今日复习内容:做复习题
例题1:希尔排序
题目描述:
希尔排序是直接插入排序算法的一种更高效的改进版本,但它是非稳定排序算法。希尔排序是基于插入排序的以下两点性质而提出的改进方法之一:
1.插入排序在对几乎已经排好序的数据操作时,效果是非常好的。
2.插入排序一般来说是低效的,因为插入排序每次只能将数据移动一位。
而通常对于希尔排序中我们选择增量序列为:[N / 2],[N / 4],...,1,其中N为待排序数组的长度。
现在,给你一个整数数组,要求使用希尔排序算法对它进行排列。
输入格式:
第一行是一个整数n,表示整数数组的长度;
第二行包含n个空格分隔的整数a1,a2,...,an。
输出格式:
输出n个整数,即从小到大排序后的数组。
参考答案:
n = int(input())
li = list(map(int,input().split()))
gap = n // 2
while gap:for i in range(gap,n):value = li[i]j = iwhile j >= gap:if li[j - gap] > value:li[j] = li[j - gap]j -= gapelse:breakli[j] = valuegap //= 2
print(*li)运行结果:

以下是我对这道题的理解:
这个问题要求使用希尔排序算法对给定的整数数组进行排序。
希尔排序是插入排序的一种改进版本,它通过引入增量序列来减少插入排序中元素比较和交换的次数,从而提高排序效率。希尔排序的核心思想是先将整个待排序的记录序列分割成若干子序列,分别进行直接插入排序,待整个序列中的记录基本有序时,再对全体记录进行直接插入排序。
而希尔排序的增量序列是选择一个递减的序列,通常为N / 2,N / 4,...,1,其中N是待排序数组的长度。
首先,输出整数数组的长度和具体的数组内容。然后,初始化增量为数组长度的一半。接下来,通过一个while循环,不断缩小增量,直到增量为0。在循环中,对每个增量间隔进行插入排序。在插入排序中,从第一个增量间隔开始,将当前待插入的值与前面的值进行比较,依次向前移动元素,直到找到合适的位置插入。最后,输出排序后的数组。
n = int(input()):我们从标准输入中获取一个整数,表示整段数组的长度,将其赋值给变量n.
li = list(map(int,input().split())):接着,我们再从标准输入中读取一行,包含了空格分隔的整数,使用split()函数将其分隔成单独的数字字符串,并通过map()函数将这些字符串转换成整数,最后把它们组成一个列表并赋值给变量li,表示整数数组。
gap = n // 2 :然后,我们初始化增量gap为数组长度的一半。希尔排序中,我们会根据增量序列进行分组,首先选择一个较大的增量。
while gap:这里是一个while循环,只有增量gap不为0,就会一直执行排序
for i in range(gap,n):在每次循环中,我们使用for循环变量从gap开始到数组长度n的范围,这是为了对增量间隔进行排序。
value = li[i]:我们将当前待插入的值存储在变量value中,即当前增量间隔内需要插入到正确位置的元素
j = i:然后,我们将变量j初始化为当前位置i,从当前位置开始向前比较
while j >= gap and li[j - gap] > value:这是一个while循环,它会在满足两个条件的情况下执行:
j >= gap:然后,确保我们没有越界访问数组;
li[j - gap] > value:比较当前位置的前一个间隔增量的值是否大于待插入的值value,如果是,则需要向后移动元素。
li[j] = li[j - gap]:如果满足条件,我们将前一个间隔增量的值向后移动要给位置。
j -= gap:然后,我们将j向前移动 一个间隔增量,继续向前比较
li[j] = value:最后,我们将待插入的值value插入到正确的位置
gap //= 2:在内层循环结束后,我们将增量gap减半,以减少增量,这是希尔排序的一个重要步骤
print(*li):最后,我们使用print函数输出最后的数组,通过*li,我们将列表li中的元素拆包传递给print()函数,以便按照空格分隔输出数组元素。
