提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
文章目录
- 1.xxl-job
- 1. 1 发展历史
- 1.2 XXL-JOB的系统架构
- 1.3 xxl-job与其他框架对比
- 2. XXL-JOB的使用
- 2.1 准备工作- 配置调度中心
- XXL-JOB的数据表
- 2.2 配置执行器
- 1 引入依赖包:
- 2 配置配置项
- 3 创建XxlJobConfig.java
- 2.3 配置可视化界面
- 1. 配置数据库路径以及其他信息
- 2. 配置登陆账号密码
- 3. 启动项目:XxlJobAdminApplication.java
- 4. 登陆可视化界面 地址: http://10.4.7.214:8080/xxl-job-admin/jobinfo
- 2.4 开发第一个任务 Hello,world
- 1.首先在配置好了执行器的微服务下创建定时任务代码:
- 2.依次启动微服务项目(Eureka,config…等)
- 3.启动调度中心: XxlJobAdminApplication.java
- 4.登录调度中心,输入账号密码,然后配置执行器
- 5.进入==任务管理==页面
- 6.点击新增任务,配置对应相关参数
- 7.返回任务管理页面
- 8.如果点击执行任务,则会只执行一次
- 9.如果点击日志,则跳转至调度日志页面
- 10.如果点击启动,则直接==启动定时任务(按照Corn表达式定时执行任务==),并且启动按钮会变成停止按钮
- 11.如果点击编辑,则进入定时任务的更新页面
