文章目录
- 前置
- 解决不确定性
- 场景1 Order By索引
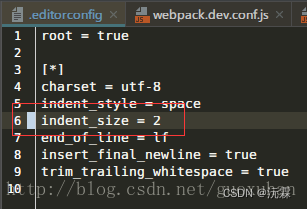
- 1.1 背景
- 1.2 不确定性产生原因
- 1.2.1 正常情况下
- 1.2.2 但是
- 1.3 补充
- 1.4 场景1总结
- 场景2 Order by id
- 2.1 背景
- 2.2 不会产生不确定性
- 原因1
- 原因2
- 2.3 推荐使用方式
- 场景3 filesort
- 3.1 背景
- 3.2 不确定性产生原因
- 3.3 内存排序和磁盘临时文件排序
- 3.4 若上述SQL filesort使用了内存排序
- 3.4.1 MySQL源码关于内存排序算法的选择
- 3.4.2 问题1:什么情况下会使用优先队列
- 3.4.3 问题2:如何快速判断是否使用了优先级队列
- 3.4.4 问题3:如何前置判断,本次查询是否会使用优先队列
- 3.4.5 问题4:我们写的sql是否会使用优先级队列
- 3.5 若上述SQL filesort使用到了磁盘临时文件排序
- 3.5.1 描述
- 3.5.2 磁盘临时文件排序不确定性产生原因
- 参考文档:
前置
MySQL 5.7官网给出了 order by limit一起使用,可能会产生不确定性:order by limit
不确定如图2.54

解决不确定性
order by limit一起使用时,order by后字段中需要有主键id或唯一键
场景1 Order By索引
1.1 背景
- user表联合索引为city_name、主键id
select * from user where city = 'shanghai' order by name limit 0,5
- user表联合索引city_name的叶子节点存储的数据如下
| city | name | id |
|---|---|---|
| beijing | zhang三 | 1 |
| shanghai | li四 | 20 |
| shanghai | li四 | 3 |
| shanghai | tian七 | 40 |
| shanghai | wang五 | 5 |
| shanghai | wang五 | 60 |
| shanghai | zhu八 | 7 |
| xuzhou | ma朋 | 80 |
| — | — | — |
1.2 不确定性产生原因
1.2.1 正常情况下
- explain此SQL,Extra不会显示filesort即不需要排序;
- 联合索引为city_name,所以数据在插入的时候就已经按照city_name排序好了;
- 上述SQL取数时,直接从联合索引中拿出排序好的数据,并返回即可,所以存的时候是什么样顺序,取的时候也一定是什么样的顺序,不会产生不确定性。
1.2.2 但是
1)情况1
- 假如两次查询期间发生了数据新增、删除、更新等操作,而且这些变更操作正好有city为shanghai的数据
- 就可能导致联合索引city_name数据页发生了变化(重排数据顺序,甚至分页)等
- 此时会导致查询的不确定性(漏查和重复查)
- eg:第一次查询limit 0,5结果id为: [20,3,40,5,60]
- 此时insert了一条数据(100,“shanghai”, “ma朋”)
- 联合索引就可能发生了变化,id=100的这条数据,会排在id=40的数据前面(city同为shanghai,ma朋排序先于tiant)
- 第二次查询limit0,5结果id集变为[20,3,100,40,5]
2)情况2
- 假如user表除了city_name索引还有city_address联合索引,则查询会产生不确定性原因;
- 两次查询可能会选择不同的联合索引,返回的数据自然不同。
1.3 补充
上述场景1和
先从db查询SQLselect *from t where city = 'shanghai' limit 0,5;
再Java程序中按照name排序返回
的这种查询方式区别:
- 假如每次查询都force index city_name联合索引,则和场景1查询没有任何区别;
- 本质都是使用city_name联合索引进行查询;
- 若还有其他city_address索引,则补充SQL每次执行时可能选择city_address也可能选择city_name
1.4 场景1总结
-
如果业务上可以保障查询期间不会有数据变更,并且每次查询都能使用相同的联合索引;
-
则场景1不会产生数据不确定性并
-
且下面两条SQL查询基本无区别代码块
SELECT * from user where city = 'shanghai' order by name limit 0,5; SELECT * from user where city = 'shanghai'limit 0,5;
场景2 Order by id
2.1 背景
-
user表联合索引为:city_name、主键id、
SELECT * from user where city ='shanghai' order by id limit 0,5;
2.2 不会产生不确定性
原因1
查询结果的展示顺序遵循以下描述
-
如果查询使用到了索引,则结果按照索引字段顺序展示;
-
如果查询没有使用到索引,则结果按照主键id顺序展示;
-
如果查询使用到了索引,又order by id,则结果按照逐渐id顺序展示。
所以场景2的查询,无论执行计划是什么样子的,查询结果总是按照主键id顺序展示,所以不会产生不确定性。
原因2
即使有数据新增、删除、更新,也不会产生不确定性
- 第一次查询limit 0,5,结果id为:[20,3,40,5,60];
- 此时insert了一条数据(100,“shanghai”,“ma朋”),联合索引就可能发生了变化,id=100的这条数据,会排在id=40的数据前面(city同为shanghai,ma朋排序先于tian七)
- 第二次查询limit 0,5结果id集仍为[20,3,40,5,60]
- 即使数据新增(100,‘shanghai’, ‘ma朋’),即使联合索引city_name需要调整数据顺序,但order by id,数据仍是按照主键id排序然后返回
2.3 推荐使用方式
相较于上述SQL,更推荐使用下述性能更好的书写方式
SELECT * from user where city = 'shanghai' order by name, id limit 0,5;
原因:场景2的书写方式,MySQL在执行时,可能直接按照主键id进行全表扫描,explain显示type = index、Extra = using where
场景3 filesort
3.1 背景
-
user表联合索引为:city_name、主键id
SELECT * from user where city = 'shanghai' order by address limit 0,5;
3.2 不确定性产生原因
- 上述SQL在执行时,会产生排序,即explain结果Extra中显示filesort;
- filesort可能为内存排序,也可能是磁盘临时文件排序;
- filesort时,如果查询出来的数据按照order by的字段(比如address),有相同的数据,且排序算法是不稳定性算法,则会产生不确定性。
详见MySQL5.7官方文档
- limit、order byOrder by limit一同使用时产生不确定性
3.3 内存排序和磁盘临时文件排序
| filesort | 内存排序 | 磁盘临时文件排序 |
|---|---|---|
| 触发条件 | 参与排序的数据大小<= sort_buffer_size | 参与排序的数据大小>sort_buffer_size |
| 使用到的排序算法 | 插入排序算法、快速排序、堆排序 | 多路归并排序算法 |
3.4 若上述SQL filesort使用了内存排序
| 内存排序算法 | 使用场景 | 是否为稳定性排序算法 | 是否会产生不确定性 |
|---|---|---|---|
| 插入排序 | 处理小数据集或近乎有序的数据集时,优先选择 | 是 | 否 |
| 堆排序 | 如果记录数量非常大,MySQL会优先选择堆排序 | 否 | 是 |
| 快速排序 | 或快排序 | 否 | 是 |
如果排序算法不是稳定性算法 并且 参与内存排序的数据按照order by字段有相同的数据时,则可能产生返回数据的不确定性
3.4.1 MySQL源码关于内存排序算法的选择
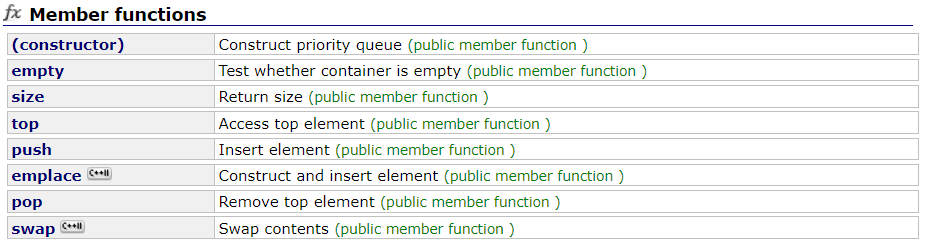
filesort.cc文件关于快速排序和堆排序(优先队列)的分析
3.4.2 问题1:什么情况下会使用优先队列
- 当order by的字段重复率特别高的时候,且带着limit查询,MySQL在满足某些条件下就会使用优先队列(PQ,priority queue)
- limit N -> 本质就是找TOP N->优先级队列->堆排序
- 优先级队列是一种优化技术,用于提高ORDER BY和LIMIT组合查询的性能,其查询结果是不确定性的
3.4.3 问题2:如何快速判断是否使用了优先级队列
- 查看执行计划结果(可以使用Sequel Pro客户端执行SQL)
SET optimizer_trace='enabled=on';
SELECT * FROM ratings ORDER BY category LIMIT 300,31;
