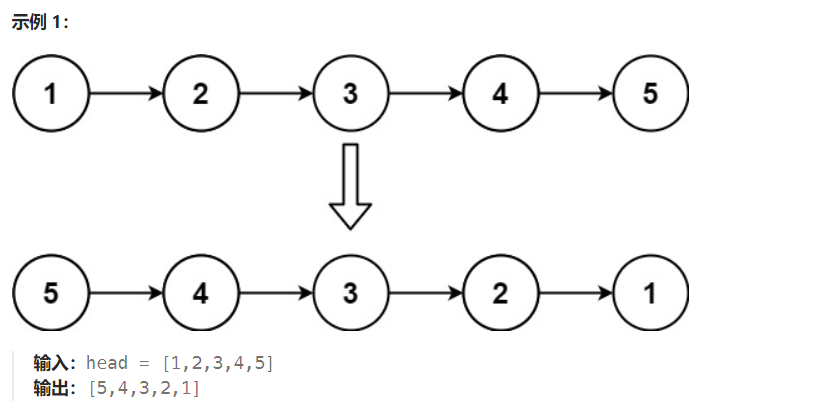
论文:《BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding》,2019
代码:[tensorflow],[pytorch]
来源:李沐精度BERT
0、摘要
与之前模型的区别:
-
GPT考虑的是一个单向预测,用左边的词预测右边的词;但BERT则是同时利用左边和右边的词,来预测中间的词
-
ELMO用的BiLSTM,但是它使用的是RNN结构,在应用到下游任务时它需要对模型结构做调整;但BERT使用的是transformer,在下游任务中只需要改上层的一小部分就可以了
基本效果:
-
11个任务上取得更高的精度
-
GLUE提升7.7%,至80.5%;MultiL1提升4.6%,至86.7%;SQuAD v1.1提升1.5,至93.2;SQuAD v2提升5.1,至83.1
1、导言
句子层面的任务:情感识别
单词层面的任务:命名实体识别
下游任务使用预训练模型的两种方式:
-
Feature-based:下游任务先用训练好的预训练模型来提取训练语料的特征,这个特征可能是预训练模型encoder的输出,也可能是某个中间层的隐藏状态;然后下游任务再用这个特征对自己的模型做训练。简单来说,就是用预训练模型做一个特征提取器?
-
