最小值this.needChannelNumber = Math.min(this.needChannelNumber, taskNumber);PerfTrace.getInstance().setChannelNumber(needChannelNumber);/*** 通过获取配置信息得到每个taskGroup需要运行哪些tasks任务*/// 公平的分配task到对应的taskGroup中List<Configuration> taskGroupConfigs = JobAssignUtil.assignFairly(this.configuration,this.needChannelNumber, channelsPerTaskGroup);LOG.info("Scheduler starts [{}] taskGroups.", taskGroupConfigs.size());ExecuteMode executeMode = null;AbstractScheduler scheduler;try {executeMode = ExecuteMode.STANDALONE;scheduler = initStandaloneScheduler(this.configuration);//设置 executeModefor (Configuration taskGroupConfig : taskGroupConfigs) {taskGroupConfig.set(CoreConstant.DATAX_CORE_CONTAINER_JOB_MODE, executeMode.getValue());}if (executeMode == ExecuteMode.LOCAL || executeMode == ExecuteMode.DISTRIBUTE) {if (this.jobId <= 0) {throw DataXException.asDataXException(FrameworkErrorCode.RUNTIME_ERROR,"在[ local | distribute ]模式下必须设置jobId,并且其值 > 0 .");}}LOG.info("Running by {} Mode.", executeMode);this.startTransferTimeStamp = System.currentTimeMillis();// 这里调用了schedulescheduler.schedule(taskGroupConfigs);this.endTransferTimeStamp = System.currentTimeMillis();} catch (Exception e) {LOG.error("运行scheduler 模式[{}]出错.", executeMode);this.endTransferTimeStamp = System.currentTimeMillis();throw DataXException.asDataXException(FrameworkErrorCode.RUNTIME_ERROR, e);}/*** 检查任务执行情况*/this.checkLimit();}
- 如果100个Task和20个Channel,需要几个TaskGroup?
- 每个TaskGroup默认5个channel,那么需要4个组
public final class JobAssignUtil {private JobAssignUtil() {}public static List<Configuration> assignFairly(Configuration configuration, int channelNumber, int channelsPerTaskGroup) {...// 计算需要多少个TaskGrouop组的核心逻辑int taskGroupNumber = (int) Math.ceil(1.0 * channelNumber / channelsPerTaskGroup);...// 计算N个Task如何分到这些TaskGroup组List<Configuration> taskGroupConfig = doAssign(resourceMarkAndTaskIdMap, configuration, taskGroupNumber);}
}
分组算法
/*** /*** 需要实现的效果通过例子来说是:* <pre>* a 库上有表:0, 1, 2* b 库上有表:3, 4* c 库上有表:5, 6, 7** 如果有 4个 taskGroup* 则 assign 后的结果为:* taskGroup-0: 0, 4,* taskGroup-1: 3, 6,* taskGroup-2: 5, 2,* taskGroup-3: 1, 7** </pre>*/private static List<Configuration> doAssign(LinkedHashMap<String, List<Integer>> resourceMarkAndTaskIdMap, Configuration jobConfiguration, int taskGroupNumber) {List<Configuration> contentConfig = jobConfiguration.getListConfiguration(CoreConstant.DATAX_JOB_CONTENT);Configuration taskGroupTemplate = jobConfiguration.clone();taskGroupTemplate.remove(CoreConstant.DATAX_JOB_CONTENT);List<Configuration> result = new LinkedList<Configuration>();List<List<Configuration>> taskGroupConfigList = new ArrayList<List<Configuration>>(taskGroupNumber);for (int i = 0; i < taskGroupNumber; i++) {taskGroupConfigList.add(new LinkedList<Configuration>());}int mapValueMaxLength = -1;List<String> resourceMarks = new ArrayList<String>();for (Map.Entry<String, List<Integer>> entry : resourceMarkAndTaskIdMap.entrySet()) {resourceMarks.add(entry.getKey());if (entry.getValue().size() > mapValueMaxLength) {mapValueMaxLength = entry.getValue().size();}}int taskGroupIndex = 0;for (int i = 0; i < mapValueMaxLength; i++) {for (String resourceMark : resourceMarks) {if (resourceMarkAndTaskIdMap.get(resourceMark).size() > 0) {int taskId = resourceMarkAndTaskIdMap.get(resourceMark).get(0);taskGroupConfigList.get(taskGroupIndex % taskGroupNumber).add(contentConfig.get(taskId));taskGroupIndex++;resourceMarkAndTaskIdMap.get(resourceMark).remove(0);}}}Configuration tempTaskGroupConfig;for (int i = 0; i < taskGroupNumber; i++) {tempTaskGroupConfig = taskGroupTemplate.clone();tempTaskGroupConfig.set(CoreConstant.DATAX_JOB_CONTENT, taskGroupConfigList.get(i));tempTaskGroupConfig.set(CoreConstant.DATAX_CORE_CONTAINER_TASKGROUP_ID, i);result.add(tempTaskGroupConfig);}return result;}
调度核心代码实现
- 多线程池
- datax/core/src/main/java/com/alibaba/datax/core/job/scheduler/AbstractScheduler.java
public abstract class AbstractScheduler {private static final Logger LOG = LoggerFactory.getLogger(AbstractScheduler.class);private ErrorRecordChecker errorLimit;private AbstractContainerCommunicator containerCommunicator;private Long jobId;public Long getJobId() {return jobId;}public AbstractScheduler(AbstractContainerCommunicator containerCommunicator) {this.containerCommunicator = containerCommunicator;}public void schedule(List<Configuration> configurations) {...// 核心代码startAllTaskGroup(configurations);...}
}
- datax/core/src/main/java/com/alibaba/datax/core/job/scheduler/processinner/ProcessInnerScheduler.java
public abstract class ProcessInnerScheduler extends AbstractScheduler {private ExecutorService taskGroupContainerExecutorService;public ProcessInnerScheduler(AbstractContainerCommunicator containerCommunicator) {super(containerCommunicator);}@Overridepublic void startAllTaskGroup(List<Configuration> configurations) {// 使用了线程池this.taskGroupContainerExecutorService = Executors.newFixedThreadPool(configurations.size());for (Configuration taskGroupConfiguration : configurations) {TaskGroupContainerRunner taskGroupContainerRunner = newTaskGroupContainerRunner(taskGroupConfiguration);this.taskGroupContainerExecutorService.execute(taskGroupContainerRunner);}this.taskGroupContainerExecutorService.shutdown();}
}
3.2 数据传输
- 线程池执行了TaskGroupContainerRunner对象
- datax/core/src/main/java/com/alibaba/datax/core/taskgroup/runner/TaskGroupContainerRunner.java
public class TaskGroupContainerRunner implements Runnable {@Overridepublic void run() {try {...// 启动了这个组容器this.taskGroupContainer.start();...} catch (Throwable e) {...}}
}
- 查看一下实现了什么run方法
- datax/core/src/main/java/com/alibaba/datax/core/taskgroup/TaskGroupContainer.java
public class TaskGroupContainer extends AbstractContainer {
@Overridepublic void start() {try {...while (true) {...while(iterator.hasNext() && runTasks.size() < channelNumber){...TaskExecutor taskExecutor = new TaskExecutor(taskConfigForRun, attemptCount);taskStartTimeMap.put(taskId, System.currentTimeMillis());// 这里是真正的执行逻辑taskExecutor.doStart();...}...}...} catch (Throwable e) {...}finally {...}}public void doStart() {// 写的线程启动this.writerThread.start();// reader没有起来,writer不可能结束if (!this.writerThread.isAlive() || this.taskCommunication.getState() == State.FAILED) {throw DataXException.asDataXException(FrameworkErrorCode.RUNTIME_ERROR,this.taskCommunication.getThrowable());}// 读的线程启动this.readerThread.start();// 这里reader可能很快结束if (!this.readerThread.isAlive() && this.taskCommunication.getState() == State.FAILED) {// 这里有可能出现Reader线上启动即挂情况 对于这类情况 需要立刻抛出异常throw DataXException.asDataXException(FrameworkErrorCode.RUNTIME_ERROR,this.taskCommunication.getThrowable());}}
}
- writerThread来自WriterRunner,readerThread来自ReaderRunner
- ReaderRunner跟限速有关系
- datax/core/src/main/java/com/alibaba/datax/core/taskgroup/runner/ReaderRunner.java
