re 是 Python 标准库中的一个模块,用于支持正则表达式操作。通过 re 模块,可以使用各种正则表达式来搜索、匹配和操作字符串数据。
使用 re 模块可以帮助在处理字符串时进行高效的搜索和替换操作,特别适用于需要处理文本数据的情况。
# 导入模块
import re一、方法
match 从开头匹配 返回match 或者None
r = re.match(r".\w{10}", "Hello_world hi world")
print(type(r), r,)
if r:print(r.group())
findmatch 从开始到位匹配 返回match 或者None
r = re.fullmatch(r"\da", "1a2b3c4d5e6f7g")
print(r)
search 匹配整个字符串 返回Match 或者None
# # search 匹配整个字符串 返回Match 或者None
r = re.search(r"\d", "1a2b3c4d5e6f7g")
print(r)
findall 找到所有 返回列表
r = re.findall(r"..", "he1\tll2o w5ol\nd")
print(type(r), r)
finditer 找到所有 返回迭代器 其中的每一个元素都是Match
# finditer 找到所有 返回迭代器 其中的每一个元素都是Match
r = re.finditer(r"\d\w", "1a2b3c4d5e6f7g")
print(r)
for e in r:print(e)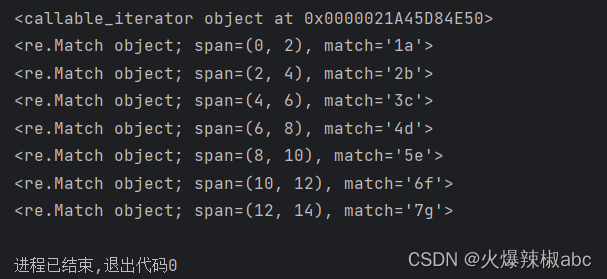
split 切割 返回列表
# # split 切割 返回列表
r = re.split(r"\d", "1a2b3c4d5e6f7g")
print(r)
sub 替换 返回字符串
# sub 替换 返回字符串
r = re.sub(r"\d", "+", "1a2b3c4d5e6f7g", 3)
print(r)
subn 替换 返回元组(新字符串, 替换个数)
# subn 替换 返回元组(新字符串, 替换个数)
r = re.subn(r"\d", "+", "1a2b3c4d5e6f7g")
print(r)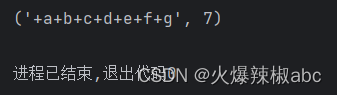
二、字符匹配
. 匹配任意字符
# . 匹配任意字符
r = re.findall(r"..", "he1\tll2o w5ol\nd")
print(type(r), r)
\d 匹配数字
# \d 匹配数字
r = re.findall(r"\d", "he1\tll2o w5ol\nd+1234/*-+595")
print(type(r), r)
\D 匹配非数字
# \D 匹配非数字
r = re.findall(r"\D", "he1\tll2o w5ol\nd+1234/*-+595")
print(type(r), r)
\w 字母数字下划线
# \w 字母数字下划线
r = re.findall(r"\w", "he1\tll2o w5ol\nd+1234/*-+595")
print(type(r), r)
\W 非字母数字下划线
# \W 非字母数字下划线
r = re.findall(r"\W", "he1\tll2o w5ol\nd+1234/*-+595")
print(type(r), r)
\s 空白字符 空格 制表符
# \s 空白字符 空格 制表符
r = re.findall(r"\s", "he1\tll2o w5ol\nd+1234/*-+595")
print(type(r), r)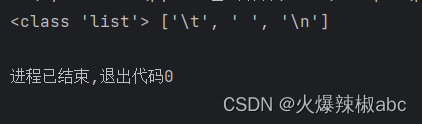
\S非空白字符
# \S非空白字符
r = re.findall(r"\S", "he1\tll2o w5ol\nd+1234/*-+595")
print(type(r), r)
三、重复
* 出现0-n次
# *出现0 - n次
r = re.findall(r"\d*", "123456")
print(r)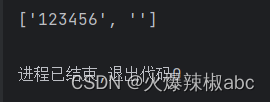
+ 有1-n次
# + 有1 - n次
r = re.findall(r"\d+", "123456")
print(r)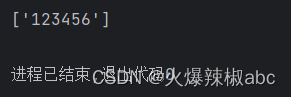
? 有0或1个
# ? 有0或1个
r = re.findall(r"\d?", "123456")
print(r)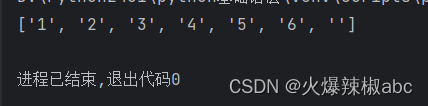
.*默认是贪婪模式(尽可能多匹配)
# .*默认是贪婪模式(尽可能多匹配)
r = re.findall(r".*", "123456")
