日志分析系统ELK|Elasticsearch|kibana
- 日志分析系统ELK
- ELK概述
- Elasticsearch
- 安装Elasticsearch
- 部署Elasticsearch集群
- Elasticsearch插件
- 熟悉Elasticsearch的API调用
- _cat API
- 创建 tedu 索引使用 PUT 方式
- 增加数据
- 查询数据
- 修改数据
- 删除数据
- Kibana
- Kibana安装配置
- 导入日志并绘制图表
日志分析系统ELK
ELK概述
- Elasticsearch:负责日志检索和存储
- Logstash:负责日志的收集和分析、处理
- Kibana:负责日志的可视化
- ELK是一整套解决方案,是三个软件产品的首字母缩写,很多公司都在使用 如:Sina 携程 华为 美团等
- 这三款软件都是开源软件,通常是配合使用,而且又先后归于Elastic.co公司名下,故被简称为ELK
ELK组件在海量日志系统的运维中,可用于解决:
分布式日志数据集中查询和管理
系统监控,包含系统硬件和应用各个组件的监控
故障排查
安全信息和事件管理
报表功能



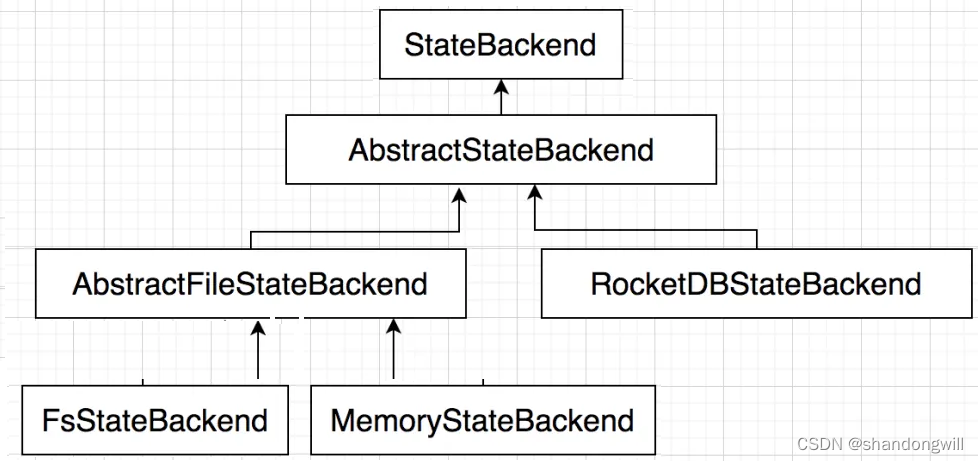
Elasticsearch
是一个基于Lucene的搜索服务器。它提供了一个分布式多用户能力的全文搜索引擎,基于RESTful API的web接口,其是用java开发的,使用apache许可条款的开源软件,是当前流程的企业级搜索引擎。设计用于云计算中,能够达到实时搜索,稳定,快速,可靠,安装使用方便。

安装Elasticsearch
最低配置: 2cpu,2G内存,20G硬盘

步骤一:先准备一台虚拟机
1.更改主机名,配置IP,搭建第三方yum源
# 在跳板机上把 elk 软件加入自定义 yum 仓库
[root@ecs-proxy ~]# cp -a elk /var/ftp/localrepo/elk
[root@ecs-proxy ~]# cd /var/ftp/localrepo/
[root@ecs-proxy localrepo]# createrepo --update .
2.安装elasticsearch
# 配置主机名解析
[root@es-0001 ~]# vim /etc/hosts
192.168.1.41 es-0001
[root@es-0001 ~]# yum makecache
[root@es-0001 ~]# yum install -y java-1.8.0-openjdk elasticsearch
[root@es-0001 ~]# vim /etc/elasticsearch/elasticsearch.yml
55: network.host: 0.0.0.0
# 设置开机自启
[root@es-0001 ~]# systemctl enable --now elasticsearch
[root@es-0001 ~]# curl http://192.168.1.41:9200/
{"name" : "War Eagle","cluster_name" : "elasticsearch","version" : {"number" : "2.3.4","build_hash" : "e455fd0c13dceca8dbbdbb1665d068ae55dabe3f","build_timestamp" : "2016-06-30T11:24:31Z","build_snapshot" : false,"lucene_version" : "5.5.0"},"tagline" : "You Know, for Search"
}
部署Elasticsearch集群
使用5台虚拟机组建 elasticsearch 集群
最低配置: 2cpu,2G内存,20G硬盘
虚拟机:
192.168.1.41 es-0001
192.168.1.42 es-0002
192.168.1.43 es-0003
192.168.1.44 es-0004
192.168.1.45 es-0005
1.更改hosts文件
[root@es-0001 ~]# vim /etc/hosts
192.168.1.41 es-0001
192.168.1.42 es-0002
192.168.1.43 es-0003
192.168.1.44 es-0004
192.168.1.45 es-0005
2.更改配置文件
[root@es-0001 ~]# yum install -y java-1.8.0-openjdk elasticsearch
[root@es-0001 ~]# vim /etc/elasticsearch/elasticsearch.yml
17: cluster.name: my-es # 集群名称
23: node.name: es-0001 # 本机主机名
55: network.host: 0.0.0.0
68: discovery.zen.ping.unicast.hosts: ["es-0001", "es-0002"] # 介绍人
[root@es-0001 ~]# systemctl enable --now elasticsearch
[root@es-0001 ~]# curl http://192.168.1.41:9200/_cluster/health?pretty
{"cluster_name" : "my-es","status" : "green","timed_out" : false,"number_of_nodes" : 5,"number_of_data_nodes" : 5,... ...
}
3) 其他机器(1.42-1.45)一样操作,安装elasticsearch和java-1.8.0-openjdk,同步配置文件在步骤一已经安装了一台elasticsearch,这里只需再准备四台即可
4)访问测试,如图-1所示:
可以访问任意一台主机, 集群的节点都是5台,ES 集群验证:返回字段解析:
”status”: ”green“ 集群状态:绿色为正常、黄色表示有问题但不是很严重、红色表示严重故障
”number_of_nodes”: 5, 表示集群中节点的数量


Elasticsearch插件
- head插件
它展示ES集群的拓扑结构,并且可以通过它来进行索引和节点级别的操作,他提供一组针对集群的查询API,并将结果以json和表格的形式返回,它提供一些快捷菜单,用以展现集群的各种状态。


使用 head插件访问集群
购买云主机: 1cpu,1G内存,20G硬盘,并安装 apache
虚拟机:
192.168.1.48 web
安装 apache,并把 apache 和 es-0001 服务发布到互联网上
安装 apache
[root@web ~]# yum install -y httpd
[root@web ~]# tar zxf head.tar.gz
[root@web ~]# mv elasticsearch-head /var/www/html/head
[root@web ~]# systemctl enable --now httpd
Created symlink from /etc/systemd/system/multi-user.target.wants/httpd.service to /usr/lib/systemd/system/httpd.service.
2)授权访问head插件访问 es-0001
[root@es-0001 ~]# vim /etc/elasticsearch/elasticsearch.yml
# 配置文件最后追加
http.cors.enabled : true
http.cors.allow-origin : "*"
http.cors.allow-methods : OPTIONS, HEAD, GET, POST, PUT, DELETE
http.cors.allow-headers : X-Requested-With,X-Auth-Token,Content-Type,Content-Length
[root@es-0001 ~]# systemctl restart elasticsearch.service

五角星 是master 主节点 是程序内部自己选的
熟悉Elasticsearch的API调用


在Linux中curl 是一个利用URL规则在命令行下工作的文件传输工具,可以说是一款很强大的http命令行工具。它支持多种请求模式,自定义请求头等强大功能,是一款综合工具。
使用格式:curl -X 请求方法 http://请求地址
curl -H 自定义请求头 http://请求地址
_cat API
_cat 关键字用来查询集群状态,节点信息等
显示详细信息(?v),显示帮助信息(?help)
例如查询集群中的master是谁
[root@localhost~]# curl -XGET http://es-0001:9200/_cat/master?v

