前言
在2022年,人工智能创作内容(AIGC)成为了AI领域的热门话题之一。在ChatGPT问世之前,AI绘画以其独特的创意和便捷的创作工具迅速走红,引起了广泛关注。随着一系列以Stable Diffusion、Midjourney、NovelAI等为代表的文本生成图像的跨模态应用相继涌现与Stable Diffusion的开源,Stable Diffusion以其出色的人物和场景生成效果备受瞩目。它包括文本生成图像、图像生成图像、特定角色的刻画,甚至超分辨率和修复缺损图像等任务。
介绍
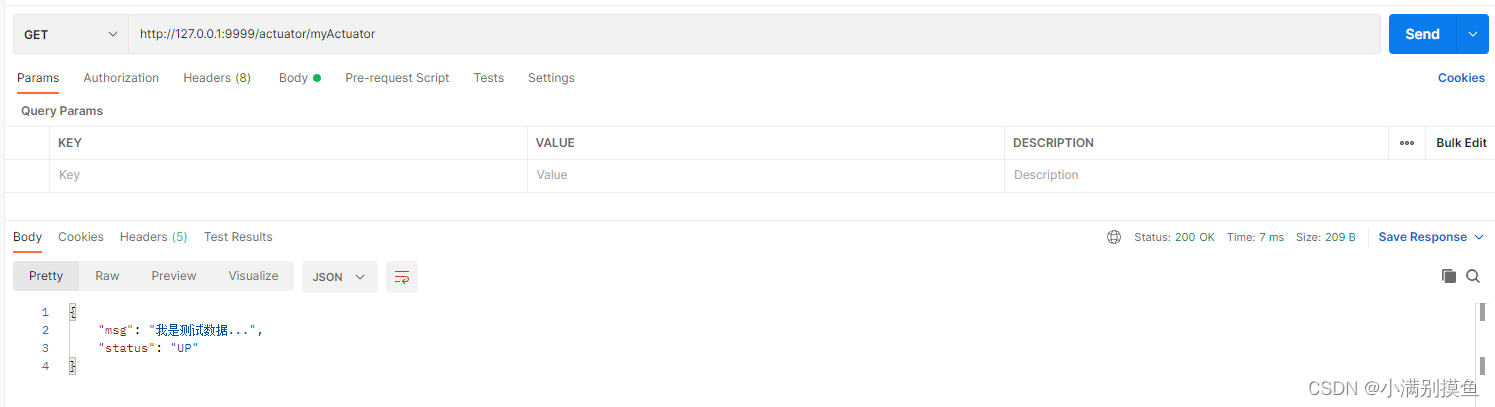
Stable Diffusion的应用范围广泛,这不仅因为它生成的图像逼真,还因为它能够以多种不同的方式使用。让我们首先关注文本生成图像的方式(text2img)。
在上述示例中,我们输入了文本描述(prompt),模型就能够生成出一幅精美的图像。例如,输入“天堂、广袤的、沙滩”,就得到了一幅美丽的画面。

除了文本到图像的转换,另一种主要的使用方式是通过文本来修改现有图像。在这种情况下,输入是文本和图像的组合。例如,将文本描述为“海盗船”,模型生成的图像就会包含海盗船。

Stable Diffusion组成模块
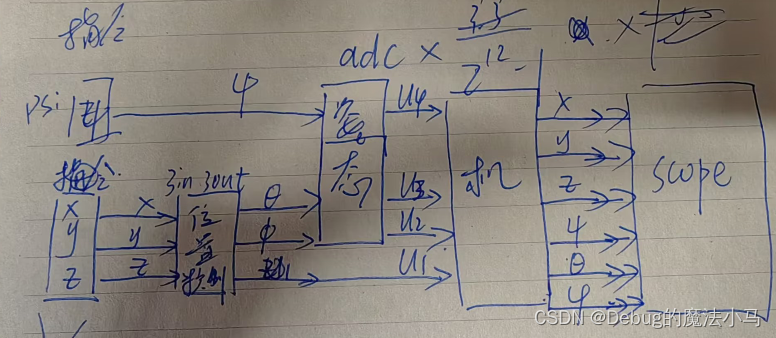