- 2.5 运行报表
1.xxl-job
- XXL-JOB是一个分布式任务调度平台,其核心设计目标是开发迅速、学习简单、轻量级、易扩展。现已开放源代码并接入多家公司线上产品线,开箱即用。
1. 1 发展历史

源码地址: https://github.com/xuxueli/xxl-job
中文文档:https://www.xuxueli.com/xxl-job/
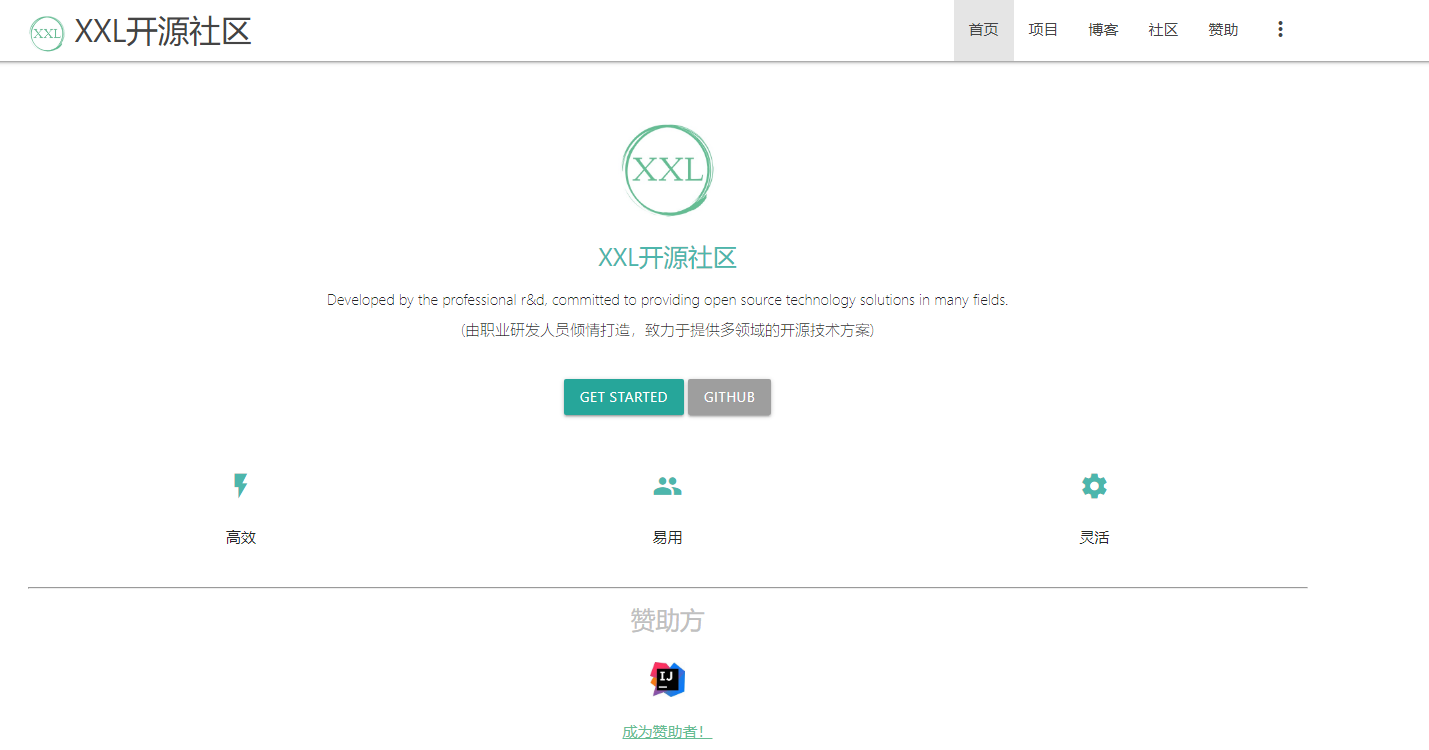
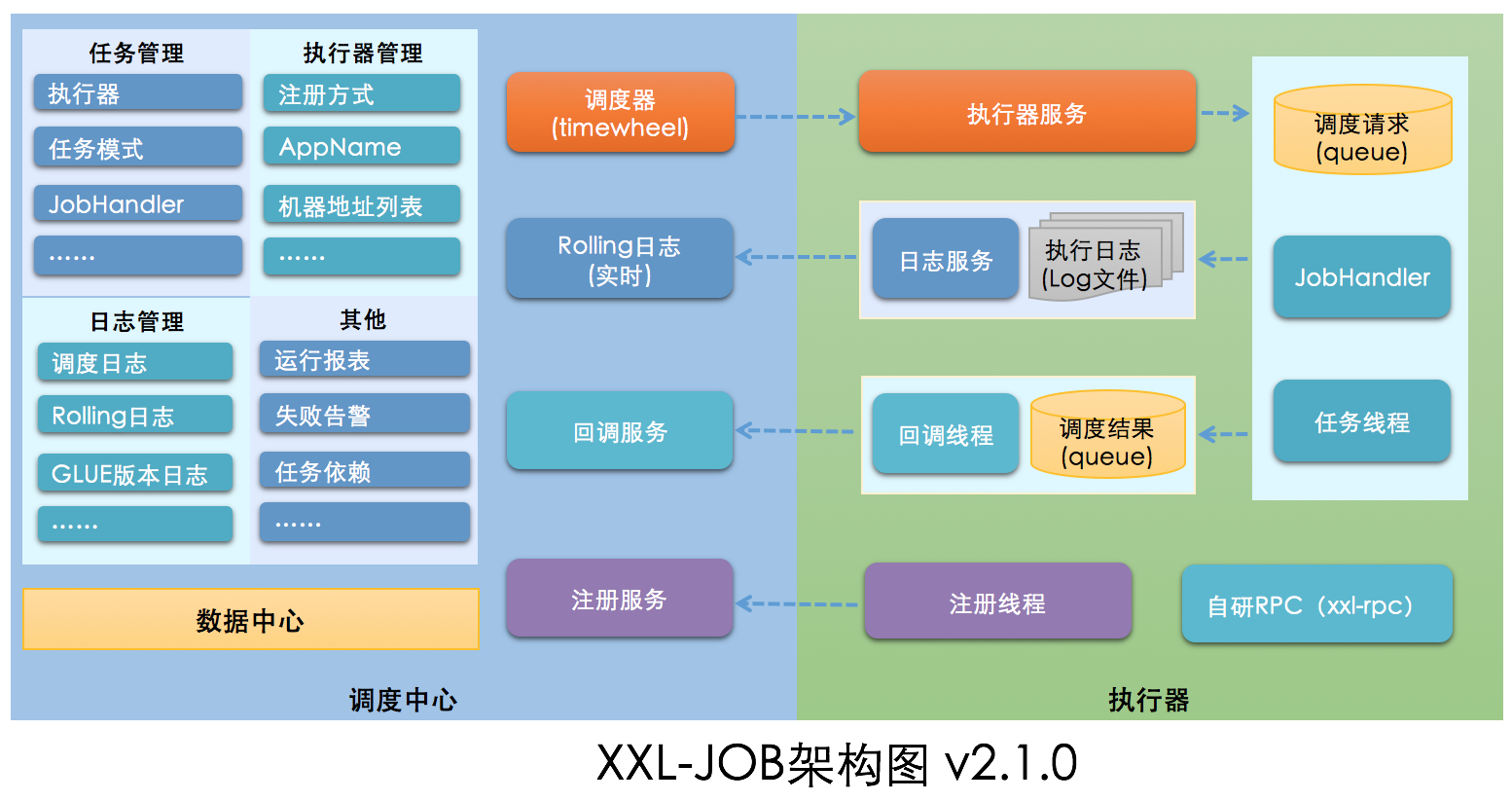
1.2 XXL-JOB的系统架构
- xxl-job框架主要用于处理分布式的定时任务,其主要由调度中心和执行器组成。
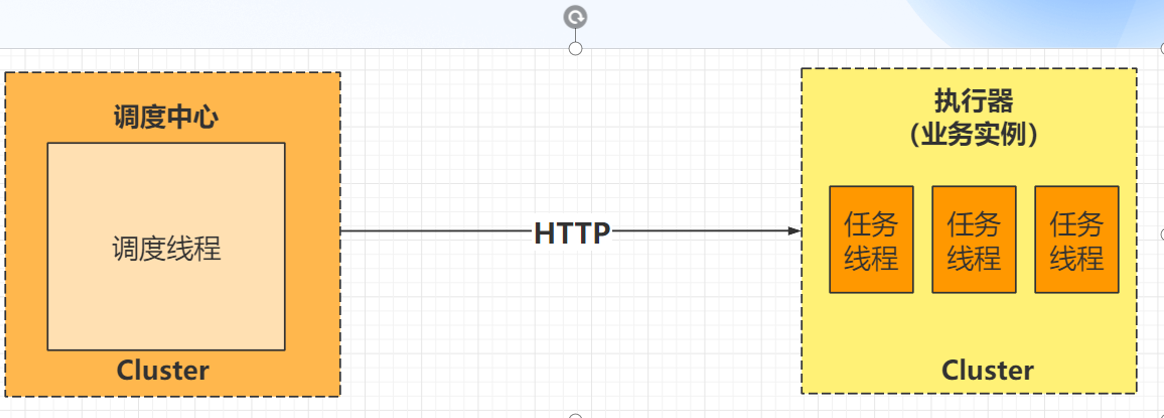
调度模块(调度中心):
- 负责管理调度信息,按照调度配置发出调度请求,自身不承担业务代码。调度系统与任务解耦,提高了系统可用性和稳定性,同时调度系统性能不再受限于任务模块;
- 支持可视化、简单且动态的管理调度信息,包括任务新建,更新,删除,GLUE开发和任务报警等,所有上述操作都会实时生效,同时支持监控调度结果以及执行日志,支持执行器Failover。
执行模块(执行器):
- 负责接收调度请求并执行任务逻辑。任务模块专注于任务的执行等操作,开发和维护更加简单和高效;
- 接收“调度中心”的执行请求、终止请求和日志请求等。
调度中心和执行器两个模块分开部署,相互分离,两者之间通过RPC进行通信,其中调度中心主要是提供一个平台,管理调度信息,发送调度请求,自己不承担业务代码,而执行器接受调度中心的调度执行业务逻辑。