Fine-tuning:根据下游特定的任务,在原来的预训练模型上进行一些结构方面的修改,这些修改通常是在模型的最后一层,使得模型输出是当前任务所需要的;然后在新的语料上重新训练修改后的模型。
之前工作的局限性:从左到右,单向,不太符合人类对语言的理解
MLM:Masked Language Model,带掩码的语言模型
贡献:
(1)展示了双向信息的重要性
(2)第一个基于微调、且在各项任务上都取得优越性能的预训练模型
2、相关工作
非监督的基于特征的方法:代表作是ELMo
非监督的微调方法:代表作是GPT
在有标注的数据上做迁移学习
3、BERT
Pre-training:在无标注的数据上做训练
Fine-tuning:模型首先用预训练好的模型做参数初始化,然后用下游任务标注好的数据对所有的参数做训练
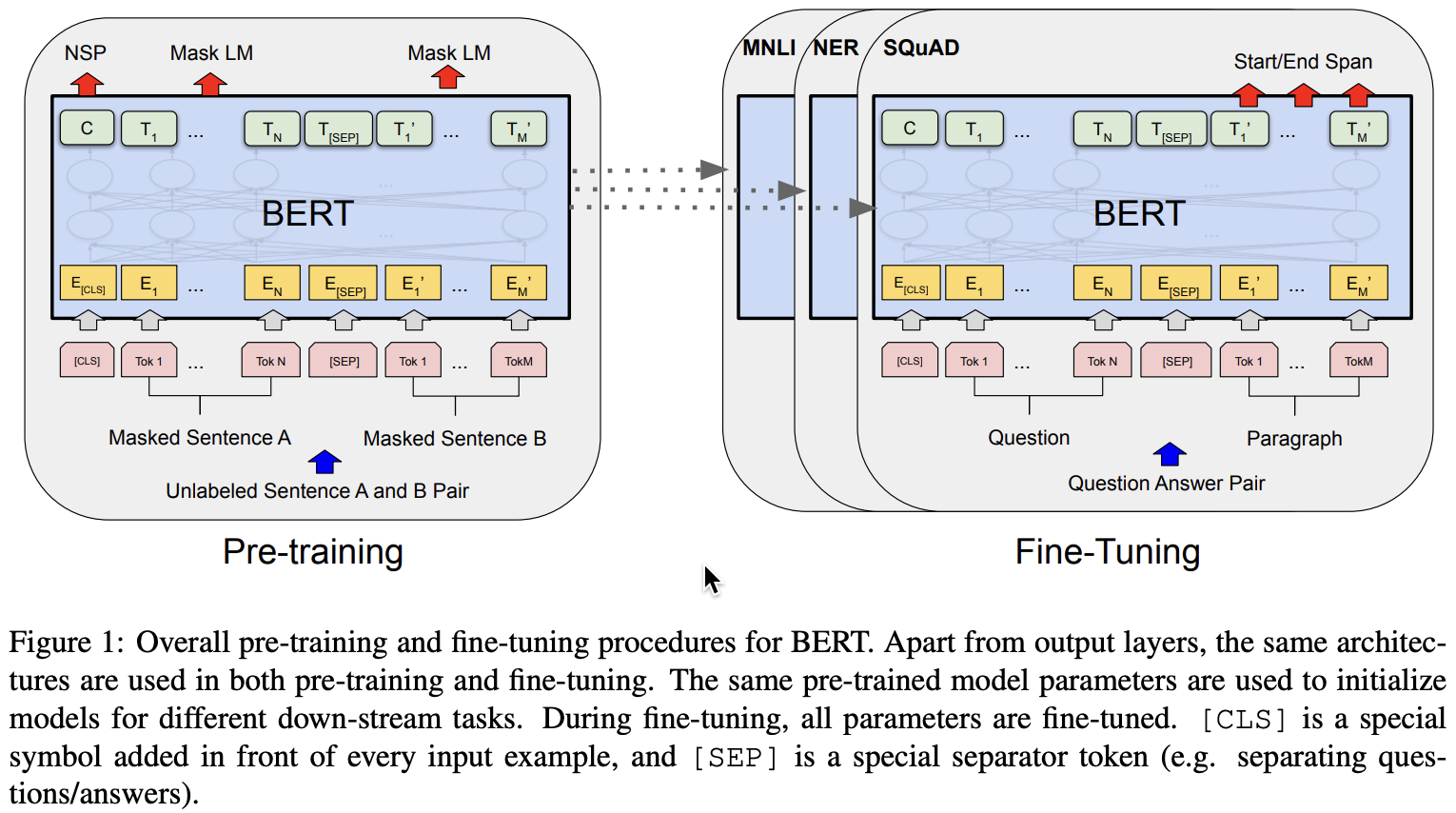
L:transformer块的个数
H:隐藏层的大小
A:自注意力机制模块head的数量
| L | H | A | Total parameters | |
|---|---|---|---|---|
| BERT_Base | 12 | 768 | 12 | 110M |
| BERT_Large | 24 | 1024 | 16 | 340M |
切词方式:WordPiece(类似于BPE,字节对编码??)