SELECT * FROM `information_schema`.`OPTIMIZER_TRACE`;
SET optimizer_trace='enabled=off';
- 分析执行计划结果
"filesort_priority_queue_optimization":{"limit": 331, //limit m,n(m+n)"rows_estimate":992,// 即MySQL源码中max_rows < num_rows / PO_slowness中的num_rows,MySQL优化器对需要进行排序的行的数量所做的估计。优化器对需要进行排序的行的数量所做的估计,动态变化值影响因素有:可用内存、系统负载、查询复杂性、表的统计信息、 "row_size":13,//一行数据的大小 "memory_available": 8388608,//sort_buffer_szie =8m(默认1M) "chosen": false,//没有选择优先队列,为true则表示选择了PQ优先队列,没有cause原因 "cause":"quicksort_is_cheaper"//原因:快排性价比更高
}"filesort_summary":{ "rows": 60,// 排序过程中会持有的行数 "examined_rows": 60,//sql语句where条件count(*) "number_of_tmp_files": 0,//磁盘排序,使用的临时文件个数=0表示内存排序 "sort buffer size":20832,//使用内存排序时,使用到的内存大小
}
网上类似执行计划结果图如图2.55右图:使用了优先队列

chosen:true表示选择了优先级队列
3.4.4 问题3:如何前置判断,本次查询是否会使用优先队列
1)参考MySQL源码:MySQL Sever源码判断什么时候使用优先队列,简介:
- s首先确定排序逻辑所处代码文件:filesort.cc
- 然后在文件filesort.cc中搜索关键字:priority_queue
- 找到check_if_pq_applicable方法,此方法的返回结果表明排序过程中是否使用到了优先队列(堆排序),同时此方法内容也有判断什么时候使用堆排序,什么时候使用快排
注意:
为了便于理解,后续filesort.cc源码中字段的值,我直接一一对应为执行计划结果filesort_priority_queue_optimization中的字段值
2)源码分析
// memory_available: 本质是sort_buff_size,对应执行计划中memory_available字段,默认1M
// max_record_length():即单行数据的大小,对应执行计划中的row_size
// sizeof(char*):指针的大小=8字节
const ulong num_available_keys = memory_available / (param->max_record_length() + sizeof(char *));param->max_rows_per_buffer = (uint)param->max_rows +1;// 情况一:整个rows_estimate是否都可以放入内存中,即内存够用
// num_rows:对应执行计划中rows_estimate
if (num_rows < num_available_keys) {
// max_rows 就是limit中M+N,对应执行计划中limit值
// num_rows:对应执行计划中rows_estimate
// PQ_slowness = 3 if (param->max_rows < num_rows / PQ_slowness) { filesort_info->set_max_size(memory_available, param->max_record_length());trace_filesort.add("chosen",true);//选择PQreturn filesort_info->max_size_in_bytes()>0;//true表示排序操作将在内存中执行;false则可能表示排序操作将使用磁盘上的临时文件来辅助排序} else { // PO will be slower.不是优先级队列,直接使用快排 // 会一批一批的给sort buffer进行内存快速排序,结果放入排序临时文件,最终使对所有排好序的临时文件进行归并排序,得到最终的结果 trace_filesort.add("chosen", false).add_alnum("cause","sort_is_cheaper"); return false;
}//情况二:
// Do we have space for LIMIT rows in memory?