print(r)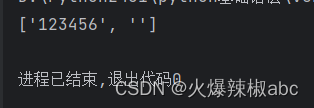
.*?是非贪婪模式(尽可能少匹配)
# .* ?是非贪婪模式(尽可能少匹配)
r = re.findall(r".*?", "123456")
print(r)
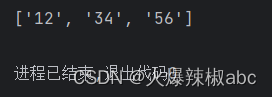
{n} 匹配n次
# {n}匹配n次
r = re.findall(r"\d{2}", "123456")
print(r)
{m,n} 匹配m-n次
# {m,n} 匹配m - n次
r = re.findall(r"\d{3,4}", "123456")
print(r)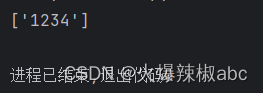
四、边界
^ 以开头
$ 以结尾
r = re.findall(r"^a.*?d$", "abcd$dd1a2b3c4d5abcd\n123456d\n123456")
print(r)
\b 匹配单词边界
\B 匹配非单词边界
r = re.findall(r".*?\b", "hello world hi python 123456")
print(r)
五、标识符
re.I 忽略大小写
re.M 多行模式: 如果有换行符+
r = re.match(r".\w{10}", "Hello_world hi world", re.I)
print(type(r), r,)
if r:print(r.group())
六、特殊字符
[abcdefg] 只能取一个
[^abcdefg] 不在abcdefg中间
[a-zA-Z0-9_] 所有数字字母下划线 相当于\w
()分组
\n取前面的分组匹配的内容
(|)
小练习:爬取百度贴吧中部分内容
from urllib import request
import reresult_datas = []
res = request.urlopen("https://tieba.baidu.com/t/f/?class=college")
res = res.read().decode()
result = re.findall(r'<a class="each_topic_entrance_item" href="//tieba.baidu.com/t/f/(\d+)" data-fid="\1">(.*?)</a>',res)
# print(result)
for school in result:# print(f"http://tieba.baidu.com/t/f/{school[0]}", school[1])res_school = request.urlopen(f"http://tieba.baidu.com/t/f/{school[0]}")res_school = res_school.read().decode()school_obj = {"name": school[1],"modules": []}modules = re.findall(r'<div class="module_item">(.*?)</ul></div>', res_school)# print(len(modules))for module in modules:module_name = re.findall(r'<p class="module_name">(.*?)</p>', module)[0]nums = re.findall(r'<div class="thread_item_left">(.*?)</div>', module)titles = re.findall(r'<a class="thread_title" href="//tieba.baidu.com/p/\d+">(.*?)</a>', module)contents = re.findall(r'<div class="thread_content thread_type_word.*?"><p>(.*?)</p><img src=.*?</div>', module)module_obj = {"name": module_name,"items": []}for i in range(len(nums)):module_obj["items"].append({"num": nums[i],"title": titles[i],"content": contents[i]})school_obj["modules"].append(module_obj)result_datas.append(school_obj)with open("result.json", "w", encoding="utf8") as f:json.dump(result_datas, ensure_ascii=False, fp=f)