Stable Diffusion实际上是一个相当复杂的系统,其中包含各种不同的模型模块。首先需要解决的问题是如何将人类理解的文字转换为计算机可理解的数学语言,毕竟计算机无法理解自然语言。这就需要一个文本理解器(text understander)来帮助进行转换。在生成图像之前,下图中蓝色的文本理解器首先将文本转换成某种计算机能够理解的数学表示:

1.图片信息生成器
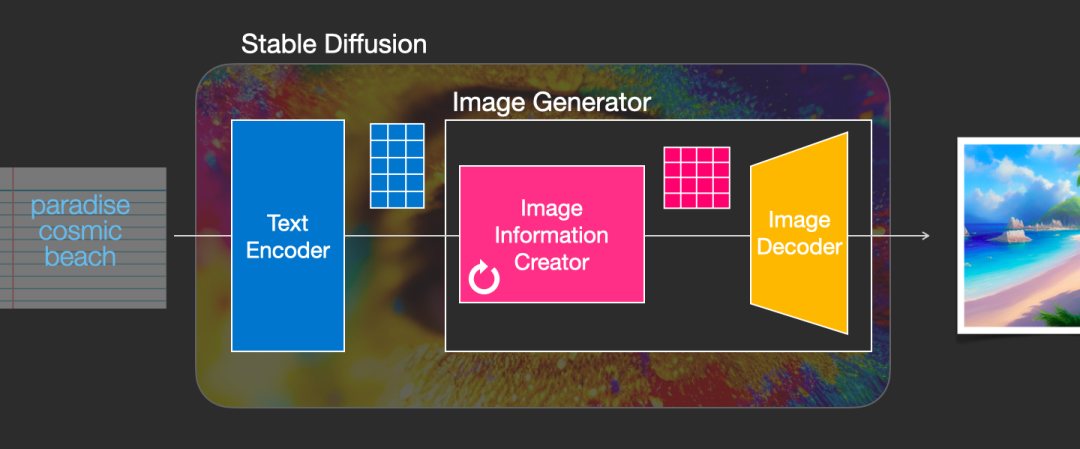
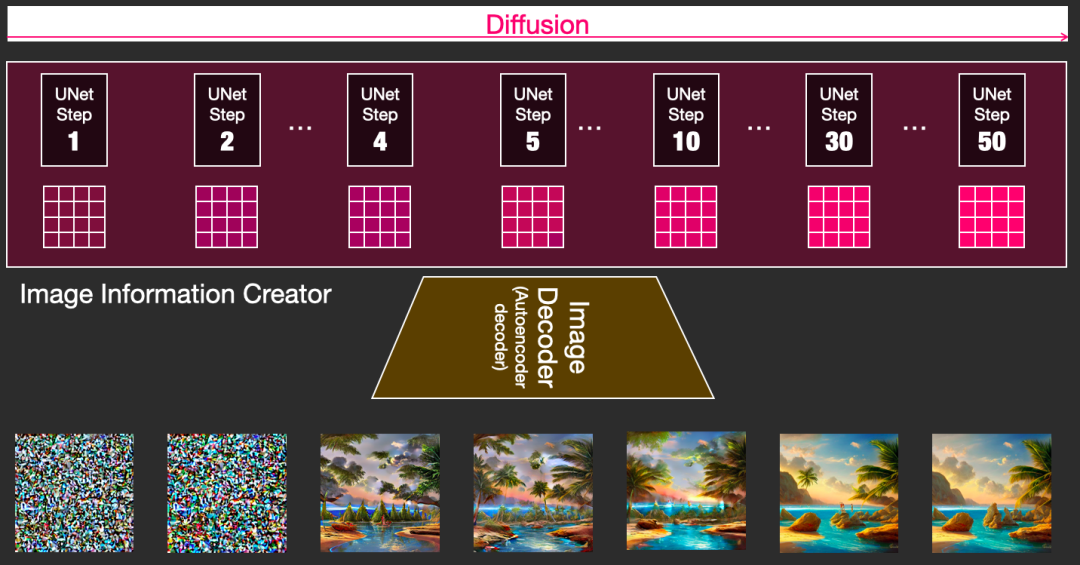
上图粉色的模块是Stable Diffusion与别的Diffusion模型最大的区别之一,也是SD性能提升的着急之一。首先,需要明确一点:图片信息生成器不直接生成图片,而是生成较低维度的图片信息,即所谓的隐空间信息(latent space information)。在下图中,这个隐空间信息被表示为粉色的 4x3 的方格,随后将这个隐空间信息输入到下图中黄色的解码器中,就可以成功生成图片了。Stable Diffusion主要引用的论文“latent diffusion”中的latent一词也来自于隐变量中的“latent”。