通过对每个间隔增量进行插入排序,并在每轮排序或缩小增量,最终完成整个数组的排序。
例题2:图书排序
题目描述:
城市图书馆决定对其藏书进行重新分类。它们决定使用希尔排序作为其分类方法的基础,但是有一些特殊的要求。
图书馆的每本书都有一个独特的ID,范围从1到N。每本书还有一个权重值,表示其在库中的重要性。图书馆希望按照权重对图书进行排列,但是他们希望保留希尔排序的某些特性。
他们的要求如下:
1.使用希尔排序的增量序列:[N / 2],[N / 4],...,1。
2.当两本书的权重相同时,书籍ID较小的书应该出现在前面。
你的任务是根据这些要求,为图书馆排序这些藏书。
输入格式:
第一行,一个整数N,表示图书的数量。
接下来的N行,每行两个整数,分别是书籍的ID和权重,题目保证每本书的ID是唯一的。
输出格式:
输出N行,每行一个整数,按权重排序后的书籍ID。
参考答案:
n = int(input())
li = []
for i in range(n):li.append(list(map(int,input().split())))
gap = n // 2
while gap:for i in range(gap,n):value = li[i]j = iwhile j >= gap:if li[j - gap][1] > value[1]:li[j] = li[j - gap]j -= gapelse:breakli[j] = valuegap //= 2
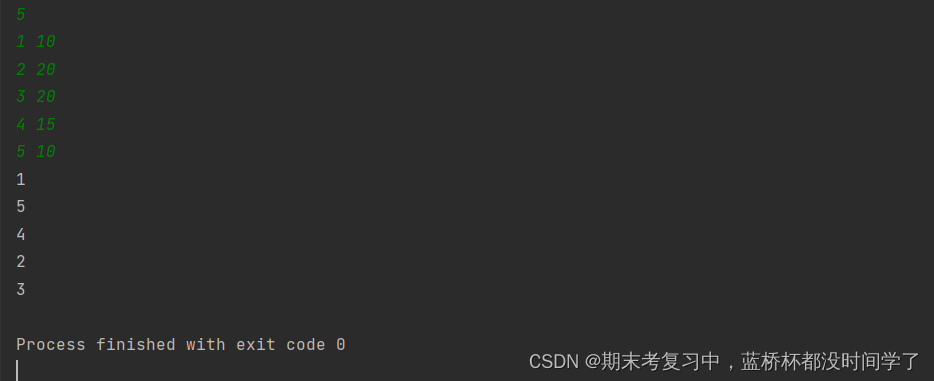
for i in li:print(i[0])运行结果:
以下是我对代码的理解:
n = int(input()):首先,我们从标准输入中读取一个整数n,表示图书的数量,将其赋值给n
li = []:然后,我们初始化一个空列表li用来存储每本图书的信息。每个元素是一个包含两个整数的列表,分别表示书籍的ID和权重。
for i in range(n):接着,我们使用for循环遍历n次,读取每本书的ID和权重,并将其作为一个包含两个整数的列表添加到列表li中。
gap //= 2:初始化希尔排序的增量为数组长度n的一半
while gap:这是一个while循环,只要增量gap不为0,循环就会一直运行下去
for i in range(gap,n):在每次循环中,我们使用for循环遍历从增量gap开始到数组长度n的范围,这是为了对每个增量间隔进行插入排序
value = li[i]:我们将当前待插入的图书信息存储在变量value中,即当前增量间隔内需要插入到正确位置的书籍。
j = i:然后,我们把变量j初始为当前位置i,从当前位置开始向前比较
while j >= gap:这是一个while循环,它会在满足条件 j >= gap的情况下执行,确保我们没有越界访问数组。
if li[j - gap][1] > value[1]:在循环中,我们比较当前位置的前一个间隔增量的书籍 权重是否大于待插入书籍的权重
li[j] = li[j - gap]:如果前一个间隔增量的权重较大,我们将其向后移一个位置
j -= gap:然后,我们将j向前移动一个间隔增量,继续向前比较
else:break:如果前一个间隔增量的书籍权重不大于待插入的书籍权重,则跳出循环,因为我们要保持相同权重的情况下ID较小的排前面。
li[j] = value:最终,我们将待插入的书籍信息插入到正确位置
gap //= 2:在内层循环结束后,我们将增量gap减半,以缩小增量,这是希尔排序的一个重要步骤
for i in li:最后,我们使用for循环遍历排序后的书籍信息列表li
print(i[0]):通过print()函数输出每本书的ID,这样就满足了题目要求,按照权重排序,并在权重相同时,保留ID较小的书籍在前面。
例题3:咖啡馆订单系统
题目描述:
一家知名的连锁咖啡馆决定改进其订单管理系统。为了提高效率,他们决定使用某种指定属性的希尔排序,并确定在给定的增量序列下,需要多少次比较和交换对订单进行排序。
输入格式:
第一行,一个整数n,表示订单的数量。
第二行,一个整数m,表示增量序列的长度。
接下来的一行,包含m个以空格分开的整数,表示增量序列,题目保证增量序列严格递减且最后一个数是1.