// 即使整个源数据集不适合内存排序,如果至少有足够的空间来存储查询限制的行数(M+N),代码将仍然选择使用PQ
if (param->max_rows_per_buffer < num_available_keys) {filesort_info->set_max_size(memory_available,param->max_record_length()); trace_filesort.add("chosen",true);return filesort_info->max_size_in_bytes()>0;
}
文字解释上述源码如下:
情况一:
1、内存够(我司默认sort_buffer_size=8M)即num_rows < num_available_keys即num_rows < sort_buffer_size /每行数据的size(执行计划结果中的filesort_priority_queue_optimization下的row_size)含义:内存8M、每行数据13bytes,指针大小8字节,总共可以放入x条数据,假如num_rows<x,则说明内存够!代入执行计划中的数值:992<8388608/ (13+8)2、max_rows < num_rows / PQ_slowness当满足1时,MySQL会对比优先级队列排序和快排序的开销,选择一个比较合适的排序算法快速排序算法效率高于堆排序,但是堆排序实现的优先级队列,无需排序完所有的元素,就可以得到order by limit的结果MySQL官方认为快速排序的速度是堆排序的3倍所以,在满足1、的情况下&&满足公式max_rows < num_rows / PQ_slowness时会使用优先队列即使用堆排堆排序时,MySQL会把sort buffer作为priority queue如果不满足公式则仍用快排序。代入执行计划中的数值:331<992/3,显然不满足,则chosen:false
满足1、且满足2、时,则情况一在内存中使用buffer_sort作为优先级队列进行堆排序。只满足1、则使用内存快排情况二:如果不满足场情况一中的1、则判断:Limit M+N < num_available_keys代入数值:331<8388608/ (13+8)如果满足,也可以使用buffer_sort作为PQ,在内存中进行堆排序
3.4.5 问题4:我们写的sql是否会使用优先级队列
select * from t where x order by xxx limit 200,200;
SET optimizer_trace='enabled=on';
select * from t where x order by xxx limit 200,200;
SELECT * FROM `information_schema`.`OPTIMIZER_TRACE`;
SET optimizer_trace='enabled=off';执行结果分析
"filesort_priority_queue_optimization":{"limit": 400,//limit m,n(m+n)"rows_estimate": 992, // 即max_rows < num_rows / P0_slowness中的num_rows (Estimate of number of rows in source record set即原表中预估计满足查询条件的行数)"row_size": 13,//一行数据的大小 "memory_available":8388608,//sort_buffer_szie =8m"chosen": false,//没有选择优先队列"cause": "quicksort_is_cheaper"//原因
}"filesort_summary":{"rows": 60,// 排序过程中会持有的行数 "examined_rows": 60,//参与排序的行数 "number_of_tmp_files": 0,//磁盘排序,使用的临时文件个数=0表示内存排序 "sort_buffer_size":20832,//使用内存排序时,使用到的内存大小 "sort_mode": "<sort_key,rowid>"//排序方式(rowid或者全字段排序)
}
.
根据执行计划结果,先判断3.5.3中情况一、再判断是否满足情况二
3.5 若上述SQL filesort使用到了磁盘临时文件排序
3.5.1 描述
- 当数据无法全部加载到内存排序时,会使用磁盘临时文件排序;
- 这个过程会将涉及到数据分割成多个“块”,如果每个“块”也需要进行排序,则可能会使用快速排序或堆排序来分割和重组数据;
- 然后在外部磁盘临时文件排序阶段使用归并排序,将多个已排序好的“块”合并成一个有序的块。
- 综上:“多路归并排序”(muli-way merge sort)的技术,是一种结合了快速排序维排序和归并排序特点的方法,即在内存排序阶段,它可能会使用快速排序或堆排序来分割和重组数据,然后在外部排序阶段使用归并排序来合并来自不同临时文件的数据
3.5.2 磁盘临时文件排序不确定性产生原因
即使最终合并多个“块”时使用到了稳定的排序算法归并排序,但每个“块”在排序阶段,可能使用到快排和堆排序,鉴于二者都是不稳定性排序算法,故不稳定原因同上3.5
参考文档:
什么情况下order by limit会使用优先队列
filesort_priority_queue_optimization



![[ai笔记12] chatGPT技术体系梳理+本质探寻](https://img-blog.csdnimg.cn/img_convert/cbf42387b2df0c76b16b4f7ac2416fa0.png)