✅作者简介:人工智能专业本科在读,喜欢计算机与编程,写博客记录自己的学习历程。
🍎个人主页:小嗷犬的个人主页
🍊个人网站:小嗷犬的技术小站
🥭个人信条:为天地立心,为生民立命,为往圣继绝学,为万世开太平。
本文目录
- VAE 简介
- 基本原理
- 应用与优点
- 缺点与挑战
- 使用 VAE 生成 MNIST 手写数字
- 忽略警告
- 导入必要的库
- 设置随机种子
- cuDNN 设置
- 超参数设置
- 数据加载
- 定义 VAE 模型
- 定义损失函数
- 定义 Lightning 模型
- 训练模型
- 绘制训练过程
- 随机生成新样本
- 根据潜变量插值生成新样本
VAE 简介
变分自编码器(Variational Autoencoder,VAE)是一种深度学习中的生成模型,它结合了自编码器(Autoencoder, AE)和概率建模的思想,在无监督学习环境中表现出了强大的能力。VAE 在 2013 年由 Diederik P. Kingma 和 Max Welling 首次提出,并迅速成为生成模型领域的重要组成部分。
基本原理
自编码器(AE)基础:
自编码器是一种神经网络结构,通常由两部分组成:编码器(Encoder)和解码器(Decoder)。原始数据通过编码器映射到一个低维的潜在空间(或称为隐空间),这个低维向量被称为潜变量(latent variable)。然后,潜变量再通过解码器重构回原始数据的近似版本。在训练过程中,自编码器的目标是使得输入数据经过编码-解码过程后能够尽可能地恢复原貌,从而学习到数据的有效表示。
VAE的引入与扩展:
VAE 将自编码器的概念推广到了概率框架下。在 VAE 中,潜变量不再是确定性的,而是被赋予了概率分布。具体来说,对于给定的输入数据,编码器不直接输出一个点估计值,而是输出潜变量的均值和方差(假设潜变量服从高斯分布)。这样,每个输入数据可以被视为是从某个潜在的概率分布中采样得到的。
变分推断(Variational Inference):
训练 VA E时,由于真实的后验概率分布难以直接计算,因此采用变分推断来近似后验分布。编码器实际上输出的是一个参数化的概率分布 q ( z ∣ x ) q(z|x) q(z∣x),即给定输入 x x x 时潜变量 z z z 的概率分布。然后通过最小化 KL 散度(Kullback-Leibler divergence)来优化这个近似分布,使其尽可能接近真实的后验分布 p ( z ∣ x ) p(z|x) p(z∣x)。
目标函数 - Evidence Lower Bound (ELBO):
VAE 的目标函数是证据下界(ELBO),它是原始数据 log-likelihood 的下界。优化该目标函数既鼓励编码器找到数据的高效潜在表示,又促使解码器基于这些表示重建出类似原始数据的新样本。
数学表达上,ELBO 通常分解为两个部分:
- 重构损失(Reconstruction Loss):衡量从潜变量重构出来的数据与原始数据之间的差异。
- KL散度损失(KL Divergence Loss):衡量编码器产生的潜变量分布与预设的标准正态分布(或其他先验分布)之间的距离。
应用与优点
- VAE 可以用于生成新数据,例如图像、文本、音频等。
- 由于其对潜变量进行概率建模,所以它可以提供连续的数据生成,并且能够探索数据的不同模式。
- 在处理连续和离散数据时具有一定的灵活性。
- 可以用于特征学习,提取数据的有效低维表示。
缺点与挑战
- 训练 VAE 可能需要大量的计算资源和时间。
- 生成的样本有时可能不够清晰或细节模糊,尤其是在复杂数据集上。
- 对于某些复杂的分布形式,VAE 可能无法完美捕获所有细节。
使用 VAE 生成 MNIST 手写数字
下面我们将使用 PyTorch Lightning 来实现一个简单的 VAE 模型,并使用 MNIST 数据集来进行训练和生成。
在线 Notebook:https://www.kaggle.com/code/marquis03/vae-mnist
忽略警告
import warnings
warnings.filterwarnings("ignore")
导入必要的库
import random
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as snssns.set_theme(style="darkgrid", font_scale=1.5, font="SimHei", rc={"axes.unicode_minus":False})import torch
import torchmetrics
from torch import nn, optim
from torch.nn import functional as F
from torch.utils.data import DataLoader
from torchvision import transforms, datasetsimport lightning.pytorch as pl
from lightning.pytorch.loggers import CSVLogger
from lightning.pytorch.callbacks.early_stopping import EarlyStopping
设置随机种子
seed = 1
random.seed(seed)
np.random.seed(seed)
torch.manual_seed(seed)
torch.cuda.manual_seed_all(seed)
cuDNN 设置
torch.backends.cudnn.enabled = True
torch.backends.cudnn.benchmark = True
torch.backends.cudnn.deterministic = True
超参数设置
batch_size = 64epochs = 10
KLD_weight = 1
lr = 0.001input_dim = 784 # 28 * 28
h_dim = 256 # 隐藏层维度
z_dim = 2 # 潜变量维度
数据加载
train_dataset = datasets.MNIST(root="data", train=True, transform=transforms.ToTensor(), download=True)
train_loader = DataLoader(dataset=train_dataset, batch_size=batch_size, shuffle=True)
定义 VAE 模型
class VAE(nn.Module):def __init__(self, input_dim=784, h_dim=400, z_dim=20):super(VAE, self).__init__()self.input_dim = input_dimself.h_dim = h_dimself.z_dim = z_dim# Encoderself.fc1 = nn.Linear(input_dim, h_dim)self.fc21 = nn.Linear(h_dim, z_dim) # muself.fc22 = nn.Linear(h_dim, z_dim) # log_var# Decoderself.fc3 = nn.Linear(z_dim, h_dim)self.fc4 = nn.Linear(h_dim, input_dim)def encode(self, x):h = torch.relu(self.fc1(x))mean = self.fc21(h)log_var = self.fc22(h)return mean, log_vardef reparameterize(self, mu, logvar):std = torch.exp(0.5 * logvar)eps = torch.randn_like(std)return mu + eps * stddef decode(self, z):h = torch.relu(self.fc3(z))out = torch.sigmoid(self.fc4(h))return outdef forward(self, x):mean, log_var = self.encode(x)z = self.reparameterize(mean, log_var)reconstructed_x = self.decode(z)return reconstructed_x, mean, log_varvae = VAE(input_dim, h_dim, z_dim)
x = torch.randn((10, input_dim))
reconstructed_x, mean, log_var = vae(x)
print(reconstructed_x.shape, mean.shape, log_var.shape)
# torch.Size([10, 784]) torch.Size([10, 2]) torch.Size([10, 2])
定义损失函数
def loss_function(x_hat, x, mu, log_var, KLD_weight=1):BCE_loss = F.binary_cross_entropy(x_hat, x, reduction="sum") # 重构损失KLD_loss = -0.5 * torch.sum(1 + log_var - mu.pow(2) - log_var.exp()) # KL 散度损失loss = BCE_loss + KLD_loss * KLD_weightreturn loss, BCE_loss, KLD_loss
定义 Lightning 模型
class LitModel(pl.LightningModule):def __init__(self, input_dim=784, h_dim=400, z_dim=20):super().