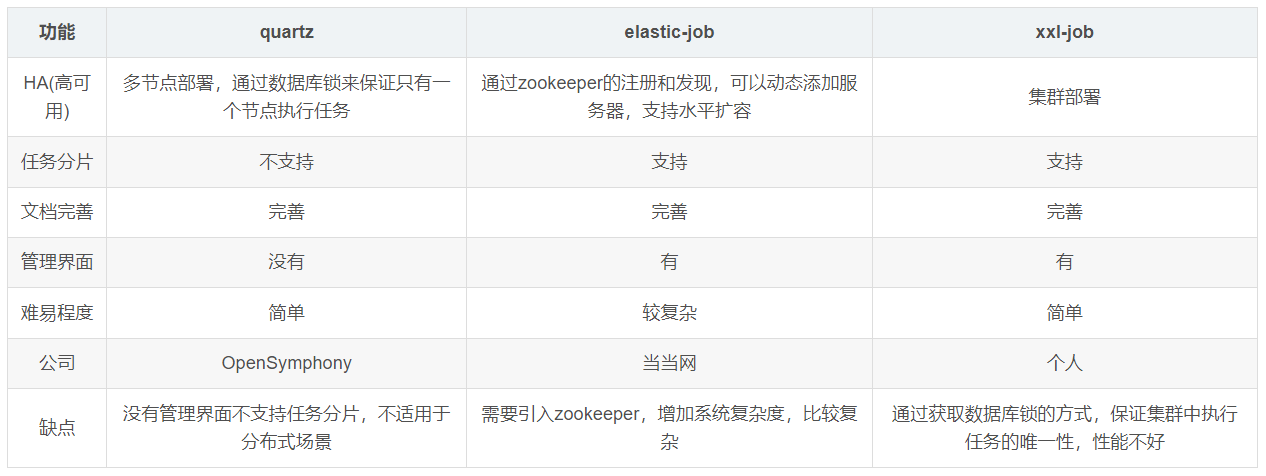
1.3 xxl-job与其他框架对比
分布式定时任务调度的框架:quartz、elastic-job、xxl-job

2. XXL-JOB的使用
2.1 准备工作- 配置调度中心
下载官方源码
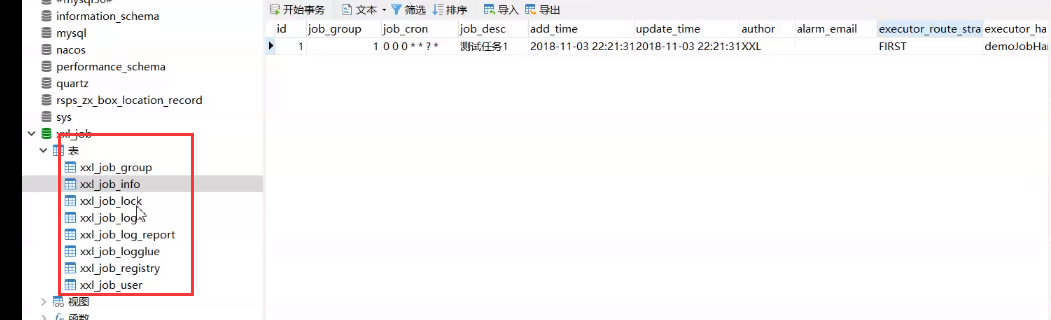
- 将项目中 /xxl-job/doc/db/ 目录下的 tables_xxl_job.sql 的数据库表导入数据库
XXL-JOB的数据表
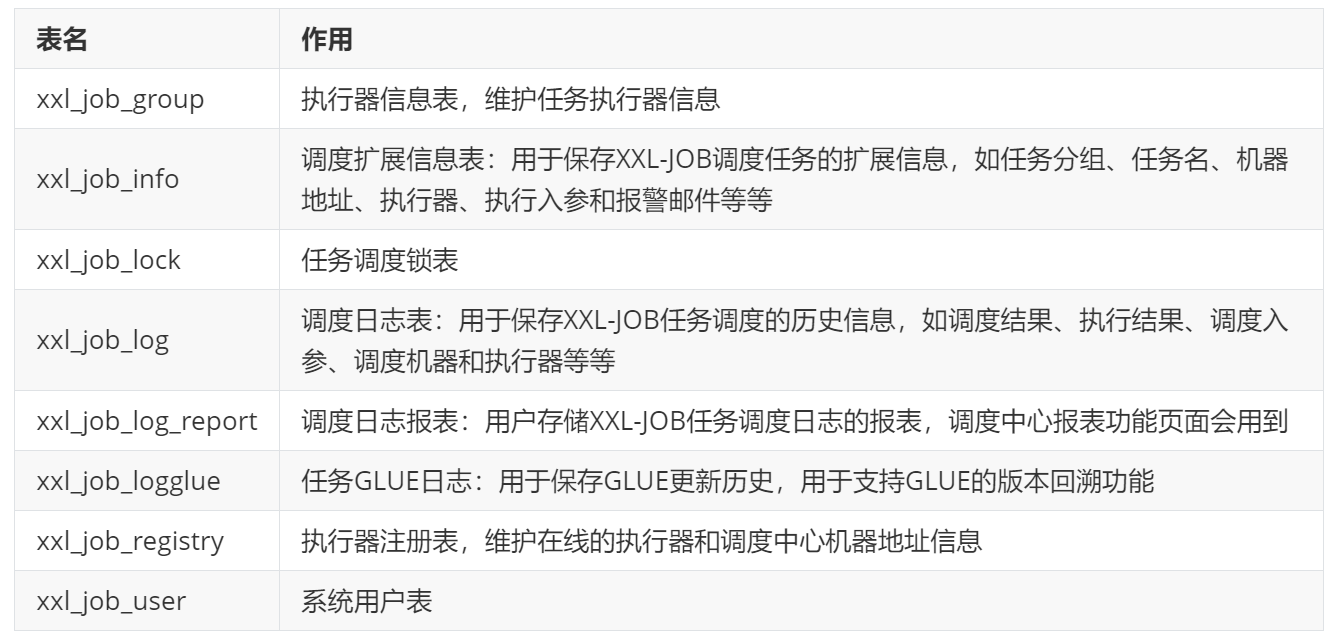
2.2 配置执行器
1 引入依赖包:
<!-- xxl-job-core --><dependency><groupId>com.cdmtc</groupId><artifactId>xxl-job-core</artifactId><version>2.0.2</version></dependency>2 配置配置项
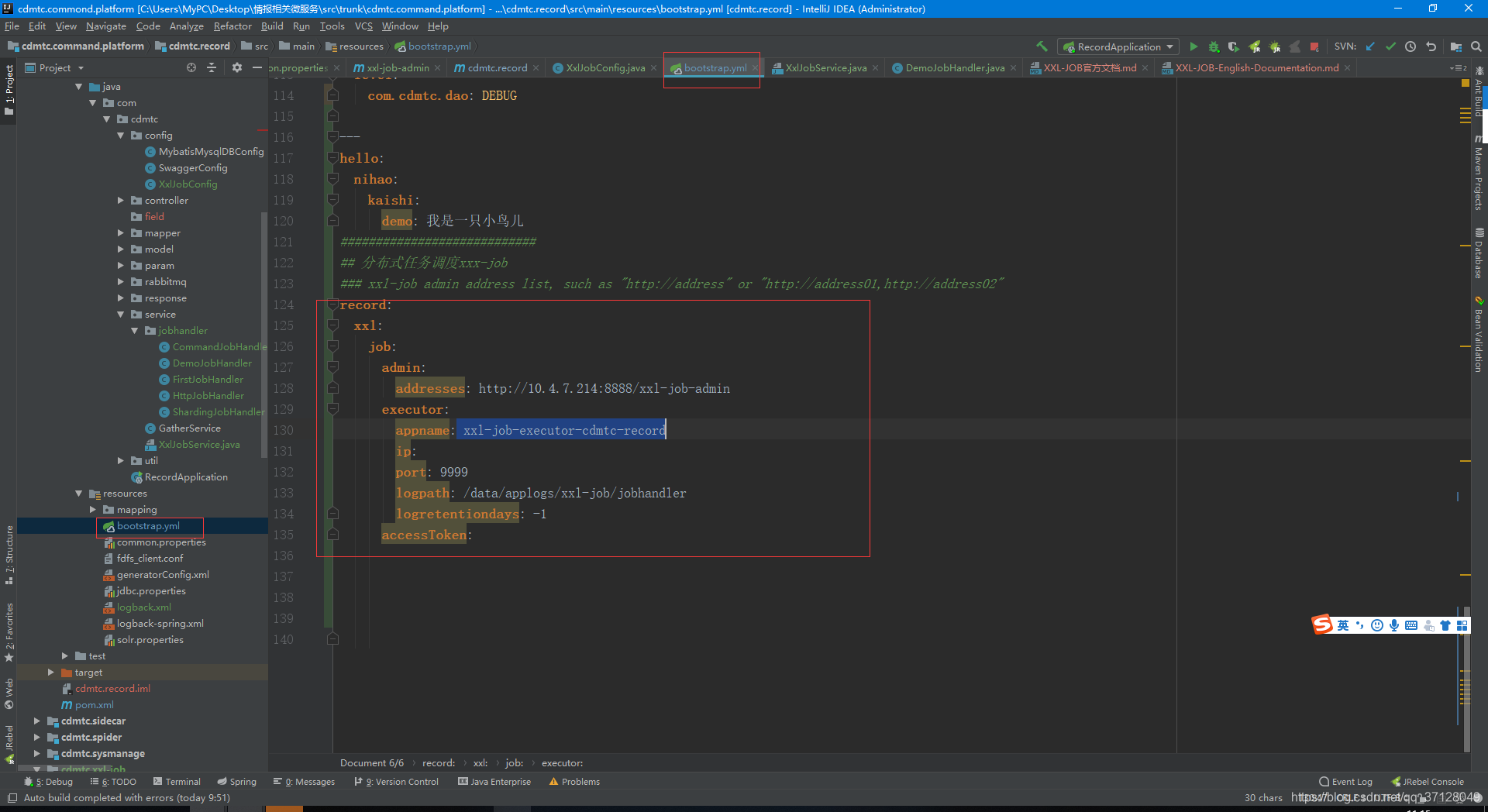
XXL-JOB执行器的相关配置项的意义,如下所示:
-
xxl.job.admin.addresses
调度中心的部署地址。若调度中心采用集群部署,存在多个地址,则用逗号分隔。执行器将会使用该地址进行”执行器心跳注册”和”任务结果回调”。 -
xxl.job.executor.appname
执行器的应用名称,它是执行器心跳注册的分组依据。 -