一般的Diffusion模型直接生成图片,而不会有先生成隐变量的过程,因此普通的Diffusion在这一步上需要生成更多的信息,负荷也更大。因此之前的Diffusion模型在速度和资源利用上都不如Stable Diffusion。技术上来说,这个图片隐变量是如何生成的呢?实际上,这是由一个Unet和一个Schedule算法共同完成的。Schedule算法控制生成的进度,而Unet则负责一步一步地执行生成的过程。在Stable Diffusion中,整个Unet的生成迭代过程大约需要重复 50~100 次,隐变量的质量也在这个迭代的过程中不断地改善。下图中粉色的Image Information Creator左下角的循环标志也象征着这个迭代的过程。
2、图片解码器

图片解码器,从图片信息生成器(Image Information Creator)中接收图片信息的隐变量,然后将其升维放大(upscale),还原成一张完整的图片。图片解码器只在最后的阶段起作用,也是我们能获得一张真实图片的最终过程。
现在让更具体地了解一下这个系统中输入输出的向量形状,这样对Stable Diffusion的工作原理应该能有更直观的认识:
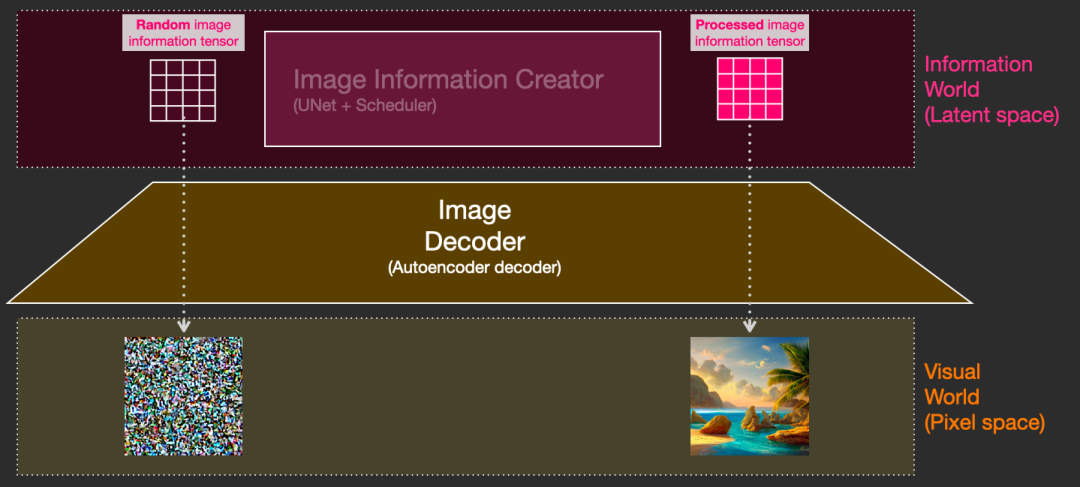
- 文本编码器(蓝色模块)功能:将人类语言转换成机器能理解的数学向量。输入:人类语言;输出:语义向量(77,768)。