创建 tedu 索引使用 PUT 方式
[root@es-0005 bin]# curl -XPUT -H "Content-Type: application/json" 'http://es-0001:9200/tedu' -d '{"settings":{"index":{"number_of_shards": 5, "number_of_replicas": 1}}
}'
{"acknowledged":true}
增加数据
[root@es-0005 bin]# curl –XPUT -H "Content-Type: application/json" 'http://es-0001:9200/tedu/teacher/1' -d \
> '{
> "职业": "诗人",
> "名字": "李白",
> "称号": "诗仙",
> "年代": "唐"
> }'
{"_index":"tedu","_type":"teacher","_id":"1","_version":1,"_shards":{"total":2,"successful":2,"failed":0},"created":true}
查询数据
[root@es-0005 bin]# curl -XGET http://es-0001:9200/tedu/teacher/1?pretty
{"_index" : "tedu","_type" : "teacher","_id" : "1","_version" : 1,"found" : true,"_source" : {"职业" : "诗人","名字" : "李白","称号" : "诗仙","年代" : "唐"}
}
修改数据
[root@es-0005 bin]# curl -XPOST -H "Content-Type: application/json" http://es-0001:9200/tedu/teacher/1/_update -d \
> '{
> "doc": {
> "年代": "公元701"
> }
> }'
{"_index":"tedu","_type":"teacher","_id":"1","_version":2,"_shards":{"total":2,"successful":2,"failed":0}}
删除数据
注:删除时候可以是文档,也可以是索引,但不能是类型
[root@es-0005 bin]# curl –XDELETE -H "Content-Type: application/json" http://es-0001:9200/tedu/teacher/1
{"found":true,"_index":"tedu","_type":"teacher","_id":"1","_version":3,"_shards":{"total":2,"successful":2,"failed":0}}
[root@es-0005 bin]# curl -XDELETE -H "Content-Type: application/json" http://es-0001:9200/tedu
{"acknowledged":true}
Kibana
kibana 是数据可视化平台工具
特点:
- 灵活的分析和可视化平台
- 实时总结流量和数据的图标
- 为不同的用户显示直观的界面
- 即时分享和嵌入的仪表板
Kibana安装配置
创建虚拟机并安装 kibana
最低配置: 1cpu,1G内存,10G硬盘
虚拟机IP: 192.168.1.46 kibana
步骤一:安装kibana
1)在另一台主机,配置ip为192.168.1.46,配置yum源,更改主机名
更改hosts文件
[root@kibana ~]# vim /etc/hosts
192.168.1.41 es-0001
192.168.1.42 es-0002
192.168.1.43 es-0003
192.168.1.44 es-0004
192.168.1.45 es-0005
192.168.1.46 kibana
[root@kibana ~]# yum -y install kibana
2)更改配置文件
[root@kibana ~]# vim /etc/kibana/kibana.yml
02 server.port: 5601
07 server.host: "0.0.0.0"
28 elasticsearch.hosts: ["http://es-0002:9200", "http://es-0003:9200"]
37 kibana.index: ".kibana"
40 kibana.defaultAppId: "home"
113 i18n.locale: "zh-CN"
[root@kibana ~]# systemctl enable --now kibana
web 页面访问
Firefox http://192.168.1.46:5601

导入日志并绘制图表
- 数据导入条件:必须指定 json格式 Content-Type:application/json
- 导入关键字:_bulk
- HTTP方法:POST
- url编码格式:data-binary
导入数据
[root@localhost ~]# scp /var/ftp/localrepo/elk/*.gz root@192.168.1.46:/root/
[root@kibana ~]# gzip -d logs.jsonl.gz
[root@kibana ~]# curl -XPOST -H "Content-Type: application/json" http://es-0001:9200/_bulk --data-binary @logs.jsonl




注意: 这里没有数据的原因是导入日志的时间段不对,默认配置是最近15分钟,在这可以修改一下时间来显示
kibana修改时间,选择Lsat 15 miuntes


除了柱状图,Kibana还支持很多种展示方式