xxl.job.executor.ip
执行器的IP地址,用于”调度中心请求并触发任务”和”执行器注册”。执行器IP默认为空,表示自动获取IP。多网卡时可手动设置指定IP,手动设置IP时将会绑定Host。 -
xxl.job.executor.port
执行器的端口号,默认值为9999。单机部署多个执行器时,注意要配置不同的执行器端口。 -
xxl.job.accessToken
执行器的通信令牌,非空时启用。 -
xxl.job.executor.logpath
执行器输出的日志文件的存储路径,需要拥有该路径的读写权限。 -
xxl.job.executor.logretentiondays
执行器日志文件的定期清理功能,指定日志保存天数,日志文件过期自动删除。限制至少保存3天,否则功能不生效。
3 创建XxlJobConfig.java
package com.cdmtc.config;import com.xxl.job.core.executor.impl.XxlJobSpringExecutor;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;/*** xxl-job config** @author xuxueli 2017-04-28*/
@Configuration
public class XxlJobConfig {private Logger logger = LoggerFactory.getLogger(XxlJobConfig.class);@Value("${record.xxl.job.admin.addresses}")private String adminAddresses;@Value("${record.xxl.job.executor.appname}")private String appName;@Value("${record.xxl.job.executor.ip}")private String ip;@Value("${record.xxl.job.executor.port}")private int port;@Value("${record.xxl.job.accessToken}")private String accessToken;@Value("${record.xxl.job.executor.logpath}")private String logPath;@Value("${record.xxl.job.executor.logretentiondays}")private int logRetentionDays;@Bean(initMethod = "start", destroyMethod = "destroy")public XxlJobSpringExecutor xxlJobExecutor() {logger.info(">>>>>>>>>>> xxl-job config init.");XxlJobSpringExecutor xxlJobSpringExecutor = new