public class ReaderRunner extends AbstractRunner implements Runnable {private static final Logger LOG = LoggerFactory.getLogger(ReaderRunner.class);private RecordSender recordSender;public void setRecordSender(RecordSender recordSender) {this.recordSender = recordSender;}public ReaderRunner(AbstractTaskPlugin abstractTaskPlugin) {super(abstractTaskPlugin);}@Overridepublic void run() {assert null != this.recordSender;Reader.Task taskReader = (Reader.Task) this.getPlugin();//统计waitWriterTime,并且在finally才end。PerfRecord channelWaitWrite = new PerfRecord(getTaskGroupId(), getTaskId(), PerfRecord.PHASE.WAIT_WRITE_TIME);try {channelWaitWrite.start();LOG.debug("task reader starts to do init ...");PerfRecord initPerfRecord = new PerfRecord(getTaskGroupId(), getTaskId(), PerfRecord.PHASE.READ_TASK_INIT);initPerfRecord.start();taskReader.init();initPerfRecord.end();LOG.debug("task reader starts to do prepare ...");PerfRecord preparePerfRecord = new PerfRecord(getTaskGroupId(), getTaskId(), PerfRecord.PHASE.READ_TASK_PREPARE);preparePerfRecord.start();taskReader.prepare();preparePerfRecord.end();LOG.debug("task reader starts to read ...");PerfRecord dataPerfRecord = new PerfRecord(getTaskGroupId(), getTaskId(), PerfRecord.PHASE.READ_TASK_DATA);// 最核心dataPerfRecord.start();taskReader.startRead(recordSender);recordSender.terminate();dataPerfRecord.addCount(CommunicationTool.getTotalReadRecords(super.getRunnerCommunication()));dataPerfRecord.addSize(CommunicationTool.getTotalReadBytes(super.getRunnerCommunication()));dataPerfRecord.end();LOG.debug("task reader starts to do post ...");PerfRecord postPerfRecord = new PerfRecord(getTaskGroupId(), getTaskId(), PerfRecord.PHASE.READ_TASK_POST);postPerfRecord.start();taskReader.post();postPerfRecord.end();// automatic flush// super.markSuccess(); 这里不能标记为成功,成功的标志由 writerRunner 来标志(否则可能导致 reader 先结束,而 writer 还没有结束的严重 bug)} catch (Throwable e) {LOG.error("Reader runner Received Exceptions:", e);super.markFail(e);} finally {LOG.debug("task reader starts to do destroy ...");PerfRecord desPerfRecord = new PerfRecord(getTaskGroupId(), getTaskId(), PerfRecord.PHASE.READ_TASK_DESTROY);desPerfRecord.start();super.destroy();desPerfRecord.end();channelWaitWrite.end(super.getRunnerCommunication().getLongCounter(CommunicationTool.WAIT_WRITER_TIME));long transformerUsedTime = super.getRunnerCommunication().getLongCounter(CommunicationTool.TRANSFORMER_USED_TIME);if (transformerUsedTime > 0) {PerfRecord transformerRecord = new PerfRecord(getTaskGroupId(), getTaskId(), PerfRecord.PHASE.TRANSFORMER_TIME);transformerRecord.start();transformerRecord.end(transformerUsedTime);}}}public void shutdown(){recordSender.shutdown();}
}
- 最核心的是 dataPerfRecord.start()
- 拿一个MySQL的reader案例看:MysqlReader.java
public class MysqlReader extends Reader {@Overridepublic void startRead(RecordSender recordSender) {int fetchSize = this.readerSliceConfig.getInt(Constant.FETCH_SIZE);// 核心方法this.commonRdbmsReaderTask.startRead(this.readerSliceConfig, recordSender,super.getTaskPluginCollector(), fetchSize);}
}
- 查看 CommonRdbmsReaderTask的startRead函数
public class CommonRdbmsReader {public static class Task {...public void startRead(Configuration readerSliceConfig,RecordSender recordSender,TaskPluginCollector taskPluginCollector, int fetchSize) {...try {...while (rs.next()) {rsNextUsedTime += (System.nanoTime() - lastTime);// 核心逻辑:对单个数据的处理逻辑this.transportOneRecord(recordSender, rs,metaData, columnNumber, mandatoryEncoding, taskPluginCollector);lastTime = System.nanoTime();}...}catch (Exception e) {throw RdbmsException.asQueryException(this.dataBaseType, e, querySql, table, username);} finally {DBUtil.closeDBResources(null, conn);}}}protected Record transportOneRecord(RecordSender recordSender, ResultSet rs, ResultSetMetaData metaData, int columnNumber, String mandatoryEncoding, TaskPluginCollector taskPluginCollector) {Record record = buildRecord(recordSender,rs,metaData,columnNumber,mandatoryEncoding,taskPluginCollector); // 每次处理完成,都会发送到writerrecordSender.sendToWriter(record);return record;}
}
- 如何将处理好的数据发送到writer的?
- datax/core/src/main/java/com/alibaba/datax/core/transport/exchanger/BufferedRecordExchanger.java
public class BufferedRecordExchanger implements RecordSender, RecordReceiver {@Overridepublic void sendToWriter(Record record) {....if (isFull) {// 核心代码flush();}...}@Overridepublic void flush() {if(shutdown){throw DataXException.asDataXException(CommonErrorCode.SHUT_DOWN_TASK, "");}// 核心代码,将数据通过channel推送给writerthis.channel.pushAll(this.buffer);this.buffer.clear();this.bufferIndex = 0;this.memoryBytes.set(0);}
}
- 查看channel的pushAll
- datax/core/src/main/java/com/alibaba/datax/core/transport/channel/Channel.java
public abstract class Channel {public void pushAll(final Collection<Record> rs) {Validate.notNull(rs);Validate.noNullElements(rs);this.doPushAll(rs);// rs.size():数据条数// this.getByteSize(rs):数据量this.statPush(rs.size(), this.getByteSize(rs));}private void statPush(long recordSize, long byteSize) {...if (interval - this.flowControlInterval >= 0) {...// 如果是通过速率数限速的if (isChannelRecordSpeedLimit) {long currentRecordSpeed = (CommunicationTool.getTotalReadRecords(currentCommunication) -CommunicationTool.getTotalReadRecords(lastCommunication)) * 1000 / interval;// 当前的速率大于限速的速率,会指定一个睡眠时间if (currentRecordSpeed > this.recordSpeed) {// 计算根据recordLimit得到的休眠时间recordLimitSleepTime = currentRecordSpeed * interval / this.recordSpeed- interval;}}// 休眠时间取较大值long sleepTime = byteLimitSleepTime < recordLimitSleepTime ?recordLimitSleepTime : byteLimitSleepTime;if (sleepTime > 0) {try {Thread.sleep(sleepTime);} catch (InterruptedException e) {Thread.currentThread().interrupt();}}...}}
}
三、DataX性能优化
1.关键参数
- job.setting.speed.channel : channel 并发数
- job.setting.speed.record : 全局配置 channel 的 record 限速
- 最终的单个channel的限速 = 全局配置channel的record限速 / channel并发数
- job.setting.speed.byte:全局配置 channel 的 byte 限速
- 最终的单个channel的限速 = 全局配置channel的byte限速 / channel并发数
- core.transport.channel.speed.record:单个 channel 的 record 限速
- core.transport.channel.speed.byte:单个 channel 的 byte 限速
2.优化:提升每个 channel 的速度
- 在 DataX 内部对每个 Channel 会有严格的速度控制,分两种,一种是控制每秒同步的记录数,另外一种是每秒同步的字节数,默认的速度限制是 1MB/s,可以根据具体硬件情况设置这个 byte 速度或者 record 速度,一般设置 byte 速度,比如:我们可以把单个 Channel 的速度上限配置为 5MB
3.优化:提升 DataX Job 内 Channel 并发数
- 并发数 = taskGroup 的数量 * 每个 TaskGroup 并发执行的 Task 数 (默认为 5)。
3.1 配置全局 Byte 限速以及单 Channel Byte 限速
- Channel 个数 = 全局 Byte 限速 / 单 Channel Byte 限速
{"core": {"transport": {"channel": {"speed": {"byte": 1048576}}}},"job": {"setting": {"speed": {"byte": 5242880}},...}
}
- core.transport.channel.speed.byte=1048576,job.setting.speed.byte=5242880,所以 Channel个数 = 全局 Byte 限速 / 单 Channel Byte 限速=5242880/1048576=5 个
3.2 配置全局 Record 限速以及单 Channel Record 限速
- Channel 个数 = 全局 Record 限速 / 单 Channel Record 限速
{"core": {"transport": {"channel": {"speed": {"record": 100}}}},"job": {"setting": {"speed": {"record": 500}},...}
}
- core.transport.channel.speed.record=100 , job.setting.speed.record=500, 所 以 配 置 全 局Record 限速以及单 Channel Record 限速,Channel 个数 = 全局 Record 限速 / 单 Channel Record 限速=500/100=5
3.3 直接配置 Channel 个数
只有在上面两种未设置才生效,上面两个同时设置是取值小的作为最终的 channel 数。
{"job": {"setting": {"speed": {"channel": 5}},...}
}
- 直接配置 job.setting.speed.channel=5,所以 job 内 Channel 并发=5 个
3.提高 JVM 堆内存
- 当提升 DataX Job 内 Channel 并发数时,内存的占用会显著增加,因为 DataX 作为数据交换通道,在内存中会缓存较多的数据。例如 Channel 中会有一个 Buffer,作为临时的数据交换的缓冲区,而在部分 Reader 和 Writer 的中,也会存在一些 Buffer,为了防止 OOM 等错误,调大 JVM 的堆内存。
- 建议将内存设置为
4G 或者 8G,这个也可以根据实际情况来调整。 - 调整 JVM xms xmx 参数的两种方式:一种是直接更改 datax.py 脚本;另一种是在启动的时候,加上对应的参数,如下:
python datax/bin/datax.py --jvm="-Xms8G -Xmx8G" XXX.json