创作不易,本篇文章如果帮助到了你,还请点赞 关注支持一下♡>𖥦<)!!
主页专栏有更多知识,如有疑问欢迎大家指正讨论,共同进步!
🔥c++系列专栏:C/C++零基础到精通 🔥给大家跳段街舞感谢支持!ጿ ኈ ቼ ዽ ጿ ኈ ቼ ዽ ጿ ኈ ቼ ዽ ጿ ኈ ቼ ዽ ጿ ኈ ቼ

目录
- 索引概述
- 索引的使用
- 为什么不使用 AVL、 红黑树作为索引?
- 为什么不使用哈希作为索引?
- B 树
- B+树
- 聚簇索引、非聚簇索引
- 最左匹配原则
- MySQL 索引的优缺点
- 索引的优化
- 索引失效
- 慢 SQL 优化
索引概述
什么是索引?可以用于优化查询
是一种已经排好序的数据结构(映射结构),根据 key 找到 value
如果不使用索引,mysql 查询就会从第一个开始逐个去查询(全表查询)
每次查询都会产生磁盘的 I/O 交互
为什么要使用索引?
就是为了缩短查询的时间。就像书本的目录一样。
数据量和数据结构有很大的关系。
mysql索引使用什么?
有使用B+树的索引,有使用hash表的 引擎决定了索引的类型
MySQL 常见引擎与索引类型:
- MyISAM、InnoDB:B+ 树
- Memory/heap:Hash 表
存储引擎形容数据库表!
索引的使用
创建索引
create index 索引名 on 表名(列名);
删除索引
drop index 索引名 on 表名;
使用 explian关键字查看是否使用索引进行检索:type = RES时代表使用索引检索,还可关注 key、row、extra等字段,查看影响查询性能的主要指标。
为什么不使用 AVL、 红黑树作为索引?
红黑树的本质仍是二叉树,当数据量比较大时,红黑树的层数比较高,每次读取节点都是在做磁盘 IO
并且每个节点只能存储一个数据,但是在索引的数据结构中,一个节点需要存两个值,一个是key 用来存节点的值,一个是value 存索引所在行的磁盘地址,查到后就能获取到其value内的值即地址。
为什么不使用哈希作为索引?
哈希表不支持排序操作,哈希表不能进行范围查询,如果发生哈希冲突效率变低
B 树
B 树相比于二叉树,每个节点横向上能够存储更多的索引元素,在树的高度相同的情况下,B 树能够存储更多的数据。
B 树的每个节点都存储索引 key 和数据地址 value,导致层数变高。
B+树
- B+树 将所有的索引都存放在叶子节点上
- B+树的节点上索引顺序从左到右依次递增
- B+树只有叶子节点存储索引 key 和数据地址 value,非叶子节点存储冗余索引(冗余索引的值为主键) 注意所有在冗余索引中出现的主键值都会在叶子节点中再现。设置冗余索引目的:为了使树高尽可能小,所以一层要尽可能多的放索引,按照B树这种结构,一个节点16KB,data元素会占用空间。如果不存储data只存储索引就可以存储更多索引,树可以分更多叉
对比红黑树: B+树的一个节点可以存放多个元素,比红黑树更低,磁盘 IO 次数更少。
对比 B 树: B 树不利于范围查询,B+树可以通过双向指针进行范围查找,只需要遍历叶子节点即可完成数据遍历
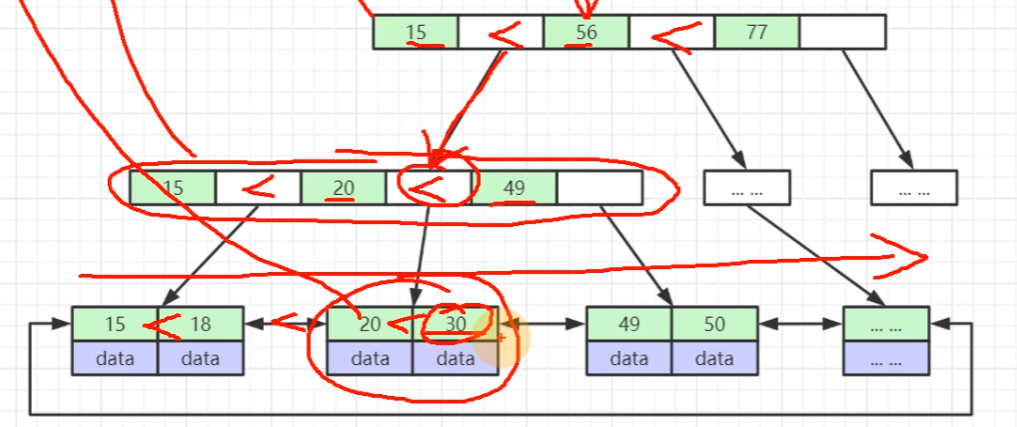
B+树查找索引的过程:
① 把根节点所有的索引从磁盘加载到内存中(如图的15、56、77),磁盘加载到内存就是一次磁盘 IO
② 在内存中比对(比对过程可用二分查找),发现在15-56之间,注意他俩之间白色框存储的是其指向节点在磁盘中的文件地址
③ 把指向节点所有索引再次加载到内存
④ 重复直到 当定位到目标索引元素30后,直接用其data中的物理地址去访问索引所在行的磁盘地址
高版本 Mysql 在启动时就将所有的非叶子节点即冗余节点加载到内存中
聚簇索引、非聚簇索引
聚簇索引是节点聚合数据,即在存储节点的位置直接存储数据
非聚簇索引是节点只存储地址,需要通过地址间接寻址来获取实际存储的数据
一张表只允许存在一种类型的索引(聚簇索引或非聚簇索引)
- 在 Innodb 引擎下主键索引是聚簇索引,表结构文件 FRM,索引与数据文件 IBD
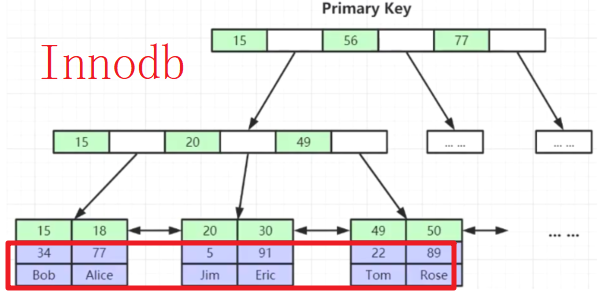
- 在 MyISAM 引擎下主键索引是非聚簇索引,表结构文件 FRM,索引文件 MYI(index),数据文件 MYD(data)
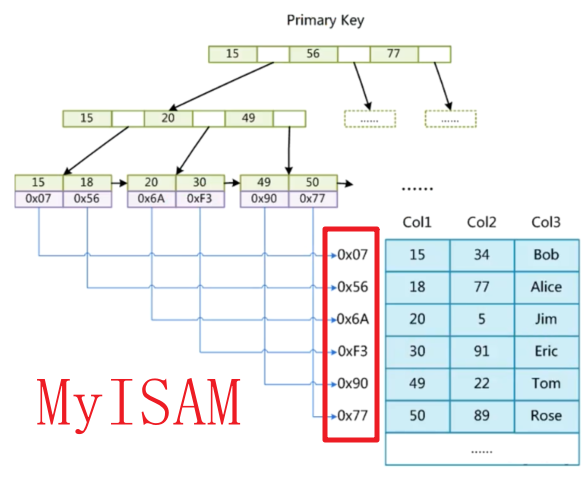
聚集索引相比于非聚集索引查找效率一般更高,直接在当前文件即可查询到数据,不用再去数据文件中查询。
聚簇索引的插入速度严重依赖于插入顺序,按照主键的顺序插入是最快的方式,否则影响性能。
对于 Innodb 表,一般主键定义为自增 整型,不可更新,二级索引访问需要进行两次索引查找,第一次找到主键值,第二次根据主键值找到行数据(回表),因此多使用主键查询
如果没有定义主键,那么会使用第一非空的唯一索引(NOT NULL and UNIQUE INDEX)作为聚簇索引
如果既没有主键也没有合适的非空索引,那么InnoDB会自动生成维护一个包含了ROW_ID值的列作为聚簇索引
最左匹配原则
联合索引:将多个字段(列)组合成为一个索引。
在使用联合索引时,需要遵循最左匹配原则,即按照最左优先的方式进行索引查询。
最左匹配原则要求查询的列必须从索引中最左的列开始,并且不能跳过中间列,否则索引失效。
联合索引底层为排好序的 B+树,如果没有给出第一字段,就无法快速找到该数据应该处在的节点,因为优先以第一字段排序,只看第二字段并不是从左到右排好序的,需要扫描所以节点
MySQL 索引的优缺点
优点:
- 1.方便查询,极大地缩短查找的时间
缺点:
- 1.创建索引。那么维护索引就需要消耗时间,数据量越多,维护成本越高
- 2.索引占用空间较大,每个节点都是 16Kb 的页大小,会影响表的最大存储量。
- 3.对表中的数据进行增加和删除修改。索引要动态维护,会降低数据维护速度
索引的优化
- 1.对于需要经常更新的字段,避免为他建立过多的索引
- 2.数据量小的表不用创建索引,不一定能比全表查询效率高
- 3.字段中存在重复数据例如性别不需要创建索引
- 4.主键索引最好是自增,方式插入新数据时对原数据的大量操作
- 5.尽量保证将索引设置为唯一,无需大量查找
索引失效
在如下情况可能会导致索引失效:
- 违背最左匹配原则
- 索引列中使用函数进行计算
- 查询条件中出现了类型转换
- 索引列和非索引列掺杂使用
- like 模糊查询%在最左或两边
- 联表查询时两个表的字符集不同
慢 SQL 优化
- 1.优先使用索引
- 2.是否索引失效
- 3.将数据量较大的表进行垂直或水平拆分
- 4.加 redis 缓存

| 大家的点赞、收藏、关注将是我更新的最大动力! 欢迎留言或私信建议或问题。 |
| 大家的支持和反馈对我来说意义重大,我会继续不断努力提供有价值的内容!如果本文哪里有错误的地方还请大家多多指出(●'◡'●) |