XxlJobSpringExecutor();xxlJobSpringExecutor.setAdminAddresses(adminAddresses);xxlJobSpringExecutor.setAppName(appName);xxlJobSpringExecutor.setIp(ip);xxlJobSpringExecutor.setPort(port);xxlJobSpringExecutor.setAccessToken(accessToken);xxlJobSpringExecutor.setLogPath(logPath);xxlJobSpringExecutor.setLogRetentionDays(logRetentionDays);return xxlJobSpringExecutor;}/*** 针对多网卡、容器内部署等情况,可借助 "spring-cloud-commons" 提供的 "InetUtils" 组件灵活定制注册IP;** 1、引入依赖:* <dependency>* <groupId>org.springframework.cloud</groupId>* <artifactId>spring-cloud-commons</artifactId>* <version>${version}</version>* </dependency>** 2、配置文件,或者容器启动变量* spring.cloud.inetutils.preferred-networks: 'xxx.xxx.xxx.'** 3、获取IP* String ip_ = inetUtils.findFirstNonLoopbackHostInfo().getIpAddress();*/}XxlJobConfig配置类有两点需要注意:
- 组件扫描
第2行使用@ComponentScan注解,扫描com.example.demo.jobhandler包,将其中的任务处理器加载至Spring容器。 - 获取执行器实例
第29行的xxlJobExecutor()方法会实例化一个XXL-JOB执行器对象,执行器初始化时调用它的start()方法
2.3 配置可视化界面
1. 配置数据库路径以及其他信息
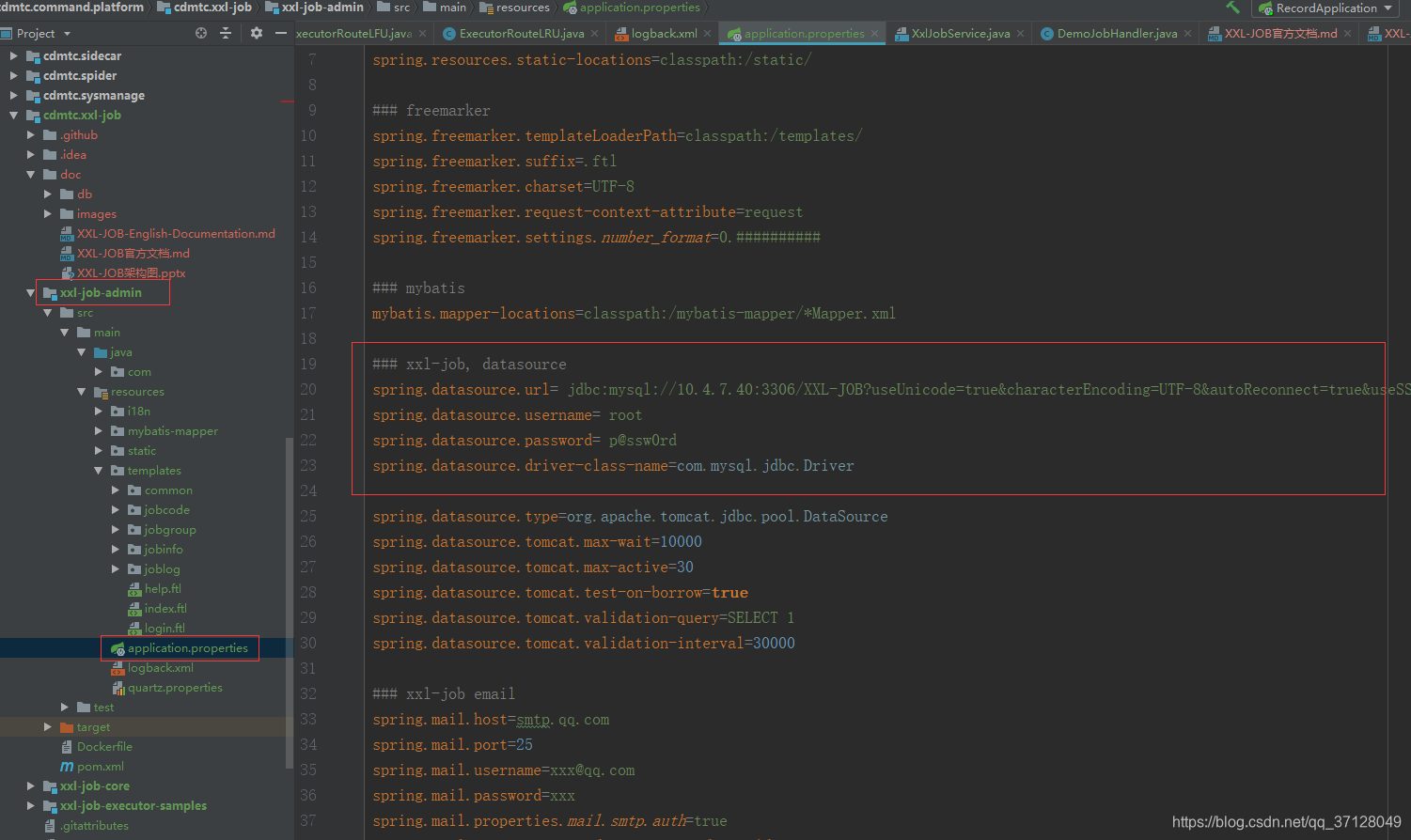
2. 配置登陆账号密码
- 可修改为其他账号密码
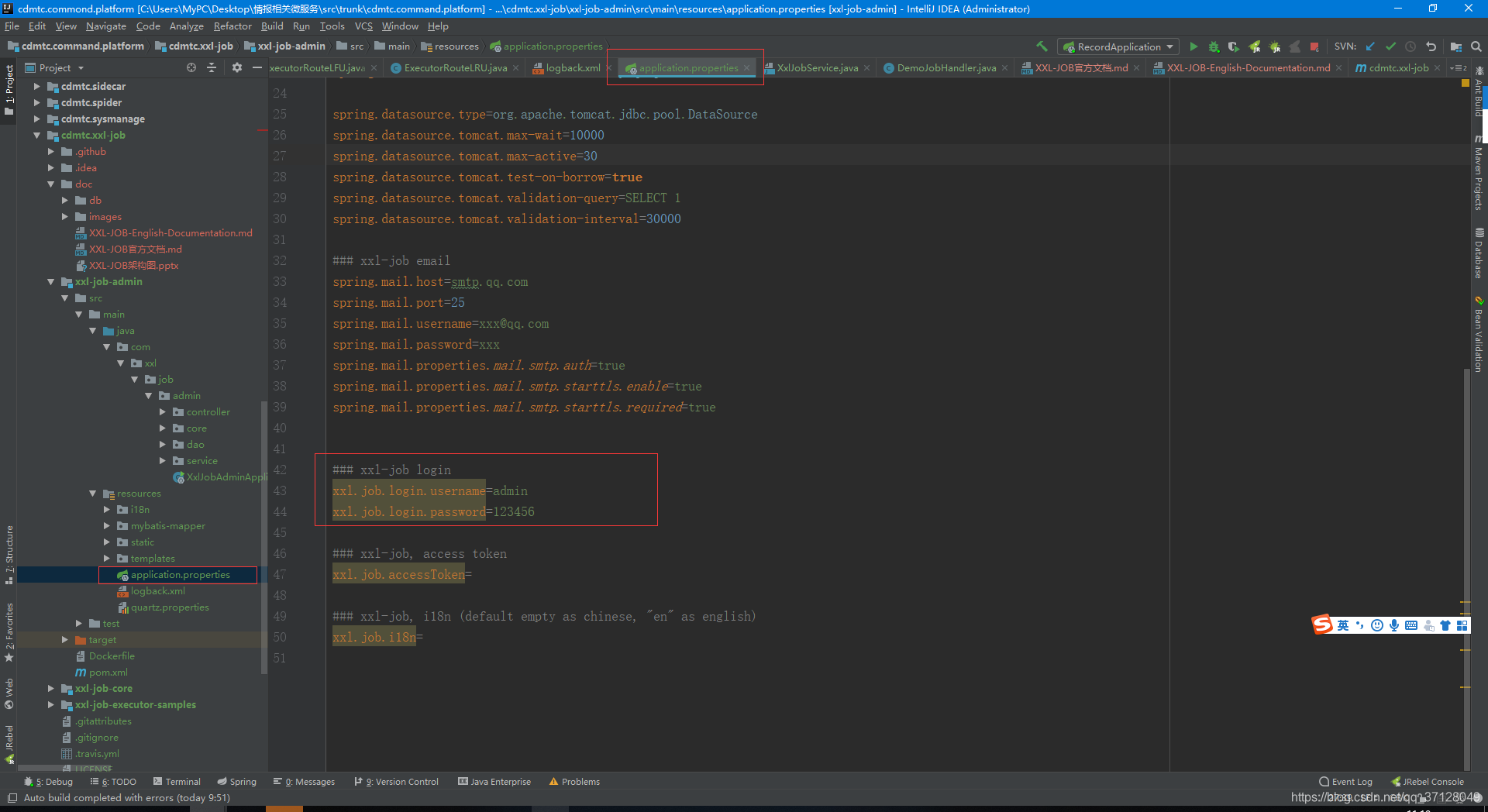
3. 启动项目:XxlJobAdminApplication.java
4. 登陆可视化界面 地址: http://10.4.7.214:8080/xxl-job-admin/jobinfo
- 【可先等配置好了执行器再进行登陆,端口可自行配置或修改,默认是8080,这里演示的端口号为8888】
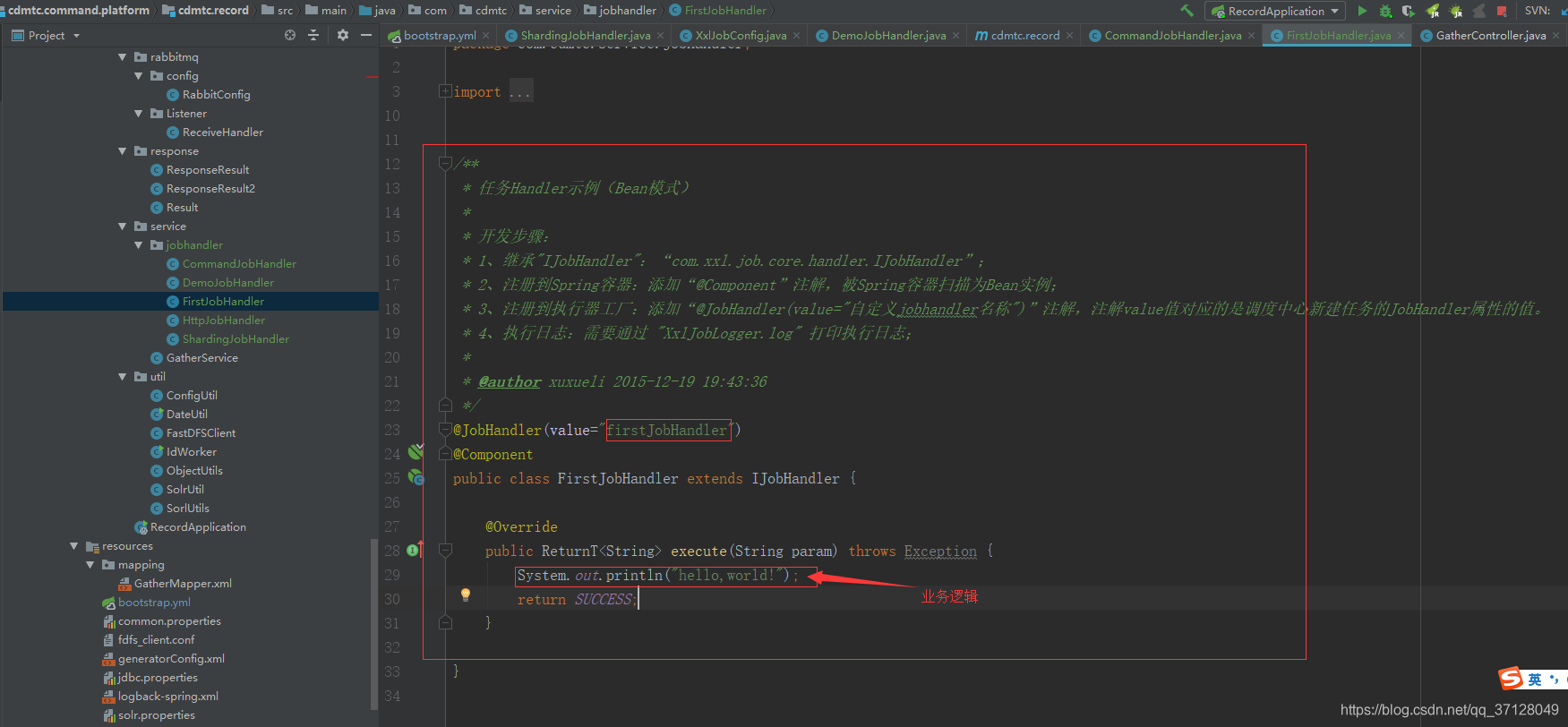
2.4 开发第一个任务 Hello,world
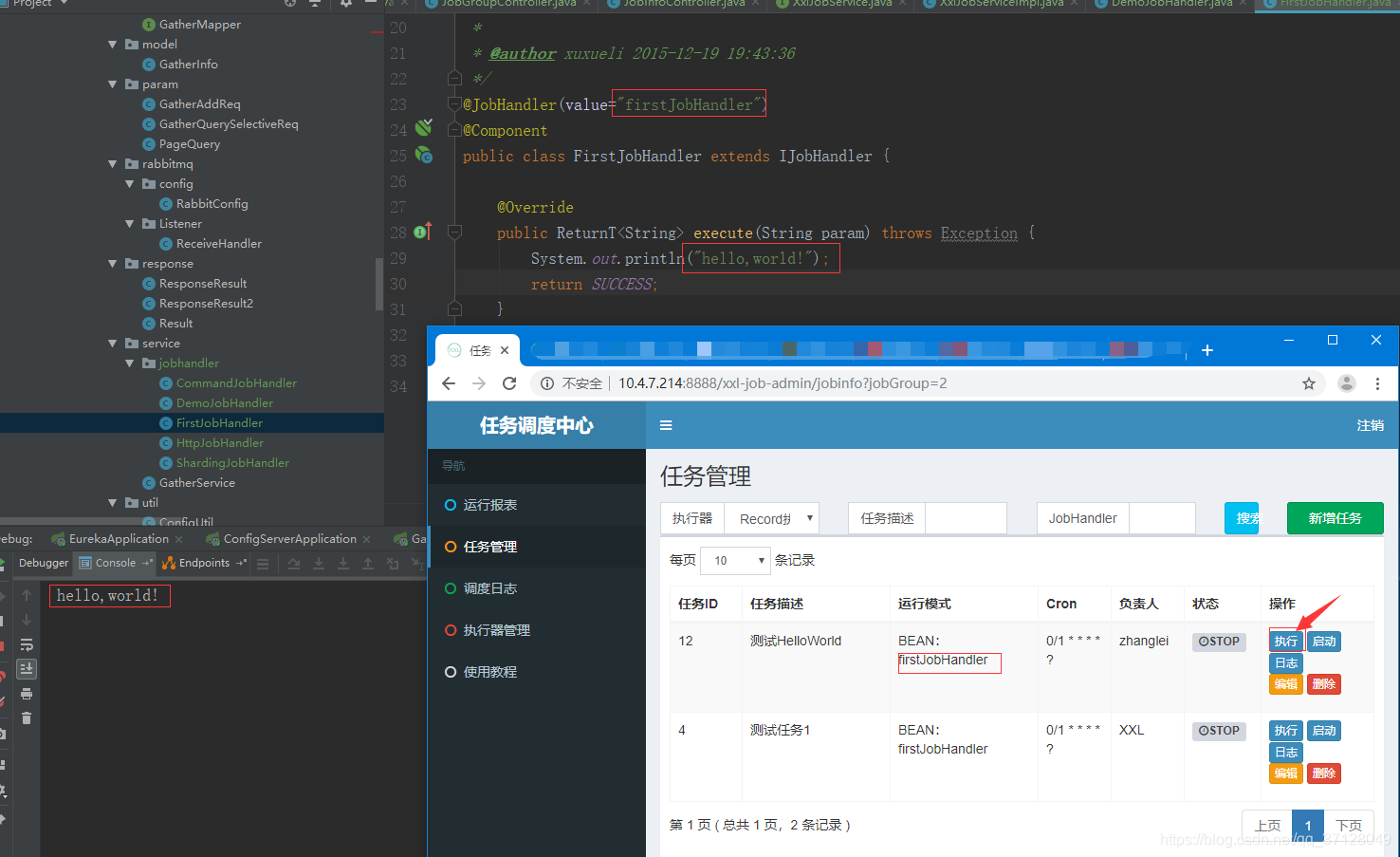
1.首先在配置好了执行器的微服务下创建定时任务代码:
2.依次启动微服务项目(Eureka,config…等)
3.启动调度中心: XxlJobAdminApplication.java
4.登录调度中心,输入账号密码,然后配置执行器
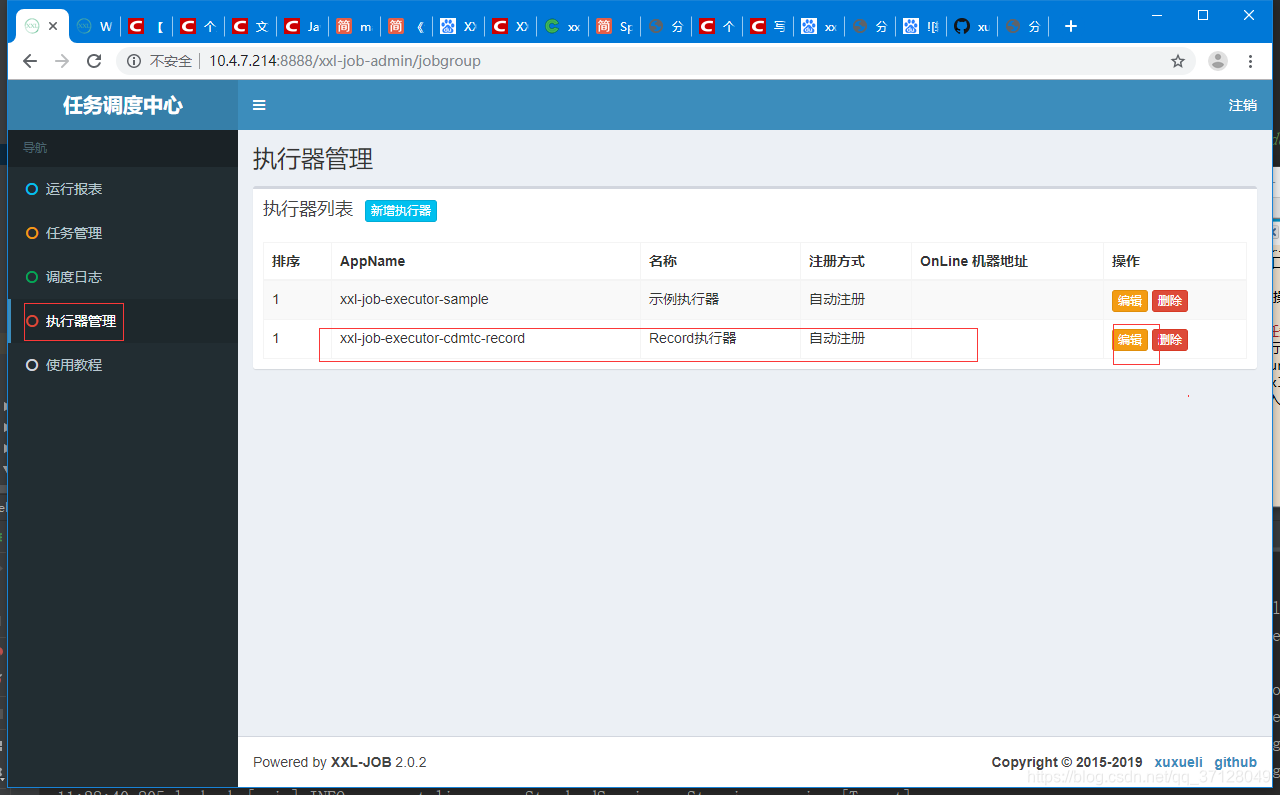