接下来的n行,每行一个整数,表示订单的属性值。
输出格式:
两个整数,分别表示比较和交换的次数。
参考答案:
n = int(input())
m = int(input())
gaps = list(map(int,input().split()))
compare = 0
change = 0
li = []
for i in range(n):li.append(int(input()))
for gap in gaps:for i in range(gap,n):value = li[i]j = iwhile j >= gap:compare += 1if li[j - gap] > value:change += 1li[j] = li[j - gap]j -= gapelse:breakli[j] = value
print(compare,change)
运行结果:

以下是我对此题的理解:
n = int(input()):从标准输入中读取订单数量n,将其转换为整数并赋值给变量n
m = int(input()):从标准输入中读取增量序列的长度m,将其转换为整数并赋值给变量m
gaps = list(map(int,input().split())):从标准输入读取一行,使用split()函数将其分割成字符串序列,然后使用map()函数将其转换为整数,再将其转换为列表赋值给gaps
compare = 0和change = 0:初始化比较次数和交换次数为0
li = []:初始化一个空列表,用于存储订单的属性值
for i in range(n):循环n次,读取每个订单的属性值,并将其作为整数添加到列表li中
for gap in gaps:遍历增量序列中的每个增量
for i in range(gap,n):从增量gap开始,遍历订单列表进行排序
value = li[i] :将当前位置的订单属性值存储在变量value中,,用于后续比较和插入操作
j = i:将变量j初始化为当前变量i,用于向前比较和插入操作
while j >= gap:只要当前位置大于等于增量gap,就执行以下操作:
compare += 1:增加比较次数
li[j] = li[j - gap]:将前一个位置的属性值想后移动一位
j -= gap:将索引j向前移动一个增量gap的位置
else:break:如果不满足上述条件,就跳出循环
li[j] = value:将当前值value插入到正确的位置
print(compare,change):输出比较和交换次数
例题4:第3大的和
题目描述:
现在给定N个数,现在要求你从这N个数中挑选处理3个数,请你求出这3个数的和中第3大的是多少?
请注意,如果在求和过程中出现了相同的和,则只能留一个,其他的忽略不计。
输入格式:
输入的第一行包含一个整数n,表示数字的数量;
输入的第2行包含n个数字,代表给出的数字序列。
输出格式:
输出一行,包含一个数字,表示第3大的和。
参考答案:
import itertools
import heapq
n = int(input())
li = list(map(int,input().split()))
res = set()
for i in itertools.combinations(li,3):print(i)res.add(sum(i))
res = list(res)
print(heapq.nlargest(3,res))
print(heapq.nlargest(3,res)[-1])运行结果:

以下是我对此题的理解:
import itertools:导入python中的itertools模块,用于生成序列的所有可能组合
import heapq:导入python中的heapq模块,用于堆操作,这里用于找出列表中的最大值
n = int(input()):从输入中读取一个整数,表示数字的数量,赋值给变量n
li = list(map(int,input().split())):从标准输入中读取一行数字,使用split()方法将其分割成单独的字符串列表,然后转换为整数,再转换为列表,赋值给变量li
res = set():初始化一个空集合,用于存储所有可能的和
for i in itertools.combinations(li,3):生成列表li中任意3个数字的组合,每次循环得到一个组合i
res.add(sum(i)):计算组合i的数字之和,并将其添加到集合set中
res = list(res):将集合转换为列表,为了后续使用heapq模块找出最大的3个值
print(heapq.nlargest(3,res)[-1]):找出前3大的和中的第3大值,即倒数第一个值,然后打印出来作为答案。
例题5:基数排序
题目描述:
实现基数排序算法。基数排序的介绍如下:
1.将整数按数位切割,然后将数值统一为同样的数位长度,数位较短的数前面补0;
2.从最低位开始,依次进行依次排序;
3.从最低位排序一直到最高位排序完成以后,数列就变成一个有序序列。
请编写代码,完成排序,对给定数据进行升序排列。
输入描述:
第一行,数字N(2 <= N<=100),表示待排序的元素个数。
第二行,待排序的元素。
输出描述:
输出一行,为升序序列。
参考答案:
n = int(input())
li = list(map(int,input().split()))
max_len = len(str(max(li)))
for i in range(n):li[i] = str(li[i])li[i] = '0' * (max_len - len(li[i])) + li[i]
for i in range(max_len - 1,-1,-1):li.sort(key = lambda x:x[i])
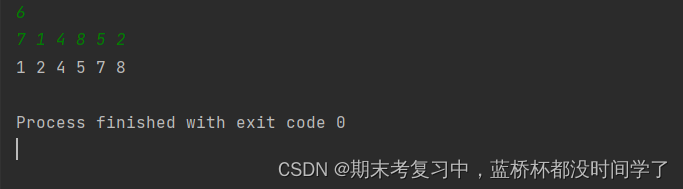
print(*list(map(int,li)))运行结果:
以下是我对此题的理解:
n = int(input()):从标准输入中读取一个整数n,表示待排序的元素个数
li = list(map(int,input().split()))
max_len = len(str(max(li))):计算列表li中最大元素的位数,将其转化为字符串再求长度,得到最大的位数,并赋值给变量max_len。
for i in range(n):变量li中的每个元素
li[i] = str(li[i]):将当前元素转换为字符串
li[i] = '0' * (max_len - len(li[i])) + li[i]:将当前元素的字符串表示补齐到最大位数,前面用0填充
接下来逆序遍历每一位
li.sort(key = lambda x:x[i]):使用列表的sort方法,根据当前位i进行排序
最后输出。
OK,这篇就写到这里,下一篇继续!