- 图片信息生成器(粉色模块)功能:结合语义向量,逐步去除噪声,生成图片信息的隐变量。输入:噪声隐变量(4,64,64)+语义向量(77,768);输出:去噪的隐变量(4,64,64)。
- 图片解码器功能:将图片信息的隐变量转换为一张真正的图片。输入:去噪的隐变量(4,64,64);输出:一张真正的图片(3,512,512)。
大概流程中的向量形状变化就是这样。至于语义向量的形状为什么是奇怪的(77,768),会在后面讲到文本编码器里的CLIP模型时解释。
Stable Diffusion定义
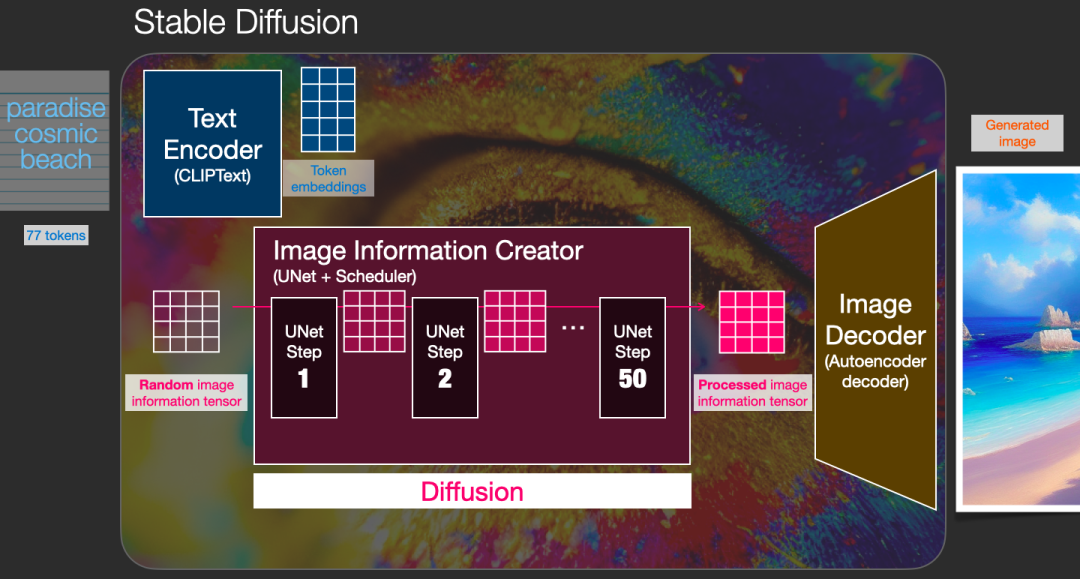
Diffusion模型的名称翻译成中文就是扩散模型,扩散的过程发生在Image Information Creator模块中,首先,使用随机函数生成一个与隐变量大小相同的纯噪声(下图中左下角透明的4x4区域)。一旦有了初始的纯噪声(下图中左下角透明的4x4区域)和语义向量(下图中左上角蓝色的3x5区域),Unet就会结合语义向量,不断地去除纯噪声隐变量中的噪声。大约重复50~100次左右就完全去除了噪声,并且不断向隐变量中注入语义信息,这样我们就得到了一个带有语义的隐变量(下图中粉色的4x4区域)。同时,我们还有一个scheduler,用来控制Unet去噪的强度,统筹整个去噪的过程。Scheduler可以在去噪的不同阶段动态调整去噪强度,也可以在某些特殊任务中匀速去除噪声,这都取决于我们最初的设计。

这个过程是通过一系列迭代步骤来去除噪声的,每一步都向隐变量中注入语义信息,直到噪声被完全去除。为了更直观地理解,可以将初始的纯噪声(左上方的透明44图像)和最终的去噪隐变量(右上方的粉色44图像)都通过最终的图像解码器进行解码,观察生成的图片。如预期所示,初始的纯噪声本身并不包含有效信息,因此解码后的图片仍然是噪声。而经过去噪处理后的隐变量已经包含了语义信息,所以解码后的图片会呈现出包含有效语义信息的图像。
迭代过程是多次重复的过程。每一次迭代的输入是一个隐变量,经过处理后输出也是一个隐变量,但噪声减少了,同时蕴含更多的语义信息。在下图中,4*4的隐变量从透明变成粉色的过程,代表了迭代的过程。颜色越粉,代表迭代次数越多,噪声也就越少。
在这个阶段,使用图像解码器可以提前观察到每一步所对应的图片,这样就可以逐步观察到我们期望的图像是如何从噪声中逐步生成的。
测试
秋叶整合包是简化了Stable Diffusion的安装和使用过程,使得没有编程背景的用户也能轻松地进行AI绘画创作。并提供详细的教程、资源和技术支持。首先确保计算机装备了Nvidia的独立显卡(N卡),尤其是RTX40系列或更高级别的显卡,显存应达到6GB以上,可以提高AI绘画的效率。如果没有N卡,可以使用CPU进行图形计算,但速度较慢,性价比也较低。此外,需要CPU性能足够高,并且至少有16GB的内存。总的来说,进行AI绘画时,推荐使用N卡,特别是RTX30系列或更高级别的显卡,以提高效率和性能。
秋叶整合包的源文件只分享在夸克网盘上,我这里把它转存到百度网盘:https://pan.baidu.com/s/1C8QBbshpgpIxBOTwsMYjaQ 提取码: pth5 ,这里的版本是4.6。
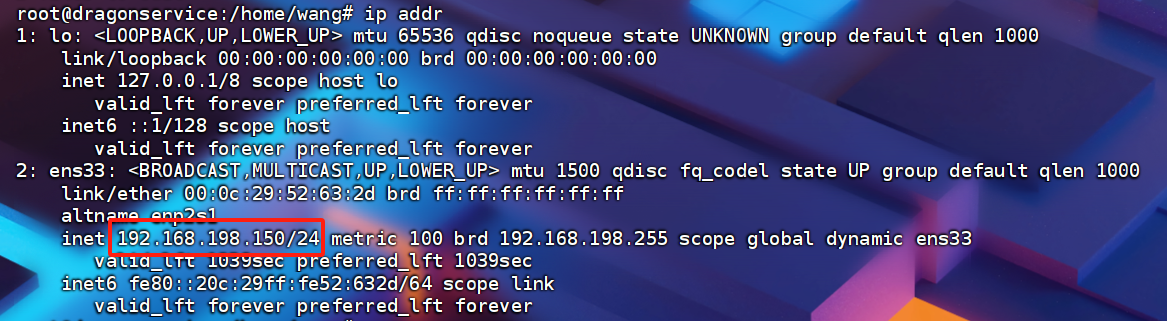
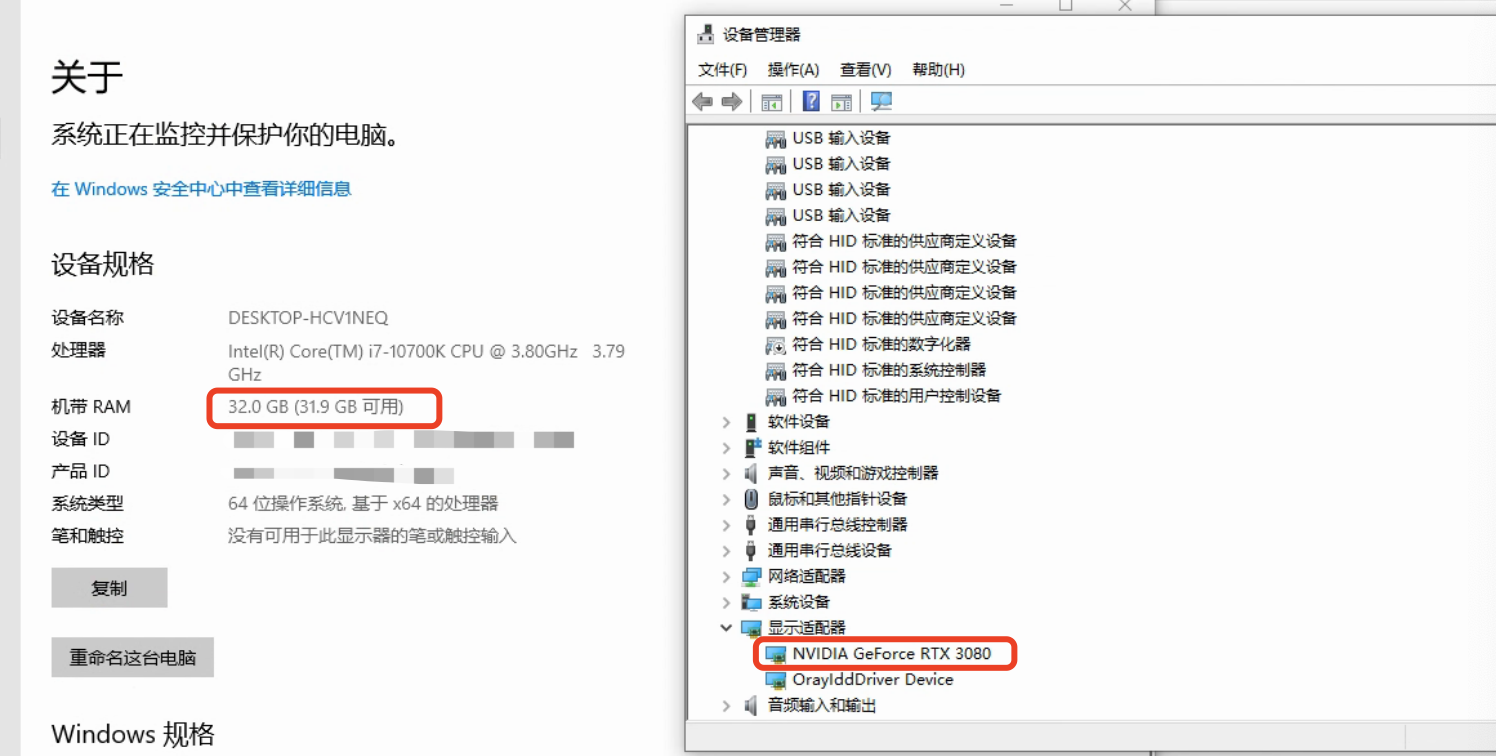
1.查看自己的GPU
查看GPU与内存大小,6G显存是出图的最低配置:
2.启动项目
下载之后,安装启动所需依赖,安装过.NET6的可以跳过这一步,不懂的再安装一遍也没问题:

解压“sd-webui-aki-v4.zip”。选择一个最少有20G以上的磁盘,因为解压出来的文件加上模型会很大,然后进入解压后的文件夹 sd-webui-aki-v4 。双击“A启动器.exe”,它会自动下载一些最新的程序文件。可能还会弹出了“设置Windows支持长路径”,确定就可以了。启动成功后,会打开下边这个界面。如果啥都做完了,也没打开这个界面,就再次双击这个文件或者以管理员身份运行。
之后点击 “一键启动",然后会弹出一个控制台窗口,做一些初始化的操作,出现“Startup time …”的提示就代表启动成功了。
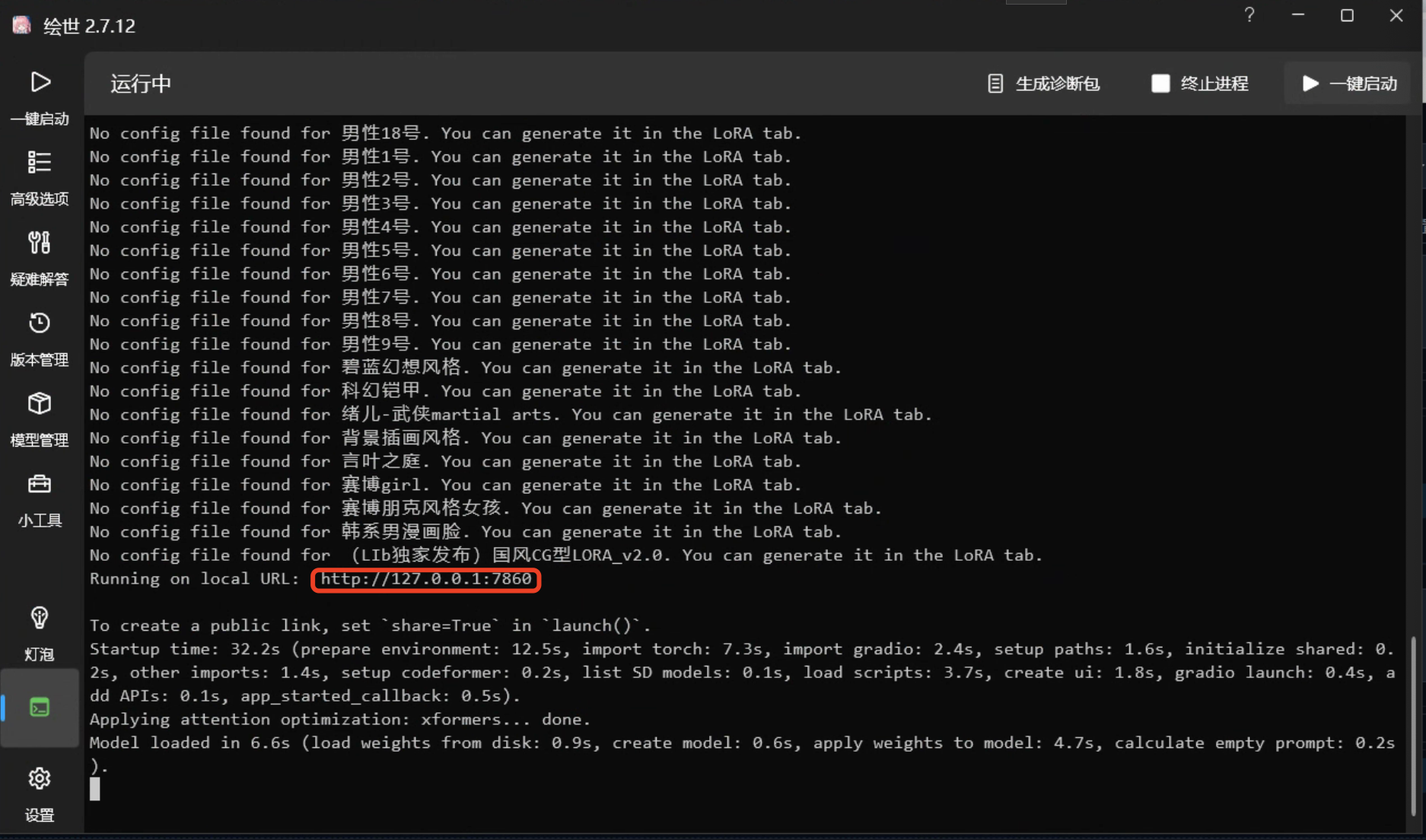
然后会自动在浏览器中打开SD WebUI的窗口。不小心关了的时候,也可以用 http://127.0.0.1:7860 再次打开。打开的界面如下图所示:
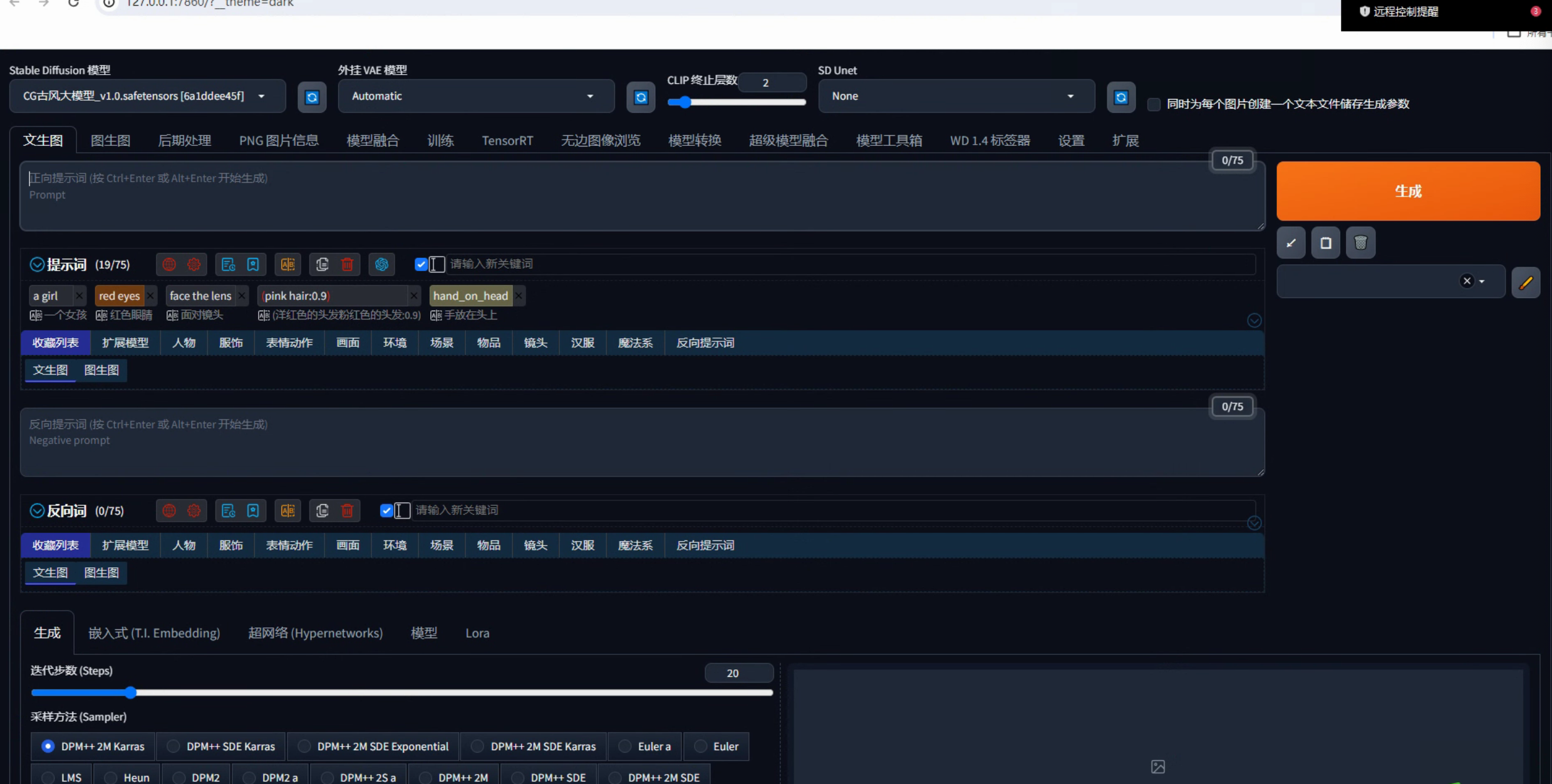
测试出图
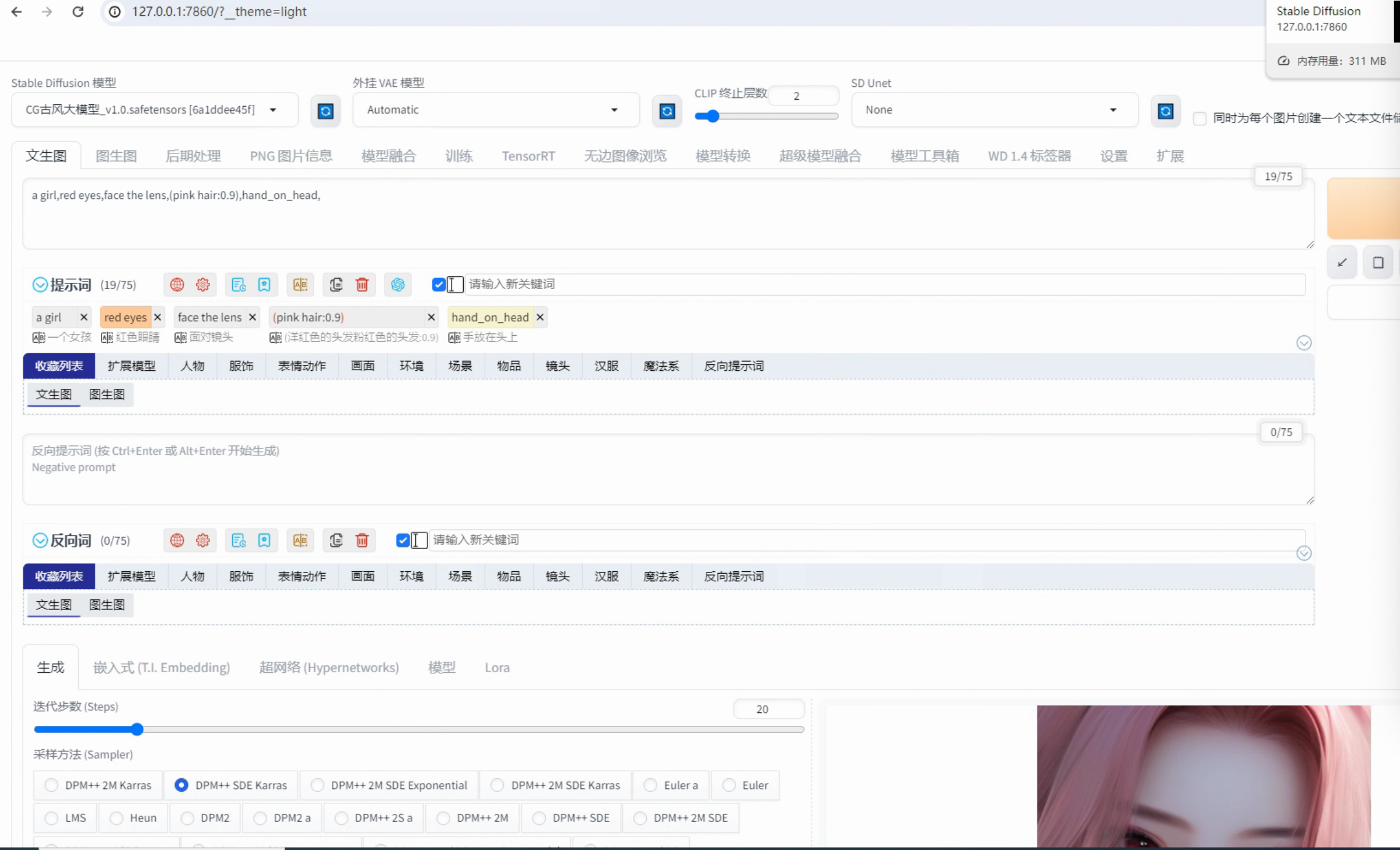
要生成图像,只需以下五个简单步骤:
-
选择模型,可以使用默认的大型模型"anything-v5"。
-
添加VAE模型。
-
提供提示词:用英文描述你想要的图像内容。
-
设置反向提示词:用英文描述你不想要在图像中出现的内容。
-
点击生成按钮。
图像生成的速度取决于你的计算机性能,稍等片刻即可。完成后,你可以点击图像放大查看,并右键下载。
常用概念
-
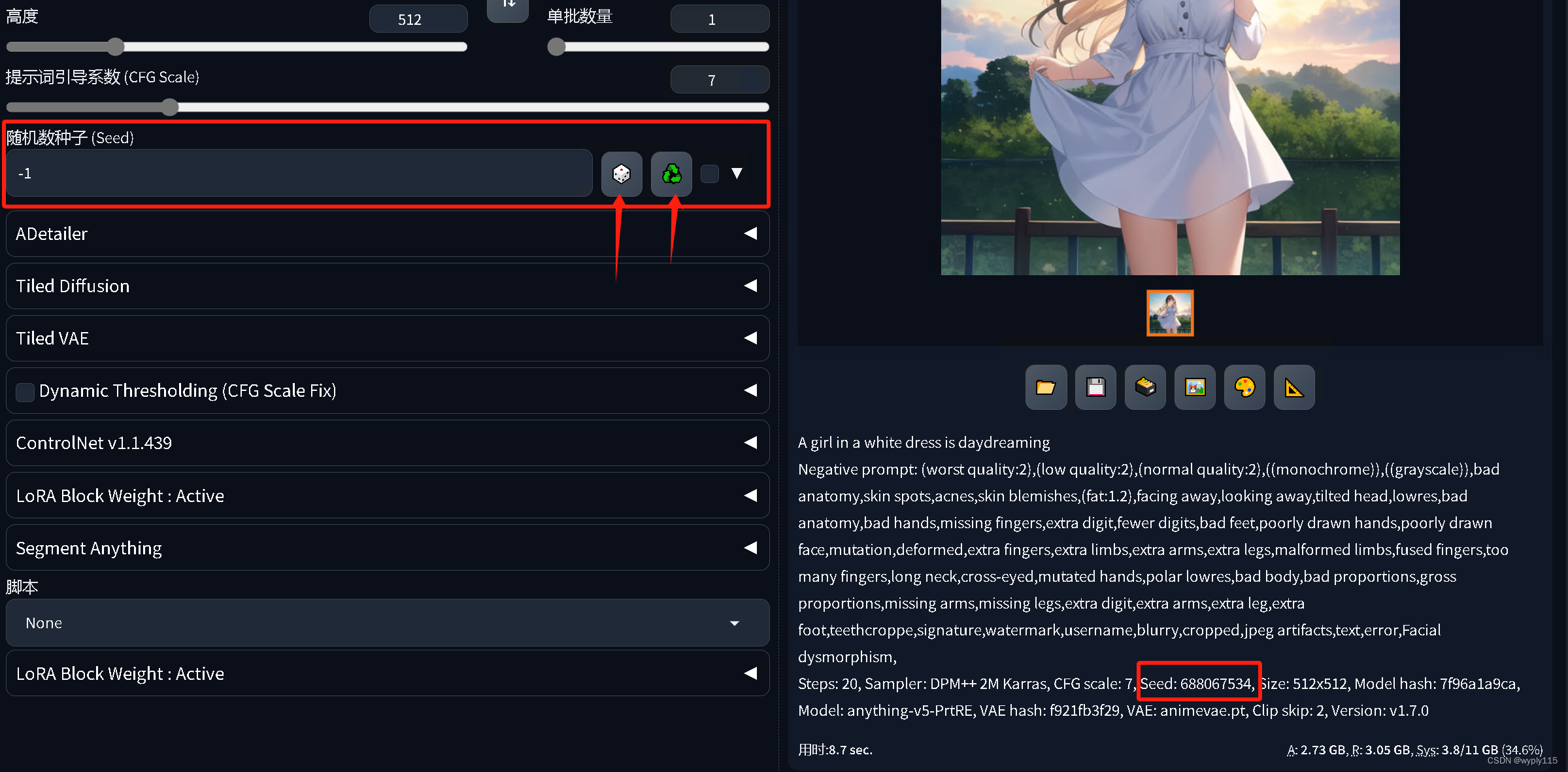
模型(Model):模型可以理解为一个函数,接受一系列参数作为输入,并生成相应的输出。在这里,模型接收一些参数(如提示词、反向提示词、图片尺寸、提示词引导系数、随机数种子等),并返回生成的图像数据。
-
大模型(Big Model):大模型通常称为基础模型,其文件大小通常在2GB至5GB之间。这些模型经过大量数据的训练,具有数十亿、甚至上百亿个参数。SD官方发布了一个通用的大模型,但由于其通用性,不能满足所有需求。因此,许多组织或个人会训练特定领域的模型,并将其发布到社区供大家使用。
-
VAE模型(Variational Autoencoder Model):VAE模型类似于图片编辑软件中的滤镜,可以增强图像的色彩和线条,使图像看起来更加丰富。一些大模型可能已经集成了VAE模型,但用户也可以选择添加一个额外的VAE模型。常用的VAE模型之一是编号为840000的模型,用于增强图像的色彩。
-
Lora模型:Lora模型是基于大模型的风格模型,用于控制图像的风格和特征。例如,在绘制人物时,可以使用Lora模型控制服装和头饰的样式;在绘制机械四肢时,可以使用Lora模型强调机甲样式;在绘制风景时,可以使用Lora模型控制绘画风格。
-
提示词(Prompt):提示词用于描述期望生成的图像内容。例如,描述场景、人物或物体的特征。良好的提示词对于生成所需的图像至关重要。
-
反向提示词(Negative Prompt):反向提示词用于描述不希望在生成图像中出现的内容。例如,排除特定物体或场景。使用通用的反向提示词可以简化此过程。
-
随机数种子(Random Seed):随机数种子影响生成图像的随机性。即使其他参数相同,不同的随机数种子也会产生不同的图像。这使得每次生成的图像都具有一定的差异,增加了创作的多样性。