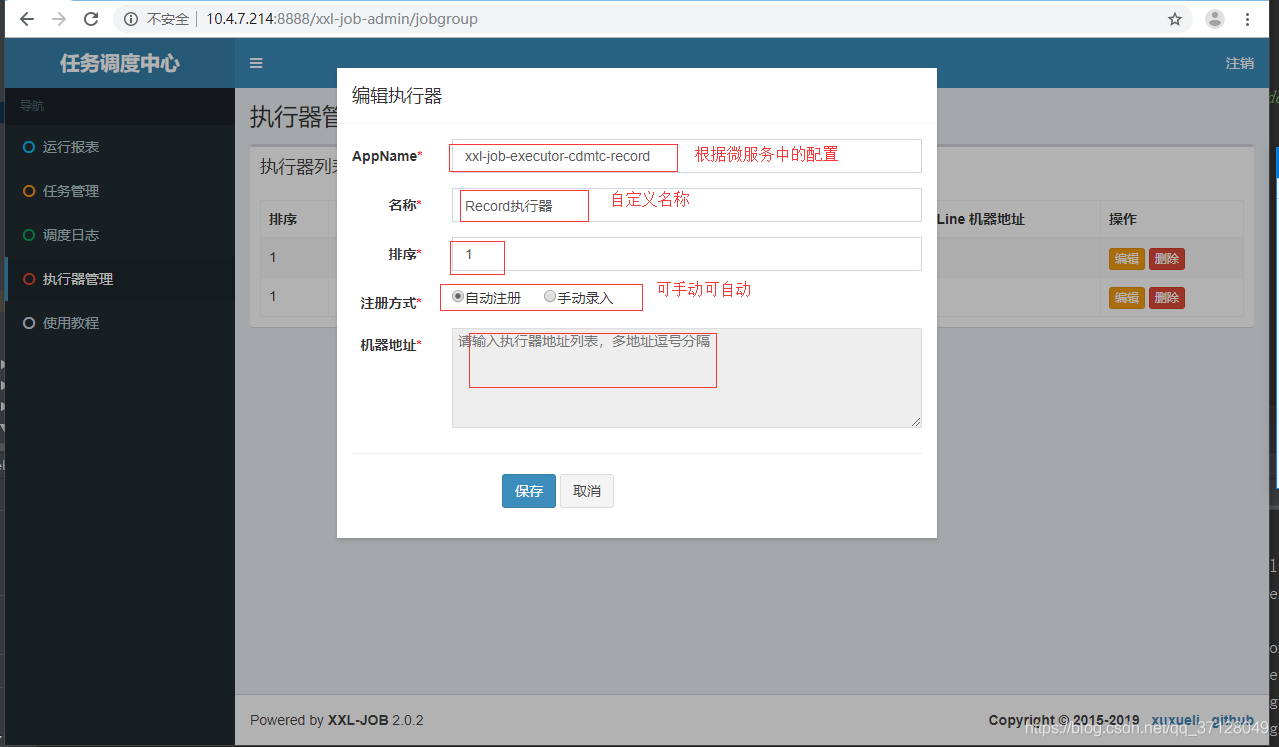
5.进入任务管理页面
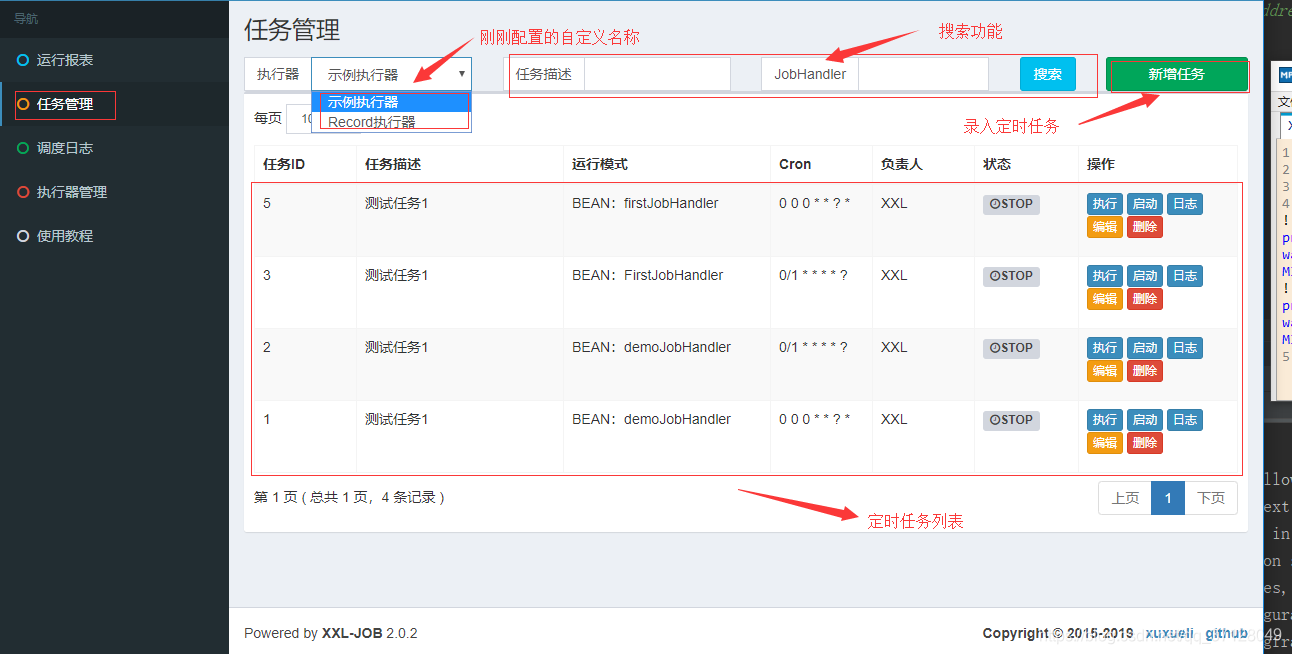
6.点击新增任务,配置对应相关参数
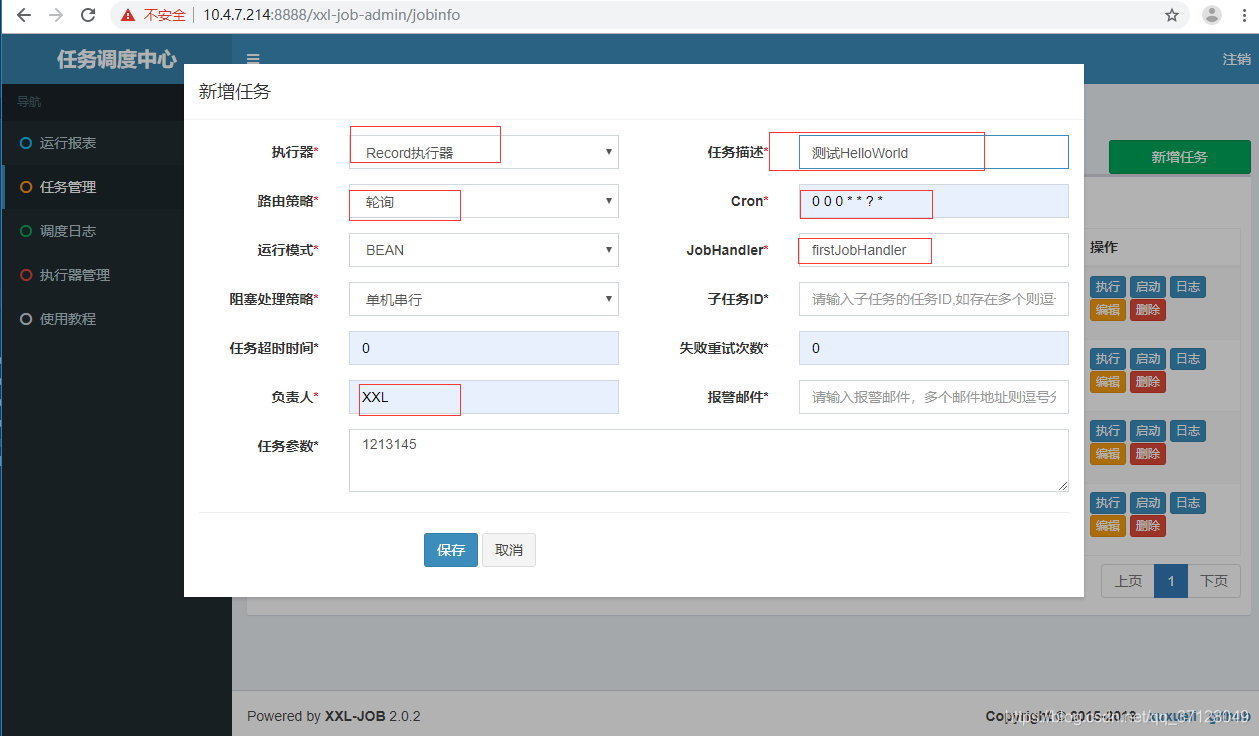
7.返回任务管理页面
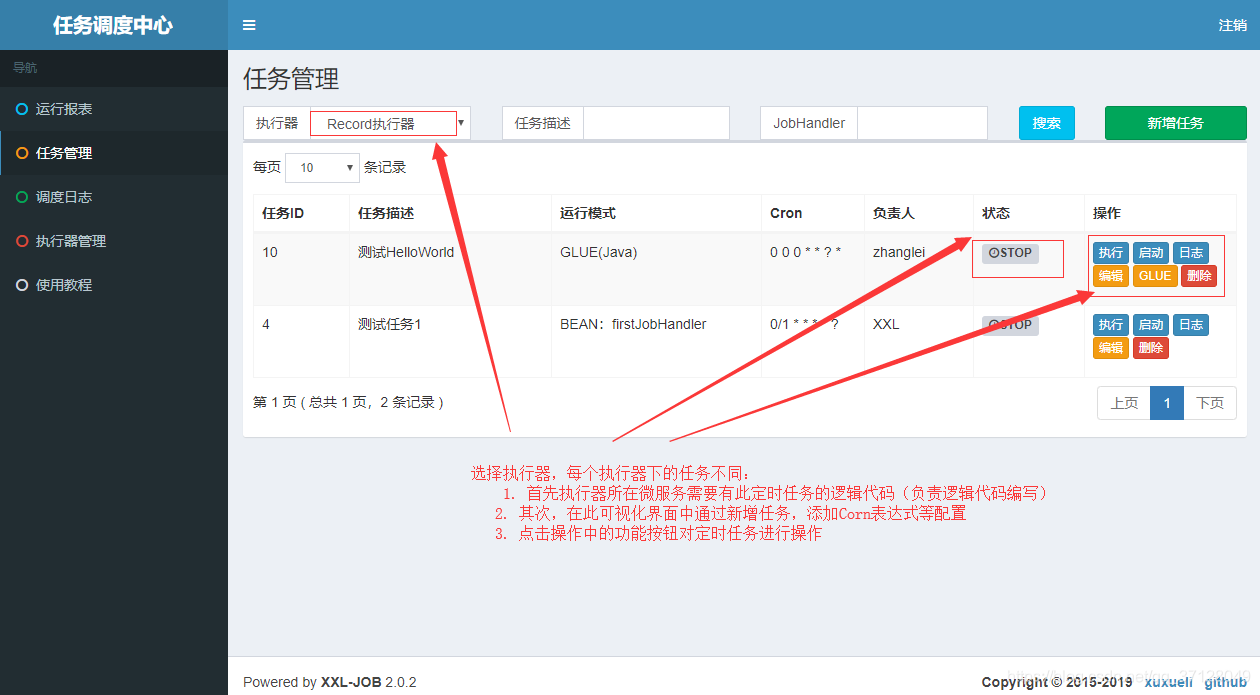
8.如果点击执行任务,则会只执行一次
9.如果点击日志,则跳转至调度日志页面
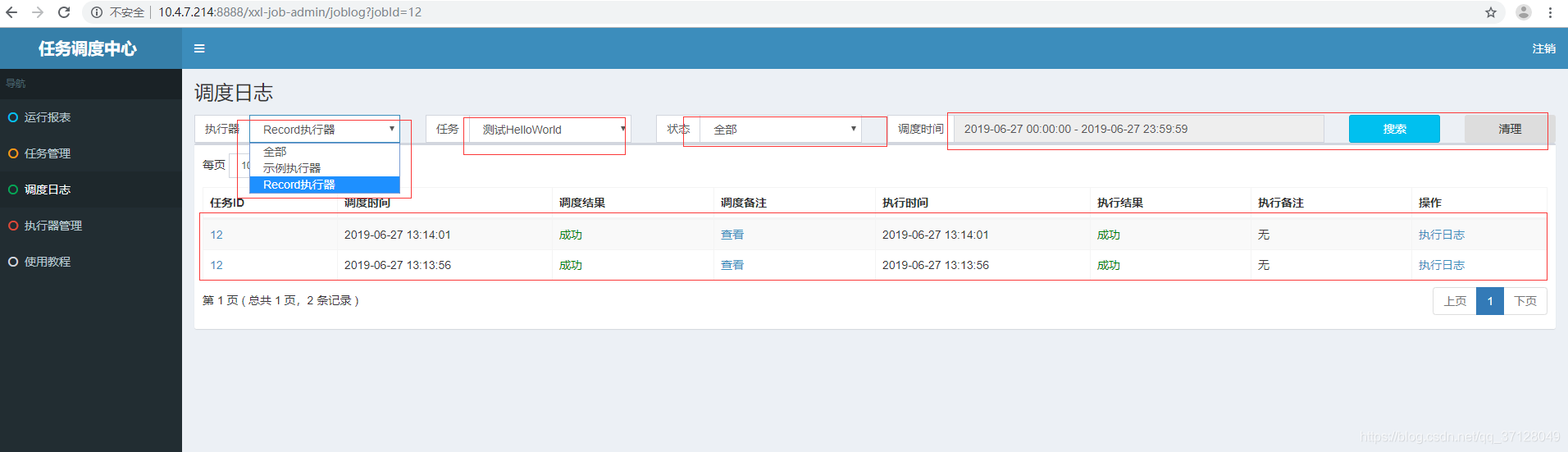
10.如果点击启动,则直接启动定时任务(按照Corn表达式定时执行任务),并且启动按钮会变成停止按钮
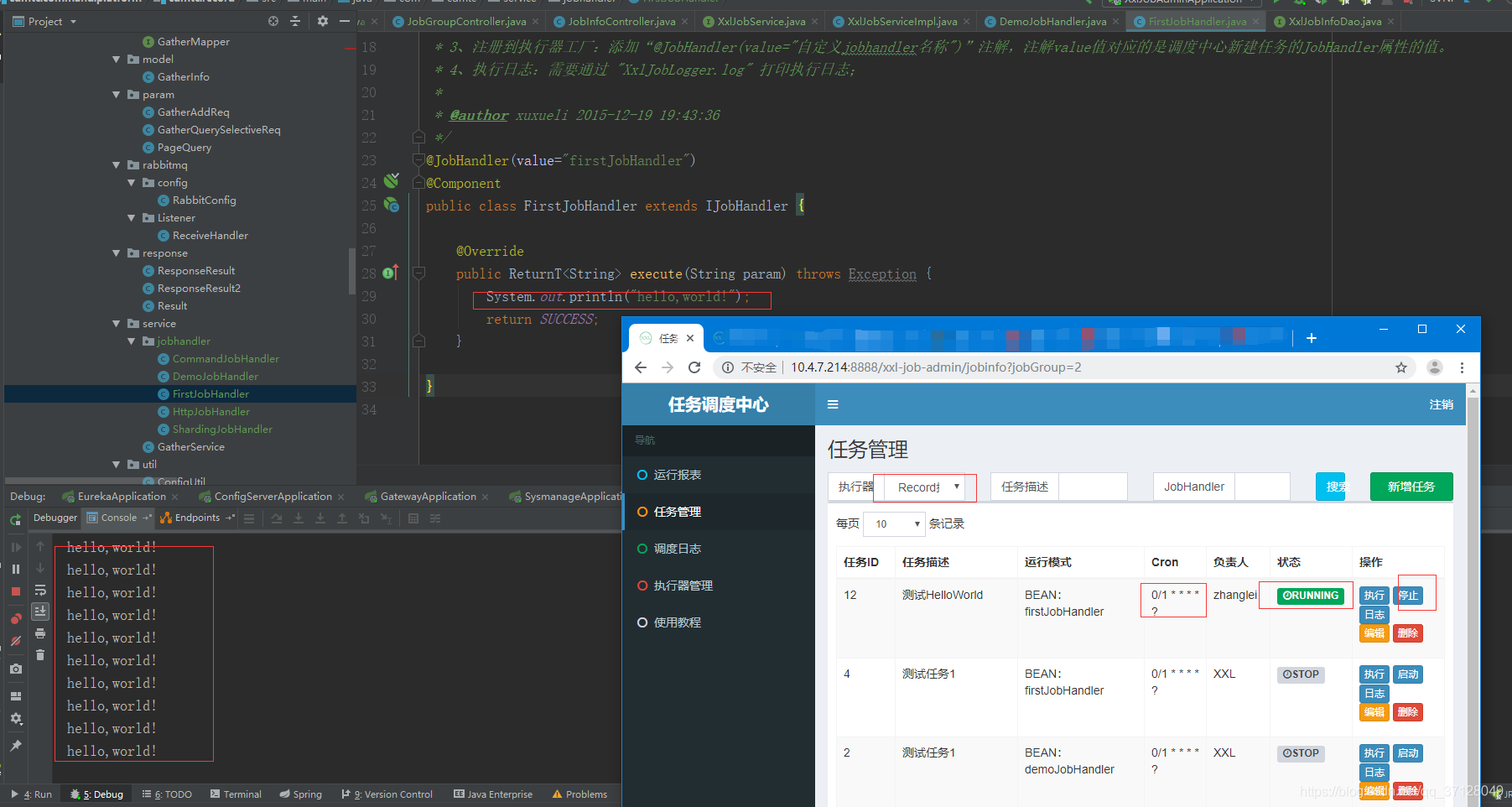
- 如果没有点击停止按钮的话,则会一直是启动状态,如果点击了停止按钮,则定时任务停止,Corn表达式不再生效;
11.如果点击编辑,则进入定时任务的更新页面
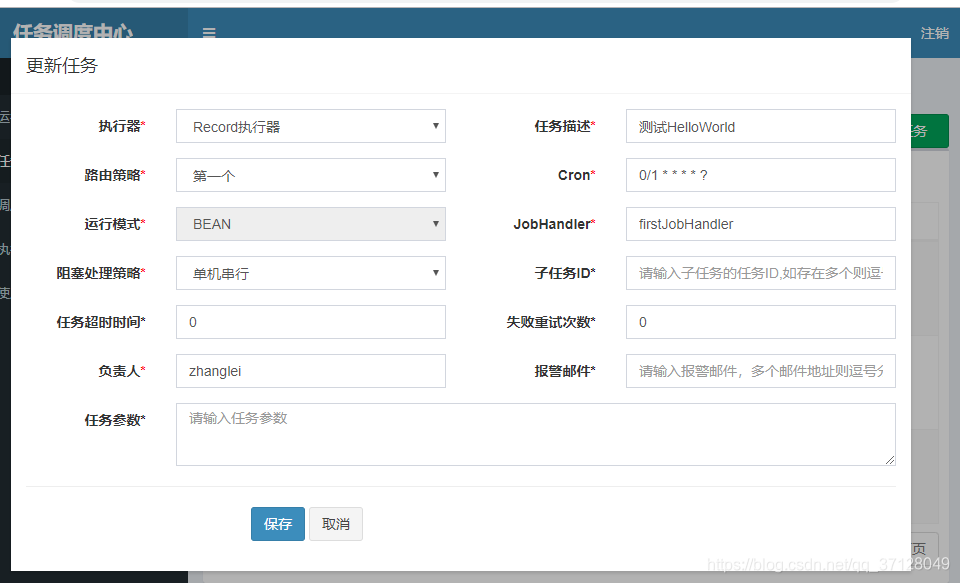
-
如果点击删除,则直接删除此定时任务配置;
-
如果点击执行器,则展示该执行器下的对应定时任务。
-
任务描述和JobHandler则为搜索条件,对定时任务配置进行搜索;
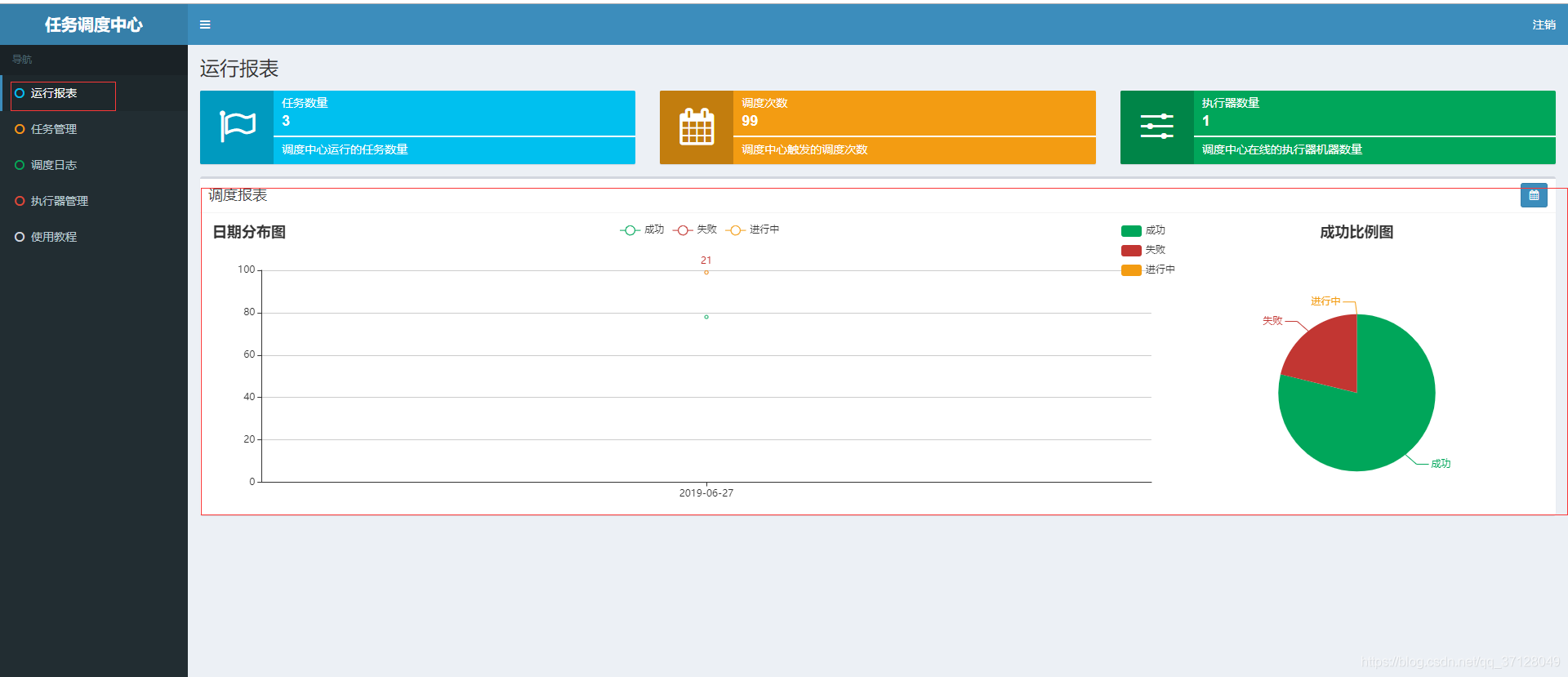
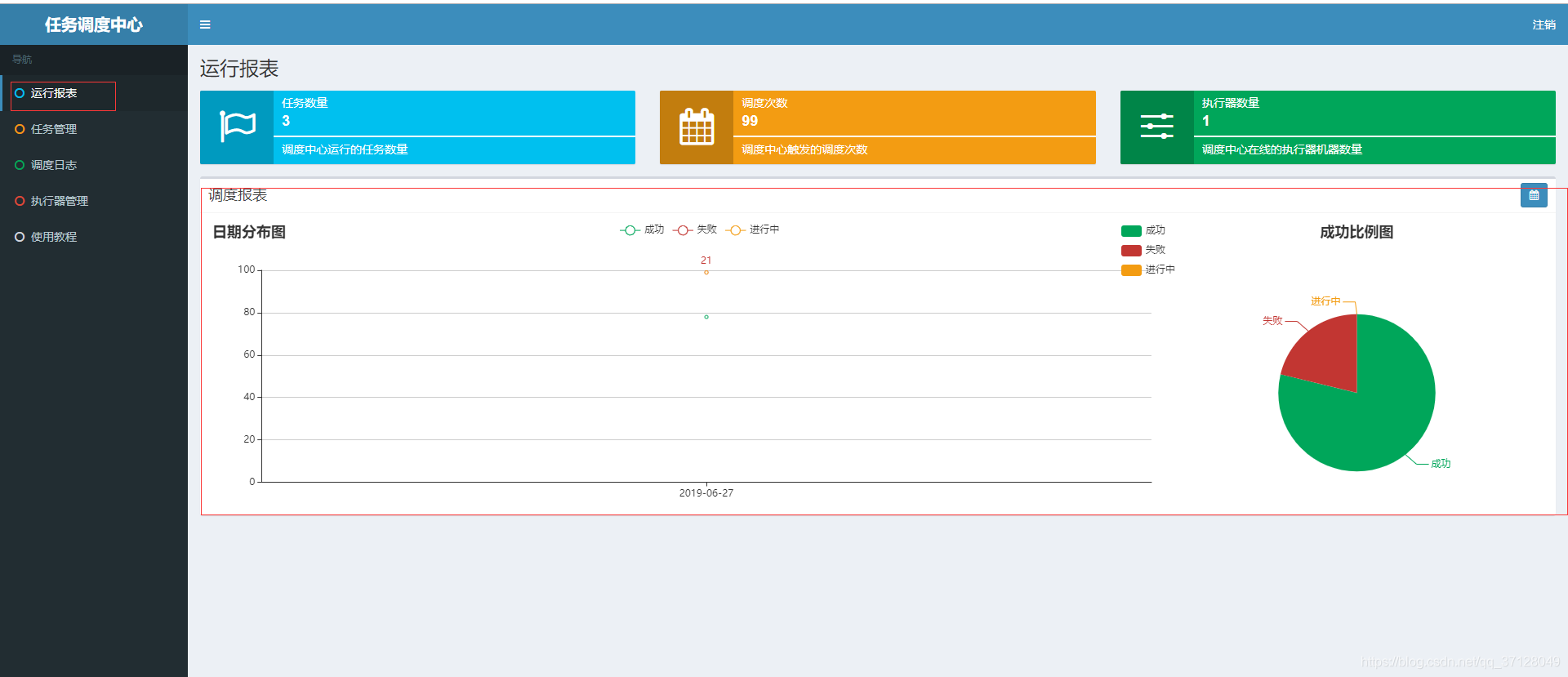
2.5 运行报表
- 可视化直观展示定时任务运行情况
- 图示如下: