当你逐步熟悉 Elastic 时,你将使用 Elasticsearch Relevance Engine™ (ESRE),该引擎旨在为 AI 搜索应用程序提供支持。 借助 ESRE,你可以利用一套开发人员工具,包括 Elastic 的文本搜索、向量数据库和我们用于语义搜索的专有转换器模型。
Elastic 提供了多种搜索技术,从文本搜索的行业标准 BM25 开始。 它为特定搜索提供精确匹配,匹配精确的关键字,并通过调整进行改进。
当你开始向量搜索时,请记住向量搜索有两种形式:“密集(dense)”(又名 kNN 向量搜索)和 “稀疏(sparse)”,例如 Elastic 的学习稀疏编码器 (ELSER)。
Elastic 还为语义搜索提供了开箱即用的 Learned Sparse Encoder 模型。 该模型在各种数据集上都表现出色,例如财务数据、天气记录、问答对等。 该模型的构建是为了提供跨领域的巨大相关性,而不需要额外的微调。
查看此交互式演示,了解当您根据 Elastic 的文本 BM25 算法测试 Elastic 的学习稀疏编码器模型时,搜索结果如何变得更相关。
此外,Elastic还支持密集向量,对文本以外的非结构化数据(例如视频、图像、音频)实现相似性搜索。
语义搜索和向量搜索的优点在于,这些技术允许客户在搜索查询中使用直观的语言。 例如,如果向想搜索有关第二收入的工作场所指南,你可以搜索 “副业”,这不是你在正式人力资源文件中可能看到的术语。
在本指南中,我们将演示如何创建 Elasticsearch 集群、使用 Elastic Web 爬网程序提取数据以及只需单击几下即可实现语义搜索。
安装
Elasticsearch
我们可参考我之前的文章 “如何在 Linux,MacOS 及 Windows 上进行安装 Elasticsearch” 来安装 Elasticsearch。特别地,我们需要按照 Elastic Stack 8.x 的安装指南来进行安装。
在 Elasticsearch 终端输出中,找到 elastic 用户的密码和 Kibana 的注册令牌。 这些是在 Elasticsearch 第一次启动时打印的。
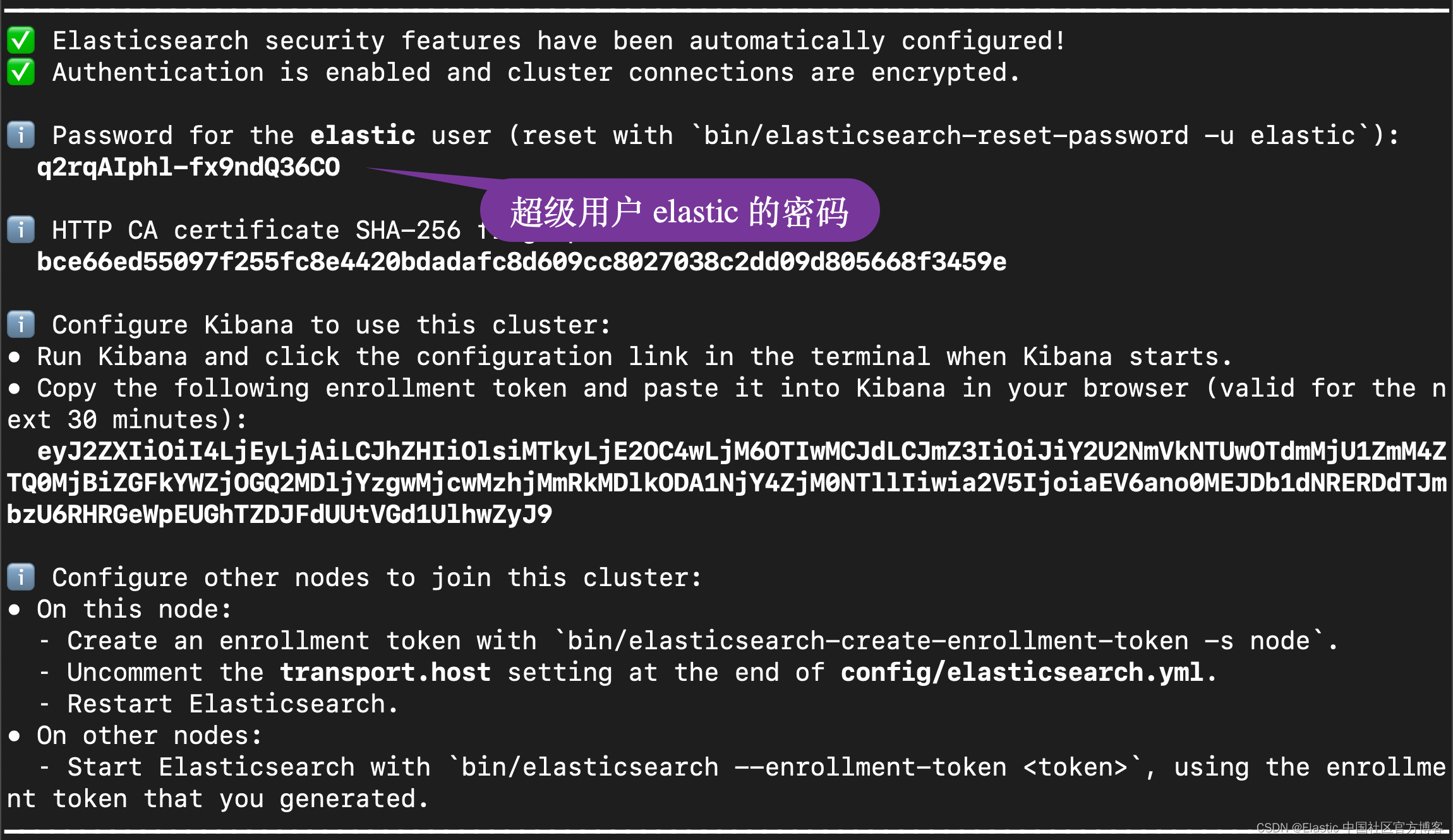
我们记下这个密码,并在下面的配置中进行使用。同时它也会生成相应的证书文件:
$ pwd
/Users/liuxg/elastic/elasticsearch-8.12.0
$ cd config/certs/
$ ls
http.p12 http_ca.crt transport.p12安装 Kibana
我们接下来安装 Kibana。我们可以参考我之前的文章 “如何在 Linux,MacOS 及 Windows 上安装 Elastic 栈中的 Kibana” 来进行我们的安装。特别地,我们需要安装 Kibana 8.2 版本。如果你还不清楚如何安装 Kibana 8.2,那么请阅读我之前的文章 “Elastic Stack 8.0 安装 - 保护你的 Elastic Stack 现在比以往任何时候都简单”。在启动 Kibana 之前,我们可以修改 Kibana 的配置文件如下。添加如下的句子到 config/kibana.yml 中去:
config/kibana.yml
enterpriseSearch.host: http://localhost:3002然后,我们使用如下的命令来启动 Kibana:

我们在浏览器中输入上面输出的地址然后输入相应的 enrollment token 就可以把 Kibana 启动起来。
Java安装
你需要安装 Java。版本在 Java 8 或者 Java 11。我们可以参考链接来查找需要的 Java 版本。
App search 安装
我们在地址 Download Elastic Enterprise Search | Elastic 找到我们需要的版本进行下载。并按照页面上相应的指令来进行按照。如果你想针对你以前的版本进行安装的话,请参阅地址 https://www.elastic.co/downloads/past-releases#app-search。
等我们下载完 Enterprise Search 的安装包,我们可以使用如下的命令来进行解压缩:
$ pwd
/Users/liuxg/elastic
$ ls
elasticsearch-8.12.0 kibana-8.12.0
elasticsearch-8.12.0-darwin-aarch64.tar.gz kibana-8.12.0-darwin-aarch64.tar.gz
enterprise-search-8.12.1.tar.gz logstash-8.12.0-darwin-aarch64.tar.gz
filebeat-8.12.0-darwin-aarch64.tar.gz metricbeat-8.12.0-darwin-aarch64.tar.gz
$ tar xzf enterprise-search-8.12.1.tar.gz
$ cd enterprise-search-8.12.1
$ ls
LICENSE NOTICE.txt README.md bin config lib metricbeat如上所示,它含有一个叫做 config 的目录。我们在启动 Enterprise Search 之前,必须做一些相应的配置。我们需要修改 config/enterprise-search.yml 文件。在这个文件中添加如下的内容:
config/enterprise-search.yml
allow_es_settings_modification: true
secret_management.encryption_keys: ['6c49f8004bfd5cb8c754c8e2f1cbe1f2793624545d052ab48fb37adc481f7d9b']
elasticsearch.username: elastic
elasticsearch.password: "q2rqAIphl-fx9ndQ36CO"
elasticsearch.host: https://127.0.0.1:9200
elasticsearch.ssl.enabled: true
elasticsearch.ssl.certificate_authority: /Users/liuxg/elastic/elasticsearch-8.12.0/config/certs/http_ca.crt
kibana.external_url: http://localhost:5601
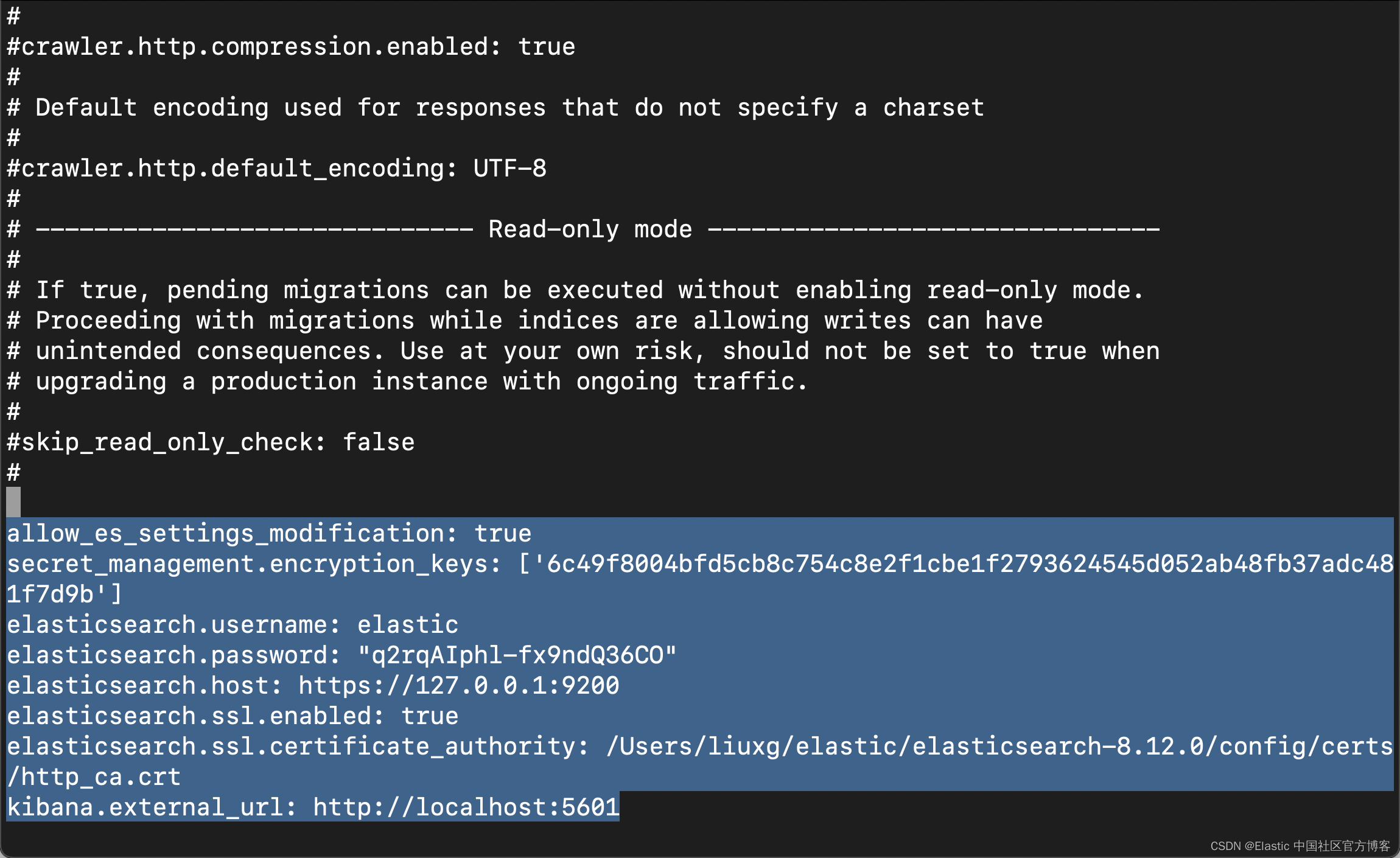
在上面,请注意 elasticsearch.password 是我们在 Elasticsearch 安装过程中生成的密码。elasticsearch.ssl.certificate_authority 必须根据自己的 Elasticsearch 安装路径中生成的证书进行配置。在上面的配置中,如果我们没有配置 secret_management.encryption_keys。我们可以使用上面的配置先运行,然后让系统帮我们生成。在配置上面的密码时,我们需要添加上引号。我发现在密码中含有 * 字符会有错误的信息。我们也可以参考链接来生成上面的 secret_management.encryption_keys。
$ openssl rand -hex 32
6c49f8004bfd5cb8c754c8e2f1cbe1f2793624545d052ab48fb37adc481f7d9b我们使用如下的命令来启动:
bin/enterprise-search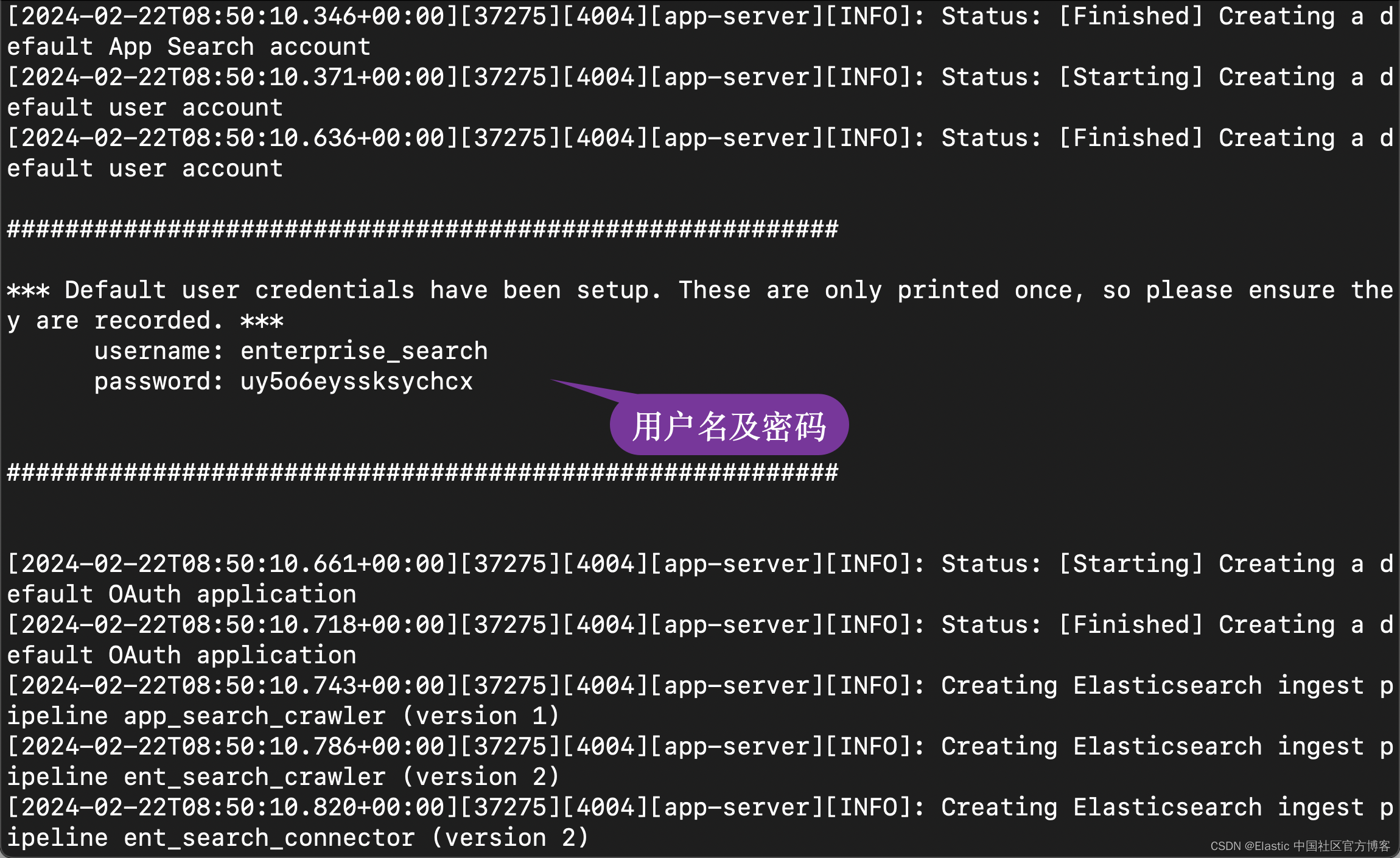
在启动的过程中,我们可以看到生成的用户名及密码信息:
username: enterprise_searchpassword: uy5o6eyssksychcx我们记下这个用户名及密码。在启动的过程中,我们还可以看到一个生成的 secret_session_key:

我们也把它拷贝下来,并添加到配置文件中去:

allow_es_settings_modification: true
secret_management.encryption_keys: ['6c49f8004bfd5cb8c754c8e2f1cbe1f2793624545d052ab48fb37adc481f7d9b']
elasticsearch.username: elastic
elasticsearch.password: "q2rqAIphl-fx9ndQ36CO"
elasticsearch.host: https://127.0.0.1:9200
elasticsearch.ssl.enabled: true
elasticsearch.ssl.certificate_authority: /Users/liuxg/elastic/elasticsearch-8.12.0/config/certs/http_ca.crt
kibana.external_url: http://localhost:5601secret_session_key: fcb5ecfd38095e81c66a36dd5ee0ea076dcb80d9a7dc7f67d46a19ba2390e07d0c71cb6895d8dba05425aa024f2dbad24fafd7310461cf14aa72492ddc39dde7feature_flag.elasticsearch_search_api: true为了能够使得我们能够在 App Search 中使用 Elasticsearch 搜索,我们必须设置
feature_flag.elasticsearch_search_api: true。 我们再次重新启动 enterprise search:
./bin/enterprise-search 这次启动后,我们再也不会看到任何的配置输出了。这样我们的 enterprise search 就配置好了。
启动白金试用
由于使用 ELSER 需要用到机器学习的功能,我们需要启动白金试用:




部署 ELSER


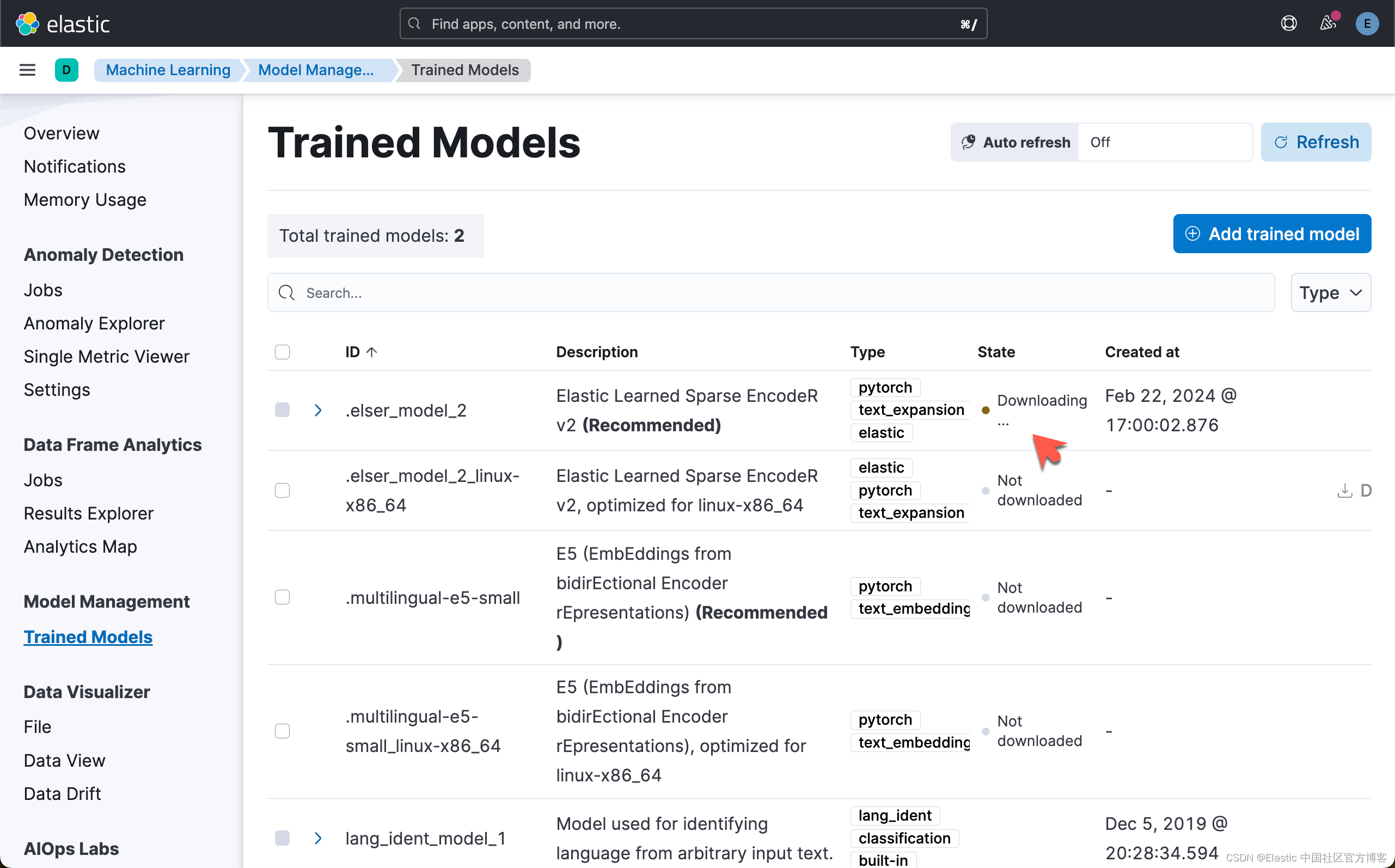
上面的下载过程讲持续一段时间。这个依赖于你的网络速度。
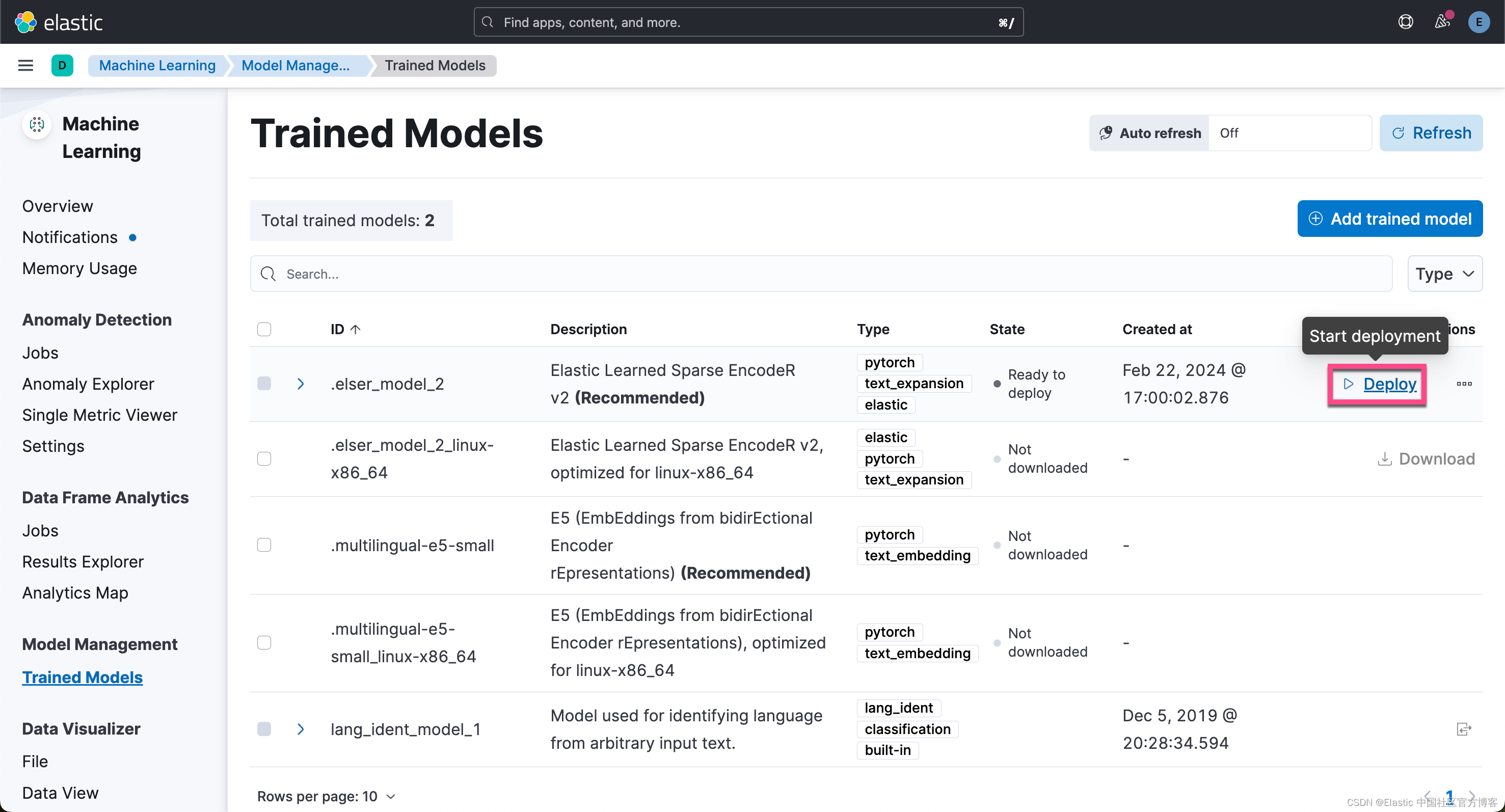


从上面的显示中,我们可以看出来,ELSER v2 的部署已经是成功的。
配置 Elastic 网络爬虫
现在你已经创建了部署,是时候将数据导入 Elasticsearch 了。 让我们使用 Elastic 的网络爬虫来完成此操作。 首先,在 “Search” 选项卡下,
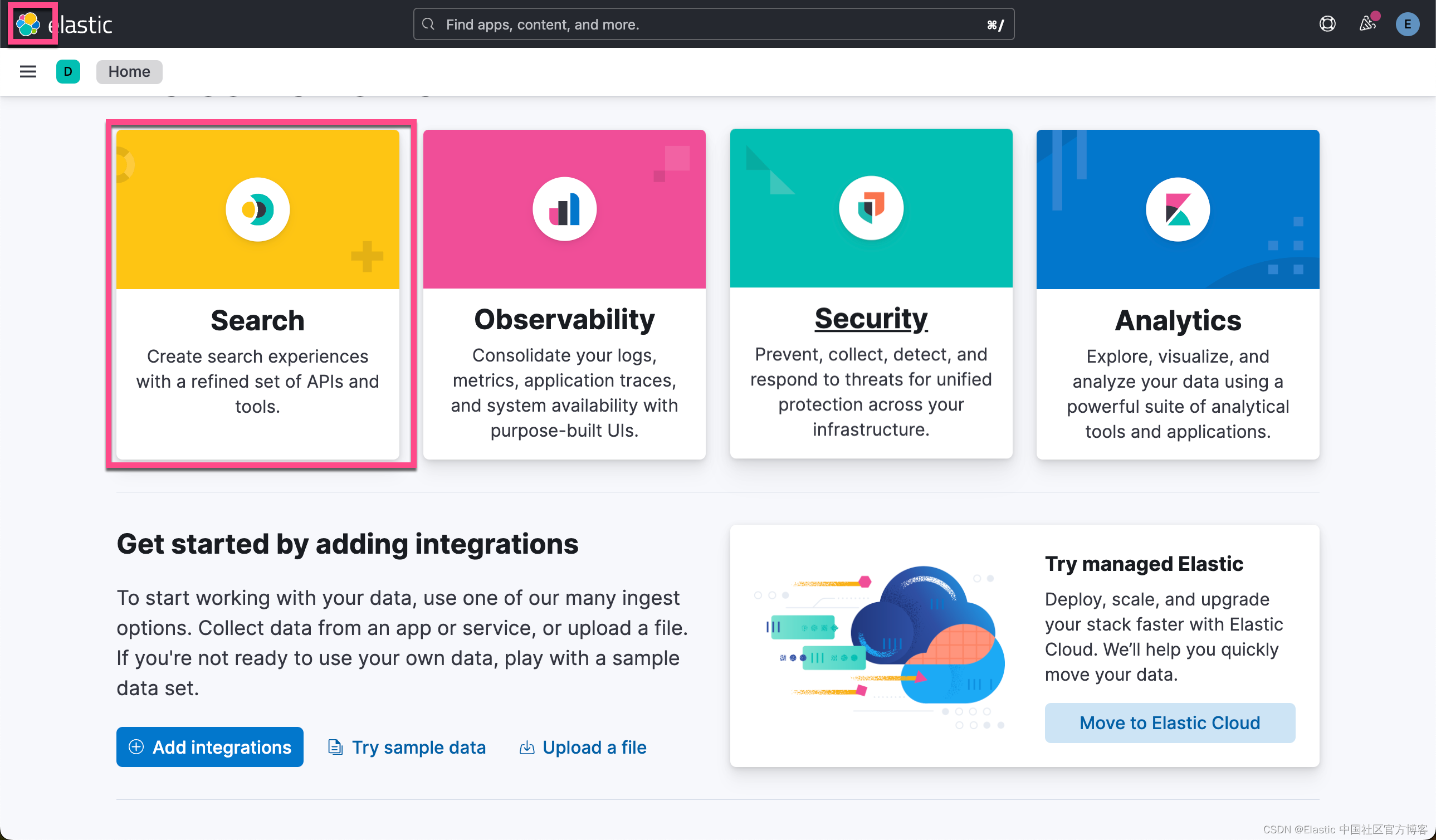

要设置网络爬虫,请查看此指南或按照以下说明操作:
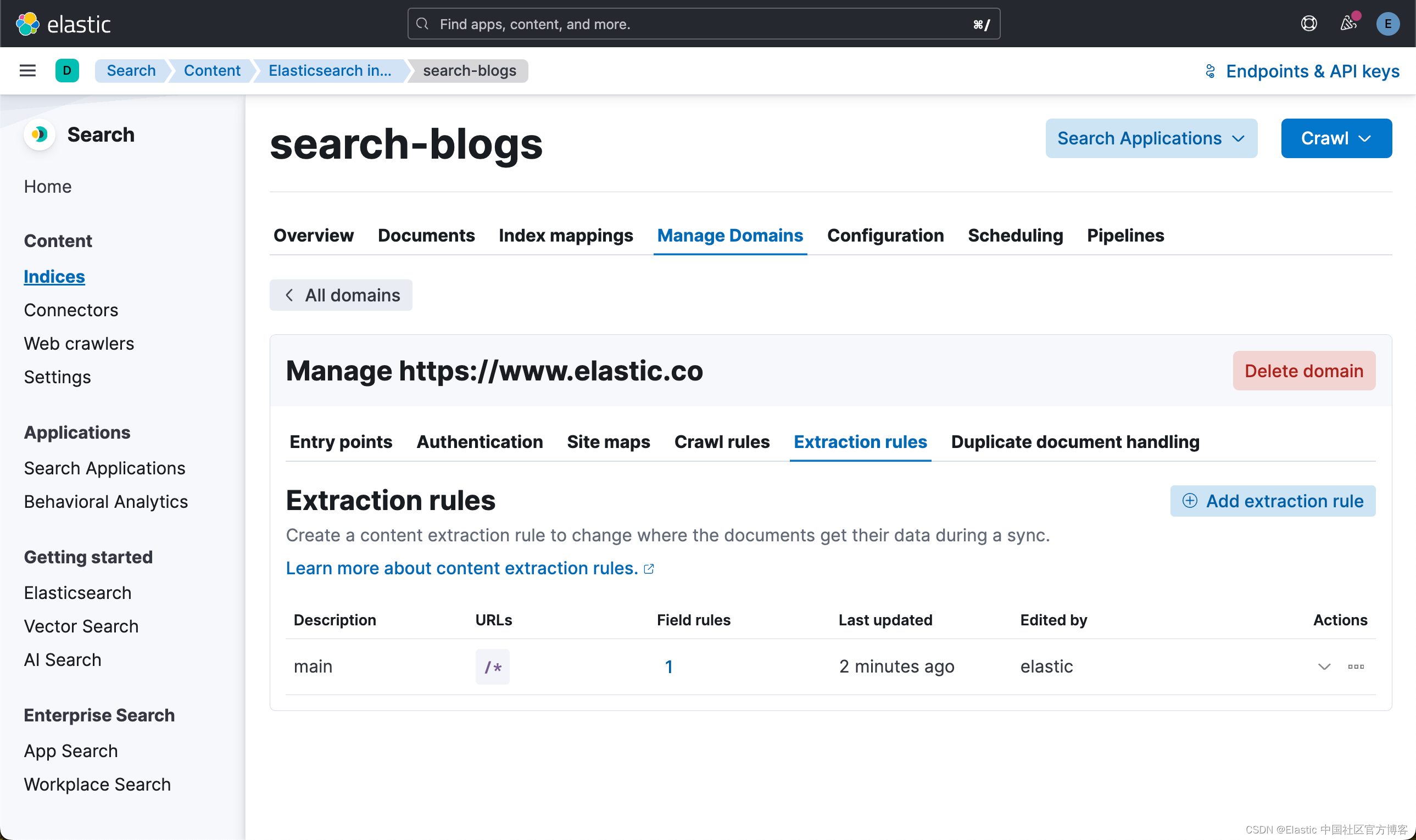
现在创建一个索引。 为了本指南的目的,我们通过 elastic.co 摄取博客。
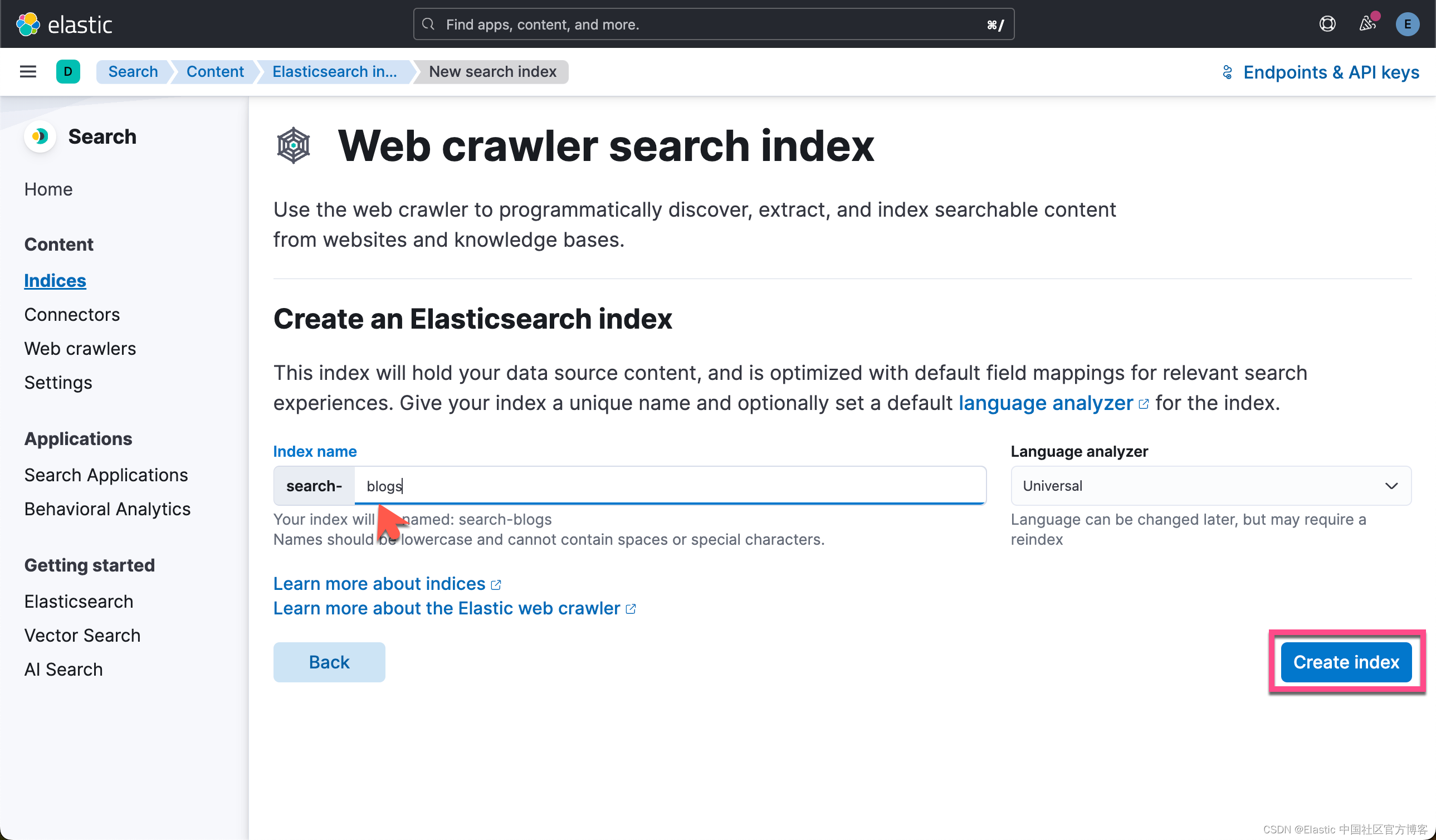
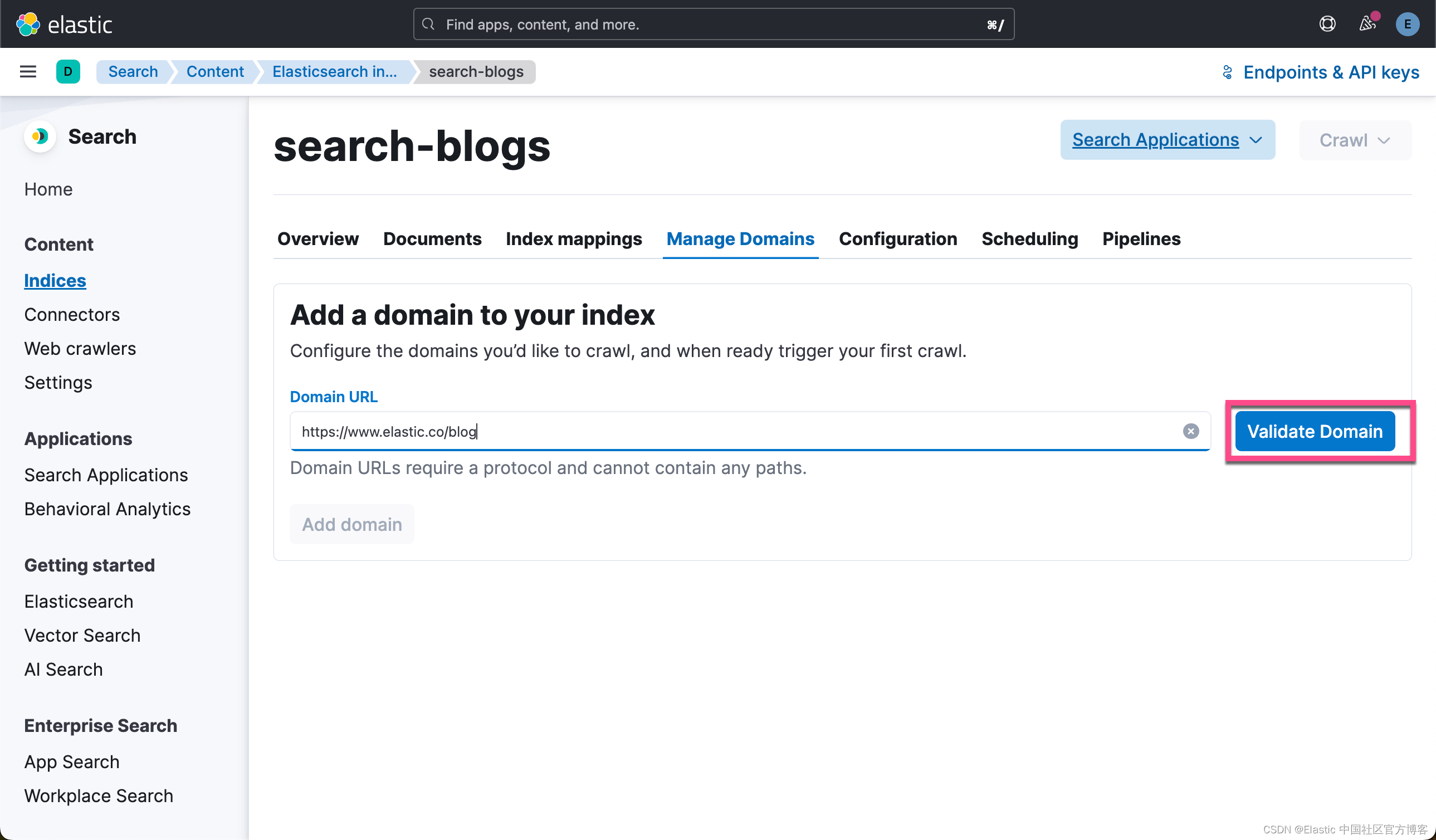
为索引命名后,选择 “Create inddex”。 接下来,你将 Validate Domain,然后选择 Add domain。
在右下角添加域后,你将选择 “Edit”,以便你可以根据需要添加 subdomain。

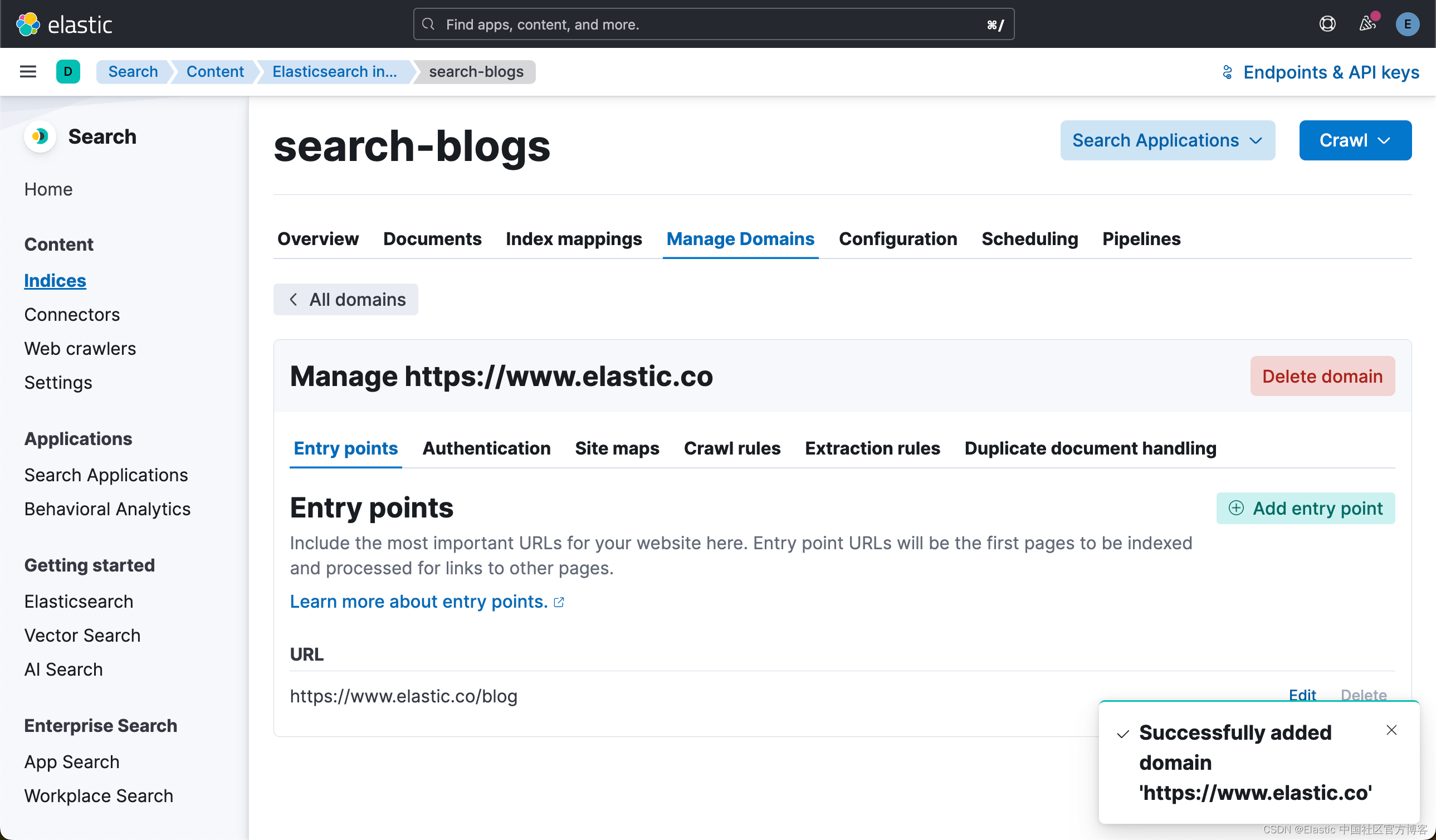
接下来,您将选择抓取规则并添加抓取规则,如下所示 .*

我们将提供抓取规则,以仅定位包含整个 elastic.co 网站上的博客的页面。由于你要抓取的页面将有链接到的页面,因此你应该添加附加规则以禁止这些链接和任何其他链接。
接下来,当你稍后选择字段时,某些字段会超过 512 个标记计数,例如 body_content。 你应该利用提取规则仅过滤掉博客的相关部分。我们将配置一个提取规则,以便仅提取 “main” 页面元素的内容,该元素包含要爬网的每个博客文章的内容。