句子的第一个 token 永远是 [CLS],它代表 classification,其在最后一个隐藏层的输出就代表整个序列在句子层面的信息。
句子与句子之间用一个 [SEP] 分割,它代表 separate。
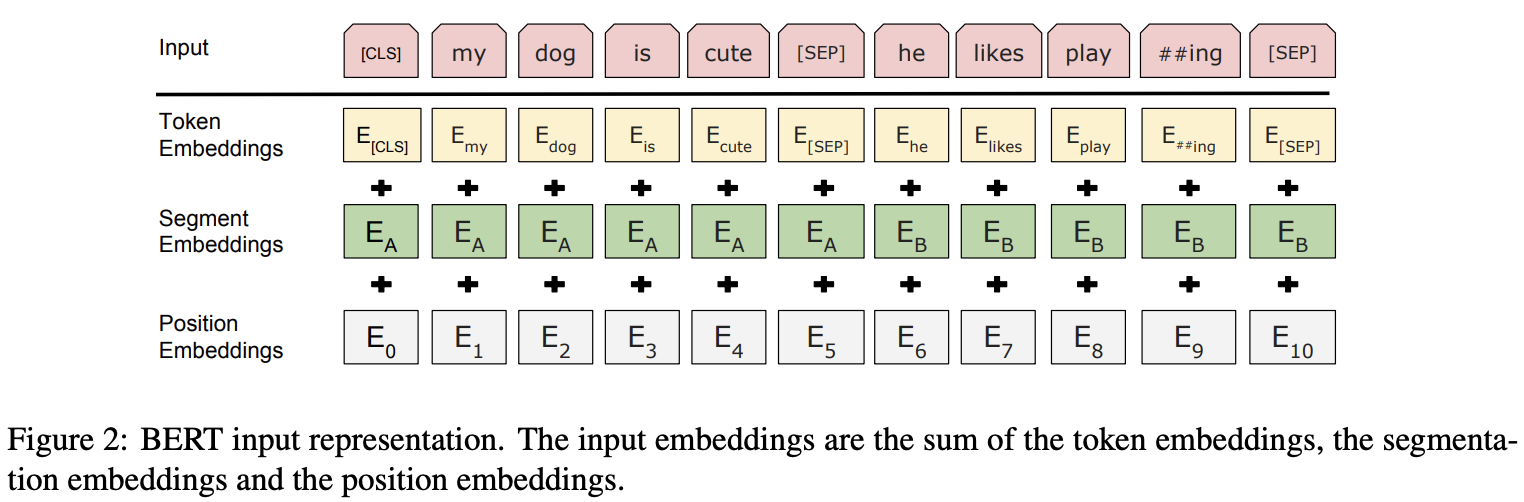
上图即为BERT嵌入层的做法,分为三部分:
- Token Embedding:词元的嵌入,就是正常的单词嵌入向量
- Segment Embedding:词元属于哪一个句子的嵌入,是属于第一个句子,还是属于第二个句子(第一个[SEP]属于第一个句子)
- Position Embedding:词元的位置嵌入,是在整个输入序列中的位置(不是在单独某一个句子中的位置)
BERT用的是transformer的编码器(没用decoder),所以它的每一个词都会跟句子中的其他词计算注意力关系。
预训练中两个比较重要的点:(1)目标函数;(2)数据。
任务一:Masked LM,预训练的数据有Mask,但是微调的数据没有Mask,这会带来一些问题(什么问题??),解决方案是:
- 15%被选中的待预测词,有80%的概率被替换成 [Mask] 掩码符号,有10%的概率被替换成随机的词元,有10%的概率保持不变但依然去做预测。

任务二:Next Sentence Prediction(NSP),预测下一个句子
- 两个句子A和B,50%的概率B是在A之后(正例),有50%的概率B就是从其他地方选取出来的、跟A无关的一个句子(负例)

注:上面的 ## 表示后面的那个词跟前面的词是一个单词,因为 flightless 是一个不常见的单词,所以就把它分开成两个常见的单词flight和less。
BERT的Fine-Tuning:根据下游任务的形式,设计模型的输入和输出(模型本身不需要做太多改变)
- 如果做分类,就用第一个词元 [CLS] 的输出来做分类;
- 如果做句子预测,就对每个词元的输出再加一个输出层,做softmax做预测;
4、实验
GLUE:分类任务,对第一个词元 [CLS] 的输出做softmax,然后分类。
SQuAD v1.1:Q&A任务,给模型一段话,然后提一个问题,需要在这段话中找出这个问题的答案,这个答案已经在这段话里面了,模型只需要找出答案片段的开始和结尾。
5、消融实验
BERT用作Feature-Based的效果并不好,用作Fine-Tuning更好一些。
6、结论
(1)使用非监督的预训练是很好的,这使得那些数据量很小的下游任务也能使用神经网络
(2)主要的贡献就是把前人的工作成果扩展到双向的深度结构上