__init__()self.model = VAE(input_dim, h_dim, z_dim)def forward(self, x):x = self.model(x)return xdef configure_optimizers(self):optimizer = optim.Adam(self.parameters(), lr=lr, betas=(0.9, 0.99), eps=1e-08, weight_decay=1e-5)return optimizerdef training_step(self, batch, batch_idx):x, y = batchx = x.view(x.size(0), -1)reconstructed_x, mean, log_var = self(x)loss, BCE_loss, KLD_loss = loss_function(reconstructed_x, x, mean, log_var, KLD_weight=KLD_weight)self.log("loss", loss, on_step=False, on_epoch=True, prog_bar=True, logger=True)self.log_dict({"BCE_loss": BCE_loss,"KLD_loss": KLD_loss,},on_step=False,on_epoch=True,logger=True,)return lossdef decode(self, z):out = self.model.decode(z)return out
训练模型
model = LitModel(input_dim, h_dim, z_dim)
logger = CSVLogger("./")
early_stop_callback = EarlyStopping(monitor="loss", min_delta=0.00, patience=5, verbose=False, mode="min")
trainer = pl.Trainer(max_epochs=epochs,enable_progress_bar=True,logger=logger,callbacks=[early_stop_callback],
)
trainer.fit(model, train_loader)
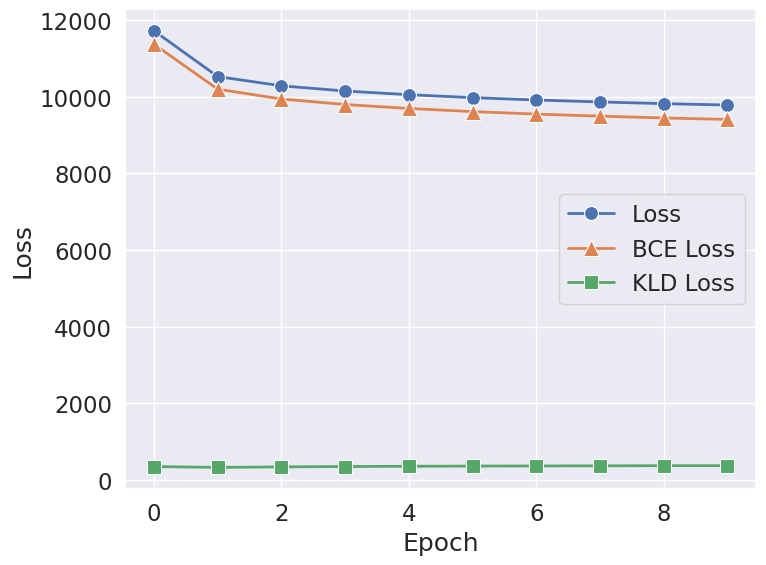
绘制训练过程
log_path = logger.log_dir + "/metrics.csv"
metrics = pd.read_csv(log_path)
x_name = "epoch"plt.figure(figsize=(8, 6), dpi=100)
sns.lineplot(x=x_name, y="loss", data=metrics, label="Loss", linewidth=2, marker="o", markersize=10)
sns.lineplot(x=x_name, y="BCE_loss", data=metrics, label="BCE Loss", linewidth=2, marker="^", markersize=12)
sns.lineplot(x=x_name, y="KLD_loss", data=metrics, label="KLD Loss", linewidth=2, marker="s", markersize=10)
plt.xlabel("Epoch")
plt.ylabel("Loss")
plt.tight_layout()
plt.show()
随机生成新样本
row, col = 4, 18
z = torch.randn(row * col, z_dim)
random_res = model.model.decode(z).view(-1, 1, 28, 28).detach().numpy()plt.figure(figsize=(col, row))
for i in range(row * col):plt.subplot(row, col, i + 1)plt.imshow(random_res[i].squeeze(), cmap="gray")plt.xticks([])plt.yticks([])plt.axis("off")
plt.show()

根据潜变量插值生成新样本
from scipy.stats import normn = 15
digit_size = 28grid_x = norm.ppf(np.linspace(0.05, 0.95, n))
grid_y = norm.ppf(np.linspace(0.05, 0.95, n))figure = np.zeros((digit_size * n, digit_size * n))
for i, yi in enumerate(grid_y):for j, xi in enumerate(grid_x):t = [xi, yi]z_sampled = torch.FloatTensor(t)with torch.no_grad():decode = model.decode(z_sampled)digit = decode.view((digit_size, digit_size))figure[i * digit_size : (i + 1) * digit_size,j * digit_size : (j + 1) * digit_size,] = digitplt.figure(figsize=(10, 10))
plt.imshow(figure, cmap="gray")
plt.xticks([])
plt.yticks([])
plt.axis("off")
plt.show()




![[职场] 实验室科研人员简历范文 #学习方法#职场发展](https://img-blog.csdnimg.cn/img_convert/01d20894e66b61acad4e890dcd2e88c4.jpeg)