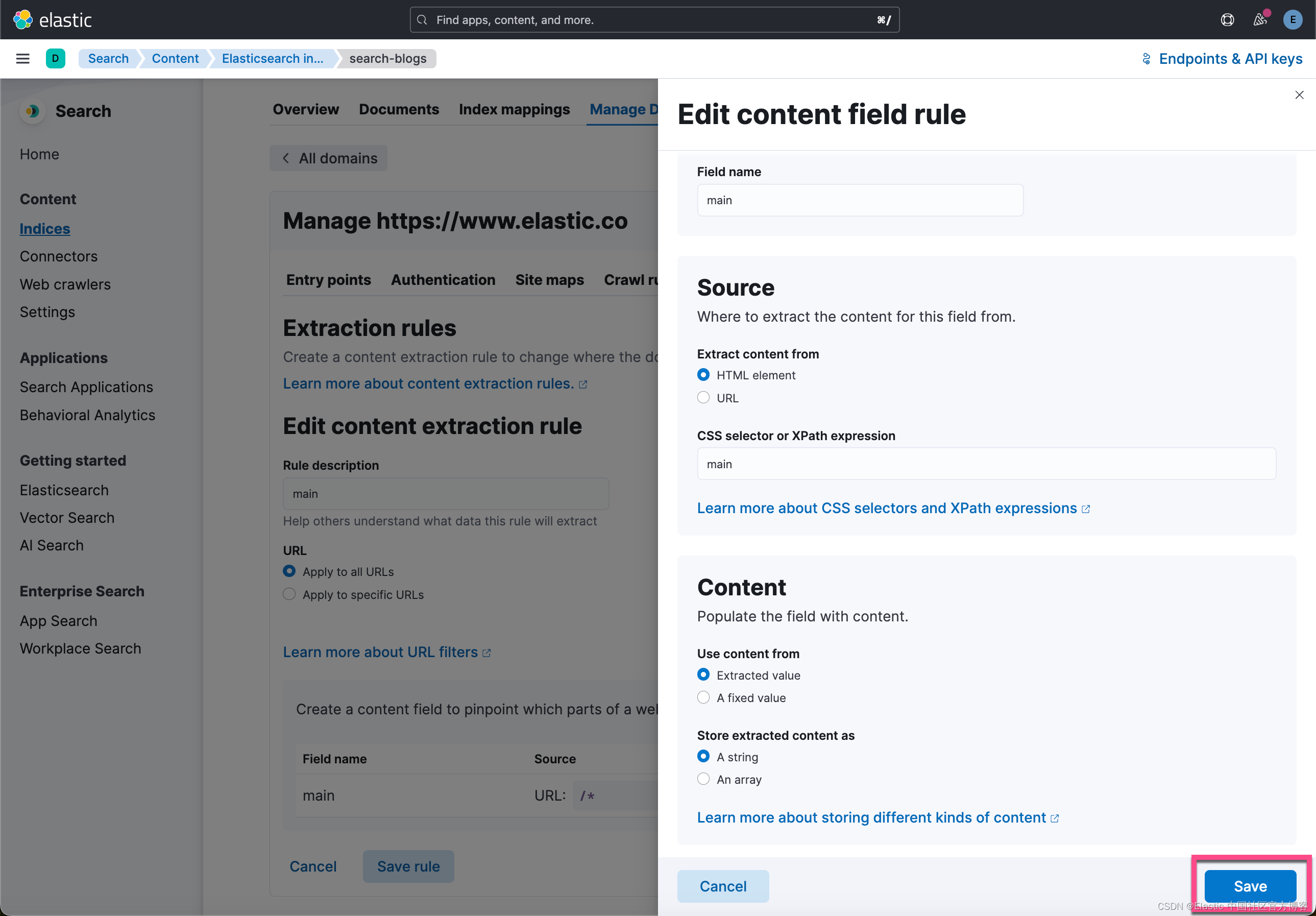

使用 Elastic Learned Sparse Encoder 丰富你的数据
按照以下说明开始使用 Elastic Learned Sparse Encoder(Elastic 的开箱即用语义搜索模型)。
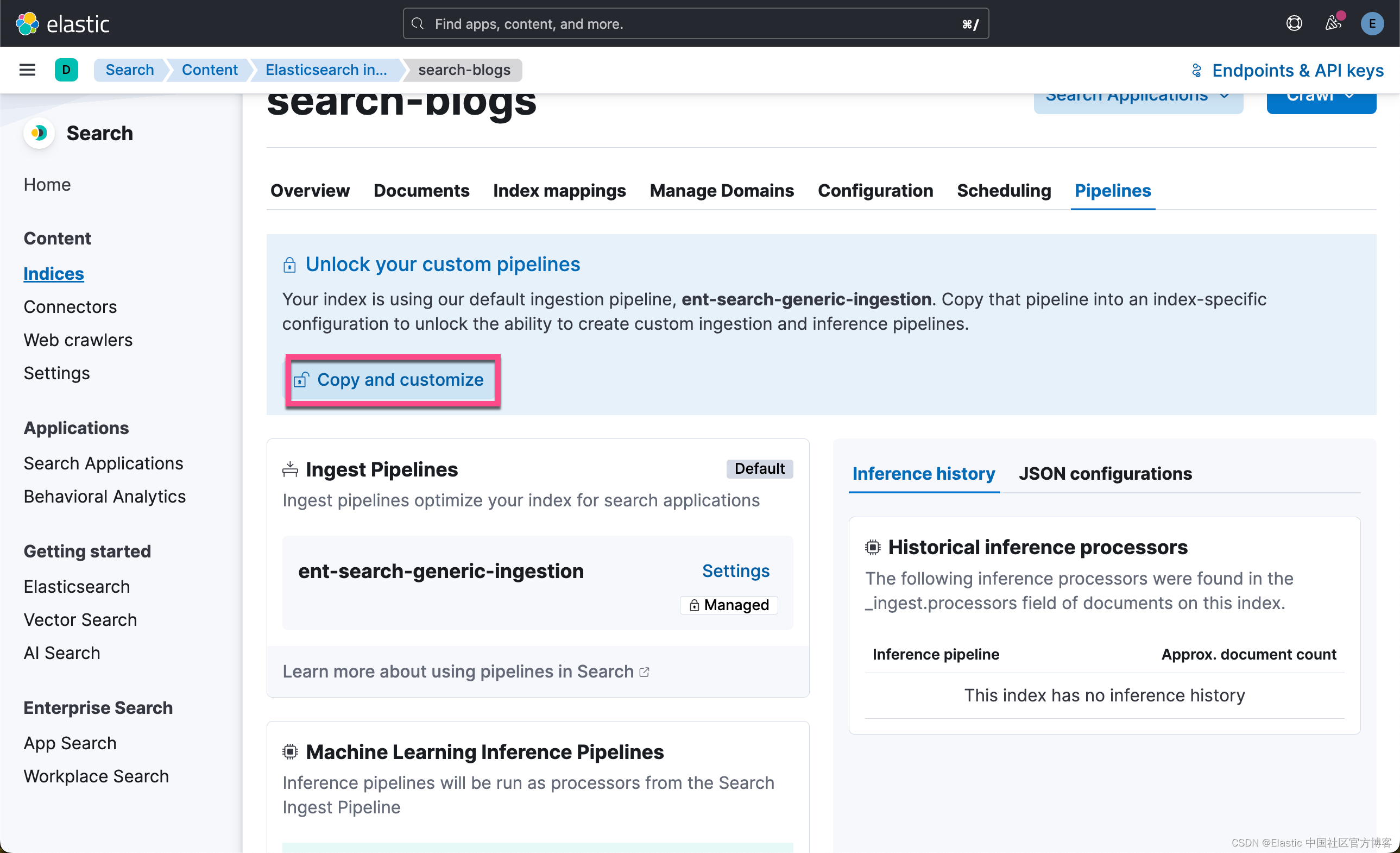
为此,你将选择 Pipeline 并通过选择顶部的 Copy and customize 来 Unlock your custom pipelines。 接下来,在 Machine Learning Inference Pipelines下,选择 Deploy 以下载模型并将其安装到你的 Elasticsearch 部署中。
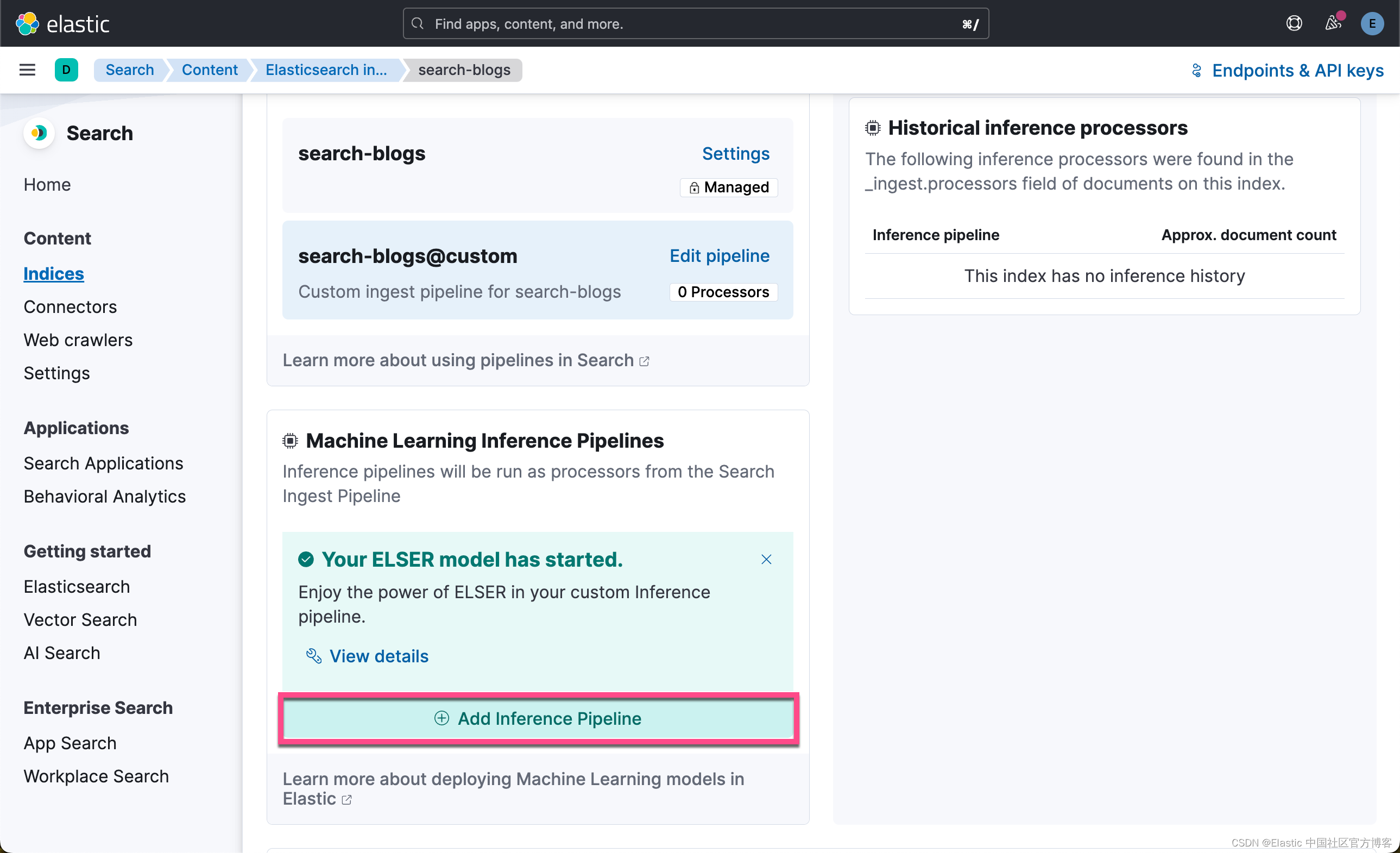

现在,你需要选择要应用 ELSER text expansion 的字段。 选择 “title” 和 “main” 作为源字段,然后添加。
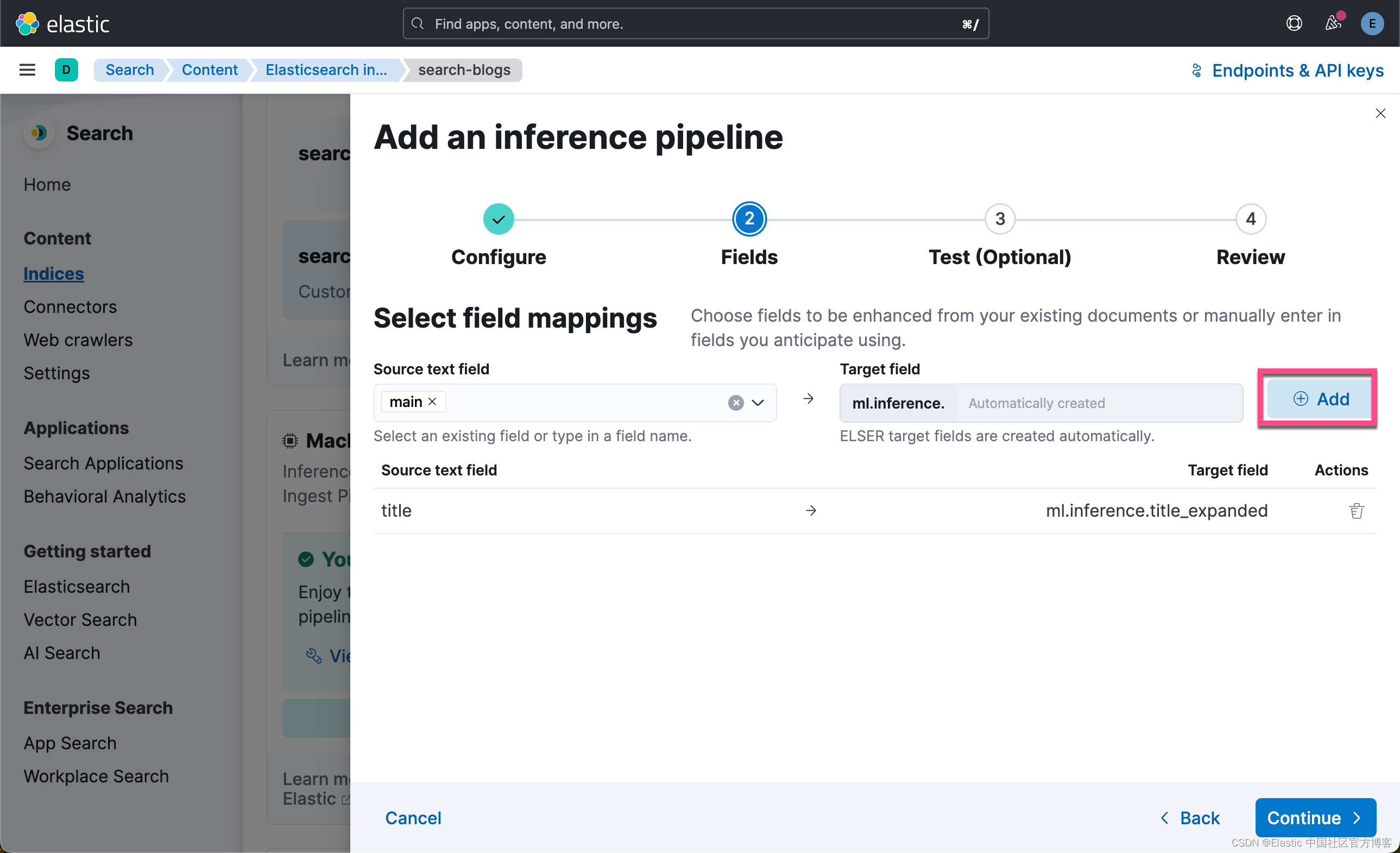

接下来,单击 Continue。



现在你已经创建了 pipeline,请选择右上角的 “Crawl”,然后选择 “Crawl all domains on this index”。


我们需要一定的时间才能完成。
为了能够验证我们是否已经正确地配置了 Crawler,我们可以在 Kibana 中进行查看:



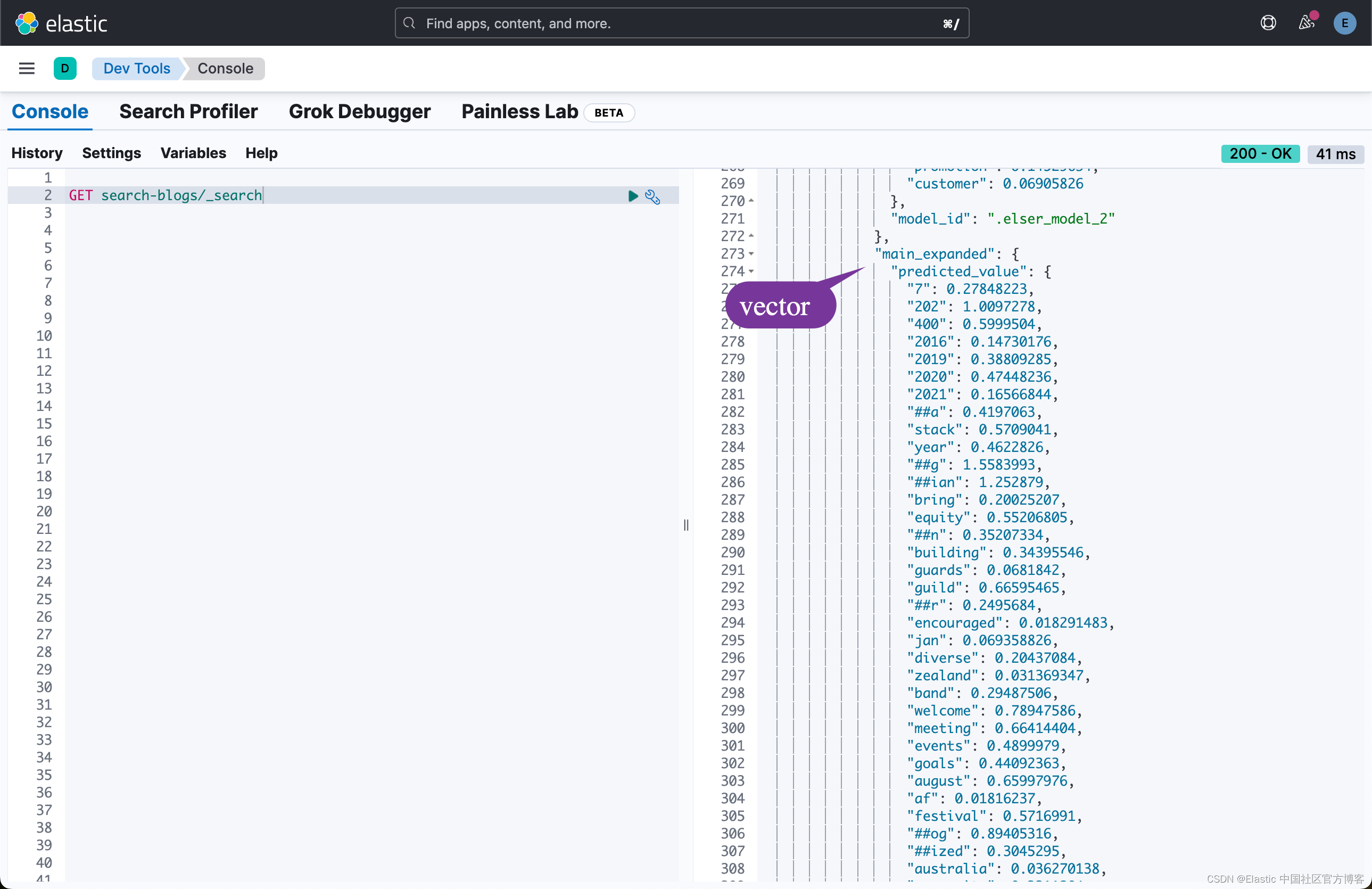
从上面的输出中,我们可以看到我们的配置是正确的。我们可以看到想要的字段已经相应的 text expansion 字段。
整个网站的爬虫是需要一定的时间。我们需要耐心等待。
使用 Elasticsearch
创建搜索查询
现在是时候搜索你要查找的信息了。 有两种推荐的方法可以做到这一点:第一种是使用开发工具。 如果你是正在实施搜索(即针对你的 Web 应用程序)的开发人员,你应该使用开发工具来测试和优化索引数据的搜索结果。
在下面,我们了解如何利用开发工具。
GET search-blogs/_search
{"_source": ["title"],"query": {"multi_match": {"query": "Implement a vector database","fields": ["title", "main"]}}
}这是一个正常的搜索。它没有使用向量搜索。

接下来,我们使用 ELSER 来进行向量搜索:
GET search-blogs/_search
{"_source": ["title"],"query": {"text_expansion": {"ml.inference.main_expanded.predicted_value": {"model_id": ".elser_model_2","model_text": "Implement a vector database"}}}
}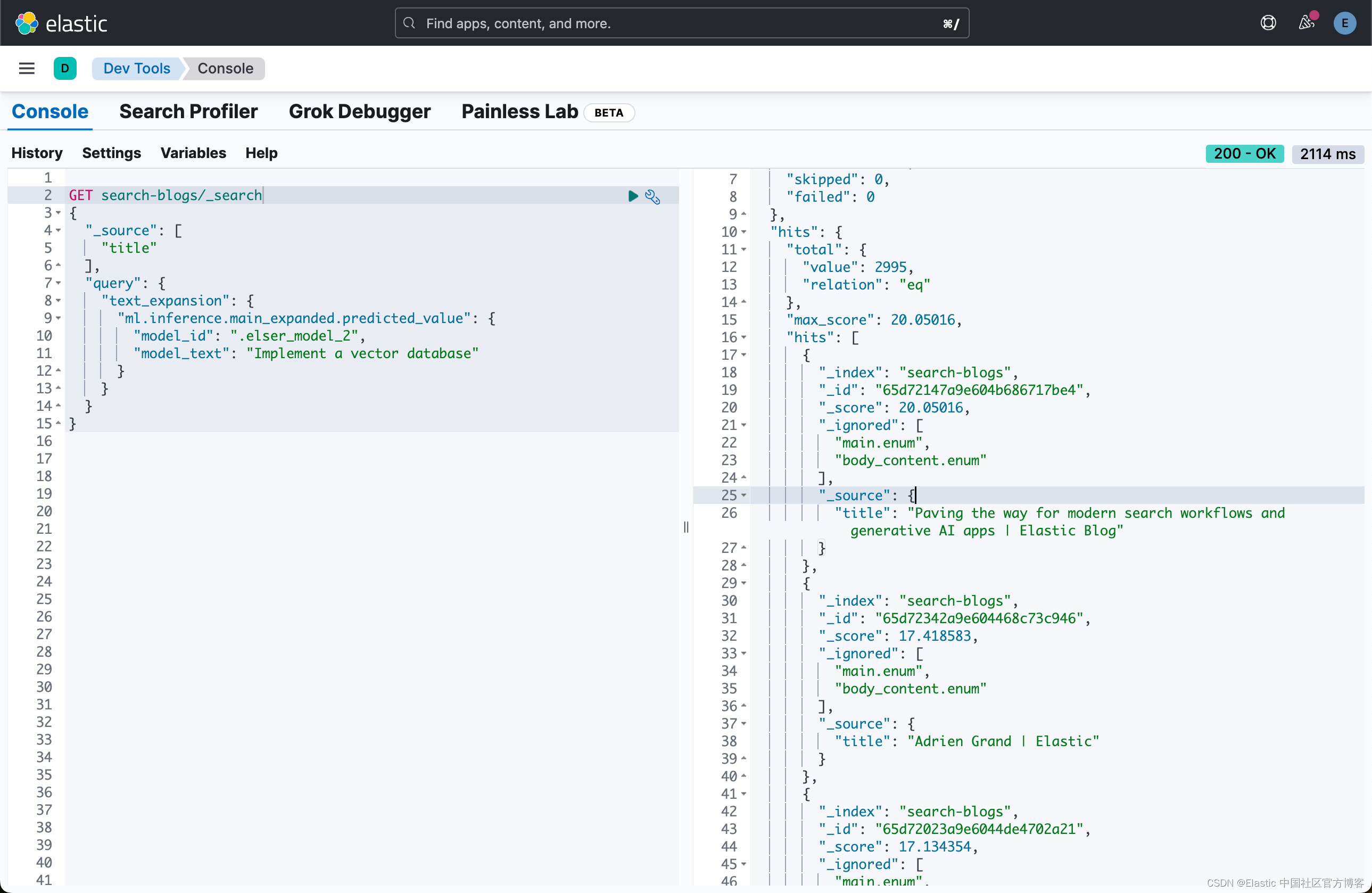
从上面的搜索结果上看,我们可以看到搜索的结果有一点不一样。通常向量搜索可以带给我们更好的语义搜索的结果。
使用 kNN 向量搜索进行摄取和搜索
我们可以阅读文章 “ChatGPT 和 Elasticsearch:OpenAI 遇见私有数据(二)” 以了解更多。
更多阅读:Enterprise:Web Crawler 基础 (一) (二)